RBF神经网络理论与实现
前言
最近发现有挺多人喜欢径向基函数(Radial Basis Function,RBF)神经网络,其实它就是将RBF作为神经网络层间的一种连接方式而已。这里做一个简单的描述和找了个代码解读。
之前也写过一篇,不过排版不好看,可以戳这里跳转
国际惯例,参考博客:
-
维基百科径向基函数
-
《模式识别与智能计算——matlab技术实现第三版》第6.3章节
-
《matlab神经网络43个案例分析》第7章节
-
tensorflow2.0实现RBF
-
numpy的实现
理论
基本思想
用RBF作为隐单元的“基”构成隐藏层空间,隐藏层对输入矢量进行变换,将低维的模式输入数据变换到高维空间内,使得在低维空间内的线性不可分问题在高维空间内线性可分。
详细一点就是用RBF的隐单元的“基”构成隐藏层空间,这样就可以将输入矢量直接(不通过权连接)映射到隐空间。当RBF的中心点确定以后,这种映射关系也就确定 了。而隐含层空间到输出空间的映射是线性的(注意这个地方区分一下线性映射和非线性映射的关系),即网络输出是隐单元输出的线性加权和,此处的权即为网络可调参数。
径向基神经网络的节点激活函数采用径向基函数,定义了空间中任一点到某一中心点的欧式距离的单调函数。
我们通常使用的函数是高斯函数:
ϕ ( r ) = e − ( ϵ r ) 2 \phi(r) = e^{-(\epsilon r)^2} ϕ(r)=e−(ϵr)2
在《Phase-Functioned Neural Networks for Character Control》论文代码中有提到很多径向基函数:
kernels = {
'multiquadric': lambda x: np.sqrt(x**2 + 1),
'inverse': lambda x: 1.0 / np.sqrt(x**2 + 1),
'gaussian': lambda x: np.exp(-x**2),
'linear': lambda x: x,
'quadric': lambda x: x**2,
'cubic': lambda x: x**3,
'quartic': lambda x: x**4,
'quintic': lambda x: x**5,
'thin_plate': lambda x: x**2 * np.log(x + 1e-10),
'logistic': lambda x: 1.0 / (1.0 + np.exp(-np.clip(x, -5, 5))),
'smoothstep': lambda x: ((np.clip(1.0 - x, 0.0, 1.0))**2.0) * (3 - 2*(np.clip(1.0 - x, 0.0, 1.0)))
}
下图是径向基神经元模型
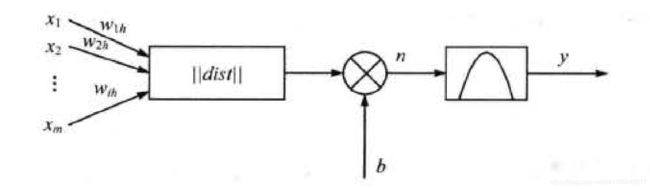
径向基函数的激活函数是以输入向量和权值向量(注意此处的权值向量并非隐藏层到输出层的权值,具体看下面的径向基神经元模型结构)之间的距离||dist||作为自变量的,图中的b为阈值,用于调整神经元的灵敏度。径向基网络的激活函数的一般表达式为
R ( ∥ d i s t ∥ ) = e − ∥ d i s t ∥ R(\parallel dist \parallel) = e^{-\parallel dist \parallel} R(∥dist∥)=e−∥dist∥
下图是以高斯核为径向基函数的神经元模型:
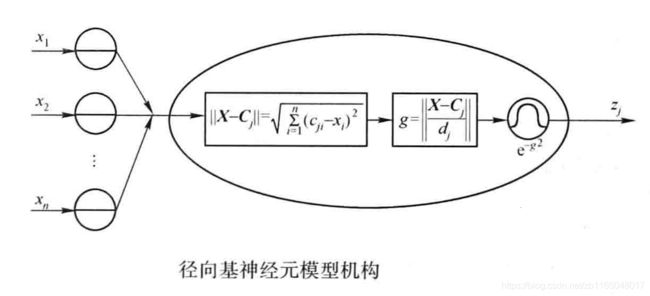
对应到激活函数表达式:
R ( x p − c i ) = exp ( − 1 2 σ 2 ∥ x p − c i ∥ 2 ) R(x_p-c_i)=\exp{\left(-\frac{1}{2\sigma^2}\parallel x_p - c_i \parallel^2 \right)} R(xp−ci)=exp(−2σ21∥xp−ci∥2)
其中X代表输入向量,C代表权值,为高斯函数的中心, σ \sigma σ是高斯函数的方差,可以用来调整影响半径(仔细想想高斯函数中 c c c和 σ \sigma σ调整后对函数图的影响);当权值和输入向量的距离越小,网络的输出不断递增,输入向量越靠近径向基函数的中心,隐层节点产生的输出越大。也就是说径向基函数对输入信号在局部产生响应,输入向量与权值距离越远,隐层输出越接近0,再经过一层线性变换映射到最终输出层,导致输出层也接近0。
结构
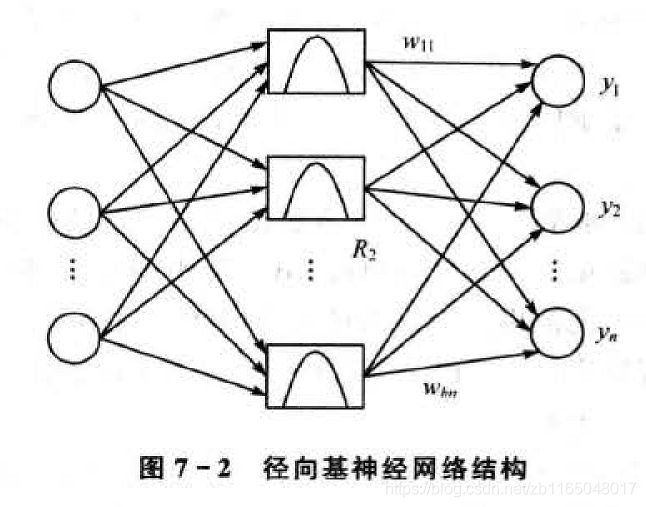
RBF是具有单隐层的三层前向网络。
-
第一层为输入层,由信号源节点组成。
-
第二层为隐藏层,隐藏层节点数视所描述问题的需要而定,隐藏层中神经元的变换函数即径向基函数是对中心点径向对称且衰减的非负线性函数,该函数是局部响应函数,具体的局部响应体现在其可见层到隐藏层的变换是通过径向基函数计算,跟其它的网络不同。以前的前向网络变换函数都是全局响应的函数。
-
第三层为输出层,是对输入模式做出的响应。
输入层仅仅起到传输信号作用,输入层和隐含层之间可以看做连接权值为1的连接,输出层与隐含层所完成的任务是不同的,因而他们的学习策略也不同。输出层是对线性权进行调整,采用的是线性优化策略,因而学习速度较快;而隐含层是对激活函数(格林函数,高斯函数,一般取后者)的参数进行调整,采用的是非线性优化策略,因而学习速度较慢。
参数
径向基函数需要两组参数:
- 基函数中心
- 方差(宽度)
隐层到输出层只需要一组参数:
- 权值
优点
- 逼近能力,分类能力和学习速度等方面都优于BP神经网络
- 结构简单、训练简洁、学习收敛速度快、能够逼近任意非线性函数
- 克服局部极小值问题。原因在于其参数初始化具有一定的方法,并非随机初始化。
缺点
- 如果中心点是样本中的数据,就并不能反映出真实样本的状况,那么输入到隐层的映射就是不准确的
- 如果使用有监督学习,函数中心是学习到的,但是如果中心点选取不当,就会导致不收敛。
各层的计算
首先初始化参数:中心、宽度、权值
不同隐含层神经元的中心应有不同的取值,并且与中心的对应宽度能够调节,使得不同的输入信息特征能被不同的隐含层神经元最大的反映出来,在实际应用时,一个输入信息总是包含在一定的取值范围内。
中心
-
方法1
《模式识别与智能计算》中介绍了一种方法:将隐含层各神经元的中心分量的初值,按从小到大等间距变化,使较弱的输入信息在较小的中心附近产生较强的响应。间距的大小可由隐藏层神经元的个数来调节。好处是能够通过试凑的方法找到较为合理的隐含层神经元数,并使中心的初始化尽量合理,不同的输入特征更为明显地在不同的中心处反映出来,体现高斯核的特点:
c j i = min i + max i − min i 2 p + ( j − 1 ) max i − min i p c_{ji} = \min i + \frac{\max i-\min i}{2p}+(j-1)\frac{\max i-\min i}{p} cji=mini+2pmaxi−mini+(j−1)pmaxi−mini
其中p为隐层神经元总个数,j为隐层神经元索引,i为输入神经元索引, max i \max i maxi是训练集中第i个特征所有输入信息的最小值,$\max i $为训练集中第i个特征所有输入信息的最大值。 -
方法2
《43案例分析》中介绍的是Kmean使用方法,就是传统的算法,先随机选k个样本作为中心,然后按照欧氏距离对每个样本分组,再重新确定聚类中心,再不断重复上面的步骤,直到最终聚类中心变化在一定范围内。
宽度
宽度向量影响着神经元对输入信息的作用范围:宽度越小,相应隐含层神经元作用函数的形状越窄,那么处于其他神经元中心附近的信息在该神经元出的响应就越小;就跟高斯函数图像两边的上升下降区域的宽度一样。按照《模式识别与智能计算》,计算有点像标准差的计算(但是此处原文没有带平方,不过我觉得应该带上,详细可以查阅这个YouTube视频,不带平方,万一出现负数是无法求根的):
d j i = d f 1 N ∑ k = 1 N ( x i k − c j i ) 2 d_{ji}= d_f\sqrt{\frac{1}{N}\sum_{k=1}^N(x_i^k-c_{ji})^2} dji=dfN1k=1∑N(xik−cji)2
当然也可以用《43案例分析》里面说的,利用中心之间的最大距离 c m a x c_{max} cmax去计算,其中h是聚类中心个数:
d = c m a x 2 h d = \frac{c_{max}}{\sqrt{2h}} d=2hcmax
输入层到隐层的计算
直接套入到选择的径向基函数中:
z j = exp ( − ∣ ∣ X − C j D j ∣ ∣ 2 ) z_j = \exp\left(- \left|\left|\frac{X-C_j}{D_j} \right|\right|^2\right) zj=exp(−∣∣∣∣∣∣∣∣DjX−Cj∣∣∣∣∣∣∣∣2)
其中 C j C_j Cj就是第j个隐层神经元对应的中心向量,由隐层第j个神经元所连接的输入层所有神经元的中心分量构成,即 C j = [ C j 1 , C j 2 , ⋯ , C j n ] C_j = [C_{j1},C_{j2},\cdots,C_{jn}] Cj=[Cj1,Cj2,⋯,Cjn]; D j D_j Dj为隐层第j个神经元的宽度向量,与 C j C_j Cj对应, D j D_j Dj越大,隐层对输入向量的影响范围就越大,而且神经元间的平滑程度就更好。
隐层到输出层的计算
就是传统的神经网络里面,把核函数去掉,变成了线性映射关系:
y k = ∑ j = 1 p w k j z j y_k = \sum_{j=1}^p w_{kj}z_j yk=j=1∑pwkjzj
其中k是输出层神经元个数。
权重迭代
直接使用梯度下降法训练,中心、宽度、权重都通过学习来自适应调节更新。
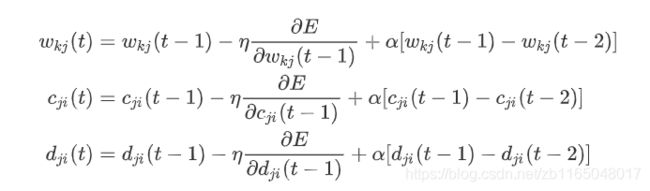
其中 η \eta η为学习率, E E E为损失函数,一般就是均方差。
训练步骤
- 先初始化中心、宽度、最后一层权重
- 计算损失,如果在接受范围内,停止训练
- 利用梯度更新的方法更新中心、宽度、权重
- 返回第二步
代码实现
有大佬利用keras实现过基于Kmeans的高斯RBF神经网络层,代码戳这里
首先利用sklearn里面的库构建一个K-means层
from keras.initializers import Initializer
from sklearn.cluster import KMeans
class InitCentersKMeans(Initializer):
""" Initializer for initialization of centers of RBF network
by clustering the given data set.
# Arguments
X: matrix, dataset
"""
def __init__(self, X, max_iter=100):
self.X = X
self.max_iter = max_iter
def __call__(self, shape, dtype=None):
assert shape[1] == self.X.shape[1]
n_centers = shape[0]
km = KMeans(n_clusters=n_centers, max_iter=self.max_iter, verbose=0)
km.fit(self.X)
return km.cluster_centers_
构建RBF层的时候,第一层初始化使用上面的Kmeans初始化
self.centers = self.add_weight(name='centers',
shape=(self.output_dim, input_shape[1]),
initializer=self.initializer,
trainable=True)
第二层用一个线性加权的层
self.betas = self.add_weight(name='betas',
shape=(self.output_dim,),
initializer=Constant(
value=self.init_betas),
# initializer='ones',
trainable=True)
计算时候:
def call(self, x):
C = K.expand_dims(self.centers)
H = K.transpose(C-K.transpose(x))
return K.exp(-self.betas * K.sum(H**2, axis=1))
但是此处我觉得有问题,这里的宽度向量好像没有体现出来,所以我重写了一个:
def call(self, x):
C = K.expand_dims(self.centers)
XC = K.transpose(K.transpose(x)-C)
D = K.expand_dims(K.sqrt(K.mean(XC**2,axis=0)),0)
H = XC/D
return K.exp(-self.betas * K.sum(H**2, axis=1))
可以看原作者的代码,作者是用于二维数据的拟合;
也可以看我的代码,基于原作者代码,做的二维数据分类

小点为训练集,大圆点为测试集
后记
RBF可以用于插值、分类;在论文《Phase-Functioned Neural Networks for Character Control》还用来更改地形,也就是说图形、图像通用,说明还是蛮重要的。这里主要介绍了一下理论,后续再去做扩展性研究。
完整的python脚本实现放在微信公众号的简介中描述的github中,有兴趣可以去找找,同时文章也同步到微信公众号中,有疑问或者兴趣欢迎公众号私信。
