【深度学习人类语言处理】1 课程介绍、语音辨识1——人类语言处理六种模型、Token、五种Seq2Seq Model(LAS、CTC、RNN-T、Neural Transducer、MoChA)
Deep Learning for Human Ianguage Processing
- 1. DLHLP-Introduction
-
- 1.1 概述
- 1.2 六种模型与应用
-
- 1.2.1 语音到文本
- 1.2.2 文本到语音
- 1.2.3 语音到语音
- 1.2.4 语音到Class
- 1.2.5 文本到文本
- 1.2.6 文本到Class
- 1.3 更多应用
- 2. 语音辨识
-
- 2.1 语音辨识的Token
- 2.2 声学特征提取
- 2.3 Listen, Attend, and Spell (LAS)
-
- 2.3.1 Encoder
- 2.3.2 Attention
- 2.3.3 Decoder
- 2.3.4 LAS结果分析
- 2.4 Connectionist Temporal Classification (CTC)
- 2.5 RNN Transducer (RNN-T)
- 2.6 Neural Transducer
- 2.7 Monotonic Chunkwise Attention (MoChA)
- 总结
这是李宏毅《深度学习人类语言处理》国语课程(2020),b站链接和此,源课程链接
1. DLHLP-Introduction
1.1 概述
这个课程的内容是什么?
让机器:
- 听懂人说的话
- 看懂人写的句子
- 写出让人看得懂的句子
- 说出人听得懂的话
- 而这些实现这些技术靠的是深度学习
课程名称由来:
-
深度学习人类语言处理(Deep Learning for Human Language Processing)
-
自然语言处理(Natural Language Processing, NLP)
- 一种在使用中自然发展起来的语言(如:中文、英语)
- 与人造语言(如JAVA、Python)相比
- 自然语言可以是语音或文本
- 这门课也可以叫深度学习与自然语言处理
-
一般自然语言处理,大多数NLP教科书和课程主要集中在文本上。(Text v.s. Speech = 9 : 1)
-
在这门课中,Text v.s. Speech = 5 : 5,所以这门课叫做深度学习人类语言处理
-
语音处理不仅仅是语音识别
-
只有56%的语言有书面形式(《民族学》((Ethnologue)第21版)
- 我们不一定知道现有的写作系统是否被广泛使用,例如闽南语,部分人不会这种语言书写
人类语言是复杂的,先看语音的部分:

1s有16k(HZ)个采样点,每个点有256个可能的值
也沒有人可以说同一段话两次:

《The Language Instinct: How the Mind Creates Language》((Steven Arthur Pinker)

永远的可以轻易创造最长的句子,探讨最长的句子没有意义,人类的语言可以是非常复杂的,所以让机器理解这些语言是一个非常有挑战性的内容
一张幻灯片概况本课程:

Model是什么?,就是Deep Network,遇到问题用 deep learning “硬 train 一下” 就对了,没有"硬 train 一下"无法解决的东西,如果有,那只是你训练资料和GPU不够多而已,这门课着重强调:"硬 train 一下"过后,人类语言处理的下一步
1.2 六种模型与应用
1.2.1 语音到文本
自动语音识别(ASR),语音辨识的模型不是常见的Seq2Seq模型:

1.2.2 文本到语音
Text-to-Speech Synthesis:现在使用文字转成语音比较优秀,但所有的问题都解决了吗?在实际应用中已经发生问题了…

Google翻译破音的视频这个问题在2018.02中就已经发现了,它已经被修复了,所以尽管文字转语音比较成熟,但仍有很多尚待克服的问题
1.2.3 语音到语音
语音分离
鸡尾酒会效应(cocktail party effect)

上面结果连 Fourier Transform 都没有用上,只有用深度学习“硬train一发”
语音转换

要"硬train一发"你需要 ……

比如我想和新垣结衣一起train,但我显然不能把她叫过来,而且就算把她叫来,她也不会说中文,能不能…

发言人A和B说的是完全不同的事情
这样就有了无监督的语音转换
- 每个说话人只说一句话(单次学习)
1.2.4 语音到Class
语者辨认(Speaker Recognition)

关键字定位 (Keyword Spotting) 检测一个句子有没有关键的词汇,例如Siri,小度小度…
先讲一个唤醒词的故事,链接1、2
- 2017.01,在德克萨斯州达拉斯市
- 一个六岁的孩子问她的亚马逊Echo “你能和我一起玩娃娃屋吗,给我买个娃娃屋?”
- 设备订购了KidKraft Sparkle豪宅娃娃屋
- 加利福尼亚州圣地亚哥的CW-6电视台正在做一个早间新闻节目
- 主播吉姆-巴顿说:"我喜欢那个小女孩说:'亚历克萨给我订了一个娃娃屋。” ……
- 之后汉堡王利用Wikipedia进行广告

Fermachado123是汉堡王市场总监的用户名,然后就被乱改:


当输入的是文字,这里直接讲BERT(打破了之前NLP的State-of-the-art),进展超乎想象,BERT 家族繁衍兴盛,BERT跟他的好朋友们:

模型变得越来越大…


1.2.5 文本到文本
文本生成
自回归(自回归):

非自律性:
有很多应用
即使是句法解析(syntactic parsing)…

我不会把所有的应用都看一遍,因为你会觉得无聊的,我们主要看Question Answering
1.2.6 文本到Class
1.3 更多应用
Meta learning
Learn to learn
Learning from Unpaired Data

知识图谱(Knowledge Graph)

对抗攻击
- 语音
- 反欺骗系统(检测合成语音)容易上当 [Liu, et al., ASRU, 2019]
- 语音识别很容易被骗 [Lea Schonherr, et al., NDSS, 2019]
- NLP

可解释AI

2. 语音辨识
Speech Recognition
语音识别难?

2.1 语音辨识的Token
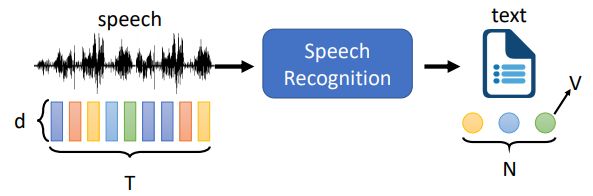
语音:一个向量序列(长度T,维数d)
文本:一个令牌序列(长度为N、V的不同令牌)
一般:T>N
Token(语音辨识的单位):
Phoneme
音素: a unit of sound(单位,需要语言学家来告诉如何定义)
Lexicon(词典):单词到音素

Grapheme
字形:文字系统中最小的单位 Lexicon free!

Word
当作语音辨识的单位

例如土耳其语:粘性语言,资料来源:

Morpheme

字节(!):系统可以独立于语言!

浏览INTERSPEECH’19、ICASSP’19、ASRU’19的100多篇论文

- grapheme最受欢迎,非常容易使用,只要收集到文字,就可以进行语音辨识,不需要语言学家帮忙
- phoneme和声音之间的关系比较明确,所以语音辨识的部分比较简单,但之后需要有比较好的词典,把phoneme转成文字
- morpheme,介于grapheme和word之间的单位,
- word是最少用的
语音辨识更多的应用:

2.2 声学特征提取
声学特性(Acoustic Feature)如下,更多部分请参见数位语音处理(Speech Signal and Front-end Processing)第七章

有人直接读spectrogram就可以读出内容,但这不是主流,一般通过一些filter,这是先贤设计出来的,之后取log,再做DCT得到MFCC,这些东西叫做声学特征
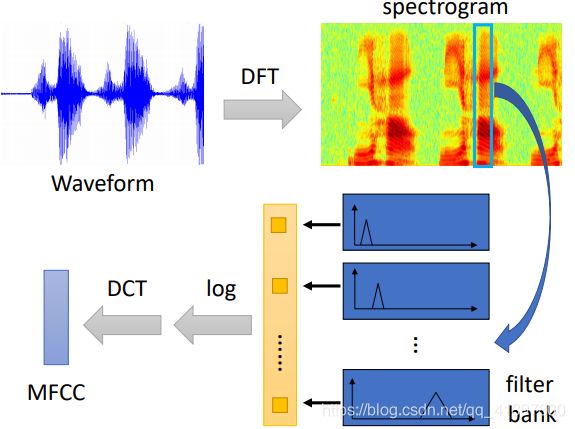
再看MFCC有被取代的趋势:

可以说filter bank output已经取代了MFCC
做语音辨识,我们需要多少数据?(英语语料库)

商业系统的使用量不止于此…
语音辨识主要有两个模型:Seq-to-seq和HMM

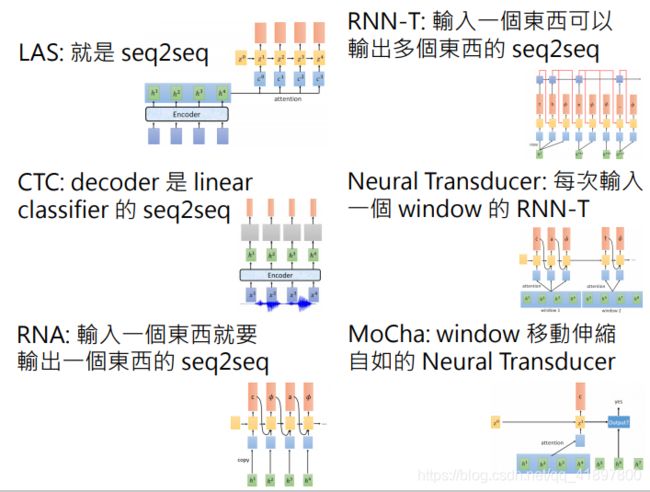
首先介绍以下Seq2Seq模型:
- Listen, Attend, and Spell (LAS) [Chorowski. et al., NIPS’15]
- Connectionist Temporal Classification (CTC) [Graves, et al., ICML’06]
- RNN Transducer (RNN-T) [Graves, ICML workshop’12]
- Neural Transducer [Jaitly, et al., NIPS’16]
- Monotonic Chunkwise Attention (MoChA) [Chiu, et al., ICLR’18]

2.3 Listen, Attend, and Spell (LAS)

2.3.1 Encoder
Encoder期望:
- 提取内容信息
- 消除扬声器差异,消除噪音

Encoder可以是RNN:

可以是CNN:
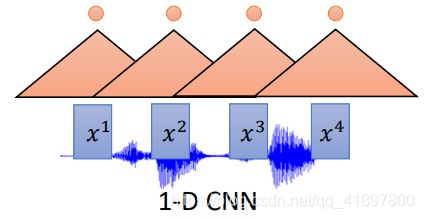
- 上层的过滤器可以考虑更长的序列
- CNN+RNN是常见的

也可以是Self-Attention:

往往一个声音信号太长了,为了节省训练量,需要进行Down Sampling:
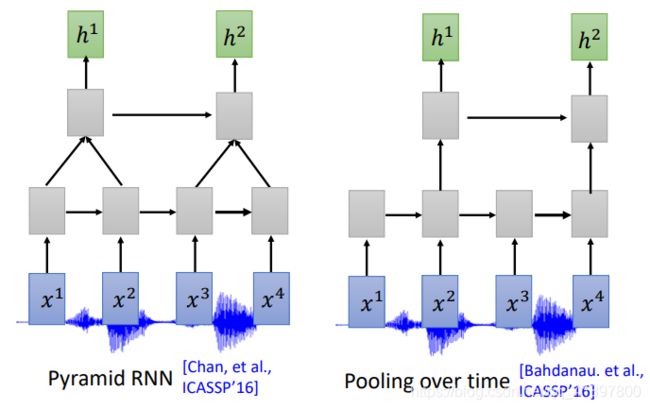
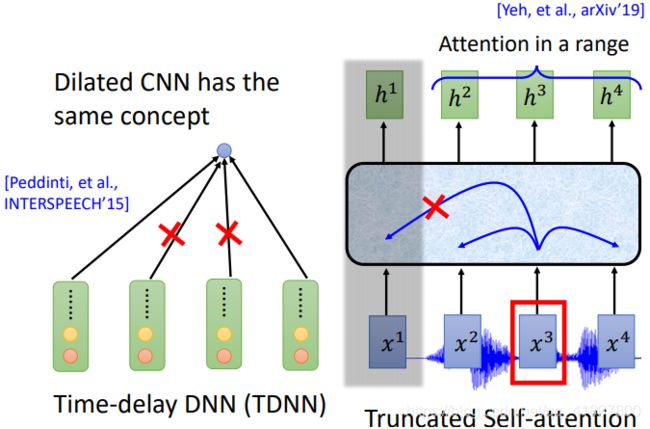
CNN和self-attention也会想办法减小运算量,Time-delay DNN (TDNN)在看相似的向量只看首尾,Truncated Self-attention只看一定范围的向量:
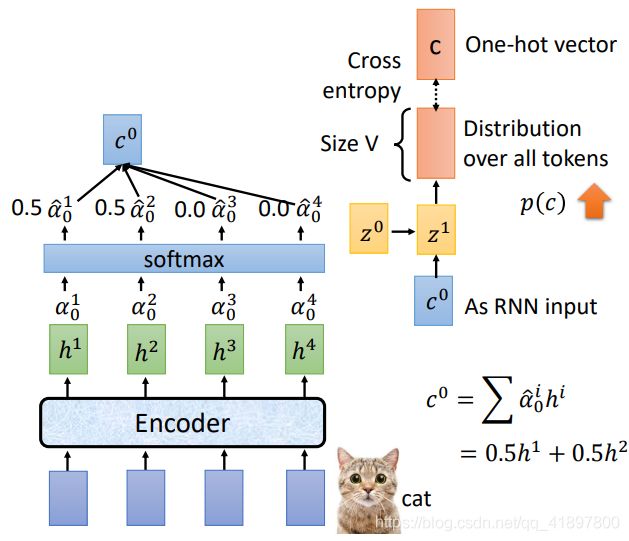
2.3.2 Attention

另一种常见的Attention的方式:
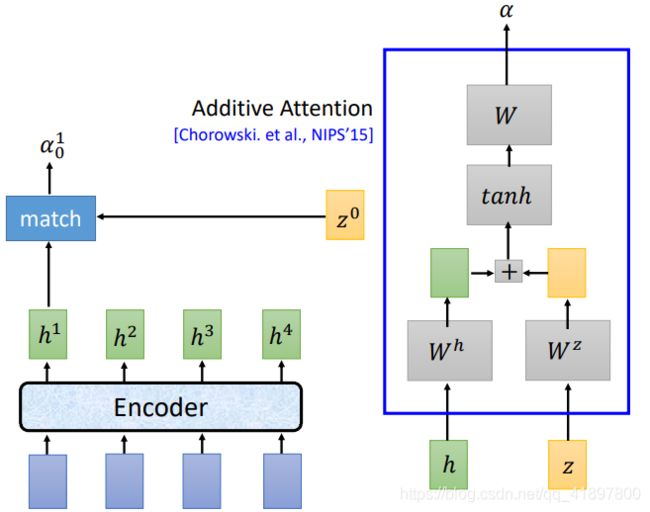
Attention的输出c0作为之后Decoder的输入,c0常常被称为Context Vector

之后Decoder给每一个token一个几率
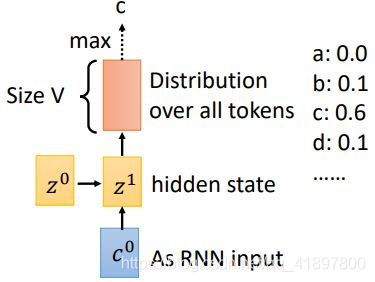
再把输出和第二个隐层做Attention,得到新的权重:


2.3.3 Decoder
Spell
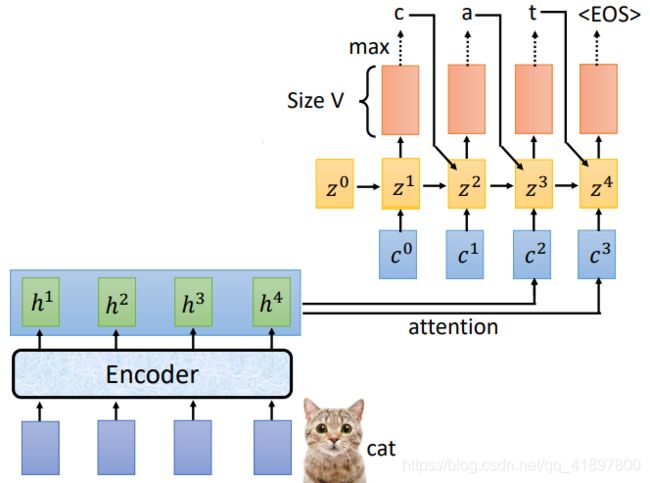
通常使用Beam Search,关于Beam可见【DL】2 Attention入门——李宏毅机器学习课程笔记
Beam Search
假设只有两个token(V=2):
- 红色的路径是贪婪解码
- 绿色的路径是最好的一个

每一步都保留B个最好的路径,B(Beam size) = 2时:

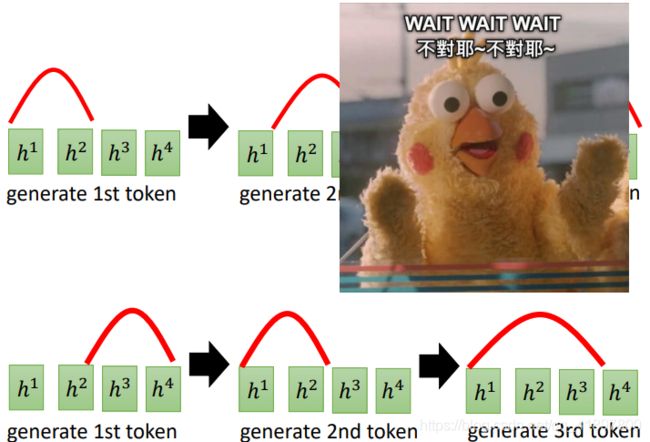
训练:
Teacher Forcing

为什么Teacher Forcing? 不能一直使用以前的输出


回到Attention

实际上,语音辨识的时候,两种Attention都使用到了:

考虑一下,是否赋予了模型太强的能力,即原本的Seq2Seq模型是用在翻译的任务中的,得到的句子可能和原始的句子没有很强的对应关系,所以需要机器自己去寻找Attention来学习如何对应,但是语音识别的输出文本和输入语音信号,基本都是一一对应的关系,所以得到的Attention的权重应该是从左到右依次移动的,如果得到的Attention是左右乱跳,那模型应该是有问题的,所以原论文加上了Location-aware attention:

2.3.4 LAS结果分析
LAS——它有用吗?
在TIMIT上错误率:

可见它打不赢传统的方法

在300个小时的数据集上也表现不好
但是,最后它能够使用!
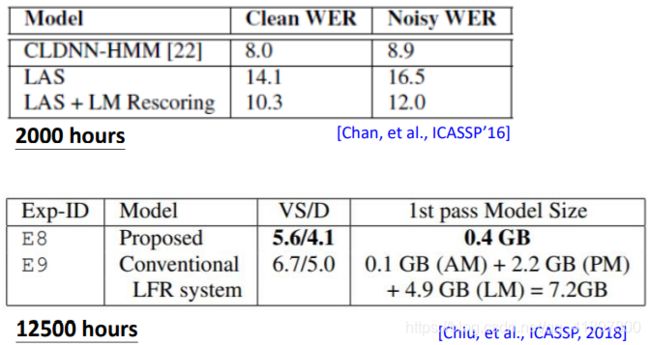
而且由上可见,LAS的模型可以很小

Attention从左到右很好的学到,而且没有用到Location-aware attention!


结果:Accuracy = 62.1%
LAS的局限性:
- LAS在监听完整个输入后输出第一个令牌
- 用户期待在线语音识别
LAS不是ASR的最终解决方案!
2.4 Connectionist Temporal Classification (CTC)
起源的很早,能够做到online的Encoder

一个声学特征的向量,代表的信息很少,所以不知道输出什么的时候会输出:

- 输入T个声学特征,输出T个令牌(忽略向下采样)
- 包括的输出标记,合并重复的标记,删除

训练的问题:不知道每个声学特征对应的标签是什么

解决办法:自己制造Label——alignment(排列)

CTC能够工作嘛?
注意到灰色的虚线是:


CTC后面需要进行一个Language Model才能有很好的效果,所以很多人并不认为CTC是一个end to end 模型
CTC的问题:

(可以认为LAS的Encoder就是CTC?)
2.5 RNN Transducer (RNN-T)
CTC的Decoder:以一个向量作为输入,输出一个标记,先看RNA,就是用RNN去取代CTC的Linear
RNA——Recurrent Neural Aligner [Sak, et al., INTERSPEECH’17] ,RNA增加了依赖性
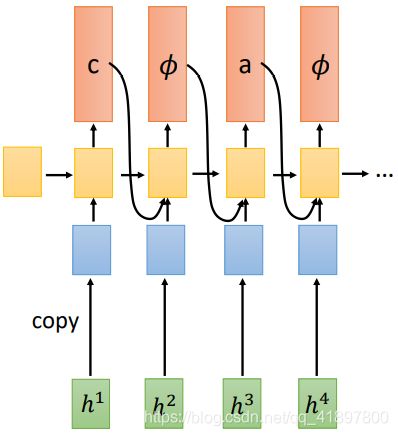
考虑一个问题:一个向量可以映射到多个令牌吗?例如,“th” 当然可以通过在Token中增加新的Token来解决这个问题,但是希望我们的模型有更好的普适性
RNN-T



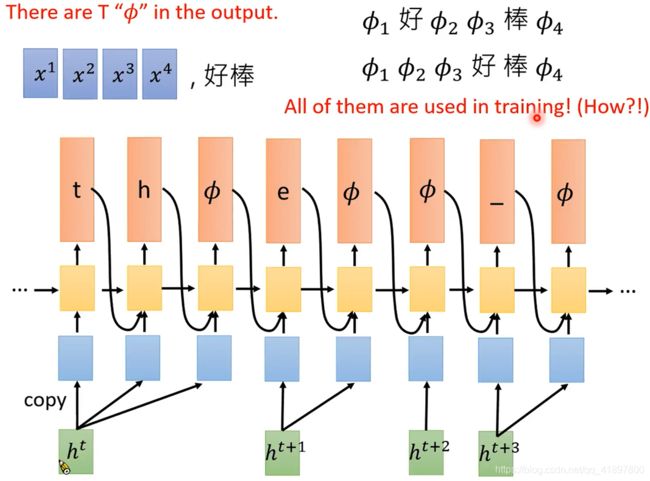
RNN-T较CTC而言,其实多训练了一个RNN,而不是以上的RNN,可以把它视为Language Model:

这样做的原因:

2.6 Neural Transducer
能不能一次读一把数据进来:

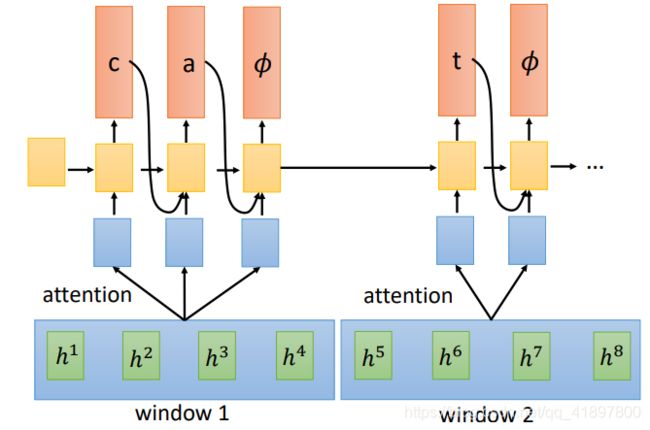
no-attention的意思就是每个Window取最后一个声学特征,意料之中随着窗口变大,模型表现会变坏,LSTM-attention意思是由输入生成前一个输入的Attention

2.7 Monotonic Chunkwise Attention (MoChA)
动态移动窗口
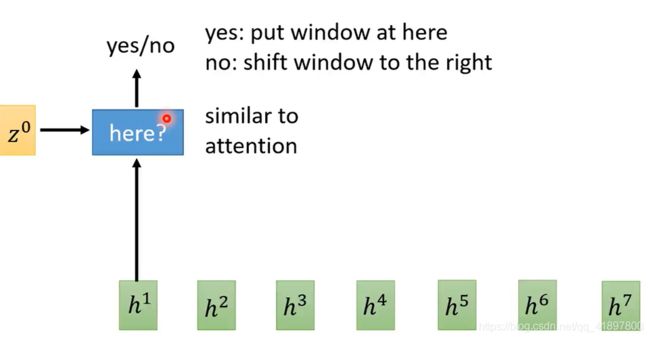
在MoChA里面没有,之后Decode 一个Token

关于确定窗口是否要定在这的Operator,其结果是一个二分类的问题,应该不能微分?具体的操作过程可见论文
总结
- 首先介绍了这门课不只有Text NLP还有Speech NLP,不论是语音还是文本都是很复杂的,人类语言处理可以分为6种不同的模型,介绍不同模型的应用,以及更多未来可能的方向
- 语音辨识的Token,包括:Phoneme、Grapheme、Word、Morpheme
- 简单介绍了五种语音辨识的Seq2Seq模型