Node.js全栈开发笔记与心得
highlight: a11y-dark
一、Node.js 全栈开发资料
1、前端入门基础
- 慕课网HTML +CSS入门
- 慕课网JS入门
- javascript进阶篇
- 菜鸟教程html部分
- 菜鸟教程CSS部分
- 阮一峰js入门
- 阮一峰es6教程
2、node 后端入门基础
- node入门
- Linux基础知识
- mysql数据库知识
- 数据库事务
- sequelize中文文档
- Express框架官方文档
- Koa官方文档
- koa框架教程
- Egg.js官网
3、深入浅出Node.js-朴灵
- 链接:https://pan.baidu.com/s/1AemxH7lLl30DnqwItmRhPA
- 提取码:nbso
4、vue学习资料
- vue官方文档
- 视频教程
- vuex官方文档
- vue-router官方文档
- axios中文文档
- ElementUI官方文档
- webpack官方文档
- webpack5视频教程
5、flex布局 - flex 布局教程:语法篇
- Flex 布局教程:实例篇
- flexb布局视频教程
二、JSON
1、JSON教程
2、JSON.stringfy() 和 JSON.parse()
2.1 JSON.stringfy() 将对象、数组转换成 JSON字符串
- 概述:
JSON.stringfy()方法是将一个JavaScript值(对象或者数组)转换为一个 JSON 字符串,如果指定了replacer是一个函数,则可以选择性的替换值,或者如果指定了replacer是一个数组,可选择性的仅包含数组指定的属性。
```js
1.转换值如果有toJSON()方法,该方法定义什么值将被序列化。
2.非数组对象的属性不能保证以特定的顺序出现在序列化后的字符串中。
3.布尔值、数字、字符串的包装对象在序列化过程中会自动转换成对应的原始值。
4.undefined 任意的函数以及 symbol 值,在序列化过程中会被忽略(出现在非数组对象的属性值中时)或者被转换成 null(出现在数组中时)。函数、undefined被单独转换时,会返回undefined,JSON.stringify(function(){}) or JSON.stringify(undefined).
5.对包含循环引用的对象(对象之间相互引用,形成无限循环)执行此方法,会抛出错误。
6.所有以 symbol 为属性键的属性都会被完全忽略掉,即便 replacer 参数中强制指定包含了它们。
7.Date日期调用了toJSON()将其转换为了string字符串(同Date.toISOString()),因此会被当做字符串处理。
8.NaN和Infinity格式的数值及null都会被当做null。
9.其他类型的对象,包括Map/Set/weakMap/weakSet,仅会序列化可枚举的属性。
```
-
例子:
JSON.stringify({}); // '{}' JSON.stringify(true); // 'true' JSON.stringify("foo"); // '"foo"' JSON.stringify([1, "false", false]); // '[1,"false",false]' JSON.stringify({ x: 5 }); // '{"x":5}' JSON.stringify({x: 5, y: 6}); // "{"x":5,"y":6}" JSON.stringify([new Number(1), new String("false"), new Boolean(false)]); // '[1,"false",false]' JSON.stringify({x: undefined, y: Object, z: Symbol("")}); // '{}' JSON.stringify([undefined, Object, Symbol("")]); // '[null,null,null]' JSON.stringify({[Symbol("foo")]: "foo"}); // '{}' JSON.stringify({[Symbol.for("foo")]: "foo"}, [Symbol.for("foo")]);// '{}' JSON.stringify( {[Symbol.for("foo")]: "foo"}, function (k, v) { if (typeof k === "symbol"){ return "a symbol"; } } ); // undefined // 不可枚举的属性默认会被忽略: JSON.stringify( Object.create( null, { x: { value: 'x', enumerable: false }, y: { value: 'y', enumerable: true } } ) ); // "{"y":"y"}"- 语法:JSON.stringfy(value [,replacer] [,space])
- value 是必选字段,就是输入对象,比如数组,类等。
- replacer: 可选的,它又分为2种方式,一种是数组,一种是方法
replacer参数可以是一个函数或者一个数组。作为函数,它有两个参数,键(key)值(value)都会被序列化。
1.如果返回一个 Number, 转换成相应的字符串被添加入JSON字符串。 2.如果返回一个 String, 该字符串作为属性值被添加入JSON。 3.如果返回一个 Boolean, "true" 或者 "false"被作为属性值被添加入JSON字符串。 4.如果返回任何其他对象,该对象递归地序列化成JSON字符串,对每个属性调用replacer方法。除非该对象是一 个函数,这种情况将不会被序列化成JSON字符串。 5.如果返回undefined,该属性值不会在JSON字符串中输出。 注意: 不能用replacer方法,从数组中移除值(values),如若返回undefined或者一个函数,将会被null取 代。情况一:
replacer为数组时,它是和第一个参数value有关系的。一般来说,序列化后的结果是通过键值对来进行表 示的。所以,如果此时第二个参数的值在第一个存在,那么就以第二个参数的值做key,第一个参数的值为 value进行表示,如果不存在,就忽略。``` 1、第二个参数的值在第一个存在 var str = {"name" : "张三", "site": "http://www.baidu.com"} const str_pretty1 = JSON.stringify(str, ["name","site"]) console.log(str_pretty1) 输出结果:{"name":"张三","site":"http://www.baidu.com"} 2、第二个参数的值在第一个不存在 var str = {"name" : "张三", "site": "http://www.baidu.com"} const str_pretty1 = JSON.stringify(str, ["username","address"]) console.log(str_pretty1) 输出结果:{} 3、不写第二个参数 var str = {"name" : "张三", "site": "http://www.baidu.com"} const str_pretty1 = JSON.stringify(str) console.log(str_pretty1) 输出结果:{"name":"张三","site":"http://www.baidu.com"} ```情况二:
replacer为方法时,那很简单,就是说把序列化后的每一个对象(记住是每一个)传进方法里面进行处理。``` function replacer(key, value) { if (typeof value === "string") { return undefined } return value } const foo = { name: "张三", age: 18, sex: "女", address: "吉祥村" } const jsonString = JSON.stringify(foo, replacer) console.log(jsonString) JSON序列化的结果为: {"age":18} ```-
space: 就是用什么来做分割符的。
1.如果省略的话,那么显示出来的值就没有分隔符,直接输出来 。 2.如果是一个数字的话,那么它就定义缩进几个字符,当然如果大于10 ,则默认为10,因为最大值为10。 3.如果是一些转义字符,比如“\t”,表示回车,那么它每行一个回车。 4.如果仅仅是字符串,就在每行输出值的时候把这些字符串附加上去。当然,最大长度也是10个字符。```js const strSpace = JSON.stringify({ a: 1, b: 2 }, null, '\t') console.log(strSpace) 输出结果: { "a": 1, "b": 2 } ``` -
返回值: 一个给定值的 JSON 字符串
2.2 JSON.parse() 将JSON字符串转换成JavaScript对象 -
概述
JSON通常用于与服务端交换数据,在接收服务端数据时一般是字符串,
我们可以使用 JSON.parse()方法将数据转换为 JavaScript 对象。 -
语法:JSON.parse(text [, reviver])
-
参数
- text 必需。 一个有效的 JSON 字符串。
- reviver
可选。 一个转换结果的函数。将为对象的每个成员调用此函数。如果成员包含嵌套对象,则先于父对象转换 嵌套对象。对于每个成员,会发生以下情况:如果 reviver 返回一个有效值,则成员值将替换为转换后的 值。如果 reviver 返回它接收的相同值,则不修改成员值。如果 reviver 返回 null 或 undefined,则删除成员。
-
返回值:
一个对象或数组。var string = { "name" : "张三", "sex" : "女", "address" : "吉祥村" } var obj = JSON.parse('{ "name" : "张三", "sex" : "女", "address" : "吉祥村" }') console.log(obj) 输出结果: { name: '张三', sex: '女', address: '吉祥村' } 注意:解析前要确保你的数据是标准的 JSON 格式,否则会解析出错
- 语法:JSON.stringfy(value [,replacer] [,space])
3、toJSON()
3.1定义和用法
- toJSON()方法可以将 Date 对象转换为字符串,并格式化为 JSON 数据格式
- JSON 数据用同样的格式就像x ISO-8601 标准: YYYY-MM-DDTHH:mm:ss.sssZ
3.2实例
```js
const d = new Date()
const a = d.toJSON()
console.log(a)
输出结果: 2022-01-01T11:40:13.147Z
```
如果一个被序列化的对象拥有 toJSON 方法,那么该 toJSON 方法就会覆盖该对象的序列化行为:不是那个对象被序列化,而是调用 toJSON 方法后的返回值会被序列化。
例如:
```js
var obj = {
foo: 'foo',
toJSON: function() {
return 'bar'
}
}
const stringFy = JSON.stringify(obj)
console.log(stringFy) // "bar"
const string = JSON.stringify({ x: obj })
console.log(string) // {"x":"bar"}
```
4、localStorage/sessionStorage/Cookie的区别及用法
4.1webstorage
webstorage是本地存储,存储在客户端,包括 localStorage和sessionStorage
4.2localStorage
localStorage生命周期是永久,这意味着除非用户显示在浏览器提供的UI上清除localStorage信息,否则这些信息将永远存在。存放数据大小为一般为5MB,而且它不仅在客户端(即浏览器)中保存,不参与和服务器的通信。
4.3sessionStorage
sessionStorage仅在当前会话下有效,关闭页面或浏览器后被清除。存放数据大小为一般为5MB,而且它仅在客户端(即浏览器)中保存,不参与和服务器的通信。源生接口可以接受,亦可再次封装来对Object和Array有更好的支持。
localStorage和sessionStorage使用时使用相同的API:
localStorage.setItem("key","value");//以“key”为名称存储一个值“value”
localStorage.getItem("key"); //获取名称为“key”的值
localStorage.removeItem("key"); //删除名称为“key”的信息。
localStorage.clear(); //清空localStorage中所有信息
- 作用域不同
不同浏览器无法共享localStorage或sessionStorage中的信息。相同浏览器的不同页面间可以共享相同的 localStorage(页面属于相同域名和端口),但是不同页面或标签页间无法共享sessionStorage的信息。这里需要注意的是,页面及标签页仅指顶级窗口,如果一个标签页包含多个iframe标签且他们属于同源页面,那么他们之间是可以共享sessionStorage的。
- Cookie
生命期为只在设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭。存放数据大小为4K左右。有个数限制(各浏览器不同),一般不能超过20个。与服务器端通信:每次都会携带在HTTP头中,如果使用cookie保存过多数据会带来性能问题。但Cookie需要程序员自己封装,源生的Cookie接口不友好(http://www.jb51.net/article/6…
)。
//Cookie方法
<script src="../js/cookie.js"></script> //Cookie函数自己封装引入
function foo(){
if(getCookie("isClose")){
$(".header").hide();
}else{
$(".header").show();
}
$(".close").click(function(){
$(".header").fadeOut(1000);
setCookie("isClose", "1","s10");
})
}
foo();
cookie的优点:具有极高的扩展性和可用性
1.通过良好的编程,控制保存在cookie中的session对象的大小。
2.通过加密和安全传输技术,减少cookie被破解的可能性。
3.只有在cookie中存放不敏感的数据,即使被盗取也不会有很大的损失。
4.控制cookie的生命期,使之不会永远有效。这样的话偷盗者很可能拿到的就是一个过期的cookie。
cookie的缺点:
1.cookie的长度和数量的限制。每个domain最多只能有20条cookie,每个cookie长度不能超过4KB。否则会被截掉。
2.安全性问题。如果cookie被人拦掉了,那个人就可以获取到所有session信息。加密的话也不起什么作用。
3.有些状态不可能保存在客户端。例如,为了防止重复提交表单,我们需要在服务端保存一个计数器。若吧计数器保存在客户端,则起不到什么作用。
- localStorage、sessionStorage、Cookie共同点:都是保存在浏览器端,且同源的。
- 使用 JSON.stringify 结合 localStorage 的例子
一些时候,你想存储用户创建的一个对象,并且,即使在浏览器被关闭后仍能恢复该对象。下面的例子是 JSON.stringify 适用于这种情形的一个样板:
// 创建一个示例数据
var session = {
'screens': [],
'state': true
};
session.screens.push({"name":"screenA", "width":450,"height":250})
session.screens.push({"name":"screenB", "width":650, "height":350})
session.screens.push({"name":"screenC", "width":750,"height":120})
// 使用 JSON.stringify 转换为 JSON 字符串
// 然后使用 localStorage 保存在 session 名称里
localStorage.setItem('session', JSON.stringify(session));
// 然后是如何转换通过 JSON.stringify 生成的字符串,该字符串以 JSON 格式保存在 localStorage 里
var restoredSession = JSON.parse(localStorage.getItem('session'));
// 现在 restoredSession 包含了保存在 localStorage 里的对象
console.log(restoredSession);
三、Vue.js
1、vue 脚手架项目搭建
- 全局安装脚手架
npm install -g @vue/cli
-低版本安装
npm install -g @vue/cli-init
- 在想要创建项目的目录下打开cmd命令行(选择需要安装的一个版本即可)
注:hello-word是我要安装的项目名,根据实际需求更改项目名
(1) 3.X版本安装(不会看到webpack的配置文件)
vue create hello-world
- 安装步骤
(1)3.X安装步骤:
①、系统将提示您选择预设:
可以选择基本Babel + ESLint设置附带的默认预设,也可以选择“手动选择功能”以选择所需的功能 (推荐选择第二个,手动选择)
②、根据个人需要选择配置项(选择方法:空格即可)
③、路由是否选择history模式(推荐选择 y,如果选择n,路由将默认为hash模式)
④、selint语法选择(推荐选择eslint+standard config:标准模式)
⑤、检测方式(推荐选择lint on sava)
⑥、文件类型(推荐使用json)
⑦、保存当前的配置为预设,以供未来使用(推荐使用 y)
⑧、保存预设并命名
(2)低版本安装步骤:
前面四步都可以一路回车,第五步询问是否安装vue-router,选择是,第六步使用eslint代码检查,根据个人情况选择是或否,第七步设置单元测试,选择否,第八步测试监听,选择否,第九步选择npm即可,等待安装完成
(其实安装都没有固定的步骤,完全根据个人项目需求,这里只是推荐大众化的步骤)
链接:https://juejin.cn/post/6844904037674909709
- 文件夹详解
(1)、src文件夹放置所有的资源文件,一般会被webpack用来打包
①assets文件夹放置资源文件,如:css,js,fonts
②components文件夹放置所有的子组件,即每个页面级组件的子组件,例如:index页面级组件,把它分为header、content、footer三部分,只要在components文件夹下新建一个index文件夹(为了区分其他组件),放入对应的子组件
③pages文件夹放置所有的页面级组件
④router文件夹中index用来配置路由信息
⑤main.js是入口文件,可在此引入公共的样式等
(2)、static放置的资源文件不会最终被weback打包(一般放置图片文件和本地模拟的json数据)
├── node_modules\
├── public\
│ ├── favicon.ico: 页签图标\
│ └── index.html: 主页面\
├── src\
│ ├── assets: 存放静态资源\
│ │ └── logo.png\
│ │── component: 存放组件\
│ │ └── HelloWorld.vue\
│ │── App.vue: 汇总所有组件\
│ │── main.js: 入口文件\
├── .gitignore: git版本管制忽略的配置\
├── babel.config.js: babel的配置文件\
├── package.json: 应用包配置文件\
├── README.md: 应用描述文件\
├── package-lock.json:包版本控制文件
- 更改配置
(1)、更改App.vue文件
<template>
<div id="app">
<img src="/static/logo.png">
<router-view/>
</div>
</template>
更改为:(目的:插入一个路由插槽,进行页面的跳转,显示不同的路由)
<template>
<router-view></router-view>
</template>
(2)、更改main.js文件
new Vue({
el: '#app',
router,
components: { App },
template: '- 项目启动方式
(1)3.X版本启动方式
npm run serve
(2)低版本启动方式
npm run dev
2、插件
- 概念
插件通常用来为 vue 添加全局功能。插件的功能范围没有严格的限制,一般有下面几种:
```js
1.添加全局方法或者属性。如:vue-custom-element
2.添加全局资源:指令/过滤器/过度等。如:vue-touch
3.通过全局混入来添加一些组件选项。如: vue-router
4.添加 Vue 实例方法,通过把它们添加到 Vue.prototype 上实现。
5.一个库,提供自己的 API,同时提供上面提到的一个或多个功能。如: vue-router
```
- 使用方法
通过全局方法 Vue.use() 使用插件。它需要在你调用 new Vue() 启动应用之前完成:
```js
// 调用 MyPlugin.install(Vue)
Vue.use(MyPlugin)
new Vue({
// ...组件选项
})
```
为防止多次注册同一个组件:我们可以传递一个可选的对象
```js
Vue.use(MyPlugin, { someOption: true })
```
Vue.use会自动阻止多次注册相同插件,届时即使多次调用也只会注册一次该插件
- 注意点:
Vue.js 官方提供的一些插件 (例如 vue-router) 在检测到 Vue 是可访问的全局变量时会自动调用 Vue.use()。然而在像 CommonJS 这样的模块环境中,你应该始终显式地调用 Vue.use():
```js
// 用 Browserify 或 webpack 提供的 CommonJS 模块环境时
var Vue = require('vue')
var VueRouter = require('vue-router')
// 不要忘了调用此方法
Vue.use(VueRouter)
```
2.1 nextTick
- 语法
this.$nextTick(回调函数) - 作用
在下一次 DOM 更新结束后执行其指定的回调。什么时候用:当改变数据后,要基于更新后的新DOM进行某些操 作时,要在nextTick所指定的回调函数中执行。
3、flex布局
3.1 flex 布局体验
-
传统布局与 flex 布局
- 传统布局
1.兼容性好 2.布局繁琐 3.局限性,不能在移动端很好的布局- flex 布局
1.操作方便,布局极为简单,移动端应用很广泛 2.PC 端浏览器支持情况较差 3.IE 11 或更低版本,不支持或仅部分支持-
初体验

<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> <style> div { display: flex; width: 80%; height: 300px; background-color: pink; justify-content: space-around; } div span { /* width: 150px; */ height: 100px; background-color:purple; margin-right: 5px; flex: 1; } </style> </head> <body> <div> <span>1</span> <span>2</span> <span>3</span> </div> </body> </html>
3.2 flex 布局原理
- 布局原理
flex 是 flexible Box 的缩写,意为“弹性布局”,用来为盒状模型提供最大的灵活性,任何一个容器都可以 指定为 flex 布局。
1.当我们为父盒子设为 flex 布局以后,子元素的 float、clear 和 vertical-align 属性将失效。
2.伸缩布局 === 弹性布局 === 伸缩盒布局 === 弹性盒布局 === flex 布局
采用 Flex 布局的元素,称为 Flex 容器 (flex container),简称“容器”。它的所有子元素自动成为容器成员, 称为 Flex 项目(flex item), 简称“项目”
1.体验中 div 就是 flex 父容器
2.体验中 span 就是 子容器 flex 项目
3.子容器可以横向排列也可以纵向排列

总结 flex 布局原理:就是通过给父盒子添加 flex 属性,来控制子盒子的位置和排列方式
3.3 flex 布局父项常见属性
- 常见父项属性
以下有6个属性是对父元素设置的
1.flex-direction: 设置主轴的方向
2.justify-content: 设置主轴上的子元素排列方式
3.flex-warp: 设置子元素是否换行
4.align-content: 设置侧轴上的子元素的排列方式(多行)
5.align-items: 设置侧轴上的子元素排列方式(单行)
6.flex-flow: 复合属性,相当于同时设置了 flex-direction 和 flex-warp
- flex-direction 设置主轴的方向
- 主轴与侧轴
在 flex 布局中,是分为主轴和侧轴两个方向,同样的叫法有:行和列、x 轴和 y 轴
- 主轴与侧轴
1.默认主轴方向就是 x 轴方向,水平向右
2.默认侧轴方向就是 y 轴方向,水平向下

- 属性值
flex-direction属性决定主轴的方向(即项目的排列方向)
注意:主轴和侧轴是会变化的,就看 flex-direction设置为主轴,剩下的就是侧轴,而我们的子元素是跟着主轴来排列的
| 属性值 | 说明 |
|---|---|
| row | 默认值从左到有 |
| row-reverse | 从右到左 |
| column | 从上到下 |
| column-reverse | 从下到上 |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div {
/* 给父级添加 flex 属性 */
display: flex;
width: 800px;
height: 300px;
background-color: pink;
/* 默认的主轴是 x 轴 行 row 那么 y 轴就是侧轴*/
/* 我们的元素是跟着主轴来排列的 */
/* flex-direction: row; */
/* 翻转 */
/* flex-direction: row-reverse; */
/* 主轴设置为 y 轴,那么 x 轴就成了侧轴 */
flex-direction: column;
}
div span {
width: 150px;
height: 100px;
background-color: purple;
}
</style>
</head>
<body>
<div>
<span>1</span>
<span>2</span>
<span>3</span>
</div>
</body>
</html>
- justify-content 设置主轴上的子元素排列方式
1.justify-content 属性定义了项目在主轴上的对齐方式
注意:使用这个属性之前一定要确定好主轴是那个
| 属性值 | 说明 |
|---|---|
| flex-start | 默认值从头部开始 如果主轴是 x 轴,则从左到右 |
| flex-end | 从尾部开始排序 |
| center | 在主轴居中对齐(如果主轴是x轴则水平居中) |
| space-around | 平分剩余空间 |
| space-between | 先两边贴边 再平分剩余空间(重要) |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div {
display: flex;
width: 80%;
height: 300px;
background-color: pink;
/* 默认的主轴是 x 轴 row */
flex-direction: row;
/* justify-content: 是设置主轴多行子元素的排列方式 */
/* justify-content: flex-start */
/* justify-content: end; */
/* 让子元素居中对齐 */
/* justify-content: center; */
/* 平分剩余空间 */
/* justify-content: space-around; */
/* 先两边贴边,在分配剩余空间 */
justify-content: space-between;
}
div span {
width: 150px;
height: 100px;
background-color:purple;
margin-right: 5px;
}
</style>
</head>
<body>
<div>
<span>1</span>
<span>2</span>
<span>3</span>
<span>4</span>
</div>
</body>
</html>
- flex-warp 设置子元素是否换行
默认情况下,项目都排在一条线上(又称"轴线")上,flex-warp属性定义,flex 布局中默认是不换行的。
| 属性值 | 说明 |
|---|---|
| nowrap | 默认值,不换行 |
| wrap | 换行 |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div {
display: flex;
width: 600px;
height: 400px;
background-color: pink;
/* flex 布局中,默认的子元素是不换行的,如果装不开,会缩小子元素的宽度,放到父元素里面 */
/* flex-wrap: nowrap; */
flex-wrap: wrap;
}
div span {
width: 150px;
height: 100px;
background-color:purple;
color: #fff;
margin: 10px;
}
</style>
</head>
<body>
<div>
<span>1</span>
<span>2</span>
<span>3</span>
<span>4</span>
<span>5</span>
</div>
</body>
</html>
- align-items 设置侧轴上的子元素排列方式(单行)
该属性是控制子项在侧轴(默认是 y 轴)上的排列方式,在子项为单项的时候使用
| 属性值 | 说明 |
|---|---|
| flex-start | 默认值 从上到下 |
| flex-end | 从下到上 |
| center | 挤在一起居中(垂直居中) |
| stretch | 拉伸 |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div {
display: flex;
width: 800px;
height: 400px;
background-color: pink;
/* 默认的主轴是 x 轴 row */
flex-direction: column;
justify-content: center;
/* 需要一个侧轴居中 */
align-items: center;
/* 拉伸,但是子盒子不要给高度 */
/* align-items: stretch; */
}
div span {
width: 150px;
height: 100px;
background-color:purple;
color: #fff;
margin: 10px;
}
</style>
</head>
<body>
<div>
<span>1</span>
<span>2</span>
<span>3</span>
</div>
</body>
</html>
- align-content 设置侧轴上的子元素的排列方式(多行)
设置子项在侧轴上的排列方式并且只能用于子项出现换行的情况(多行),在单行下是没有效果的。
| 属性值 | 说明 |
|---|---|
| flex-start | 默认值在侧轴的头部开始排列 |
| flex-end | 在侧轴的尾部开始排列 |
| center | 在侧轴中间显示 |
| space-around | 子项在侧轴平分剩余空间 |
| space-between | 子项在侧轴先分布在两头,再平分剩余空间 |
| stretch | 设置子项元素高度平分父元素高度 |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div {
display: flex;
width: 800px;
height: 400px;
background-color: pink;
/* 换行 */
flex-wrap: wrap;
/* 因为有了换行,此时我们侧轴上控制子元素的对齐方式我们用 align-content */
/* align-content: flex-start; */
/* align-content: center; */
/* align-content: space-between; */
align-content: space-around;
}
div span {
width: 150px;
height: 100px;
background-color:purple;
color: #fff;
margin: 10px;
}
</style>
</head>
<body>
<div>
<span>1</span>
<span>2</span>
<span>3</span>
<span>4</span>
<span>5</span>
<span>6</span>
</div>
</body>
</html>
align-content 和 align-items 区别
1.align-items 适用于单行情况下,只有上对齐、下对齐、居中和拉伸
2.align-content 适用于换行(多行)的情况下(单行情况下无效),可以设置上对齐、下对其、居中、拉伸以及平均分配剩余空间等属性值
3.总结就是单行找 align-items 和多行找 align-content
- flex-flow
flex-flow 属性是 flex-direction 和 flex-wrap 属性的复合属性
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div {
display: flex;
width: 600px;
height: 400px;
background-color: pink;
/* flex-direction: column;
flex-wrap: wrap; */
/* 把设置主轴方向和是否换行(换列)简写*/
flex-flow: column wrap;
}
div span {
width: 150px;
height: 100px;
background-color:purple;
color: #fff;
margin: 10px;
}
</style>
</head>
<body>
<div>
<span>1</span>
<span>2</span>
<span>3</span>
<span>4</span>
<span>5</span>
<span>6</span>
</div>
</body>
</html>
3.4 flex 布局子项常见属性
1.flex 子项目占的份数
2.align-self控制子项自己在侧轴的排列方式
3.order 属性定义子项的排列顺序(前后顺序)
flex 属性定义子项目分配剩余空间,用 flex 来表示占多少份数
.item {
flex: <number>; /* default 0 */
}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
section {
display: flex;
width: 60%;
height: 200px;
background-color: pink;
margin: 0 auto;
}
section div {
height: 150px;
flex: 1;
margin: 10px;
background-color: sienna;
}
section div:nth-child(6) {
height: 150px;
flex: 2;
background-color: sandybrown;
margin: 10px;
}
p {
display: flex;
width: 60%;
height: 200px;
background-color: rosybrown;
margin: 100px auto;
}
p span {
flex: 1;
}
p span:nth-child(2) {
flex: 2;
background-color: seagreen;
}
</style>
</head>
<body>
<section>
<div>1</div>
<div>2</div>
<div>3</div>
<div>4</div>
<div>5</div>
<div>6</div>
</section>
<p>
<span>1</span>
<span>2</span>
<span>3</span>
</p>
</body>
</html>
- align-self 控制子项自己在侧轴上的排列方式
align-self属性允许单个项目有与其他项目不一样的对齐方式,可覆盖 align-items 属性。默认值为 auto,表示继承父元素的 align-items 属性,如果没有父元素,则等同于 stretch - order 属性定义项目的排列顺序
数值越小,排列越靠前,默认为 0。注意:和 z-index 不一样
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div {
display: flex;
width: 60%;
height: 300px;
background-color: pink;
/* 让三个子盒子沿着侧轴底侧对齐 */
/* align-items: flex-end; */
/* 想只让3号盒子下来底侧 */
}
div span {
width: 20%;
height: 100px;
background-color: plum;
margin-right: 10px;
}
div span:nth-child(2) {
/* 默认是0, -1 比 0 小所以在前面 */
order: -1;
}
div span:nth-child(3) {
align-self: flex-end;
}
section {
display: flex;
width: 60%;
height: 400px;
background-color: pink;
margin-top: 100px;
/* 默认的主轴是 x 轴 row */
flex-direction: row;
justify-content: center;
/* 需要一个侧轴居中 */
align-items: center;
}
section span {
flex: 1;
height: 150px;
background-color: powderblue;
margin: 10px;
}
section span:nth-child(2) {
flex: 2;
}
</style>
</head>
<body>
<div>
<span>1</span>
<span>2</span>
<span>3</span>
</div>
<section>
<span>1</span>
<span>2</span>
</section>
</body>
</html>
4、refs、emit、props三中的传参方式区别和使用
4.1 $refs的使用
- 父组件
<!-- 父组件 -->
<template>
<div>
<h1>我是父组件!</h1>
<child ref="msg"></child>
</div>
</template>
<script>
import Child from '../components/child.vue'
export default {
components: {Child},
mounted: function() {
console.log(this.$refs.msg)
this.$refs.msg.getMessage('我是子组件一!')
}
}
</script>
- 子组件
<!-- 子组件 -->
<template>
<h3>{{ message }}</h3>
</template>
<script>
export default {
data() {
return {
message: ''
}
},
methods: {
getMessage(m) {
this.message = m
}
}
}
</script>
通过 ref = ‘msg’ 可以将子组件 child 的实例指给 $refs,并且通过 .msg.getMessage() 调用到子组件的 getMessage 方法, 将参数传递给子组件。
4.2 $emit的使用方式
$emit 绑定一个自定义事件 event,当这个语句被执行到的时候,就会将参数 arg 传递给父组件,父组件通过 @event 监听并接受参数。
- 父组件
<template>
<div>
<h1>我是父组件</h1>
<child message="我是子组件一!"></child>
<!-- 这是一个 JavaScript 表达式而不是一个字符串。-->
<child v-bind:message="a+b"></child>
<!-- 用一个变量进行动态赋值。-->
<child v-bind:message="msg"></child>
<other-child @getMessage="showMsg"></other-child>
<h1>{{ content }}</h1>
</div>
</template>
<script>
import Child from '../components/child.vue'
import OtherChild from '../components/otherChild.vue'
export default {
data () {
return {
a: '我是子组件二!',
b: 112233,
msg: '我是子组件三!' + Math.random(),
content: ''
}
},
methods: {
showMsg(title) {
this.content = title
}
}
}
</script>
- 子组件
<template>
<h3>我是子组件!</h3>
</template>
export default {
mounted: function() {
this.$emit('getMessage', '我是子组件传给父组件的参数!')
}
}
4.3 props的使用方式
子组件的 props 选项能够接受来自父组件数据
功能:让组件接收外部传过来的数据
传递数据:`- 父组件(这里采用的是动态传递)
<!-- 父组件 -->
<template>
<div>
<h1>我是父组件!</h1>
<child message="我是子组件一!"></child>
<!-- 这是一个 JavaScript 表达式而不是一个字符串。-->
<child v-bind:message="a+b"></child>
<!-- 用一个变量进行动态赋值。-->
<child v-bind:message="msg"></child>
</div>
</template>
<script>
import Child from '../components/child.vue'
export default {
components: {Child},
data () {
return {
a: '我是子组件二!',
b: 112233,
mas: '我是子组件三!' + Math.random()
}
}
}
</script>
- 子组件
<template>
<h3>{{ message }}</h3>
</template>
<script>
export default {
props: ['message']
}
</script>
4.4 三者的使用场景和区别
- $refs
$refs用于数据之间的传递,如果ref用在子组件上能通过$refs获取到子组件节点、事件、数据、属性,主要还是父组件向子组件通信
$refs 着重于索引,主要用来调用子组件里的属性和方法,其实并不擅长数据传递。而且ref用在dom元素的时候,能使到选择器的作用,这个功能比作为索引更常有用到。
- $emit
$emit用于事件之间的传递, 可以实现子组件传参给父组件
$emit主要是可以在子组件中触发父组件里面的方法
- props
props用于父组件向子组件传递数据信息,传参方式是单向传输,只能父组件传给子组件,不能实现子组件传参给父组件.
props 着重于数据的传递,它并不能调用子组件里的属性和方法。像创建文章组件时,自定义标题和内容这样的使用场景,最适合使用prop。
4.5 父组件向子组件传值
- 父组件向子组件传值步骤:
在这里先定义一下,相对本案例来说:App.vue是父组件,Second-module.vue是子组件。
1.首先,值肯定是定义在父组件中的,供所有子组件共享。所以要在父组件的data中定义值:

2.其次,父组件要和子组件有契合点:就是在父组件中调用、注册、引用子组件:**
调用:
import Secondmodule from './components/Second-module'
注册:
components: {
// 局部注册组件这里,可能会定义多个组件,所以 component 这个单词加上 ‘s’
SecondModule
}
引用:
<!-- 实现父组件给子组件传值 -->
<second-module v-bind:newLists="newLists" v-bind:secondList="secondList"></second-module>
3.接下来,就可以在父组件和子组件链接的地方(即引用子组件的标签上),把父组件的值绑定给子组件:
<!-- 实现父组件给子组件传值 -->
<second-module v-bind:newLists="newLists" v-bind:secondList="secondList"></second-module>
这里绑定了两个值,一个是数组,一个是字符串。
总的来说父传子就是这三个步骤:父组件中定义值、调用子组件并引用、在引用的标签上给子组件传值。
但是注意是要用 v-bind: 绑定要传的值,不用v-bind直接把值放到标签上,会被当成html的节点属性解析的。
4.最后,子组件内部肯定要去接受父组件传过来的值:props(小道具)来接收:**
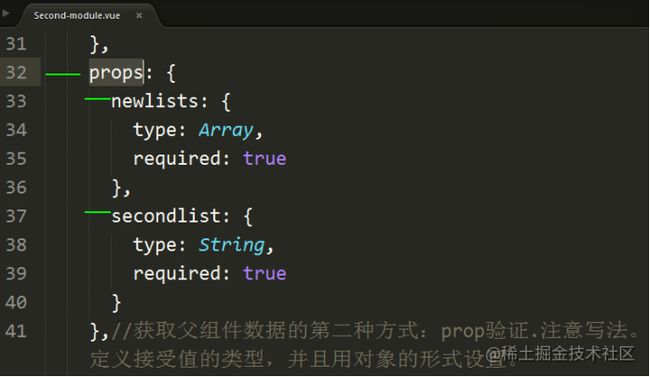
5.这样,子组件内部就可以直接使用父组件的值了。
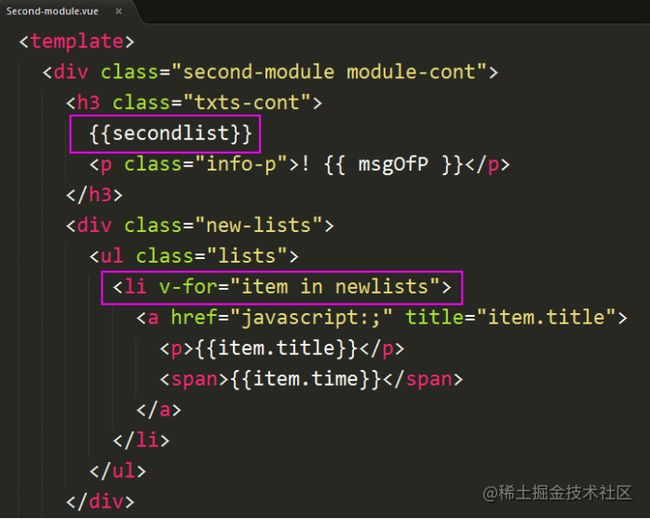
但是有要**注意**的点:
**子组件接受的父组件的值分为——引用类型和普通类型两种,**
普通类型:字符串(String)、数字(Number)、布尔值(Boolean)、空(Null)**
引用类型:数组(Array)、对象(Object)**
其中,普通类型是可以在子组件中更改,不会影响其他兄弟子组件内同样调用的来自父组件的值,
但是,引用类型的值,当在子组件中修改后,父组件的也会修改,那么后果就是,其他同样引用了改值的子组件内部的值也会跟着被修改。除非你有特殊的要求这么去做,否则最好不要这么做。
父组件传给子组件的值,在子组件中千万不能修改,因其数据是公用的,改了所有引用的子组件就都改了。
(6)Object.assign()的使用
- Object.assign()对象的拷贝
Object.assign() 方法用于将所有可枚举的值从一个或多个源对象复制到目标对象。它将返回目标对象。
Object.assign(target, ...sources) [target: 目标对象],[source: 源对象(可多个)]
案列:
const object1 = {
a: 1,
b: 2,
c: 3
}
const object2 = Object.assign({ c: 4, d: 5 }, object1)
console.log(object2) // { c: 3, d: 5, a: 1, b: 2 }
注意:
1.如果目标对象中的属性具有相同的键,则属性将被源对象中的属性覆盖。后面的源对象的属性将类似地覆盖前面的源对象的属性
2.Object.assign 方法只会拷贝源对象自身的并且可枚举的属性到目标对象。该方法使用源对象的[[Get]]和目标
对象的[[Set]],所以它会调用相关 getter 和 setter。因此,它分配属性,而不仅仅是复制或定义新的属性。如
果合并源包含getter,这可能使其不适合将新属性合并到原型中。为了将属性定义(包括其可枚举性)复制到
原型,应使用Object.getOwnPropertyDescriptor()和Object.defineProperty() 。
- Object.assign()对象的深拷贝
1.针对深拷贝,需要使用其他办法,因为 Object.assign()拷贝的是属性值。假如源对象的属性值是一个对象的引用,那么它也只指向那个引用。
const obj1 = { a: 0, b: { c: 1 } }
const obj2 = Object.assign({}, obj1)
console.log(obj2) // { a: 0, b: { c: 1 } }
const obj3 = JSON.stringify(obj2)
console.log(obj3) // {"a":0,"b":{"c":1}}
obj1.a = 2
console.log(JSON.stringify(obj1)) // {"a":2,"b":{"c":1}}
console.log(JSON.stringify(obj2)) // {"a":0,"b":{"c":1}}
obj2.a = 3
console.log(JSON.stringify(obj1)) // {"a":2,"b":{"c":1}}
console.log(JSON.stringify(obj2)) // {"a":3,"b":{"c":1}}
obj2.b.c = 4
console.log(JSON.stringify(obj1)) // {"a":2,"b":{"c":4}}
console.log(JSON.stringify(obj2)) // {"a":3,"b":{"c":4}}
最后一次赋值的时候,b的值是对象的引用,只要修改一次,其他的也会影响
2.深拷贝
const obj1 = {a: 1, b: { c: 1 }}
const obj2 = JSON.parse(JSON.stringify(obj1))
console.log(obj2) // { a: 1, b: { c: 1 } }
obj1.a = 2
obj1.b.c = 2;
console.log(JSON.stringify(obj2)) // {"a":1,"b":{"c":1}}
3.如何区分深拷贝与浅拷贝,简单点来说,就是假设B复制了A,当修改A时,看B是否会发生变化,如果B也跟着变了,说明这是浅拷贝,拿人手短,如果B没变,那就是深拷贝,自食其力。
基本数据类型有哪些,**number,string,boolean,null,undefined,symbol**以及未来ES10新增的**BigInt**(任意精度整数)七类。
- 对象的合并
const o1 = { a: 1 }
const o2 = { b: 2 }
const o3 = { c: 3 }
const obj1 = Object.assign(o1,o2,o3)
console.log(obj1) // { a: 1, b: 2, c: 3 }
console.log(o1) // { a: 1, b: 2, c: 3 } 注意目标对象自身也会改变
其实就是对象的拷贝,o1就是目标对象,后面的是源对象,后面的属性等会拷贝到目标对象
- 合并具有相同属性的对象
const o1 = { a: 1, b: 1, c: 1 };
const o2 = { b: 2, c: 2 };
const o3 = { c: 3 };
const obj = Object.assign({}, o1, o2, o3);
console.log(obj); // { a: 1, b: 2, c: 3 }
1.属性被后续参数中具有相同属性的其他对象覆盖。
2.目标对象的属性与源对象的属性相同,源的会覆盖目标的属性
- 继承属性和不可枚举属性是不能拷贝的
const obj = Object.create({foo: 1}, { // foo 是个继承属性。
bar: {
value: 2 // bar 是个不可枚举属性。
},
baz: {
value: 3,
enumerable: true // baz 是个自身可枚举属性。
}
});
创建对象时,如果没有设置enumerable的值,默认为false(不可枚举属性),设置为true,则为可枚举属性
const copy = Object.assign({}, obj);
console.log(copy); // { baz: 3 }
- 原始类型会被包装为对象
const v1 = "abc";
const v2 = true;
const v3 = 10;
const v4 = Symbol("foo")
const obj = Object.assign({}, v1, null, v2, undefined, v3, v4);
// 原始类型会被包装,null 和 undefined 会被忽略。
// 注意,只有字符串的包装对象才可能有自身可枚举属性。
console.log(obj); // { "0": "a", "1": "b", "2": "c" }
- 异常会打断后续拷贝任务
const target = Object.defineProperty({}, "foo", {
value: 1,
writable: false
}); // target 的 foo 属性是个只读属性。
Object.assign(target, {bar: 2}, {foo2: 3, foo: 3, foo3: 3}, {baz: 4});
// TypeError: "foo" is read-only
// 注意这个异常是在拷贝第二个源对象的第二个属性时发生的。
console.log(target.bar); // 2,说明第一个源对象拷贝成功了。
console.log(target.foo2); // 3,说明第二个源对象的第一个属性也拷贝成功了。
console.log(target.foo); // 1,只读属性不能被覆盖,所以第二个源对象的第二个属性拷贝失败了。
console.log(target.foo3); // undefined,异常之后 assign 方法就退出了,第三个属性是不会被拷贝到的。
console.log(target.baz); // undefined,第三个源对象更是不会被拷贝到的。
四、CSS
1、margin
margin是外边距的意思,当一个元素样式属性里有margin:0 auto时,并且父元素的宽度是确定的,意思是这个元素处于其父元素的居中位置,并且这个元素的上下外边距为0。
- margin还有其他配置类型:
1.margin-bottom:设置元素的下外边距。
2.margin-left:设置元素的左外边距。
3.margin-right:设置元素的右外边距。
4.margin-top:设置元素的上外边距。
五、SQL
1、sql、DB、DBMS
- DB
DataBase(数据库,数据库实际上在硬盘上以文件的形式存在)
- DBMS
DataBase Management System(数据库管理系统,常见的有:MySQL Oracle DB2 Sybase SqlServer…)
- SQL
结构化查询语言,是一门标准通用的语言。标准的sql适合于所有的数据库产品。
SQL属于高级语言。只要能看懂英语单词的,写出来的sql语句,可以读懂什么意思。
SQL语句在执行的时候,实际上内部也会先进行编译,然后再执行sql。(sql语句的编译由DBMS完成。)
DBMS负责执行sql语句,通过执行sql语句来操作DB当中的数据。
DBMS -(执行)-> SQL -(操作)-> DB
2、表
- 表:table
表:table是数据库的基本组成单元,所有的数据都以表格的形式组织,目的是可读性强。
一个表包括行和列:
行:被称为数据/记录(data)
列:被称为字段(column)
学号(int) 姓名(varchar) 年龄(int)
------------------------------------
110 张三 20
120 李四 21
每一个字段应该包括哪些属性?
字段名、数据类型、相关的约束。
3、SQL 语句分类
- DQL(数据查询语言): 查询语句,凡是select语句都是DQL。
- DML(数据操作语言):insert delete update,对表当中的数据进行增删改。
- DDL(数据定义语言):create drop alter,对表结构的增删改。
- TCL(事务控制语言):commit提交事务,rollback回滚事务。(TCL中的T是Transaction)
- DCL(数据控制语言): grant授权、revoke撤销权限等。
4、导入数据
第一步:登录mysql数据库管理系统
dos命令窗口:mysql -uroot -p333
第二步:查看有哪些数据库
show databases; (这个不是SQL语句,属于MySQL的命令。)
第三步:创建属于我们自己的数据库
create database powernode; (这个不是SQL语句,属于MySQL的命令。)
第四步:使用 powernode 数据
use powernode; (这个不是SQL语句,属于MySQL的命令。)
第五步:查看当前使用的数据库中有哪些表?
show tables; (这个不是SQL语句,属于MySQL的命令。)
第六步:初始化数据
mysql> source D:\course\05-MySQL\resources\powernode.sql
5、sql脚本
当一个文件的扩展名是.sql,并且该文件中编写了大量的sql语句,我们称这样的文件为sql脚本。注意:直接使用source命令可以执行sql脚本。sql脚本中的数据量太大的时候,无法打开,请使用source命令完成初始化。
6、MySql 基本命令
6.1基础命令
mysql -uroot -p 密码; (也可以不带密码,输入之后)本地登录
mysql -h 登录 ip -p 端口(通常 3306 ) -uroot -p密码; 远程登录
desc 表名; 查看表的各个字段的属性,以及自增键
mysqldump -u 用户 -p 数据库名 > xx.sql; 导出数据库文件,保存
mysql -u 用户名 -p 密码 数据库名 < xx.sql; 导入数据库文件(也可以选择登录进去,在选择数据库后,使用 source 命令导入数据)
select database(); 查看当前使用的是哪个数据库
select version(); 查看mysql的版本号。
\c 命令,结束一条语句。
exit 命令,退出mysql。
show create table emp;查看创建表的语句:
6.2创建命令
create user '用户名' @ 'ip' identified by '密码'; 创建用户
ip 是指用户登录 mysql 的电脑 ip,可以写 %,本地写 localhost
grant 权限(select/insert/updata/all priveleges) on 表/数据库名 to '用户'@'ip' identified by '密码'; 用户授权
drop user 用户名@ip 删除用户
show databases; 查数据库
use databases; 使用数据库
drop database powernode; 删除数据库
1.创建表
建表语句的语法格式:
create table 表名(
字段名1 数据类型,
字段名2 数据类型,
字段名3 数据类型,
....
);
2.关于MySQL当中字段的数据类型?以下只说常见的
int 整数型(java中的int)
bigint 长整型(java中的long)
float 浮点型(java中的float double)
char 定长字符串(String)
varchar 可变长字符串(StringBuffer/StringBuilder)
date 日期类型 (对应Java中的java.sql.Date类型)
BLOB 二进制大对象(存储图片、视频等流媒体信息) Binary Large OBject (对应java中的Object)
CLOB 字符大对象(存储较大文本,比如,可以存储4G的字符串。) Character Large OBject(对应java中的Object)
......
3.char和varchar怎么选择?
在实际的开发中,当某个字段中的数据长度不发生改变的时候,是定长的,例如:性别、生日等都是采用char。
当一个字段的数据长度不确定,例如:简介、姓名等都是采用varchar。
4.BLOB和CLOB类型的使用?
电影表: t_movie
id(int) name(varchar) playtime(date/char) haibao(BLOB) history(CLOB)
----------------------------------------------------------------------------------------
1 蜘蛛侠
2
3
表名在数据库当中一般建议以:t_或者tbl_开始。
5.insert语句插入数据
语法格式:
insert into 表名(字段名1,字段名2,字段名3,....) values(值1,值2,值3,....)
要求:字段的数量和值的数量相同,并且数据类型要对应相同。
需要注意的地方:
当一条insert语句执行成功之后,表格当中必然会多一行记录。
即使多的这一行记录当中某些字段是NULL,后期也没有办法在执行
insert语句插入数据了,只能使用update进行更新。
字段可以省略不写,但是后面的value对数量和顺序都有要求。
一次插入多行数据
insert into t_student
(no,name,sex,classno,birth)
values
(3,'rose','1','gaosi2ban','1952-12-14'),(4,'laotie','1','gaosi2ban','1955-12-14');
6.表的复制
语法:
create table 表名 as select语句;
将查询结果当做表创建出来。
7.将查询结果插入到一张表中?
insert into dept1 select * from dept;
6.3查表命令
-
条件查询
-
提示:
1.任何一条sql语句以 “;” 结尾。 2.sql语句不区分大小写。 3.标准sql语句中要求字符串使用单引号括起来。虽然mysql支持双引号,尽量别用。 4.as关键字可以省略(起别名) 5.语法格式: select 字段,字段... from 表名 where 条件; 执行顺序:先from,然后where,最后select
select * from 表名; select 列名···from 表名; select 列名 from 表名 where 列名(id等) >/</!= value; select 列名,常量 from 表名; 增加一个常量列 select 列名 from 表名 where 列名 in/not in/between and value; select 列名 from 表名 where 条件1 and 条件2; 特殊的:select 列名 from 表名 where 列名 in (select 列名(只能一列) from 表名); select 列名 from 表名 where 列名 like 'xx%'/'%xx'/"xx_"; 查询以xx开头/xx结尾 %代表任意位,_代表一位 -
-
分页
1.limit是mysql特有的,其他数据库中没有,不通用。(Oracle中有一个相同的机制,叫做rownum) 2.limit取结果集中的部分数据,这是它的作用。 3.语法机制: limit startIndex, length startIndex表示起始位置,从0开始,0表示第一条数据。 length表示取几个 案例:取出工资前5名的员工(思路:降序取前5个) select ename,sal from emp order by sal desc; 取前5个: select ename,sal from emp order by sal desc limit 0, 5; select ename,sal from emp order by sal desc limit 5; 4.limit是sql语句最后执行的一个环节: select 5 ... from 1 ... where 2 ... group by 3 ... having 4 ... order by 6 ... limit 7 ...; 5.通用的标准分页sql? 每页显示3条记录: 第1页:0, 3 第2页:3, 3 第3页:6, 3 第4页:9, 3 第5页:12, 3 每页显示pageSize条记录: 第pageNo页:(pageNo - 1) * pageSize, pageSize pageSize是什么?是每页显示多少条记录 pageNo是什么?显示第几页 select 列名 from 表名 limit num; 显示num个 select 列名 from 表名 limit num1,num2; 从num1后取num2行数据,num1是起始位置,num2 是个数 select 列名 from 表名 limit num1 offset num2; 从num2后取num1行数据,num2是起始位置,num1 是个数 -
排序
默认是升序。 select 字段 3 from 表名 1 where 条件 2 order by .... 4 order by是最后执行的。 select * from 表名 order by 列名 desc; 从大到小排序 select * from 表名 order by 列名 asc; 从小到大排序 select * from 表名 order by 列名1 desc 列名2 asc; 首先遵循列1从大到小排序,遇到相同数据时, 按列2从小到大排序 -
分组
1.分组函数 count 计数 sum 求和 avg 平均值 max 最大值 min 最小值 分组函数一共5个。 分组函数还有另一个名字:多行处理函数。 多行处理函数的特点:输入多行,最终输出的结果是1行。 分组函数自动忽略NULL。 2.count(*)和count(具体的某个字段),他们有什么区别? count(*):不是统计某个字段中数据的个数,而是统计总记录条数。(和某个字段无关) count(comm): 表示统计comm字段中不为NULL的数据总数量。 select count/sum/max/min/avg(列名1),列名2 from 表名 group by 列名(通常是列名2); 分组操作 select count/sum/max/min/avg(列名1),列名2 from 表名 group by 列名(通常是列名2)having 条件;分组操作后筛选 3.单行处理函数 什么是单行处理函数? 输入一行,输出一行。 计算每个员工的年薪? select ename,(sal+comm)*12 as yearsal from emp; 重点:**所有数据库都是这样规定的,只要有NULL参与的运算结果一定是NULL**。 使用ifnull函数: select ename,(sal+ifnull(comm,0))*12 as yearsal from emp; ifnull() 空处理函数? ifnull(可能为NULL的数据,被当做什么处理) : 属于单行处理函数。 select ename,ifnull(comm,0) as comm from emp;- group by 和 having
group by : 按照某个字段或者某些字段进行分组。 having : having是对分组之后的数据进行再次过滤。 案例:找出每个工作岗位的最高薪资。 select max(sal),job from emp group by job; +----------+-----------+ | max(sal) | job | +----------+-----------+ | 3000.00 | ANALYST | | 1300.00 | CLERK | | 2975.00 | MANAGER | | 5000.00 | PRESIDENT | | 1600.00 | SALESMAN | +----------+-----------+ 注意:分组函数一般都会和group by联合使用,这也是为什么它被称为分组函数的原因。 并且任何一个分组函数(count sum avg max min)都是在group by语句执行结束之后才会执行的。 当一条sql语句没有group by的话,整张表的数据会自成一组。 select ename,max(sal),job from emp group by job; 以上在mysql当中,查询结果是有的,但是结果没有意义,在Oracle数据库当中会报错。语法错误。 Oracle的语法规则比MySQL语法规则严谨。 记住一个规则:**当一条语句中有group by的话,select后面只能跟分组函数和参与分组的字段。**- 总结一个完整的DQL语句
select 5 .. from 1 .. where 2 .. group by 3 .. having 4 .. order by 6 ..- 关于查询结果集的去重
distinct关键字去除重复记录。 select distinct job from emp 记住:distinct只能出现在所有字段的最前面。
6.4连接查询
-
什么是连接查询
在实际开发中,大部分的情况下都不是从单表中查询数据,一般都是多张表联合查询取出最终的结果。 在实际开发中,一般一个业务都会对应多张表,比如:学生和班级,起码两张表。 stuno stuname classno classname ----------------------------------------------------------------------------------- 1 zs 1 北京大兴区亦庄经济技术开发区第二中学高三1班 2 ls 1 北京大兴区亦庄经济技术开发区第二中学高三1班 ... 学生和班级信息存储到一张表中,结果就像上面一样,数据会存在大量的重复,导致数据的冗余。 -
连接查询的分类
1.根据语法出现的年代来划分的话,包括: SQL92(一些老的DBA可能还在使用这种语法。DBA:DataBase Administrator,数据库管理员) SQL99(比较新的语法) 2.根据表的连接方式来划分,包括: 内连接: 等值连接 非等值连接 自连接 外连接: 左外连接(左连接) 右外连接(右连接) 全连接 3.在表的连接查询方面有一种现象被称为:笛卡尔积现象。(笛卡尔乘积现象) 笛卡尔积现象:当两张表进行连接查询的时候,没有任何条件进行限制,最终的查询结果条数是两张表记录条数的乘积。 案例:找出每一个员工的部门名称,要求显示员工名和部门名。 EMP表 +--------+--------+ | ename | deptno | +--------+--------+ | SMITH | 20 | | ALLEN | 30 | | WARD | 30 | | JONES | 20 | | MARTIN | 30 | | BLAKE | 30 | | CLARK | 10 | | SCOTT | 20 | | KING | 10 | | TURNER | 30 | | ADAMS | 20 | | JAMES | 30 | | FORD | 20 | | MILLER | 10 | +--------+--------+ DEPT表 +--------+------------+----------+ | DEPTNO | DNAME | LOC | +--------+------------+----------+ | 10 | ACCOUNTING | NEW YORK | | 20 | RESEARCH | DALLAS | | 30 | SALES | CHICAGO | | 40 | OPERATIONS | BOSTON | +--------+------------+----------+ select ename,dname from emp,dept; +--------+------------+ | ename | dname | +--------+------------+ | SMITH | ACCOUNTING | | SMITH | RESEARCH | | SMITH | SALES | | SMITH | OPERATIONS | | ALLEN | ACCOUNTING | | ALLEN | RESEARCH | | ALLEN | SALES | | ALLEN | OPERATIONS | ............ 56 rows in set (0.00 sec) 笛卡尔积现象:当两张表进行连接查询的时候,没有任何条件进行限制,最终的查询结果条数是两张表记录条数的乘积。 4.关于表的别名: select e.ename,d.dname from emp e,dept d; 表的别名有什么好处? 第一:执行效率高。 第二:可读性好。 5.怎么避免笛卡尔积现象?当然是加条件进行过滤。 思考:避免了笛卡尔积现象,会减少记录的匹配次数吗? 不会,次数还是56次。只不过显示的是有效记录。 6.内连接之等值连接:最大特点是:条件是等量关系。 7.内连接之非等值连接:最大的特点是:连接条件中的关系是非等量关系。 8.自连接:最大的特点是:一张表看做两张表。自己连接自己。 9.外连接 什么是外连接,和内连接有什么区别? 内连接: 假设A和B表进行连接,使用内连接的话,凡是A表和B表能够匹配上的记录查询出来,这就是内连接。 AB两张表没有主副之分,两张表是平等的。 外连接: 假设A和B表进行连接,使用外连接的话,AB两张表中有一张表是主表,一张表是副表,主要查询主表中 的数据,捎带着查询副表,当副表中的数据没有和主表中的数据匹配上,副表自动模拟出NULL与之匹配。 外连接的分类: 左外连接(左连接):表示左边的这张表是主表。 右外连接(右连接):表示右边的这张表是主表。 左连接有右连接的写法,右连接也会有对应的左连接的写法。 外连接最重要的特点是:主表的数据无条件的全部查询出来。 10.连表操作 select * from 表1 left join 表2 on 表1.列名=表2.列名; 左连接 select * from 表1 right join 表2 on 表1.列名=表2.列名; 右连接 select * from 表1 inner join 表2 on 表1.列名=表2.列名; 内连接 注意:如果超过3个表联合操作,如果其中两个表操作时已经改变了表结构,应该将这两个表操作的结果作为一个临时表再与第三个表联合操作。 11.临时表 (select * from 表名)as e 12.union (可以将查询结果集相加) 案例:找出工作岗位是SALESMAN和MANAGER的员工? 第一种:select ename,job from emp where job = 'MANAGER' or job = 'SALESMAN'; 第二种:select ename,job from emp where job in('MANAGER','SALESMAN'); +--------+----------+ | ename | job | +--------+----------+ | ALLEN | SALESMAN | | WARD | SALESMAN | | JONES | MANAGER | | MARTIN | SALESMAN | | BLAKE | MANAGER | | CLARK | MANAGER | | TURNER | SALESMAN | +--------+----------+ 第三种:union select ename,job from emp where job = 'MANAGER' union select ename,job from emp where job = 'SALESMAN'; +--------+----------+ | ename | job | +--------+----------+ | JONES | MANAGER | | BLAKE | MANAGER | | CLARK | MANAGER | | ALLEN | SALESMAN | | WARD | SALESMAN | | MARTIN | SALESMAN | | TURNER | SALESMAN | +--------+----------+ 两张不相干的表中的数据拼接在一起显示? select ename from emp union select dname from dept; +------------+ | ename | +------------+ | SMITH | | ALLEN | | WARD | | JONES | | MARTIN | | BLAKE | | CLARK | | SCOTT | | KING | | TURNER | | ADAMS | | JAMES | | FORD | | MILLER | | ACCOUNTING | | RESEARCH | | SALES | | OPERATIONS | +------------+ mysql> select ename,sal from emp -> union -> select dname from dept; ERROR 1222 (21000): The used SELECT statements have a different number of columns 13.子查询 什么是子查询?子查询都可以出现在哪里? select语句当中嵌套select语句,被嵌套的select语句是子查询。 子查询可以出现在哪里? select ..(select). from ..(select). where ..(select).
6.5修改、删除数据
-
修改
1.语法格式: update 表名 set 字段名1=值1,字段名2=值2... where 条件; 2.修改表结构 alter table 表名 auto_increment=value;设置自增键起始值; alter table 表名 drop 列名; 删除列 alter table 表名 add 列名 数据类型 约束; 增加列 alter table 表名 change 旧列名 新列名 数据类型; 修改字段类型 alter table 表名 modify 列名 数据类型; 修改数据类型 alter table 旧表名 rename 新表名; 修改表名 alter table 表名 drop primary key; 删除表中主键 alter table 表名 add 列名 数据类型 primary key; 添加主键 alter table 表名 add primary key(列名); 设置主键 alter table 表名 add column 列名 数据类型 after 列名; 在某一列后添加主键 -
删除
语法格式: delete from 表名 where 条件; 注意:没有条件全部删除。 删除10部门数据? delete from dept1 where deptno = 10; 删除所有记录? delete from dept1; 怎么删除大表中的数据?(重点) truncate table 表名; // 表被截断,不可回滚。永久丢失。 删除表? drop table 表名; // 这个通用。 drop table if exists 表名; // oracle不支持这种写法。 delete from 表名; 清除表(如果有自增id,id 不会重新开始) delete from 表名 where 条件;清除特定数据 truncate table 表名; 清除表(如果有自增id,id 会重新开始)
7、常用 SQl 语句
7.1 case when 行转列、列转行
行转列,列转行是我们在开发过程中经常碰到的问题。行转列一般通过CASE WHEN 语句来实现,也可以通过 SQL SERVER 2005 新增的运算符PIVOT来实现。用传统的方法,比较好理解。层次清晰,而且比较习惯。 但是PIVOT 、UNPIVOT提供的语法比一系列复杂的SELECT…CASE 语句中所指定的语法更简单、更具可读性。下面我们通过几个简单的例子来介绍一下列转行、行转列问题。
-
行转列
mysql> create table t_student_scores( -> id int(10) primary key AUTO_INCREMENT, -> user_name varchar(255), -> subject varchar(255), -> score int(10)); insert into t_student_scores values(1,'Jack', '语文', 80), (2,'Rose', '语文', 80), (3,'张三','数学',98), (4, '李四','英语',78), (5, '王五', '物理', 89), (6, '赵六','化学',78); mysql> select * from t_student_scores; +----+-----------+---------+-------+ | id | user_name | subject | score | +----+-----------+---------+-------+ | 1 | Jack | 语文 | 80 | | 2 | Rose | 语文 | 80 | | 3 | 张三 | 数学 | 98 | | 4 | 李四 | 英语 | 78 | | 5 | 王五 | 物理 | 89 | | 6 | 赵六 | 化学 | 78 | +----+-----------+---------+-------+ 6 rows in set (0.00 sec) 案例: 想知道每位学生的每科成绩,而且每个学生的全部成绩排成一行,这样方便我查看、统计,导出数据 mysql> select user_name, -> max(case subject when '语文' then score else 0 end) as '语文', -> max(case subject when '数学' then score else 0 end) as '数学', -> max(case subject when '英语' then score else 0 end) as '英语', -> max(case subject when '物理' then score else 0 end) as '物理', -> max(case subject when '化学' then score else 0 end) as '化学', -> max(case subject when '生物' then score else 0 end) as '生物' -> from t_student_scores -> group by user_name; +-----------+--------+--------+--------+--------+--------+--------+ | user_name | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | +-----------+--------+--------+--------+--------+--------+--------+ | Jack | 80 | 0 | 0 | 0 | 0 | 0 | | Rose | 80 | 0 | 0 | 0 | 0 | 0 | | 张三 | 0 | 98 | 0 | 0 | 0 | 0 | | 李四 | 0 | 0 | 78 | 0 | 0 | 0 | | 王五 | 0 | 0 | 0 | 89 | 0 | 0 | | 赵六 | 0 | 0 | 0 | 0 | 78 | 0 | +-----------+--------+--------+--------+--------+--------+--------+ 6 rows in set (0.00 sec) -
列转行
主要通过 UNION ALL 来实现
mysql> select user_name, subject as items, score from t_student_scores
-> union all
-> select user_name, score as scores, subject from t_student_scores;
+-----------+--------+--------+
| user_name | items | score |
+-----------+--------+--------+
| Jack | 语文 | 80 |
| Rose | 语文 | 80 |
| 张三 | 数学 | 98 |
| 李四 | 英语 | 78 |
| 王五 | 物理 | 89 |
| 赵六 | 化学 | 78 |
| Jack | 80 | 语文 |
| Rose | 80 | 语文 |
| 张三 | 98 | 数学 |
| 李四 | 78 | 英语 |
| 王五 | 89 | 物理 |
| 赵六 | 78 | 化学 |
+-----------+--------+--------+
12 rows in set (0.00 sec)
7.2 concat()函数
功能:将多个字符串连接成一个字符串。
语法:concat(str1, str2,...)
返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
mysql> select user_name, concat(t.subject, t.score) items from t_student_scores t;
+-----------+----------+
| user_name | items |
+-----------+----------+
| Jack | 语文80 |
| Rose | 语文80 |
| 张三 | 数学98 |
| 李四 | 英语78 |
| 王五 | 物理89 |
| 赵六 | 化学78 |
+-----------+----------+
6 rows in set (0.01 sec)
- concat_ws()函数
功能:和concat()一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符~(concat_ws就是concat with separator)
语法:concat_ws(separator, str1, str2, ...)
说明:第一个参数指定分隔符。需要注意的是分隔符不能为null,如果为null,则返回结果为null。
mysql> select user_name, concat_ws('|', t.subject, t.score) items from t_student_scores t;
+-----------+-----------+
| user_name | items |
+-----------+-----------+
| Jack | 语文|80 |
| Rose | 语文|80 |
| 张三 | 数学|98 |
| 李四 | 英语|78 |
| 王五 | 物理|89 |
| 赵六 | 化学|78 |
+-----------+-----------+
6 rows in set (0.00 sec)
- group_concat()函数
功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
7.3 ifNull()、isNull(),nullif()
- isnull(expr) 的用法
如expr 为null,那么isnull() 的返回值为 1,否则返回值为 0。
mysql> select user_name, score from t_student_scores where isnull(score);
Empty set (0.00 sec)
使用= 的null 值对比通常是错误的。
isnull() 函数同 is null比较操作符具有一些相同的特性。请参见有关is null 的说明。
**** ISNULL()**
用途:使用指定的替换值替换返回值为NULL
语法:ISNULL(check_expression,replacement_value)
参数:
check_expression,将被检查是否为NULL的表达式,可以为任意类型的。
replacement_value,在check_expression为NULL时返回的表达式。必须与check_expression相同类型。
返回类型:返回与check_expression相同的类型
注释:如果check_expression不为NULL,那么返回该表达式的值;否则返回replacement_value'
- IFNULL(expr1,expr2)的用法
假如expr1不为null(),则IFNULL()的返回值为expr1;否则其返回值为expr2。
IFNULL()的返回值是数字或是字符串,具体情况取决于其所使用的语境。
mysql> select ifnull(1,0);
+-------------+
| ifnull(1,0) |
+-------------+
| 1 |
+-------------+
1 row in set (0.01 sec)
mysql> select ifnull(null,10);
+-----------------+
| ifnull(null,10) |
+-----------------+
| 10 |
+-----------------+
1 row in set (0.00 sec)
IFNULL(expr1,expr2)的默认结果值为两个表达式中更加“通用”的一个,顺序为STRING、REAL或INTEGER。假设一个基于表达式的表的情况,或MySQL必须在内存储器中储存一个临时表中IFNULL()的返回值:
CREATE TABLE tmp SELECT IFNULL(1,'test') AS test;
在这个例子中,[测试](http://lib.csdn.net/base/softwaretest)列的类型为 CHAR(4)。
- NULLIF(expr1,expr2)的用法
如果expr1 = expr2成立,那么返回值为NULL,否则返回值为expr1。
这和CASE WHEN expr1 = expr2
THEN NULL ELSE expr1 END相同。
mysql> select user_name, case when subject='物理' then subject else null end from t_student_scores;
+-----------+-------------------------------------------------------+
| user_name | case when subject='物理' then subject else null end |
+-----------+-------------------------------------------------------+
| Jack | NULL |
| Rose | NULL |
| 张三 | NULL |
| 李四 | NULL |
| 王五 | 物理 |
| 赵六 | NULL |
+-----------+-------------------------------------------------------+
6 rows in set (0.11 sec)
7.4 trim()
问题描述:
在数据库中,批量导入数据的时候,没有注意字段数据的空格,造成导入数据库里的数据末尾有空格。
解决方案:
trim() 函数介绍:
trim 函数可以移除字符串的**首尾信息**。最常见的用法为移除字符首尾空格。
trim() 函数使用:
mysql> update t_student_scores
-> set subject=trim(subject)
-> where subject = '物理';
Query OK, 0 rows affected (0.12 sec)
Rows matched: 1 Changed: 0 Warnings: 0
7.5 union和 union all
- SQL UNION 操作符
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
SQL UNION 语法
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
- SQL UNION ALL 语法
SELECT column_name(s) FROM table_name1
UNION ALL
SELECT column_name(s) FROM table_name2
另外,UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
(6)row_number() over (partition by)
row_number 语法
ROW_NUMBER()函数将针对SELECT语句返回的每一行,从1开始编号,赋予其连续的编号。在查询时应用了一个排序标准后,只有通过编号才能够保证其顺序是一致的,当使用ROW_NUMBER函数时,也需要专门一列用于预先排序以便于进行编号
partition by关键字是分析性函数的一部分,它和聚合函数不同的地方在于它能返回一个分组中的多条记录,而聚合函数一般只有一条反映统计值的记录,partition by用于给结果集分组,如果没有指定那么它把整个结果集作为一个分组,分区函数一般与排名函数一起使用。
8、索引和主键
8.1 索引
一般学习编程语言都是从c语言开始,c语言里面有个东东叫"指针",都知道c语言里面指针用的不好会带来不安全性,学习java的时候都知道java里面没有指针。Java里面还有类似指针的地方,java里面叫做索引。索引指向的是对象在jvm里面分配的内存地址,由于中间隔了一层jvm,所以安全性有保障。
MySQL官方对于索引的定义为:索引是帮助MySQL高效获取数据的数据结构。
数据库查询是数据库最主要的功能之一,我们都希望查询数据的速度尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找,当然这种时间复杂度为O(N)的算法在数据量很大时显然是糟糕的,于是有了二分查找O(log N) 、二叉树查找等。但是二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树,但是数据本身的组织结构不可能完全满足各种数据结构。所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
插曲:大O表示法。检查长度为n的列表,二分查找最坏的情况需要执行log N次操作,使用大O表示法来表示算法的运行时间,也就是O(log N) 。括号里面指算法需要执行的操作次数。
创建表时,不能在同一个字段上建立两个索引(主键默认建立唯一索引),在需要 经常查询的字段上建立索引(如:deal_id已经是主键,不能再次执行:create index tmp_table_index on tmp_table(deal_id), 会报错);
-
主键:该字段没有重复值,且不允许为空
-
惟一索引:该字段没有重复值,但允许空值(该字段可以有多个null值)
一张table只允许一个主键,但可以创建多个unique index
比如,表中有5行,ID的值是12345,就可以作为主键
但如果ID的值是1234 NULL NULL,则可以建立惟一索引,不能作为主键
-
可以为 多个字段建立唯一索引:
create unique index unique_index01 on search_result_tmp(deal_id,compare_flag);
建立唯一索引以后,只允许插入一条如下记录,插入两条时会违反unique index约束
Insert into search_result_temp values(1,null);
-
删除索引:drop index unique_index01;
-
函数索引
如果在我们的查询条件使用了函数,那么索引就不可用了。
可以用建立函数索引的方式,来解决这个问题
例如: select * from product where nvl(price,0.0)>1000.0 ;
这里,nvl(price,0.0)使用了函数,索引不能利用price字段上做的索引了ok,我们来创建函数索引
create index index_price on product(nvl(price,0.0));
-
其他:
唯一索引能极大的提高查询速度,而且还有唯一约束的作用
一般索引,只能提高30%左右的速度
经常插入,修改,应在查询允许的情况下,尽量减少索引,因为添加索引,插入,修改等操作,需要更多的时间
```js
A、主键一定是唯一性索引,唯一性索引并不一定就是主键。
B、 一个表中可以有多个唯一性索引,但只能有一个主键。
C、主键列不允许空值,而唯一性索引列允许空值。
D、索引可以提高查询的速度。
```
主键和索引都是键,不过主键是逻辑键,索引是物理键,意思就是主键不实际存在,而索引实际存在在数据库中
(1)优势
类似大学图书馆建书目索引,提高数据检索效率,降低数据库的IO成本。
通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
(2)劣势
实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占空间的。
虽然索引大大提高了查询速度,同时确会降低更新表的速度,如对表进行INSERT、UPDATE、DELETE。
因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段。
8.2 索引的数据结构
在关系数据库中,索引是一种对数据库表中的值进行排序的存储结构。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。数据库使用索引以找到特定值,然后顺指针找到包含该值的行。这样可以使对应于表的SQL语句执行得更快,可快速访问数据库表中的特定信息。
-
什么样的信息才能成为索引
在关系型数据库中,主键,唯一键,普通键,都可以作为数据库的索引。
-
索引的数据结构

如图是一个二叉查找树,在二叉查找树中,我们可以使用二分查找法,去检索需要的数据。
那为什么不用二叉树去作为索引的数据结构呢?如图所示的二叉树,如果我们删除了数据为6的节点,增加一个数据为10的节点,那此二叉树便成为了一个线形二叉树。也就是说,在插入删除的过程中,二叉树可能会演变成线性结构,线性结构会明显降低查询的效率;同时,二叉树在数据较多时,深度狠深,也不利于数据的查找。
- 我们再来看一下B树。
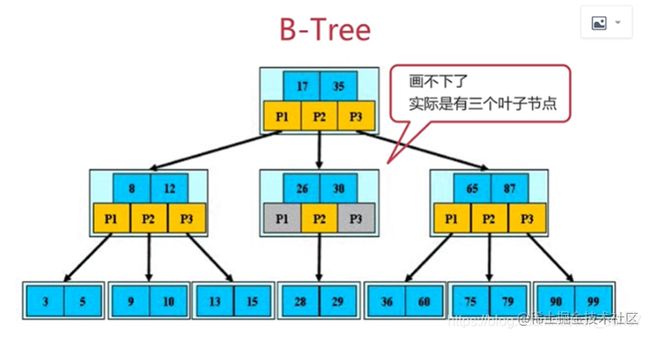
什么是B树呢,B树,又称B-树,它具有以下特点:
(1)排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
(2)它是一个多阶树,他的叶子节点和非叶子节点都记录有关键字;
(3)所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指 针地址都为null。
B树的这些规则保证了关键字信息的顺序排列,并且在B树中进行删除增加操作时,b树仍然会保持树形结构。
显然B树相较于平衡二叉树,更加适合做索引的数据结构,但是呢,我们常用的mysql用的却并不是B树,而是更适合的B+树。
-
B+树
B+树是B树的一个升级版,相对于B树来说B+树更充分的利用了节点的空间,让查询速度更加稳定,来看下B+树:
B+树具有以下特点:
1)B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引; 2)B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样; 3)B+树叶子节点的**关键字从小到大有序排列**,左边结尾数据都会保存右边节点开始数据的指针。所以,用B+树作为索引结构,有着以下优点:
1)B+树的中间节点不保存数据,是纯索引,但是B树的中间节点是保存数据和索引的,相对来说,B+树在磁盘页中能容纳更多节点元素。 2)B+树每次查询都要从根节点一直查到叶节点,所以查询效率更加稳定。 3)因为每个叶子节点都存放了指向下一个节点的指针,且关键数据有序排列,所以在范围查找中,B+树更占优势。 4)增删节点时,效率更高,因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储。我们常用的Mysql 就是默认采用了B+树作为索引结构。
在我们创建索引时,可以看到mysql也是支持hash索引结构的,我们再来简单介绍下hash 索引。
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
听起来很吊,但是hash索引虽然再等值查询时占有一定的优势,但是它相比于B+tree却有一些无法弥补的缺点:
1)它仅仅能满足等值查询,不支持范围查询。 2)无法进行数据的排序操作。 3)不支持多列联合索引的最左匹配规则。因为hash索引的联合索引,是把多个键值房子一起算hash值的。 4)遇到大量hash值相等的情况后性能下降。
综上,mysql采用了默认B+tree作为索引结构,也支持hash结构作为索引的方式。
8.3 唯一索引和聚合索引(聚集索引)
(1)一个表只能有一个主索引-PRIMARY,且只有是数据库表才有主索引,后缀为 .CDX,索引关键字是不可以重复的.哪怕是空记录也只可以有一条.
(2)候选索引可以有很多个,索引关键字同样不可以重复,同样只存在于数据库表.
(3)唯一索引,可以存在于自由表,但索引关键字不可以重复.
(4)普通索引简单的理解就是只起排序作用.索引关键字是可以重复的.可存在于自由表.
CREATE UNIQUE **INDEX** test_UniqueKey **ON** test (UniqueKey);
-
主键与唯一索引的区别
主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。 主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。 唯一性索引列允许空值,而主键列不允许为空值。 主键列在创建时,已经默认为空值 + 唯一索引了。 主键可以被其他表引用为外键,而唯一索引不能。 一个表最多只能创建一个主键,但可以创建多个唯一索引。 主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。 在 RBO 模式下,主键的执行计划优先级要高于唯一索引。 两者可以提高查询的速度。
-
聚集索引:
决定物理顺序,所以一个表只能有一个聚集索引、
对有顺序或自增列更有效 eg:日期等、
对值只有唯一值的列效率更高、
对经常排序的列效率高、
◆使用聚集索引如果插入新数据会进行重新排序
create clustered index CLU_ABC on abc(A)
◆删除聚集索引,会发现表的顺序不会发生改变。
create nonclustered index NONCLU_ABC on abc(A)
一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。
聚集索引确定表中数据的物理顺序。聚集索引类似于电话簿,后者按姓氏排列数据。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。
聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如,如果应用程序执行的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚集(物理排序),避免每次查询该列时都进行排序,从而节省成本。
当索引值唯一时,使用聚集索引查找特定的行也很有效率。例如,使用唯一雇员 ID 列 emp_id 查找特定雇员的最快速的方法,是在 emp_id 列上创建聚集索引或 PRIMARY KEY 约束。
聚集索引基于数据行的键值,在表内排序和存储这些数据行。每个表只能有一个聚集索引,应为数据行本分只能按一个顺序存储。
在聚集索引中,表中各行的物理顺序与索引键值的逻辑(索引)顺序相同。聚集索引通常可加快UPDATE和DELETE操作的速度,因为这两个操作需要读取大量的数据。创建或修改聚集索引可能要花很长时间,因为执行这两个操作时要在磁盘上对表的行进行重组。
- 非聚集索引:
因为一个表中只能有一个聚集索引,如果需要在表中建立多个索引,则可以创建为非聚集索引。表中的数据并不按照非聚集索引列的顺序存储,但非聚集索引的索引行中保存了非聚集键值和行定位器,可以快捷地根据非聚集键的值来定位记录的存储位置。
无论是聚集索引,还是非聚集索引,都可以是唯一索引。在SQL Server中,当唯一性是数据本身的特点时,可创建唯一索引,但索引列的组合不同于表的主键。例如,如果要频繁查询表Employees(该表主键为列Emp_id)的列Emp_name,而且要保证姓名是唯一的,则在列Emp_name上创建唯一索引。如果用户为多个员工输入了相同的姓名,则数据库显示错误,并且不能保存该表。
- 深入检出理解索引结构
实际上,您可以把索引理解为一种特殊的目录。微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引、簇集索引)和非聚集索引(nonclustered index,也称非聚类索引、非簇集索引)。下面,我们举例来说明一下聚集索引和非聚集索引的区别:
其实,我们的汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引” 。
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引” 。
通过以上例子,我们可以理解到什么是“聚集索引”和“非聚集索引”。进一步引申一下,我们可以很容易的理解:每个表只能有一个聚集索引,因为目录只能按照一种方法进行排序。
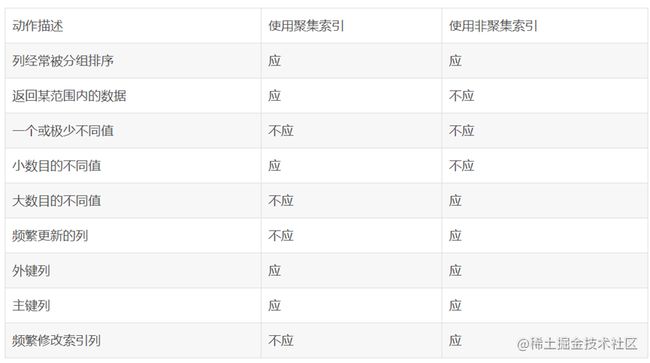
聚集:返回一个区间的列、值小数目不同、不要频繁更新*
非聚集索引 : 可以频繁更新、值大数目不同
事实上,我们可以通过前面聚集索引和非聚集索引的定义的例子来理解上表。如:返回某范围内的数据一项。比如您的某个表有一个时间列,恰好您把聚合索引建立在了该列,这时您查询2004年1月1日至2004年10月1日之间的全部数据时,这个速度就将是很快的,因为您的这本字典正文是按日期进行排序的,聚类索引只需要找到要检索的所有数据中的开头和结尾数据即可;而不像非聚集索引,必须先查到目录中查到每一项数据对应的页码,然后再根据页码查到具体内容。****
在进行数据查询时都离不开字段的是“日期”还有用户本身的“用户名”。既然这两个字段都是如此的重要,我们可以把他们合并起来,建立一个复合索引(compound index)。
9、MySql的存储引擎
9.1 Innodb引擎
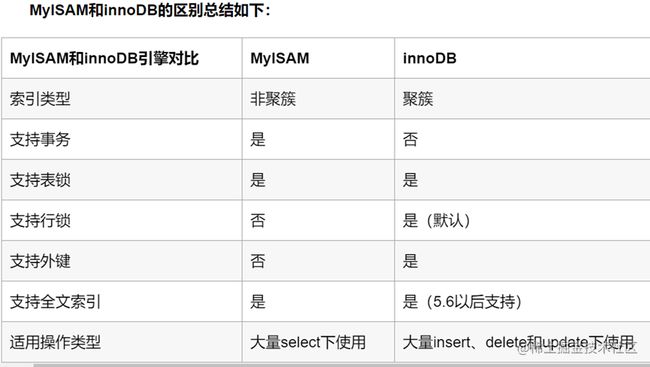
Innodb引擎现在是MySQL的默认引擎。Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别(mysql数据库默认的隔离级别是:可重复读。读未提交,读已提交,可重复读,串行化读) 。该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统***,它本身其实就是基于MySQL后台的完整数据库系统,MySQL运行时Innodb会在内存中建立缓冲池*,用于缓冲数据和索引。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当SELECT COUNT() FROM TABLE时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表。***
9.2 MyISAM引擎
在MySQL5.1之前,MyISAM是MySQL默认的引擎,它没有提供对数据库事务的支持,也不支持行级锁和外键,因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。不过和Innodb不同,MyISAM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
9.3 InNoDB与MyISAM异同
InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text (InNoDB从1.2.X版本开始支持全文搜索的技术)等索引,不支持 Hash 索引,但是给了又有一个特殊的解释:InnoDB存储引擎 是支持hash索引的,不过,我们必须启用,hash索引的创建由InnoDB存储引擎引擎自动优化创建,是数据库自身创建并使用,DBA(数据库管理员)无法干预;
MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
MyISAM引擎不支持外键,InnoDB支持外键
MyISAM引擎的表在大量高并发的读写下会经常出现表损坏的情况
对于count()查询来说MyISAM更有优势,MyISAM直接通过计数器获取,MyISAM会有一个空间转专门又来存储行数。InnoDB需要通过扫描全部数据,虽然InNoDB存储引擎是支持行级别锁,InNoDB是行级别锁,是where对他主键是有效,非主键的都会锁全表的
MyISAM 引擎的表的查询、更新、插入的效率要比InnoDB高,如果你的数据量是百万级别的,并且没有任何的事务处理,那么用MyISAM是性能最好的选择。并且MyISAM可以节省很多内存,因为MyISAM索引文件是与数据文件分开放置,并且索引是有压缩,内存使用率提高不少平台承载的大部分项目是读多写少的项目,MyISAM读性能比InNoDB强很多
9.4 两种引擎的选择
大尺寸的数据集趋向于选择InnoDB引擎,因为它支持事务处理和故障恢复。数据库的大小决定了故障恢复的时间长短,InnoDB可以利用事务日志进行数据恢复,这会比较快。
主键查询在InnoDB引擎下也会相当快,不过需要注意的是如果主键太长也会导致性能问题,因为在检索索引树的时候不管是主键索引还是辅助键索引最终都是会通过比较主键来进行检索进而取得行数据的,如果逐渐太长,那么比较主键的操作也会变复杂。
大批的INSERT语句(在每个INSERT语句中写入多行,批量插入)在MyISAM下会快一些
但是UPDATE语句在InnoDB下则会更快一些,尤其是在并发量大的时候。
六、git基础知识
1、git提交代码
-
创建远程仓库(GitHub,Gitee,coding…)
-
如果没有本地仓库
echo “# toutiao-publish-admin” >> README.md
-
初始化本地仓库
git init
-
把文件添加到暂存区
git add README.md
-
把暂存区文件提交到本地仓库形成历史记录
git commit -m “first commit”
-
添加远程仓库地址到本地仓库
git remote add origin https://github.com/hyjAdmin/toutiao-publish-admin.git
-
推送到远程仓库
git push -u origin master
-
如果已有本地仓库
-
VueCli 在创建项目的时候自动帮我们初始化了Git仓库,并且基于初始化代码默认执行了一次提交
git remote add origin https://github.com/hyjAdmin/toutiao-publish-admin.git
-
-u 记住本次推送的信息,下次就不用写推送信息了,可以直接 git push
git push -u origin master
-
-
之后如果代码有变动需要提交
git add git commit-
推送到远程仓库
git push
-
-
项目修改 git 远程仓库地址
(1)查看所有远程仓库,一般默认远程仓库名为origin git remote (2)修改当前项目远程地址为 http://192.168.1.88:9090/test/git_test.git git remote set-url origin http://192.168.1.88:9090/test/git_test.git (3)更改地址后,需要提交初始代码到远程库 git push
2、git创建和合并分支命令
查看分支:git branch
创建分支:git branch <name>
切换分支:git checkout <name>
创建+切换分支:git checkout -b <name>
合并某分支到当前分支:git merge <分支名> 合并分支时,加上--no-ff参数就可以用普通模式合并,合并后的历史有分支,能看出来曾经做过合并,而不加--no-ff合并就看不出来曾经做过合并。例git merge --no-ff -m "详细解释" 分支
删除分支:git branch -d <name>
查看分支合并图: git log --graph
3、gitlib配置SSH Key
在继续阅读后续内容前,请自行注册GitLab账号(一般进公司,配置管理员或者组长会给你创建账户的)。由于你的本地Git仓库和GitLab仓库之间的传输是通过SSH加密的,所以,需要以下设置:
3.1 第1步:
创建SSH Key。在用户主目录下,看看有没有.ssh目录,如果有,再看看这个目录下有没有id_rsa和id_rsa.pub这两个文件,如果已经有了,可直接跳到下一步。如果没有,打开Shell(Windows下打开Git Bash),创建SSH Key:
$ ssh-keygen -t rsa -C "[email protected]"
你需要把邮件地址换成你自己的邮件地址,然后一路回车,使用默认值即可,由于这个Key也不是用于军事目的,所以也无需设置密码。
如果一切顺利的话,可以在用户主目录里找到.ssh目录,里面有id_rsa和id_rsa.pub两个文件,这两个就是SSH Key的秘钥对,id_rsa是私钥,不能泄露出去,id_rsa.pub是公钥,可以放心地告诉任何人。
3.2 第2步:
登陆GitLab,打开“settings”,“SSH Keys”页面:
然后,点“Add SSH Key”,填上任意Title,在Key文本框里粘贴id_rsa.pub文件的内容:
点“Add Key”,你就应该看到已经添加的Key:

为什么GitLab需要SSH Key呢?因为GitLab需要识别出你推送的提交确实是你推送的,而不是别人冒充的,而Git支持SSH协议,所以,GitLab只要知道了你的公钥,就可以确认只有你自己才能推送。
当然,GitLab允许你添加多个Key。假定你有若干电脑,你一会儿在公司提交,一会儿在家里提交,只要把每台电脑的Key都添加到GitLab,就可以在每台电脑上往GitLab推送了。
其他的操作就和GitHub是一样的了.
七、Linux基础知识
1、从认识操作系统开始
1.1 操作系统简介
我通过以下四点介绍什么操作系统:
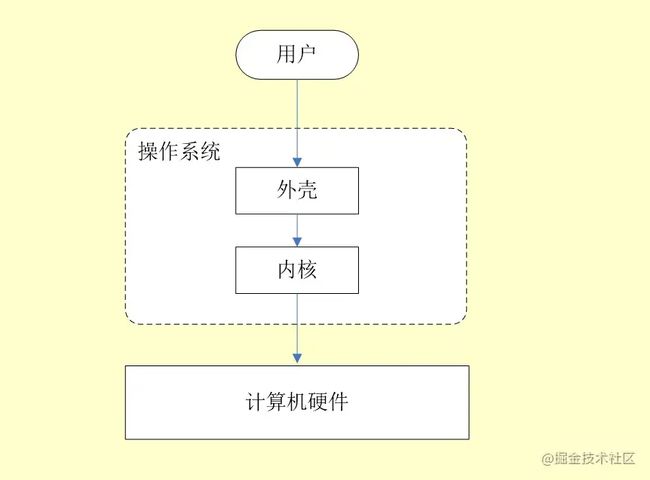
- 操作系统(Operation System,简称OS)是管理计算机硬件与软件资源的程序,是计算机系统的内核与基石;
- 操作系统本质上是运行在计算机上的软件程序 ;
- 为用户提供一个与系统交互的操作界面 ;
- 操作系统分内核与外壳(我们可以把外壳理解成围绕着内核的应用程序,而内核就是能操作硬件的程序)。
1.2 操作系统简单分类
-
Windows: 目前最流行的个人桌面操作系统 ,不做多的介绍,大家都清楚。
-
Unix: 最早的多用户、多任务操作系统 .按照操作系统的分类,属于分时操作系统。Unix 大多被用在服务器、工作站,现在也有用在个人计算机上。它在创建互联网、计算机网络或客户端/服务器模型方面发挥着非常重要的作用。

-
Linux: Linux是一套免费使用和自由传播的类Unix操作系统.Linux存在着许多不同的Linux版本,但它们都使用了 Linux内核 。Linux可安装在各种计算机硬件设备中,比如手机、平板电脑、路由器、视频游戏控制台、台式计算机、大型机和超级计算机。严格来讲,Linux这个词本身只表示Linux内核,但实际上人们已经习惯了用Linux来形容整个基于Linux内核,并且使用GNU 工程各种工具和数据库的操作系统。

2、初探Linux
2.1 Linux简介
我们上面已经介绍到了Linux,我们这里只强调三点。
- 类Unix系统: Linux是一种自由、开放源码的类似Unix的操作系统
- Linux内核: 严格来说,Linux这个词本身只表示Linux内核
- Linux之父: 一个编程领域的传奇式人物。他是Linux内核的最早作者,随后发起了这个开源项目,担任Linux内核的首要架构师与项目协调者,是当今世界最著名的电脑程序员、黑客之一。他还发起了Git这个开源项目,并为主要的开发者。

2.2 Linux诞生简介
- 1991年,芬兰的业余计算机爱好者Linus Torvalds编写了一款类似Minix的系统(基于微内核架构的类Unix操作系统)被ftp管理员命名为Linux 加入到自由软件基金的GNU计划中;
- Linux以一只可爱的企鹅作为标志,象征着敢作敢为、热爱生活。
2.3 Linux的分类
Linux根据原生程度,分为两种:
-
内核版本: Linux不是一个操作系统,严格来讲,Linux只是一个操作系统中的内核。内核是什么?内核建立了计算机软件与硬件之间通讯的平台,内核提供系统服务,比如文件管理、虚拟内存、设备I/O等;
-
发行版本: 一些组织或公司在内核版基础上进行二次开发而重新发行的版本。Linux发行版本有很多种(ubuntu和CentOS用的都很多,初学建议选择CentOS),如下图所示:

3、Linux文件系统概览
3.1 Linux文件系统简介
在Linux操作系统中,所有被操作系统管理的资源,例如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或是目录都被看作是一个文件。
也就是说在LINUX系统中有一个重要的概念:一切都是文件。其实这是UNIX哲学的一个体现,而Linux是重写UNIX而来,所以这个概念也就传承了下来。在UNIX系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。
3.2 文件类型与目录结构
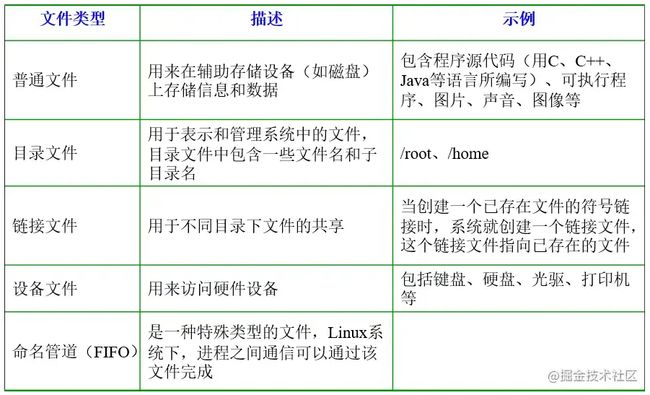
Linux支持5种文件类型 :
Linux的目录结构如下:
Linux文件系统的结构层次鲜明,就像一棵倒立的树,最顶层是其根目录:
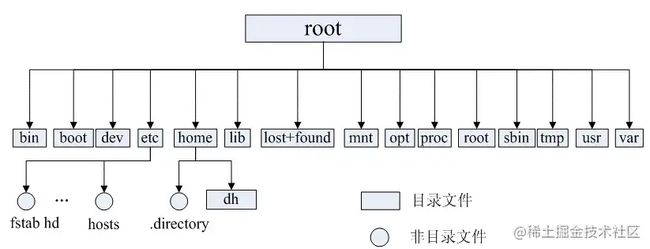
常见目录说明:
- /bin: 存放二进制可执行文件(ls,cat,mkdir等),常用命令一般都在这里;
- /etc: 存放系统管理和配置文件;
- /home: 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示;
- /usr : 用于存放系统应用程序;
- /opt: 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里;
- /proc: 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
- /root: 超级用户(系统管理员)的主目录(特权阶级o);
- /sbin: 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等;
- /dev: 用于存放设备文件;
- /mnt: 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
- /boot: 存放用于系统引导时使用的各种文件;
- /lib : 存放着和系统运行相关的库文件 ;
- /tmp: 用于存放各种临时文件,是公用的临时文件存储点;
- /var: 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
- /lost+found: 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里。
4、Linux基本命令
下面只是给出了一些比较常用的命令。推荐一个Linux命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。
Linux命令大全:man.linuxde.net/
4.1 目录切换命令
cd usr: 切换到该目录下usr目录cd ..(或cd../): 切换到上一层目录cd /: 切换到系统根目录cd ~: 切换到用户主目录cd -: 切换到上一个所在目录
4.2 目录的操作命令(增删改查)
-
mkdir 目录名称: 增加目录 -
ls或者ll(ll是ls -l的缩写,ll命令以看到该目录下的所有目录和文件的详细信息):查看目录信息 -
find 目录 参数: 寻找目录(查)示例:
- 列出当前目录及子目录下所有文件和文件夹:
find . - 在
/home目录下查找以.txt结尾的文件名:find /home -name "*.txt" - 同上,但忽略大小写:
find /home -iname "*.txt" - 当前目录及子目录下查找所有以.txt和.pdf结尾的文件:
find . ( -name "*.txt" -o -name "*.pdf" )或find . -name "*.txt" -o -name "*.pdf"
- 列出当前目录及子目录下所有文件和文件夹:
-
mv 目录名称 新目录名称: 修改目录的名称(改)注意:mv的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩包等进行 重命名的操作。mv命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。后面会介绍到mv命令的另一个用法。
-
mv 目录名称 目录的新位置: 移动目录的位置—剪切(改)注意:mv语法不仅可以对目录进行剪切操作,对文件和压缩包等都可执行剪切操作。另外mv与cp的结果不同,mv好像文件“搬家”,文件个数并未增加。而cp对文件进行复制,文件个数增加了。
-
cp -r 目录名称 目录拷贝的目标位置: 拷贝目录(改),-r代表递归拷贝注意:cp命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r递归
-
rm [-rf] 目录: 删除目录(删)注意:rm不仅可以删除目录,也可以删除其他文件或压缩包,为了增强大家的记忆, 无论删除任何目录或文件,都直接使用
rm -rf目录/文件/压缩包
4.3 文件的操作命令(增删改查)
-
touch 文件名称: 文件的创建(增) -
cat/more/less/tail 文件名称文件的查看(查)cat: 只能显示最后一屏内容more: 可以显示百分比,回车可以向下一行, 空格可以向下一页,q可以退出查看less: 可以使用键盘上的PgUp和PgDn向上 和向下翻页,q结束查看tail-10: 查看文件的后10行,Ctrl+C结束
注意:命令 tail -f 文件 可以对某个文件进行动态监控,例如tomcat的日志文件, 会随着程序的运行,日志会变化,可以使用tail -f catalina-2016-11-11.log 监控 文 件的变化
-
vim 文件: 修改文件的内容(改)vim编辑器是Linux中的强大组件,是vi编辑器的加强版,vim编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用vim编辑修改文件的方式基本会使用就可以了。
在实际开发中,使用vim编辑器主要作用就是修改配置文件,下面是一般步骤:
vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q! (输入wq代表写入内容并退出,即保存;输入q!代表强制退出不保存。)
-
rm -rf 文件: 删除文件(删)同目录删除:熟记
rm -rf文件 即可
4.4 压缩文件的操作命令
1)打包并压缩文件:
Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.gz结尾的。
而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般.tar.gz。 命令:tar -zcvf 打包压缩后的文件名 要打包压缩的文件 其中:
z:调用gzip压缩命令进行压缩
c:打包文件
v:显示运行过程
f:指定文件名
比如:加入test目录下有三个文件分别是 :aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz可以使用命令:tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt或:tar -zcvf test.tar.gz /test/
2)解压压缩包:
命令:tar [-xvf] 压缩文件
其中:x:代表解压
示例:
1 将/test下的test.tar.gz解压到当前目录下可以使用命令:tar -xvf test.tar.gz
2 将/test下的test.tar.gz解压到根目录/usr下:tar -xvf xxx.tar.gz -C /usr(- C代表指定解压的位置)
4.5 Linux的权限命令
操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在Linux中权限一般分为读(readable)、写(writable)和执行(excutable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。通过 ls -l 命令我们可以 查看某个目录下的文件或目录的权限
示例:在随意某个目录下ls -l
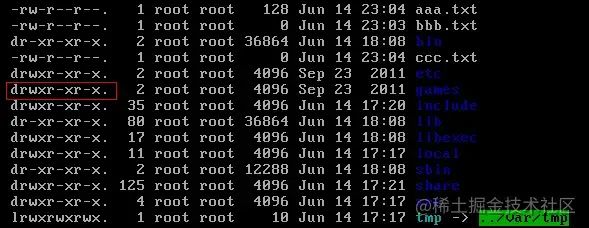
第一列的内容的信息解释如下:
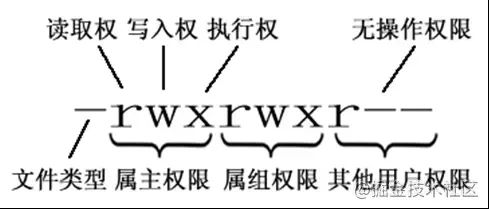
下面将详细讲解文件的类型、Linux中权限以及文件有所有者、所在组、其它组具体是什么?
文件的类型:
- d: 代表目录
- -: 代表文件
- l: 代表链接(可以认为是window中的快捷方式)
Linux中权限分为以下几种:
- r:代表权限是可读,r也可以用数字4表示
- w:代表权限是可写,w也可以用数字2表示
- x:代表权限是可执行,x也可以用数字1表示
文件和目录权限的区别:
对文件和目录而言,读写执行表示不同的意义。
对于文件:
| 权限名称 | 可执行操作 |
|---|---|
| r | 可以使用cat查看文件的内容 |
| w | 可以修改文件的内容 |
| x | 可以将其运行为二进制文件 |
对于目录:
| 权限名称 | 可执行操作 |
|---|---|
| r | 可以查看目录下列表 |
| w | 可以创建和删除目录下文件 |
| x | 可以使用cd进入目录 |
在linux中的每个用户必须属于一个组,不能独立于组外。在linux中每个文件有所有者、所在组、其它组的概念。
-
所有者
一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用ls ‐ahl命令可以看到文件的所有者 也可以使用chown 用户名 文件名来修改文件的所有者 。
-
文件所在组
当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组 用ls ‐ahl命令可以看到文件的所有组 也可以使用chgrp 组名 文件名来修改文件所在的组。
-
其它组
除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组
我们再来看看如何修改文件/目录的权限。
修改文件/目录的权限的命令:chmod
示例:修改/test下的aaa.txt的权限为属主有全部权限,属主所在的组有读写权限, 其他用户只有读的权限
chmod u=rwx,g=rw,o=r aaa.txt
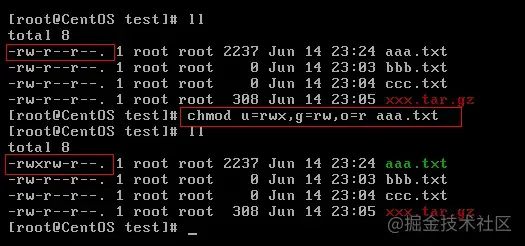
上述示例还可以使用数字表示:
chmod 764 aaa.txt
补充一个比较常用的东西:
假如我们装了一个zookeeper,我们每次开机到要求其自动启动该怎么办?
- 新建一个脚本zookeeper
- 为新建的脚本zookeeper添加可执行权限,命令是:
chmod +x zookeeper - 把zookeeper这个脚本添加到开机启动项里面,命令是:
chkconfig --add zookeeper - 如果想看看是否添加成功,命令是:
chkconfig --list
4.6 Linux 用户管理
Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
Linux用户管理相关命令:
useradd 选项 用户名:添加用户账号userdel 选项 用户名:删除用户帐号usermod 选项 用户名:修改帐号passwd 用户名:更改或创建用户的密码passwd -S 用户名:显示用户账号密码信息passwd -d 用户名: 清除用户密码
useradd命令用于Linux中创建的新的系统用户。useradd可用来建立用户帐号。帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号。使用useradd指令所建立的帐号,实际上是保存在/etc/passwd文本文件中。
passwd命令用于设置用户的认证信息,包括用户密码、密码过期时间等。系统管理者则能用它管理系统用户的密码。只有管理者可以指定用户名称,一般用户只能变更自己的密码。
4.7 Linux系统用户组的管理
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
Linux系统用户组的管理相关命令:
groupadd 选项 用户组:增加一个新的用户组groupdel 用户组:要删除一个已有的用户组groupmod 选项 用户组: 修改用户组的属性
4.8 其他常用命令
-
pwd: 显示当前所在位置 -
grep 要搜索的字符串 要搜索的文件 --color: 搜索命令,–color代表高亮显示 -
ps -ef/ps aux: 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:ps aux|grep redis(查看包括redis字符串的进程)注意:如果直接用ps((Process Status))命令,会显示所有进程的状态,通常结合grep命令查看某进程的状态。
-
kill -9 进程的pid: 杀死进程(-9 表示强制终止。)先用ps查找进程,然后用kill杀掉
-
网络通信命令:
- 查看当前系统的网卡信息:ifconfig
- 查看与某台机器的连接情况:ping
- 查看当前系统的端口使用:netstat -an
-
shutdown:shutdown -h now: 指定现在立即关机;shutdown +5 "System will shutdown after 5 minutes":指定5分钟后关机,同时送出警告信息给登入用户。 -
reboot:reboot: 重开机。reboot -w: 做个重开机的模拟(只有纪录并不会真的重开机)。
八、npm 和 yarn
标签: nodejs 电脑 yarn环境变量 yarn安装
Yarn是由Facebook、Google、Exponent 和 Tilde 联合推出了一个新的JS 包管理工具 ,正如官方文档中写的,Yarn 是为了弥补 npm 的一些缺陷而出现的。yarn和npm一样,都可以用来添加和删除某个软件包,但yarn比npm安装软件包的速度更快,安装语法也更简洁。
命令对比如下:
npm install <==> yarn
npm install taco --save <==> yarn add taco
npm uninstall taco --save <==> yarn remove taco
npm install taco --save-dev <==> yarn add taco --dev
npm update --save <==> yarn upgrade
下面介绍在win10平台上,yarn工具的安装和环境配置。
1、使用PowerShell的管理员方式安装yarn工具
1.1 按Win+R,输入:powershell–>回车,弹出第一个蓝色的PowerShell,在里面输入命令:
Start-Process powershell -Verb runAs
1.2 在第二个弹出的蓝色框框里,继续输入如下命令:
set-ExecutionPolicy RemoteSigned
1.3 输入yarn的全局安装命令:
npm install -g yarn
2、配置yarn环境变量
这里以node的默认路径,即C:\Program Files为例进行说明。当然,如果你的node安装在其他盘,将其改成node的实际路径即可。
2.1 在系统环境变量里,添加一个NODE_PATH变量,如下:
点击[我的电脑] -->属性–> 高级系统变量 -->环境变量 --> 系统变量 -->新建:
变量名:NODE_PATH
路径:C:\Program Files\nodejs\node_global\node_modules;

图(1) 添加NODE_PATH系统变量
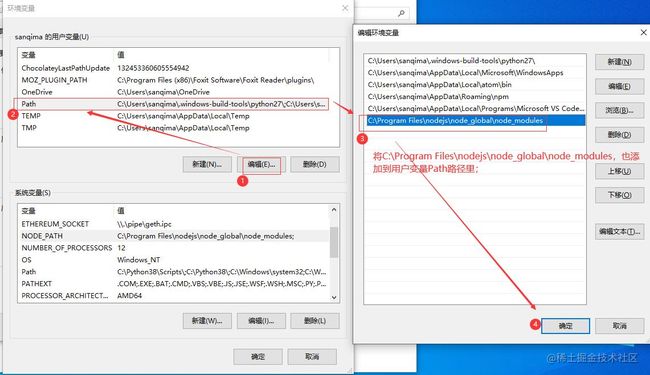
2.2 同时,将上面的C:\Program Files\nodejs\node_global\node_modules路径,也添加到[用户变量]的Path里,如图(2)所示:
图(2) 在用户变量Path里也添加一份相同的路径
2.3 设置node软件包的全局安装目录和缓存目录,在powershell管理员的蓝色框框里,输入如下2个命令即可:
npm config set prefix "C:\Program Files\nodejs\node_global"
npm config set cache "C:\Program Files\nodejs\node_cache"
2.4设置淘宝镜像
npm install -g cnpm --registry=https://registry.npm.taobao.org
3、重启电脑
4、进入powershell的蓝色框框,输入如下命令:
yarn -v
若有版本信息打印,说明yarn的环境变量设置成功,即yarn命令能被系统识别。如图(3)所示:
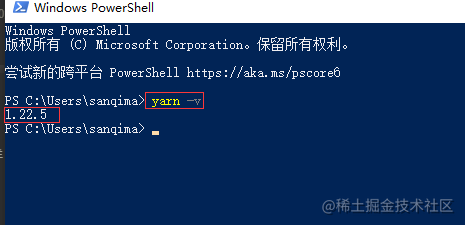
图(3) 能打印yarn的版本信息,即说明环境配置成功
九、CDN与存储
1、什么是CDN
CDN的全称是Content Delivery Network,即内容分发网络。
我们都用过天猫超市,在上面买东西非常方便。天猫超市的模式是货品先入天猫超市(后文简称为"猫超")的菜鸟仓,然后由猫超统一派送的。
为了缩短物流的时间,可以让消费者快速的收到货品,菜鸟在全国各地建了本地仓库,现在大多数情况下,在猫超下单,第二天都可以收到(楼主在江浙沪包邮区,其他地区可能稍有延迟)。
比如我在杭州市西湖区,下单购买了一箱零食,没过多久就可以看到猫超已经发货了,发货地址是杭州的萧山仓,从杭州的一个区运输到另外一个区,24小时怎么也到了。

猫超的配送采用的是智能仓配模式,菜鸟为天猫超市提供全国智能分仓,在商品销售前就已经来到距离消费者最近的仓储基地,下单购买后,由最近的仓发货,就近配送,速度比跨越多个省市跑过来的快多了。
我们可以在菜鸟网络的官网上看到其全国各地的仓库情况,我们可以看到他目前覆盖了全国20哥省份,70个城市,共有327各仓库。这些仓库组合在一起被称之为"全国仓网"。

图:菜鸟全国仓配网络
我们在浏览网络的时候,其实就和以上这个过程十分相似,我们访问一个页面的时候,会向服务器请求很多网络资源,包括各种图片、声音、影片、文字等信息。这和我们要购买的多种货物一样。
就像猫超会把货物提前存储在菜鸟建设在全国各地的本地仓库来减少物流时间一样,网站也可以预先把内容分发至全国各地的加速节点。这样用户就可以就近获取所需内容,避免网络拥堵、地域、运营商等因素带来的访问延迟问题,有效提升下载速度、降低响应时间,提供流畅的用户体验。
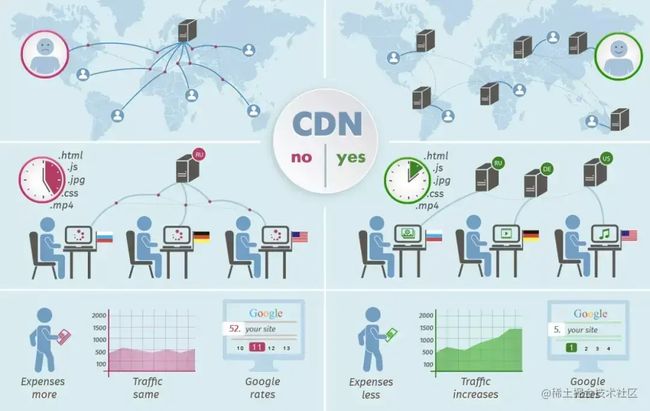
所以,"内容分发网络"就像前面提到的"全国仓配网络"一样,解决了因分布、带宽、服务器性能带来的访问延迟问题,适用于站点加速、点播、直播等场景。使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度和成功率。
1.1 有了仓配网络之后,除了可以提升货物的配送效率,还有很多其他的好处:
1)首先通过预先做好了货物分发,使得最终货品从出仓到消费者手中的过程是比较短的,那么同城范围内可选择的配送公司就有很多选择,除了比较大的四通一达、顺丰以外,还可以选用一些小的物流公司、甚至菜鸟直接调用饿了么的蜂鸟配送也不是不可能。
CDN技术消除了不同运营商之间互联的瓶颈造成的影响,实现了跨运营商的网络加速,保证不同网络中的用户都能得到良好的访问质量
2)对于仓配系统来说,最大的灾难可能就是仓库发生火灾、水灾等自然灾害。如果把原来的一个集中式的大仓库打散成多个分布式的小仓库,分别部署在不同地区,就可以有效的减小自然灾害带来的影响。
广泛分布的CDN节点加上节点之间的智能冗余机制,可以有效地预防黑客入侵以及降低各种DDoS攻击对网站的影响,同时保证较好的服务质量
2、CDN的基本工作过程
传统快递企业采用的配送模式,通过"商家→网点→分拨→分拨→网点→客户"的环节进行配送。这个过程会有一些问题,如环节多、时效慢、易破损等。
上面这个过程和传统网站的请求响应过程类似,一般经历以下步骤:
- 用户在自己的浏览器中输入要访问的网站域名。
- 浏览器向本地DNS服务器请求对该域名的解析。
- 本地DNS服务器中如果缓存有这个域名的解析结果,则直接响应用户的解析请求。
- 本地DNS服务器中如果没有关于这个域名的解析结果的缓存,则以迭代方式向整个DNS系统请求解析,获得应答后将结果反馈给浏览器。
- 浏览器得到域名解析结果,就是该域名相应的服务设备的IP地址 。
- 浏览器获取IP地址之后,经过标准的TCP握手流程,建立TCP连接。
- 浏览器向服务器发起HTTP请求。
- 服务器将用户请求内容传送给浏览器。
- 经过标准的TCP挥手流程,断开TCP连接。
电商自建物流之后,配送模式有所变化:提前备货将异地件转化成同城件,省去干线环节提升时效,仓储高自动化分拣保证快速出库的同时也保证了分拣破损率较低。
对于用户来说,购物过程并没有变化,唯一的感受就是物流好像是比以前快了。所以,引入CDN之后,用户访问网站一般经历以下步骤:
- 当用户点击网站页面上的内容URL,先经过本地DNS系统解析,如果本地DNS服务器没有相应域名的缓存,则本地DNS系统会将域名的解析权交给CNAME指向的CDN专用DNS服务器。
- CDN的DNS服务器将CDN的全局负载均衡设备IP地址返回给用户。
- 用户向CDN的全局负载均衡设备发起URL访问请求。
- CDN全局负载均衡设备根据用户IP地址,以及用户请求的URL,选择一台用户所属区域的区域负载均衡设备,并将请求转发到此设备上。
- 基于以下这些条件的综合分析之后,区域负载均衡设备会选择一个最优的缓存服务器节点,并从缓存服务器节点处得到缓存服务器的IP地址,最终将得到的IP地址返回给全局负载均衡设备:
- 根据用户IP地址,判断哪一个边缘节点距用户最近;
- 根据用户所请求的URL中携带的内容名称,判断哪一个边缘节点上有用户所需内容;
- 查询各个边缘节点当前的负载情况,判断哪一个边缘节点尚有服务能力。
- 全局负载均衡设备把服务器的IP地址返回给用户。
- 用户向缓存服务器发起请求,缓存服务器响应用户请求,将用户所需内容传送到用户终端。如果这台缓存服务器上并没有用户想要的内容,而区域均衡设备依然将它分配给了用户,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
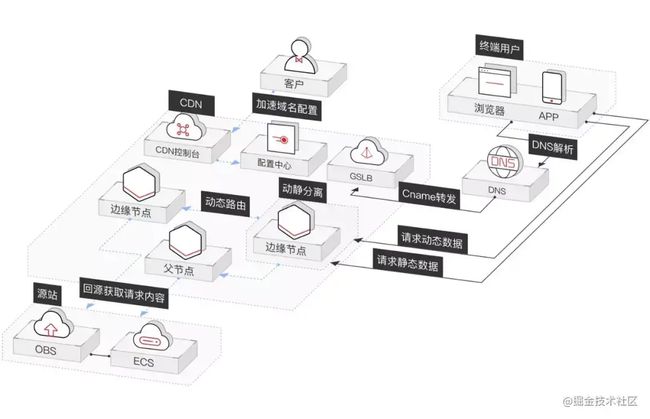
图:华为云全站加速示意图
CDN全局负载均衡设备与CDN区域负载均衡设备根据用户IP地址,将域名解析成相应节点中缓存服务器的IP地址,实现用户就近访问,从而提高服务端响应内容的速度。
3、CDN的组成
前面我们说过,一个仓配网络是由多个仓库组成的,同理,内容分发网络(CDN)是由多个节点组成的。一般来讲,CDN网络主要由中心节点、边缘节点两部分构成。
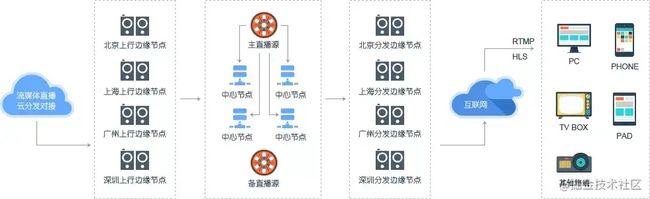
图:帝联云下载加速场景图
3.1 中心节点
中心节点包括CDN网管中心和全局负载均衡DNS重定向解析系统,负责整个CDN网络的分发及管理。
3.2 边缘节点
CDN边缘节点主要指异地分发节点,由负载均衡设备、高速缓存服务器两部分组成。
负载均衡设备负责每个节点中各个Cache的负载均衡,保证节点的工作效率;同时还负责收集节点与周围环境的信息,保持与全局负载均衡DNS的通信,实现整个系统的负载均衡。
高速缓存服务器(Cache)负责存储客户网站的大量信息,就像一个靠近用户的网站服务器一样响应本地用户的访问请求。通过全局负载均衡DNS的控制,用户的请求被透明地指向离他最近的节点,节点中Cache服务器就像网站的原始服务器一样,响应终端用户的请求。因其距离用户更近,故其响应时间才更快。
中心节点就像仓配网络中负责货物调配的总仓,而边缘节点就是负责存储货物的各个城市的本地仓库。
目前,主要由很多提供CDN服务的云厂商在各地部署了很多个CDN节点,拿阿里云举例,我们可以在阿里云的官网上了解到:阿里云在全球拥有2500+节点。中国大陆拥有2000+节点,覆盖34个省级区域,大量节点位于省会等一线城市。海外和港澳台拥有500+节点,覆盖70多个国家和地区。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J6wXrf8E-1646577368573)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/f1d4e57ee5d44e1a98714689823ab5ce~tplv-k3u1fbpfcp-zoom-1.image “-w777”)]
图:阿里云在中国大陆的CDN节点的分布情况
有了如上图的阿里云在中国大陆的CDN节点的分布之后(这是不是也和我们前面看到的那张菜鸟网络的全国仓网很像),一个在杭州的电信网络用户,访问某个部署在阿里云上面的网站时,获取到的一些资源,如页面上的某个图片、某段影片或者某些文字,可能就是该网站预先分发到浙江的某个移动CDN存储节点提供的,这样就可以大大的减少网站的响应时间。
4、CDN相关技术
首先我们想一下,要想建设一个庞大的仓配网络都需要考虑哪些问题,需要哪些技术手段呢?
笔者认为主要是四个重要关注的点,分别是:
1、如何妥善的将货物分发到各个城市的本地仓。
2、如何妥善的各个本地仓存储货物。
3、如何根据用户的收货地址,智能的匹配出应该优先从哪个仓库发货,选用哪种物流方式等。
4、对于整个仓配系统如何进行管理,如整体货物分发的精确度、仓配的时效性、发货地的匹配度等。

图:菜鸟仓库智能机器人分拣货物
这其实和CDN中最重要的四大技术不谋而合,那就是内容发布、内容存储、内容路由以及内容管理等。
4.1 内容发布
它借助于建立索引、缓存、流分裂、组播(Multicast)等技术,将内容发布或投递到距离用户最近的远程服务点(POP)处。
4.2 内容存储
对于CDN系统而言,需要考虑两个方面的内容存储问题。一个是内容源的存储,一个是内容在 Cache节点中的存储。
4.3 内容路由
它是整体性的网络负载均衡技术,通过内容路由器中的重定向(DNS)机制,在多个远程POP上均衡用户的请求,以使用户请求得到最近内容源的响应。
4.4 内容管理
它通过内部和外部监控系统,获取网络部件的状况信息,测量内容发布的端到端性能(如包丢失、延时、平均带宽、启动时间、帧速率等),保证网络处于最佳的运行状态。