程序设计与数据结构笔记01
一、程序设计基础
前提:
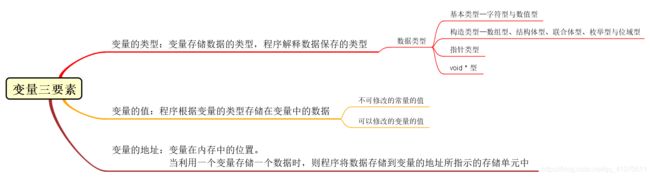
变量三要素:
- 变量的类型
- 变量的值
- 变量的地址
1.1 程序设计思想
①、抽象化
实际的应用程序中可能会用到成千上万个函数,为了保证结果正确性,须保持处理与数据的一贯性——数据抽象技术(数据与处理方法的结合,对数据的处理和操作,必须通过定义好的方法进行)。
面向过程编程引入了抽象模块的概念,由此可说程序是由模块构成,而模块又是由函数构成,一个模块就是一个过程。由于不同结构中的数据是由函数或过程管理,因此在设计的时候就可以对这些模块分别进行抽象、设计、编码和测试,最后将这些模块有机地组合在一起形成完整的程序。
②、功能分解法
功能分解法:将复杂问题,分解为多个小问题,分成多个子模块,解决每个小问题,实现每个子模块。最后通过主函数按照某种次序调用这些子模块,组织业务逻辑流程,最终解决问题。
结构化/面向过程编码——从问题出发,自顶而下逐步求精利用算法作为基本构建块构建复杂系统的开发方法。

面向对象编码作为对抗软件复杂性手段出现的。
补充:
面向过程与面向对象编程的区别:
面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了;
面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
例子:-拿生活中的实例来理解面向过程与面向对象,例如五子棋,
——面向过程的设计思路就是首先分析问题的步骤:1、开始游戏,2、黑子先走,3、绘制画面,4、判断输赢,5、轮到白子,6、绘制画面,7、判断输赢,8、返回步骤2,9、输出最后结果。把上面每个步骤用不同的方法来实现。
——如果是面向对象的设计思想来解决问题。面向对象的设计则是从另外的思路来解决问题。整个五子棋可以分为1、黑白双方,这两方的行为是一模一样的,2、棋盘系统,负责绘制画面,3、规则系统,负责判定诸如犯规、输赢等。第一类对象(玩家对象)负责接受用户输入,并告知第二类对象(棋盘对象)棋子布局的变化,棋盘对象接收到了棋子的变化就要负责在屏幕上面显示出这种变化,同时利用第三类对象(规则系统)来对棋局进行判定。
总之,
可以看出,面向对象是以功能来划分问题,而不是步骤。同样是绘制棋局,这样的行为在面向过程的设计中分散在了多个步骤中,很可能出现不同的绘制版本,因为通常设计人员会考虑到实际情况进行各种各样的简化。而面向对象的设计中,绘图只可能在棋盘对象中出现,从而保证了绘图的统一。
③、程序 语言——构建通用语言的过程就是自我思维训练和建立逻辑推理的过程

1.2 变量与指针
1.2.1 变量
①、
变量三要素:
- 变量的类型
- 变量的值
- 变量的地址
读写变量过程:
从变量中取值:通过变量名找到相应的存储地址,然后读取该存储单元中的值,
写变量:将变量的值存放到与之相应的存储地址中。
对象:用于存储数据的“位置”。
声明:命名一个对象的一条语句。
定义:为一个对象分配内存空间的声明,一个定义通常会提供一个初始值。
②、变量的指针与指针
&操作符返回操作数的地址,如 int INum=0x64;&iNum就是变量iNum的内存地址
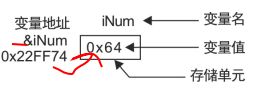
指针:用于存储变量的内存地址的&iNum 抽象为指向变量iNum的指针。本质就是一个内存地址,指向内存的某个位置。
左值与右值:
L-value =“locator value”——在内存中有特定位置的值,即内存的索引值——地址。
R-value=“read value”——可读的值
如:int INum=0x64
L-value =&iNum
R-value=0x64
③ 、 变量的存储
LSB:最低有效位,如D0
MSB:最高有效位,如D31
![]()

CPU采用哪种存储模式取决于硬件,与编译器无关

④ 、 变量类型别名
typedef :声明类型的别名,只是为某个已经存在的类型增加一个新的名字。可以提高程序可移植性
&
使用typedef构造新的数据类型
1.2.2 程序转为机器执行
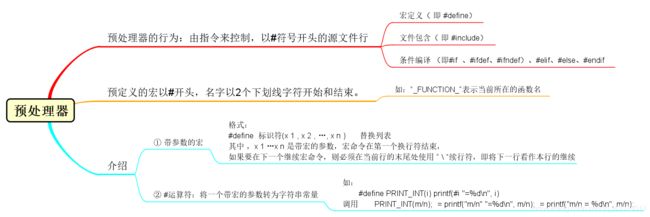
①、将程序转为机器执行的形式,对C程序分为4个步骤:
- 预处理:首先程序会被送交给预处理器,预处理器执行#开头的指令,将C语言转换为可执行的程序
- 编译:完成一定的翻译工作,将一种格式转换成另外一种格式
- 汇编:将C 转为汇编语言。
- 链接:链接器将由编译器产生的目标代码和所需要的其他附加代码整合到一起,产生最终完全可执行的程序,其中的附加代码包括程序中的库函数。
参考:
1.3 指针变量与指针的指针
1.3.1 变量的声明
①、指针变量
- 指针变量:值为内存地址的变量。
- ” * “( 重过载符号 )将变量声明为指针。
- 当声明一个指针时,仅仅只是为了指针本身分配了空间,并没有为指针所引用的数据分配空间。
- 虽然指针不可变,但其
指向的数据可变。
int iNum=0x64;
int *ptr=&iNum; / ptr 与&iNum的值相同,但类型不同
ptr 类型为: int *, &iNum 类型为 int *const — — &iNum是指向非常量的常量指针,
- 声明多个指针时要加上”*“
❌ 错误:
int* ptr1, ptr2; /ptr1是int型的指针,而ptr2是int型的常量,
✔ 正确:
int* ptr1, *ptr2;
- 指针变量类型别名
✔正确:
typedef int *PINT;
PINT ptr1, ptr2; = int *ptr1, *ptr2;
❌ 不用#define
#define PINT int
PINT ptr1, ptr2; = int * ptr1, ptr2; /ptr2 是int型,
原因:
#define ,仅在编译前对源代码进行字符串替代。
typedef,建立了一个新的数据类型别名
const知识:
const修饰:紧跟在它后面的单词,
如:
☺const int a[2] ={5, 2};将数组a的元素修饰为只读(值保持不变),而不是变量a修饰为只读
☺ char * const src 将 src 自身修饰为只读
☺ const char * const srcā :将str和str指向的值都修饰为只读。
✔ 当指针转为传递参数时,const 常用于将指针指向的对象设定为只读
✔只读变量与指令一起保存在”只读段“,而变量保存在”读写段“
②、NULL
当指针不指向任何地方时(此时指针相当危险,等于使用了随机生成的地址,使用此数值会导致程序崩溃或数据损坏),就必须在使用指针前将他初始化为NULL 空指针,
int *ptr = NULL;
可使用 assert 测试指针是否为空。
assert(ptr != NULL);
NULL 与 NUL比较:
NULL : #define NULL ((void *)0) 是空字符,不包含任何字符。
NUL:ASCII 字符,定义为全0 字节
✉总结:
- 变量是值的表现形式,值实际上存储在一个特定的地址,有了变量的地址,只要在程序运行时
将数据块的位置(内存地址)传递给函数即可。 - 当一个变量存储另外一个变量的地址,——说其指向了某个变量
1.3.2 变量的访问

强制转换补充:
/**/例子/**/
unsigned int a = 5, b;
b = (unsigned int)&a;
/**/
/**/将数据0x05存入绝对地址0x22FF74 /**/
*(unsigned int *)0x22FF74 = 0x05;
printf("*(unsigned int *)0x22FF74 = 0x%x\n", *(unsigned int *)0x22FF74);
/**/
/**/判别类型名 /**/
void (*func)(); /类型名:void (*)(),是将void (*func)();的标识符func 去掉形成。
/该类型名解释为指向返回void函数的指针,func 是指向返回void函数的指针。
/**/
1.3.3 指针的访问
int iNum = 0x64;
int *ptr = &iNum;
int **pPtr = &ptr;
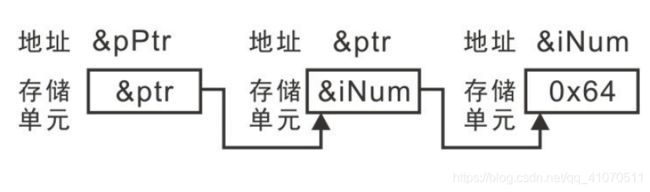
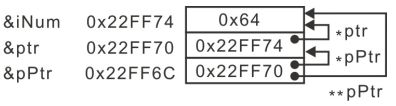
恒成立:
*pPtr ==*(&ptr) == ptr == &iNum
**pPtr == *ptr == *(&iNum) == iNum
1.4 简化表达式
介绍几种可以简化重构就是,
核心:分解条件语句,将一个条件语句拆分为多个部分
①、逻辑表达式
短路运算:如果第一个表达式是布尔型且返回为F(逻辑与&&)or 为T,(逻辑或)则第二个表达式将不会计算。
if(x !=0 && 10 / x < 2) /先判断x 是否为0,=0 为F,则直接跳过,不会接着判断。
if( value != 2 || value !=3 ) /先判断value是否为2,如果!=2 为T,就不用接着判断
恒成立
!(a || b || c) == (!a)&& (!b) && (!c)
!(a && b && c) ==(!a) || (!b) || (!c)
因为优先级关系,最好在表达式加括号。
if((x & MASK) == BITS)
②、条件表达式
cond ? a : b
如:
time_str += (hour >= 12) ? "pm" : "am";
1.5 共性与可变性分析CVA
— —怎样在问题中找到不同的变化,共性分析寻找不可能随时间而改变的结构,可变性分析找到可能变化的结构(只在相关联共性分析定义的上下文有意义)。
从架构的视角来看,共性分析为架构提供长效的要素,而可变分析则促 进他适应实际使用所需。也就是说,如果变化是问题领域中各个特定的具体情况,共性就定义了问题领域中将这些情况联系起来的概念。
eg.“粉笔、铅笔、圆珠笔”
共性:书写工具
变性:材料、用途
共同的概念将用抽象类表示,可变性分析所发现的变化将通过具体类实现。
名词动词分析法,常常得的比较大的类层次结构。
1概念视角、2规约视角、3实现视角
共性分析占了1和2
变性分析占了2和3
1.5.1 分析方法
- 从问题出发分析
int a = 1, b = 2;
5 int temp;
6
7 printf("%d, %d \n", a, b);
8 temp = a; a = b; b = temp;
9 printf("%d, %d \n", a, b);
10 return 0;
可将 temp = a; a = b; b = temp; 编写成函数来组织代码,以便重复使用,
1.5.2 抽象建立
——抽象化(黑盒化):目的使调用者无需知道模块内部的细节,只需要知道模块或函数的名字。
调用者只需要知道黑盒子的输入与输出,而过程使隐藏的。
——————————————————————————
参考文献:
1、面向过程与面向对象编程的区别和优缺点:https://www.cnblogs.com/strivers/p/6681876.html
2、程序设计与数据结构,周立功,周攀峰著
3、gcc工作流程:
https://blog.csdn.net/PPPYZ/article/details/78156968
4、共性与可变性分析
https://blog.csdn.net/iteye_11196/article/details/81554604?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
https://blog.csdn.net/chenxiang0207/article/details/8195142