一篇文章搞懂TCP协议及TCP编程
目录
运输层端口号、多路复用、多路分解
1.1、运输层端口号
端口号的基本概念
TCP/IP体系的应用层常用协议所使用的熟知端口号
1.2、运输层的多路复用与多路分解
编辑面向连接的运输:TCP
2.1TCP连接
2.2TCP协议与UDP协议对比
2.3TCP报文段格式
2.4TCP三次握手(建立连接)
2.4.1TCP为了保证连接的可靠性,每次都会通过进行三次握手来建立可靠的连接
2.4.2使用tcpdump命令抓包查看建立过程
2.5两次握手是否可以?(面试题)
2.5TCP四次挥手(释放连接)
2.5.1TCP使用四次挥手进行断开连接;编辑
2.5.2使用tcpdump命令抓包查看断开连接过程
2.5.3TIME-WAIT时间是否多余,为什么?(面试问题)
2.5.4是否可以强制使用被处于TIME_WAIT状态的连接占用的socket地址?怎样实现?(面试)
2.6TCP连接时SYN泛洪攻击
2.7TCP中报活计时器作用
2.8用状态图表示TCP建立与断开
2.8TCP流量控制
2.9TCP的拥塞控制
2.9.1从三个方面来说明出现拥塞的原因以及拥塞的代价(书上讲解);
2.9.2拥塞控制方法
2.9.3慢开始,拥塞避免
2.9.4快重传和快恢复
2.10TCP超时重传的时间选择
2.10.1超时重传时间的极端情况
2.10.1往返时间的估计与超时
2.11TCP总结
TCP之socket编程(c++实现代码)
TCP编程流程
客户端
服务器端
参考文献
运输层端口号、多路复用、多路分解
1.1、运输层端口号
端口号的基本概念
在网络编程中我们可以经常听到端口号这个概念,TCP协议也是不例外的,那什么是端口号?
举个简单的例子:如果 IP 是用来定位街区的,那么端口就是对应于该街区中每一户的门牌号。在通讯过程中,数据通过各种通讯协议最终抵达设备(如计算机)后,这里的设备就相当于一个街区,而在设备计算机内部有很多程序在跑,数据进来之后,必须要给它一个对应的门牌号(即端口号),程序才方便进行后续操作。端口号属于传输协议的一部分,因此我们可以说,数据通过 IP 地址发送对应的数据到指定设备上,而通过端口号把数据发送到指定的服务或程序上。
TCP/IP体系的运输层使用端口号来区分应用层的不同应用进程。
端口号使用16比特表示,因此取值范围为0~65535;
端口号根据范围分为三种,如下:
- 熟知端口号:0~1023,IANA把这些端口号指派给TCP/IP体系中最重要的一些应用协议,例如FTP使用21/20,HTTP使用80,DNS使用53;
- 登记端口号:1024~49151,为没有数值端口号的引用程序使用,使用这类端口号必须在IANA按照规定的手续的的登记,以防止超重复,例如:Microsoft RDP微软远程桌面使用的端口号3389.
- 短暂端口号:49152~65535,留给客户进程选择暂时使用。当服务器进程受到客户进程的报文时,就知道了客户进程所使用的动态端口号。通信结束后,这个端口号可供其他客户进程以后使用。
TCP/IP体系的应用层常用协议所使用的熟知端口号
| 协议及服务器 | 端口号 |
| HTTP |
80/8080/3128/8081/9098 |
| HTTPS | 443/tcp 443/udp |
| SOCKS代理协议服务器 | 1080 |
| .FTP(文件传输)协议 | 21 |
| Telnet(远程登录)协议 | 23 |
| FTP | 21/tcp |
| TFTP | 69/udp |
| SSH(安全登录)、SCP(文件传输) | 22/tcp |
| SMTP | 25/tcp |
| POP3(E-mail) | 110/tcp |
| Webshpere应用程序 | 9080 |
| webshpere管理工具 | 9090 |
| JBOSS | 8080 |
| TOMCAT | 8080 |
| WIN2003远程登录 | 3389 |
| MS SQL*SERVER数据库server | 1433/tcp 1433/udp |
| MS SQL*SERVER数据库monitor | 1434/tcp 1434/udp |
| DNS | 53/udp |
| Mysql数据库 | 3306 |
| BGP | 179 |
1.2、运输层的多路复用与多路分解
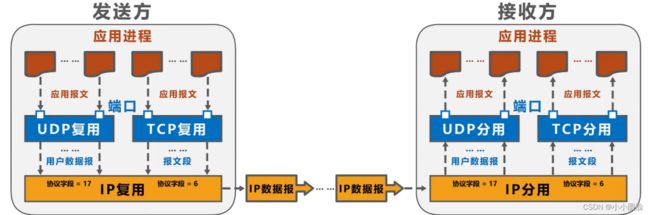
为了解释分解和复用的过程,在这里举一个简单的例子:
用一个家庭类比;家庭的每一个孩子通过他们的名字来标识。假设Ann的家庭向Bill发送信件;当Bill从邮递员处收到一批信件,并通过查看收件人姓名将信件交付给他的兄弟姐妹是,他执行的操作就是分解;当Ann从兄弟姐妹们那里手机信件并将它们交给邮寄员是,她执行的操作就是多路复用;
现在给出多路复用和多路分解的概念:
- 在接收端:运输层检查这些字段,标识出接收套接字,进而将报文段定向到该套接字。将运输层报文段中的数据交付到正确的套接字的工作称为多路分解( demultiplexing)。
- 在源主机:源主机从不同套接字中收集数据块,并为每个数据块封装上首部信息(这将在以后用于分解)从而生成报文段,然后将报文段传递到网络层,所有这些工作称为多路复用( multiplexing)。
如图表示多路复用及分解过程:
面向连接的运输:TCP
2.1TCP连接
TCP被称为面向连接的(connection-oriented),这是因为在一个应用进程可以开始向另一个应用进程发送数据之前,这两个进程必须先进行相互“握手”,即他们必须相互发送某些预备报文段,以建立确保数据传输的参数。作为TCP连接建立的一部分,连接的双方都将初始化与TCP连接相关的许多TCP状态变量。

TCP为每块客户数据配上一个TCP首部,从而形成多个TCP报文段( TCP segment)。这些报文段被下传给网络层,网络层将其分别封装在网络层IP数据报中。然后这些IP数据报被发送到网络中。当TCP在另一端接收到一个报文段后,该报文段的数据就被放入该TCP连接的接收缓存中,如上图所示。应用程序从此缓存中读取数据流。该连接的每一端都有各自的发送缓存和接收缓存。
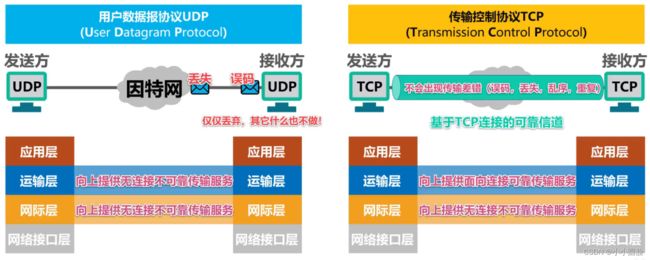
2.2TCP协议与UDP协议对比
- TCP 协议提供的是:面向连接、可靠的、字节流服务。使用 TCP 协议通信的双发必须先建立连接,然后才能开始数据的读写。双方都必须为该连接分配必要的内核资源,以管理连接的状态和连接上数据的传输。TCP 连接是全双工的,双方的数据可以通过一个连接进行读写。完成数据交换之后,通信双方都必须断开连接以释放系统资源。
- UDP 数据报服务特点:发送端应用程序每执行一次写操作,UDP 模块就将其封装成一个 UDP 数据报发送。接收端必须及时针对每一个 UDP 数据报执行读操作,否则就会丢包。并且,如果用户没有指定足够的应用程序缓冲区来读取 UDP 数据,则 UDP 数据将被截断。
下图可以帮助记忆:
2.3TCP报文段格式
TCP 报文段由首部字段和一个数据字段组成。数据字段包含一块应用数据。MSS限制了报文段数据字段的最大长度。当TCP发送一个大文件,例如某Web页面上的一个图像时,TCP通常是将该文件划分成长度为MSS的若干块(最后一块除外,它通常小于MSS)。然而,交互式应用通常传送长度小于MSS的数据块。例如,对于像Telnet这样的远程登录应用,其TCP报文段的数据字段经常只有一个字节。由于TCP的首部一般是20字节(比UDP首部多12字节),所以Telnet发送的报文段也许只有21字节长。
下图表示表示TCP报文段结构: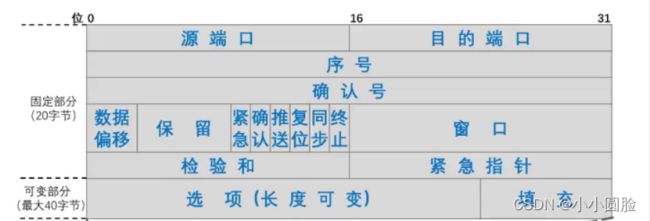
- 源端口:用来标识本主机端口号。
- 目的端口号:用来标识目标主机的端口号。
- 序号:占32比特,取值范围[0,
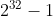 ],序号增加到最后一个后,下一个序号就又回到0。指出本TCP报文段数据载荷的第一个字节的序号。
],序号增加到最后一个后,下一个序号就又回到0。指出本TCP报文段数据载荷的第一个字节的序号。 - 确认号:占32比特,取值范围[0, ],确认号增加到最后一个后,下一个确认号就又回到0。指出期望收到对方下一个TCP报文段的数据载荷的第-个字节的序号,同时也是对之前收到的所有数据的确认。若确认号=n,则表明到序号n-1为止的所有数据都已正确接收,期望接收序号为n的数据。
- 确认标志位ACK:取值为1时确认号字段才有效;取值为0时确认号字段无效。TCP规定,在连接建立后所有传送的TCP报文段都必须把ACK置1。
- 数据偏移:占4比特,并以4字节为单位。用来指出TCP报文段的数据载荷部分的起始处距离TCP报文段的起始处有多远。这个字段实际上是指出了TCP报文段的首部长度。
- 保留:占6比特,保留为今后使用,但目前应置为0。
- 窗口:占1 6比特,以字节为单位。指出发送本报文段的一方的接收窗口。窗口值作为接收方让发送方设置其发送窗口的依据。这是以接收方的接收能力来控制发送方的发送能力,称为流量控制。
- 校验和:占1 6比特,检查范围包括TCP报文段的首部和数据载荷两部分。在计算校验和时,要在TCP报文段的前面加,上12字节的伪首部。
- 同步标志位SYN:在TCP连接建立时用来同步序号。(tcp三次握手之置1)
- 终止标志位FIN:用来释放TCP连接。(四次挥手 FIN置1)。
- 推送标志位PSH:接收方的TCP收到该标志位为1的报文段会尽快.上交应用进程,而不必等到接收缓存都填满后再向上交付。
- 紧急标志位URG:取值为1时紧急指针字段有效;取值为0时紧急指针字段无效。
- 紧急指针:占16比特,以字节为单位,用来指明紧急数据的长度。当发送方有紧急数据时,可将紧急数据插队到发送缓存的最前面,并立刻封装到一个TCP报文段中进行发送。紧急指针会指出本报文段数据载荷部分包含了多长的紧急数据,紧急数据之后是普通数据。
- 填充:由于选项的长度可变,因此使用填充来确保报文段首部能被4整除(因为数据偏移字段,也就是首部长度字段,是以4字节为单位的)
- 选项:是TCP报文段功能可以拓展,有以下几个:
- (1)最大报文段长度MSS选项: TCP报文段数据载荷部分的最大长度。
- (2)窗口扩大选项:为了扩大窗口(提高吞吐率)
- (3)时间戳选项:用来计算往返时间RTT用于处理序号超范围的情况,又称为防止序号绕回PAWS。
2.4TCP三次握手(建立连接)
2.4.1TCP为了保证连接的可靠性,每次都会通过进行三次握手来建立可靠的连接
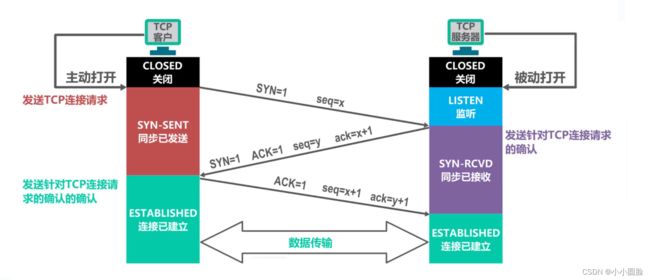
- 第一步:客户端的TCP首先向服务器端的TCP发送一个特殊的TCP报文段。该报文段中不包含应用层数据。但是在报文段的首部中的一个标志位(即SYN比特)被置为1。因此,这个特殊报文段被称为SYN报文段。另外,客户会随机地选择一个初始序号(seq=x), 并将此编号放置于该起始的TCP SYN报文段的序号字段中。该报文段会被封装在一个IP数据报中,并发送给服务器。
- 第二步:一旦包含TCP SYN报文段的IP数据报到达服务器主机(假定它的确到达了!),服务器会从该数据报中提取出TCP SYN报文段,为该TCP连接分配TCP缓存和变量,并向该客户TCP发送允许连接的报文段。( 在完成三次握手的第三步之前分配这些缓存和变量,使得TCP易于受到称为SYN洪泛的拒绝服务攻击。)这个允许连接的报文段也不包含应用层数据。但是,在报文段的首部却包含3个重要的信息。首先,SYN比特被置为1。其次,该TCP报文段首部的确认号字段ack被置为x+1。最后,服务器选择自己的初始序号(seq=y),并将其放置到TCP报文段首部的序号字段中。这个允许连接的报文段实际上表明了:“我收到了你发起建立连接的SYN分组,该分组带有初始序号client_ isn。我同意建立该连接。我自己的初始序号是y。" 该允许连接的报文段被称为SYNACK报文段( SYNACK segment)。
- 第三步:在收到SYNACK报文段后,客户也要给该连接分配缓存和变量。客户主机则向服务器发送另外一个报文段;这最后一个报文段对服务器的允许连接的报文段进行了确认ack(该客户过将值y+1放置到TCP报文段首部的确认字段中来完成此项工作)。因为连接已经建立了,所以该SYN比特被置为0。该三次握手的第三个阶段可以在报文段负载中携带客户到服务器的数据。
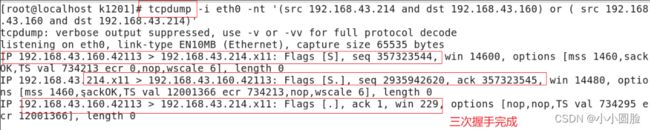
2.4.2使用tcpdump命令抓包查看建立过程
在Ubuntu下使用命令 tcpdump 可以抓包观察 TCP 连接的建立与关闭。该命令需要管理员权限,格式如下(假设两个测试用的主机 IP 地址为 192.168.43.214 和 192.168.43.160 ) :
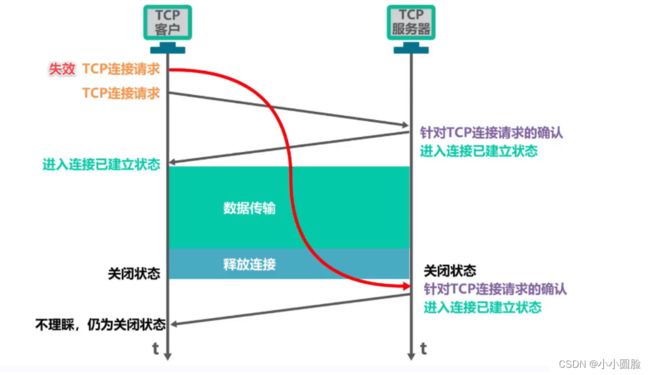
2.5两次握手是否可以?(面试题)
不可以
假定客户端向服务器发送了一个建立连接的请求(SYN报文段),但是由于某种原因没有按时到达服务器端;基于TCP协议超时重传机制,客户端第二次发送建立连接的SYN报文段,服务器收到之后,对客户端发送的SYN报文段进行确认,如上面说的三次握手的第二步;此时我们已经完成连接(两次握手)进行数据传输等等直到最后关闭连接;此时处于关闭状态的服务器收到了客户端发送的第一条SYN报文段(建立连接),服务器对其进行回应(进入连接已建立阶段)但是客户端已经关闭(服务器并不知道)所以服务器端一直进行重传期望得到客户端的数据;过程如图所示:
2.5TCP四次挥手(释放连接)
2.5.1TCP使用四次挥手进行断开连接;
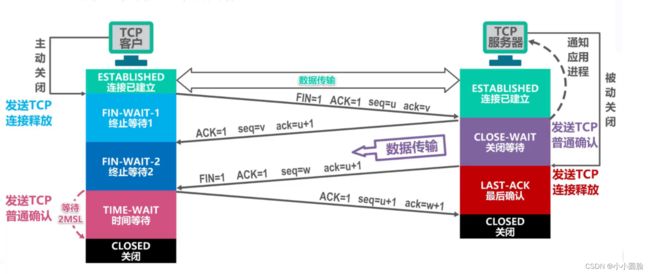
- 第一步:客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
- 第二步:服务器收到连接释放报文,发出确认报文,ACK=1,确认序号为 u+1,并且带上自己的序列号seq=v,此时服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
- 第三步:客户端收到服务器的确认请求后,此时客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最终数据)
- 第四步:服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,确认序号为u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
- 第五步:客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,确认序号为w+1,而自己的序列号是u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
- 第六步:服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
- MSL最长报文段寿命,RFC793建议为2分钟;(现在的网络可能更短);
2.5.2使用tcpdump命令抓包查看断开连接过程

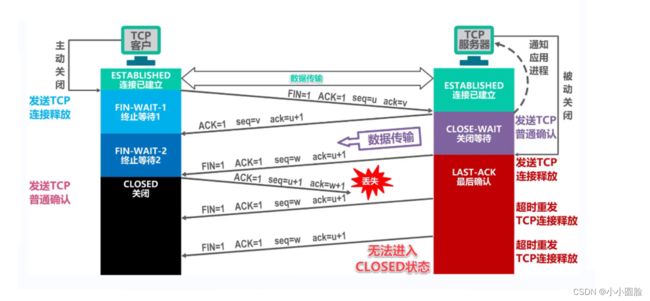
2.5.3TIME-WAIT时间是否多余,为什么?(面试问题)
答案是不多多余;
如图,假设取消了TIME-WAIT时间,当客户端的发送确认报文段,因为没有TIME_WAIT时间,所以此时客户端直接关闭;如果客户端发送的确认报文段丢失,如图所示,则服务器端将一直等待客户端的确认报文,进行不停的重传,一直无法关闭;
2.5.4是否可以强制使用被处于TIME_WAIT状态的连接占用的socket地址?怎样实现?(面试)
可以;服务器程序可以通过设置socket选项SO_REUSEADDR来强制使用被处于TIME_WAIT状态的连接占用的socket地址。
int sock = socket( PF_INET,SOCK_ STREAM,0 ) ;
assert( sock >= 0 );
int reuse = 1;
setsockopt( sock, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse)) ;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
inet_pton( AF_INET, ip, &address.sin_addr ) ;
address.sin port=htons(port );
int ret = bind( sock, ( struct sockaddr* ) &address, sizeof(address));2.6TCP连接时SYN泛洪攻击
我们在TCP三次握手的讨论中已经看到,服务器为了响应一个收到的SYN,分配并初始化连接变量和缓存。然后服务器发送一个SYNACK进行响应,并等待来自客户的ACK报文段。如果某客户不发送ACK来完成该三次握手的第三步,最终(通常在一分多钟之后)服务器将终止该半开连接并回收资源。这种TCP连接管理协议为经典的DoS攻击即SYN洪泛攻击(SYN flood attack) 提供了环境。在这种攻击中,攻击者发送大量的TCP SYN报文段,而不完成第三次握手的步骤。随着这种SYN报文段纷至沓来,服务器不断为这些半开连接分配资源( 但从未使用),导致服务器的连接资源被消耗殆尽。这种SYN洪泛攻击是被记载的众多DoS 攻击中的第一种[CERTSYN 1996]。幸运的是,现在有一种有效的防御系统,称为SYNcookie [ RFC 4987],它们被部署在大多数主流操作系统中。SYN cookie 以下列方式工作:
- 1、当服务器接收到一个SYN报文段时,它并不知道该报文段是来自一个合法的用,户,还是一个SYN洪泛攻击的一部分。因此服务器不会为该报文段生成一个半开连接。相反,服务器生成一个初始TCP序列号,该序列号是SYN报文段的源和目的IP地址与端口号以及仅有该服务器知道的秘密数的一个复杂函数(散列函数)。这种精心制作的初始序列号被称“cookie!”。 服务器则发送具有这种特殊初始序列号的SYNACK分组。重要的是,服务器并不记忆该cookie或任何对应于SYN的其他状态信息。
- 2、如果客户是合法的,则它将返回一个ACK报文段。当服务器收到该ACK,需要验证该ACK是与前面发送的某些SYN相对应的。如果服务器没有维护有关SYN报文段的记忆,这是怎样完成的呢?正如你可能猜测的那样,它是借助于cookie来做到的。前面讲过对于一个合法的ACK,在确认字段中的值等于在SYNACK字段(此时为cookie值)中的值加1。服务器则将使用在SYNACK报文段中的源和目的地IP地址与端口号( 它们与初始的SYN中的相同)以及秘密数运行相同的散列函数。如果该函数的结果加1与在客户的SYNACK中的确认(cookie)值相同的话,服务器认为该ACK对应于较早的SYN报文段,因此它是合法的。服务器则生成一个具有套接字的全开的连接。
- 3、在另一方面,如果客户没有返回一个ACK报文段,则初始的SYN并没有对服务器产生危害,因为服务器没有为它分配任何资源。
2.7TCP中保活计时器作用

如图所示 当TCP客户端出现故障时,TCP服务器如何发现?
使用保活计时器;
- (1)TCP服务器进程每收到一次TCP客户进程数据,就重新设置并启动保活计时器(2小时定时);
- (2)若保活计时器定时周期内未收到TCP客户进程发来的数据,则保活计时器到时后,TCP服务器进程就向TCP客户端发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文段仍无TCP客户进程响应,TCP服务器进程就认为TCP客户进程所在主机出了故障,接着就关闭这个连接;
2.8用状态图表示TCP建立与断开

客户TCP开始时处于CLOSED (关闭)状态。客户的应用程序发起一个新的TCP连接。这引起客户中的TCP向服务器中的TCP发送一个SYN报文段。在发送过SYN报文段后,客户TCP进入了SYN_SENT状态。当客户TCP处在SYN_ SENT 状态时,它等待来自服务器TCP的对客户所发报文段进行确认且SYN比特被置为1的一个报文段。收到这样一个报文段之后,客户端进入TCESTABLISHED (已建立)状态。当处在ESTABLISHED状态时,TCP客户就能发送和接收包含有效载荷数据(即应用层产生的数据)的TCP报文段了。
假设客户应用程序决定要关闭该连接。(注意到服务器也能选择关闭该连接。)这引起客户TCP发送一个带有FIN比特被置为1的TCP报文段,并进入FIN_WAIT_1状态。当处在FIN_WAIT1状态时,客户TCP等待一个来自服务器的带有确认的TCP报文段。当它收到该报文段时,客户TCP进入FIN _WAIT 2状态。当处在FIN_WAIT 2状态时,客户等待来自服务器的FIN比特被置为1的另一个报文段;当收到该报文段后,客户TCP对服务器的报文段进行确认,并进入TIME_ WAIT状态。假定ACK丢失,TIME_WAIT 状态使TCP客户重传最后的确认报文。在TIME_ WAIT 状态中所消耗的时间是与具体实现有关的,而典型的值是30秒、1分钟或2分钟。经过等待后,连接就正式关闭,客户端所有资源(包括端口号)将被释放。
2.8TCP流量控制
我们知道一条TCP连接的每一侧主机都为该连接设置了接收缓存。当该TCP连接收到正确、按序的字节后,它就将数据放入接收缓存。相关联的应用进程会从该缓存中读取数据,但不必是数据刚一到达就立即读取。事实上,接收方应用也许正忙于其他任务,甚至要过很长时间后才去读取该数据。如果某应用程序读取数据时相对缓慢,而发送方发送得太多、太快,发送的数据就会很容易地使该连接的接收缓存溢出。
因此TCP为它的应用程序提供了流量控制服务( flow-control service) 以消除发送方使接收方缓存溢出的可能性。流量控制因此是一个速度匹配服务,即发送方的发送速率与接收方应用程序的读取速率相匹配。TCP发送方也可能因为IP网络的拥塞而被遏制;这种形式的发送方的控制被称为拥塞控制,即使流量控制和拥塞控制采取的动作非常相似(对发送方的遏制),但是它们显然是针对完全不同的原因而采取的措施。
TCP通过让发送方维护一个称为接收窗口( receive window)的变量来提供流量控制。通俗地说,接收窗口用于给发送方一个指示该接收方还有多少可用的缓存空间。因为TCP是全双工通信,在连接两端的发送方都各自维护一个接收窗口。我们在文件传输的情况下研究接收窗口。假设主机A通过一条TCP连接向主机B发送一个大文件。主机B为该连接分配了一个接收缓存,并用RevBuffer来表示其大小。主机B上的应用进程不时地从该缓存中读取数据。我们定义以下变量:
- LastByteRead:主机B上的应用进程从缓存读出的数据流的最后一个字节编号;
- LastByteRcvd:从网络中到达的并且已经放入主机B接收缓存中的数据流的最后一个字节的编号;
由于TCP不允许已分配的缓存溢出,下面公式必须成立:
![]()
接收窗口用rwnd来表示,根据缓存可用空间的数量来设置:
![]()
由于时间和空间是变化的,所以说rwnd是动态的。
主机B通过把当前的rwnd值放人它发给主机A的报文段接收窗口字段中,通知主机A它在该连接的缓存中还有多少可用空间。开始时,主机B设定rwnd =RcvBuffer。为了实现这点,主机B必须跟踪几个与连接有关的变量主机A轮流跟踪两个变量,LastByteSent 和LastByteAcked,这两个变量的意义很明显。注意到这两个变量之间的差LastByteSent E LastByteAcked,就是主机A发送到连接中但未被确认的数据量。通过将未确认的数据量控制在值rwnd以内,就可以保证主机A不会使主机B的接收缓存溢出。因此,主机A在该连接的整个生命周期须保证:
![]()
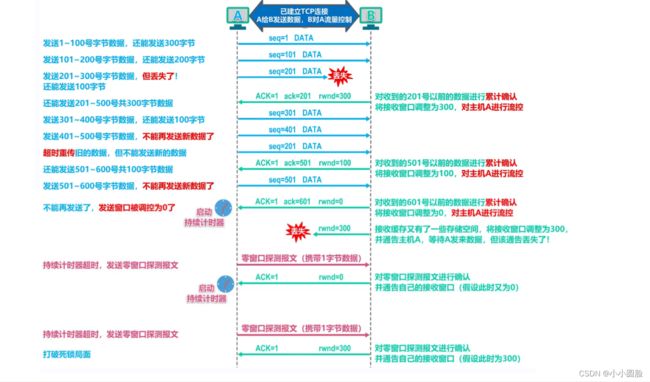
那么假设主机B的接收缓存已经存满,使得rwnd=0。在将rwnd=0通告给主机A之后,还要假设主机B没有任何数据要发给主机A。此时,考虑会发生什么情况。因为主机B上的应用进程将缓存清空,TCP并不向主机A发送带有rwnd新值的新报文段;事实上,TCP仅当在它有数据或有确认要发时才会发送报文段给主机A。这样主机A不可能知道主机B的接收缓存已经有新的空间了,即主机A被阻塞而不能再发送数据!
为了解决这个问题,TCP规范中要求:当主机B的接收窗口为0时,主机A继续发送只送一个字节数据的报文段。这些报文段将会被接收方确认。最终缓存将开始清空,并且确认报文里将包含一个非0的rwnd值;
如图所示 假设主机A主机B发送如下报文段;

则按照上面我们所说的那样,有如下图所示的过程:
2.9TCP的拥塞控制
2.9.1从三个方面来说明出现拥塞的原因以及拥塞的代价(书上讲解);
情况一:两个发送方和一台具有无穷大缓存的路由器;
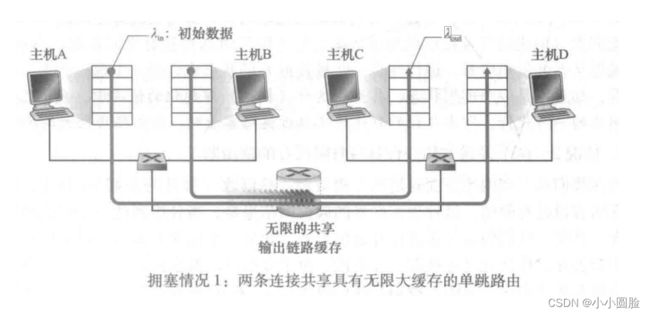 我们假设主机A中的应用程序以λn字节/秒的平均速率将数据发送到连接中(例如、通过一个套接字将数据传递给运输层协议)。这些数据是初始数据,这意味着每个数据单元仅向套接字中发送一次。下面的运输层协议是一个简单的协议。数据被封装并发送;不执行差错恢复(如重传)、流量控制或拥塞控制。忽略由于添加运输层和较低层首部信息产生的额外开销,在第一 种情况下,主机A向路由器提供流量的速率是λn字节/秒。主机B也以同样的方式运行,为了简化问题,我们假设它也是以速率λin字节/秒发送数据。来自主机A和主机B的分组通过一台路由器,在一.段容量为R的共享式输出链路上传输。该路由器带有缓存,可用于当分组到达速率超过该输出链路的容量时存储“人分组”。在此第一种情况下,我们将假设路由器有无限大的缓存空间。
我们假设主机A中的应用程序以λn字节/秒的平均速率将数据发送到连接中(例如、通过一个套接字将数据传递给运输层协议)。这些数据是初始数据,这意味着每个数据单元仅向套接字中发送一次。下面的运输层协议是一个简单的协议。数据被封装并发送;不执行差错恢复(如重传)、流量控制或拥塞控制。忽略由于添加运输层和较低层首部信息产生的额外开销,在第一 种情况下,主机A向路由器提供流量的速率是λn字节/秒。主机B也以同样的方式运行,为了简化问题,我们假设它也是以速率λin字节/秒发送数据。来自主机A和主机B的分组通过一台路由器,在一.段容量为R的共享式输出链路上传输。该路由器带有缓存,可用于当分组到达速率超过该输出链路的容量时存储“人分组”。在此第一种情况下,我们将假设路由器有无限大的缓存空间。
下图描绘出了第一种情况下主机A的连接性能。左边的图形描绘了每连接的吞吐量(per-connection throughput) (接收方每秒接收的字节数)与该连接发送速率之间的函数关系。当发送速率在0~R/2之间时,接收方的吞吐量等于发送方的发送速率,即发送方发送的所有数据经有限时延后到达接收方。然而当发送速率超过R/2时,它的吞吐量只能达R/2。这个吞吐量上限是由两条连接之间共享链路容量造成的。链路完全不能以超过R/2的稳定状态速率向接收方交付分组。无论主机A和主机B将其发送速率设置为多高,它们都不会看到超过R/2的吞吐量。
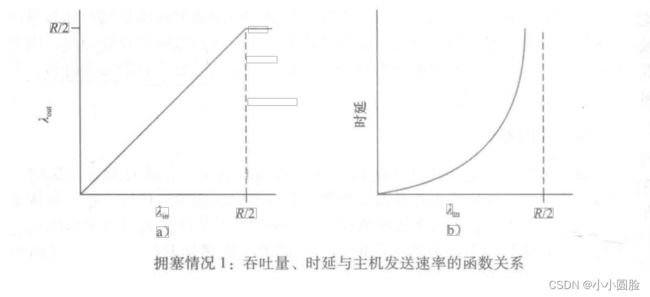 取得每连接R/2的吞吐量实际上看起来可能是件好事,因为在将分组交付到目的地的过程中链路被充分利用了。但是,图b的图形却显示了以接近链路容量的速率运行时产生的后果。当发送速率接近R/2时(从左至右),平均时延就会越来越大。当发送速率超过R/2时,路由器中的平均排队分组数就会无限增长,源与目的地之间的平均时延也会变成无穷大(假设这些连接以此发送速率运行无限长时间并且有无限量的缓存可用)。因此,虽然从吞吐量角度看,运行在总吞吐量接近R的状态也许是一个理想状态,但从时延角度看,却远不是一个理想状态。甚至在这种(极端)理想化的情况中,我们已经发现了拥塞网络的一种代价,即当分组的到达速率接近链路容量时,分组经历巨大的排队时延。
取得每连接R/2的吞吐量实际上看起来可能是件好事,因为在将分组交付到目的地的过程中链路被充分利用了。但是,图b的图形却显示了以接近链路容量的速率运行时产生的后果。当发送速率接近R/2时(从左至右),平均时延就会越来越大。当发送速率超过R/2时,路由器中的平均排队分组数就会无限增长,源与目的地之间的平均时延也会变成无穷大(假设这些连接以此发送速率运行无限长时间并且有无限量的缓存可用)。因此,虽然从吞吐量角度看,运行在总吞吐量接近R的状态也许是一个理想状态,但从时延角度看,却远不是一个理想状态。甚至在这种(极端)理想化的情况中,我们已经发现了拥塞网络的一种代价,即当分组的到达速率接近链路容量时,分组经历巨大的排队时延。
情况二:两个发送方和一台具有有限缓存的路由器
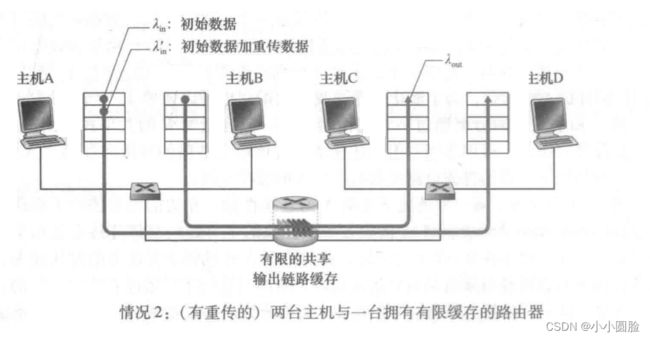
现在我们从下列两个方面对情况1稍微做一些修改。首先,假定路由器缓存的容量是有限的。这种现实世界的假设的结果是,当分组到达一个已满的缓存时会被丟弃。其次,我们假定每条连接都是可靠的。如果一个包含有运输层报文段的分组在路由器中被丢弃,那么它终将被发送方重传。由于分组可以被重传,所以我们现在必须更小心地使用发送速率这个术语。特别是我们再次以λin字节/秒表示应用程序将初始数据发送到套接字中的速率。运输层向网络中发送报文段( 含有初始数据或重传数据)的速率用入:字节/秒表示。λ有时被称为网络的供给载荷(ofered load)。
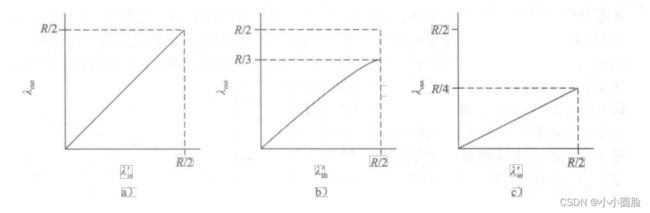
首先,考虑一种不真实的情况,即主机A能够以某种方式(不可思议地!)确定路由器中的缓存是否空闲,因而仅当缓存空闲时才发送一个分组。在这种情况下,将不会产生丢包,λin与λin'相等,并且连接的吞吐量就等于λin。下图a中描述了这种情况。从吞吐量的角度看,性能是理想的,即发送的每个分组都被接收到。注意到在这种情况下,平均主机发送速率不能超过R/2,因为假定不会发生分组丢失。
接下来考虑一种更为真实的情况,发送方仅当在确定了一个分组已经丢失时才重传。(同样,所做的假设有一些弹性。然而,发送主机有可能将超时时间设置得足够长,以无形中使其确信一个还没有被确认的分组已经丢失。)在这种情况下,性能就可能与下图b所示的情况相似。为了理解这时发生的情况,考虑一下供给载荷λ'in(初始数据传输加上重传的总速率)等于R/2的情况。根据下图b,在这一供给载荷值时,数据被交付给接收方应用程序的速率是R/3。因此,在所发送的0.5R单位数据当中,从平均的角度说,0. 333R字节/秒是初始数据,而0.166R字节/秒是重传数据。我们在此看到了另一种网络拥塞的代价,即发送方必须执行重传以补偿因为缓存溢出而丢弃(丢失)的分组。最后,我们考虑下面一种情况:发送方也许会提前发生超时并重传在队列中已被推迟但还未丢失的分组。在这种情况下,初始数据分组和重传分组都可能到达接收方。当然,接收方只需要一份这样的分组副本就行了,重传分组将被丢弃。在这种情况下,路由器转发重传的初始分组副本是在做无用功,因为接收方已收到了该分组的初始版本。而路由器本可以利用链路的传输能力去发送另一个分组。这里,我们又看到了网络拥塞的另一种代价,即发送方在遇到大时延时所进行的不必要重传会引起路由器利用其链路带宽来转发不必要的分组副本。图c 显示了当假定每个分组被路由器转发(平均)两次时,吞吐量与供给载荷的对比情况。由于每个分组被转发两次,当其供给载荷接近R/2时,其吞吐量将渐近R/4。
情况三:4个发送方和具有有限缓存的多台路由器及多跳路径
有4台主机发送分组,每台都通过交叠的两跳路径传输,如图所示。我们再次假设每台主机都采用超时/重传机制来实现可靠数据传输服务,所有的主机都有相同的λ值,所有路由器的链路容量都是R字节/秒。我们考虑从主机A到主机C的连接,该连接经过路由器R1和R2。A-C连接与D-B连接共享路由器R1,并与B-D连接共享路由器R2。对极小的λ值,路由器缓存的溢出是很少见的(与拥塞情况1、拥塞情况2中的一样),吞吐量大致接近供给载荷。对稍大的λ值,对应的吞吐量也更大,因为有更多的初始数据被发送到网络中并交付到目的地,溢出仍然很少。因此,对于较小的λ日,λin的增大会导致λout的增大。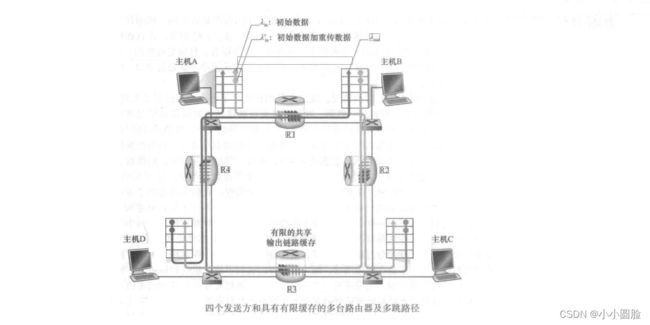
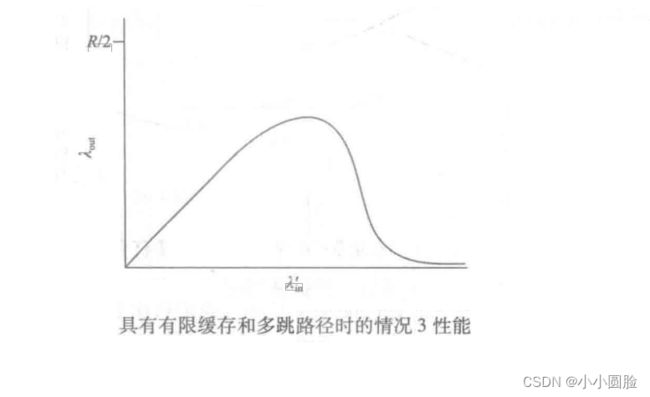
在考虑了流量很小的情况后,下面分析当λin (因此λin')很大时的情况。考虑路由器R2。不管λm的值是多大,到达路由器R2的A-C流量(在经过路由器R1转发后到达路由器R2)的到达速率至多是R,也就是从R1到R2的链路容量。如果λi对于所有连接(包括B-D连接)来说是极大的值,那么在R2上,B-D流量的到达速率可能会比A-C流量的到达速率大得多。因为A-C流量与B-D流量在路由器R2上必须为有限缓存空间而竞争,所以当来自B- D连接的供给载荷越来越大时,A-C连接上成功通过R2 (即由于缓存溢出而未被丢失)的流量会越来越小。在极限情况下,当供给载荷趋近于无穷大时,R2的空闲缓存会立即被B- D连接的分组占满,因而A-C连接在R2上的吞吐量趋近于0。这又一次说明
在重载的极限情况下,A-C端到端吞吐量将趋近于0。这些考虑引发了供给载荷与吞吐量之间
的权衡,如图所示。当考虑由网络所做的浪费掉的工作量时,随着供给载荷的增加而使吞吐量最终减少的原因是明显的。在上面提到的大流量的情况中,每当有一个分组在第二跳路由器上被丢弃时,第一跳路由器所做的将分组转发到第二跳路由器的工作就是“劳而无功”的。如果第一跳路由器只是丢弃该分组并保持空闲,则网络中的情况是幸运的(更准确地说是糟糕的)。需要指出的是,第一跳路由器所使用的将分组转发到第二跳路由器的传输容量用来传送不同的分组可能更有效益。
 从上述知识因此我们可以对拥塞控制的原因进行总结:
从上述知识因此我们可以对拥塞控制的原因进行总结:
- 在某段时间,若对网络中某一资源的需求超过 了该资源所能提供的可用部分,网络性能就要变坏。这种情况就叫做拥塞(congestion)。
- 在计算机网络中的链路容量(即带宽)、交换结点中的缓存和处理机等,都是网络的资源。
- 若出现拥塞而不进行控制,整个网络的吞吐量将随输入负荷的增大而下降。
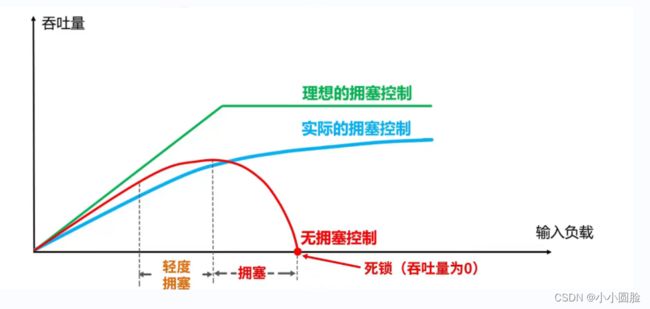
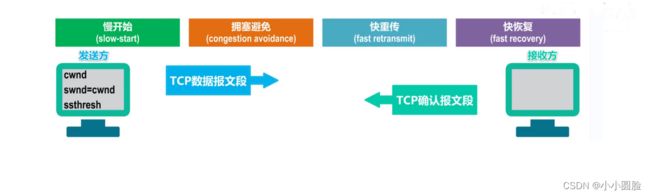
2.9.2拥塞控制方法
四种方法即 慢开始 拥塞避免 快重传 快恢复
- 发送方维护一个叫做拥塞窗口cwnd的状态变量,其值取决于网络的拥塞程度,并且动态变化。
- 拥塞窗口cwnd的维护原则:只要网络没有出现拥塞,拥塞窗口就再增大一些;但只要网络出现拥塞, 拥塞窗口就减少一些。
- 判断出现网络拥塞的依据:没有按时收到应当到达的确认报文(即发生超时重传)。
- 发送方将拥塞窗口作为发送窗口swnd,即swnd = cwnd.
- 维护一个慢开始门限ssthresh状态变量:
- 当cwnd < ssthresh时, 使用慢开始算法;
- 当cwnd > ssthresh时,停止使用慢开始算法而改用拥塞避免算法;
- 当cwnd = ssthresh时,既可使用慢开始算法.也可使用拥寒避免算法;
2.9.3慢开始,拥塞避免
当TCP连接开始时,cwnd的值通常初始置为一个MSS的较小值,这就使得初始发送速率大约为MSS/RTT。例如,如果MSS=500字节且RTT =200ms,则得到的初始发送速率大约只有20kbps。由于对TCP发送方而言,可用带宽可能比MSS/RTT大得多,TCP发送方希望迅速找到可用带宽的数量。
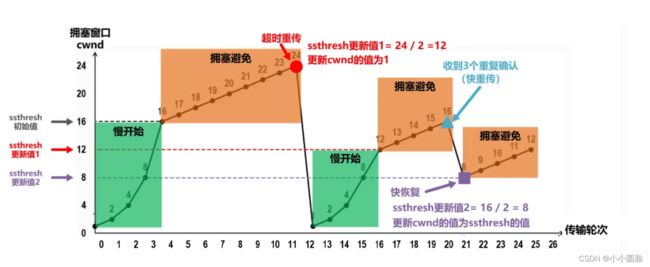
慢启动( slow-start):cwnd的值以1个MSS开始并且每当传输的报文段首次被确认就增加1个MSS。TCP向网络发送第一个报文段并等待一个确认。当该确认到达时,TCP发送方将拥塞窗口增加一个RMSS,并发送出两个最大长度的报文段。这两个报文段被确认,则发送方对每个确认报文段将拥塞窗口增加一个MSS,使得拥塞窗口变为4个MSS,并这样下去。这一过程每过一个RTT,发送速率就翻番。因此,TCP发送速率起始慢,但在慢启动阶段以指数增长。
ssthresh:慢启动阈值;当检测到拥塞时将ssthresh置为拥塞窗口的一半。
拥塞避免模式:继续使cwnd翻番可能有些鲁莽。因此,当cwnd的值等于ssthresh时,结束慢启动并且TCP转移到拥塞避免模式。
假设初始如图所示:
2.9.4快重传和快恢复
- 有时,个别报文段会在网络中丢失,但实际上网络并未发生拥塞。(这将导致发送方超时重传,并误认为网络发生了拥塞;
- 发送方把拥塞窗口cwnd又设置为最小值1,并错误地启动慢开始算法,因而降低了传输效率。
采用快重传算法可以让发送方尽早知道发生了个别报文段的丢失。
- 所谓快重传,就是使发送方尽快进行重传,而不是等超时重传计时器超时再重传。
- 要求接收方不要等待自己发送数据时才进行捎带确认,而是要立即发送确认;
- 即使收到了失序的报文段也要立即发出对已收到的报文段的重复确认。
- 发送方一旦收到3个连续的重复确认,就将相应的报文段立即重传,而不是等该报文段的超时重传计时器超时再重传
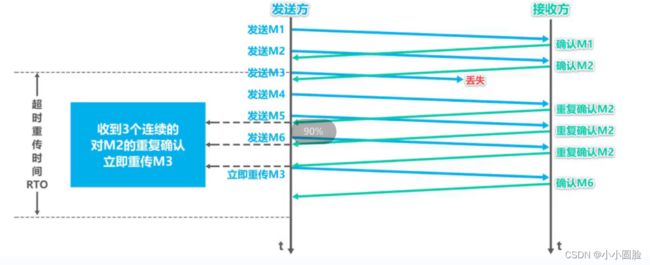
快重传:当出现超时时,TCP的拥塞避免算法行为相同。与慢启动的情况一样,cwnd 的值被设置为1个MSS,当丢包事件出现时,ssthresh 的值被更新为cwnd值的一半。然而,前面讲过丢包事件也能由一个三个冗余ACK事件触发。在这种情况下,网络继续从发送方向接收方交付报文段( 就像由收到冗余ACK所指示的那样)。因此TCP对这种丢包事件的行为,相比于超时指示的丢包,应当不那么剧烈:TCP 将cwnd的值减半( 为使测量结果更好,计及已收到的3个冗余的ACK要加上3个MSS),并且当收到3个冗余的ACK,将ssthresh的值记录为cwnd的值的一半。 接下来进入快速恢复状态。
快恢复:在快速恢复中,对于引起TCP进人快速恢复状态的缺失报文段,对收到的每个冗余ACK, cwnd 的值增加一个MSS。最终,当对丢失报文段的一个ACK到达时,TCP在降低cwnd后进人拥塞避免状态。如果出现超时事件,快速恢复在执行如同在慢启动和拥塞避免中相同的动作后,迁移到慢启动状态:当丢包事件出现时,cwnd 的值被设置为1个MSS,并且ssthresh的值设置为cwnd值的一半。快速恢复是TCP推荐的而非必需的构件。一种称为TCPTahoe的TCP早期版本,不管是发生超时指示的丟包事件,还是发生3个冗余ACK指示的丢包事件,都无条件地将其拥塞窗口减至1个MSS,并进人慢启动阶段。TCP的较新版本TCP Reno,则综合了快速恢复。
2.10TCP超时重传的时间选择
2.10.1超时重传时间的极端情况
我们知道TCP协议采用超时/重传机制来处理报文段的丢失问题。尽管这在概念上简单,但是当在如TCP这样的实际协议中实现超时/重传机制时还是会产生许多微妙的问题。
RTT:报文段的样本RTT就是从某报文段被发出(即交给IP)到对该报文段的确认被收到之间的时间量。
情况一:RTO(超时重传时间)小于RTT时间,如图所示,则会出现不必要重传报文;

情况二:RTO(超时重传时间)远大于RTT时间,如图所示,则会出现重传报文时间太长,使得网络空闲时间增大;
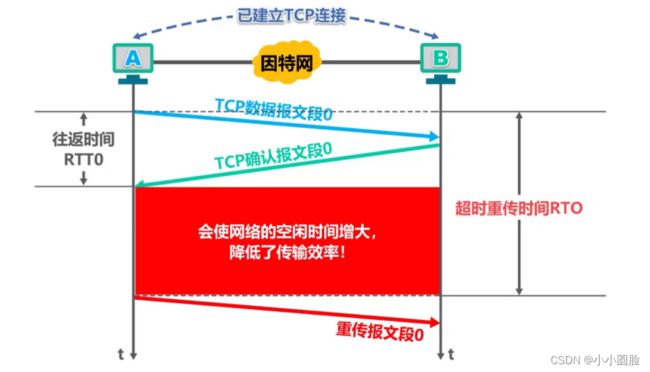
问题:这个时间间隔到底应该是多大呢?刚开始时应如何估计往返时间呢?是否应该为所有未确认的报文段各设一个定时器?
2.10.1往返时间的估计与超时
大多数TCP的实现仅在某个时刻做一次RTTs(样本RTT)测量,而不是为每个发送的报文段测量一个RTTs。这就是说,在任意时刻,仅为一个已发送的但目前尚未被确认的报文段估计RTTs,从而产生一个接近每个RTT的新RTTs值。另外,TCP 决不为已被重传的报文段计算RTTs;它仅为传输一次的报文段测量。
由于路由器的拥塞和端系统负载的变化,这些报文段的RTTs值会随之波动。由于这种波动,任何给定的RTTs值也许都是非典型的。因此,为了估计一个典型的RTT,采取某种对RTTs取平均的办法。TCP维持一个RTTs均值。一旦获得一个新RTTs时,TCP就会根据下列公式来更新RTT:

- 若a很接近于0,则新RTT样本对RTTs的影响不大;
- 若a很接近于1,则新RTT样本对RTTs的影响较大;
RTT的新值是由以前的RTT值与RTT新值加权组合而成的。在[ RFC 6298]中给出的a推荐值是α=0.125 (即1/8);
RFC6298建议使用下式计算超时重传时间RTO:
![]()

我们可以看出不管是RTTs还是RTTd都与新的RTT样本有关系;但是又出现了以下两种情况如图:
情况一:源主机若误将确认当做对原报文段的确认,计算出来的RTTs和RTO就会偏大,降低了传输效率;
情况二:源主机若误将确认当做是对重传报文段的确认;计算出来的RTTs和RTO就会偏小,导致报文段没必要的重传,增加网络负荷;
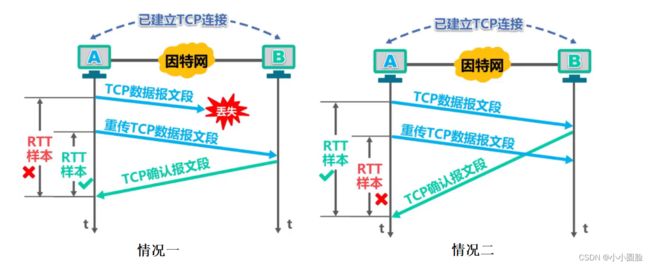
针对出现超时重传时无法测准往返时间RTT的问题,Karn提出了一个算法:
在加权平均往返时间RTTs时,只要报文段重传了,就不采用其往返时间RTT样本。也就是出现重传时,不重新计算RTTs,进而超时重传时间RTO也不会重新计算。
这又引起了新的问题。设想出现这样的情况:报文段的时延突然增大了很多,并且之后很长一段时间都会保持这种时延。因此在原来得出的重传时间内,不会收到确认报文段。于是就重传报文段。但根据Karn算法,不考虑重传的报文段的往返时间样本。这样,超时重传时间就无法更新。这会导致报文段反复被重传。
因此,要对Karn算法进行修正。方法是:
报文段每重传一次,就把超时重传时间RTO增大些。典型的做法是将新RTO的值取为旧RTO值的2倍。
2.11TCP总结
虽然发送方的发送窗口是根据接收方的接收窗口设置的,但在同一时刻,发送方的发送窗口并不总是和接收方的接收窗口一样大。
- 网络传送窗口值需要经历一定的时间滞后,并且这个时间还是不确定的。
- 发送方还可能根据网络当时的拥塞情况适当减小自己的发送窗口尺寸。
对于不按序到达的数据应如何处理,TCP并无明确规定。
- 如果接收方把不按序到达的数据一律丢弃, 那么接收窗口的管理将会比较简单,但这样做对网络资源的利用不利,因为发送方会重复传送较多的数据。
- TCP通常对不按序到达的数据是先临时存放在接收窗口中, 等到字节流中所缺少的字节收到后,再按序交付上层的应用进程。
TCP要求接收方必须有累积确认和捎带确认机制,这样可以减小传输开销。接收方可以在合适的时候发送确认,也可以在自己有数据要发送时把确认信息顺便捎带上。
- 接收方不应过分推迟发送确认, 否则会导致发送方不必要的超时重传,这反而浪费了网络的资源。TCP标准规定,确认推迟的时间不应超过0.5秒。若收到-连串具有最大长度的报文段,则必须每隔一个报文段就发送一个确认。
- 捎带确认实际上并不经常发生, 因为大多数应用程序很少同时在两个方向 上发送数据。
TCP的通信是全双工通信。通信中的每一方都在发送和接收报文段。因此,每一方都有自己的发送窗口和接收窗口。在谈到这些窗口时,一定要弄清楚是哪一方的窗口。
TCP之socket编程(c++实现代码)
TCP编程流程
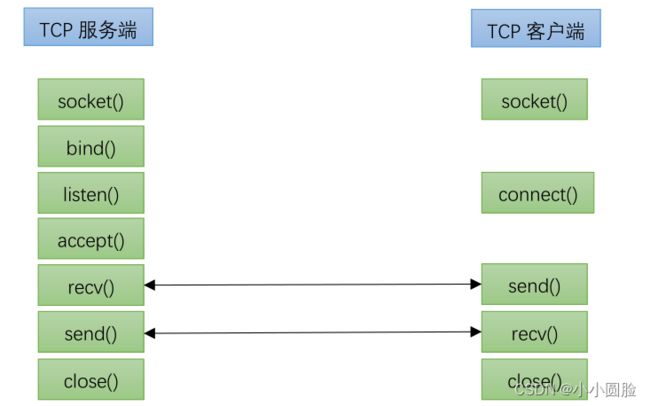
- socket():socket()方法是用来创建一个套接字,有了套接字就可以通过网络进行数据的收发。这也是为什么进行网络通信的程序首先要创建一个套接字。创建套接字时要指定使用的服务类型,使用 TCP 协议选择流式服务(SOCK_STREAM)。
- bind():bind()方法是用来指定套接字使用的 IP 地址和端口。IP 地址就是自己主机的地址,如果主机没有接入网络,测试程序时可以使用回环地址“127.0.0.1”。端口是一个 16 位的整形值,一般 0-1024 为知名端口,如 HTTP 使用的 80 号端口。这类端口一般用户不能随便使用。其次,1024-4096 为保留端口,用户一般也不使用。4096 以上为临时端口,用户可以使用。在Linux 上,1024 以内的端口号,只有 root 用户可以使用。
- listen():listen()方法是用来创建监听队列。监听队列有两种,一个是存放未完成三次握手的连接,一种是存放已完成三次握手的连接。listen()第二个参数就是指定已完成三次握手队列的长度。
- accept():accept()处理存放在 listen 创建的已完成三次握手的队列中的连接。每处理一个连接,则accept()返回该连接对应的套接字描述符。如果该队列为空,则 accept 阻塞。
- connect():connect()方法一般由客户端程序执行,需要指定连接的服务器端的 IP 地址和端口。该方法执行后,会进行三次握手, 建立连接。
- send():send()方法用来向 TCP 连接的对端发送数据。send()执行成功,只能说明将数据成功写入
- 到发送端的发送缓冲区中,并不能说明数据已经发送到了对端。send()的返回值为实际写入到发送缓冲区中的数据长度。
- recv():recv()方法用来接收 TCP 连接的对端发送来的数据。recv()从本端的接收缓冲区中读取数据,如果接收缓冲区中没有数据,则 recv()方法会阻塞。返回值是实际读到的字节数,如果recv()返回值为 0, 说明对方已经关闭了 TCP 连接。
- close():close()方法用来关闭 TCP 连接。此时,会进行四次挥手。
客户端
tcpclient.h/tcpclient.cc
#ifndef __TCP_CLIENT__H__
#define __TCP_CLIENT__H__
#include
class TcpClient {
private:
int m_sfd; // server fd
public:
TcpClient(const IpAddressPort&);
~TcpClient();
int SendMsg(const std::string& msg);
Msg RecvMsg();
int GetSfd() const;
};
#endif #include "tcpClient.h"
// linux api的
#include
#include
#include
#include
#include
// c标准库的
#include // #include
TcpClient::TcpClient(const IpAddressPort& ipAddressAndPort) {
// tcp
m_sfd = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == m_sfd) {
LOG_FATAL << strerror(errno);//自己实现的日志文件
}
struct sockaddr_in ser;
// 本机字节序 -》 网络字节序
// intel 小端模式 -》 网络字节序 大端模式
ser.sin_family = AF_INET;
ser.sin_port = htons(ipAddressAndPort.GetPort());
ser.sin_addr.s_addr = inet_addr(ipAddressAndPort.GetIpAddress().c_str());
if (-1 == connect(m_sfd, (struct sockaddr*)&ser, sizeof(ser))) {
LOG_FATAL << strerror(errno);
}
LOG_INFO << "connect success!";
}
TcpClient::~TcpClient() {
if (-1 == close(m_sfd)) {
// log_fatal
LOG_FATAL << strerror(errno);
}
}
int TcpClient::SendMsg(const std::string& msg) {
// send
int numberOfSendByte = send(m_sfd, msg.c_str(), strlen(msg.c_str()), 0);
if (-1 == numberOfSendByte) {
LOG_ERROR << strerror(errno);
}
return numberOfSendByte;
}
// 怎么返回多个返回值
Msg TcpClient::RecvMsg() {
// recv api
char buf[LARGE_BUF_LEN] = {0};
int numberOfRecvByte = recv(m_sfd, buf, LARGE_BUF_LEN, 0);
if (-1 == numberOfRecvByte) {
LOG_ERROR << strerror(errno);
}
// c风格
// struct Msg {
// std::string m_msg;
// int m_numberOfRecvBytes;
// Msg(std::string msg, int numberOfRecvBytes) : m_msg(msg),
// m_numberOfRecvBytes(numberOfRecvBytes) {}
// std::string ToString() const {
// std::stringstream ss;
// ss << "[recmsg:" << m_msg << "], [numberOfByte:" << m_numberOfRecvBytes << "]";
// return ss.str();
// }
// };
// return Msg{.m_msg = buf, .m_numberOfRecvBytes = numberOfRecvByte};
return Msg{buf, numberOfRecvByte};
}
int TcpClient::GetSfd() const {
return m_sfd;
} 服务器端
tcpserver.h/tcpserver.cc
#ifndef __TCP_SERVER__H__
#define __TCP_SERVER__H__
#include
class TcpServer {
private:
int m_lfd;
public:
TcpServer(const IpAddressPort&);
~TcpServer();
int Accept();
int SendMsg(int cfd, const std::string& msg);
Msg RecvMsg(int cfd);
int GetLfd() const;
};
#endif #include "tcpServer.h"
#include "msg.h"
#include
#include
#include
#include
#include
#include
#include
// socket bind listen fd->(ip+port)
TcpServer::TcpServer(const IpAddressPort& ipAddressAndPort) {
m_lfd = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == m_lfd) {
LOG_FATAL << strerror(errno);
}
struct sockaddr_in ser;
ser.sin_family = AF_INET;
// 主机字节序 -》 网络字节序
ser.sin_addr.s_addr = inet_addr(ipAddressAndPort.GetIpAddress().c_str());
ser.sin_port = htons(ipAddressAndPort.GetPort());
if (-1 == bind(m_lfd, (struct sockaddr*)&ser, sizeof(ser))) {
LOG_FATAL << strerror(errno);
}
if (-1 == listen(m_lfd, 5)) {
LOG_FATAL << strerror(errno);
}
}
// close
TcpServer::~TcpServer() {
if (-1 == close(m_lfd)) {
LOG_FATAL << strerror(errno);
}
}
// 从全连接队列中获取一个完成三次握手的cfd
int TcpServer::Accept() {
struct sockaddr_in cli;
socklen_t len = sizeof(cli);
int cfd = accept(m_lfd, (struct sockaddr*)& cli, &len);
if (-1 == cfd) {
LOG_ERROR << strerror(errno);
return -1;
} else {
char clientIpBuf[SMALL_BUF_LEN] = {0};
if (!inet_ntop(AF_INET, &cli.sin_addr, clientIpBuf, SMALL_BUF_LEN)) {
LOG_ERROR << strerror(errno);
} else {
// 数据的转换 网络字节序 -》 本机字节序
std::string clientIp(clientIpBuf);
unsigned short clientPort = ntohs(cli.sin_port);
IpAddressPort ipAddressPort(clientIp, clientPort);
LOG_INFO << ipAddressPort.ToString();
}
}
return cfd;
}
int TcpServer::SendMsg(int cfd, const std::string& msg) {
int numberOfSendByte = send(cfd, msg.c_str(), strlen(msg.c_str()), 0);
if (-1 == numberOfSendByte) {
LOG_ERROR << strerror(errno);
}
return numberOfSendByte;
}
Msg TcpServer::RecvMsg(int cfd) {
char buf[LARGE_BUF_LEN] = {0};
int numberOfRecvByte = recv(cfd, buf, LARGE_BUF_LEN, 0);
if (-1 == numberOfRecvByte) {
LOG_ERROR << strerror(errno);
}
return Msg{buf, numberOfRecvByte};
}
int TcpServer::GetLfd() const {
return m_lfd;
}
参考文献
linux高性能服务器开发——前四章
计算机网络自顶而下——第三章
tcp/ip详解卷
计算机网络第五版 谢希仁
计算机网络面经 汇总
参考课程