聚类算法-K-means 和 DBSCAN【机器学习笔记简摘】
简介
决策树,随机森林,PCA和逻辑回归,他们虽然有着不同的功能,但却都属于“有监督学习”的一部分,即是说,模型在训练的时候,即需要特征矩阵X,也需要真实标签y。机器学习当中,还有相当一部分算法属于“无监督学习”,无监督的算法在训练的时候只需要特征矩阵X,不需要标签。而聚类算法,就是无监督学习的代表算法。
聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇)。这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。比如在商业中,如果我们手头有大量的当前和潜在客户的信息,我们可以使用聚类将客户划分为若干组,以便进一步分析和开展营销活动,最有名的客户价值判断模型RFM,就常常和聚类分析共同使用。再比如,聚类可以用于降维和矢量量化(vectorquantization),可以将高维特征压缩到一列当中,常常用于图像,声音,视频等非结构化数据,可以大幅度压缩数据量。
聚类算法与分类算法最大的区别
聚类算法是无监督的学习算法,而分类算法属于监督的学习算法。
| 聚类 | 分类 | |
|---|---|---|
| 核心 | 将数据分成多个组 探索每个组的数据是否有联系 |
从已经分组的数据中去学习 把新数据放到已经分好的组中去 |
| 学习类型 | 无监督,无需标签进行训练 | 有监督,需要标签进行训练 |
| 典型算法 | k-Means-,DBSCAN,层次聚类,光谱聚类 | 决策树,贝叶斯,逻辑回归 |
| 算法输出 | 聚类结果是不确定的 不一定总是能够反映数据的真实分类 同样的聚类,根据不同的业务需求 可能是一个好结果,也可能是一个坏结果 |
分类结果是确定的 分类的优劣是客观的 不是根据业务或算法需求决定 |
聚类相关API
| 类 | 含义 | 输入 []内代表可以选择输入,[]外代表必须输入 |
|---|---|---|
| cluster. AffinityPropagation | 执行亲和传播数据聚类 | [damping,…] |
| cluster. AgglomerativeClustering | 凝聚聚类 | [,…] |
| cluster.Birch | 实现 Birch聚类算法 | [threshold, branching_factor,…] |
| cluster.DBSCAN | 从矢量数组或距离矩阵执行 DBSCAN聚类 | [eps,min_ samples, metric,…] |
| cluster. FeatureAgglomeration | 凝聚特征 | [n_clusters,…] |
| cluster. KMeans | K均值聚类 | [n_clusters, init, n_init,…] |
| cluster. MiniBatchKMeans | 小批量K均值聚类 | [n_clusters,init,…] |
| cluster. MeanShift | 使用平坦核函数的平均移位聚类 | [bandwidth, seeds,…] |
| cluster. SpectralClustering | 光谱聚类,将聚类应用于规范化拉普拉斯的投影 | [nclusters,…] |
| 函数 | 含义 | 输入 |
| cluster.affinity_propagation | 执行亲和传播数据聚类 | S[,…] |
| cluster.dbscan | 从矢量数组或距离矩阵执行 DBSCAN聚类 | X[, eps, min_samples,…] |
| cluster.estimate bandwidth | 估计要使用均值平移算法的带宽 | X[, quantile,…] |
| cluster.k_means | K均值聚类 | X,n_clusters[,…] |
| cluster.mean_shift | 使用平坦核函数的平均移位聚类 | X[, bandwidth, seeds, …] |
| cluster.spectral_clustering | 将聚类应用于规范化拉普拉斯的投影 | affinity[,…] |
| cluster.ward_tree | 光谱聚类,将聚类应用于规范化拉普拉斯的投影 | X[, connectivity,…] |
需要注意的一件重要事情是,该模块中实现的算法可以采用不同类型的矩阵作为输入。所有方法都接受形状[n_samples,n_features]的标准特征矩阵,这些可以从sklearn.feature_extraction模块中的类中获得。对于亲和力传播,光谱聚类和DBSCAN,还可以输入形状[n_samples,n_samples]的相似性矩阵,我们可以使用sklearn.metrics.pairwise模块中的函数来获取相似性矩阵。
k-means概述
k-means其实包含两层内容:
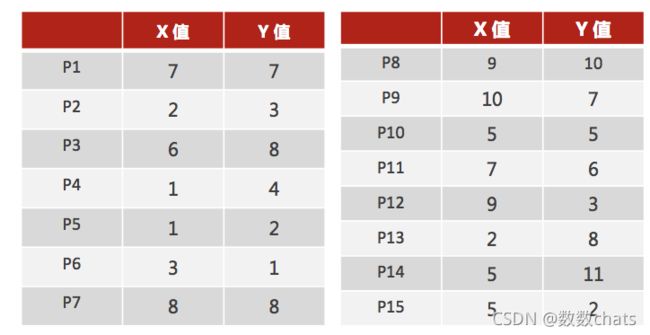
K : 初始中心点个数(计划聚类数)
means:求中心点到其他数据点距离的平均值
k-means聚类步骤
- 1、随机设置K个特征空间内的点作为初始的聚类中心(一般选取平均点)
- 2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程
通过下图解释实现流程:
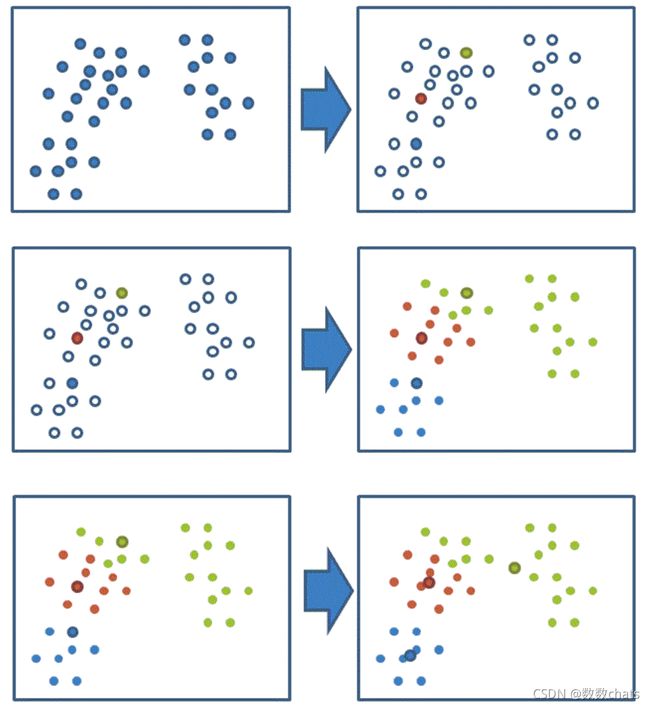
说明案例
1、随机设置K个特征空间内的点作为初始的聚类中心(本案例中设置p1和p2)
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
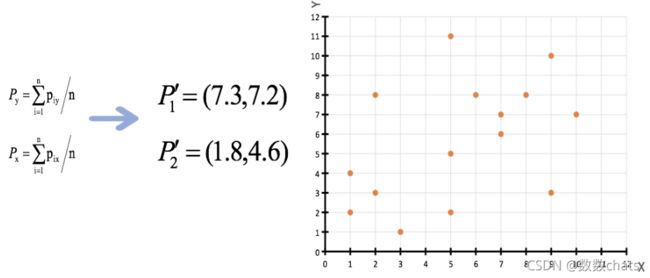
4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程【经过判断,需要重复上述步骤,开始新一轮迭代】
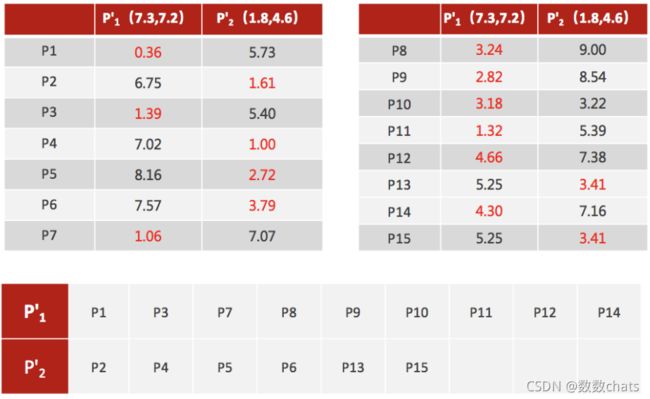
5、当每次迭代结果不变时,认为算法收敛,聚类完成,K-Means一定会停下,不可能陷入一直选质心的过程。
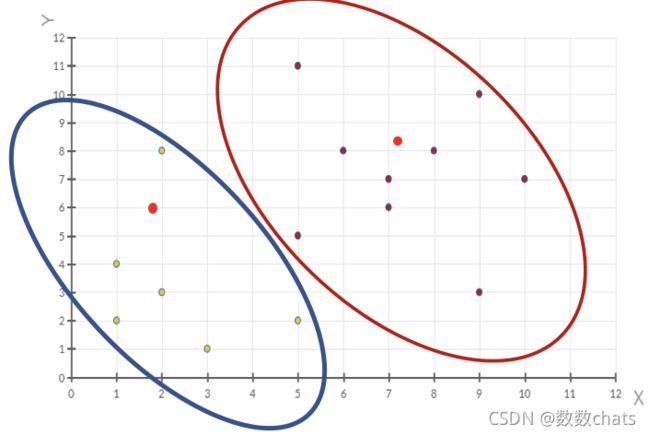
小结
流程:
- 事先确定常数K,常数K意味着最终的聚类类别数;
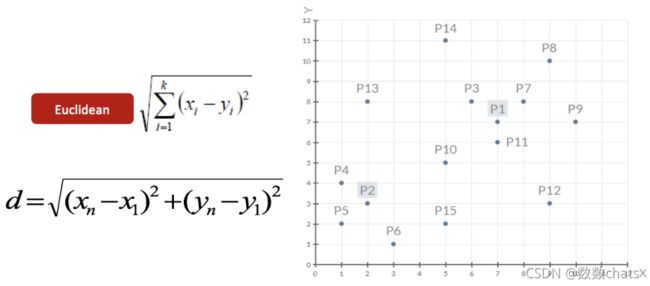
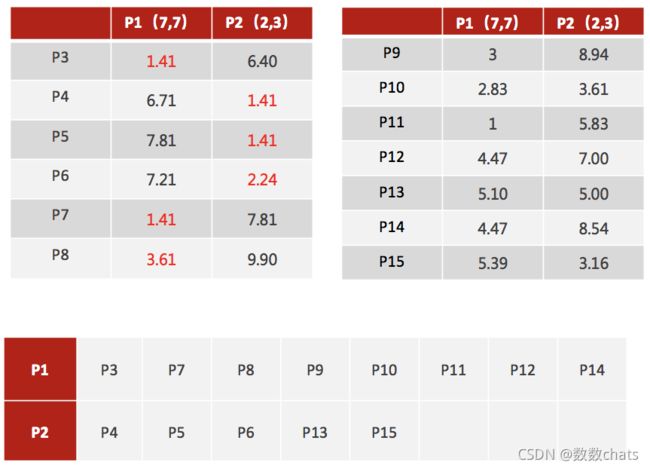
- 首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,
- 接着,重新计算每个类的质心(即为类中心),重复这样的过程,直到质心不再改变,
- 最终就确定了每个样本所属的类别以及每个类的质心。
注意:
- 由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。
| Kmeans有损失函数吗? |
|---|
| 记得我们在逻辑回归中曾有这样的结论:损失函数本质是用来衡量模型的拟合效果的,只有有着求解参数需求的算法,才会有损失函数。Kmeans不求解什么参数,它的模型本质也没有在拟合数据,而是在对数据进行一 种探索。所以如果你去问大多数数据挖掘工程师,甚至是算法工程师,他们可能会告诉你说,K-Means不存在 什么损失函数,Inertia更像是Kmeans的模型评估指标,而非损失函数。 但我们类比过了Kmeans中的Inertia和逻辑回归中的损失函数的功能,我们发现它们确实非常相似。所以, 从“求解模型中的某种信息,用于后续模型的使用“这样的功能来看,我们可以认为Inertia是Kmeans中的损失函数,虽然这种说法并不严谨。 对比来看,在决策树中,我们有衡量分类效果的指标准确度accuracy,我们不能通过最小化accuracy来求解某个模型中需要的信息。因此决策树,KNN等算法,是绝对没有损失函数的。 |
KMeans算法api
from sklearn.cluster import KMeans
class sklearn.cluster.KMeans(n_clusters=8, *, init='k-means++', n_init=10, max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True, algorithm='auto')
-
参数:
n_clusters:整形,缺省值=8 【生成的聚类数,即产生的质心(centroids)数。】
max_iter:整形,缺省值=300 , 执行一次k-means算法所进行的最大迭代数。
n_init:整形,缺省值=10
用不同的质心初始化值运行算法的次数,最终解是在inertia意义下选出的最优结果。
init:有三个可选值:’k-means++’, ‘random’,或者传递一个ndarray向量。
此参数指定初始化方法,默认值为 ‘k-means++’。
(1)‘k-means++’ 用一种特殊的方法选定初始质心从而能加速迭代过程的收敛(即上文中的k-means++介绍)
(2)‘random’ 随机从训练数据中选取初始质心。
(3)如果传递的是一个ndarray,则应该形如 (n_clusters, n_features) 并给出初始质心。
precompute_distances:三个可选值,‘auto’,True 或者 False。
预计算距离,计算速度更快但占用更多内存。
(1)‘auto’:如果 样本数乘以聚类数大于 12million 的话则不预计算距离。This corresponds to about 100MB overhead per job using double precision.
(2)True:总是预先计算距离。
(3)False:永远不预先计算距离。
tol:float形,默认值= 1e-4 与inertia结合来确定收敛条件。
n_jobs:整形数。 指定计算所用的进程数。内部原理是同时进行n_init指定次数的计算。
(1)若值为 -1,则用所有的CPU进行运算。若值为1,则不进行并行运算,这样的话方便调试。
(2)若值小于-1,则用到的CPU数为(n_cpus + 1 + n_jobs)。因此如果 n_jobs值为-2,则用到的CPU数为总CPU数减1。
random_state:整形或 numpy.RandomState 类型,可选
用于初始化质心的生成器(generator)。如果值为一个整数,则确定一个seed。此参数默认值为numpy的随机数生成器。
copy_x:布尔型,默认值=True
当我们precomputing distances时,将数据中心化会得到更准确的结果。如果把此参数值设为True,则原始数据不会被改变。如果是False,则会直接在原始数据
上做修改并在函数返回值时将其还原。但是在计算过程中由于有对数据均值的加减运算,所以数据返回后,原始数据和计算前可能会有细小差别。属性:
cluster_centers_:向量,[n_clusters, n_features] (聚类中心的坐标)
labels_: 每个点的分类
inertia_:float形,每个点到其簇的质心的距离之和。
get_params([deep]):取得估计器的参数。
score(X[,y]):计算聚类误差
set_params(**params):为这个估计器手动设定参数。
transform(X[,y]): 将X转换为群集距离空间。
在新空间中,每个维度都是到集群中心的距离。 请注意,即使X是稀疏的,转换返回的数组通常也是密集的。 -
方法:
- estimator.fit(x)
- estimator.predict(x)
- estimator.fit_predict(x)
- 计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1)
fig, ax1 = plt.subplots(1)
ax1.scatter(X[:, 0], X[:, 1]
, marker='o' # 点的形状
, s=8 # 点的大小
)
plt.show()
# 如果我们想要看见这个点的分布,怎么办?
color = ["red", "pink", "orange", "gray"]
fig, ax1 = plt.subplots(1)
for i in range(4):
ax1.scatter(X[y == i, 0], X[y == i, 1]
, marker='o' # 点的形状
, s=8 # 点的大小
, c=color[i]
)
plt.show()
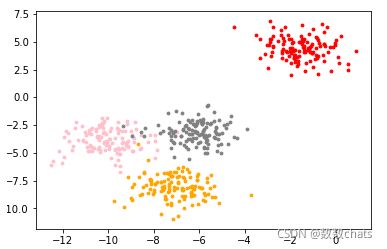
# 有了数据之后,我们来猜测数据集的簇
from sklearn.cluster import KMeans
n_clusters = 3 # 指定为3簇
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
# 不用predict,可以直接使用cluster.labels来展示分好的簇
y_pred = cluster.labels_
y_pred
#当数据量比较大的时候,用predict
#KMeans因为并不需要建立模型或者预测结果,因此我们只需要fit就能够得到聚类结果了
#KMeans也有接口predict和fit_predict,表示学习数据X并对X的类进行行预测
#但所得到的结果和我们不调用predict,直接fit之后调用属性Labels一模一样
pre = cluster.fit_predict(X)
print(pre)
print(pre == y_pred)
#我们什么时候需要predict呢?当数前量太人的时候!
#其实我们不必使用所有的数据来寻找质心,少量的数据就可以帮助我们确定质心了
#当我们数据量非常大的时候,我们可以使用部分费据来帮励我们确认质心
#剩下的数据的聚类结果,使用predict来用
cluster_smallsub = KMeans(n_clusters=n_clusters, random_state=0).fit(X[:200]) #从500个样本选择200个来训练
y_pred_ = cluster_smallsub.predict(X)
y_pred == y_pred_ # 部分相等,部分不等
#但这样的结果,肯定与直接fit全部费据会不一致。有时候,当我们不要求都么精确,或者我们的数据解实在太大,我们可以使用这种方法
#重要属性cLuster_centers_,查看质心
centroid = cluster.cluster_centers_
centroid
#重要属性inertia_,查看总距离平方和
inertia = cluster.inertia_
inertia
# 对聚出来的类进行可视化
color = ["red", "pink", "orange", "gray"]
fig, ax1 = plt.subplots(1)
for i in range(n_clusters):
ax1.scatter(X[y_pred == i, 0], X[y_pred == i, 1]
, marker='o'
, s=8
, c=color[i]
)
ax1.scatter(centroid[:, 0], centroid[:, 1]
, marker="x"
, s=15
, c="black")
plt.show()
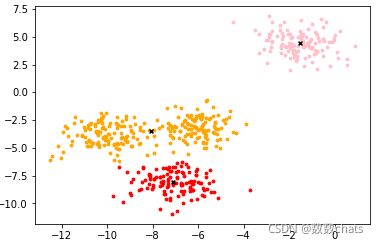
n_clusters = 4
cluster_ = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
inertia_ = cluster_.inertia_
inertia_
模型评估
聚类模型的结果不是某种标签输出,并且聚类的结果是不确定的,其优劣由业务需求或者算法需求来决定,并且没有永远的正确答案。那我们如何衡量聚类的效果呢?
0.sse
误差平方和
值越小越好
1. 肘部法
下降率突然变缓时即认为是最佳的k值
2. SC系数
取值为[-1, 1],其值越大越好
3. CH系数
分数s高则聚类效果越好
CH需要达到的目的:
用尽量少的类别聚类尽量多的样本,同时获得较好的聚类效果。
1、误差平方和
(SSE \The sum of squares due to error):
举例:(下图中数据-0.2, 0.4, -0.8, 1.3, -0.7, 均为真实值和预测值的差)

在k-means中的应用:
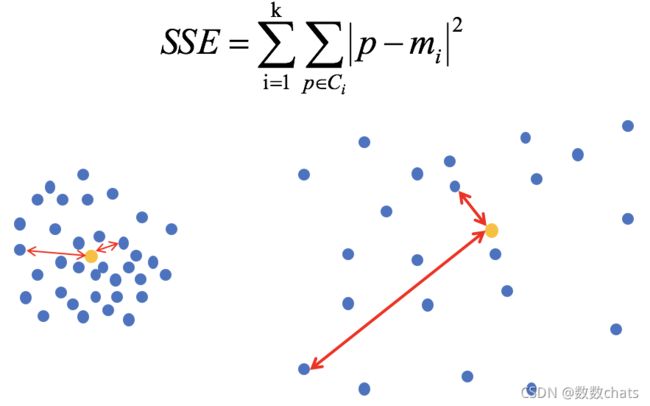
公式各部分内容:
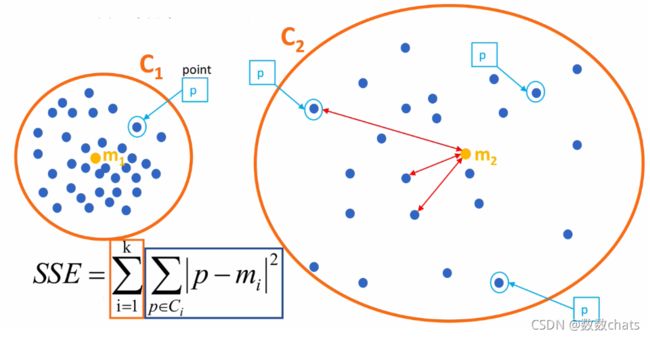
上图中: k=2
-
SSE图最终的结果,对图松散度的衡量.(eg: SSE(左图)
-
SSE随着聚类迭代,其值会越来越小,直到最后趋于稳定:
-
如果质心的初始值选择不好,SSE只会达到一个不怎么好的局部最优解.
首先,它不是有界的。我们只知道,Inertia是越小越好,是0最好,但我们不知道,一个较小的Inertia究竟有没有达到模型的极限,能否继续提高。
第二,它的计算太容易受到特征数目的影响,数据维度很大的时候,Inertia的计算量会陷入维度诅咒之中,计算量会爆炸,不适合用来一次次评估模型。
第三,它会受到超参数K的影响,在我们之前的常识中其实我们已经发现,随着K越大,Inertia注定会越来越小,但这并不代表模型的效果越来越好了
第四,Inertia对数据的分布有假设,它假设数据满足凸分布(即数据在二维平面图像上看起来是一个凸函数的样子),并且它假设数据是各向同性的(isotropic),即是说数据的属性在不同方向上代表着相同的含义。但是现实中的数据往往不是这样。所以使用Inertia作为评估指标,会让聚类算法在一些细长簇,环形簇,或者不规则形状的流形时表现不佳:
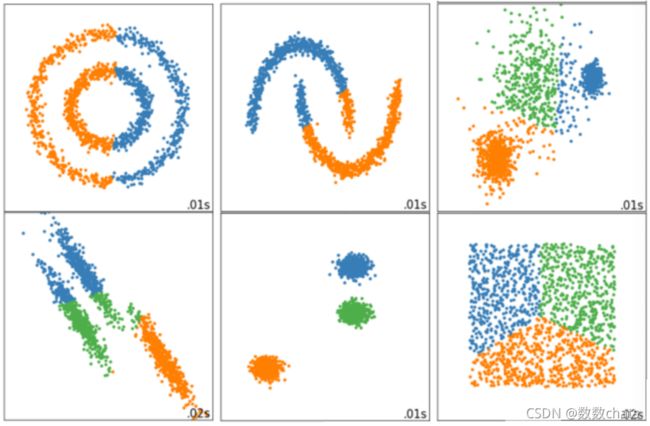
2、“肘”方法 (Elbow method) — K值确定

(1)对于n个点的数据集,迭代计算k from 1 to n,每次聚类完成后计算每个点到其所属的簇中心的距离的平方和;
(2)平方和是会逐渐变小的,直到k==n时平方和为0,因为每个点都是它所在的簇中心本身。
(3)在这个平方和变化过程中,会出现一个拐点也即“肘”点,下降率突然变缓时即认为是最佳的k值。
在决定什么时候停止训练时,肘形判据同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
3、轮廓系数法(Silhouette Coefficient)
结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果:
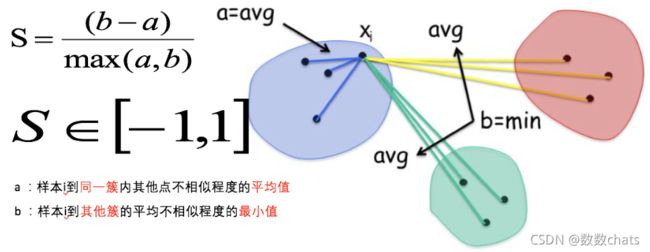
目的:
内部距离最小化,外部距离最大化
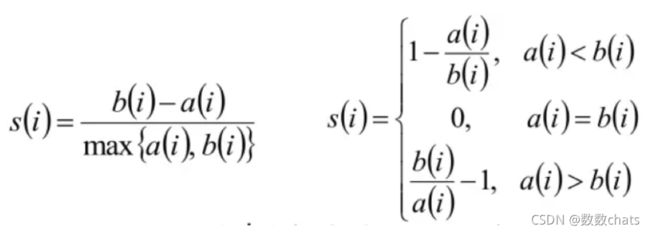
计算样本i到同簇其他样本的平均距离ai,ai 越小样本i的簇内不相似度越小,说明样本i越应该被聚类到该簇。
计算样本i到最近簇Cj 的所有样本的平均距离bij,称样本i与最近簇Cj 的不相似度,定义为样本i的簇间不相似度:bi =min{bi1, bi2, …, bik},bi越大,说明样本i越不属于其他簇。
求出所有样本的轮廓系数后再求平均值就得到了平均轮廓系数。
平均轮廓系数的取值范围为[-1,1],系数越大,聚类效果越好。
簇内样本的距离越近,簇间样本距离越远
优缺点:
轮廓系数有很多优点,它在有限空间中取值,使得我们对模型的聚类效果有一个“参考”。并且,轮廓系数对数据的分布没有假设,因此在很多数据集上都表现良好。但它在每个簇的分割比较清洗时表现最好。但轮廓系数也有缺陷,它在凸型的类上表现会虚高,比如基于密度进行的聚类,或通过DBSCAN获得的聚类结果,如果使用轮廓系数来衡量,则会表现出比真实聚类效果更高的分数。
4、CH系数(Calinski-Harabasz Index)
卡林斯基-哈拉巴斯指数(Calinski-Harabaz Index,简称CHI,也被称为方差比标准),戴维斯-布尔丁指数(Davies-Bouldin)以及权变矩阵(Contingency Matrix)可以使用。
| 标签未知时的评估指标 |
|---|
| 卡林斯基-哈拉巴斯指数 sklearn.metrics.calinski_harabaz_score (X, y_pred) |
| 戴维斯-布尔丁指数 sklearn.metrics.davies_bouldin_score (X, y_pred) |
| 权变矩阵 sklearn.metrics.cluster.contingency_matrix (X, y_pred) |
Calinski-Harabasz:
类别内部数据的协方差越小越好,类别之间的协方差越大越好(换句话说:类别内部数据的距离平方和越小越好,类别之间的距离平方和越大越好),
数据之间的离散程度越高,协方差矩阵的迹就会越大。组内离散程度低,协方差的迹就会越小, t r ( W k ) tr (W_k) tr(Wk)也就越小,同时,组间离散程度大,协方差的的迹也会越大, t r ( B k ) tr (B_k) tr(Bk)就越大,这正是我们希望的,因此Calinski-harabaz指数越高越好。
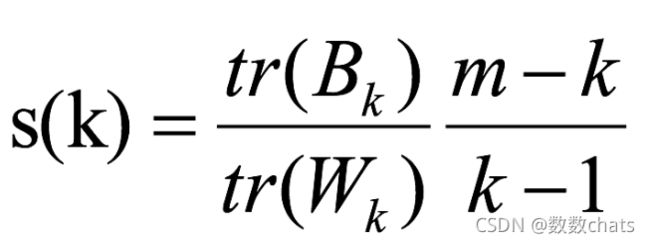
tr为矩阵的迹, B k B_k Bk为类别之间的协方差矩阵, W k W_k Wk为类别内部数据的协方差矩阵;
m为训练集样本数,k为类别数。
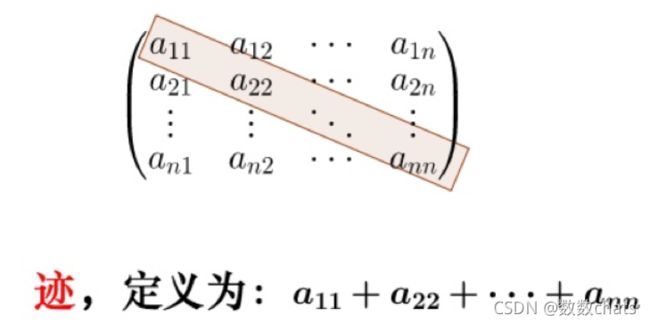
使用矩阵的迹进行求解的理解:
矩阵的对角线可以表示一个物体的相似性
在机器学习里,主要为了获取数据的特征值,那么就是说,在任何一个矩阵计算出来之后,都可以简单化,只要获取矩阵的迹,就可以表示这一块数据的最重要的特征了,这样就可以把很多无关紧要的数据删除掉,达到简化数据,提高处理速度。
CH需要达到的目的:
用尽量少的类别聚类尽量多的样本,同时获得较好的聚类效果。
小结
1. 肘部法
下降率突然变缓时即认为是最佳的k值
2. SC系数
取值为[-1, 1],其值越大越好
3. CH系数
分数s高则聚类效果越好
案例:基于轮廓系数来选择n_clusters
我们通常会绘制轮廓系数分布图和聚类后的数据分布图来选择我们的最佳n_clusters。
#基于我们的轮廓系数来选择最佳的n_clusters
#知道每个聚出来的类的轮廓系数是多少,还想要一个各个类之间的轮廓系数的对比
#知道聚类完华之后图像的分布是什么模样
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
X, y = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1)
n_clusters = 4
clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X)
cluster_labels = clusterer.labels_
#调用轮廓系数分数,注意,silhouette_score生成的是所有样本点的轮廓系数均值
#两个需要输入的参数是,特征矩X和聚类完毕后的标签
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters,"The average silhouette_score is :", silhouette_avg)
#调用silhouette_samples,返回每个样本点的轮廓系数,这就是我们的横坐标
sample_silhouette_values = silhouette_samples(X, cluster_labels)
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(18, 7)
#首先我们来设定横坐标
#轮廓系数的取值范围在[-1,1]之间,但我们至少是希望轮廓系数要大于0的
#太长的横坐标不利于我们的可视化,所以只设定x轴的取值在[-0.1,1]之间
ax1.set_xlim([-0.1, 1])
#接下来设定纵坐标,通常来说,纵坐标是从0开始,最大值取到X.shape[0]的取值
#但我们希望,每个簇能够排在一起,不同的簇之间能够有一定的空隙
#以便我们看到不同的条形图聚合成的块,理解它是对应了哪一个簇
#因此我们在设定纵坐标的取值范围的时候,在x.shape[0]上,加上一个距离(n_clusters+1)*10,留作间隔用
ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])
y_lower = 10
for i in range(n_clusters):
#从每个样本的轮廓系数结果中抽取出第个的轮廓系数,并对他进行排序
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
#注意,.sort()这个命令会直接改掉原数据的顺序
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
#这一个簇在y轴上的较值,应该是由初始值(y_lower)开始,到初始值+加上这个簇中的样本数量结束(y_upper)
y_upper = y_lower + size_cluster_i
#coLormap库中的,使用小数来调用颜色的函数
#在nipy_spectral([输入在意小数来代表一个颜色])
#在这里我们希望每个簇的颜色是不同的,我们需要的颜色种类刚好是循环的个数的种类
#在这望,只要能够确保,每次语环生成的小数是不同的,可以使用在意方式来获取小数
#在这里,我是用i的浮点数除以n_clusters,在不同的i下,自然生成不同的小数
#以确保所有的簇会有不同的颜色
color = cm.nipy_spectral(float(i)/n_clusters)
#开始填充子图1中的内容
#fill_between是让一个范围中的柱状图都统一颜色的函数
#fill_betweenx的范围是在纵坐标上
#fill_betweeny的范围是在横坐标上
#fill_betweenx的参数应该输入(纵坐标的下限,纵坐标的上限,在状图的颜色)
ax1.fill_betweenx(np.arange(y_lower, y_upper)
,ith_cluster_silhouette_values
,facecolor=color
,alpha=0.7
)
#为每个簇的轮廓系数写上簇的编号,并且让簇的编号显示坐标轴上每个条形图的中间位置
#text的参数为(要显示编号的位置的横坐标,要显示编号的位置的纵坐标,要显示的编号内容)
ax1.text(-0.05
, y_lower + 0.5 * size_cluster_i
, str(i))
#为下一个簇计算新的y轴上的初始值,是每一次送代之后,y的上线再加上10
#以此来保证,不同的簇的图像之间显示有空隙
y_lower = y_upper + 10
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
#开始对第二个图进行处理,首先获取新颜色,由于这里没有循环,因此我们需要一次性生成多个小数来获取多个颜色
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1]
,marker='o' #点的形状
,s=8 #点的大小
,c=colors
)
centers = clusterer.cluster_centers_
ax2.scatter(centers[:, 0], centers[:, 1], marker='x',c="red", alpha=1, s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
#为整个图设理标题
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()
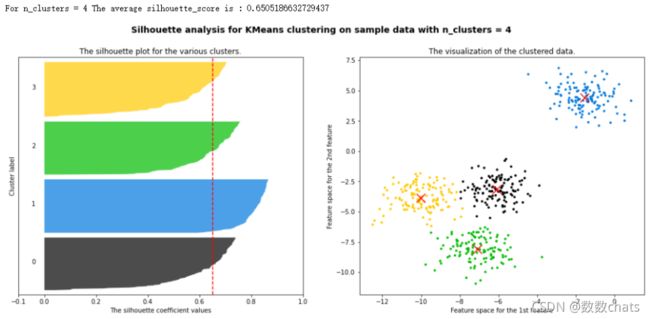
将上述过程包装成一个循环,可以得到:
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
X, y = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1)
for n_clusters in [2,3,4,5,6,7]:
n_clusters = n_clusters
clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X)
cluster_labels = clusterer.labels_
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters,
"The average silhouette_score is :", silhouette_avg)
sample_silhouette_values = silhouette_samples(X, cluster_labels)
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(18, 7)
ax1.set_xlim([-0.1, 1])
ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])
y_lower = 10
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i)/n_clusters)
ax1.fill_betweenx(np.arange(y_lower, y_upper)
,ith_cluster_silhouette_values
,facecolor=color
,alpha=0.7
)
ax1.text(-0.05
, y_lower + 0.5 * size_cluster_i
, str(i))
y_lower = y_upper + 10
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
#开始对第二个图进行处理,首先获取新颜色,由于这里没有循环,因此我们需要一次性生成多个小数来获取多个颜色
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1]
,marker='o'
,s=8
,c=colors
)
centers = clusterer.cluster_centers_
# Draw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='x',
c="red", alpha=1, s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()
重要参数init
初始簇心怎么放好
在K-Means中有一个重要的环节,就是放置初始质心。如果有足够的时间,K-means一定会收敛,但Inertia可能收敛到局部最小值。是否能够收敛到真正的最小值很大程度上取决于质心的初始化。init就是用来帮助我们决定初始化方式的参数。
初始质心放置的位置不同,聚类的结果很可能也会不一样,一个好的质心选择可以让K-Means避免更多的计算,让算法收敛稳定且更快。在之前讲解初始质心的放置时,我们是使用”随机“的方法在样本点中抽取k个样本作为初始质心,这种方法显然不符合”稳定且更快“的需求。为此,我们可以使用random_state参数来控制每次生成的初始质心都在相同位置,甚至可以画学习曲线来确定最优的random_state是哪个整数。
一个random_state对应一个质心随机初始化的随机数种子。如果不指定随机数种子,则sklearn中的K-means并不会只选择一个随机模式扔出结果,而会在每个随机数种子下运行多次,并使用结果最好的一个随机数种子来作为初始质心。我们可以使用参数n_init来选择,每个随机数种子下运行的次数。这个参数不常用到,默认10次,如果我们希望运行的结果更加精确,那我们可以增加这个参数n_init的值来增加每个随机数种子下运行的次数。
然而这种方法依然是基于随机性的。
为了优化选择初始质心的方法,2007年Arthur, David, and Sergei Vassilvitskii三人发表了[论文](k-means++: The advantages of careful seeding),他们开发了”k-means ++“初始化方案,使得初始质心(通常)彼此远离,以此来引导出比随机初始化更可靠的结果。在sklearn中,我们使用参数init ='k-means ++'来选择使用k-means ++作为质心初始化的方案。通常来说,我建议保留默认的"k-means++"的方法。
init:可输入"k-means++",“random"或者一个n维数组。这是初始化质心的方法,默认"k-means++”。输入"kmeans++":一种为K均值聚类选择初始聚类中心的聪明的办法,以加速收敛。如果输入了n维数组,数组的形状应该是(n_clusters,n_features)并给出初始质心。
random_state:控制每次质心随机初始化的随机数种子。
n_init:整数,默认10,使用不同的质心随机初始化的种子来运行k-means算法的次数。最终结果会是基于Inertia来计算的n_init次连续运行后的最佳输出。
import time
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X, y = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1)
t0=time.time()
plus = KMeans(n_clusters = 10).fit(X)
print(plus.n_iter_)
time.time()-t0
#12
#0.05382823944091797
t0=time.time()
random = KMeans(n_clusters = 10,init="random",random_state=420).fit(X)
print(random.n_iter_)
time.time()-t0
#19
#0.03091883659362793
重要参数max_iter & tol
让迭代停下来
在之前描述K-Means的基本流程时我们提到过,当质心不再移动,Kmeans算法就会停下来。但在完全收敛之前, 我们也可以使用max_iter,最大迭代次数,或者tol,两次迭代间Inertia下降的量,这两个参数来让迭代提前停下 来。有时候,当我们的n_clusters选择不符合数据的自然分布,或者我们为了业务需求,必须要填入与数据的自然 分布不合的n_clusters,提前让迭代停下来反而能够提升模型的表现。
max_iter:整数,默认300,单次运行的k-means算法的最大迭代次数
tol:浮点数,默认1e-4,两次迭代间Inertia下降的量,如果两次迭代之间Inertia下降的值小于tol所设定的值,迭代就会停下
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
X, y = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1)
random = KMeans(n_clusters = 10,init="random",max_iter=10,random_state=420).fit(X)
y_pred_max10 = random.labels_
silhouette_score(X,y_pred_max10)
#0.3952586444034157
random = KMeans(n_clusters = 10,init="random",max_iter=20,random_state=420).fit(X)
y_pred_max20 = random.labels_
silhouette_score(X,y_pred_max20)
#0.3401504537571701
为展示差异簇设为10,这样迭代次数不会在3时停止,因而计算的silhouette_score偏低。上述例子展示了限制迭代次数可以提升模型表现。
KMeans重要属性与重要接口总结
重要属性
| 属性 | 含义 |
|---|---|
| cluster_centers_ | 收敛到的质心,如果算法在完全收敛之前就已经停下了,(受到参数max_iter和tol的控制),所返回的内容将与labels属性中反应出来的聚类结果不一致。 |
| labels_ | 每个样本点对应的标签 |
| interis_ | 每个样本点到距离他们最近的簇心的均方距离,又叫做“簇内平方和” |
| n_iter_ | 实际的迭代次数 |
重要接口
| 接口 | 输入 | 功能&返回 |
|---|---|---|
| fit | 训练特征矩阵X | 拟合模型,计算K均值的聚类结果 |
| fit_predict | 训练特征矩阵X | 返回每个样本所对应的簇的索引。计算质心并且为每个样本预测所在簇的索引,功能相当于先fit再predict |
| fit_transform | 训练特征矩阵X | 返回空间中的特征矩阵,进行聚类并且将特征矩阵X转换到簇距离空间当中,功能相当于先fit再transform |
| get_params | 不需要任何输入 | 获取该类的参数 |
| predict | 测试特征矩阵X | 预测每个测试集X中的样本所在簇,并返回每个样本对应的簇的索引。在矢量化的相关文献中,cluster_centers_被称为代码薄,而predict返回的每个值是代码薄中最接近的代码的索引。 |
| score | 测试特征矩阵X | 返回聚类后的Interia,即簇内平方和的负数,簇内平方和Kmeans常用的Kmeans常用的moving评价指标,簇内平方和越小越好,最佳值为0。 |
| set_params | 需要新设定的参数 | 为建设好的类重设参数 |
| transform | 任意特征矩阵X | 将X转换到簇距离空间中,在新空间中,每个维度(每个坐标轴)是样本点到集群中心的距离,即使X是稀疏的,变换返回的数组通常也是密集的 |
函数cluster.k_means
sklearn.cluster.k_means (X, n_clusters, sample_weight=None, init=’kmeans++’, precompute_distances=’auto’,n_init=10, max_iter=300, verbose=False,tol=0.0001, random_state=None, copy_x=True, n_jobs=None,algorithm=’auto’, return_n_iter=False)
函数k_means的用法其实和类非常相似,不过函数是输入一系列值,而直接返回结果,是元组。一次性地,函数k_means会依次返回质心,每个样本对应的簇的标签,inertia以及最佳迭代次数。
from sklearn.datasets import make_blobs
from sklearn.cluster import k_means
X, y = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1)
k_means(X,4,return_n_iter=True)
#参数return_n_iter默认为False,调整为True后就可以看到返回的最佳迭代次数
KMeans的矢量量化引用
K-Means聚类最重要的应用之一是非结构数据(图像,声音)上的矢量量化(VQ)。非结构化数据往往占用比较多的储存空间,文件本身也会比较大,运算非常缓慢,我们希望能够在保证数据质量的前提下,尽量地缩小非结构化数据的大小,或者简化非结构化数据的结构。矢量量化就可以帮助我们实现这个目的。KMeans聚类的矢量量化本质是一种降维运用,但它与我们之前学过的任何一种降维算法的思路都不相同。特征选择的降维是直接选取对模型贡献最大的特征,PCA的降维是聚合信息,而矢量量化的降维是在同等样本量上压缩信息的大小,即不改变特征的数目也不改变样本的数目,只改变在这些特征下的样本上的信息量。
对于图像来说,一张图片上的信息可以被聚类如下表示:
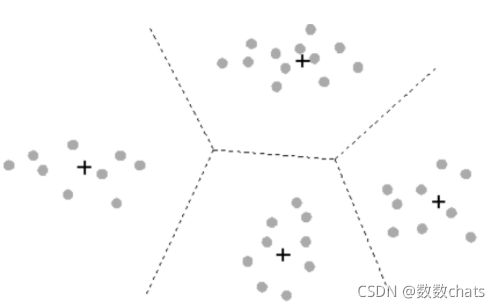
这是一组40个样本的数据,分别含有40组不同的信息(x1,x2)。我们将代表所有样本点聚成4类,找出四个质心,我们认为,这些点和他们所属的质心非常相似,因此他们所承载的信息就约等于他们所在的簇的质心所承载的信息。于是,我们可以使用每个样本所在的簇的质心来覆盖原有的样本,有点类似四舍五入的感觉,类似于用1来代替0.9和0.8。这样,40个样本带有的40种取值,就被我们压缩了4组取值,虽然样本量还是40个,但是这40个样本所带的取值其实只有4个,就是分出来的四个簇的质心。
用K-Means聚类中获得的质心来替代原有的数据,可以把数据上的信息量压缩到非常小,但又不损失太多信息。我们接下来就通过一张图图片的矢量量化来看一看K-Means如何实现压缩数据大小,却不损失太多信息量。
1.初始化
导入需要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# 对两个序列中的点进行距离匹配
from sklearn.metrics import pairwise_distances_argmin
# 导入图片数据所用的类
from sklearn.datasets import load_sample_image
# 打乱顺序
from sklearn.utils import shuffle
探索图片基本信息
# 导入图片
china = load_sample_image("china.jpg")
print(china)
print(china.dtype) # uint8
print(china.shape) # (427, 640, 3) 长度*宽度*像素 3个特征组成的颜色
# 查看图片包含多少种不同的颜色
newimage = china.reshape((427 * 640, 3))
print(newimage.shape) # (273280, 3)
import pandas as pd
pd.DataFrame(newimage).drop_duplicates().shape
# (96615, 3)表示有96615个颜色,每一个颜色由三个特征决定
print(pd.DataFrame(newimage).drop_duplicates().shape)
plt.figure(figsize=(15, 15))
plt.imshow(china) # 导入三维数组形成的图片
plt.show()
图像探索完毕,我们了解了,图像现在有9W多种颜色。我们希望来试试看,能否使用K-Means将颜色压缩到64种,还不严重损耗图像的质量。为此,我们要使用K-Means来将9W种颜色聚类成64类,然后使用64个簇的质心来替代全部的9W种颜色,记得质心有着这样的性质:簇中的点都是离质心最近的样本点。
为了比较,我们还要画出随机压缩到64种颜色的矢量量化图像。我们需要随机选取64个样本点作为随机质心,计算原数据中每个样本到它们的距离来找出离每个样本最近的随机质心,然后用每个样本所对应的随机质心来替换原本的样本。两种状况下,我们观察图像可视化之后的状况,以查看图片信息的损失。
在这之前,我们需要把数据处理成sklearn中的K-Means类能够接受的数据。
2.数据处理
plt.imshow()在小数表现优秀
# plt.imshow在浮点数上表现很优异,在这里我们把china中的数据转换为浮点数,压缩到[0,1]之间
print(china.max()) # 255
china = np.array(china, dtype=np.float64) / china.max()
- kmeans不接受三维的数据,把图像格式转换为矩阵格式。
# 把图像格式转换为矩阵格式。
# kmeans不接受三维作为特征矩阵
# 所以我们要把他们变为二维的
n_clusters = 64
w, h, d = original_shape = tuple(china.shape)
assert d == 3 # 如果不等于3,就帮我报错,这是为了保证特征数目一直为3个
# np.reshape(要改变结构的对象,需要改变为的新结构)
image_array = np.reshape(china, (w * h, d))
print(image_array.shape) #(273280, 3)
3.对数据进行K-Means矢量量化
#数据行数多,先小样本进行fit,再整体predict,减少计算量
# 随机选择的1000个样本导入,返回64个质心
image_array_sample = shuffle(image_array, random_state=0)[:1000]
kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(image_array_sample)
kmeans.cluster_centers_
print(kmeans.cluster_centers_.shape) # (64, 3)
# 找到质心后,按照已存在的质心对所有数据进行聚类
labels = kmeans.predict(image_array)
print(labels.shape) #(273280,)
- 有了质心,我们就可以使用质心来替换所有的样本
# 有了质心,替换所有的样本
image_kmeans = image_array.copy()
# images_kmeans是27W个样本点,9W个不同的颜色
# 第一个质心[0.73524384 0.82021116 0.91925591]
print(kmeans.cluster_centers_[labels[0]])
# labels:[62 62 62 ... 1 6 6]
# 表示labels第一个数62在质心里对应的数
print(kmeans.cluster_centers_[labels[180]])
#替换样本
for i in range(w * h):
image_kmeans[i] = kmeans.cluster_centers_[labels[i]]
print(image_kmeans.shape) # (273280, 3)
# 剩下64种颜色了 (64, 3)
print(pd.DataFrame(image_kmeans).drop_duplicates().shape)
- 恢复样本
# 恢复样本
image_kmeans = image_kmeans.reshape(w,h,d)
image_kmeans.shape
print(image_kmeans.shape) #依然是(427, 640, 3)
4.对数据进行随机矢量量化(同理)
只是在选择质心时不太一样
# 进行随机矢量化
# 随机选定64个质心
centroid_random = shuffle(image_array, random_state=0)[:n_clusters]
labels_random = pairwise_distances_argmin(centroid_random, image_array, axis=0)
# 函数pairwise_distance_argmin(x1,x2,axis) #x1和x2是序列
# 用来计算x2中每个样本到x1中的每个样本的距离,并返回与x2相同形状的,x1中相对应的最近的样本点的索引
print(labels_random.shape) #(273280,)
print(len(set(labels_random))) #64
image_random = image_array.copy()
for i in range(w * h):
image_random[i] = centroid_random[labels_random[i]]
image_random = image_random.reshape(w, h, d) #(427, 640, 3)
5.将原图,按KMeans矢量量化和随机矢量量化的图像绘制出来
plt.figure(figsize=(10, 10))
plt.axis('off')
plt.title('Original image (96,615 colors)')
plt.imshow(china)
plt.figure(figsize=(10, 10))
plt.axis('off')
plt.title('Quantized image (64 colors, K-Means)')
plt.imshow(image_kmeans)
plt.figure(figsize=(10, 10))
plt.axis('off')
plt.title('Quantized image (64 colors, Random)')
plt.imshow(image_random)
plt.show()
K-Means优缺点
K-Means的主要优点:
- 1,原理比较简单,实现也是很容易,收敛速度快
- 2,聚类效果较优(依赖K的选择)
- 3,算法的可解释度比较强
- 4,主要需要调参的参数仅仅是簇数 k
K-Means的主要缺点:
- 1,K值的选取不好把握
- 2,对于不是凸的数据集比较难收敛
- 3,如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳
- 4,采用迭代方法,得到的结果只能保证局部最优,不一定是全局最优(与K的个数及初值选取有关)
- 5,对噪音和异常点比较的敏感(中心点易偏移)
DBSCAN密度聚类算法
DBSCAN算法的本质是一个发现类簇并不断扩展类簇的过程。对于任意一点q,若他是核心点,则在该点为中心,r为半径可以形成一个类簇 c。而扩展的方法就是,遍历类簇c内所有点,判断每个点是否是核心点,若是,则将该点的 ε-邻域也划入类簇c,递归执行,知道不能太扩展类簇C。
1、密度聚集原理
基于密度的聚类寻找被低密度区域分离的高密度区域。DBSCAN是一种简单,有效的基于密度的聚类算法,它解释了基于密度的聚类方法的许多重要概念,在这里我们仅关注DBSCAN。
DBSCAN是一种基于密度的聚类算法,这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间是紧密相连的,也就是说,在该类别任意样本周围不远处一定有同类别的样本存在。
通过将紧密相连的样本划为一类,这样就得到了一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,则我们就得到了最终的所有聚类类别结果。
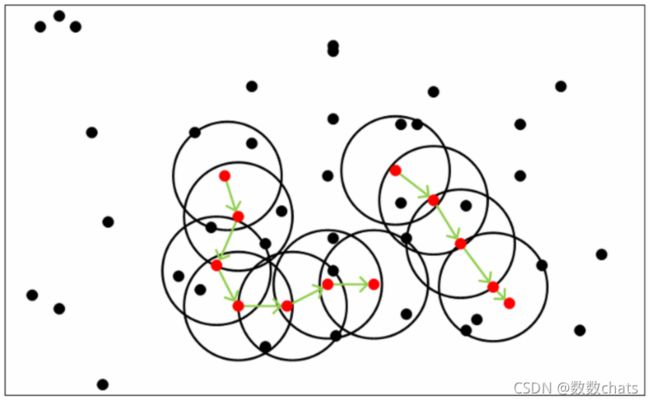
如图所示:A为核心对象 ; BC为边界点 ; N为离群点; 圆圈代表 ε-邻域
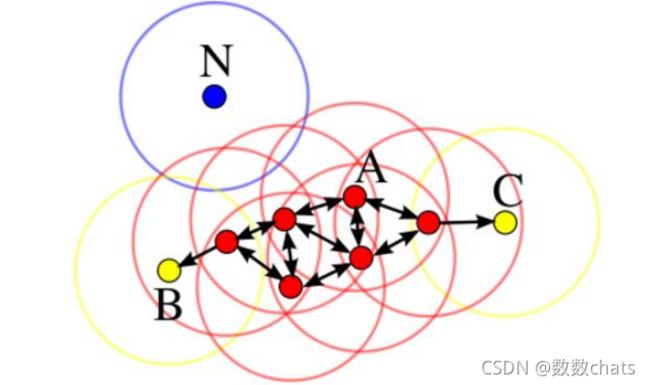
DBSCAN算法的本质是一个发现类簇并不断扩展类簇的过程。对于任意一点q,若他是核心点,则在该点为中心,r为半径可以形成一个类簇 c。而扩展的方法就是,遍历类簇c内所有点,判断每个点是否是核心点,若是,则将该点的 ε-邻域也划入类簇c,递归执行,知道不能太扩展类簇C。
假设上图中 minPts为3,r为图中圆圈的半径,算法从A开始,经计算其为核心点,则将点A及其邻域内的所有点(共四个)归为类Q,接着尝试扩展类Q。查询可知类Q内所有的点均为核心点(红点),故皆具有扩展能力,点C也被划入类Q。在递归扩展的过程中,查询C,以C为原点,r为半径画圆,不能圈进minPts(为3)个点在圆内,故C不是核心点,类Q不能从点C扩充,称C为边界点。边界点被定义为属于某一个类的非核心点。在若干次扩展以后类Q不能再扩张,此时形成的类为图中除N外的所有的点,点N则称为噪声点。即不属于任何一个类簇的点,等价的可以定义为从任何一个核心点出发都是密度不可达的。在上图中数据点只能聚成一个类,在实际使用中往往会有多个类,即在某一类扩展完成后另外选择一个未被归类的核心点形成一个新的类簇并扩展,算法结束的标志是所有的点都已被划入某一类或噪声,且所有的类都是不可再扩展。
上面提到了几个概念,下面细说一下:
核心点(core point):这些点在基于密度的簇内部。点的邻域由距离函数和用户指定的距离参数 Eps 决定。核心点的定义是,如果该点的给定邻域内的点的个数超过给定的阈值MinPts,其中MinPts也是一个用户指定的参数。
边界点(border point):边界点不是核心点,但它落在某个核心点的邻域内。如上图B点。
噪声点(noise point):噪声点是即非核心点也是非边界点的任何点。如上图N点。
2、DBSCAN密度定义
在上面我们定性描述了密度聚类的基本思想,下面我们看看DBSCAN是如何描述密度聚类的。DBSCAN是基于一组邻域来描述样本集的紧密程度的,参数(ε,MinPts)用来描述邻域的样本分布紧密程度。其中 ε 描述了某一样本的邻域距离阈值,MinPts 描述了某一样本的距离为 ε的邻域中样本个数的阈值。
假设我的样本集是 D = ( x 1 , x 2 , . . . , X m ) D=(x_1, x_2,...,X_m) D=(x1,x2,...,Xm) 则DBSCAN 具体的密度描述定义如下:
1) ε-邻域:对于 x j € D x_j € D xj€D,其 ε- 邻域包含样本集D中与 x j x_j xj的距离不大于 ε 的子样本集,即 N ε ( x j ) = x i € D ∣ d i s t a n c e ( x i , x j ) ≤ ε N_ε(x_j)={x_i € D| distance(x_i, x_j) \leq ε} Nε(xj)=xi€D∣distance(xi,xj)≤ε,这个子样本集的个数记为 ∣ N ε ( x j ) ∣ | N_ε(x_j)| ∣Nε(xj)∣
2)核心对象:对于任一样本 x j € D x_j € D xj€D ,如果其 ε- 邻域对应的 $N_ε(x_j) $至少包含 MinPts个样本,即如果 ∣ N ε ( x j ) ∣ ≥ M i n P t s | N_ε(x_j)| \geq MinPts ∣Nε(xj)∣≥MinPts,则 x j x_j xj是核心对象。简单来说就是若某个点的密度达到算法设定的阈值则其为核心点
3)密度直达:如果 x i x_i xi 位于 x j x_j xj 的 ε- 邻域中,且 x j x_j xj是核心对象,则称 x i x_i xi由 x j x_j xj 密度直达。注意反之不一定成立,即此时不能说 x j x_j xj 由 x i x_i xi密度直达,除非且 x i x_i xi 也是核心对象
4)密度可达:对于 x i x_i xi 和 x j x_j xj ,如果存在样本序列 p 1 , p 2 , . . . p T p_1, p_2, ...p_T p1,p2,...pT,满足 p 1 = x i , p T = x j p_1=x_i, p_T=x_j p1=xi,pT=xj,且 p t + 1 p_{t+1} pt+1由 pt 密度直达,则称 x j x_j xj由 x i x_i xi 密度可达。也就是说,密度可达满足传递性。此时序列中的传递样本 p 1 , p 2 , . . . . . p T − 1 p_1, p_2,.....p_{T-1} p1,p2,.....pT−1均为核心对象,因为只有核心对象才能使其他样本密度直达。注意密度可达也不满足对称性,这个可以由密度直达的不对称性得出。
5)密度相连:对于 x i x_i xi和 x j x_j xj ,如果存在核心对象样本 x k x_k xk,使 x i x_i xi 和 x j x_j xj 均由 x k x_k xk 密度可达,则称 x i x_i xi 和 x j x_j xj密度相连。注意密度相连关系是满足对称性的。
从下图可以很容易理解上述定义,图中 MinPts=5,红色的点都是核心对象,因为其 ε- 邻域至少有5个样本。黑色的样本是非核心对象。所有核心对象密度直达的样本在以红色核心对象为中心的超球体内,如果不在超球体内,则不能密度直达。图中用绿色箭头连起来的核心对象组成了密度可达的样本序列。在这些密度可达的样本序列 ε-邻域内所有的样本相互都是密度相连的。
3、DBSCAN 小结
和传统的K-Means算法相比,DBSCAN最大的不同激素不需要输入类别k,当然它最大的优势是可以发现任意形状的聚类簇,而不是像K-Means,一般仅仅使用于凸的样本集聚类,同时它在聚类的同时还可以找出异常点,这点和BIRCH算法类似。
那么我们什么时候需要用DBSCAN来聚类呢?一般来说,如果数据集是稠密的,并且数据集不是凸的,那么用DBSCAN会比K-Means聚类效果好很多。如果数据集不是稠密的,则不推荐使用DBSCAN来聚类。
下面对DBSCAN算法的优缺点做一个总结:
3.1 DBSCAN优点:
1) 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的算法一般只适用于凸数据集。
2) 可以在聚类的同时发现异常点,对数据集中的异常点不敏感。
3)聚类结果没有偏倚,相对的K,K-Means之类的聚类算法那初始值对聚类结果有很大的影响。
3.2 DBSCAN缺点:
1)如果样本集的密度不均匀,聚类间距离相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
2)如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
3)调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值 ε ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
3.3 DBSCAN和K-Means算法的区别:
- 1,可以不需要事先指定cluster的个数
- 2,可以找出不规则形状的cluster
4、sklearn实现DBSCAN算法
在sklearn中,DBSCAN算法类为sklearn.cluster.DBSCAN。要熟练的掌握用DBSCAN类来聚类,除了对DBSCAN本身的原理有较深的理解之外,还要对最近邻的思想有一定的理解。结合这两者,就可以熟练应用DBSCAN。
1,DBSCAN类重要参数
class sklearn.cluster.DBSCAN(eps=0.5, *, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)
1)**eps:**DBSCAN算法参数,即我们的 ε- 邻域的距离阈值,和样本距离超过ε- 的样本点不在ε- 邻域内,默认值是0.5。一般需要通过在多组值里面选择一个合适的阈值,eps过大,则更多的点会落在核心对象的ε- 邻域,此时我们的类别数可能会减少,本来不应该是一类的样本也会被划分为一类。反之则类别数可能会增大,本来是一类的样本却被划分开。
2)**min_samples:**DBSCAN算法参数,即样本点要成为核心对象所需要的ε- 邻域的样本数阈值,默认是5。一般需要通过在多组值里面选择一个合适的阈值。通常和eps一起调参。在eps一定的情况下,min_smaples过大,则核心对象会过少,此时簇内部分本来是一类的样本可能会被标为噪音点,类别数也会变多。反之 min_smaples过小的话,则会产生大量的核心对象,可能会导致类别数过少。
3)**metric:**最近邻距离度量参数,可以使用的距离度量较多,一般来说DBSCAN使用默认的欧式距离(即 p=2 的闵可夫斯基距离)就可以满足我们的需求。可以使用的距离度量参数有:欧式距离,曼哈顿距离,切比雪夫距离,闵可夫斯基距离,马氏距离等等。
4)algorithm:最近邻搜索算法参数,算法一共有三种,第一种是蛮力实现,第二种是KD树实现,第三种是球树实现,对于这个参数,一共有4种可选输入,‘brute’对应第一种蛮力实现,‘kd_tree’对应第二种KD树实现,‘ball_tree’对应第三种的球树实现, ‘auto’则会在上面三种算法中做权衡,选择一个拟合最好的最优算法。需要注意的是,如果输入样本特征是稀疏的时候,无论我们选择哪种算法,最后scikit-learn都会去用蛮力实现‘brute’。个人的经验,一般情况使用默认的 ‘auto’就够了。 如果数据量很大或者特征也很多,用"auto"建树时间可能会很长,效率不高,建议选择KD树实现‘kd_tree’,此时如果发现‘kd_tree’速度比较慢或者已经知道样本分布不是很均匀时,可以尝试用‘ball_tree’。而如果输入样本是稀疏的,无论你选择哪个算法最后实际运行的都是‘brute’。
5)leaf_size: 最近邻搜索算法参数,为使用KD树或者球树时,停止建子树的叶子节点数量的阈值。这个值越小,则生成的KD树或者球树就越大,层数越深,建树时间越长,反之,则生成的KD树或者球树会小,层数较浅,建树时间较短。默认是30,因为这个值一般只影响算法的运行速度和使用内存大小,因此一般情况可以不管它。
6)**p:**最近邻距离度量参数。只用于闵可夫斯基距离和带权值闵可夫斯基距离中 p 值的选择, p=1为曼哈顿距离,p=2为欧式距离,如果使用默认的欧式距离就不需要管这个参数。
以上就是DBSCAN类的主要参数介绍,其实需要调参的就是两个参数eps和min_samples,这两个值的组合对最终的聚类效果有很大的影响。
2,Sklearn DBSCAN聚类实例
首先,我们随机生成一组数据,为了体现DBSCAN在非凸数据的聚类有点,我们生成了两簇数据,然后再将这两簇结合起来,代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs, make_circles
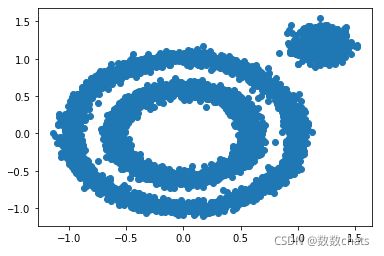
# 下面我们生成三组数据
X1, y1 = make_circles(n_samples=5000, factor=0.6, noise=0.05)
X2, y2 = make_blobs(n_samples=1000, n_features=2, centers=[[1.2, 1.2]],
cluster_std=[[0.1]], random_state=9)
X = np.concatenate((X1, X2))
plt.scatter(X[:, 0], X[:, 1], marker='o')
plt.show()
K-Means的聚类效果
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=3, random_state=9).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
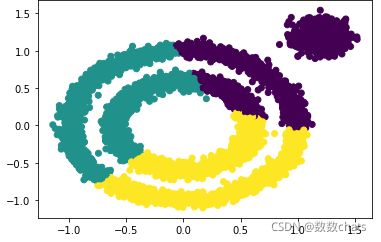
K-Means对于非凸数据集的聚类表现不好。
那么如果使用DBSCAN效果如何呢?先不调参,直接使用默认参数,看看聚类效果,代码如下:
from sklearn.cluster import DBSCAN
y_pred = DBSCAN().fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
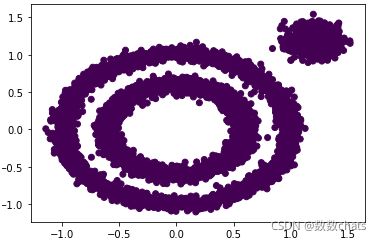
现输出结果不好,DBSCAN居然认为所有的数据都是一类。
下面我们尝试调参,我们需要对DBSCAN的两个关键的参数eps和min_samples进行调参!从上图我们可以发现,类别数太少,我们需要增加类别数,那么我们可以减少 ε- 邻域的大小,默认是0.5,我们减少到0.1看看效果,代码如下:
y_pred = DBSCAN(eps = 0.1).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
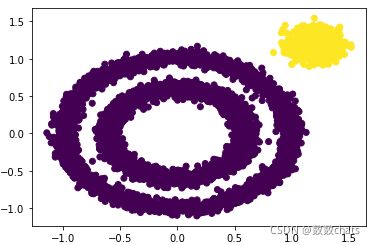
可以看到聚类效果有了改进。此时我们可以继续调参增加类别,有两个方向都是可以的,一个是继续减少eps,另一个是增加min_samples。我们现在将min_samples从默认的5增加到10
y_pred = DBSCAN(eps = 0.1, min_samples = 10).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
出现了一个异常点。。。。不过我们可以使用不调参的模型,聚类效果比较好。
上面这个例子只是帮大家理解DBSCAN调参的一个基本思路,在实际运用中可能要考虑很多问题,以及更多的参数组合。