音频降噪概述(1)一传统降噪方法
目录
一. 噪声的分类:
加性噪声和乘性噪声:
稳态噪声和非稳态噪声:
二. 如何降噪
1.线性滤波器:
2.谱减法
3.基于统计模型的实时降噪算法
3.1 核心思想:
3.2 基于两个假设:
3.3 维纳滤波
WebRTC原生降噪算法的三个特点:
3.4 改进方法OMLSA & IMCRA
4.子空间算法
思想:
算法:
算法场景:
4.基于机器学习的降噪
5.其他降噪方法
一. 噪声的分类:
加性噪声和乘性噪声:
加性噪声:加性噪声和信号直接不相关,满足加性条件。由噪声和源信号相加得到的。 种类按照声源,比如风声、汽笛声、键盘敲击声等。
乘性噪声:噪声和信号是相关联的,比如房间的混响、信号的衰减、开普勒效应等。并且往往是从信道传输中产生,也叫信号噪声。
稳态噪声和非稳态噪声:
从降噪的角度,按照噪声是否稳定。
稳态噪声:一直存在且响度、频率分布等特性不随时间变化或变化缓慢。 如手机、电脑之类的设备底噪、电脑散热架的风扇声等。
非稳态噪声:这些噪声等统计特性随时间变化 比如开关门等声音、门铃声、背景人声等。 非稳态噪声按照是否连续又分为 连续非稳态噪声(持续的背景人声)和瞬态噪声(敲击声)。
如下图,左稳态噪声右为非稳态噪声:
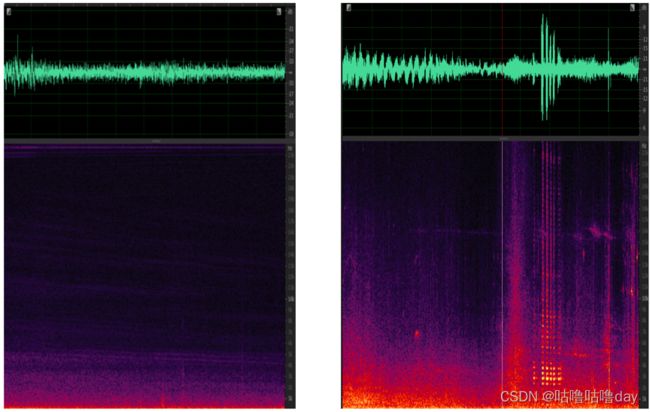
稳态噪声可以通过之前出现过的噪声进行建模抑制。非稳态噪声则是通过区分和正常语音的差异。另外噪声往往不是单独存在。
二. 如何降噪
1.线性滤波器:
【频段降噪、硬件】
线性滤波器处理方法算力要求较低,但需知道噪声会在哪个频段出现。 实际中会先做噪声出现的频段检测,再设计线性滤波器或滤波器组来消除噪声。
常见于音频采集硬件中,因为硬件厂商知道自己的硬件噪声特性。如电路设计中有些频段会有持续的电流声,则可以采用比如高通滤波器消除滴频噪声、用一些陷波滤波器消除某些频段的持续噪声。
2.谱减法
【非人声、减噪声谱、幅度谱减法、功率谱减法】
核心是先取一段非人声音频,记录下噪声的频谱能量,然后从音频频谱中减去这个噪声频谱能量。 适用于离线稳态噪声的降噪处理。
3.基于统计模型的实时降噪算法
3.1 核心思想:
用统计的方法估算出音频每个频点对应噪声和语言的能量。 (适用于相对平稳噪声)
3.2 基于两个假设:
- 噪声相对于人声在时频域上的声学统计特性更稳定。
- 所有的噪声都满足加性条件。
3.3 维纳滤波
采用最小均方误差准则设计的线性滤波器。
如实时频域维纳滤波器,目标是求当前帧每个频点的能量中有多少占比是语音。 只能通过后验的带噪信号 与 噪声的信噪比 估计前验的语音和含噪信号比值。
3.3.1维纳滤波的降噪原理:
从动态平滑的噪声模型得到噪声,根据带噪信号和噪声模型经过维纳滤波器进行降噪。
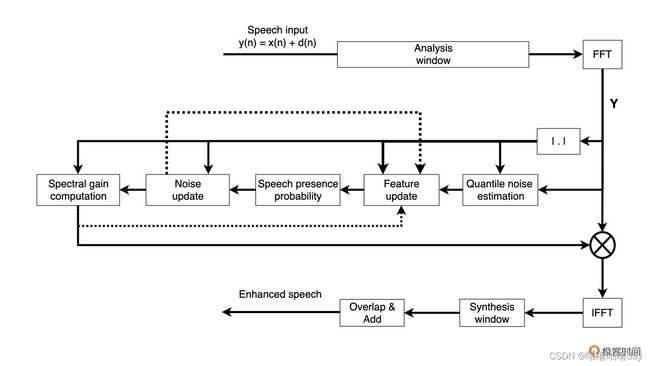
3.3.2 流程:
- 短时傅里叶变换(加窗分帧),再快速傅里叶变换得到模,再求功率谱。
- 利用功率谱进行分位数噪声估计、语音存在概率、噪声更新以及噪声抑制系数计算。
- 得到的每个频点的抑制系数乘 带噪信号的频谱 得到降噪后的频谱。
- ISTFT得到降噪后的时域信号。
3.3.3 分位数噪声估计与维纳滤波降噪的特点
分位数噪声估计与维纳滤波的降噪算法逻辑背后的思考:
- 基于统计的降噪主要是对噪声进行建模(一般是稳态的噪声)。 且噪声模型迭代不能太快,比如WebRTC所用的分位数噪声估计是基于频域更新,更新周期大约是700ms。 当噪声发生了变化,模型可能需要500ms-4s的时间来收敛到新的噪声模型,并且会存在噪声残留。
- 降噪思想类似于谱减法,利用无人段进行噪声估计。
- 为区分人声与非人声采用VAD。 这里VAD通过人工提取的特征统计得出的语音存在概率进行判断。 特征包括,频谱平坦度、频谱差异度以及先验和后验信噪比的差异得出的似然因子。
3.3.4 Speech Probability的计算流程:
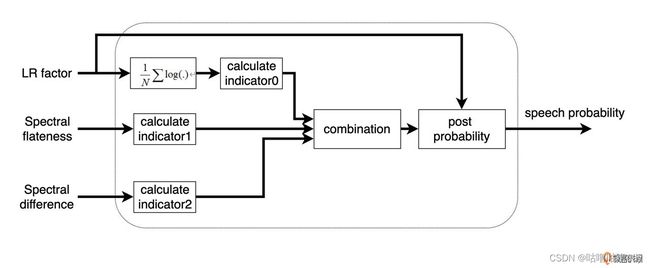
- 似然因子在频域计算log 均值得到 in dicator0;
- 根据频谱平坦度和差异度分别得到indicator1/2
语音概率通过三个指标的加权平均和似然因子进行更新。 实际更新zhong 概率较大时,噪声模型更新很缓慢,因为语音存在的概率大,反之更新快。
噪声模型是通过分位数据噪声估计得到。 比如有经验假设在噪声能量谱里,能量最小的1/4是稳态噪声。应该用这个部分更新初始噪声模型。
利用初始的噪声模型可以得到频谱平坦度、频谱差异度以及对数似然因子,进而得到语音存在概率。 有了语音存在概率就可以更新噪声模型。 再根据噪声模型和带噪信号,根据加性假设。干净语谱是通过带噪信号减去 噪声信号 或带噪信号乘。频谱增益。
WebRTC原生降噪算法的三个特点:
- 由于语音概率的判断降噪在有人声时不会进行噪声模型的更新。优点是不会对语音造成损伤比如不会吃字,但如果噪声在说话的时候发现变化,那么噪声无法被有效消除。
- 就MMSE的维纳滤波的弊端是对于浊音谐波间的噪声会存在残留。 噪声残留随着语音出现,即音乐噪声。
- 在低信噪比时,语音存在概率的判断会失效,会产生较大的语谱损伤。
3.4 改进方法OMLSA & IMCRA
OMLSA:是对人声估计,通过先验概率和先验信噪比SNR的估计 得到有声条件概率。
IMCRA:是对信号的最小值追踪,同样得到先验无声概率和先验信噪比估计,计算 条件有声概率,进而获取噪声谱的估计。
两者结合是对功率谱的最小点进行追踪。所以谐波中的音乐噪声由于明显小于谐波的能量就可以被去除,可以有效去除音乐噪声。
4.子空间算法
【NMF、耳机风噪、单独建模】
思想:
子空间算法重要是针对已知的噪声类型,量身定做一个降噪算法。 把噪声和人声投影到高纬度的空间,把不容易分离的信号变成高纬度可分的子空间,从而可分的信号。
算法:
NMF(非负矩阵分离)和字典法建模等
算法场景:
比如去除风噪,可以对风噪建模,可以有效去噪。但缺点很明显,每种噪声都得单独建模。
4.基于机器学习的降噪
基于数据驱动的方法,训练神经网络进行降噪。 特点是噪声鲁棒性好,能兼顾稳态、非稳态和瞬态噪声。 见下一讲
5.其他降噪方法
【麦克风阵列定向增强+单通道降噪】
结合基于麦克风阵列的降噪: 采集信号用麦克风阵列,可以使用波束形成的方法先锁定声源方向进行收音,比如说话人的方向进行收音,这样采集的信号信噪比更高,再通过单通道降噪可以更有效。
参考文献:
WIP: https://patentimages.storage.googleapis.com/a4/d9/d6/f3e557a291b982/WO2012158156A1.pdf
