李宏毅机器学习作业3——Convolutional Neural Network
本作业来源于李宏毅机器学习作业说明,详情可看 Homework 3 - Convolutional Neural Network(友情提示,可能需要)
作业要求
作业要求: 在收集来的资料中均是食物的照片,共有11类,Bread, Dairy product, Dessert, Egg, Fried food, Meat, Noodles/Pasta, Rice, Seafood, Soup, and Vegetable/Fruit.我们要创建一个CNN,用来实现食物的分类。
我们可以借助于深度学习的框架(例如:Tensorflow/pytorch等)来帮助我们快速实现网络的搭建,在这里我们利用Pytorch来实现,不懂Pytorch的同学可以看看官网的Pytorch60分钟入门,看完基本可以了解Pytorch框架的用法
用到的数据 training set,testing set和validation set (之前存在百度云里的,但是发现数据全部被和谐了,去外网找到了数据。服了。。。就上传到csdn上了,能下载就下载吧,不能下载就私信我,到时候发给你。)
请将作业3所需资料下载解压,确保资料中有3个文件,分别是training。testing,validation,并保存到自己的目录当中。
最底下有kaggle提交结果。并且本作业用到了gpu,所以电脑弄不出来的可以看最下面的两种方法,还是比较香的!
Convolutional Neural Network
开始之前先导入需要的库:
- pandas:一个强大的分析结构化数据的工具集-
- numpy: Python的一个扩展程序库,支持大量的维度数组与矩阵运算
- os:可以对路径和文件进行操作的模块
- time:提供各种与时间相关的函数
- pytorch:深度学习框架(下载时注意有无gpu)
- opencv:开源的图像处理库
没有库的请自行安装(Jupyter Notebook安装方法:进入自己的环境,conda install 库名字 即可)
import os
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import pandas as pd
from torch.utils.data import DataLoader, Dataset
import time
创建一个读取文件的函数readfile
def readfile(path, label):
# label 是一個 boolean variable,代表需不需要回傳 y 值
image_dir = sorted(os.listdir(path))
x = np.zeros((len(image_dir), 128, 128, 3), dtype=np.uint8)
y = np.zeros((len(image_dir)), dtype=np.uint8)
for i, file in enumerate(image_dir):
img = cv2.imread(os.path.join(path, file))
x[i, :, :] = cv2.resize(img,(128, 128))
if label:
y[i] = int(file.split("_")[0])
if label:
return x, y
else:
return x
这里对几个函数进行了一些测试,我们图片确实缩小了(不是该程序代码,不要复制)
import os
import cv2
worksapce_path = '../data'
training_path = os.path.join(worksapce_path,"training")
img = cv2.imread(os.path.join(training_path,"0_0.jpg"))
# 裁剪图片
img_r = cv2.resize(img,(128,128))
# 显示图片 winame:一个字符串,表示创建的窗口名字,每一个窗口必须有一个唯一的名字;mat:是一个图片矩阵,numpy.ndarray类型
cv2.namedWindow('image')
cv2.imshow('image', img_r)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 保存图片
cv2.imwrite("./img_r.jpg", img_r)

设置好我们数据的存放路径,将数据加载进来
workspace_dir = 'E:\\jupyter\\data\\hw3\\food-11'
print("Reading data")
train_x, train_y = readfile(os.path.join(workspace_dir, "training"), True)
print("Size of training data = {}".format(len(train_x)))
val_x, val_y = readfile(os.path.join(workspace_dir, "validation"), True)
print("Size of validation data = {}".format(len(val_x)))
test_x = readfile(os.path.join(workspace_dir, "testing"), False)
print("Size of Testing data = {}".format(len(test_x)))
打印一下看看
Reading data
Size of training data = 9866
Size of validation data = 3430
Size of Testing data = 3347
训练集有9866张图片,验证集有3430张图片,测试集有3347张图片
接下来对数据增强,就是增加数据量
下面函数不懂的可以看这里: torchvision的使用(transforms用法介绍)
# training 时做 data augmentation
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(), # 随机将图片水平翻转
transforms.RandomRotation(15), # 随机旋转图片
transforms.ToTensor(), # 将图片向量化,并 normalize 到 [0,1] (data normalization)
])
# testing 时不需要做 data augmentation
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor(),
])
在 PyTorch 中,我们可以利用 torch.utils.data 的 Dataset 及 DataLoader 來"包装" data,使后续的 training 及 testing 更为方便。
class ImgDataset(Dataset):
def __init__(self, x, y=None, transform=None):
self.x = x
# label is required to be a LongTensor
self.y = y
if y is not None:
self.y = torch.LongTensor(y)
self.transform = transform
def __len__(self):
return len(self.x)
def __getitem__(self, index):
X = self.x[index]
if self.transform is not None:
X = self.transform(X)
if self.y is not None:
Y = self.y[index]
return X, Y
else:
return X
训练过程中,我们采用分批次训练(加快参数更新速度),设置好我们的batch_size大小,这里设置为128,然后包装好我们的数据
# 这里batch_size会跟占用内存有关,gpu内存不够可以调小一些
# 能接受的最大batchsize数是128
batch_size = 128
train_set = ImgDataset(train_x, train_y, train_transform)
val_set = ImgDataset(val_x, val_y, test_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
数据我们已经构建好了
接着就是利用pytorch来构建我们的模型
利用nn.Conv2d,nn.BatchNorm2d,nn.ReLU,nn.MaxPool2d这4个函数来构建一个5层的CNN
- nn.Conv2d:卷积层
- nn.BatchNorm2d:归一化
- nn.ReLU:激活层
- nn.MaxPool2d:最大池化层
卷积层之后进入到一个3层全连接层,最后输出结果
代码实现如下
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 維度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
模型构建好之后,我们就可以开始训练了
model = Classifier().cuda()
loss = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # optimizer 使用 Adam
num_epoch = 30 #迭代次数
#训练
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0 #计算每个opoch的精度与损失
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # 确保 model 是在 train model (开启 Dropout 等...)
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 用 optimizer 将 model 参数的 gradient 归零
train_pred = model(data[0].cuda()) # 利用 model 进行向前传播,计算预测值
batch_loss = loss(train_pred, data[1].cuda()) # 计算 loss (注意 prediction 跟 label 必须同时在 CPU 或是 GPU 上)
batch_loss.backward() # 利用 back propagation 算出每个参数的 gradient
optimizer.step() # 以 optimizer 用 gradient 更新参数值
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
# (10, 11) a torch.Size([10, 3, 128, 128]) b [ 8 3 3 0 1 9 4 10 2 0] c 2.389495372772217
# print(train_pred.cpu().data.numpy().shape, "a", data[0].cuda().data.shape, "b", data[1].numpy(), "c", batch_loss.item())
train_loss += batch_loss.item()
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
batch_loss = loss(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
#将結果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_set.__len__(), train_loss/train_set.__len__(), val_acc/val_set.__len__(), val_loss/val_set.__len__()))
运行开始训练
注意:如果没有cuda加速可能无法进行训练,可以放在cpu上跑或者在google cloab上运行
不过也不用急,可以看最下面的方法,很不错。
运行时间得一小会。。。。
Reading data
Size of training data = 9866
Size of validation data = 3430
Size of Testing data = 3347
[001/030] 31.51 sec(s) Train Acc: 0.256740 Loss: 0.017339 | Val Acc: 0.269096 loss: 0.017131
[002/030] 31.47 sec(s) Train Acc: 0.347456 Loss: 0.014601 | Val Acc: 0.175802 loss: 0.025778
[003/030] 31.49 sec(s) Train Acc: 0.398236 Loss: 0.013649 | Val Acc: 0.364723 loss: 0.014694
[004/030] 31.48 sec(s) Train Acc: 0.444253 Loss: 0.012573 | Val Acc: 0.368513 loss: 0.015320
[005/030] 31.46 sec(s) Train Acc: 0.480134 Loss: 0.011773 | Val Acc: 0.390671 loss: 0.015177
[006/030] 31.46 sec(s) Train Acc: 0.521285 Loss: 0.010926 | Val Acc: 0.446356 loss: 0.012525
[007/030] 31.48 sec(s) Train Acc: 0.533854 Loss: 0.010505 | Val Acc: 0.479592 loss: 0.011968
[008/030] 31.46 sec(s) Train Acc: 0.563248 Loss: 0.009854 | Val Acc: 0.477843 loss: 0.012600
[009/030] 31.51 sec(s) Train Acc: 0.585040 Loss: 0.009391 | Val Acc: 0.554810 loss: 0.010543
[010/030] 31.48 sec(s) Train Acc: 0.603081 Loss: 0.009005 | Val Acc: 0.527988 loss: 0.010995
[011/030] 31.47 sec(s) Train Acc: 0.635617 Loss: 0.008287 | Val Acc: 0.409621 loss: 0.016356
[012/030] 31.44 sec(s) Train Acc: 0.637949 Loss: 0.008086 | Val Acc: 0.548105 loss: 0.011001
[013/030] 31.48 sec(s) Train Acc: 0.665518 Loss: 0.007590 | Val Acc: 0.505248 loss: 0.012896
[014/030] 31.51 sec(s) Train Acc: 0.671701 Loss: 0.007425 | Val Acc: 0.614577 loss: 0.009454
[015/030] 31.44 sec(s) Train Acc: 0.703020 Loss: 0.006732 | Val Acc: 0.628863 loss: 0.008776
[016/030] 31.43 sec(s) Train Acc: 0.712041 Loss: 0.006546 | Val Acc: 0.594752 loss: 0.010056
[017/030] 31.41 sec(s) Train Acc: 0.719542 Loss: 0.006220 | Val Acc: 0.558309 loss: 0.011534
[018/030] 31.40 sec(s) Train Acc: 0.731502 Loss: 0.006048 | Val Acc: 0.615743 loss: 0.009514
[019/030] 31.45 sec(s) Train Acc: 0.744577 Loss: 0.005679 | Val Acc: 0.596793 loss: 0.010074
[020/030] 31.41 sec(s) Train Acc: 0.759781 Loss: 0.005400 | Val Acc: 0.627114 loss: 0.009538
[021/030] 31.36 sec(s) Train Acc: 0.781776 Loss: 0.004982 | Val Acc: 0.597668 loss: 0.010447
[022/030] 31.37 sec(s) Train Acc: 0.787959 Loss: 0.004679 | Val Acc: 0.605248 loss: 0.010871
[023/030] 31.38 sec(s) Train Acc: 0.816542 Loss: 0.004230 | Val Acc: 0.602041 loss: 0.011603
[024/030] 31.33 sec(s) Train Acc: 0.795561 Loss: 0.004701 | Val Acc: 0.595044 loss: 0.012817
[025/030] 31.35 sec(s) Train Acc: 0.811981 Loss: 0.004217 | Val Acc: 0.586880 loss: 0.011210
[026/030] 31.38 sec(s) Train Acc: 0.834077 Loss: 0.003668 | Val Acc: 0.632945 loss: 0.010403
[027/030] 31.30 sec(s) Train Acc: 0.855666 Loss: 0.003213 | Val Acc: 0.638776 loss: 0.010132
[028/030] 31.22 sec(s) Train Acc: 0.847659 Loss: 0.003263 | Val Acc: 0.662682 loss: 0.009819
[029/030] 31.31 sec(s) Train Acc: 0.877863 Loss: 0.002750 | Val Acc: 0.510787 loss: 0.021343
[030/030] 31.30 sec(s) Train Acc: 0.870667 Loss: 0.002954 | Val Acc: 0.581924 loss: 0.014669
这是博主的训练结果,看到模型在训练集上的精度达到了87.06%,在验证集上达到了58.19%,模型好像过拟合了。。。效果不太好
我们将训练集和验证集放到一起训练一次看看效果
将训练集和验证集组成一个训练集
train_val_x = np.concatenate((train_x, val_x), axis=0)
train_val_y = np.concatenate((train_y, val_y), axis=0)
train_val_set = ImgDataset(train_val_x, train_val_y, train_transform)
train_val_loader = DataLoader(train_val_set, batch_size=batch_size, shuffle=True)
再次进行训练
model_best = Classifier().cuda()
loss = nn.CrossEntropyLoss() # 因為是 classification task,所以 loss 使用 CrossEntropyLoss
optimizer = torch.optim.Adam(model_best.parameters(), lr=0.001) # optimizer 使用 Adam
num_epoch = 30
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
model_best.train()
for i, data in enumerate(train_val_loader):
optimizer.zero_grad()
train_pred = model_best(data[0].cuda())
batch_loss = loss(train_pred, data[1].cuda())
batch_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
#將結果 print 出來
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % \
(epoch + 1, num_epoch, time.time()-epoch_start_time, \
train_acc/train_val_set.__len__(), train_loss/train_val_set.__len__()))
运行
Reading data
Size of training data = 9866
Size of validation data = 3430
Size of Testing data = 3347
[001/030] 20.87 sec(s) Train Acc: 0.252407 Loss: 0.017331
[002/030] 20.60 sec(s) Train Acc: 0.365373 Loss: 0.014035
[003/030] 21.14 sec(s) Train Acc: 0.431709 Loss: 0.012709
[004/030] 20.64 sec(s) Train Acc: 0.485936 Loss: 0.011544
[005/030] 20.93 sec(s) Train Acc: 0.524744 Loss: 0.010650
[006/030] 21.03 sec(s) Train Acc: 0.565508 Loss: 0.009740
[007/030] 20.57 sec(s) Train Acc: 0.599428 Loss: 0.009066
[008/030] 20.95 sec(s) Train Acc: 0.620187 Loss: 0.008535
[009/030] 21.05 sec(s) Train Acc: 0.653655 Loss: 0.007884
[010/030] 20.66 sec(s) Train Acc: 0.671706 Loss: 0.007459
[011/030] 21.14 sec(s) Train Acc: 0.693216 Loss: 0.007006
[012/030] 20.86 sec(s) Train Acc: 0.710966 Loss: 0.006622
[013/030] 20.55 sec(s) Train Acc: 0.727437 Loss: 0.006172
[014/030] 21.19 sec(s) Train Acc: 0.738869 Loss: 0.005865
[015/030] 20.69 sec(s) Train Acc: 0.759251 Loss: 0.005466
[016/030] 20.71 sec(s) Train Acc: 0.767223 Loss: 0.005225
[017/030] 21.28 sec(s) Train Acc: 0.790614 Loss: 0.004688
[018/030] 20.82 sec(s) Train Acc: 0.790839 Loss: 0.004681
[019/030] 20.60 sec(s) Train Acc: 0.806709 Loss: 0.004360
[020/030] 21.31 sec(s) Train Acc: 0.817915 Loss: 0.004004
[021/030] 20.69 sec(s) Train Acc: 0.830475 Loss: 0.003795
[022/030] 20.68 sec(s) Train Acc: 0.841381 Loss: 0.003569
[023/030] 20.89 sec(s) Train Acc: 0.852738 Loss: 0.003259
[024/030] 20.85 sec(s) Train Acc: 0.861236 Loss: 0.003105
[025/030] 20.79 sec(s) Train Acc: 0.873496 Loss: 0.002797
[026/030] 21.11 sec(s) Train Acc: 0.885304 Loss: 0.002535
[027/030] 20.89 sec(s) Train Acc: 0.890193 Loss: 0.002402
[028/030] 20.97 sec(s) Train Acc: 0.895758 Loss: 0.002317
[029/030] 20.84 sec(s) Train Acc: 0.902001 Loss: 0.002158
[030/030] 20.83 sec(s) Train Acc: 0.906664 Loss: 0.002056
可以看出模型在训练集上的精度达到了90.66%,相对之前又提高了3.6%左右
但是博主感觉还是过拟合
我们在测试集上跑一下看看预测结果
test_set = ImgDataset(test_x, transform=test_transform)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
model_best.eval()
prediction = []
with torch.no_grad():
for i, data in enumerate(test_loader):
test_pred = model_best(data.cuda())
test_label = np.argmax(test_pred.cpu().data.numpy(), axis=1)
for y in test_label:
prediction.append(y)
#保存预测结果
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))
打开predict文件可以看到我们在测试集上的预测结果
Kaggle测试
我这里在Kaggle上进行了测试
https://www.kaggle.com/c/ml2020spring-hw3/submissions
这里我特意对上面两次的结果都进行了评估,结果如下:
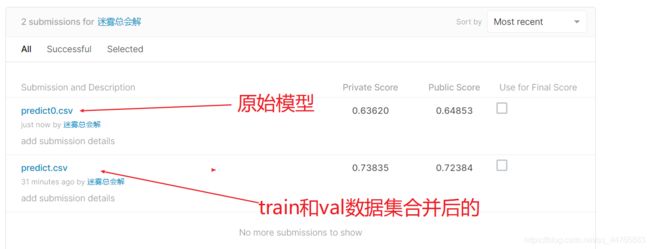
可以看到,还是有些差距的。但都不是太好,有大佬刷到了0.97132,萌新不会搞,以后弄多了再来看看。

使用google colab和Kaggle
我的电脑batch_size=128是跑不了的,无奈呀,而且还跑的嗡嗡响,在自习室跑真的是。。。实在没办法。
大家可以使用google colab来跑这些实验,因为这些实验的数据集老师都是开放的,所以我们只需通过链接就可以访问,但首先你的科学上网。
https://colab.research.google.com/drive/16a3G7Hh8Pv1X1PhZAUBEnZEkXThzDeHJ#scrollTo=5ebVIY5HQQH7
colab大家都说不好用的原因是因为我们需要挂载google drive来存放数据集进而进行训练,而google drive只有50g的免费空间,如果数据集过大,一是国内上传速度太慢,而是如果50g不够就得缴费了。所以大家好像都不是很感冒。但!因为我们做的作业数据集是保存在李老师网盘中的,而且给了链接任何人都可以访问,所以完美的解决我们的问题!
但要注意的一点是,我们要手动开启一下!
右上角的 修改 > 笔记本设置

当然,使用Kaggle跑也可以,具体的使用看一下这篇文章吧。 https://www.cnblogs.com/moonfan/p/12256832.html
我对比了一下,Kaggle上跑的快一些,这里看我上面两次训练就能看出来,上面的是在colab上跑的,下面的是在Kaggle上跑的,一般会快8s左右(不是因为数据集不同,同一个数据集我都跑过)。但是Kaggle上要自己上传数据,其实也无所谓。而且Kaggle每个星期会给30h的时间,好像不用就不算时间,还是不错的。