图谱实战 | 开源知识图谱融合工具剖析:Dedupe与OpenEA工具实现思想、关键环节与实操分析...
转载公众号 | 老刘说NLP
实体对齐旨在发现不同知识图谱中的共指实体,如百度百科的360与Wikipedia中的360 qihoo。实体对齐是知识融合的重要任务,通过实体对齐集成多源知识图谱可以为下游任务提供更加全面的知识表示。
实际上,实体对齐本质上就是个去重的工作,在数据治理等场景中应用也十分广泛。
Dedupe实体对齐工具和OpenEA实体对齐工具是基于有监督方式进行实体对齐的两个代表开源工具,前者使用主动学习和聚类的方式,后者使用知识嵌入的方式完成对齐目标。
本文主要以这两个工具的调研和实验介绍为主题,从对齐思想、模型构成、模型实验以及评估测试等几个方面进行综合介绍,以达到一定的普及目标,供大家一起参考。
一、Dedupe实体对齐工具
Dedupe是一个python库,使用机器学习对结构化数据快速执行模糊匹配,重复数据删除和实体对齐。基于dedupe方法的对齐,本质上都是去除重复,通过各种数据类型来对样本进行比较,计算相似度,再进行聚类,达到将重复的数据聚集到同一类下,实现去重的目的。
地址:https://github.com/dedupeio/dedupe
Dedupe本质上都是“去重”,其核心方法就是通过各种数据类型(fields中的数据类型)来对样本进行比较计算相似度,然后通过聚类,进而达到将重复的数据(叫做同一类也好)聚集到同一类下,最终实现去重的目的。
1、对齐思想
Deque将数据去重转换为一个基于特征打分的过程,例如,比较一下两条记录是否相似,当我们计算两张唱片是否相似时,我们可以将每张唱片视为长字符串。
record_distance = string_distance('bob roberts 1600 pennsylvania ave. 555-0123',
'Robert Roberts 1600 Pensylvannia Avenue')转变为各个字段值的相似度:
record_distance = (string_distance('bob', 'Robert')
+ string_distance('roberts', 'Roberts')
+ string_distance('1600 pennsylvania ave.', '1600 Pensylvannia Avenue')
+ string_distance('555-0123', ''))而不同的字段也可以使用不同的权重,逐字段比较的主要优势是,我们不必平等对待每个字段字符串距离。也许我们认为姓氏和地址相似真的很重要,但名字和电话号码接近并不重要。我们可以用数字权重来表达这种重要性,即
record_distance = (0.5 * string_distance('bob', 'Robert')
+ 2.0 * string_distance('roberts', 'Roberts')
+ 2.0 * string_distance('1600 pennsylvania ave.', '1600 Pensylvannia Avenue')
+ 0.5 * string_distance('555-0123', ''))其中,对于不同类型的字段,采用不同的距离度量方式,例如,对于String这种类型,模型是采用 affine gap string distance间隙惩罚方法。
2、模型训练
1)模型设置与数据输入
Dedupe给出了多个去重的例子,数据来源于10个不同的芝加哥早期儿童教育网站,
input_file = 'csv_example_messy_input.csv'
output_file = 'csv_example_output.csv'
settings_file = 'csv_example_learned_settings'
training_file = 'csv_example_training.json'
print('importing data ...')
data_d = readData(input_file)
# If a settings file already exists, we'll just load that and skip training
if os.path.exists(settings_file):
print('reading from', settings_file)
with open(settings_file, 'rb') as f:
deduper = dedupe.StaticDedupe(f)其中:
csv_example_input_with_true_ids.csv表示带标记的训练集
其中,rue Id就是label,即重复数据的True Id是相同的。
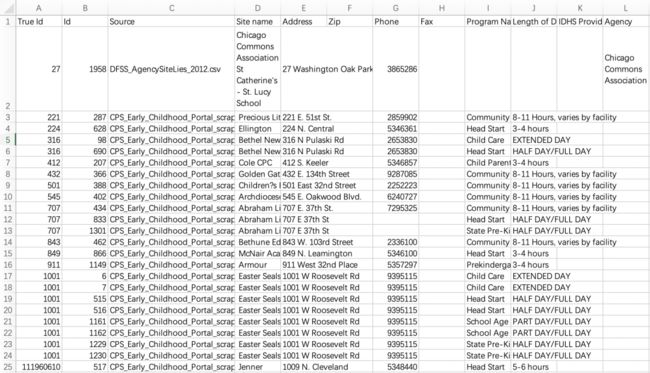
csv_example_messy_input.csv表示训练集:
其中,该csv中是没有True Id和Id这两列的,该文件中样本的顺序是按照csv_example_input_with_true_ids.csv中Id的顺序给出的,所以csv_example_messy_input.csv的第一条样本对应的就是csv_example_input_with_true_ids.csv中Id为0的样本,

2)选择特征及样本抽样
基于上述思想,训练部分首先要定义模型需要考虑的字段,这个是整个训练的基础,后面会不断学习各个特征的权重。
# Define the fields dedupe will pay attention to
fields = [
{'field': 'Site name', 'type': 'String'},
{'field': 'Address', 'type': 'String'},
{'field': 'Zip', 'type': 'Exact', 'has missing': True},
{'field': 'Phone', 'type': 'String', 'has missing': True},
]
# Create a new deduper object and pass our data model to it.
deduper = dedupe.Dedupe(fields)在训练阶段,需要抽取一部分随机样本的记录对,然后从中选择有可能是重复的记录对,也可以通过参数blocked_proportion设置取样记录对的比例。
3)Active learning与人工标注
Deque在训练阶段使用了一个Active learning模型,为了找出重复一组数据的最佳规则,必须给它一组带标签的示例来学习,这就需要引入标注。给出的标记示例越多,重复数据删除结果就越好,所以在运行的过程中,其会将其不能做出判断的样本打印出来让人工来判断。
Phone : 2850617
Address : 3801 s. wabash
Zip :
Site name : ada s. mckinley st. thomas cdc
Phone : 2850617
Address : 3801 s wabash ave
Zip :
Site name : ada s. mckinley community services - mckinley - st. thomas
Do these records refer to the same thing?
(y)es / (n)o / (u)nsure / (f)inished4)partition聚类与同类数据分配
partition分区将返回dedupe认为都是指同一实体的记录集,在输出格式中,单文件csv表格,同时对相似的记录打上标签,以及对应的置信度,可以看到多了两列,一列是聚类号,相同的聚类号为相似实体,还有一列为置信度
clustered_dupes = deduper.partition(data_d, 0.5)
cluster_membership = {}
for cluster_id, (records, scores) in enumerate(clustered_dupes):
for record_id, score in zip(records, scores):
cluster_membership[record_id] = {
"Cluster ID": cluster_id,
"confidence_score": score
}使用的是hierarchy.fcluster聚类方法,其思想在于从给定的链接矩阵定义的层次聚类中形成平面聚类。
def cluster(
dupes: Scores, threshold: float = 0.5, max_components: int = 30000
) -> Clusters:
distance_threshold = 1 - threshold
dupe_sub_graphs = connected_components(dupes, max_components)
for sub_graph in dupe_sub_graphs:
if len(sub_graph) > 1:
i_to_id, condensed_distances, N = condensedDistance(sub_graph)
linkage = scipy.cluster.hierarchy.linkage(
condensed_distances, method="centroid"
)
partition = scipy.cluster.hierarchy.fcluster(
linkage, distance_threshold, criterion="distance"
)
clusters: dict[int, list[int]] = defaultdict(list)
for i, cluster_id in enumerate(partition):
clusters[cluster_id].append(i)
squared_distances = condensed_distances**2
for cluster in clusters.values():
if len(cluster) > 1:
scores = confidences(cluster, squared_distances, N)
yield tuple(i_to_id[i] for i in cluster), scores
else:
((ids, score),) = sub_graph
if score > threshold:
yield tuple(ids), (score,) * 23、模型评估
Deque主要定义了evaluateDuplicates来进行评价,思想在于通过计算预测值和真实值(test_dupes,true_dupes)的交集和差集个数进而计算准确率和回归率。
def evaluateDuplicates(found_dupes, true_dupes):
true_positives = found_dupes.intersection(true_dupes)
false_positives = found_dupes.difference(true_dupes)
uncovered_dupes = true_dupes.difference(found_dupes)
print('found duplicate')
print(len(found_dupes))
print('precision')
print(1 - len(false_positives) / float(len(found_dupes)))
print('recall')
print(len(true_positives) / float(len(true_dupes)))其中,dupePairs函数是将同一聚类下所有样本两两组合,假设Cluster ID=4这一类下有样本为2,3,4那么返回的结果就是(2,3),(2,4),(3,4),在计算时候,分别以真实样本和测试样本为例进行组合,得到组合序列。
def dupePairs(filename, rowname) :
dupe_d = collections.defaultdict(list)
with open(filename) as f:
reader = csv.DictReader(f, delimiter=',', quotechar='"')
for row in reader:
dupe_d[row[rowname]].append(row['Id'])
if 'x' in dupe_d :
del dupe_d['x']
dupe_s = set([])
for (unique_id, cluster) in viewitems(dupe_d) :
if len(cluster) > 1:
for pair in itertools.combinations(cluster, 2):
dupe_s.add(frozenset(pair))
return dupe_s地址:https://github.com/dedupeio/dedupe
二、OpenEA知识图谱融合工具
OpenEA (https://github.com/nju-websoft/OpenEA) 是一个面向基于嵌入的知识图谱实体对齐的开源软件库,由南京大学万维网软件研究组 (Websoft) 贡献。
通过Python和Tensorflow开发得到,集成了12 种具有代表性的基于嵌入的实体对齐方法,同时它使用了一种灵活的架构,可以较容易地集成大量现有的嵌入模型。
1)内置模型

2)内置数据集
地址:https://github.com/nju-websoft/OpenEA/tree/master/tutorial
1、模型构成
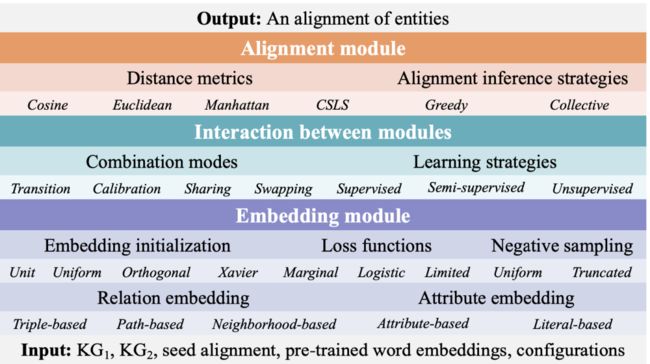
1)嵌入模块 (embedding module)
嵌入模块试图将知识图谱嵌入到低维空间中。根据三元组的类型,我们可以将嵌入模型分为两类:关系嵌入与属性嵌入。
前者采用关系学习技术捕捉知识图谱结构,后者利用实体的属性三元组信息。
关系嵌入主要有三种实现方式:
基于三元组的嵌入能够捕捉关系三元组的局部语义 (例如 TransE)
基于路径的嵌入利用跨越路径的关系之间的长程依赖信息 (例如 IPTransE、RSN4EA)
基于邻居的嵌入主要利用实体之间的关系构成的子图结构 (例如 GCN)。
属性嵌入有两种方式:
属性相关性嵌入主要考虑属性间的相关性 (例如 JAPE)
字面量嵌入将字面量值引入到属性嵌入中 (例如 AttrE)。
2)对齐模块 (alignment module)
对齐模块使用种子实体对作为训练数据来捕捉实体嵌入表示的相关性,其中两个关键是选择何种距离度量方式以及设计何种对齐推断策略。
度量方式有三种:余弦距离、欧几里得距离和曼哈顿距离。 针对对齐推断策略,目前所有方法都采用贪心搜索方式,即为每一个实体依据度量方式选择距离最短的实体作为推断的对齐实体。
3)交互模块 (Interaction between modules)
有四种典型的组合模式用于调整知识图谱嵌入以便实体对齐:
嵌入空间的转换,通过种子实体对 (e1,e2) 学习两个嵌入空间中的转换矩阵 M 使得 Me1≈e2;
嵌入空间校准,将两个知识图谱嵌入到统一空间中,通过最小化||e1-e2||来校准实体对中的嵌入表示;
2、输入数据
OpenEA提供了基于DBP2.0数据集的案例,可以通过figshare下载。该数据集抽取自多语言DBpedia, 其包含三个实体对齐任务,分别是ZH-EN、JA-EN和FR-EN。但本次实验只考虑ZH-EN,其包含以下(本实验所需的)文件:
1)rel_triples_1: 源知识图谱的关系三元组,格式是(头实体 \t 关系 \t 尾实体),总数量286067
http://zh.dbpedia.org/resource/E860025 http://zh.dbpedia.org/property/R954812 http://zh.dbpedia.org/resource/E285844
http://zh.dbpedia.org/resource/E048877 http://zh.dbpedia.org/property/R901817 http://zh.dbpedia.org/resource/E744067
http://zh.dbpedia.org/resource/E711315 http://zh.dbpedia.org/property/R177205 http://zh.dbpedia.org/resource/E506745
http://zh.dbpedia.org/resource/E234064 http://zh.dbpedia.org/property/R733324 http://zh.dbpedia.org/resource/E219104
http://zh.dbpedia.org/resource/E595017 http://zh.dbpedia.org/property/R127973 http://zh.dbpedia.org/resource/E6022342)rel_triples_2: 目标知识图谱的关系三元组,格式是(头实体 \t 关系 \t 尾实体),总数量 586868
http://dbpedia.org/resource/E586550 http://dbpedia.org/property/R003961 http://dbpedia.org/resource/E943329
http://dbpedia.org/resource/E742102 http://dbpedia.org/property/R772631 http://dbpedia.org/resource/E199274
http://dbpedia.org/resource/E570181 http://dbpedia.org/property/R683819 http://dbpedia.org/resource/E312656
http://dbpedia.org/resource/E005637 http://dbpedia.org/property/R545180 http://dbpedia.org/resource/E513394
http://dbpedia.org/resource/E355628 http://dbpedia.org/property/R545180 http://dbpedia.org/resource/E5061333)splits/train_links: 实体对齐的训练数据,格式是(源实体 \t 等价的目标实体),总数量9954条
http://zh.dbpedia.org/resource/E365845 http://dbpedia.org/resource/E828694
http://zh.dbpedia.org/resource/E235226 http://dbpedia.org/resource/E471688
http://zh.dbpedia.org/resource/E526120 http://dbpedia.org/resource/E499307
http://zh.dbpedia.org/resource/E394136 http://dbpedia.org/resource/E439798
http://zh.dbpedia.org/resource/E679479 http://dbpedia.org/resource/E280886
http://zh.dbpedia.org/resource/E488435 http://dbpedia.org/resource/E5115554)splits/valid_links: 实体对齐的验证数据,格式是(源实体 \t 等价的目标实体),总数量6636条
http://zh.dbpedia.org/resource/E095694 http://dbpedia.org/resource/E091946
http://zh.dbpedia.org/resource/E891776 http://dbpedia.org/resource/E703020
http://zh.dbpedia.org/resource/E973944 http://dbpedia.org/resource/E411192
http://zh.dbpedia.org/resource/E830920 http://dbpedia.org/resource/E611288
http://zh.dbpedia.org/resource/E407836 http://dbpedia.org/resource/E5215005)splits/test_links: 实体对齐的测试数据,格式是(源实体 \t 等价的目标实体),总数量16593条
http://zh.dbpedia.org/resource/E663112 http://dbpedia.org/resource/E065714
http://zh.dbpedia.org/resource/E238387 http://dbpedia.org/resource/E050785
http://zh.dbpedia.org/resource/E833924 http://dbpedia.org/resource/E143604
http://zh.dbpedia.org/resource/E800312 http://dbpedia.org/resource/E2623772、模型训练
在模型训练上,可以指定MTransEV2模型进行训练,例如:
if __name__ == '__main__':
kgs = read_kgs_from_folder(args.training_data, args.dataset_division, args.alignment_module,
args.ordered, args.align_direction)
model = MTransEV2()
model.set_args(args)
model.set_kgs(kgs)
model.init()
model.run()
model.test()其中,针对2个KG,分别进行比对处理:
kg1 = KG(kg1_relation_triples, set())
kg2 = KG(kg2_relation_triples, set())
if direction == "left":
two_kgs = MyKGs(kg1, kg2, train_links, test_links,
train_unlinked_ent1, valid_unlinked_ent1, test_unlinked_ent1,
train_unlinked_ent2, valid_unlinked_ent2, test_unlinked_ent2,
valid_links=valid_links, mode=mode, ordered=ordered)
else:
assert direction == "right"
train_links_rev = [(e2, e1) for e1, e2 in train_links]
test_links_rev = [(e2, e1) for e1, e2 in test_links]
valid_links_rev = [(e2, e1) for e1, e2 in valid_links]
two_kgs = MyKGs(kg2, kg1, train_links_rev, test_links_rev,
train_unlinked_ent2, valid_unlinked_ent2, test_unlinked_ent2,
train_unlinked_ent1, valid_unlinked_ent1, test_unlinked_ent1,
valid_links=valid_links_rev, mode=mode, ordered=ordered)3、模型评估
基于表示学习的实体对齐方法将两个知识图谱映射到一个向量空间,期望共指的实体具有相似的向量表示,即在空间内互为最近邻。
模型训练完成后,给定每一条测试数据(源实体、对应的目标实体),先读取该源实体的向量表示(如果有必要,还需要将其映射到目标知识图谱的表示空间),然后计算其和所有目标实体向量的相似度,并根据相似度对候选目标实体进行降序排列,期望对应的目标实体排在第一位(即最近邻)。
在评价指标上,使用Hits@k (k=1或10)、mean rank (MR)、mean reciprocal rank (MRR)是常用的实体对齐性能指标。
Hits@k计算了对应目标实体排名在top k的测试数据的比例;
MR是所有测试数据的对应目标实体的平均排名;
MRR是这些排名的倒数的平均值;
Hits@k和MRR越高且MR越低,说明模型性能越好。
基线方法在ZH-EN数据上的表现如下:

总结
本文主要围绕着实体对齐这一主题,对现有的两个具有代表性的对齐工具进行了介绍。
Dedupe使用主动学习和聚类的方式,OpenEA使用知识嵌入的方式完成对齐目标.
从中我们可以看到:
基于表示学习的实体对齐方法有两个模块。一个是embedding learning (EL) 模块,它读取两个知识图谱的关系三元组,使用表示学习技术为实体学习向量表示。另一个是alignment learning (AL) 模块,它读取实体对齐的训练数据,为共指的实体学习相似的表示。 基于统计聚类方法的实体对齐方法对一特征以及聚类方法的选择较为敏感。
基于统计聚类方法的实体对齐方法对一特征以及聚类方法的选择较为敏感。
而在实际的业务过程中,如何在保证正确率的情况下,选择更为有效的方式,如基于规则的严控策略十分必要,后面几篇文章我们将进一步介绍。
参考文献
1、http://www.vldb.org/pvldb/vol13/p2326-sun.pdf
2、 OpenEA: A Benchmarking Study of Embedding-based Entity Alignment for Knowledge Graphs. VLDB 2020
3、https://docs.dedupe.io/en/latest/API-documentation.html
4、https://blog.csdn.net/xs1997/article/details/125060217
5、https://github.com/dedupeio/dedupe-examples
6、https://blog.csdn.net/weixin_42001089/article/details/94573050
7、https://en.wikipedia.org/wiki/Gap_penalty#Affine
关于老刘
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
就职于360人工智能研究院、曾就职于中国科学院软件研究所。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。