文本分类——运行代码text-classification-cnn-rnn-master
Text Classification with CNN and RNN
使用卷积神经网络以及循环神经网络进行中文文本分类
1、 环境配置
-
Python 2/3
-
TensorFlow 1.3以上
-
numpy
-
scikit-learn
-
scipy
2、 数据集
使用THUCNews的一个子集进行训练与测试,
本次训练使用了其中的10个分类,每个分类6500条数据。
类别如下:
```
体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐
```
这个子集可以在此下载:链接: https://pan.baidu.com/s/1hugrfRu 密码: qfud
数据集划分如下:
训练集: 5000*10
验证集: 500*10
测试集: 1000*10
原数据集生成子集:
helper下的两个脚本。
copy_data.sh用于从每个分类拷贝6500个文件,
#!/bin/bash
# copy MAXCOUNT files from each directory
MAXCOUNT=6500
# shellcheck disable=SC2045
for category in $( ls D:/data_training_sample/THUCNews); do
echo item: $category
dir=D:/data_training_sample/THUCNews/$category
newdir=D:/data_training_sample/helper/txt
if [ -d $newdir ]; then
rm -rf $newdir
mkdir $newdir
fi
COUNTER=1
for i in $(ls $dir); do
cp $dir/$i $newdir
if [ $COUNTER -ge $MAXCOUNT ]
then
echo finished
break
fi
let COUNTER=COUNTER+1
done
done
cnews_group.py用于将多个文件整合到一个文件中。执行该文件后,得到三个数据文件:
- cnews.train.txt: 训练集(50000条)
- cnews.val.txt: 验证集(5000条)
- cnews.test.txt: 测试集(10000条)
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
将文本整合到 train、test、val 三个文件中
"""
import os
def _read_file(filename):
"""读取一个文件并转换为一行"""
with open(filename, 'r', encoding='utf-8') as f:
return f.read().replace('\n', '').replace('\t', '').replace('\u3000', '')
def save_file(dirname):
"""
将多个文件整合并存到3个文件中
dirname: 原数据目录
文件内容格式: 类别\t内容
"""
f_train = open('D:/text-classification-cnn-rnn-master/data/cnews/cnews.train.txt', 'w', encoding='utf-8')
f_test = open('D:/text-classification-cnn-rnn-master/data/cnews/cnews.test.txt', 'w', encoding='utf-8')
f_val = open('D:/text-classification-cnn-rnn-master/data/cnews/cnews.val.txt', 'w', encoding='utf-8')
for category in os.listdir(dirname): # 分类目录
# cat_dir = os.path.join(dirname, category)
#if not os.path.isdir(cat_dir):
# continue
cat_dir = dirname + '/'+ category
files = os.listdir('D:/data_training_sample/helper/txt')
count = 0
for cur_file in files:
filename = os.path.join(cat_dir, cur_file)
content = _read_file(filename)
if count < 5000:
f_train.write(category + '\t' + content + '\n')
elif count < 6000:
f_test.write(category + '\t' + content + '\n')
else:
f_val.write(category + '\t' + content + '\n')
count += 1
print('Finished:', category)
f_train.close()
f_test.close()
f_val.close()
if __name__ == '__main__':
save_file('D:/data_training_sample/helper/txt')
print(len(open('D:/text-classification-cnn-rnn-master/data/cnews/cnews.train.txt', 'r', encoding='utf-8').readlines()))
print(len(open('D:/text-classification-cnn-rnn-master/data/cnews/cnews.test.txt', 'r', encoding='utf-8').readlines()))
print(len(open('D:/text-classification-cnn-rnn-master/data/cnews/cnews.val.txt', 'r', encoding='utf-8').readlines()))
3、 预处理
data/cnews_loader.py为数据的预处理文件。
- read_file(): 读取文件数据;
- build_vocab(): 构建词汇表,使用字符级的表示,这一函数会将词汇表存储下来,避免每一次重复处理;
- read_vocab(): 读取上一步存储的词汇表,转换为{词:id}表示;
- read_category(): 将分类目录固定,转换为{类别: id}表示;
- to_words(): 将一条由id表示的数据重新转换为文字;
- preocess_file(): 将数据集从文字转换为固定长度的id序列表示;
- batch_iter(): 为神经网络的训练准备经过shuffle的批次的数据。
经过数据预处理,数据的格式如下:
| Data | Shape | Data | Shape |
|---|---|---|---|
| x_train | [50000, 600] | y_train | [50000, 10] |
| x_val | [5000, 600] | y_val | [5000, 10] |
| x_test | [10000, 600] | y_test | [10000, 10] |
这个文件没有改文件名的,只有类别需要更改,做的时候先用10个,和源程序的个数一样,否则中间出了问题就不好办了。(尽量选择文件多的文件类别)。
4、 RNN循环神经网络
配置项
RNN可配置的参数如下所示,在rnn_model.py中。之后在run_rnn.py中调用
关于类别数目:
除了修改cnews_loader里面的矩阵数目,还要修改rnn_module里面的类别数,可以完成任意数目的分类了:
class TRNNConfig(object):
"""RNN配置参数"""
# 模型参数
embedding_dim = 64 # 词向量维度
seq_length = 600 # 序列长度
num_classes = 10 # 类别数
vocab_size = 5000 # 词汇表达小
num_layers= 2 # 隐藏层层数
hidden_dim = 128 # 隐藏层神经元
rnn = 'gru' # lstm 或 gru
dropout_keep_prob = 0.8 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 128 # 每批训练大小
num_epochs = 10 # 总迭代轮次
print_per_batch = 100 # 每多少轮输出一次结果
save_per_batch = 10 # 每多少轮存入tensorboard
RNN模型
具体参看rnn_model.py的实现。
大致结构如下:
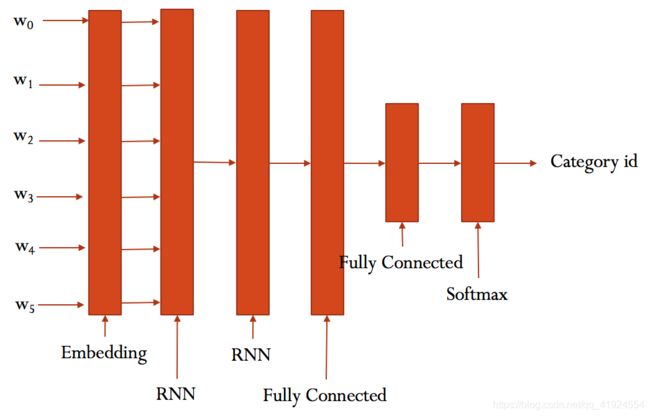
训练与验证
运行 python run_rnn.py train,开始训练。
若之前进行过训练,请把tensorboard/textrnn删除,避免TensorBoard多次训练结果重叠。
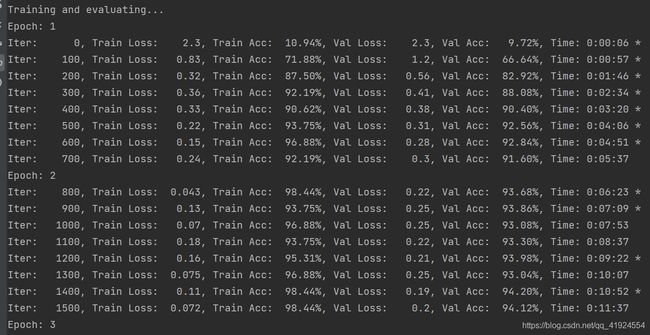
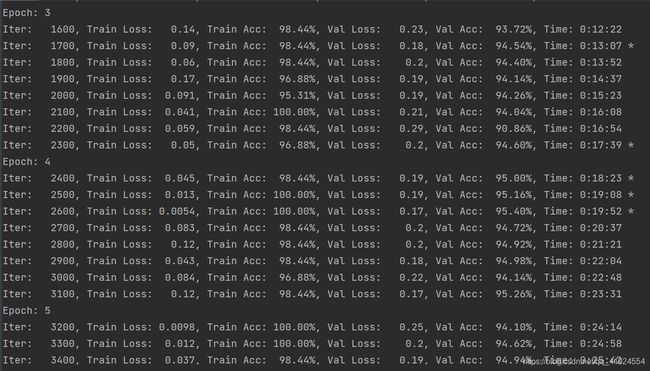

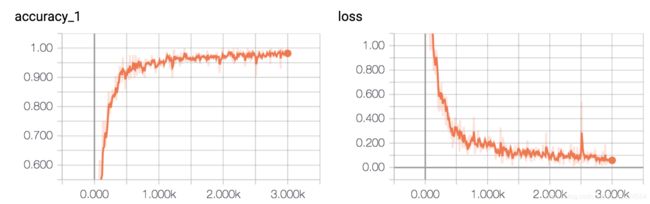
在验证集上的最佳效果为95.40%,经过了5轮迭代停止
准确率和误差如图所示:
测试
运行 python run_rnn.py test 在测试集上进行测试。
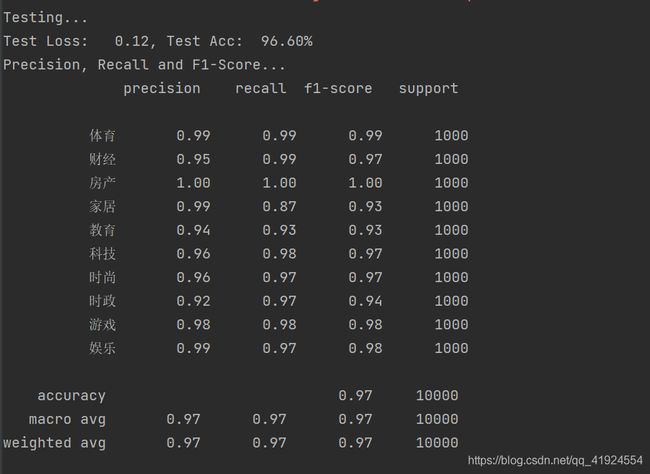
在测试集上的准确率达到了96.60%,且各类的precision, recall和f1-score,除了家居这一类别,都超过了0.9。
从混淆矩阵可以看出分类效果非常优秀。
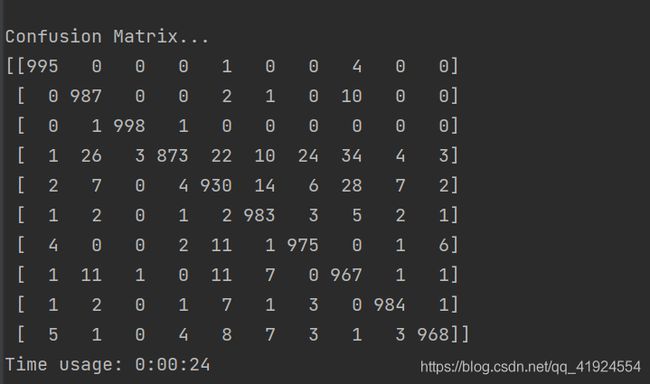
可见RNN除了在家居分类的表现不是很理想,其他几个类别都可以。
还可以通过进一步的调节参数,来达到更好的效果。