Microsoft SQL Server 2008技术内幕:T-SQL查询——读书笔记(全)
特别注意: 本笔记不适合初学者
SQL的官方(ANSI)发音是:ess kyooell,但更多的人叫它sequel.
** 第一章:逻辑查询处理**
在sql server中负责实际工作计划执行的是查询优化器(Query optimizer).
查询包括逻辑处理和物理处理。
- 1.1-1.3逻辑查询处理的各个阶段
步骤1:From阶段:
From 标识出查询的来源表
步骤2:JOIN阶段:
join 运算符涉及的子阶段依次为笛卡尔积、ON筛选器、添加外部行。
① 笛卡尔积:
若左表n行,右表m行,则执行笛卡尔积后的行数为n*m行,得到虚拟表VT1-J1。
② ON筛选器:
是在查询过程中可指定的三种筛选器(ON、WHERE、HAVING)中的第一个。
ON的作用是将紧跟的谓语条件作用于上一步的虚拟表VT1-J1后,返回虚拟表VT1-J2且其中仅包含<on_predicate>为TRUE的所有行。
③ 添加外部行:
这一步只有在外连接(OUTER JOIN)中才会发生,通过为其指定外连接类型(LEFT,RIGHT,FULL)中的一种,把一个或两个输入表记为保留表(preserved table).左外连接记左表,右外连接记右表,完全外连接记左表以及右表。
将这一步的保留表的行作为外部行(outer row)重新添加到VT1-J2中,外部行中非保留表的属性列的值都记为NULL,然后生成虚拟表VT1-J3并返回。
题外话(初学者调过):三值逻辑(Three-Valued Logic)
三值逻辑是sql特有的属性,即谓词的取值是三种:TRUE,FALSE,UNKNOWN.
而其它语言逻辑表达式多为TRUE,FALSE两种。
UNKNOWN通常存在于涉及NULL值的逻辑表达式中,其逻辑结果一般为UNKNOWN。
以下情况的逻辑值均为UNKNOWN:NULL>42,NULL=NULL,X+NULL>Y
① 所有的查询筛选器(ON、WHERE、HAVING)都把UNKNOWN当做False处理。
② 表的CHECK约束会把UNKNOWN按True来处理,例如CHECK约束要求表T的列Salary的值必须大于0,但该列在存储NULL值时是可以的,故将UNKNOWN按True处理的。
③ 在UNIQUE约束、集合运算(如UNION和EXCEPT)、以及排序和分组中,认为两个NULL是相等的。
例:在UNIQUE约束中,不能插入两个NULL值,即NULL<>NULL
GROUP BY以及ORDER BY会将NULL值排到一组,即NULL=NULL
注:具体的应视sql版本对应的逻辑为准,本实例仅针对sql2008。
步骤3:WHERE阶段
对上一步返回的虚拟表的所有行应用WHERE筛选器,让<where_predicate>逻辑条件为True的行组成虚拟表VT2并返回。
步骤4:GROUP BY阶段
分组
步骤5:HAVING阶段
HAVING筛选器对上一步返回的虚拟表中的组进行筛选,只有使<having_predicate>条件取值为TRUE的组才会组成虚拟表并返回,
即HAVING必须和GROUP BY联合使用。
步骤6:SELECT阶段
从步骤5得到的虚拟表中获取select后声明的列,并将结果组合为虚拟表VT5并返回。
步骤7:DISTINCT阶段
将上一步返回的虚拟表中的重复行(同列NULL值相等)删除后组合成虚拟表VT5-2并返回。
步骤8:TOP阶段
TOP是T-SQL特有的功能,允许要返回的行数或百分比(向上取整)。
可与order by连用。
步骤9:ORDER BY阶段
这一步按ORDER BY后指定的列名依次从左至右按指定的顺序排序,然后返回游标VC6.
因为ORDER BY的结果返回的是游标,不是表,所以不能定义在表表达式中。表表达式包括:视图、内联表值函数、派生表、公用表达式(CTE).
注:若在视图中使用TOP加ORDER BY的定义,但其返回的结果并不会是排序后的结果,也可以理解为order by是无效的。
1.4:逻辑查询处理的深入理解
深入理解表运算符(JOIN,APPLY,PIVOT和UNPIVOT)、OVER子句,以及集合运算符(UNION、EXCEPT和INTERSECT).
表达运算符:
① APPLY运算符:
APPLY有两种形式,分别为OUTER APPLY和CROSS APPLY。
OUTER APPLY运算符就是把OUTER APPLY后的表达式的结果附加到OUTER APPLY左表的行上;
而CROSS APPLY就是将CROSS APPLY后的表达式的结果附加到CROSS APPLY左表的行上,并将无值的行删去后生成虚拟表并返回。
注:此处NULL为UNKOOWN 记为FALSE.
Apply深入理解网址
② PIVOT运算符:
PIVOT运算符用于在列和行之间对数据进行旋转或透视转换(即行转列),同时进行聚合运算。
PIVOT涉及三个逻辑阶段,依次为:分组、扩展、聚合。
① 分组阶段:
逻辑上相当于执行了一个GROUP BY子句。
② 扩展阶段:
逻辑上相当于进行了CASE WHEN THEN END;的操作。
③ 聚合阶段:
对每个CASE表达式应用指定的聚合函数,然后生成虚拟表并返回。
PIVOT理解网址
③UNPIVOT运算符:
与PIVOT刚好相反,实现列转行。
UNPIVOT涉及三个逻辑阶段,依次为:生成副本、提取元素、删除带有NULL的行。
UNPIVOT理解网址
OVER子句:
OVER子句用于支持基于窗口(window-based)的计算;可以和聚合函数一起使用,同时也是四个分析排名函数(ROW_NUMBER、RANK、DENSE_RANK和NTILE)必须要求的元素。OVER子句会定义数据行的一个窗口,在这个窗口上可以执行聚合或排名函数的计算。
原理暂且不说,只介绍两种用法如下:


集合运算符:
**① UNION ALL**运算符:
返回两个输入并集的所有行,存在重复行。
**② UNION**运算符:
返回两个输入的并集所有行,不存在重复行。
**③ EXCEPT**运算符:
返回两个输入的差集的所有行。
**③ INTERSECT**运算符:
返回两个输入的交集的所有行。
第二章:集合论和谓词逻辑
此章涉及数学知识过多,不做赘述。
第三章:关系模型
数据库的结构称为**数据模型(data model)**或**架构(schema)**,也称为**数据库的设计**,是对数据库对象的指定。现代数据库的几种最重要的模型之一就是关系模型。关系模型主要用于事务型(transactional)数据库,这类数据库首先是为了存储企业数据;与仓库型数据库不同,数据仓库用于存储历史数据。
关系数据库管理系统(RDBMS)是按关系格式来存储数据的系统,这其中包括Microsoft SQL Server.
- 实体完整性
数据库中的表是关系的物理表示,表中的行代表元组,关系是由各个
唯一的元组组成的,也就是说表中的每一行都应该有能够唯一标识的列的
组合来代表这一行,最小的一组列集称为键(key),也就是说每个表可
以有多个唯一列的组合(换句话说就是可以具有多个候选键candidatekey)
.从这多个候选键中选择一个作为对每一行的主引用(primaryReference)
,称其为主键(primary key).
SqlServer具有两种约束:Unique约束(唯一性约束,用于定义候
选键)和Primary Key约束(主键约束,用于定义主键)。每个表可以有
多个Unique约束和一个主键约束。
Sqlserver可以建立没有约束的表。同时要注意PrimaryKey约束
的列不允许NULL值,而Unique约束允许。
- 参照完整性
外键(foreign key)是列值能够和另一个表的某个键进行匹配的一
组列,也就是另一个关系中某个键的副本。在任何时候,数据库中不能有
不匹配的外键。父表和子表存在“级联”关系,删除父表要先删子表。
外键约束必须引用父表中的一个键。父表与子表可以是同一个表,外
键可以引用自身的表。邻接表模型也正是利用这一点,才可以表示图、树
和层次结构。
- 域完整性
域完整性是对属性的可能取值范围进行限制。对属性的域进行限制的一个
方法就是Check约束。 Check约束是一个逻辑表达式,可以返回真、假或未知这三种真值。
后面的多是讲关系物理模型的,不过多赘述。
第四章:查询优化
自定向下方法的优化论:
- 分析实例级别的等待
- 关联等待和队列
- 确定方案
- 细化到数据库/文件级
- 细化到进程级
- 优化索引/查询
Sqlserver 2008引入数据收集器(data collector),用于收集不同类型的数据(性能方面),并将信息保存在管理数据仓库的关系数据库中。
1.分析实例级别的等待
可以通过查询动态管理图(DMV,dynamic management view)
sys.dm_os_wait_stats来完成。该DMV包含400多种等待类型。
可执行下面SQL查看结果:
select *
from sys.dm_os_wait_stats
order by wait_type
这个DMV是从服务器最后一次重新启动开始累积值,如果想重置它的值,
可以运行如下代码(不要现在运行):
DBCC SQLPERF('sys.dm_os_wait_stats',CLEAR)
属性介绍:
wait_type:等待类型
waiting_tasks_count:该类等待的数量
wait_time_ms:以毫秒为单位的该类等待的总等待时间(包含signal_wait_time_ms)
max_wait_time_ms:
signal_wait_time_ms:正在等待的线程从收到信号通知到其开始运行之间的时差。
就是表示从线程收到资源可用的信号开始,到线程得到CPU的时间,开始使用资源为止经历的时间。
注:所有的临时表都是在tempdb数据库中创建(无论隐式还是显式)。
2. 分离重量级别的等待(P128)
上一步查找的是所有的等待类型,但直接将重量级等待(top waits)更利于分析,以下查询分离出累积总和达到系统总等待时间80%的等待类型,而且至少返回按等待时间排名前5位的等待:
WITH Waits AS
(
SELECT
wait_type,
wait_time_ms / 1000. AS wait_time_s,
100.* wait_time_ms / SUM(wait_time_ms) OVER() AS pct,
ROW_NUMBER() OVER(ORDER BY wait_time_ms DESC)AS rn,
100.* signal_wait_time_ms/wait_time_ms as signal_pct
FROM sys.dm_os_wait_stats
WHERE wait_time_ms>0
AND wait_type NOT LIKE N'%SLEEP%'
AND wait_type NOT LIKE N'%IDLE%'
AND wait_type NOT LIKE N'%QUEUE%'
AND wait_type NOT IN (N'CLR_AUTO_EVENT'
,N'REQUEST_FOR_DEADLOCK_SEARCH'
,N'SQLTRACE_BUFFER_FLUSH'
/*filter out additional irrelevant waits*/
)
)
SELECT
W1.wait_type,
CAST(W1.wait_time_s AS numeric(12,2)) AS wait_time_s,--从系统最后一次重启或计数器清空以来,该等待类型的总等待时间(以秒为单位)
CAST(W1.pct AS numeric(5,2)) AS pct,--该类型总等待时间占所有类型总等待类型的百分比
CAST(SUM(W2.pct)AS numeric(5,2)) AS running_pct,--从最重量级的等待类型到当前等待类型的连续百分比
CAST(W1.signal_pct AS numeric(5,2)) AS signal_pct--信号等待时间占等待时间的百分比(wait_time_ms包含signal_wait_time_ms)
FROM Waits AS W1
JOIN Waits AS W2 ON W2.rn<=W1.rn
GROUP BY W1.rn,W1.wait_type,W1.wait_time_s,W1.pct,W1.signal_pct
HAVING SUM(W2.pct) - W1.pct<80 --percentage threshold
OR W1.rn<=5
ORDER BY W1.rn
可以通过分析上述sql的执行结果得到有用的性能信息。
3. 关联等待和队列
SQL Server:Buffer Manager对象的“Page life expectancy”这个计数器可以显示没有被引用的页在缓冲池中平均停留多少秒。若值较低,表示增加内存可以让页在缓冲池中停留更久,而较高表示增加内存也没用。
sqlserver2008引入sys.dm_os_performance_counters的DMV,包含了Performance Monitor中所有与SqlServer实例对象相关的计数器。
执行下述sql查看详细信息:
select *
from sys.dm_os_performance_counters
4. 确定行动方案
根据1、2、3的信息,分析性能低下的原因。
5.细化到数据库/文件级别
分析I/O信息的一种工具是动态管理函数sys.dm_io_virtual_file_stats,这个函数有两个输入参数:数据库ID以及文件ID,返回与该数据库文件相关的I/O信息。若返回所有数据库和所有文件信息则将两个参数都指定为NULL。该函数返回个别属性解释:
sample_ms:SqlServer自启动以来的毫秒数,可以用于比较该函数返回的不同输出
io_stall_read_ms:用户等在该文件上发出等待读取所用的总时间,一毫秒为单位
io_stall:用户在该文件上等待I/O完成的总时间,以毫秒为单位
size_on_disk_bytes:以字节为单位bytes 1G=1024M=1024*1024Kb=1024*1024*1024Bytes=1024*1024*1024*8bit
file_handle:用于该文件的MicrosoftWindows文件句柄
以下sql可获取db对应的I/O信息:
WITH DBIO AS
(
SELECT
DB_NAME(IVFS.database_id) AS db,
MF.type_desc,
SUM(IVFS.num_of_bytes_read +IVFS.num_of_bytes_written) AS io_bytes,
SUM(IVFS.io_stall) AS io_stall_ms
FROM SYS.dm_io_virtual_file_stats(NULL,null) AS IVFS
JOIN SYS.master_files AS MF ON IVFS.database_id=MF.database_id AND IVFS.file_id=MF.file_id
GROUP BY DB_NAME(IVFS.database_id),MF.type_desc
)
SELECT db,type_desc
,CAST(1.*io_bytes/(1024*1024) AS numeric(12,2) ) AS io_mb
,CAST(io_stall_ms/1000. AS numeric(12,2)) AS io_stall_s
,CAST(100.*io_stall_ms /SUM(io_stall_ms) OVER() AS NUMERIC(10,2)) AS io_stall_pct
,ROW_NUMBER() OVER(ORDER BY io_stall_ms DESC) AS rn
FROM DBIO
ORDER BY io_stall_ms DESC
由上述sql可获得I/O消耗大的DB。
6. 细化到进程级别
我们深入具体的DB,找出要优化的进程(存储过程、查询等)。这个查询进程的过程使用sqlserver内建的跟踪(tracing)功能很方便。但跟踪时会影响系统性能(海森堡不确定性原理(Heisenberg Uncertainty Principle):当你在测量什么东西时,测量宗会导致某种不确定性的因素。)。所以我们需要遵循以下步骤准则来减少影响:

下面用一个存储过程来定义一个跟踪;这个存储过程接受一个数据库ID和文件名作为输入参数,最后会返回生成的TraceID。
--这个存储过程的下面一部分不易理解,但是无关紧要,现在只需要正确执行就行
SET NOCOUNT ON;
USE master;
GO
IF OBJECT_ID('dbo.PerfworkloadTraceStart','P') IS NOT NULL
DROP PROC dbo.PerfworkloadTraceStart;
GO
CREATE PROC dbo.PerfworkloadTraceStart
@dbid AS INT,
@tracefile AS NVARCHAR(245),
@traceid AS INT OUTPUT
AS
--CREATE A Queue
DECLARE @rc AS INT;
DECLARE @maxfilesize AS BIGINT;
SET @maxfilesize = 5;
EXEC @rc = sp_trace_create @traceid OUTPUT,0,@tracefile,@maxfilesize,NULL
IF (@rc != 0) GOTO error;
-- Set the events
DECLARE @on AS BIT;
SET @on = 1;
-- RPC:Completeed
exec sp_trace_setevent @traceid,10,15,@on;
exec sp_trace_setevent @traceid,10,8,@on;
exec sp_trace_setevent @traceid,10,16,@on;
exec sp_trace_setevent @traceid,10,48,@on;
exec sp_trace_setevent @traceid,10,1,@on;
exec sp_trace_setevent @traceid,10,17,@on;
exec sp_trace_setevent @traceid,10,10,@on;
exec sp_trace_setevent @traceid,10,18,@on;
exec sp_trace_setevent @traceid,10,11,@on;
exec sp_trace_setevent @traceid,10,12,@on;
exec sp_trace_setevent @traceid,10,13,@on;
exec sp_trace_setevent @traceid,10,6,@on;
exec sp_trace_setevent @traceid,10,14,@on;
-- SP:Completed
exec sp_trace_setevent @traceid,43,15,@on;
exec sp_trace_setevent @traceid,43,8,@on;
exec sp_trace_setevent @traceid,43,48,@on;
exec sp_trace_setevent @traceid,43,1,@on;
exec sp_trace_setevent @traceid,43,10,@on;
exec sp_trace_setevent @traceid,43,11,@on;
exec sp_trace_setevent @traceid,43,12,@on;
exec sp_trace_setevent @traceid,43,13,@on;
exec sp_trace_setevent @traceid,43,6,@on;
exec sp_trace_setevent @traceid,43,14,@on;
--SP:StmtCompleted
exec sp_trace_setevent @traceid,45,8,@on;
exec sp_trace_setevent @traceid,45,16,@on;
exec sp_trace_setevent @traceid,45,48,@on;
exec sp_trace_setevent @traceid,45,1,@on;
exec sp_trace_setevent @traceid,45,17,@on;
exec sp_trace_setevent @traceid,45,10,@on;
exec sp_trace_setevent @traceid,45,18,@on;
exec sp_trace_setevent @traceid,45,11,@on;
exec sp_trace_setevent @traceid,45,12,@on;
exec sp_trace_setevent @traceid,45,13,@on;
exec sp_trace_setevent @traceid,45,6,@on;
exec sp_trace_setevent @traceid,45,14,@on;
exec sp_trace_setevent @traceid,45,15,@on;
-- SQL:BatchCompleted
exec sp_trace_setevent @traceid,12,15,@on;
exec sp_trace_setevent @traceid,12,8,@on;
exec sp_trace_setevent @traceid,12,16,@on;
exec sp_trace_setevent @traceid,12,48,@on;
exec sp_trace_setevent @traceid,12,1,@on;
exec sp_trace_setevent @traceid,12,17,@on;
exec sp_trace_setevent @traceid,12,6,@on;
exec sp_trace_setevent @traceid,12,10,@on;
exec sp_trace_setevent @traceid,12,14,@on;
exec sp_trace_setevent @traceid,12,18,@on;
exec sp_trace_setevent @traceid,12,11,@on;
exec sp_trace_setevent @traceid,12,12,@on;
exec sp_trace_setevent @traceid,12,13,@on;
--SP:StmtCompleted
exec sp_trace_setevent @traceid,41,15,@on;
exec sp_trace_setevent @traceid,41,8,@on;
exec sp_trace_setevent @traceid,41,16,@on;
exec sp_trace_setevent @traceid,41,48,@on;
exec sp_trace_setevent @traceid,41,1,@on;
exec sp_trace_setevent @traceid,41,17,@on;
exec sp_trace_setevent @traceid,41,10,@on;
exec sp_trace_setevent @traceid,41,18,@on;
exec sp_trace_setevent @traceid,41,11,@on;
exec sp_trace_setevent @traceid,41,12,@on;
exec sp_trace_setevent @traceid,41,13,@on;
exec sp_trace_setevent @traceid,41,6,@on;
exec sp_trace_setevent @traceid,41,14,@on;
-- Set the Filters
-- Application name filter
EXEC sp_trace_setfilter @traceid,10,0,7,N'SQL Server Profiler%';
-- Database ID filter
EXEC sp_trace_setfilter @traceid,3,0,0,@dbid;
--Set the trace status to start
EXEC sp_trace_setstatus @traceid,1;
--Print trace id and file name for future references
PRINT 'Trace ID:'+CAST(@traceid AS VARCHAR(10)) + ',Trace File:'''+@tracefile+'.trc''';
GOTO finish;
error:
PRINT 'Error Code:'+CAST(@rc AS VARCHAR(10));
finish:
GO
上述sql之星成功后,使用下面的SQL来指定数据库生成相应的跟踪文件:
DECLARE @dbid AS INT ,@traceid AS INT,@tracefile AS NVARCHAR;
SET @dbid=DB_ID('DBName');
EXEC master.dbo.PerfworkloadTraceStart
@dbid =@dbid,
@tracefile='生成的trc文件地址',
@traceid =@traceid OUTPUT;
示例:
--EntradeCnooc我要跟踪的数据库名,C:\迅雷下载\Perfworkload 202104191:我要存放的跟踪文件地址及文件名
DECLARE @dbid AS INT ,@traceid AS INT,@tracefile AS NVARCHAR;
SET @dbid=DB_ID('EntradeCnooc');
EXEC master.dbo.PerfworkloadTraceStart
@dbid =@dbid,
@tracefile='C:\迅雷下载\Perfworkload 202104191',
@traceid =@traceid OUTPUT;
上述代码执行完毕应该会生成类似下面的提示:
![]()
要将得到的Trace ID保存好(弄丢了,可以用这个SQL查询SELECT * FROM sys.traces),因为上述存储过程只是将该ID对应的跟踪过程启动了,后面还要用该ID停止或关闭跟踪。关闭或跟踪的SQL如下:
EXEC sp_trace_setstatus @TraceID,0;--0 跟踪的关闭
EXEC sp_trace_setstatus @TraceID,2;--2 跟踪的删除
对于上述的跟踪过程,有些跟踪几个小时即可,而有些可能需要跟踪几天在关闭跟踪,才能根据跟踪的结果(双击@tracefile即可获得跟踪的相关信息,如下图)得到有用的信息。

注:从经验上来讲这个存储过程对小型跟踪更有效。
分析跟踪数据:
将跟踪的数据加载到WorkLoad表:
IF OBJECT_ID('dbo.WorkLoad','U') IS NOT NULL
DROP TABLE dbo.WorkLoad;
SELECT CAST(TextData AS nvarchar(MAX)) AS tsql_code,
Duration
INTO DBO.WorkLoad
FROM sys.fn_trace_gettable('C:\迅雷下载\Perfworkload 202104191.trc',NULL) AS T
WHERE Duration>0 AND EventClass IN (41,45)
下面这一部分的作用是获取查询语句的模板,这一块只是辅助作用,可以忽略!!!
----------------------获取查询语句模板可忽略内容开始线------------------------------
接着我们直接SELECT * FROM DBO.WorkLoad即可获取所有的信息,但是这样并不直观。下面通过定义一个函数dbo.SQLSig:
IF OBJECT_ID('dbo.SQLSig','FN') IS NOT NULL
DROP FUNCTION dbo.SQLSig;
GO
CREATE FUNCTION dbo.SQLSig(@p1 NTEXT,@parselength INT=4000)
RETURNS NVARCHAR(4000)
AS
BEGIN
DECLARE @pos AS INT;
DECLARE @mode AS CHAR(10);
DECLARE @maxlength AS INT;
DECLARE @p2 AS NCHAR(4000);
DECLARE @currchar AS CHAR(1),@nextchar AS char(1);
DECLARE @p2len AS INT;
SET @maxlength=LEN(RTRIM(SUBSTRING(@p1,1,4000)));
SET @maxlength=CASE WHEN @maxlength>@parselength THEN @parselength ELSE @maxlength END;
SET @pos=1;
SET @p2='';
SET @p2len=0;
SET @currchar='';
SET @nextchar='';
SET @mode='command';
WHILE(@pos<=@maxlength)
BEGIN
SET @currchar=SUBSTRING(@p1,@pos,1);
SET @nextchar=SUBSTRING(@p1,@pos+1,1);
IF @mode='command'
BEGIN
SET @p2=LEFT(@p2,@p2len)+@currchar;
SET @p2len=@p2len+1;
IF @currchar IN (',','(',' ','=','<','>','!') AND @nextchar BETWEEN '0' AND '9'
BEGIN
SET @mode='number';
SET @p2=LEFT(@p2,@p2len)+'#';
SET @p2len=@p2len+1;
END
IF @currchar =''''
BEGIN
SET @mode='literal';
SET @p2=LEFT(@p2,@p2len)+'#''';
SET @p2len=@p2len+2;
END
END
ELSE IF @mode='number' AND @nextchar IN (',','(',' ','=','<','>','!')
SET @mode='command';
ELSE IF @mode='literal' AND @currchar=''''
SET @mode='command';
SET @pos=@pos+1;
END
RETURN @P2;
END
GO
上述函数dbo.SQLSig的作用如下:
SELECT dbo.SQLSig(N'SELECT * FROM dbo.T1 WHERE col1 = 3 AND COL2 > 78',4000)
获取的结果如下:
SELECT * FROM dbo.T1 WHERE col1 = # AND COL2 > #
也就是将某一模式的查询的参数用#替换掉了;上面的函数是用T-SQL来实现这一作用的,下面还有一个使用CLR(公共语言运行时)的方法来实现,且效率比上面的方法高10倍。
下面介绍CLR定义函数RegexReplace:
①使用VS新建一个方案名为RegExp,项目类型为ClassLibrary,然后确定。
②将文件Class1.cs重命名为RegExp.cs,再把下面代码覆盖当前内容。
using Microsoft.SqlServer.Server;
using System.Data.SqlTypes;
using System.Text.RegularExpressions;
public partial class RegExp
{
[SqlFunction(IsDeterministic = true, DataAccess = DataAccessKind.None)]
public static SqlString RegexReplace(SqlString input, SqlString pattern, SqlString replacement)
{
return (SqlString)Regex.Replace(input.Value, pattern.Value, replacement.Value);
}
}
③build该程序集,得到.dll文件(例:我的地址为:C:\Users\LP\source\repos\ConsoleApp_EmptyProject\RegExp\bin\Debug\RegExp.dll)
④为SQLServer激活CLR(默认是被禁用的),执行下面SQL即可:
EXEC sp_configure 'clr enabled',1;
RECONFIGURE;
⑤通过下面代码,从dll文件中加载中间语言代码(intermediate language,IL)到相应的数据库:
CREATE ASSEMBLY RegExp
FROM 'C:\Users\LP\source\repos\ConsoleApp_EmptyProject\RegExp\bin\Debug\RegExp.dll';
⑥运行下面代码,为该数据库注册RegexReplace函数:
CREATE FUNCTION dbo.RegexReplace
(@input AS NVARCHAR(MAX)
,@pattern AS NVARCHAR(MAX)
,@replacement AS NVARCHAR(MAX)
)
RETURNS NVARCHAR(MAX)
WITH RETURNS NULL ON NULL INPUT
EXTERNAL NAME RegExp.RegExp.RegexReplace;
GO
⑦打开SSMS的Scalar Function下是否存在该函数,若存在即注册成功(下图是我的示例):
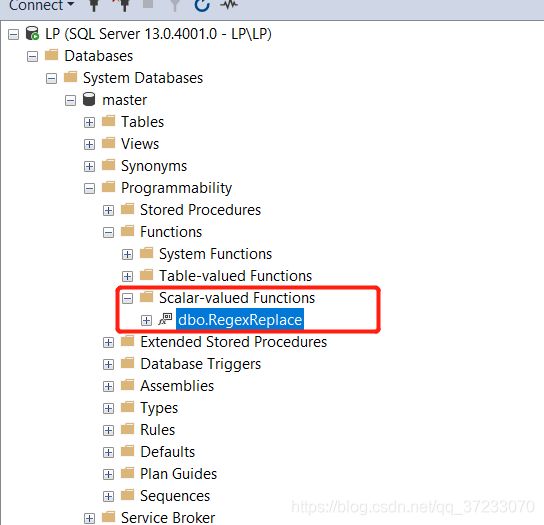
下面使用RegexReplace函数,通过包含正确解析逻辑的正则表达式,来为查询字符串生成查询签名。以下代码演示对dbo.Workload表的tsql_code属性生成查询签名:
SELECT dbo.RegexReplace(tsql_code,
N'([\s,(=<>!](?![^\]]+[\]]))(?:(?:(?:(?#
)(?:([N])?('')(?:[^'']|'''')*(''))(?#
)|(?:0x[\da-dA-F]*)(?#
)|(?:[-+]?(?:(?:[\d]*\.[\d]*|[\d]+)(?#
)(?:[eE]?[\d]*)))(?#
)|(?:[~]?[-+]?(?:[\d]+))(?#
))(?:[\s]?[\+\-\*\/\%\&\|\^][\s]?)?)+(?#
))',
N'$1$2$3$4') AS sig,
Duration
FROM dbo.WorkLoad
对上面的sql继续优化,使用CHECKSUM函数为每个查询字符串生成一个整数的校验和(checksum),如下所示:
SELECT CHECKSUM(dbo.RegexReplace(tsql_code,
N'([\s,(=<>!](?![^\]]+[\]]))(?:(?:(?:(?#
)(?:([N])?('')(?:[^'']|'''')*(''))(?#
)|(?:0x[\da-dA-F]*)(?#
)|(?:[-+]?(?:(?:[\d]*\.[\d]*|[\d]+)(?#
)(?:[eE]?[\d]*)))(?#
)|(?:[~]?[-+]?(?:[\d]+))(?#
))(?:[\s]?[\+\-\*\/\%\&\|\^][\s]?)?)+(?#
))',
N'$1$2$3$4')) AS sig,
Duration
FROM dbo.WorkLoad
查询结果如下:

使用以下代码为Workload表添加一个cs列,用这个列保存每个查询签名的校验和的计算结果,并在该cs列上创建一个聚合索引:
ALTER TABLE dbo.workload ADD cs AS CHECKSUM(dbo.RegexReplace(tsql_code,
N'([\s,(=<>!](?![^\]]+[\]]))(?:(?:(?:(?#
)(?:([N])?('')(?:[^'']|'''')*(''))(?#
)|(?:0x[\da-dA-F]*)(?#
)|(?:[-+]?(?:(?:[\d]*\.[\d]*|[\d]+)(?#
)(?:[eE]?[\d]*)))(?#
)|(?:[~]?[-+]?(?:[\d]+))(?#
))(?:[\s]?[\+\-\*\/\%\&\|\^][\s]?)?)+(?#
))',
N'$1$2$3$4')) PERSISTED;
CREATE CLUSTERED INDEX idx_cl_cs ON dbo.workload(cs);
接着返回Workload表最新内容:SELECT * FROM dbo.WorkLoad

下面再对经过上面优化的dbo.Workload进行分析,下面使用百分比来显示并将结果保存到临时表#AggQueries中:
IF OBJECT_ID('tempdb..#AggQueries','U') IS NOT NULL
DROP TABLE #AggQueries;
SELECT cs,SUM(Duration) AS total_duration,
100. * SUM(duration)/SUM(SUM(duration)) OVER() AS pct,
ROW_NUMBER() OVER(ORDER BY SUM(duration) DESC) AS rn
INTO #AggQueries
FROM DBO.WorkLoad
GROUP BY cs;
CREATE CLUSTERED INDEX idx_cl_cs ON #AggQueries(cs);
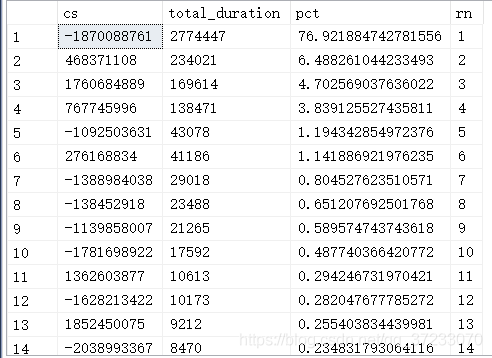
获取#AggQueries结果:
SELECT * FROM #AggQueries ORDER BY rn
接着再进行关联,得到Duration最大的相关查询语句:
方法一:
WITH RunningTotals AS
(
SELECT AQ1.cs
,CAST(AQ1.total_duration/1000. AS numeric(12,2)) AS total_s
,CAST(SUM(AQ2.total_duration)/1000. AS numeric(12,2)) AS running_total_s
,CAST(AQ1.pct AS numeric(12,2)) AS pct
,CAST(SUM(AQ2.pct) AS numeric(12,2)) AS run_pct,
AQ1.rn
FROM #AggQueries AS AQ1
JOIN #AggQueries AS AQ2 ON AQ2.rn<=AQ1.rn
GROUP BY AQ1.cs,AQ1.total_duration,AQ1.pct,AQ1.rn
HAVING SUM(AQ2.pct)-AQ1.pct<=80 --percentage threshold
)
SELECT RT.rn,RT.pct,W.tsql_code
FROM RunningTotals AS RT
JOIN DBO.WorkLoad AS W ON W.cs=RT.cs
ORDER BY RT.rn;
方法二:
WITH RunningTotals AS
(
SELECT AQ1.cs
,CAST(AQ1.total_duration/1000. AS numeric(12,2)) AS total_s
,CAST(SUM(AQ2.total_duration)/1000. AS numeric(12,2)) AS running_total_s
,CAST(AQ1.pct AS numeric(12,2)) AS pct
,CAST(SUM(AQ2.pct) AS numeric(12,2)) AS run_pct,
AQ1.rn
FROM #AggQueries AS AQ1
JOIN #AggQueries AS AQ2 ON AQ2.rn<=AQ1.rn
GROUP BY AQ1.cs,AQ1.total_duration,AQ1.pct,AQ1.rn
HAVING SUM(AQ2.pct)-AQ1.pct<=80 --percentage threshold
)
SELECT RT.rn,RT.pct,S.sig,s.tsql_code AS sample_query
FROM RunningTotals AS RT
CROSS APPLY
(SELECT TOP(1) tsql_code,dbo.RegexReplace(tsql_code,
N'([\s,(=<>!](?![^\]]+[\]]))(?:(?:(?:(?#
)(?:([N])?('')(?:[^'']|'''')*(''))(?#
)|(?:0x[\da-dA-F]*)(?#
)|(?:[-+]?(?:(?:[\d]*\.[\d]*|[\d]+)(?#
)(?:[eE]?[\d]*)))(?#
)|(?:[~]?[-+]?(?:[\d]+))(?#
))(?:[\s]?[\+\-\*\/\%\&\|\^][\s]?)?)+(?#
))',
N'$1$2$3$4') AS sig
FROM dbo.WorkLoad AS W
WHERE W.cs=RT.cs) AS S
ORDER BY RT.rn

分析上述结果,pct列就是相应的tsql_code对应的查询语句运行的总时间,因此上述的步骤就是为了得到这些影响较大的查询语句(此例只有两行)
----------------------获取查询语句模板可忽略内容结束线------------------------------
使用如下的SQL可以直接获取需要优化的查询:
IF OBJECT_ID('tempdb..#AggQueries','U') IS NOT NULL
DROP TABLE #AggQueries;
SELECT cs,SUM(Duration) AS total_duration,
100. * SUM(duration)/SUM(SUM(duration)) OVER() AS pct,
ROW_NUMBER() OVER(ORDER BY SUM(duration) DESC) AS rn
INTO #AggQueries
FROM DBO.WorkLoad
GROUP BY cs;
CREATE CLUSTERED INDEX idx_cl_cs ON #AggQueries(cs);
WITH RunningTotals AS
(
SELECT AQ1.cs
,CAST(AQ1.total_duration/1000. AS numeric(12,2)) AS total_s
,CAST(SUM(AQ2.total_duration)/1000. AS numeric(12,2)) AS running_total_s
,CAST(AQ1.pct AS numeric(12,2)) AS pct
,CAST(SUM(AQ2.pct) AS numeric(12,2)) AS run_pct,
AQ1.rn
FROM #AggQueries AS AQ1
JOIN #AggQueries AS AQ2 ON AQ2.rn<=AQ1.rn
GROUP BY AQ1.cs,AQ1.total_duration,AQ1.pct,AQ1.rn
HAVING SUM(AQ2.pct)-AQ1.pct<=80 --percentage threshold
)
SELECT RT.rn,RT.pct,s.tsql_code AS sample_query
FROM RunningTotals AS RT
CROSS APPLY
(SELECT TOP(1) tsql_code
FROM dbo.WorkLoad AS W
WHERE W.cs=RT.cs) AS S
ORDER BY RT.rn
结果如下(和上面忽略那部分里的结果是一样的,但省去很多步骤(那些步骤适用更深入研究的人群)):

查询统计
通过以下代码找出相应数据库中具有最高总持续时间的5个查询模式(也就是查询语句):
SELECT TOP(5)
MAX(query) AS sample_query,
SUM(execution_count) AS cnt,--执行次数
SUM(total_worker_time) AS cpu,--占用CPU总时长
SUM(total_physical_reads) AS reads,--物理读取次数
SUM(total_logical_reads) AS logical_reads,--逻辑读取次数
SUM(total_elapsed_time) AS duration--消耗时间
FROM
(
SELECT
QS.*,
SUBSTRING(ST.text,(QS.statement_start_offset/2)+1,((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE QS.statement_end_offset END-QS.statement_start_offset)/2)+1) AS query
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
CROSS APPLY sys.dm_exec_plan_attributes(QS.plan_handle) AS PA
WHERE PA.attribute='dbid'
AND PA.value=DB_ID('Test')
)AS D
GROUP BY query_hash
ORDER BY duration DESC;
在我的数据库中输出如下:

通过上面的两步我们可以很清楚的找到要优化的查询模式。
7. 优化索引和查询
如果使用上面查询统计的SQL查到的有类似SELECT ID,date FROM dbo.test这样的查询模式,我们就只需要在orderdate列上创建一个聚集索引:
CREATE CLUSTERED INDEX idx_cl_od ON dbo.test(orderdate);
后面会介绍为什么这样可以解决问题。
按上面的操作完后,再次启动一个新的跟踪,经过一段时间后停止跟踪,并查看trc文件,看上面的优化是否起作用。一般情况下经过上面的索引优化,相应的查询模式的运行时间和I/O会大大减少,但也有会产生大量网络流量的例外。
- 查询优化的工具
首先明确下面两个概念:
DMV(Dynamic Management View):动态管理视图
DMF(Dynamic Management Function):动态管理函数
这两个概念对应的对象提供了监视SQL Server、诊断问题、优化性能的相关信息。
1. 查询执行计划的缓存
下面有几个分析缓存中查询执行计划的行为:
----------------假设句柄为:0x050005001356C94AE02DA2385300000001000000000000000000000000000000000000000000000000000000
--DMF 针对计划句柄所指定计划的每个计划属性返回一行,计划句柄作为输入提供给该DMF(这一步可以简单的理解为获取句柄)
SELECT * FROM sys.dm_exec_cached_plans
--DMF针对计划句柄所指定计划的每个计划属性返回一行,计划句柄作为输入提供给该DMF(简单理解:将句柄作为参数输入后,获取这个句柄对应的相关信息,例如该句柄所执行的数据库ID)
SELECT * FROM sys.dm_exec_plan_attributes(0x050005001356C94AE02DA2385300000001000000000000000000000000000000000000000000000000000000)
--DMF 返回与查询相关的文本,查询的句柄作为输入提供给该MDF(这一步可以简单的理解为将句柄作为参数输入,然后获取执行计划的脚本内容)
SELECT * FROM sys.dm_exec_sql_text(0x050005001356C94AE02DA2385300000001000000000000000000000000000000000000000000000000000000)
--以XML格式返回计划句柄指定的批查询的显示计划。计划句柄指定的计划可以处于缓存或正在执行状态。
SELECT * FROM sys.dm_exec_query_plan(0x050005001356C94AE02DA2385300000001000000000000000000000000000000000000000000000000000000)
2. 清空缓存
注意:清空缓存会对系统性能产生很大影响,因为清空后所有的数据都要从新加载,包括sqlserver需要重新从磁盘读取物理页等操作。
--从缓存中清空所有数据
DBCC DROPCLEANBUFFERS;
--从缓存中清空执行计划
DBCC FREEPROCCACHE;
--清空特定的数据库执行计划
DBCC FLUSHPROCINDB(<db_id>);
--清空特定缓存存储区中的执行计划
DBCC FREESYSTEMCACHE(<cachestore>);
3. STATISTICS IO
这是一个会话选项,它返回与运行语句相关的I\O信息。下面的演示要先清空数据缓存:
DBCC DROPCLEANBUFFERS;
SET STATISTICS IO ON;
SELECT * FROM Deals
SET STATISTICS IO OFF;
--结果Message上属性的意思:
--Scan count:该表在查询计划中被访问了多少次
--logical reads:数据缓存读取的页数
--physical reads和read-ahead reads:磁盘读取的页数
--lob logical reads、lob physical reads、lob read-ahead reads:大型对象相关的逻辑读取和物理读取次数
结果如下:

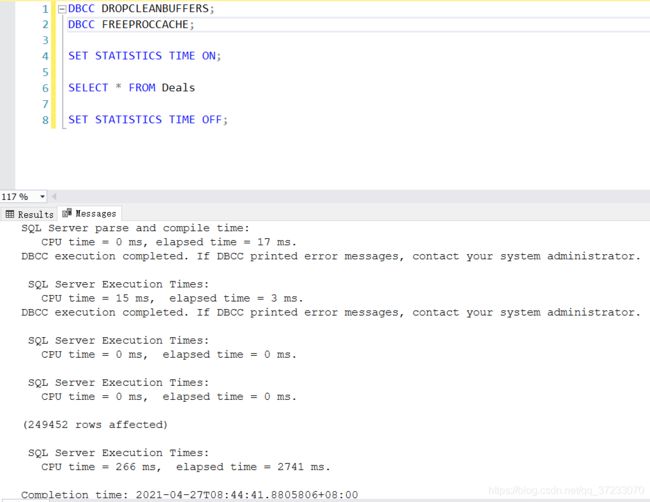
4. 测量查询的运行时间 STATISTICS TIME
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
SET STATISTICS TIME ON;
SELECT * FROM Deals
SET STATISTICS TIME OFF;
--CPU Time:执行该计划纯CPU使用的时间
--elapsed time:执行该计划使用的总时间
结果如下:
5. 分析执行计划
- 图形化的执行计划:
--选中要执行的SQL语句(以下面sql为例),然后按住Ctrl+L即可得到如下图形化界面:
SELECT * FROM Deals d
left join counterparties c on c.cpartyUID=d.cpartyUID
left join counterparties cd on cd.cpartyuid=d.dealeruid

把鼠标放到上面的箭头上,可以看到该运算符返回的估计行数,箭头粗细与资源占用成正比;即箭头越粗代表该过程越消耗资源,也就预示着该部分可能存在性能问题。
信息窗口属性简单描述:
--Physical Operation(物理运算):将在数据库引擎上发生的物理运算。
--Logical Operation(逻辑运算):与微软的查询处理概念模型相对应的逻辑运算。
-----若Physical Operation属性表示的连接算法(嵌套循环、合并、哈希),Logical Operation属性表示使用的逻辑联接类型(内连接、外连接、半连接等)。当运算符没有相应的逻辑运算时,该项的值和物理运算显示的值相同。
--Actual Number of Rows(实际行数):从运算符返回的实际行数(只在实际的计划中显示).
--Estimated I/O Cost和Estimated CPU Cost(估计I/O开销和估计CPU开销):哪个值大,就说明这个运算符和哪个密切相关。
--Estimated Number of Executions and Number of Executions(估计执行次数和执行次数) :可以帮助找到优化器做出的次优选择。
--
6. 提示(Hint)
这块讲的感绝没什么用。


7. 跟踪/Profiler
这块讲的也没啥用。
8. 数据库引擎优化顾问
这块也没啥用。
9. 数据收集和管理数据仓库
这块也没啥用。

10. 使用SMO来复制统计信息

4.4索引优化
4.4.1 表和索引的结构
首先需要了解页和区(extent)、堆(heap)、聚集索引(clustered index)和非聚集索引(nonclustered index)。
-
页和区(extent)
页是SQL SERVER存储数据的基本单位,大小为8KB。
·页也是sqlserver读写的最小I/O单位。页的大小是8192个字节,其中标头(header)占96个字节,在页尾维护的行指针占2个字节,还有其他几个保留的字节以备后用。
·当sqlserver需要查询一行时,也要把整页加载到缓存中,再从缓存中读取数据。物理读取一页比从缓存中逻辑地读取一页所产生的开销理论上大得多。区是由8个物理上连续的页组成的单元。
当sqlserver为一个不足64KB的对象分配空间时,通常指分配一个单独的页,而不是整个区;但是当对象大于64KB时通常分配一个完整的区。delete语句要记录完整日志,而Drop(删除)和Truncate(清空)表只会记录最小限度的日志故效率更高。I/O中开销最大的部分是磁盘臂(disk arm)的移动,故读取一个页和读取整个区所用的时间几乎一样长。- 表的组织方式
表有两种组织方式:堆或B树。
从技术上来说,当表在创建一个聚集索引时,表就组织为一个B树;否则就组织为一个堆。
表必须按这两种方式中的一种进行组织,所以表的组织方式又称为HOBT。
无论表是如何组织的,都可以在表上定义0个或多个非聚集索引。
非聚集索引总是组织为B树。HOBT以及非聚集索引可以在一个或多个称为分区(Partition)的单元上实现。
从技术上来说,各分区上的HOBT和每个非聚集索引可以是不相同的。
每个HOBT和非聚集索引的各分区将数据存储在称为分配单元的一组页中。
分配单元有下列三种类型:IN_ROW_DATA、ROW_OVERFLOW_DATA、LOB_DATA.
①IN_ROW_DATA用于存储所有固定长度的列,以及可变长度的列(只要行大小不超过8060字节限制)。
②ROW_OVERFLOW_DATA用于存储不超过8000字节的VARCHAR、NVARCHAR、VARBINARY、SQL_VARIANT和CLR用户自定义类型的数据,
但因为行大小超过了8060字节的限制,而从原始行移动到了这里。
③LOB_DATA用于存储大型对象数据类型值(超过8000字节的VARCHAR(MAX)、NVARCHAR(MAX)、VARBINARY(MAX)以及XML和CLR UDT)。
分配单元中存储的页集合由系统视图sys.system_internals_allocation_units中的页指针定位。
- 堆
堆是不含聚集索引的表。它的数据不按任何顺序进行组织,而是按分区组对数据进行组织。下图为以堆方式存储时可能的结构:

在一个堆中,用于保存数据之间关系的唯一结构是一个称为索引分配映射(IAM,Index Allocation Map)
的位图页(如果需要,也可以有一系列IAM页)。
对于在混合区(mixed extent)分配的前8个页,这个位图中有指向这些页的指针,还包含一个大位图,
其中每个位代表文件中4G范围内的一个区。如果某个位是0,它所代表的区将不属于拥有该IAM页的分配单元;
为1则表示属于相应的分配单元。
如果一个IAM不足以覆盖分配单元的所有数据,SQL Server将维护一个IAM的链。当扫描分配单元时,
SQL Server使用IAM页来遍历该分配单元的数据。SQL Server先加载该分配单元的第一个IAM页,
然后指示磁盘臂按分区文件的顺序,连续的取回各分区。只要数据文件没有文件系统碎片,
这个扫描过程在磁盘上就可以连续顺序地进行。
堆不是按特定的顺序来维护数据的,所以增加到表中的行可以保存到任何数据页上。
SQL Server使用一种称为页可用空间页(PFS,Page Free Space)的位图来跟踪数据页中的可用空间,
以便快速的找到有足够空间能够容纳新行的页面,如果这样的页面不存在则分配一个新页面。
当对长度可变的列进行更新时,行的大小就会扩展,页可能会因为没有空间而无法容纳行的。
此时SQL Server会把扩展后的行移动到具有足够空间的页上,而在原来的位置上保留一个所谓的正向指针(forwarding pointer),
指向行的新位置。正向指针的作用是为了在移动数据行时,避免再修改非聚集索引中的行指针。
页拆分只在B树中发生。堆中不会发生也拆分。
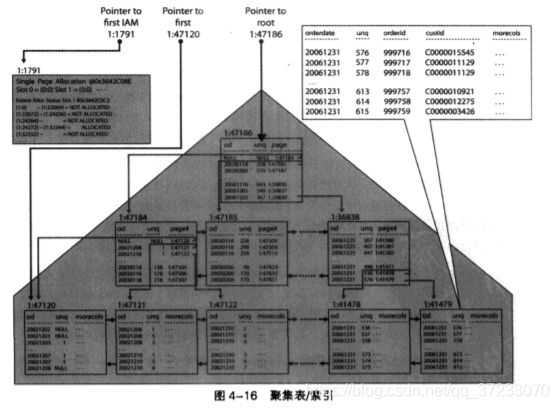
- 聚集索引
SQLSERVER中的所有索引都组织为B树结构,B树是平衡树(balanced tree)的
一种特例。平衡树的定义是:“不存在叶子节点比其他叶子节点到根的距离要远的多的树”。
聚集索引被结构化为一棵树,它在叶子结点中维护整个表的所有数据。聚集索引不是数据的副本,
而是数据本身。下图为聚集索引的结构:
本章后面是逻辑解释以及第五章,都较底层,可以浏览PDF文件简单了解,不做赘述。
第六章:子查询、表表达式和排名函数
- 决胜属性
是一个属性或属性列表,通过他可以唯一的对元素进行排名。
- All、Any和Some谓词
- 公用表达式(CTE)
类似于派生表(表套表)。
--一个CTE格式定义如下:
--WITH
--AS
--(
-- <定义CTE的内部查询>
--)
--<对CTE进行查询的外部查询>
--示例:
WITH A
AS
(
SELECT * FROM Deals
)
SELECT * FROM A D WHERE D.DealUID>1240000
--多CTE格式定义如下:
--WITH
--AS
--(
-- <定义CTE的内部查询>
--),
--
--AS
--(
-- <定义CTE的内部查询>
--)
--<对CTE进行查询的外部查询>
示例:
WITH A
AS
(
SELECT * FROM Deals
),
B AS
(
SELECT * FROM A WHERE DealUID>1240000
)
SELECT * FROM B
--可以在视图中使用CTE
--例
create view dbo.testCTE
as
WITH A
AS
(
SELECT * FROM Deals
)
SELECT * FROM A
GO;
--也可以使用CTE实现增删改
--例:
WITH A
AS
(
SELECT * FROM Deals WHERE DealUID=1240001
)
DELETE FROM A WHERE VersionSEQ=0;
--等同于 但CTE语法更易读
DELETE A FROM (SELECT * FROM Deals WHERE DealUID=1240001) A WHERE A.VersionSEQ=0;
--CTE的递归调用(不常用,知道即可,实际根本用不到)
--它的终止条件是隐式的且没有显示终止条件,只要递归成员返回空集就会自动终止。
--如果你的递归写的不正确会报这个错:The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
WITH A
AS
(
SELECT DealUID,VersionSEQ,'1' AS C FROM Deals WHERE DealUID=1240001 AND VersionSEQ=1
UNION ALL
SELECT A.DealUID,A.VersionSEQ,'2' AS C FROM A
JOIN Deals D ON D.DealUID=A.DealUID
WHERE A.DealUID=1240001 AND A.VersionSEQ=0
)
SELECT * FROM A
6.3.1 行号
SQLServer支持四个排名函数:ROW_NUMBER、RANK、DENSE_RANK和NTILE.
- ROW_NUMBER
--排名函数以一组行构成的窗口作为上下文进行计算,OVER子句专门用于定义这样的窗口,因此这些函数又称为排名开窗函数。
--OVER子句:可以简单的理解为有一个窗口,其中的数据是由FROM和JION后得到的笛卡尔结果集
--PARTITION BY:根据这一子句后跟的列名进行分区,不声明则表明整个数据区域
--ORDER BY:根据这一子句后的列名进行排序
--若出现ORDER BY(SELECT 0)的用法,则表明行号可以不按某列顺序随机生成
例:

- 子查询
子查询也可以实现排序,但是随着表的行数的增加,性能按平方阶的速度下降(n²),且代码较难理解,故不推荐。
- 游标实现排序
随着表的行数的增加,性能按线性(2n)速度下降(比子查询好),但也应避免使用。

6.3.2 RANK和DENSE_RANK
--示例:
SELECT RANK() OVER( ORDER BY DEALUID),
DENSE_RANK() OVER( ORDER BY DEALUID),
*
FROM Deals D
WHERE D.DealUID IN (743589,743590,743591)
结果:
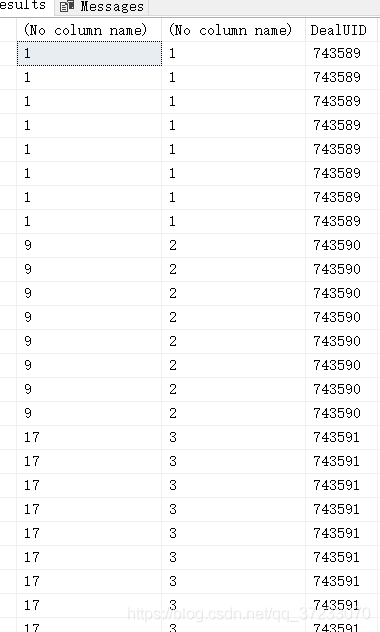
示例:

- 6.3.3组号(tile Number)
组号主要用于分析目的,要把数据项分成大小相同的几个组。
- NTILE函数
当行数/组数有余数时,会把余数的个数平分到前面的组。例如11行分3组,就是4,4,3的分组。
示例:

- 6.4数字辅助表
通过下面方法实现:
--要想明白逻辑,可以吧L0、L1、L2、L3、L4、L5按普通查询带入
IF OBJECT_ID('dbo.GetNums') IS NOT NULL
DROP TABLE dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@N AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS(SELECT 1 AS C UNION ALL SELECT 1),--2 2的(2的n次幂)次幂= 2的(2)次幂
L1 AS(SELECT 1 AS C FROM L0 AS A CROSS JOIN L0 AS B),--16 2的(2*2)次幂
L2 AS(SELECT 1 AS C FROM L1 AS A CROSS JOIN L1 AS B),--256 2的(2*2*2*2)次幂
L3 AS(SELECT 1 AS C FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS(SELECT 1 AS C FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS(SELECT 1 AS C FROM L4 AS A CROSS JOIN L4 AS B),
NUMS AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT 0))AS N FROM L5)
SELECT N FROM NUMS WHERE N<=@N;
GO
--示例如下:
--参数10为你要得到的表的行数
SELECT * FROM dbo.GetNums(10)
--结果如下图:

- 6.5 缺失范围和现有范围(也称为间断和孤岛)
感绝不到有什么价值,故忽略。
第七章 联接和集合运算
联接(CROSS、INNER、OUTER)通常指表之间的水平操作,集合运算(UNION、EXCEPT、INTERSECT)通常指表之间的垂直操作。
- 7.1联接
平常我们写联接时总是习惯性会把筛选器仅跟在联接后边,也就是如下这种写法:
SELECT *
FROM Deals D1
JOIN Deals D2 ON D1.DealUID=D2.DealUID
JOIN Deals D3 ON D1.DealUID=D3.DealUID
这样的写法Sqlserver的查询优化器总是考虑右向深度树布局。还有左向深度树布局(这种基本不怎么用到)以及浓密树布局。
右向深度树布局查询计划执行图示例如下:

浓密树布局示例如下:
SELECT *
FROM (Deals D1 JOIN Deals D2 ON D1.DealUID=D2.DealUID)
JOIN (Deals D3 JOIN Deals D4 ON D3.DealUID=D4.DealUID)
ON D1.DEALUID=D3.DEALUID
浓密树布局查询计划执行图示例如下:

外连接查询可以使用NOT EXISTS的方法来实现,一般情况下NOT EXISTS的解决方案计划更高效,但需要具体情况具体分析。
7.1.5算法
哈希(Hash):SQLSERVER不允许显式的创建哈希索引,只能创建B树,但在处理联接、聚合等操作时会内部使用哈希表。注意:哈希表是在内存中创建的(除非没有足够的内存空间,才会转到磁盘上)。
查询时可以自定义(通过OPTION)合并联接算法:
SELECT *
FROM Deals D1
JOIN Deals D2 ON D1.DealUID=D2.DealUID
JOIN Deals D3 ON D1.DealUID=D3.DealUID
where D1.DealUID=743589
option(hash join)
7.2 集合运算
- UNION
返回两个输入的所有行并去除重复行 - UNION ALL
返回两个输入的所有行,包含重复行 - EXCEPT
可以查出在第一个输入中出现,但在第二个输入中没有出现的行
EXCEPT DISTINCT
返回在第一个输入中出现,但在第二个输入中没有出现的不重复行。
EXCEPT ALL(忽略,sqlserver未实现这个运算符,一般也用不到) - INTERSECT
返回在两个输入中都出现的行,并去除重复行。
INTERSECT ALL (可忽略,不常用) - 集合运算的优先级
INTERSECT 最高,然后从左到右依次
第八章 透视转换(Pivoting)
透视转换是一种行转列的技术。
- CASE WHEN+Group BY+聚合函数
- PIVOT
逆透视转换:列转行
- UNPIVOT
使用CLR及C#或VB自定义函数
- GROUPING SETS从属子句
等同于多个Group By查询的结果集统一在一起,但性能更好,不常用。


- CUBE从属子句
例:


- WITH CUBE
不是标准SQL,不常用,用到再查其他资料吧。
- ROOLUP
不是标准SQL,不常用,用到再查其他资料吧。
- 分组集代数
不常用,用到再查其他资料吧。
第九章 TOP和APPLY
- SELECT TOP
TOP的执行顺序在ORDER BY之后,故和ORDER BY联合使用,指定查询排序靠前的行。
两种用法示例:
SELECT top 10 * from Deals
SELECT top 0.001 percent * from Deals
- INSERT TOP
示例1:
--这种只是将Select出的前10行插入
INSERT TOP(10) INTO DEALS
SELECT * FROM Deals
--这种可以指定SELECT出前10行再Insert
INSERT INTO DEALS
SELECT TOP(10) * FROM Deals
ORDER BY DealUID
- UPDATE TOP
示例:
- DELETE TOP
示例:
- APPLY
APPLY表运算符的作用是把右表达式应用到左表达式的每一行。
两种表现形式:
-
CROSS APPLY
逻辑上类似INNER JOIN。 -
OUTER APPLY
逻辑上类似LEFT OUTER JOIN。
第十章 数据修改
- VALUES
示例:
- SELECT INTO
示例:
- BULK行集提供程序
不常用,想了解再查资料吧。

- INSERT EXEC
此语句可以把存储过程或动态批处理返回的表结果集保存到现有表中: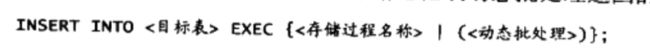
- 全局唯一标示符(GUID)

- 删除数据
1. TRUNCATE
TRUNCATE TABLE无论sqlserver采用哪种恢复模式,总是按照最小的方式记录日志。性能极高,删除几百万行数据只需几秒,而delete需要几个小时。把IDENTITY属性重置为最初的值,而DELETE不会。
2. DELETE
总是执行完整的日志记录。
3. MERGE语句基础
语法如下:

注意:Matched 后可跟Delete和Update,而Not Matched后只能跟Insert。
- 也可以在Matched或Not Matched后增加一个AND谓词使用,示例如下:

- 多个WHEN子句
MERGE语句最多可以支持WHEN MATCHED子句。
①当使用两个WHEN MATCHED子句时,第一个子句必须带有一个额外的谓词,而第二个子句带不带谓词都可以。
②如果同时指定了两个WHEN子句,只有当ON谓词和第1个WHEN子句的额外谓词均为TRUE时,MERGE语句才会应用第一个WHEN子句中的操作。如果ON谓词为TRUE,但第1个WHEN子句的额外谓词为FALSE或UNKNOWN,则继续处理第2个WHEN子句。
示例如下:

- WHEN NOT MATCHED BY SOURCE子句

注意(如下图):

- 带有OUTPUT 的INSERT

- 带有OUTPUT的DELETE


- 带有OUTPUT的UPDATE(p500)



- 带有OUTPUT的MERGE(p503)

- 可组合的DML(p505)

第十一章 查询分区表(P506)
说实话,这章的内容没啥意思,偏向底层。
第十一章 图、树、层次结构和递归查询(P520)
平常的ERP、CTRM都用不到这块的东西,想了解就自行查看吧。