Cross-Iteration Batch Normalization
Cross-Iteration Batch Normalization
批量归一化的一个众所周知的问题是,在mini-batch的情况下,它的有效性大大降低。当一个mini-batch包含很少的例子时,在训练迭代中,无法可靠地估计归一化所依据的统计数据。为了解决这个问题,我们提出了Cross-Iteration Batch Normalization(CBN),其中来自多个最近迭代的样本被共同利用以提高估计质量。在多个迭代中计算统计信息的一个挑战是,由于网络权重的变化,不同迭代的网络激活不能相互比较。因此,我们通过提出的基于泰勒多项式的技术对网络权重变化进行补偿,从而可以准确估计统计数据,有效地应用batch normalization。在small mini-batch sizes的目标检测和图像分类上,发现CBN的性能优于原来的批量归一化和在没有提出补偿技术的情况下直接计算之前迭代的统计数据。代码可在https://github.com/Howal/Cross-iterationBatchNorm。
1. Introduction
批量归一化(BN)(Ioffe & Szegedy,2015)在深度神经网络的成功中发挥了重要作用。它的引入是为了解决内部协方差的问题,即在训练迭代过程中,由于网络参数的更新,网络激活的分布会发生变化。这种转变通常被认为是对网络训练的破坏,而BN通过对网络激活的均值和方差进行归一化,在每次迭代时对mini-batch内的样本进行计算,从而缓解了这个问题。通过这种归一化,网络训练可以在更高的学习率下进行,并且对权重初始化不敏感。
在BN中,假设每个小批量内的样本的分布统计反映了整个训练集的统计。虽然这个假设一般对大批量规模是有效的,但在小批量规模的制度下,它被打破了(Peng等人,2018年;Wu & He,2018年;Ioffe,2017年),从小样本集计算出的嘈杂统计数据会导致性能的急剧下降。这个问题阻碍了BN在耗费内存的任务中的应用,如目标检测(Ren等,2015;Dai等,2017)、语义分割(Long等,2015;Chen等,2017)和动作识别(Wang等,2018b),由于内存限制,批量大小受到限制。
为了改善小批量规模下的统计估计,已经提出了替代的归一化器。其中一些包括层归一化(LN)(Baet al.,2016)、Instance Normalization(IN)(Ulyanov等人,2016)Group Normalization(GN)(Wu & He,2018),计算通道维度上的均值和方差,与批次大小无关。然而,不同的通道归一化技术,往往适用于不同的任务,这取决于所涉及的通道集。虽然GN是为检测任务设计的,但缓慢的推理速度限制了它的实际使用。另一方面,同步BN(SyncBN)(Peng等人,2018)通过在多个GPU上处理更大的批次规模,产生了一致的改进。这些性能的提升是以跨设备同步所需的额外开销为代价的。
一个很少被探索的方向是对最近多次训练迭代的样本进行计算,而不是像以前的技术那样只对当前迭代进行计算,以估计更好的统计数据。这可以极大地扩大获得均值和方差的数据池。但是,这种方法存在一个明显的缺点,即由于网络权重的变化,不同迭代的激活值之间没有可比性。如图1所示,直接计算多次迭代中的统计数据,我们称之为Naive CBN,其精度较低。
在本文中,我们提出了一种在迭代之间补偿网络权重变化的方法,从而可以有效地利用前面迭代的例子来提高批量归一化。我们的方法被称为CrossIteration Batch Normalization(CBN),其动机是由于观察到网络权重在连续的训练迭代之间会逐渐变化,而不是突然变化,这得益于随机梯度下降(SGD)的迭代性。因此,最近迭代的样本的均值和方差可以通过一个低阶泰勒多项式很好地近似于当前网络权重,定义在统计量相对于网络权重的梯度上。将最近多次迭代的compensated均值和方差与当前迭代的均值和方差进行平均,以产生更好的统计估计。
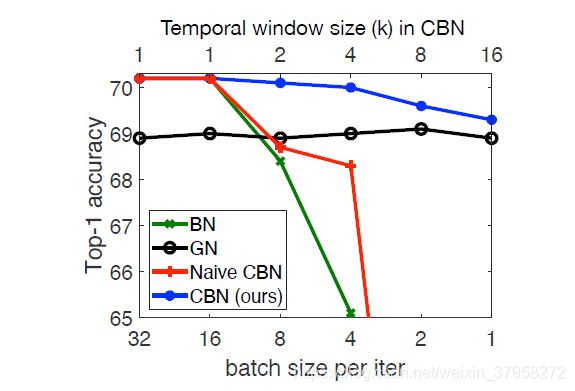
图1. Top-1分类精度与每次迭代的batch sizes。基础模型是在ImageNet(Russakovsky等人,2015)上训练的ResNet-18(He等人,2016)。当batch sizes减少时,BN(Ioffe & Szegedy,2015)的精度迅速下降。GN(Wu & He,2018)表现出稳定的性能,但在足够的批次大小上表现不及BN。CBN通过利用最近迭代中的近似统计数据来补偿每个GPU的batch sizes的减少(时间窗口大小表示最近迭代的统计数据被利用的次数).CBN在不同的批处理量上表现出相对稳定的性能。在不同的批处理规模下,CBN表现出相对稳定的性能,而直接从最近的迭代中计算统计数据而不进行补偿的Naive CBN则表现出了不好的效果。
在小批量规模的情况下,CBN比原来的BN有明显的性能提升,如图1所示。通过对ImageNet分类和COCO上的目标检测进行更广泛的实验,进一步证明了我们提出的方法的优越性.这些收益是在可以忽略不计的开销下获得的,因为之前迭代的统计数据已经被计算出来,而且泰勒多项式很容易计算。通过这项工作,表明batch normalization的线索可以成功地沿时间维度提取,开辟了一个新的研究方向。
2. Related Work
归一化在训练神经网络中的重要性已经被认识了几十年(LeCun等,1998)。一般来说,归一化可以对三个部分进行:输入数据、隐藏激活和网络参数。其中,输入数据归一化因其简单有效而被最常用(Sola& Sevilla,1997;LeCun等,1998)。在引入Batch Normalization(Ioffe & Szegedy,2015)之后,激活的归一化几乎变得非常普遍。通过对每个mini-batch的隐藏激活量按其统计量进行归一化,BN有效地缓解了消失梯度问题,显著加快了深度网络的训练速度。为了缓解BN的mini-batch的大小依赖性,人们提出了许多变体,包括层归一化(LN)(Ba等,2016)、实例归一化(IN)(Ulyanov等,2016)、组归一化(GN)(Wu & He,2018)和批实例归一化(BIN)(Nam & Kim,2018)。LN的动机是探索更适合序列模型的统计数据,而IN执行归一化的方式与BN类似,但只对每个实例进行统计。GN通过将特征沿信道维度划分为多个组,并计算每个组内的均值和方差进行归一化,实现了IN和LN的平衡。BIN引入了一种可学习的方法,在归一化和维护风格信息之间自动切换,在风格转移任务上同时享受BN和IN的优势。Cross-GPU批量归一化(CGBN或SyncBN)(Peng等,2018)将BN扩展到多个GPU上,以达到增加有效批量的目的。虽然提供了更高的准确性,但它为训练过程引入了同步开销。Kalman Normalization(KN)(Wang等人,2018a)提出了一种Kalman滤波程序,用于根据网络层的观测统计数据和前一层的计算统计信息来估计网络层的统计信息。
Batch Renormalization(BRN)(Ioffe,2017)是第一次尝试利用最近迭代的统计数据进行归一化。它并不是对最近迭代的统计数据进行补偿,而是对远期迭代的统计数据的重要性进行降权。然而,这种降权启发法并不能使得到的统计数据 “正确”,因为来自最近迭代的统计数据并不属于当前网络的权重。BRN可以看作是我们的Naive CBN基线的一个特殊版本(不含泰勒多项式逼近),其中远距离迭代被降权。
最近的工作也对网络参数的归一化进行了研究。在Weight Normalization(WN)(Salimans & Kingma,2016)中,通过将权重向量重新参数化为其长度和方向,来改善网络权重的优化。Weight Standar(WS)(Qiao等,2019)则是根据权重的第一时刻和第二时刻重新参数化,以达到平滑优化问题损失情况的目的。为了结合多种归一化技术的优势,Switchable Normalization(SN)(Luo等,2018)和Sparse Switchable Normalization(SSN)(Shao等,2019)利用可区分学习在不同的归一化方法之间切换。
所提出的CBN采用激活归一化的方法,旨在缓解BN的mini-batch赖性。与现有技术不同的是,它提供了一种在多个训练迭代中有效汇总统计数据的方法。
3. Method
3.1. Revisiting Batch Normalization
原始的batch normalization(BN)(Ioffe & Szegedy,2015)通过在一个mini-batch内计算的统计数据来改变每个层的激活。让 θ t \theta_t θt和 x t , i ( θ t ) x_{t,i}(\theta_t) xt,i(θt)代表网络权重和第t个mini-batch神经网络某层中第i个样本的特征响应。在这些值的基础上,BN进行以下归一化。

其中 x ^ t , i ( θ t ) \hat x_{t,i}(\theta_t) x^t,i(θt)是均值为零、单位方差为零的whitened activation。 ϵ \epsilon ϵ是为数值稳定性增加一个小常数, μ t ( θ t ) \mu_t(\theta_t) μt(θt)和 σ t ( θ t ) \sigma_t(\theta_t) σt(θt)是对当前小批量的所有样本计算的均值和方差,即:

其中 v t ( θ t ) = 1 m Σ i = 1 m x t , i ( θ t ) 2 \mathcal v_t(\theta_t)=\frac{1}{m}\Sigma^m_{i=1}x_{t,i}(\theta_t)^2 vt(θt)=m1Σi=1mxt,i(θt)2,而m表示当前mini-batch中的样本数量。白化后的激活 x ^ t , i ( θ t ) \hat x_{t,i}(\theta_t) x^t,i(θt)进一步进行可学习权重的线性变换,以提高其表现力。

其中, γ \gamma γ和 β \beta β为可学习参数(初始化为 γ = 1 , β = 0 \gamma=1,\beta=0 γ=1,β=0)
当batch sizes m较小时,统计量 μ t ( θ t ) \mu_t(\theta_t) μt(θt) 和 σ t ( θ t ) \sigma_t(\theta_t) σt(θt) 成为训练集统计量的噪声估计,从而降低了批归一化的效果。在最初设计BN模块的ImageNet分类任务中,典型的批量大小为32。然而,对于其他需要更大模型和/或更高图像分辨率的任务,如目标检测、语义分割和视频识别,由于GPU内存的限制,典型的批次大小可能会小到1或2。在这种情况下,原始BN的效率就会大大降低。
3.2. Leveraging Statistics from Previous Iterations 利用以前迭代的统计数据
为了解决小的mini-batch的BN问题,一个天真的方法是计算当前和前一次迭代的平均值和方差。然而,统计数据 μ t − τ ( θ t − τ ) \mu_{t-\tau}(\theta_{t-\tau}) μt−τ(θt−τ)和 v t − τ ( θ t − τ ) v_{t-\tau}(\theta_{t-\tau}) vt−τ(θt−τ)为第 t − τ t-\tau t−τ次迭代时通过网络权重 θ t − τ \theta_{t-\tau} θt−τ计算的,使其在当前迭代中过时。因此,直接汇总多次迭代的统计数据会产生不准确的均值和方差估计,导致性能大大降低。
我们观察到,由于基于梯度训练的特性,网络权重在连续迭代之间平滑变化。这允许我们通过泰勒多项式从现成的 μ t − τ ( θ t − τ ) \mu_{t-\tau}(\theta_{t-\tau}) μt−τ(θt−τ)和 v t − τ ( θ t − τ ) v_{t-\tau}(\theta_{t-\tau}) vt−τ(θt−τ)中进行近似 μ t − τ ( θ t ) \mu_{t-\tau}(\theta_{t}) μt−τ(θt)和 v t − τ ( θ t ) v_{t-\tau}(\theta_{t}) vt−τ(θt),例如:
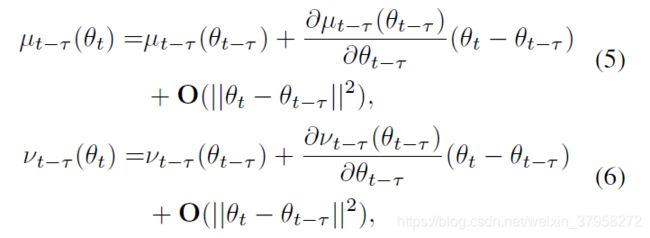
其中 ∂ μ t − τ ( θ t − τ ) / ∂ θ t − τ \partial_{\mu_{t-\tau}}(\theta_{t-\tau})/\partial\theta_{t-\tau} ∂μt−τ(θt−τ)/∂θt−τ和 ∂ v t − τ ( θ t − τ ) / ∂ θ t − τ \partial_{v_{t-\tau}}(\theta_{t-\tau})/\partial\theta_{t-\tau} ∂vt−τ(θt−τ)/∂θt−τ是统计量相对于网络权重的梯度, O ( ∥ θ t − θ t − τ ∥ 2 ) \mathbf O(\parallel\theta_t-\theta_{t-\tau}\parallel^2) O(∥θt−θt−τ∥2)表示泰勒多项式的高阶项,可以省略,因为当 θ t − θ t − τ \theta_t-\theta_{t-\tau} θt−θt−τ很小时,一阶项占主导地位。
在式(5)和式(6)中,梯度 ∂ μ t − τ ( θ t − τ ) / ∂ θ t − τ \partial_{\mu_{t-\tau}}(\theta_{t-\tau})/\partial\theta_{t-\tau} ∂μt−τ(θt−τ)/∂θt−τ和 ∂ v t − τ ( θ t − τ ) / ∂ θ t − τ \partial_{v_{t-\tau}}(\theta_{t-\tau})/\partial\theta_{t-\tau} ∂vt−τ(θt−τ)/∂θt−τ 不能以可忽略的成本精确确定,因为第l层网络层节点 μ t − τ l ( θ t − τ ) \mu^l_{t-\tau}(\theta_{t-\tau}) μt−τl(θt−τ)和 v t − τ l ( θ t − τ ) v^l_{t-\tau}(\theta_{t-\tau}) vt−τl(θt−τ)取决于第l层之前的所有的网络权重,例如对$r\le l , , ,\partial\mu_{t-\tau}l(\theta_{t-\tau})/\partial\thetar_{t-\tau}\ne0$ 和 ∂ v t − τ l ( θ t − τ ) / ∂ θ t − τ r ≠ 0 \partial v_{t-\tau}^l(\theta_{t-\tau})/\partial\theta^r_{t-\tau}\ne0 ∂vt−τl(θt−τ)/∂θt−τr=0 ,其中 θ t − τ r \theta^r_{t-\tau} θt−τr代表第r层的网络权重。只有当r=l时,才能有效地得出这些梯度的封闭形式(Only when r = l can these gradients be derived in closed form efficiently.)。
经验上,我们发现随着层索引r的减小( r ≤ l r\le l r≤l),局部梯度(the partial gradients)KaTeX parse error: Undefined control sequence: \part at position 7: \frac{\̲p̲a̲r̲t̲\mu_t^l(\theta_…和KaTeX parse error: Undefined control sequence: \part at position 7: \frac{\̲p̲a̲r̲t̲ ̲v_t^l(\theta_t)…迅速减少。浅层网络权值变化对深层激活分布的影响减弱,可能是BN内部协方差漂移(shift)减少的原因。基于这一现象(第4.4节中的研究),我们建议截断l层的这些局部梯度。
因此,我们进一步逼近式(5)和式(6)
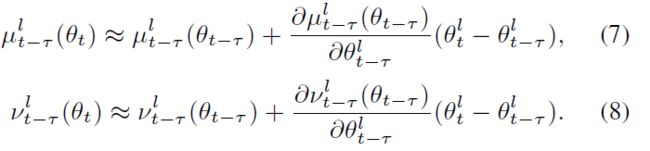
A naive implementation of ∂ μ t − τ l ( θ t − τ ) / ∂ θ t − τ l \partial\mu_{t-\tau}^l(\theta_{t-\tau})/\partial\theta_{t-\tau}^l ∂μt−τl(θt−τ)/∂θt−τl和 ∂ v t − τ l ( θ t − τ ) / ∂ θ t − τ l \partial v_{t-\tau}^l(\theta_{t-\tau})/\partial\theta_{t-\tau}^l ∂vt−τl(θt−τ)/∂θt−τl涉及的计算开销为 O ( C l × C l × C l − 1 × K ) O(C^l\times C^l\times C^{l-1}\times K) O(Cl×Cl×Cl−1×K),其中 C l C^l Cl和 C l − 1 C^{l-1} Cl−1表示第l层和第(l-1)层的通道维度,K代表 θ t − τ l \theta^l_{t-\tau} θt−τl的卷积核尺寸大小。在这里,我们发现该操作可以高效地在 O ( C l × C l − 1 × K ) O(C^l\times C^{l-1}\times K) O(Cl×Cl−1×K)复杂度内计算,多亏了 μ \mu μ和 v v v的特征响应的平均值。详见附件。
B. Efficient Implementation of
![]()
让 C l C^l Cl和 C l − 1 C^{l-1} Cl−1代表第l和l-1层的通道维度,K代表 θ t − τ l \theta^l_{t-\tau} θt−τl的卷积核大小, μ t − τ l \mu^l_{t-\tau} μt−τl和 v t − τ l v^l_{t-\tau} vt−τl为 C l C^l Cl维, θ t − τ l \theta^l_{t-\tau} θt−τl为 C l × C l − 1 × K C^l\times C^{l-1}\times K Cl×Cl−1×K维tensor。A naive implementation of ∂ μ t − τ l ( θ t − τ ) / ∂ θ t − τ l \partial\mu_{t-\tau}^l(\theta_{t-\tau})/\partial\theta_{t-\tau}^l ∂μt−τl(θt−τ)/∂θt−τl和 ∂ v t − τ l ( θ t − τ ) / ∂ θ t − τ l \partial v_{t-\tau}^l(\theta_{t-\tau})/\partial\theta_{t-\tau}^l ∂vt−τl(θt−τ)/∂θt−τl涉及的计算开销为 O ( C l × C l × C l − 1 × K ) O(C^l\times C^l\times C^{l-1}\times K) O(Cl×Cl×Cl−1×K)。这里我们发现 μ \mu μ和 v v v可以高效的在 O ( C l − 1 × K ) O(C^{l-1}\times K) O(Cl−1×K)和 O ( C l × C l − 1 × K ) O(C^l \times C^{l-1}\times K) O(Cl×Cl−1×K)复杂度内实现,多亏了 μ \mu μ和 v v v的特征响应的平均值。在这里我们推导了 ∂ μ t − τ l ( θ t − τ ) / ∂ θ t − τ l \partial\mu_{t-\tau}^l(\theta_{t-\tau})/\partial\theta_{t-\tau}^l ∂μt−τl(θt−τ)/∂θt−τl的高效实现, ∂ v t − τ l ( θ t − τ ) / ∂ θ t − τ l \partial v_{t-\tau}^l(\theta_{t-\tau})/\partial\theta_{t-\tau}^l ∂vt−τl(θt−τ)/∂θt−τl是相同的。让我们先简化一下符号。让 μ l \mu^l μl和 θ l \theta^l θl代表 μ t − τ l θ t − τ \mu^l_{t-\tau}\theta_{t-\tau} μt−τlθt−τ和 θ t − τ l \theta^l_{t-\tau} θt−τl。正向传递中的element-wise计算可以计算为:

其中, μ j l \mu_j^l μjl代表 μ l \mu^l μl中的第j个通道, x i , j l x_{i,j}^l xi,jl代表第i个样本的第j个通道, x i , j l x_{i,j}^l xi,jl的计算公式为:
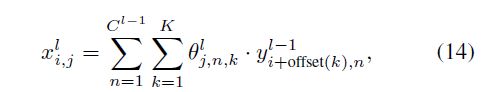
其中,n和k分别枚举输入特征维度和卷积核index,offset(k)表示应用第k核时的空间偏移量, y l − 1 y^{l-1} yl−1为(l - 1)层的输出。


3.3. Cross-Iteration Batch Normalization
在对网络权重变化进行补偿后,我们将最近k - 1次迭代的统计数据与当前迭代t的统计数据进行汇总,得到CBN中使用的统计数据。

其中 μ t − τ l ( θ t ) \mu^l_{t-\tau}(\theta_t) μt−τl(θt)和 v t − τ l ( θ t ) v^l_{t-\tau}(\theta_t) vt−τl(θt)由式(7)和式(8)计算。在公式(10)中, v ‾ t , k l ( θ t ) \overline v_{t,k}^l(\theta_t) vt,kl(θt)是由 v t − τ l ( θ t ) v^l_{t-\tau}(\theta_t) vt−τl(θt) 和 μ t − τ l ( θ t ) 2 \mu_{t-\tau}^l(\theta_t)^2 μt−τl(θt)2在每次迭代中的最大值决定的,因为 v t − τ l ( θ t ) ≥ μ t − τ l ( θ t ) 2 v^l_{t-\tau}(\theta_t) \ge\mu_{t-\tau}^l(\theta_t)^2 vt−τl(θt)≥μt−τl(θt)2对于有效的统计量应该是成立的,但可能被式(7)和式(8)中的泰勒多项式近似所违反。最后, μ ‾ t , k l ( θ t ) \overline \mu_{t,k}^l(\theta_t) μt,kl(θt)和 σ ‾ t , k l ( θ t ) \overline \sigma_{t,k}^l(\theta_t) σt,kl(θt) 用于对在当前迭代中相应的特征 { x t , i l ( θ t ) } i = 1 m \{x_{t,i}^l(\theta_t)\}^m_{i=1} {xt,il(θt)}i=1m响应进行归一化:
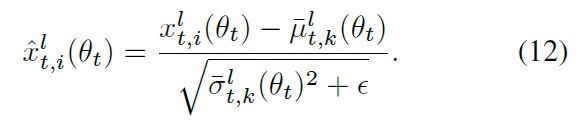
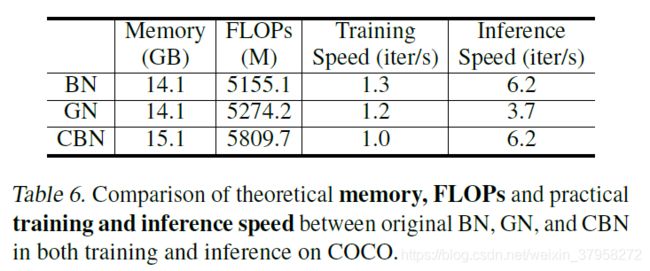
在CBN中,用于计算当前迭代统计的有效样本数量是原始BN的k倍。在训练中,损失梯度被反向传播到当前迭代时的网络权重和激活,即 θ t l \theta^l_t θtl和 x t , i l ( θ t ) x^l_{t,i}(\theta_t) xt,il(θt)。前面那些迭代是固定的,不接收梯度。因此,CBN在反向传播中的计算成本与BN相同。用CBN取代网络中的BN模块,只会导致计算开销和内存占用的轻微增加。对于计算来说,额外的开销主要来自于计算p偏导数 ∂ μ t − τ ( θ t − τ ) / ∂ θ t − τ l \partial\mu_{t-\tau}(\theta_{t-\tau})/\partial\theta^l_{t-\tau} ∂μt−τ(θt−τ)/∂θt−τl和 ∂ v t − τ ( θ t − τ ) / ∂ θ t − τ l \partial v_{t-\tau}(\theta_{t-\tau})/\partial\theta^l_{t-\tau} ∂vt−τ(θt−τ)/∂θt−τl ,相对于整个网络的开销来说是微不足道的。对于内存,该模块需要访问最近k-1迭代计算的统计数据 { μ t − τ l ( θ t − τ ) } τ = 1 k − 1 \{\mu^l_{t-\tau}(\theta_{t-\tau})\}^{k-1}_{\tau=1} {μt−τl(θt−τ)}τ=1k−1和 { v t − τ l ( θ t − τ ) } τ = 1 k − 1 \{v^l_{t-\tau}(\theta_{t-\tau})\}^{k-1}_{\tau=1} {vt−τl(θt−τ)}τ=1k−1和梯度 { ∂ μ t − τ ( θ t − τ ) } τ = 1 k − 1 \{\partial\mu_{t-\tau}(\theta_{t-\tau})\}^{k-1}_{\tau=1} {∂μt−τ(θt−τ)}τ=1k−1和 { ∂ v t − τ ( θ t − τ ) } τ = 1 k − 1 \{\partial v_{t-\tau}(\theta_{t-\tau})\}^{k-1}_{\tau=1} {∂vt−τ(θt−τ)}τ=1k−1与处理输入示例所消耗的其余内存相比,也是小巫见大巫。表6中报告了CBN的额外计算和内存。
在CBN中,一个关键的超参数是用于统计估计的最近迭代的时间窗口大小,k。较宽的窗口可以扩大样本集,但对于较远的迭代来说,例子质量会越来越低,因为网络参数 θ t \theta_t θt 和 θ t − τ \theta_{t-\tau} θt−τ的差异会变得更加显著,而且使用低阶泰勒多项式的补偿效果也会降低。经验上,我们发现CBN在各种环境和任务中,窗口大小达到k=8时是有效的。唯一的诀窍是,在训练开始时,窗口大小应保持较小,因为此时网络权重变化很快。
因此,我们为窗口大小引入一个长度为 T b u r n − i n T_{burn-in} Tburn−in的周期,其中k=1时,CBN退化为原始BN。在我们的实验中,burn-in period在ImageNet图像分类上默认设置为25个epochs,在COCO对象检测上默认设置为3个epochs。在附录中介绍了对该参数的消减。

表1比较了CBN和其他特征归一化方法。这些方法的关键区别在于统计数字和特征归一化的轴线。之前的技术都是为了利用来自同一迭代的例子。相比之下,CBN探索的是沿时间维度的实例聚合。由于CBN所利用的数据与之前的方法处于正交方向,所提出的CBN有可能与其他特征归一化方法相结合,以进一步提高某些具有挑战性的应用中的统计估计。
4. Experiments
4.1. Image Classification on ImageNet
Experimental settings. ImageNet(Russakovsky等人,2015)是一个图像分类的基准数据集,包含1.28M训练图像和来自1000个类的50K验证图像。我们遵循(He等,2015)中的标准设置,在训练集上训练深度网络,并在验证集上报告single-crop的top-1精度。我们的预处理和增强策略严格遵循GN基线(Wu & He,2018)。我们对所有权重层(包括 γ \gamma γ 和 β \beta β)使用0.0001的权重衰减。我们在4个GPU上训练标准ResNet-18的100个epochs,并通过余弦衰减策略降低学习率(He等人,2019)。我们进行5次试验,并报告其平均值和标准偏差(误差条)。ResNet-18与BN是我们的基础模型。为了与其他归一化方法进行比较,我们直接用IN、LN、GN、BRN和我们提出的CBN替换BN。

Comparison of feature normalization methods. 在表2中,我们比较了每一种归一化方法的性能,批次大小为32,足以计算可靠的统计数据。在这种设置下,BN显然产生了最高的top-1精度。与之前工作中发现的结果相似(Wu & He,2018),IN和LN的性能明显差于BN。GN在图像分类上效果良好,但比BN差1.2%。在所有方法中,我们的CBN是唯一一个能够达到与BN相当的精度的方法,因为它在较大的批次规模下收敛到BN的程序。
Sensitivity to batch size. 我们比较了CBN、原始BN(Ioffe & Szegedy,2015)、GN(Wu & He,2018)和BRN(Ioffe,2017)在每个GPU相同图像数量下在ImageNet分类上的行为。对于CBN,利用最近的迭代,以保证有效例子的数量不少于16个。对于BRN,设置严格遵循原论文。我们采用的学习率为0.1,批处理量为32,批处理量为N时,学习率按N=32线性缩放。

结果如表3所示。对于原来的BN,当每个GPU的图像数量从32张减少到2张时,其精度明显下降。 BRN的性能也明显下降。GN通过利用通道维度,但不利用批处理维度来保持其精度。对于CBN来说,通过利用最近迭代的例子,它的精度保持了。另外,CBN在不同批次大小的情况下,平均top-1精度比GN高出0.9%。这是很合理的,因为CBN的统计计算引入了像BN中的随机批次抽样造成的不确定性,但GN中没有这种不确定性,导致正则化能力有所下降。对于每个GPU的图像数量为1的极端情况,BN和BRN都无法产生结果,而CBN在这种情况下,在top-1精度上比GN高出0.4%。
4.2. Object Detection and Instance Segmentation on COCO
Experimental settings. 选择COCO(Lin等,2014)作为目标检测和实例分割的基准。模型在118k图像的COCO 2017训练分割上进行训练,并在5k图像的COCO 2017验证分割上进行评估。按照(Lin et al.,2014)中的标准协议,对象检测和实例分割的精度分别由intersection-over-union(IoU)重叠处的平均精度(mAP)分数来衡量。
继(Wu & He,2018)之后,分别选择Faster R-CNN(Ren等,2015)和Mask R-CNN(He等,2017)与FPN(Lin等,2017)作为目标检测和实例分割的基线。对于这两者,为了更好地使用归一化机制,将2fcbox head替换为4conv1 fc head(Wu & He,2018)。骨干网络为ImageNet预训练的ResNet-50(默认)或ResNet-101,具体归一化。通过SGD在4个GPU上对12个epochs的COCO训练集进行微调,其中每个GPU处理4张图像(默认)。需要注意的是,CBN中的均值和方差统计是在每个GPU内计算的。学习率初始化为0.02 N=16,每个GPU的批次大小为N,并在第9个和第11个epoch以10倍衰减。权重衰减和动量参数分别设置为0.0001和0.9。我们使用5次试验的平均值为所有结果。由于所有方法的标准差值都小于0.1的COCO,他们在这里被忽略。
正如在(Wu&He,2018)中所做的那样,我们试验了两种设置,即规范化器仅在任务特定的头部被激活,主干上冻结BN(默认),或者规范化器在除ResNet的早期conv1和conv2阶段之外的所有层激活。
Normalizers at backbone and task-specific heads. 我们进一步研究了不同归一化器对骨干网络和任务特定头在COCO上进行物体检测的影响。CBN、原始BN、syncBN和GN被纳入比较范围。

表4.特征归一化方法在Faster R-CNN与FPN和ResNet50上的结果 Faster R-CNN与FPN和ResNet50在COCO上的特征归一化方法的结果。由于在COCO上所有方法的标准差值都小于0.1,我们在这里忽略它们。
4.3. Ablation Study
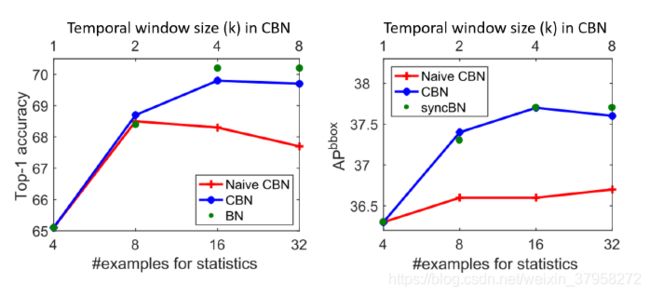
图3.时间窗口大小(k)对ImageNet的影响 时间窗口大小(k)对ImageNet(ResNet-18)和COCO(Faster R-CNN with ResNet-50 and FPN)的影响,#bs/GPU=4的CBN和Naive CBN。Naive CBN直接利用最近迭代的统计数据,而BN则使用与CBN相当的#实例进行统计计算。
Effect of temporal window size k. 我们在ImageNet图像分类和COCO对象检测上进行消融,每个GPU处理4张图像。图3展示了结果。当k=1时,只利用了当前迭代的批次,因此,CBN退化为原始BN。由于小批量尺寸上的噪声统计,精度受到影响。随着窗口大小k的增加,更多来自最近迭代的例子被利用来进行统计估计,从而提高了精度。精度在k=8时达到饱和,甚至略有下降。对于较远的迭代,网络权重差异较大,泰勒多项式近似的准确度变低。
另一方面,经验观察到,在众多应用中,原始BN在16或32个批次大小时饱和(Peng等,2018;Wu & He,2018),表明计算统计变得准确。因此,建议时间窗口大小为 k = m i n ( ⌈ 16 b s p e r G P U ⌉ , 8 ) k=min(\lceil\frac{16}{bs \,per\, GPU}\rceil,8) k=min(⌈bsperGPU16⌉,8)
Effect of compensation. 为了研究这个问题,我们将CBN与以下两种方法进行比较:1)Naive CBN,通过泰勒多项式将最近迭代的统计数据直接汇总,不需要补偿;2)应用与CBN相同有效例数的原始BN(即其每GPU的批次大小设置为每GPU的批次大小与CBN的时间窗口大小的乘积),它不需要任何补偿,作为性能上限。
实验结果也如图3所示。当包含前面的迭代时,CBN明显超过了Naive CBN。实际上,如图3(a)所示,当时间窗口大小增长到k=8时,Naive CBN就失效了,这证明了对迭代过程中网络权重变化进行补偿的必要性。与原来的BN上界相比,CBN在相同的有效样本数下,实现了相似的精度。这一结果表明,CBN使用低阶泰勒多项式进行补偿是有效的。

图4.CBN、Naive CBN和BN的训练和测试曲线 CBN、Naive CBN 和 BN 在 ImageNet 上的训练和测试曲线,CBN、Naive CBN 和 BN-bs4 的每 GPU 批量为 4,时间窗口大小 k = 4,BN-bs16 的每 GPU 批量为 16。BN-bs16的图是理想的边界。
图4是CBN、Naive CBN、BN-bs4和BN-bs16在ImageNet上的训练和测试曲线,CBN、Naive CBN和BN-bs4每个GPU有4张图片,时间窗口大小为4,BN-bs16每个GPU有16张图片.CBN的训练曲线在开始时接近BN-bs4,最后接近BN-bs16。原因是我们采用burn-in period,避免了训练开始时统计数据变化快的缺点。Naive CBN的训练曲线与CBN的训练曲线之间的差距表明,Naive CBN甚至不能很好地收敛在训练集上。CBN的测试曲线在末端接近BN-bs16,而Naive CBN则表现出相当大的抖动。所有这些现象都表明我们提出的泰勒多项式补偿的有效性。

图5. CBN上不同的burn-in periods(以epoch为单位)的结果,每次迭代的批次大小为4,在ImageNet和COCO上。
Effect of burn-in period length T. 我们研究在每个GPU有4张图像的情况下,改变burn-in periods长度 T b u r n − i n T_{burn-in} Tburn−in对ImageNet图像分类(ResNet-18)和COCO对象检测(Faster R-CNN with FPN和ResNet-50)的影响。图5(a)和5(b)展示了结果。当burn-in periods太短时,准确率会受到影响。这是因为在训练之初,网络权重变化很快,导致跨迭代的补偿效果较差。尽管如此,在很宽的burn-in周期 T b u r n − i n T_{burn-in} Tburn−in范围内,精度是稳定的。
A. Algorithm Outline
算法1是我们提出的CrossIteration Batch Normalization(CBN)的概要。
in periods太短时,准确率会受到影响。这是因为在训练之初,网络权重变化很快,导致跨迭代的补偿效果较差。尽管如此,在很宽的burn-in周期 T b u r n − i n T_{burn-in} Tburn−in范围内,精度是稳定的。
A. Algorithm Outline
算法1是我们提出的CrossIteration Batch Normalization(CBN)的概要。
