利用python进行数据分析-numpy入门
4.1Numpy的ndarray
4.2通用函数:快速的元素级数组函数
4.3利用数组进行数据处理
4.4用于数组的文件输入输出
4.5线性代数
4.6伪随机数生成
4.7示例 随机漫步
-
对于数据分析而言,最关注的功能主要集中在:
-
用于数据整理和清理、子集构造和过滤、转换等快速的矢量化数组运算。
-
常用的数组算法,如排序、唯一化、集合运算等。
-
高效的描述统计和数据聚合/摘要运算。
-
用于异构数据集的合并/连接运算的数据对齐和关系型数据运算。
-
将条件逻辑表述为数组表达式(而不是带有if-elif-else分支的循环)。
-
数据的分组运算(聚合、转换、函数应用等)。
-
- numpy最重要的原因之一,是因为它可以**高效处理大数组的数据**。这是因为:
-
NumPy是在一个连续的内存块中存储数据,独立于其他Python内置对象。NumPy的C语言编写的算法库可以操作内存,而不必进行类型检查或其它前期工作。比起Python的内置序列,NumPy数组使用的内存更少。
-
NumPy可以在整个数组上执行复杂的计算,而不需要Python的for循环。
-
#考察一个一百万整数的数组 和一个等价的py列表:
import numpy as np
my_arr = np.arange(1000000)
my_list = list(range(1000000))
##各个序列分别乘以 2
%time for _ in range(10):my_arr2 = my_arr * 2
Wall time: 24 ms
%time for _ in range(10): my_list2 = [x * 2 for x in my_list]
#基于Numpy算法比纯py快10 - 1000倍 并且使用更少的内存
Wall time: 1.12 s
4.1Numpy的ndarray
- 创建ndarray
- ndarray数据类型
- numpy数组的运算
- 基本的索引和切片
- 切片索引
- bool索引
- 花式索引
- 数组转置和轴对换
创建ndarray
data = np.random.randn(2,3)
data
array([[ 0.6141173 , 0.17961086, 2.03771464],
[ 0.89655866, -0.60078493, -1.27983922]])
data * 10
array([[ 6.14117299, 1.79610856, 20.37714637],
[ 8.96558659, -6.0078493 , -12.79839221]])
data + data
array([[ 1.2282346 , 0.35922171, 4.07542927],
[ 1.79311732, -1.20156986, -2.55967844]])
#sahpe 表示各维度大小元组 dtype 用于说明数组数据类型对象
data.shape
(2L, 3L)
data.dtype
dtype('float64')
data1 = [6,7.5,8,0,1]
arr1 = np.array(data1)
arr1
array([6. , 7.5, 8. , 0. , 1. ])
#嵌套序列 多维数组
data2 = [[1,2,3,4],[5,6,7,8]]
arr2 = np.array(data2)
arr2
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
arr2.ndim
2
arr2.shape
(2L, 4L)
除了np.array之外,还有一些函数可以新建数组。比如,zeros和ones分别可以创建指定长度或形状的全0 | 1 数组 empty可以创建一个没有具体值得数组。要用这些方法创建多维数组,只需要传入一个表示形状的元组即可:
np.zeros(10)
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
np.zeros([3,3])
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
np.empty((2,3,2))
array([[[4.33431578e-316, 2.47032823e-322],
[0.00000000e+000, 0.00000000e+000],
[0.00000000e+000, 8.60952352e-072]],
[[7.12298518e-091, 1.02290495e+166],
[4.29055704e-038, 4.54681480e+174],
[3.99910963e+252, 1.46030983e-319]]])
np.empty会返回全0数组的想法不安全 很多情况下 返回的都是一些未初始化的垃圾值。
ndarray数据类型
arr1 = np.array([1,2,3],dtype = np.float64)
arr2 = np.array([1,2,3],dtype = np.int32)
arr1.dtype
dtype('float64')
arr2.dtype
dtype('int32')
dtype是numpy灵活交互其他系统的源泉之一。多数情况下,直接映射到相应的机器表示,这使得"读写磁盘上的二进制数据流"以及“集成低级语言代码”等工作变得更加简单。数值型dtype的命名方式相同:一个类型名(float或int)后面跟一个用于表示各元素位长的数字。标准的双精度浮点值 需要占用8字节
通常只需要知道你所处理的数据的大致类型是浮点数、复数、整数、布尔值、字符串,还是普通的Python对象即可
当需要控制数据在内存和磁盘中的存储方式时,就得了解如何控制存储类型。

arr = np.array([1,2,3,4,5])
arr.dtype
dtype('int32')
##将一个数组从一个dtype转换成另一个dtype
float_arr = arr.astype(np.float64)
float_arr.dtype
dtype('float64')
#integer <-> float
arr = np.array([3.7,-1.2,-2.6,0.5,12.9,10.1])
arr
array([ 3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
arr.astype(np.int64)
array([ 3, -1, -2, 0, 12, 10], dtype=int64)
#如果某字符串数组表示的全是数字,也可以用astype将其转换为数值形式。
numeric_strings = np.array(['1.25','-9.6','42'],dtype = np.string_)
numeric_strings.astype(float)
array([ 1.25, -9.6 , 42. ])
注意使用numpy.string_类型时,一定要小心,因为numpy的字符串数据是大小固定的,发生截取时,不会发出警告。pandas提供了更多非数值数据的便利的处理方法
int_array = np.arange(10)
calibers = np.array([.22,.270,.357,.363])
int_array.astype(calibers.dtype)
array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
calibers.dtype
dtype('float64')
#可以用简洁类型代码表示dtype
empty_uint32 = np.empty(8,dtype='u4')
empty_uint32
array([3264175145, 1070344437, 343597384, 1070679982, 2267742732,
1071044886, 1511828488, 1071070052], dtype=uint32)
empty_uint32.dtype
dtype('uint32')
调用astype总会创建一个新的数组,即使新的dtype与旧的dtype相同
numpy数组的运算
numpy用户称其为矢量化
arr = np.array([
[1.,2.,3.],
[4.,5.,6.]
])
arr
array([[1., 2., 3.],
[4., 5., 6.]])
arr * arr
array([[ 1., 4., 9.],
[16., 25., 36.]])
arr - arr
array([[0., 0., 0.],
[0., 0., 0.]])
#数组与标量的算术运算会将标量值传播到各个元素
1/arr
array([[1. , 0.5 , 0.33333333],
[0.25 , 0.2 , 0.16666667]])
arr ** 0.5
array([[1. , 1.41421356, 1.73205081],
[2. , 2.23606798, 2.44948974]])
#大小相同的数组之间的比较会生成bool数组
arr2 = np.array([
[0.,4.,1.],
[7.,2.,12.]
])
arr2 > arr1
array([[False, True, False],
[ True, False, True]])
基本的索引和切片
arr = np.arange(10)
arr
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr[5]
5
arr[5:8]
array([5, 6, 7])
arr_slice = arr[5:8]
arr_slice
array([5, 6, 7])
arr_slice[:] = 64
arr
#会给所有值赋值
array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
由于NumPy的设计目的是处理大数据,所以你可以想象一下,假如NumPy坚持要将数据复制来复制去的话会产生何等的性能和内存问题。

arr2d = np.array([
[1,2,3],
[4,5,6],
[7,8,9]
])
arr2d[2]
array([7, 8, 9])
#以下两个等价
arr2d[0][2]
3
arr2d[0,2]
3
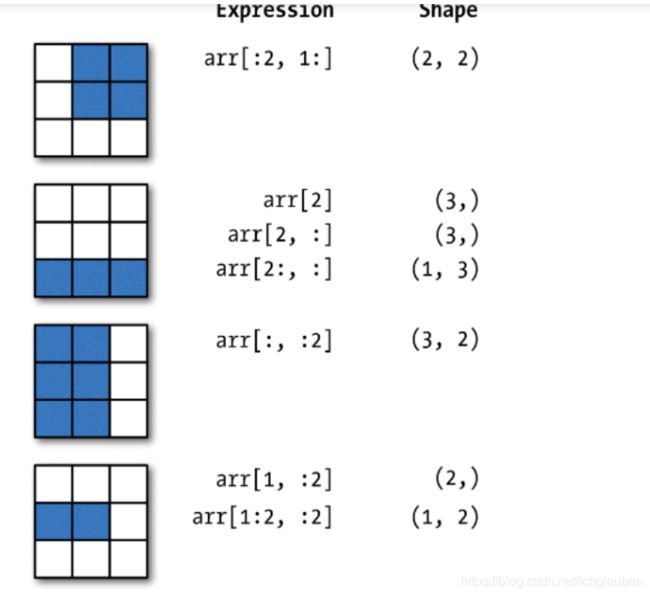
在多维数组中如果省略了后面的索引,返回对象会是一个维度低点的ndarray(含有高一级维度上的所有数据)
arr3d = np.array([
[[1,2,3],
[4,5,6]],
[[7,8,9],
[10,11,12]]
])
arr3d
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])
arr3d[0]#是一个2*3的数组
array([[1, 2, 3],
[4, 5, 6]])
#标量值和数组都可以被赋值给arr3d[0]
old_values = arr3d[0].copy()
arr3d[0] = 55
arr3d
array([[[55, 55, 55],
[55, 55, 55]],
[[ 7, 8, 9],
[10, 11, 12]]])
#相似的 arr3d[1,0]可以访问索引(1,0)开头的那些值(以一维数组的形式返回):
arr3d[1,0]
array([7, 8, 9])
#虽然用两步进行索引 表达式相同:
x = arr3d[1]
x
array([[ 7, 8, 9],
[10, 11, 12]])
x[0]
array([7, 8, 9])
切片索引
arr
array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
arr[1:6]
array([ 1, 2, 3, 4, 64])
#二维数组切片方式
arr2d
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
arr2d[:2]
array([[1, 2, 3],
[4, 5, 6]])
它是沿着第0轴切片的。就是说,切片是沿着一个轴向选取元素的。表达式arr2d[:2]可以被认为是选取 arr2d前两行
arr2d[:2,:2]
array([[1, 2],
[4, 5]])
arr2d[0,0:2]#第一行 第 1 2列
array([1, 2])
arr2d[:,:1]
array([[1],
[4],
[7]])

bool索引
来看这样一个例子,假设我们有一个用于存储数据的数组以及一个存储姓名的数组。在这里,我将使用numpy.random的randn函数生成一些正态分布的随机数据。
names = np.array(['Bob','Joe','Will','Bob','Will','Joe','Joe'])
data = np.random.randn(7,4)# 7 row 4 column
names
array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='|S4')
data
array([[-0.72230465, 0.78196394, 0.4297224 , -0.23100626],
[-0.09260799, 0.97562741, -0.91985061, 2.11889301],
[-0.95422621, -0.10126194, 1.36407324, -0.04231048],
[-1.46019906, 0.25216944, 0.62382515, -1.28653627],
[ 1.73250189, -0.12787307, 1.45648103, 0.71737467],
[ 0.10289804, 1.49219221, 0.43248312, -0.7245715 ],
[-1.43817579, 0.89582166, 1.52649938, -0.32845354]])
假设每个名字都对应data数组中的一行,想要选出对应于名字“Bob”的所有行。跟算术运算一样,数组的比较运算 也是矢量化的。因此,对names和字符串"BOB"的比较运算会产生一个bool型数组
names == 'Bob'
array([ True, False, False, True, False, False, False])
#也可以这样用于数组索引
data[names == 'Will']
array([[-0.95422621, -0.10126194, 1.36407324, -0.04231048],
[ 1.73250189, -0.12787307, 1.45648103, 0.71737467]])
bool数组长度必须跟被索引的轴长度一致。此外,还可以将bool数组跟切片、整数混合使用。
#选取了 names = 'Will' 行 索引了列0 1列
data[names == 'Will',:2]
array([[-0.95422621, -0.10126194],
[ 1.73250189, -0.12787307]])
- 选择除BOB以外的其他值 既可以使用!= 也可以通过~对条件进行否定
names != 'Bob'
array([False, True, True, False, True, True, True])
data[~(names == 'Bob')]
array([[-0.09260799, 0.97562741, -0.91985061, 2.11889301],
[-0.95422621, -0.10126194, 1.36407324, -0.04231048],
[ 1.73250189, -0.12787307, 1.45648103, 0.71737467],
[ 0.10289804, 1.49219221, 0.43248312, -0.7245715 ],
[-1.43817579, 0.89582166, 1.52649938, -0.32845354]])
cond = names == 'Bob'
data[~cond]
array([[-0.09260799, 0.97562741, -0.91985061, 2.11889301],
[-0.95422621, -0.10126194, 1.36407324, -0.04231048],
[ 1.73250189, -0.12787307, 1.45648103, 0.71737467],
[ 0.10289804, 1.49219221, 0.43248312, -0.7245715 ],
[-1.43817579, 0.89582166, 1.52649938, -0.32845354]])
#选取这三个名字中的两个需要组合应用多个bool条件 使用& | 之类的bool算术运算符即可
mask = (names == 'Bob') | (names == 'Will')
mask
array([ True, False, True, True, True, False, False])
data[mask]#选取mask对应的行 1 3 4 5行
array([[-0.72230465, 0.78196394, 0.4297224 , -0.23100626],
[-0.95422621, -0.10126194, 1.36407324, -0.04231048],
[-1.46019906, 0.25216944, 0.62382515, -1.28653627],
[ 1.73250189, -0.12787307, 1.45648103, 0.71737467]])
#将<0的值赋值为0
data[data < 0] = 0
data
array([[0. , 0.78196394, 0.4297224 , 0. ],
[0. , 0.97562741, 0. , 2.11889301],
[0. , 0. , 1.36407324, 0. ],
[0. , 0.25216944, 0.62382515, 0. ],
[1.73250189, 0. , 1.45648103, 0.71737467],
[0.10289804, 1.49219221, 0.43248312, 0. ],
[0. , 0.89582166, 1.52649938, 0. ]])
#通过一维bool数组设置整行或列的值很简单
data[names != 'Joe'] = 7
data
array([[7. , 7. , 7. , 7. ],
[0. , 0.97562741, 0. , 2.11889301],
[7. , 7. , 7. , 7. ],
[7. , 7. , 7. , 7. ],
[7. , 7. , 7. , 7. ],
[0.10289804, 1.49219221, 0.43248312, 0. ],
[0. , 0.89582166, 1.52649938, 0. ]])
花式索引(Fancy indexing)
- 利用整数数组进行索引。假设有一个8*4数组:
arr = np.empty((8,4))
arr.shape
#arr = np.empty((8*4)) 报错 发现是一维数组 敲错代码了!!!!
for i in range(8):# row 0 - 7
for j in range(4):# colum 0 - 3
arr[i,j] = i
arr
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
#为了一特定顺序选取行子集,只需要传入一个用于指定顺序的整数列表或ndarray即可:
arr[[5,7,4,1,0]]
array([[5., 5., 5., 5.],
[7., 7., 7., 7.],
[4., 4., 4., 4.],
[1., 1., 1., 1.],
[0., 0., 0., 0.]])
#使用"-"将会从末尾开始选取行:
arr[[-1,-2,-5]]
array([[7., 7., 7., 7.],
[6., 6., 6., 6.],
[3., 3., 3., 3.]])
arr = np.arange(32).reshape(8,4)
arr
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
arr[[1,5,7,2],[0,3,1,2]]
array([ 4, 23, 29, 10])
arr[[1,5,7,2],:][:,[0,3,1,2]]# 2 6 8 3行 按照 1 4 2 3列排列
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])
arr#花式索引 和 切片不一样 总是将数据复制到新的数组中
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
数组转置和轴对换
- 转置是重塑的一种特殊形式 它返回的是源数据的视图(不会进行任何复制操作) 数组不仅有transpose方法,还有一个特殊的T属性:
arr = np.arange(15).reshape(3,5)
arr
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
arr.T
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])
- 在进行矩阵计算时,经常需要用到该操作 比如利用np.dot计算矩阵内积
arr = np.random.randn(6,3)
arr
array([[-0.74828937, -0.42977691, -0.69217468],
[ 1.04925324, -0.32452027, -0.72236249],
[ 0.51535819, -1.87033518, 1.95841616],
[-0.04133086, 0.64583836, -1.14689452],
[ 1.13435366, -0.35554267, 0.72745511],
[-1.47417425, 2.55414223, 0.33564803]])
np.dot(arr.T,arr)
array([[ 5.3881196 , -5.1780539 , 1.14708141],
[-5.1780539 , 10.85533561, -3.27304969],
[ 1.14708141, -3.27304969, 6.7935248 ]])
#对于高维数组,transpose需要得到一个由轴编号组成的元组才能对这些轴进行转置
arr = np.arange(16).reshape(2,2,4)
arr
#2 column 2 row 2
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
arr1 = arr.reshape(4,2,2)
arr1
array([[[ 0, 1],
[ 2, 3]],
[[ 4, 5],
[ 6, 7]],
[[ 8, 9],
[10, 11]],
[[12, 13],
[14, 15]]])
arr.transpose(1,0,2)
#第一个轴 变成第二个
#第二个轴 变成第一个
#第三个轴 不变
# 2*2*4
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
Numpy 操作的axis讲解:
#example
import numpy as np
arr = np.arange(16).reshape(2,4,2)
arr
array([[[ 0, 1],
[ 2, 3],
[ 4, 5],
[ 6, 7]],
[[ 8, 9],
[10, 11],
[12, 13],
[14, 15]]])
arr.sum(axis=0)
array([[ 8, 10],
[12, 14],
[16, 18],
[20, 22]])
arr.sum(axis =1)
array([[12, 16],
[44, 48]])
arr.sum(axis = 2)
array([[ 1, 5, 9, 13],
[17, 21, 25, 29]])
通过以上可以发现,通过指定不同axis numpy会沿着不同的方向进行操作,如果不设置 表示对所有元素进行操作。
axis = 0沿着纵轴进行操作axis = 1沿着横轴进行操作
可以总结:设axis=i 则numpy沿着第i个下标变化的方向进行操作
下面考虑三维的方向处理:
#three D
arr = np.arange(16).reshape(2,4,2)
arr
array([[[ 0, 1],
[ 2, 3],
[ 4, 5],
[ 6, 7]],
[[ 8, 9],
[10, 11],
[12, 13],
[14, 15]]])
arr.sum(axis = 0)
#就是(4,2)二维结果
array([[ 8, 10],
[12, 14],
[16, 18],
[20, 22]])
arr的shape为(2,4,2) arr的shape下标为(0,1,2),则axis=0对应于数组shape下标的第一个位置。那么第一个位置的变化方向有几个,需要看shape下标对应的数值,为2 下面列举两个变化的方向:
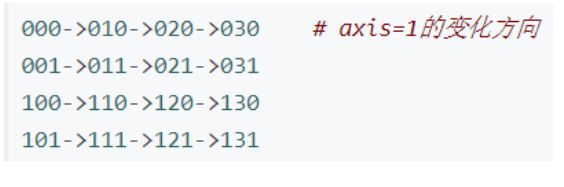
- 将以上两两变化的下标对应的数字进行sum就好了,得到了上述的结果。
arr.sum(axis = 1)
array([[12, 16],
[44, 48]])
arr.sum(axis = 1)
swapaxes方法:需要接受一对轴编号:
arr
#2 * 2 * 4
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7]],
[[ 8, 9, 10, 11],
[12, 13, 14, 15]]])
arr.swapaxes(1,2)
# 2 * 4 * 2 将 1 和 2 axis进行兑换
array([[[ 0, 4],
[ 1, 5],
[ 2, 6],
[ 3, 7]],
[[ 8, 12],
[ 9, 13],
[10, 14],
[11, 15]]])
4.2通用函数:快速的元素级数组函数
通用函数是一种对ndarray中的数据执行元素级运算的函数。可以将其看做简单函数(接受一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。
arr = np.arange(10)
arr
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.sqrt(arr)
array([0. , 1. , 1.41421356, 1.73205081, 2. ,
2.23606798, 2.44948974, 2.64575131, 2.82842712, 3. ])
x = np.random.randn(8)
y = np.random.randn(8)
x
array([ 0.01405846, -0.70512306, 1.06652829, 0.0734746 , -0.24392996,
0.52697044, 0.55488568, -1.3440912 ])
y
array([-0.45326333, -0.60979654, -2.09286773, -2.5700492 , 0.27796645,
0.79478465, -0.43451777, -0.26488798])
np.maximum(x,y)
#这里计算了x和y的元素级别最大的元素
array([ 0.01405846, -0.60979654, 1.06652829, 0.0734746 , 0.27796645,
0.79478465, 0.55488568, -0.26488798])


4.3利用数组进行数据处理
用数组表达式代替循环做法 称为矢量化。后面介绍广播,这是一种针对矢量化计算的强大手段。
#想在一组值(网格型)上计算函数sqrt(x^2+y^2) np.meshgrid函数接受两个一维数组,并产生两个
#二维矩阵
points = np.arange(-5,5,0.01)
xs,ys = np.meshgrid(points,points)
ys
array([[-5. , -5. , -5. , ..., -5. , -5. , -5. ],
[-4.99, -4.99, -4.99, ..., -4.99, -4.99, -4.99],
[-4.98, -4.98, -4.98, ..., -4.98, -4.98, -4.98],
...,
[ 4.97, 4.97, 4.97, ..., 4.97, 4.97, 4.97],
[ 4.98, 4.98, 4.98, ..., 4.98, 4.98, 4.98],
[ 4.99, 4.99, 4.99, ..., 4.99, 4.99, 4.99]])
z = np.sqrt(xs**2 +ys**2)
z
array([[7.07106781, 7.06400028, 7.05693985, ..., 7.04988652, 7.05693985,
7.06400028],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
...,
[7.04988652, 7.04279774, 7.03571603, ..., 7.0286414 , 7.03571603,
7.04279774],
[7.05693985, 7.04985815, 7.04278354, ..., 7.03571603, 7.04278354,
7.04985815],
[7.06400028, 7.05692568, 7.04985815, ..., 7.04279774, 7.04985815,
7.05692568]])
import matplotlib.pyplot as plt
plt.imshow(z,cmap=plt.cm.gray)
plt.colorbar()
plt.title("Image plot of $\sqrt{x^2+y^2}$ for a grid of values")
Text(0.5,1,'Image plot of $\\sqrt{x^2+y^2}$ for a grid of values')

将逻辑表述为数组运算
Numpy.where函数是三元表达式x if condition else y的矢量版本。假设我们有一个bool数组和两个值数组。
xarr = np.array([1.1,1.2,1.3,1.4,1.5],dtype = float)
yarr = np.array([2.1,2.2,2.3,2.4,2.5],dtype = float)
cond = np.array([True,False,True,True,False])
#假设根据cond中的值选取xarr 和 yarr值:cond -> True 选取xarr 否则选取yarr
#列表推导公式
#的写法应该如下所示:
result = [(x if c else y)
for x,y,c in zip(xarr,yarr,cond)]
result
[1.1, 2.2, 1.3, 1.4, 2.5]
- Pro above:
- 1.对大数组处理速度不是很快
- 2.无法用于多维数组 若使用np.where 则可以将功能写的很简洁:
result = np.where(cond,xarr,yarr)
result
array([1.1, 2.2, 1.3, 1.4, 2.5])
np.where的第二个和第三个参数不必是数组 都可以是标量值。在数据分析工作中,where通常用于根据另一个数组而产生一个新的数组 假设有个由随机数组成的矩阵,希望所有正值替换为2,将所有负值替换为 -2 若利用Np.where 则会非常简单
arr = np.random.randn(4,4)
arr
array([[ 0.06558874, -2.70606526, 1.44692089, -0.39903601],
[-0.68711786, -1.75560247, -0.76330474, -0.59857356],
[-1.18115698, -1.35253882, -0.5534564 , -0.97926207],
[-0.77505713, -0.56019667, 0.46180098, 1.04687073]])
arr > 0
array([[ True, False, True, False],
[False, False, False, False],
[False, False, False, False],
[False, False, True, True]])
np.where(arr > 0 , 2 , -2)
array([[ 2, -2, 2, -2],
[-2, -2, -2, -2],
[-2, -2, -2, -2],
[-2, -2, 2, 2]])
- 使用np.where 可以将标量和数组结合起来。例如 可以用常数2替换arr中所有正的值
np.where(arr > 0,2,arr)
array([[ 2. , -2.70606526, 2. , -0.39903601],
[-0.68711786, -1.75560247, -0.76330474, -0.59857356],
[-1.18115698, -1.35253882, -0.5534564 , -0.97926207],
[-0.77505713, -0.56019667, 2. , 2. ]])
数学和统计方法:
可以通过数组上的一组数学函数对对个数组或轴向数据进行统计计算 sum、mean以及标准差std等聚合计算(aggregation 通常叫做约简(reduction)可以当做数组的示例方法调用 可以当做顶级Numpy函数使用)
arr = np.random.randn(5,4)
arr
array([[ 0.6383171 , 0.4107347 , -0.80231428, 0.21591313],
[ 0.96458743, -1.61906183, -0.03083475, 0.60562961],
[ 1.29263996, 0.12877919, 1.23673408, -0.14365957],
[-0.60738506, 1.39670689, -0.62700838, 1.19102011],
[-1.48107429, 0.12330974, 0.76627256, 1.05623004]])
arr.mean()
0.23577681910980633
np.mean(arr)
0.23577681910980633
arr.sum(axis = 0)#计算每列的和
array([0.80708514, 0.44046869, 0.54284923, 2.92513332])
arr.mean(axis = 1 )#就算每行的平均值
array([ 0.11566266, -0.01991988, 0.62862342, 0.33833339, 0.11618451])
- 其他如cumsum何cumprod之类的方法则不聚合,而是产生一个由中间结果组成的数组。
arr = np.array([0,1,2,3,4,5,6,7])
arr.cumsum()
array([ 0, 1, 3, 6, 10, 15, 21, 28])
#多维数组 累加函数(cumsum) 返回的是同样大小的数组 但根据每个低维切片沿着标记轴计算
#部分聚类
arr = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
arr
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
arr.cumsum(axis=0)
array([[ 0, 1, 2],
[ 3, 5, 7],
[ 9, 12, 15]])
以下是全部的基本数组统计方法:

用于bool数组的方法
在上面这些方法中,bool值会被强制转换为1和0
因此,sum经常被用来对bool数组中的True值计数。
arr = np.random.randn(100)
(arr > 0 ).sum()
43
- way 2: any & all 他们对bool数组很有用。
- any 用于检测数组是否存在一个或多个true
- all检测数组中所有值是否都是true
bools = np.array([False,False,True,False])
bools.any()
True
bools.all()
False
排序
和py内置列表类型一样 numpy数组也可以通过sort方法就地排序:
arr = np.random.randn(6)
arr
array([-0.39065258, -2.71242898, -1.92679479, 1.55291201, 0.51294281,
-0.11633546])
arr.sort()
arr
array([-2.71242898, -1.92679479, -0.39065258, -0.11633546, 0.51294281,
1.55291201])
- 多维数组可以在任何一个轴向上进行排序 只需要将轴编号传给sort即可:
arr = np.random.randn(5,3)
arr
array([[ 0.30207802, -0.81233625, -0.56164607],
[-0.10964939, -1.37365698, -0.049106 ],
[-0.64501391, -1.7706598 , -0.6320434 ],
[-0.0695195 , 0.86075897, 2.00105375],
[-0.13046796, 0.6264181 , -0.79649535]])
arr.sort(0) #纵向排序
arr
array([[-0.64501391, -1.7706598 , -0.79649535],
[-0.13046796, -1.37365698, -0.6320434 ],
[-0.10964939, -0.81233625, -0.56164607],
[-0.0695195 , 0.6264181 , -0.049106 ],
[ 0.30207802, 0.86075897, 2.00105375]])
large_arr = np.random.randn(1000)
large_arr.sort()
large_arr[int(0.05 * len(large_arr))]
#更多技术参见 附录A
-1.6464279203960233
唯一化及其他的集合逻辑
np.unique 用于找出数组中的唯一值并返回已排序的结果:
names = np.array(['Bob','Joe','Will','Bob','Will', 'Joe','Will'])
np.unique(names)
array(['Bob', 'Joe', 'Will'], dtype='|S4')
ints = np.array([1,2,3,4,5,1,2,2,1,7])
np.unique(ints)
array([1, 2, 3, 4, 5, 7])

4.4用于数组的文件输入输出
numpy能够读写磁盘上的文本数据或二进制数据。np.save和np.load是读写磁盘数组数据的两个主要函数。默认情况下,数组是以未压缩的原始二进制格式保存在拓展名为.npy文件中的:
arr = np.arange(10)
np.save('some_array',arr)
np.load('some_array.npy')
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
如果文件路径末尾没有扩展名.npy 则该扩展名会被自动加上 然后通过np.load读取磁盘上的数组。
np.savez('some_archive.npz',a=arr,b=arr)
通过np.savez可以将多个数组保存到一个未压缩文件中,将数组以关键字参数的形式传入即可。
#加载npz文件时,会得到一个类似字典的对象 该对象会对各个数组进行延迟加载。
arch = np.load('some_archive.npz')
arch['b']
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
#想将数据压缩 使用np.savez_compressed:
np.savez_compressed('arrays_comprossed.npz',a=arr, b = arr)
4.5线性代数
- linear algebra是任何数组库的重要组成部分。不像某些语言,通过*对两个二维数组相乘得到的是一个元素级的积,而不是一个矩阵点积。因此np提供了一个用于矩阵乘法的dot函数:
x = np.array([[1., 2., 3.], [4., 5., 6.]])
#2*3
y = np.array([[6., 23.], [-1, 7], [8, 9]])
#3*2
x.dot(y)
array([[ 28., 64.],
[ 67., 181.]])
#x.dot(y) == np.dot(x,y)
np.dot(x,y)
array([[ 28., 64.],
[ 67., 181.]])
np.dot(x,np.ones(3))
array([ 6., 15.])
@表示矩阵乘法 #3.6语法
x @ np.ones(3)
np.linalg中有一组标准的矩阵分解运算以及诸如求逆和行列式之类的东西。
线性代数参考函数
- np.linalg.inv()矩阵的逆 它乘以原始矩阵=单位矩阵
- np.linalg.solve() 给出了矩阵的线性方程的解
- np.linalg.det() 左上和游侠元素的成绩与其他两个的乘积的差
- np,linalg.matul() 返回两个数组的矩阵乘积
- np.inner() 返回一维数组的向量内积 对于高维度 返回最后一个最后一个轴上的和的成绩
from numpy.linalg import inv,qr
X = np.random.randn(5,5)
mat = X.T.dot(X)
#计算X和它的转置的点积
inv(X)
array([[ 0.11308974, -0.11250289, 0.13933068, -0.30489062, 0.1950831 ],
[ 0.45149202, -0.08040628, -1.23983825, -1.59884382, -0.02865385],
[ 1.44367483, -0.65488517, -2.24816212, -3.26605913, -0.09523802],
[ 0.28095089, 0.07998305, 0.17209162, -0.30694757, -0.31436612],
[-0.23363819, -0.21210541, 0.19039961, -0.19629612, -0.37542163]])
mat.dot(inv(mat))
array([[ 1.00000000e+00, 6.66175389e-18, -1.15198245e-16,
1.65824985e-16, -2.88608427e-17],
[-5.93265432e-17, 1.00000000e+00, 8.97046660e-17,
-4.07539310e-16, 2.86477122e-17],
[-4.28341066e-16, 1.20657157e-16, 1.00000000e+00,
-5.42891650e-16, -2.77112029e-17],
[ 3.51099456e-16, 1.08052799e-16, -1.45156592e-17,
1.00000000e+00, -9.56530652e-17],
[ 3.81828462e-16, -6.22696755e-17, 2.96105669e-16,
-3.26589874e-16, 1.00000000e+00]])
q,r = qr(mat)
r
array([[-2.88178926, 5.36777815, 4.67041404, 1.7423072 , -2.8741252 ],
[ 0. , -7.9373961 , -4.5047787 , -4.28509008, 3.03048883],
[ 0. , 0. , -7.89377311, -5.55621837, 2.65445333],
[ 0. , 0. , 0. , -0.56228365, 1.66290593],
[ 0. , 0. , 0. , 0. , 2.74060938]])

4.6伪随机数生成
numpy.random模块对py内置进行补充 增加了一些用于高效生产多种概率分布的样本值函数
samples = np.random.normal(size=(4,4))
samples
array([[ 0.27252875, -0.90220088, 1.0978832 , -0.21163186],
[-0.59617607, -0.25670218, -0.09046641, 0.1052227 ],
[ 0.33653998, -1.29007404, 1.30382925, -0.28602955],
[-0.18526258, 0.8320744 , 1.09525305, 0.71737174]])
from random import normalvariate
N = 1000000
%timeit samples = [normalvariate(0,1) for _ in range(N) ]
1 loop, best of 3: 918 ms per loop
%timeit np.random.normal(size=N)
10 loops, best of 3: 38.9 ms per loop
这些都是伪随机数,因为都是通过算法基于随机数生成器种子,在确定性的条件下生成的。可以用Numpy的np.random.seed更改随机数生成种子:
np.random.seed(1234)
numpy.random的数据生成函数使用了全局的随机种子。要避免全局状态,可以使用Numpy.random.RandomState,创建一个与其他隔离的随机数生成器:
rng = np.random.RandomState(1234)
rng.randn(10)
array([ 0.47143516, -1.19097569, 1.43270697, -0.3126519 , -0.72058873,
0.88716294, 0.85958841, -0.6365235 , 0.01569637, -2.24268495])

4.7示例 随机漫步
- 从0开始,步长1和-1出现的概率相等。
下面是一个通过内置的random模块用纯py方式实现1000步的随机漫步:
import random
position = 0
walk = [position]
steps = 1000
for i in range(steps):
step = 1 if random.randint(0,1) else -1#给定的范围内随机选取整数
position += step
walk.append(position)
plt.plot(walk[:1000])
[]

不难看出,其实就是随机漫步中各部的累计和,可以用一个数组运算来实现。因此Np.random模块依次性随机产生1000个"掷硬币"结果(两个数中任选一个),将其分别设置为1和-1,然后计算累计和:
nsteps = 1000
draws = np.random.randint(0,2,size=nsteps)
steps = np.where(draws > 0,1,-1)
walk = steps.cumsum()
#求最大值 最小值
walk.min()
-9
walk.max()
60
复杂的统计任务:首次穿越时间 随机漫步过程中第一次达到某个特定值的时间。假设我们想要知道本次随机漫步需要多久才能距离初始0点至少10步远。
np.abs(walk)>=10可以得到一个bool数组,表示的是距离是否达到或超过10,我们想要知道的是第一个10或-10的索引。可以用argmax来解决这个问题。
(np.abs(walk) >= 10).argmax()
#argmax并不是很高效 因为无论如何都会对数组进行完全扫描
#本例 只要发现一个true 就是最大值了
297
一次模拟多个随机漫步
只需要给np.random的函数传入一个二元元组就可以产生一个二维数组,然后就可以一次性计算5000个随机漫步过程的累计和了。
nwalks = 5000
nsteps = 1000
draws = np.random.randint(0,2,size=(nwalks,nsteps))
#0 or 1
steps = np.where(draws > 0,1,-1)#if draws > 0 then 1 else -1
walks = steps.cumsum(1)#累加起来
walks
array([[ -1, 0, 1, ..., -6, -5, -4],
[ -1, -2, -1, ..., -18, -19, -18],
[ 1, 0, -1, ..., 24, 23, 22],
...,
[ -1, 0, -1, ..., -2, -3, -4],
[ -1, 0, -1, ..., 30, 29, 30],
[ 1, 0, -1, ..., 18, 19, 20]])
walks.max()
137
walks.min()
-137
#计算30 或 -30的最小穿越时间 不是 5000个过程都达到了30 可以用any方法进行检查
hits30 = (np.abs(walks) > 30).any(1)
hits30
array([False, False, False, ..., False, True, True])
hits30.sum()
3278
#利用bool选出了30的随机漫步 并调用argmax在轴1获取穿越时间
crossing_times = (np.abs(walks[hits30]) >= 30)
crossing_times.mean()
0.2723794996949359
#不同的漫步数据
steps = np.random.normal(loc=0, scale=0.25,
size=(nwalks, nsteps))