马尔可夫链 (Markov Chains)
目录
- 马尔可夫链
-
- 马尔可夫链的基本定义
- 离散状态马尔可夫链 (Finite-State Markov Chains)
-
- 转移概率矩阵
- 状态分布
- 平稳分布 (steady-state vector / equilibrium vector)
-
- 平稳分布的定义
- 平稳分布的存在性
- 如何找到平稳分布?
- 连续状态马尔可夫链
- 马尔可夫链的简单应用
-
- 语言模型
- Signal Transmission
- Random Walks on { 1 , . . . , n } \{1,...,n\} {1,...,n}
- Random Walks on Graphs
- 平稳分布
-
- 平稳分布一定是状态分布的极限?
- Regular Matrices (正则矩阵)
- Properties of a regular transition matrix
- 参考文献
马尔可夫链
马尔可夫链的基本定义

- 时间齐次的马尔可夫链 (time homogenous Markov chain): 转移概率分布 P ( X t ∣ X t − 1 ) P(X_t|X_{t -1}) P(Xt∣Xt−1) 与 t t t 无关,即
 (后文提到的马尔可夫链都是时间齐次的)
(后文提到的马尔可夫链都是时间齐次的) - 以上定义的是一阶马尔可夫链,可以扩展到 n n n 阶马尔可夫链,满足 n n n 阶马尔可夫性

离散状态马尔可夫链 (Finite-State Markov Chains)
转移概率矩阵
- 若马尔可夫链在时刻 ( t − 1 ) (t -1) (t−1) 处于状态 j j j,在时刻 t t t 移动到状态 i i i,将转移概率记作
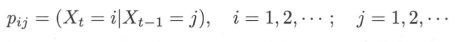 其中 p i j p_{ij} pij 满足下式,即 p j \boldsymbol p_j pj 是一个概率向量 (probability vector)
其中 p i j p_{ij} pij 满足下式,即 p j \boldsymbol p_j pj 是一个概率向量 (probability vector)
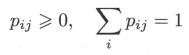 则可以构成马尔可夫链的转移概率矩阵 (矩阵的每一列都是概率向量且为方阵,即为随机矩阵 (stochastic matrix))
则可以构成马尔可夫链的转移概率矩阵 (矩阵的每一列都是概率向量且为方阵,即为随机矩阵 (stochastic matrix))

马尔可夫链的转移矩阵也可能不是随机矩阵,例如某一个状态 j j j 不会向任何其他状态转移,则转移矩阵中对应的第 j j j 列全为 0,此时转移矩阵并不是随机矩阵
状态分布
- 考虑马尔可夫链 X = { X 0 , X 1 , . . . , X t , … } X = \{X_0,X_1,...,X_t,…\} X={X0,X1,...,Xt,…} 在时刻 t t t ( t = 0 , 1 , 2 , . . . t = 0,1,2,... t=0,1,2,...) 的概率分布,称为时刻 t t t 的状态分布 或 状态向量 (state vector),记作
 其中,
其中,
 通常初始分布 π ( 0 ) \pi(0) π(0) 的向量只有一个分量是 1,其余分量都是 0,表示马尔可夫链从一个具体状态开始
通常初始分布 π ( 0 ) \pi(0) π(0) 的向量只有一个分量是 1,其余分量都是 0,表示马尔可夫链从一个具体状态开始
- 马尔可夫链 X X X 在时刻 t t t 的状态分布,可以由在时刻 ( t − 1 ) (t - 1) (t−1) 的状态分布以及转移概率分布决定
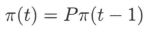 递推可得
递推可得
 这里的 P t P^t Pt 称为 t t t 步转移概率矩阵,
这里的 P t P^t Pt 称为 t t t 步转移概率矩阵,
 上式说明,马尔可夫链的状态分布由初始分布和转移概率分布决定
上式说明,马尔可夫链的状态分布由初始分布和转移概率分布决定
平稳分布 (steady-state vector / equilibrium vector)
平稳分布的定义

- 直观上,如果马尔可夫链的平稳分布存在,那么以该平稳分布作为初始分布,面向未来进行随机状态转移,之后任何一个时刻的状态分布都是该平稳分布
- 下面的例子用数值计算的方法演示了状态分布在如下的转移矩阵作用下,若干个时间步后收敛于平稳分布
EXAMPLE
Let P = [ . 5 . 2 . 3 . 3 . 8 . 3 . 2 0 . 4 ] P=\begin{bmatrix} .5&.2&.3\\ .3&.8&.3\\.2&0&.4 \end{bmatrix} P=⎣⎡.5.3.2.2.80.3.3.4⎦⎤ and x 0 = [ 1 0 0 ] \boldsymbol x_0=\begin{bmatrix} 1\\0\\0 \end{bmatrix} x0=⎣⎡100⎦⎤. Consider a system whose state is described by the Markov chain x k + 1 = P x k f o r k = 0 , 1 , 2 , . . . \boldsymbol x_{k+1}=P\boldsymbol x_k\ \ \ \ \ for\ k=0,1,2,... xk+1=Pxk for k=0,1,2,... What happens to the system as time passes?
SOLUTION

- The results of further calculations are shown below, with entries rounded to four or five significant figures.
 These vectors seem to be approaching q = [ . 3 . 6 . 1 ] \boldsymbol q=\begin{bmatrix} .3\\.6\\.1 \end{bmatrix} q=⎣⎡.3.6.1⎦⎤. The probabilities are hardly changing from one value of k k k to the next. Observe that the following calculation is exact (with no rounding error):
These vectors seem to be approaching q = [ . 3 . 6 . 1 ] \boldsymbol q=\begin{bmatrix} .3\\.6\\.1 \end{bmatrix} q=⎣⎡.3.6.1⎦⎤. The probabilities are hardly changing from one value of k k k to the next. Observe that the following calculation is exact (with no rounding error): When the system is in state q \boldsymbol q q, there is no change in the system from one measurement to the next.
When the system is in state q \boldsymbol q q, there is no change in the system from one measurement to the next. - Increasing powers of the transition matrix P P P may also be computed, as follows
 so the sequence of matrices { P n } \{P^n\} {Pn} also seems to be converging to a matrix as n n n increases, and this matrix has the unusual property that all of its columns equal q \boldsymbol q q. (这是合理的,因为这样不管初始分布 x x x 是什么, P n x P^nx Pnx 都收敛于 q q q)
so the sequence of matrices { P n } \{P^n\} {Pn} also seems to be converging to a matrix as n n n increases, and this matrix has the unusual property that all of its columns equal q \boldsymbol q q. (这是合理的,因为这样不管初始分布 x x x 是什么, P n x P^nx Pnx 都收敛于 q q q)
平稳分布的存在性
- 马尔可夫链可能存在唯一平稳分布,无穷多个平稳分布,或不存在平稳分布 (当离散状态马尔可夫链有无穷多个状态时,有可能没有平稳分布)。但 如果马尔可夫链的转移矩阵为随机矩阵,则一定存在平稳分布
证明
- (1) 首先证明随机矩阵 P P P 必有特征值 1:即证 d e t ( P − I ) = 0 det(P-I)=0 det(P−I)=0,而 P − I P-I P−I 的每一列的和都为 0,因此可以将 P − I P-I P−I 的前 n − 1 n-1 n−1 行加到第 n n n 行上,必可将第 n n n 行化为 0 行,因此 d e t ( P − I ) = 0 det(P-I)=0 det(P−I)=0, ( P − I ) π = 0 (P-I)\pi=0 (P−I)π=0 必有非平凡解,即一定存在平稳分布
- (2) 再证明一条辅助结论:若 A A A 为一个 m × m m\times m m×m 的随机矩阵, x ∈ R m x\in\R^m x∈Rm, y = A x y=Ax y=Ax,则有
∣ y 1 ∣ + . . . + ∣ y m ∣ ≤ ∣ x 1 ∣ + . . . + ∣ x m ∣ |y_1|+...+|y_m|\leq|x_1|+...+|x_m| ∣y1∣+...+∣ym∣≤∣x1∣+...+∣xm∣当且仅当 x x x 所有元素符号相同时取等号。下面进行证明:设 A = [ a 1 T . . . a m T ] A=\begin{bmatrix}a_1^T\\...\\a_m^T\end{bmatrix} A=⎣⎡a1T...amT⎦⎤ ( ∑ i m a i = 1 \sum_i^ma_i=\boldsymbol 1 ∑imai=1), ∣ x ∣ = [ ∣ x 1 ∣ . . . ∣ x m ∣ ] |x|=\begin{bmatrix}|x_1|\\...\\|x_m|\end{bmatrix} ∣x∣=⎣⎡∣x1∣...∣xm∣⎦⎤,因此
∑ i = 1 m ∣ y i ∣ = ∑ i = 1 m ∣ a i T x ∣ = ∑ i = 1 m ∣ ∑ j = 1 m a i j x j ∣ ≤ ∑ i = 1 m ∑ j = 1 m a i j ∣ x j ∣ = ∑ i = 1 m a i T ∣ x ∣ = 1 T ∣ x ∣ = ∑ i = 1 m ∣ x i ∣ \begin{aligned}\sum_{i=1}^m|y_i|&=\sum_{i=1}^m|a_i^Tx|=\sum_{i=1}^m|\sum_{j=1}^ma_{ij}x_j| \\&\leq\sum_{i=1}^m\sum_{j=1}^ma_{ij}|x_j|=\sum_{i=1}^ma_i^T|x| \\&=\boldsymbol 1^T|x|=\sum_{i=1}^m|x_i| \end{aligned} i=1∑m∣yi∣=i=1∑m∣aiTx∣=i=1∑m∣j=1∑maijxj∣≤i=1∑mj=1∑maij∣xj∣=i=1∑maiT∣x∣=1T∣x∣=i=1∑m∣xi∣ - (3) 下面就借助上面两条结论进行最终的证明:由 (1) 可知,存在 v v v 使得 P v = v Pv=v Pv=v,又由 (2) 可知, v v v 的所有元素符号必相同。在将 v v v 进行归一化后 (将 v v v 的所有元素除以它们的和) 就能得到平稳分布
如何找到平稳分布?
EXAMPLE
Let P = [ . 6 . 3 . 4 . 7 ] P=\begin{bmatrix} .6&.3\\ .4&.7\end{bmatrix} P=[.6.4.3.7]. Find a steady-state vector for P P P.
SOLUTION
- First, solve the equation P x = x P\boldsymbol x = \boldsymbol x Px=x.
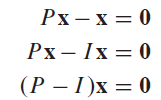 For P P P as above,
For P P P as above,
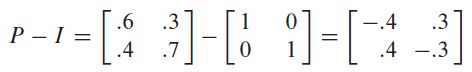 Row reduce the augmented matrix:
Row reduce the augmented matrix:
 The general solution is x 2 [ 3 / 4 1 ] x_2\begin{bmatrix} 3/4\\1\end{bmatrix} x2[3/41].
The general solution is x 2 [ 3 / 4 1 ] x_2\begin{bmatrix} 3/4\\1\end{bmatrix} x2[3/41]. - Next, choose a simple basis for the solution space. Divide x 2 \boldsymbol x_2 x2 by the sum of its entries and obtain
q = [ 3 / 7 4 / 7 ] \boldsymbol q=\begin{bmatrix}3/7\\4/7\end{bmatrix} q=[3/74/7]
连续状态马尔可夫链
- 连续状态马尔可夫链 X = { X 0 , . . . , X t , . . . } X = \{X_0,...,X_t,...\} X={X0,...,Xt,...},随机变量 X t X_t Xt ( t = 0 , 1 , 2 , . . . ) (t = 0, 1,2,...) (t=0,1,2,...) 定义在连续状态空间 S \mathcal S S,转移概率分布由概率转移核或转移核 (transition kernel) 表示
- 对任意的 x ∈ S x\in\mathcal S x∈S, A ⊂ S A\subset S A⊂S,转移核 P ( x , A ) P(x ,A) P(x,A) 定义为
 其中 p ( x , • ) p(x, •) p(x,•) 是概率密度函数,满足 p ( x i , • ) ≥ 0 p(x_i,•)\geq 0 p(xi,•)≥0, P ( x , S ) = ∫ S p ( x , y ) d y = 1 P(x,\mathcal S) = \int_{\mathcal S} p(x,y)dy = 1 P(x,S)=∫Sp(x,y)dy=1。转移核 P ( x , A ) P(x,A) P(x,A) 表示从 x ∼ A x\sim A x∼A 的转移概率
其中 p ( x , • ) p(x, •) p(x,•) 是概率密度函数,满足 p ( x i , • ) ≥ 0 p(x_i,•)\geq 0 p(xi,•)≥0, P ( x , S ) = ∫ S p ( x , y ) d y = 1 P(x,\mathcal S) = \int_{\mathcal S} p(x,y)dy = 1 P(x,S)=∫Sp(x,y)dy=1。转移核 P ( x , A ) P(x,A) P(x,A) 表示从 x ∼ A x\sim A x∼A 的转移概率

- 对任意的 x ∈ S x\in\mathcal S x∈S, A ⊂ S A\subset S A⊂S,转移核 P ( x , A ) P(x ,A) P(x,A) 定义为
- 连续状态马尔可夫链的平稳分布:
 或
或
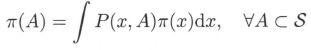
马尔可夫链的简单应用
语言模型
- 自然语言处理、语音处理中经常用到语言模型, 是建立在词表上的 n n n 阶马尔可夫链。比如, 在英语语音识别中,语音模型产生出两个候选: “How to recognize speech” 与 "How to wreck a nice beach”,语言模型要判断哪个可能性更大
- 将一个语句看作是一个单词的序列 w 1 w 2 . . . w s w_1w_2...w_s w1w2...ws,目标是计算其概率。同一个语句很少在语料中重复多次出现,所以直接从语料中估计每个语句的概率是困难的。语言模型用局部的单词序列的概率,组合计算出全局的单词序列的概率,可以很好地解决这个问题。假设每个单词只依赖于其前面出现的单词,也就是说单词序列具有马尔可夫性,那么可以定义一阶马尔可夫链 (可以轻易扩展到 n n n 阶马尔可夫链),即语言模型,如下计算语句的概率:
 如果有充分的语料,转移概率可以直接从语料中估计。直观上, “wreck a nice” 出现之后,下面出现 “beach” 的概率极低,所以第二个语句的概率应该更小,从语言模型的角度看第一个语句的可能性更大
如果有充分的语料,转移概率可以直接从语料中估计。直观上, “wreck a nice” 出现之后,下面出现 “beach” 的概率极低,所以第二个语句的概率应该更小,从语言模型的角度看第一个语句的可能性更大
Signal Transmission
- Consider the problem of transmitting a signal along a telephone line or by radio waves. Each piece of data must pass through a multi-stage process to be transmitted, and at each stage there is a probability that a transmission error will cause the data to be corrupted.
- Assume that the probability of an error in transmission is not affected by transmission errors in the past and does not depend on time, and that the number of possible pieces of data is finite. The transmission process may then be modeled by a Markov chain, with states 0 and 1 and transition matrix
 , where p p p is the probability that the bit will pass through the stage unchanged
, where p p p is the probability that the bit will pass through the stage unchanged

Random Walks on { 1 , . . . , n } \{1,...,n\} {1,...,n}
- Think of the states { 1 , . . . , n } \{1,...,n\} {1,...,n} as lying on a line. Place an object at a point that is not on the end of the line. At each step the object moves left one unit with probability p p p and right one unit with probability 1 − p 1-p 1−p
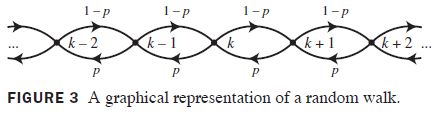 The object must move to either the left or the right at the states 2 , . . . , n − 1 2,...,n-1 2,...,n−1, but it cannot do this at the endpoints 1 and n n n. The molecule’s possible movements at the endpoints 1 and n n n must be specified.
The object must move to either the left or the right at the states 2 , . . . , n − 1 2,...,n-1 2,...,n−1, but it cannot do this at the endpoints 1 and n n n. The molecule’s possible movements at the endpoints 1 and n n n must be specified.
- One possibility is to have the molecule stay at an endpoint forever once it reaches either end of the line. This is called a random walk with absorbing boundaries, and the endpoints 1 and n n n are called absorbing states.
- Another possibility is to have the molecule bounce back one unit when an endpoint is reached. This is called a random walk with reflecting boundaries
- e.g. A random walk on { 1 , 2 , 3 , 4 , 5 } \{1, 2, 3, 4, 5\} {1,2,3,4,5} with absorbing boundaries has a transition matrix of
 A random walk on { 1 , 2 , 3 , 4 , 5 } \{1, 2, 3, 4, 5\} {1,2,3,4,5} with reflecting boundaries has a transition matrix of
A random walk on { 1 , 2 , 3 , 4 , 5 } \{1, 2, 3, 4, 5\} {1,2,3,4,5} with reflecting boundaries has a transition matrix of

One simple application of random walks
- Consider a very simple casino game. A gambler (who still has some money left with which to gamble) flips a fair coin and calls heads or tails. If the gambler is correct, he wins a dollar; if he is wrong, he loses a dollar. Suppose that the gambler will quit the game when he has either won n n n dollars or lost all of his money.
- Suppose that n = 7 n=7 n=7 and the gambler starts with 4 dollars. Notice that the gambler’s winnings move either up or down 1 dollar for each coin flip, and once the gambler’s winnings reach 0 or 7, they do not change any more since the gambler has quit the game. Thus the gambler’s winnings may be modeled by a random walk on { 0 , 1 , . . . , 7 } \{0,1,...,7\} {0,1,...,7} with absorbing boundaries.
Random Walks on Graphs
- To define a simple random walk on a graph, allow the chain to move from vertex
to vertex on the graph. At each step, the chain is equally likely to move along any of the edges attached to the vertex.- e.g. Suppose a mouse runs through the five-room maze. The mouse moves to a different room at each time step. When the mouse is in a particular room, it is equally likely to choose any of the doors out of the room. Note that a Markov chain can model the motion of the mouse.
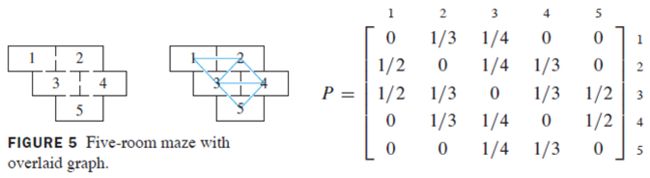
- e.g. Suppose a mouse runs through the five-room maze. The mouse moves to a different room at each time step. When the mouse is in a particular room, it is equally likely to choose any of the doors out of the room. Note that a Markov chain can model the motion of the mouse.
不仅可以在无向图上定义随机游走模型,还可以在有向图上定义随机游走模型,其中一个著名的应用就是 PageRank 算法
平稳分布
平稳分布一定是状态分布的极限?
- 虽然在之前给出的例子中,当 n → ∞ n\rightarrow\infty n→∞ 时状态序列 { x n } \{x_n\} {xn} 收敛于平稳分布 q q q,即 lim n → ∞ x n = q \lim_{n\rightarrow\infty}x_n=q limn→∞xn=q。此时平稳分布可以表示处于各个状态的长期概率 (long-run probabilities) 或处于各个状态的时间占比 (occupation times)
- 但实际上却存在有平稳分布但状态序列却不收敛于平稳分布的马尔可夫链,此时平稳分布就不能被理解为长期概率或时间占比
- 下面几个例子举出了马尔可夫链具有平稳分布但状态序列不收敛于平稳分布的情况
例
- 下面是一个在 { 1 , 2 , 3 , 4 , 5 } \{1,2,3,4,5\} {1,2,3,4,5} 上随机游走的马尔可夫链对应的转移矩阵 (with absorbing boundaries),当 n → ∞ n\rightarrow\infty n→∞ 时,模型最终一定会停在状态 1 或状态 5。下面计算一下 P n P^n Pn
 可见 P n P^n Pn 似乎收敛于如下矩阵
可见 P n P^n Pn 似乎收敛于如下矩阵
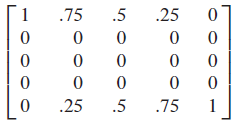 该矩阵的每一列并不相同,这意味着随着初始状态分布的不同,模型在状态 1 或状态 5 结束的概率并不相同,例如加入初始在状态 2,则有 75% 的概率结束在状态 1,25% 的概率结束在状态 5
该矩阵的每一列并不相同,这意味着随着初始状态分布的不同,模型在状态 1 或状态 5 结束的概率并不相同,例如加入初始在状态 2,则有 75% 的概率结束在状态 1,25% 的概率结束在状态 5 - 此外,可以计算得到 P P P 的平稳分布为
 其中 0 ≤ q ≤ 1 0\leq q \leq1 0≤q≤1。这意味着 P P P 有无数的稳态向量, x n x_n xn 当然也不可能收敛于所有的稳态向量
其中 0 ≤ q ≤ 1 0\leq q \leq1 0≤q≤1。这意味着 P P P 有无数的稳态向量, x n x_n xn 当然也不可能收敛于所有的稳态向量
例
- 下面是一个在 { 1 , 2 , 3 , 4 , 5 } \{1,2,3,4,5\} {1,2,3,4,5} 上随机游走的马尔可夫链对应的转移矩阵 (with reflecting boundaries)
 在上述马尔可夫链中,如果初始状态为 1,那么经过偶数步只可能到达 1、3、5,经过奇数步只能到达 2、4。但如果初始状态为 2,那么经过偶数步只可能到达 2、4,经过奇数步只能到达 1、3、5。可见 P n P^n Pn 甚至不可能收敛于一个矩阵。下面采用数值计算的方法表明 P n P^n Pn 的极限取决于 n n n 的奇偶:
在上述马尔可夫链中,如果初始状态为 1,那么经过偶数步只可能到达 1、3、5,经过奇数步只能到达 2、4。但如果初始状态为 2,那么经过偶数步只可能到达 2、4,经过奇数步只能到达 1、3、5。可见 P n P^n Pn 甚至不可能收敛于一个矩阵。下面采用数值计算的方法表明 P n P^n Pn 的极限取决于 n n n 的奇偶:

- 虽然 P n P^n Pn 不收敛于唯一矩阵,但 P P P 却存在平稳分布:
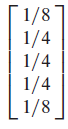
例
- 下面是一个马尔可夫链对应的转移矩阵:
 由转移矩阵可知,马尔可夫链实际上由两个分离的链组成,每个链都有自己的稳态向量:如果初始状态为 1、2、3,那么状态只会在 1、2、3 中变化;而如果初始状态为 4、5,那么状态只会在 4、5 中变化。因此 P n P^n Pn 收敛于一个各列不相同的矩阵,以下两个向量分别为两个链的稳态向量:
由转移矩阵可知,马尔可夫链实际上由两个分离的链组成,每个链都有自己的稳态向量:如果初始状态为 1、2、3,那么状态只会在 1、2、3 中变化;而如果初始状态为 4、5,那么状态只会在 4、5 中变化。因此 P n P^n Pn 收敛于一个各列不相同的矩阵,以下两个向量分别为两个链的稳态向量:

Regular Matrices (正则矩阵)

- 由于 P k P^k Pk 是 k k k 步转移概率矩阵,当 P P P 为正则矩阵时, P k P^k Pk 的所有元素均大于 0,这意味着从任意状态都可以用刚好 k k k 步到达任意其他状态
Properties of a regular transition matrix

Theorem 1 is a special case of the Perron-Frobenius Theorem, which is used in applications of linear algebra to economics, graph theory, and systems analysis.
- 上述定理说明了,如果转移矩阵是正则的 (regular),那么
- (1) 一定存在唯一的平稳分布,且当 k → ∞ k\rightarrow\infty k→∞ 时,状态序列 { x k } \{x_k\} {xk} 收敛于该平稳分布
- (2) P P P 除 1 以外的特征值 λ \lambda λ 满足 ∣ λ ∣ < 1 |\lambda|<1 ∣λ∣<1。这意味着,我们可以直接由幂法求得正则随机矩阵 P P P 的平稳分布
下面可以证明一下当 A A A 为正随机矩阵时, A A A 除 1 以外的特征值 λ \lambda λ 满足 ∣ λ ∣ < 1 |\lambda|<1 ∣λ∣<1
- 回忆一下,在 “平稳分布的存在性” 一节中,我们证明了若 A A A 为一个 m × m m\times m m×m 的随机矩阵, x ∈ R m x\in\R^m x∈Rm, y = A x y=Ax y=Ax,则有
∣ y 1 ∣ + . . . + ∣ y m ∣ ≤ ∣ x 1 ∣ + . . . + ∣ x m ∣ |y_1|+...+|y_m|\leq|x_1|+...+|x_m| ∣y1∣+...+∣ym∣≤∣x1∣+...+∣xm∣当且仅当 x x x 所有元素符号相同时取等号,即 ∣ ∣ A x ∣ ∣ 1 ≤ ∣ ∣ x ∣ ∣ 1 ||Ax||_1\leq||x||_1 ∣∣Ax∣∣1≤∣∣x∣∣1 - 由以上结论可知,若 x x x 为随机矩阵 A A A 的特征向量,则有
∣ ∣ A x ∣ ∣ 1 = ∣ ∣ λ x ∣ ∣ 1 ≤ ∣ λ ∣ ∣ ∣ x ∣ ∣ 1 ≤ ∣ ∣ x ∣ ∣ 1 ||Ax||_1=||\lambda x||_1\leq|\lambda||| x||_1\leq||x||_1 ∣∣Ax∣∣1=∣∣λx∣∣1≤∣λ∣∣∣x∣∣1≤∣∣x∣∣1因此,随机矩阵的特征值的绝对值一定小于等于 1,当且仅当特征值对应的特征向量所有元素符号相同时取等号: ∣ λ ∣ ≤ 1 |\lambda|\leq1 ∣λ∣≤1下面只需证明 λ = − 1 \lambda=-1 λ=−1 一定不是 A A A 的特征值即可 - 假设 λ = − 1 \lambda=-1 λ=−1 为 A A A 的特征值,则它对应的特征向量 x x x 的所有元素同号,又因为 A A A 的各个元素均大于 0,因此 A x Ax Ax 的各个元素的符号必然与 x x x 中元素一致。然而 λ x = − x \lambda x=-x λx=−x 的各个元素符号均与 x x x 中元素相反,因此 A x = − x Ax=-x Ax=−x 一定不成立, − 1 -1 −1 一定不是正随机矩阵 A A A 的特征值,因此结论得证
参考文献
- 《统计学习方法》
- L i n e a r Linear Linear a l g e b r a algebra algebra a n d and and i t s its its a p p l i c a t i o n s applications applications
- Proof that the largest eigenvalue of a stochastic matrix is 1



