grafana&prometheus 快速配置报警规则及报警接收
系列文章目录
1、使用helm快速安装 grafana&prometheus
2、利用grafana&prometheus 快速配置 k8s & 主机监控
3、grafana&prometheus 快速配置报警规则及报警接收
文章目录
- 系列文章目录
- 前言
- 报警设置选型
- 配置prometheus报警rule
-
- 导出对应服务配置
- 新增服务配置
- 新增报警管理器(alertmanager)配置,让产生的告警发送到邮箱
- 参考资料
前言
前两回讲了如何做大屏dashborad监控,本节课给大家讲解快速将 metrics 指标 配置到告警中(超过阈值报警)。
学习完本节课,你将会快速配置你的监控项目。
报警设置选型
前文讲过 grafana&prometheus 的安装及配置,其实这两个服务内部都会有报警配置项的。
配置界面分别如下:
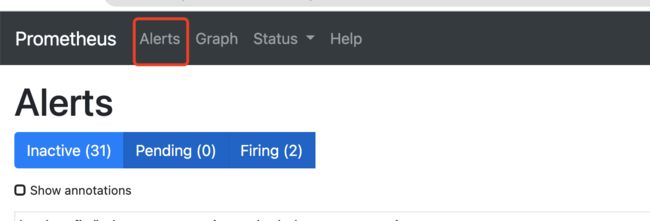
prometheus支持通过配置文件自定义分组配置,比较灵活。
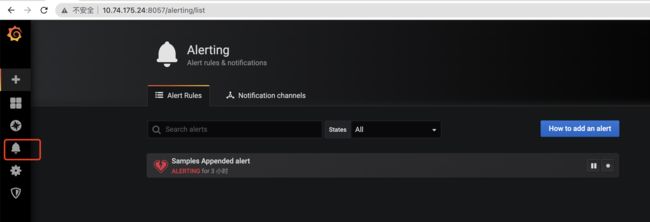
Grafana中的报警配置是基于图表创建时的聚合参数构建的,如果有报警需要是与页面显示相关的推荐使用Grafana的报警。
但是一般模板系统的报警规则,这里推荐使用prometheus进行设置。
配置prometheus报警rule
我们已经通过helm安装完了prometheus,我现在想看下prometheus的安装配置是什么样子的。这里需要helm pull一下,我们需要看看配置规则到底设置到哪里了。
helm pull apphub/prometheus-operator
tar xvf prometheus-10.4.0.tgz
cd prometheus
vim README.md
这个README.md里面有更加细致的 values.yaml参数,现在贴到下面:
| Parameter | Description | Default |
|---|---|---|
alertmanager.configFromSecret |
The name of a secret in the same kubernetes namespace which contains the Alertmanager config, setting this value will prevent the default alertmanager ConfigMap from being generated | "" |
alertmanager.configFileName |
The configuration file name to be loaded to alertmanager. Must match the key within configuration loaded from ConfigMap/Secret. | alertmanager.yml |
alertmanager.configFileName 报警管理器,核心配置是维护到ConfigMap中的。
导出对应服务配置
kubectl get configMap my-prometheus-server -o yaml > prometheus-server-config.yaml
核心内容如下:
apiVersion: v1
data:
alerts: |
{}
....
prometheus.yml: |
global:
evaluation_interval: 1m
scrape_interval: 1m
scrape_timeout: 10s
rule_files:
- /etc/config/recording_rules.yml
- /etc/config/alerting_rules.yml
- /etc/config/rules
- /etc/config/alerts
scrape_configs:
- job_name: prometheus
...
在rule_files中新增对应配置参数即可。
新增服务配置
我们以k8s服务监控举例,有很多成型的报警规则我们可以直接使用:
参考网址:https://awesome-prometheus-alerts.grep.to/rules#kubernetes
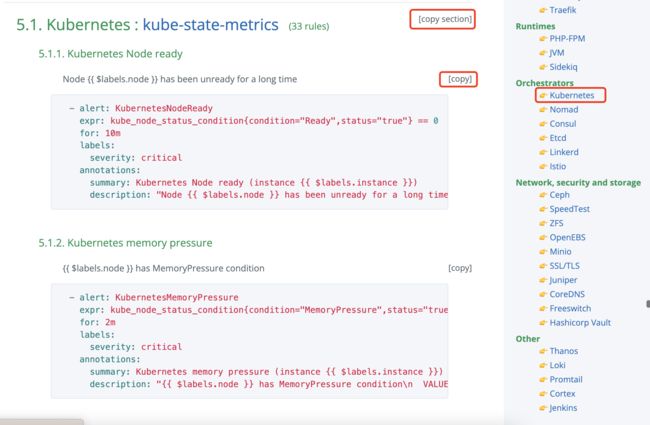
规则都是现成的我们直接用即可。
下面开始编辑我们的配置文件:
核心内容如下:
vim prometheus-server-config.yaml
apiVersion: v1
data:
alerts: |
{}
kube_state_metrics.yml: |
groups:
- name: kube_state_metrics
rules:
...
#增加从上面拷贝的内容即可注意缩进,比如下面
#- alert: KubernetesNodeReady
# expr: kube_node_status_condition{condition="Ready",status="true"} == 0
# for: 10m
# labels:
# severity: critical
# annotations:
# summary: Kubernetes Node ready (instance {{ $labels.instance }})
# description: "Node {{ $labels.node }} has been unready for a long time\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
....
prometheus.yml: |
global:
evaluation_interval: 1m
scrape_interval: 1m
scrape_timeout: 10s
rule_files:
- kube_state_metrics.yml
- /etc/config/recording_rules.yml
- /etc/config/alerting_rules.yml
- /etc/config/rules
- /etc/config/alerts
scrape_configs:
- job_name: prometheus
...
然后执行配置写入
kubectl apply -f my-prometheus-server.yaml
查看配置效果:
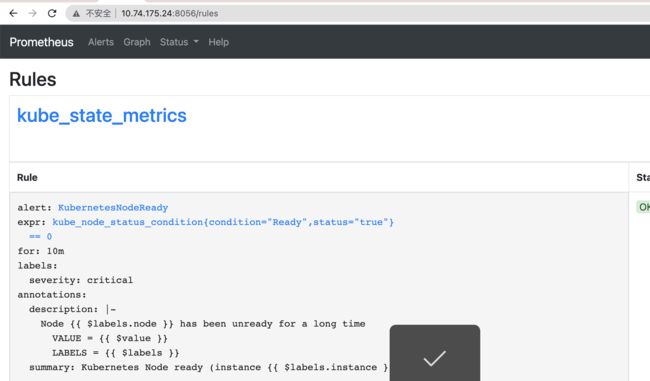
新增报警管理器(alertmanager)配置,让产生的告警发送到邮箱
上面配置完毕的规则后,恰好我的集群里有几个服务没有启动,所以果然出发了alarms消息,效果如图:

如果将这个报警消息通知到用户邮箱里呢?
这里就需要设置另外一个配置了。
查看当前的配置字典:
$ kubectl get configMap
NAME DATA AGE
kube-root-ca.crt 1 20d
my-prometheus-alertmanager 1 10h
my-prometheus-server 6 10h
mygrafana 1 10h
mygrafana-test 1 10h
my-prometheus-alertmanager就是我们想要的配置,同理导出然后修改即可,下面我们快速过了。
#导出配置文件
kubectl get configMap my-prometheus-alertmanager -o yaml > my-prometheus-alertmanager.yaml
如果想走邮件发送的话,调整文件如下,其他类型自行百度。
apiVersion: v1
data:
alertmanager.yml: |-
global:
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]'
smtp_auth_username: 'xxxx'
smtp_auth_password: 'xxxx#Q'
resolve_timeout: 5m
smtp_require_tls: false
route:
group_by: ['alertname']
group_interval: 5s
repeat_interval: 5s
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
- to: '[email protected]'
kind: ConfigMap
...
更新配置文件
kubectl apply -f my-prometheus-alertmanager.yaml
静等几分钟,打开邮箱看看是不是已经收到邮件了?


参考资料
https://www.cnblogs.com/sanduzxcvbnm/p/14759693.html
https://awesome-prometheus-alerts.grep.to/rules#kubernetes
https://blog.csdn.net/qq_40843231/article/details/121698566