python-opencv车牌检测和定位
18.python-opencv车牌检测和定位
第一章 python-opencv-图片导入和显示
第二章 python-opencv图像简单处理
第三章 python-opencv图像mask掩膜处理
第四章 python-opencv图像马赛克
第五章 python-opencv人脸马赛克
第六章 python-opencv人脸检测
第七章 python-opencv图像张贴
第八章 python-opencv轮廓绘制
第九章 python-opencv边缘检测
第十章 python-opencvpython-opencv边缘检测与人脸检测应用
第十一章 python-opencv直方图绘制与直方图均衡
第十二章 python-opencv图像傅里叶变换
第十三章 python-opencv图像的高通滤波和低通滤波
第十四章 python-opencv视频中的人脸检测
第十五章 python-opencv视频人脸检测和保存
第十六章 python-opencv使用摄像头实时人脸检测
第十七章 python-opencv图像处理-腐蚀和膨胀
文章目录
- 18.python-opencv车牌检测和定位
- 前言
- 一、完整代码
- 代码说明
-
- 加载图片
- 图片预处理
-
- 灰度处理
- 高斯滤波平滑处理
- 边界提取
-
- Sobel边界提取
- Canny边界提取
- 二值化
- 形态学运算
- 获取轮廓
- 检测结果
前言
本篇文章主要说明了如何是哦用python-opencv进行车牌检测,包括图像处理和目标检测相关知识,我对代码进行了详细的说明和注释,请查看!
一、完整代码
废话不多说,直接上代码!!!
import cv2
import numpy as np
def lpr(filename):
img = cv2.imread(filename)
# 预处理,包括灰度处理,高斯滤波平滑处理,Canny或Sobel提取边界,图像二值化
# 对于高斯滤波函数的参数设置,第四个参数设为零,表示不计算y方向的梯度,原因是车牌上的数字在竖方向较长,重点在于得到竖方向的边界
# 对于二值化函数的参数设置,第二个参数设为127,是二值化的阈值,是一个经验值
gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
GaussianBlur_img = cv2.GaussianBlur(gray_img, (3, 3), 0) # 高斯平滑/高斯模糊
# Sobel_img = cv2.Sobel(GaussianBlur_img, -1, 1, 0, ksize=3) # 提取边界
canny = cv2.Canny(GaussianBlur_img,135,225) # 提取边界
ret, binary_img = cv2.threshold(canny, 127, 255, cv2.THRESH_BINARY) # 二值化,大于127变为255,小于127变为0
# 形态学运算
kernel = np.ones((5, 15), np.uint8)
# 先闭运算将车牌数字部分连接,再开运算将不是块状的或是较小的部分去掉
close_img = cv2.morphologyEx(binary_img, cv2.MORPH_CLOSE, kernel)
open_img = cv2.morphologyEx(close_img, cv2.MORPH_OPEN, kernel)
# 由于部分图像得到的轮廓边缘不整齐,因此再进行一次膨胀操作
dilation_img = cv2.dilate(open_img, np.ones(shape=[5,5],dtype=np.uint8), iterations=3)
# 获取轮廓
contours, hierarchy = cv2.findContours(dilation_img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 测试边框识别结果
# cv2.drawContours(img, contours, -1, (0, 0, 255), 3)
# cv2.imshow("lpr", img)
# cv2.waitKey(0)
# 将轮廓规整为长方形
rectangles = []
for c in contours:
x = []
y = []
for point in c:
y.append(point[0][0])
x.append(point[0][1])
r = [min(y), min(x), max(y), max(x)]
rectangles.append(r)
# 用颜色识别出车牌区域
# 需要注意的是这里设置颜色识别下限low时,可根据识别结果自行调整
dist_r = []
max_mean = 0
for r in rectangles:
block = img[r[1]:r[3], r[0]:r[2]]
hsv = cv2.cvtColor(block, cv2.COLOR_BGR2HSV)
low = np.array([100, 60, 60])
up = np.array([140, 255, 255])
result = cv2.inRange(hsv, low, up)
# 用计算均值的方式找蓝色最多的区块
mean = cv2.mean(result)
if mean[0] > max_mean:
max_mean = mean[0]
dist_r = r
# 画出识别结果,由于之前多做了一次膨胀操作,导致矩形框稍大了一些,因此这里对于框架+3-3可以使框架更贴合车牌
cv2.rectangle(img, (dist_r[0]+3, dist_r[1]), (dist_r[2]-3, dist_r[3]), (0, 255, 0), 2)
cv2.imshow("lpr", img)
cv2.waitKey(0)
# 主程序
for i in range(5):
lpr('./car1.jpg') # 记得将这里换成自己检测的图片哈
代码说明
加载图片
使用imread函数加载图片,这里就不展开说了
img = cv2.imread(filename)
图片预处理
在这里呢,图像预处理包括灰度处理,高斯滤波平滑处理,Canny或Sobel提取边界,图像二值化,让我们一一详细说明吧。
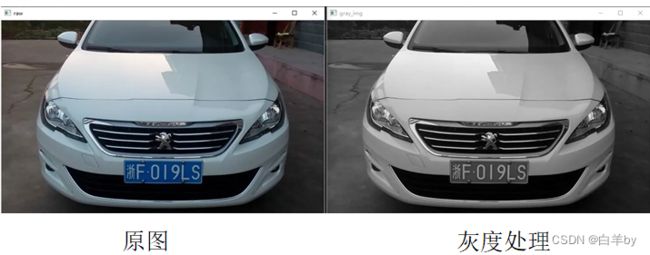
灰度处理
灰度处理代码:
gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
灰度处理使用cvtColor函数,直接调用opencv中cv2.COLOR_RGB2GRAY方法进行灰度化.
先让我们简单看一下opencv中的cvtColor函数吧!
cvtColor函数将输入图像从一种颜色空间转换为另一种颜色空间。 在从 RGB 颜色空间转换的情况下,应明确指定通道的顺序(RGB 或 BGR)。 请注意,OpenCV 中的默认颜色格式通常称为 RGB,但实际上是 BGR(字节反转)。 因此,标准(24 位)彩色图像中的第一个字节将是 8 位蓝色分量,第二个字节将是绿色,第三个字节将是红色。 然后第四、第五和第六个字节将是第二个像素(蓝色,然后是绿色,然后是红色),依此类推。
R、G 和 B 通道值的常规范围是:
-
CV_8U 图像为 0 到 255
-
0 到 65535 用于 CV_16U 图像
-
CV_32F 图像的 0 到 1
要注意的是,在线性变换的情况下,范围无关紧要。但是在非线性变换的情况下,输入的 RGB 图像应该被归一化到适当的值范围以获得正确的结果,例如,对于 RGB 变换。例如,如果您有一个 32 位浮点图像直接从 8 位图像转换而来,没有任何缩放,那么它将具有 0-255 的值范围,而不是函数假定的 0-1。因此,在调用 cvtColor 之前,您需要先将图像缩小:
img *= 1./255;
cvtColor(img, img, COLOR_BGR2Luv)
opencv中的cvtColor函数定义如下:
def cvtColor(src, code, dst=None, dstCn=None)
其中:
src: 输入图像:8 位无符号、16 位无符号 (CV_16UC…) 或单精度浮点。
dst: 输出与 src 大小和深度相同的图像。
code:颜色空间转换代码
dstCn: 目标图像中的通道数; 如果参数为 0,则通道数由 src 和 code 自动得出。
灰度化处理后的结果如下图所示:
高斯滤波平滑处理
高斯滤波代码:
GaussianBlur_img = cv2.GaussianBlur(gray_img, (3, 3), 0)
高斯滤波平滑处理使用的时OpenCV中GaussianBlur() 函数。
先让我们看一下opencv中的GaussianBlur函数
高斯滤波器是一类根据高斯函数的形状来选择权值的线性平滑滤波器。在对图像进行卷积的时候其实是对图像进行点操作,用所求像素点周围的像素通过模板的权值计算得到新的像素值。
GaussianBlur函数就是将源图像与指定的高斯核进行卷积,并且支持就地过滤。
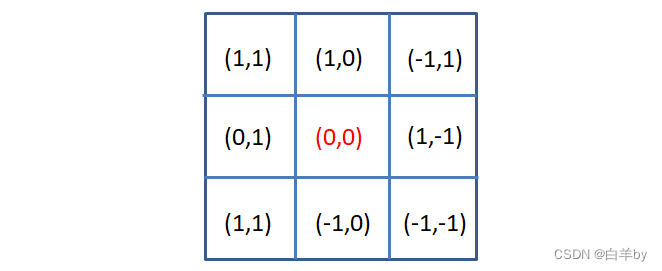
高斯滤波一般使用的二维零均值的高斯分布函数,通过高斯分布函数求出模板系数,例如一个3*3的模板:以模板的中心位置为坐标原点进行取样,其中模板各个坐标位置如下图,x轴水平向右,y轴垂直向下,(x,y)表示。
上面提到二维高斯函数的形式为:
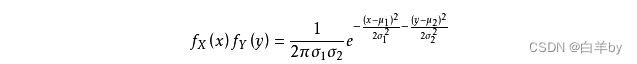
但是在图像上是离散的像素点,将该函数离散化得到:
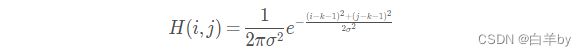
opencv中的GaussianBlur定义如下:
def GaussianBlur(src, ksize, sigmaX, dst=None, sigmaY=None, borderType=None)
其中各参数解释如下:
src 输入图像; 图像可以有任意数量的通道,它们是独立处理的,但深度应该是 CV_8U、CV_16U、CV_16S、CV_32F 或 CV_64F。
dst 输出与 src 大小和类型相同的图像。
ksize 高斯核大小。 ksize.width 和 ksize.height 可以不同,但它们都必须是正数和奇数。 或者,它们可以是零,然后根据 sigma 计算它们。
sigmaX X 方向的高斯核标准差。
sigmaY Y方向的高斯核标准差; 如果 sigmaY 为零,则设置为等于 sigmaX,如果两个 sigma 均为零,则分别从 ksize.width 和 ksize.height 计算(详见#getGaussianKernel); 为了完全控制结果,无论将来可能修改所有这些语义,建议指定所有 ksize、sigmaX 和 sigmaY。
borderType 像素外推法
高斯滤波后的结果如下图所示:

边界提取
在这里我们可以使用两种方法进行边界提取:Canny或Sobel
Sobel边界提取
Sobel边界提取代码:
Sobel_img = cv2.Sobel(GaussianBlur_img, -1, 1, 0, ksize=3)
Sobel算子是把图像中每个像素的上下左右四领域的灰度值加权差,在边缘处达到极值从而检测边缘。
opencv中Sobel函数的定义:
def Sobel(src, ddepth, dx, dy, dst=None, ksize=None, scale=None, delta=None, borderType=None)
其中各参数解释如下:
src 输入图像。
dst 输出与 src 大小和通道数相同的图像。
ddepth 输出图像深度,见@ref filter_depths “combinations”; 在 8 位输入图像的情况下,它将导致截断导数。
dx x的一阶导数。
dy y的一阶导数。
ksize 扩展 Sobel 核的大小; 它必须是 1、3、5 或 7。
scale 计算导数值的可选比例因子; 默认情况下,不应用缩放。
delta 可选 delta 值,在将结果存储到 dst 之前添加到结果中。
borderType 像素外推法
Canny边界提取
Canny边界提取代码如下:
canny = cv2.Canny(GaussianBlur_img,135,225)
Canny的工作本质是,从数学上表达前面的三个准则。因此Canny的步骤如下:
- 对输入图像进行高斯平滑,降低错误率。
- 计算梯度幅度和方向来估计每一点处的边缘强度与方向。
- 根据梯度方向,对梯度幅值进行非极大值抑制。本质上是对Sobel、Prewitt等算子结果的进一步细化。
- 用双阈值处理和连接边缘。
opencv中Canny函数的定义:
def Canny(image, threshold1, threshold2, edges=None, apertureSize=None, L2gradient=None)
该函数在输入图像中查找边缘,并使用 Canny 算法在输出地图边缘中标记它们。 threshold1 和 threshold2 之间的最小值用于边缘链接。 最大值用于查找强边缘的初始段。
其中各参数解释如下:
image 图像 8 位输入图像。
edges 边缘输出边缘图; 单通道 8 位图像,其大小与 image 相同。
threshold1 滞后过程的第一个阈值。
threshold2 滞后过程的第二个阈值。
apertureSize Sobel 算子的孔径大小。
L2gradient 一个标志,表示是否更准确的 L_2范数
Sobel和Canny边界提取结果如下:

二值化
二值化代码:
ret, binary_img = cv2.threshold(canny, 127, 255, cv2.THRESH_BINARY)
二值化就是将规定向度范围内的像素值设为255,将规定像素范围外的像素值设为0.
opencv中的二值化函数定义如下:
def threshold(src, thresh, maxval, type, dst=None)
该函数将固定级别的阈值应用于多通道阵列。 该函数通常用于从灰度图像中获取双层(二进制)图像(#compare 也可用于此目的)或用于去除噪声,即过滤掉值过小或过大的像素 . 该函数支持几种类型的阈值。 它们由类型参数确定。
其中各参数解释如下:
src 输入数组(多通道、8 位或 32 位浮点)。
dst 与 src 具有相同大小和类型以及相同通道数的输出数组。
thresh 阈值。
maxval 与 #THRESH_BINARY 和 #THRESH_BINARY_INV 阈值类型一起使用的最大值。
type 阈值类型。
二值化结果如下:

形态学运算
形态学运算主要就是开运算和闭运算,即图像的腐蚀处理和膨胀处理,其中开运算为先进行腐蚀再进行膨胀,而闭运算正好相反的顺序。
在这里呢,首先进行闭运算将车牌数字部分连接,再开运算将不是块状的或是较小的部分去掉。
闭运算代码如下:
close_img = cv2.morphologyEx(binary_img, cv2.MORPH_CLOSE, kernel)
开运算代码如下
open_img = cv2.morphologyEx(close_img, cv2.MORPH_OPEN, kernel)
注意:开运算和闭运算都是用morphologyEx函数,不同的是使用的主要方法不同,闭运算是cv2.MORPH_CLOSE,开运算是cv2.MORPH_OPEN。
进行形态学运算后的图像如下:

由于部分图像得到的轮廓边缘不整齐,因此再进行一次膨胀操作处理

获取轮廓
获取轮廓代码为:
contours, hierarchy = cv2.findContours(dilation_img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
此时我们已经获取了轮廓,让我们测试一下边框识别结果:

将轮廓规整为长方形:
rectangles = []
for c in contours:
x = []
y = []
for point in c:
y.append(point[0][0])
x.append(point[0][1])
r = [min(y), min(x), max(y), max(x)]
rectangles.append(r)
调整后的轮廓如图:

用颜色识别出车牌区域,需要注意的是这里设置颜色识别下限low时,可根据识别结果自行调整
dist_r = []
max_mean = 0
for r in rectangles:
block = img[r[1]:r[3], r[0]:r[2]]
hsv = cv2.cvtColor(block, cv2.COLOR_BGR2HSV)
low = np.array([100, 120, 120])
up = np.array([140, 255, 255])
result = cv2.inRange(hsv, low, up)
# 用计算均值的方式找蓝色最多的区块
mean = cv2.mean(result)
if mean[0] > max_mean:
max_mean = mean[0]
dist_r = r
画出识别结果,由于之前多做了一次膨胀操作,导致矩形框稍大了一些,因此这里对于框架+3-3可以使框架更贴合车牌
cv2.rectangle(img, (dist_r[0]+16, dist_r[1]), (dist_r[2]-16, dist_r[3]), (0, 255, 0), 2)
至此,车片的检测已经完成,最后就是显示检测结果了
cv2.imshow("lpr", img)
cv2.waitKey(0)
检测结果
最后让我们看一下检测效果吧!




如果有错误的地方欢迎在评论区交流,谢谢!
最后的最后!
如果这篇文章对你有帮助的话!
麻烦动动小手一键三连哈,嘻嘻!!!