期末复习--机器学习总结(全)
填空题
- pandas两种核心数据结构:一维数据结构Series,二维数据结构DataFrame
- 回归 可用于预测连续的目标变量,分类 可用于预测离散的目标变量
- OLAP 是On-Line Analytical Processing 的简称,称联机分析处理。被OLAP被看作一种广义的数据挖掘方法,旨在简化和支持联机分析。
- 常见的分类算法包括: 逻辑回归、决策树、神经网络、KNN、支持向量机、贝叶斯
- 数据挖掘任务主要集中在 回归、分类、预测、关联、聚类、异常检测 6个方面,前3个是 预测性 ,后3个是 描述性
- 聚类可分为 层次聚类、划分聚类、基于密度的聚类、基于网格的聚类
- 机器学习处理问题分为监督学习 和 无监督学习
- 分类问题的基本流程分为训练和预测两个阶段
- 岭回归和Lasso回归的出现是为解决线性回归中出现的非满秩矩阵求解问题和过拟合问题,通过在损失函数中添加了正则化项实现、
- 关联规则的挖掘过程:找出所有的高频项目组,这些高频项目组中产生关联规则
- 协同过滤推荐算法分为两类:基于用户 的协同过滤算法,基于物品 的协同过滤算法
简答题
数据挖掘的定义?
数据挖掘是指从大量的、随机的、不完全的、有噪声的、模糊的应用数据中,提取出潜在有价值的信息,该过程自动完成,信息的表现形式可以为规则、概念、模型、模式等。
知识发现的过程?
- 确定知识发现的目标
- 数据采集
- 数据探索
- 数据预处理
- 数据挖掘(模型选择)
- 模式评估
回归的概念,一元回归、多元回归的区分
回归分析是确定两种或两种以上的变量间相互依赖的定量关系的一种统计分析方法。
- 如果回归分析只包括一个自变量和一个因变量,且两者的关系可以用一条直线进行拟合,则称为一元回归。
- 如果回归分析包括两个或两个以上的自变量,且自变量之间存在线性相关,则称为多重线性回归分析。
机器学习框架的步骤与代码,数据集可以选择鸢尾花(IRIS),模型可以选择支持向量机(SVM)
- 数据的加载
- 模型的选择
- 模型的训练
- 模型的评估
- 模型的保存
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn import svm
#数据的加载
data = load_iris().data
target = load_iris().target
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.8,random_state=1)
#模型的选择
model = svm.SVC()
#模型的训练
model.fit(x_train,y_train)
model.predict(x_test)
#模型的评估
model.score(x_test,y_test)
#模型的保存
import pickle
clf = pickle.dumps(model)
使用model.save()保存模型失败,查看svc的属性没有save(),改用pickle来保存。
何谓数据挖掘?它有哪些方面的功能?
从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程称为数据挖掘;(3分)
数据挖掘的功能包括:概念描述、关联分析、分类与预测、聚类分析、趋势分析、孤立点分析以及偏差分析等(3分)
监督学习和无监督学习的定义是什么?分别从监督类学习和无监督类学习中找一类算法的实例应用进行举例说明。
监督学习:从标记的训练数据来推断一个功能的机器学习任务。举例:分类算法,利用分类算法进行垃圾电子邮件的分类。
无监督学习:根据类别未知(没有标记)的训练样本解决模式识别中的各种问题。举例:聚类算法。例如,检索系统中文档的自动分类问题。
列举4种监督式学习算法?
K-近邻算法(k-Nearest Neighbors) (1分)
线性回归(Linear Regression) (1分)
逻辑回归(Logistic Regression) (1分)
支持向量机(1分)
过拟合问题产生的原因有哪些以及解决过拟合的办法有哪些?
产生的原因:
(1)使用的模型比较复杂,学习能力过强。 (1分)
(2)有噪声存在 (1分)
(3)数据量有限 (1分)
解决过拟合的办法:
(1)提前终止(当验证集上的效果变差的时候) (1分)
(2)数据集扩增 (1分)
(3)寻找最优参数 (1分)
为什么有噪声存在会导致过拟合?当噪声数量比例过多,跟正常数据一起训练,得到的模型是正常数据和噪声数据一起决定,放在正常数据进行拟合模型,得不到理想的泛化效果。
什么是降维分析?以及常用的降维算法有哪些?
降维分析是指从高维数据空间到低维数据空间的变化过程,其目的是为了降低时间和空间复杂度,或者是去掉数据集中夹杂的噪声,或者是为了使用较少的特征进行解释,方便我们更好地解释数据以及实现数据的可视化 (3分)
常用的降维算法有:主成分分析,因子分析,独立成分分析 (3分)
Kmeans算法的概念与伪代码
Kmeans是划分聚类的一种,其中K表示子集的数量,means表示均值。算法通过预先设定的k值及每个子集的初始质心对所有的数据点进行划分,并通过划分后的均值迭代优化获得最优的聚类结果。
伪代码:
- 从数据中选取k个对象作为初始簇的中心
- 根据数据到聚类中心的距离,划分每个对象
- 更新聚类中心位置,即计算每个簇中所有对象的质心,将聚类中心移动到质心位置
- 重复2、3的过程
- 直到聚类中心不再发生变化
最小二乘法、梯度下降
支持向量机有哪些优缺点?
优势:
(1)在高维空间非常高效 (1分)
(2)即使在数据维度比样本大的情况下仍然有效 (1分)
(3)在决策函数中使用训练集的子集,因此它也是高效利用内存的 (1分)
缺点:
(1)如果特征数量比样本数量大得多,在选择核函数时要避免过拟合 (1分)
(2)支持向量机通过寻找支持向量找到最优分割平面,是典型的二分类问题,因此无法解决多分类问题。 (1分)
(3)不直接提供概率估计 (1分)
谈谈K近邻算法的优缺点有哪些?
优点:简单,易于理解,易于实现;
只需保存训练样本和标记,无须估计参数,无须训练。
不易受最小错误概率的影响。 (3分)
缺点:K的选择不固定;
预测结果容易受含噪声数据的影响;
当样本不平衡时,新样本的类别偏向于训练样本中数量占优的类别,容易导致预测错误;
具有较高的计算复杂度和内存消耗,因为对每一个未知样本,都要计算它到全体已知样本的距离,才能求得它的K个最近邻。 (3分)
计算题
贝叶斯公式

全概率公式

某地区居民肝癌的发病率为0.0004,现用甲胎蛋白法进行普查。医学研究表明,化验结果是有错检的可能性。已知患有肝癌的人其化验结果99%呈阳性(有病),而没患肝癌的人其化验结果99.9%呈阴性(无病)。现某人的检查结果呈阳性,问他真正得肝癌的概率有多大?如果他第二次复检,仍然呈阳性。请问该患者患肝癌的概率又有多大?
1)假设A={检查结果是阳性},B={此人是肝癌患者},根据已知条件
P(A|B)=0.99,P(A|B-)=0.001,这里B-表示B的对立事件,P(B)=0.0004
那么根据贝叶斯公式,
P(B|A)=(P(B)P(A|B))/(P(B)P(A|B)+P(B-)P(A|B-))
=(0.00040.99)/(0.00040.99+0.9996*0.001)
=0.284
意思是首查结果呈阳性,是乙肝患者概率是28.4%;
2)因为该患者初查已经是阳性,其患病概率P(B)=0.284,如果复查还是阳性,则:
P(B|A)=(P(B)P(A|B))/(P(B)P(A|B)+P(B-)P(A|B-))
=(0.2840.99)/(0.2840.99+0.716*0.001)
=0.997
意思是复查也呈阳性,那么是乙肝患者概率是99.7%
贝叶斯算法

如果一对男女朋友,男生向女生求婚,男生的四个特点分别是不帅,性格不好,身高矮,不上进,请你判断一下女生是嫁还是不嫁?
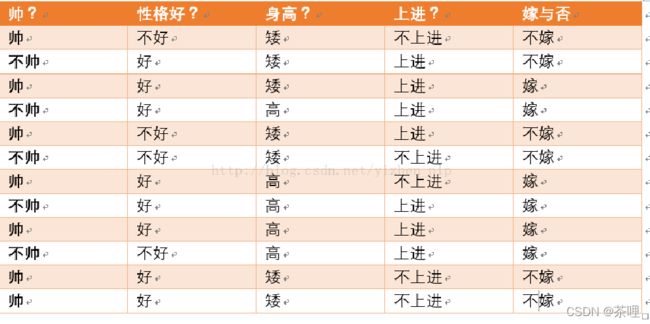 p(嫁) = 6/12(总样本数) = 1/2
p(嫁) = 6/12(总样本数) = 1/2
p(不帅|嫁) = 3/6 = 1/2
p(性格不好|嫁) = 1/6
p(身高矮|嫁) = 1/6
p(不上进|嫁) = 1/6
p(不帅) = 5/12
p(性格不好) = 4/12=1/3
p(身高矮) =7/12
p(不上进) =5/12

= (1/21/61/61/61/2)/(5/121/37/12*5/12)
=0.053
距离计算公式
欧式距离

曼哈顿距离
