跨模态行人重识别:Deep Learning for Person Re-identification:A Survey and Outlook(行人重识别综述)
Deep Learning for Person Re-identification:A Survey and Outlook(行人重识别综述)
写在前面:感谢叶茫博士对AGW的开源,AGW非常适合刚接触跨模态ReID的同学作为baseline,具有优异性能的同时,代码层面逻辑非常清晰,开源代码在文末附上链接。本文虽为综述类文章,但专栏的重点在于跨模态行人重识别。
目录
- Deep Learning for Person Re-identification:A Survey and Outlook(行人重识别综述)
- Abstract
- 1、Introduction
- 2 、Closed-World Person ReID(封闭世界)
-
- 2.1、Feature Representation Learning(特征表示学习)
-
- 2.1.1、 Global Feature Representation Learning(全局特征)
- 2.1.2、 Local Feature Representation Learning(局部特征)
- 2.1.3、 Auxiliary Feature Representation Learning(辅助特征)
- 2.1.4、 Architecture Design(架构设计)
- 2.2、Deep Metric Learning(深度度量学习)
-
- 2.2.1、 Loss Function Design
- 2.2.2、 Training strategy
- 3 、Open-World Person ReID(开放世界)
- 4 、AN OUTLOOK: RE-ID IN NEXT ERA
-
- 4.1、mINP: A New Evaluation Metric for Re-ID
- 4.2、A New Baseline for Single-/Cross-Modality Re-ID
Abstract
1)通过行人重识别领域的研究,将该领域分为封闭世界(closed-world)和开放世界(open-world)。
2)从三个不同角度对封闭世界进行深入分析,分别为深度特征表示学习,深度度量学习和排名优化。从五个方面总结了开放世界。
3)提出名为AGW的baseline,引入针对ReID的新评价指标mINP。
1、Introduction
不同视角、参差不齐的低分辨率图像、光照变化、姿态不同、遮挡情况、异构数据都会对ReID任务造成影响和挑战。
针对特定场景构建行人ReID系统需要五个步骤:
1)原始数据收集:从处于不同环境的不同地方的摄像机获取原始视频数据。这些数据包含大量的背景杂波。
2)边界框(Bounding Box)生成:通过行人检测或跟踪算法从原始视频数据中提取包含行人图像的边界框。在大规模应用中不可能手动裁剪所有行人图像。
3)训练数据标注:对于区分行人任务来说,图像标注必不可少。
4)模型构建和训练:已经开发了广泛运用的模型,重点在于特征表示学习、度量学习或两者结合。
5)测试阶段:给定一个query和一组gallery,使用上一阶段训练完毕的模型进行行人特征提取,计算query图像和gallery图像的相似度进行排序。
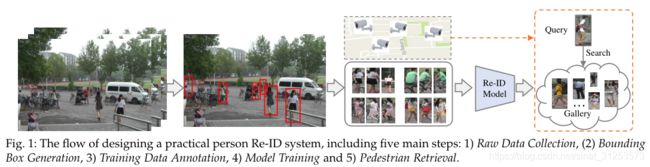
————————————————————————————————————————
根据上面提到的五个步骤,将现有的ReID分为两个主要的方向:封闭世界和开放世界。如下图所示:

1、单模态和异构数据(Single-modality Data vs. Heterogeneous Data):对于步骤1中的原始数据收集,默认所有行人都是在可见光单模态下进行拍摄的,但是在实际的开放世界中,数据可能是异构的,例如,行人可能是在不同光谱、草图、深度图像相机所捕获,甚至可能是文本描述。(这也是本博客关注的重点,即跨模态行人重识别)
2、边界框生成和原始图像/视频(Bounding Box Generation vs. Raw Images/Videos):封闭世界中的行人重识别通常基于边界框提取的行人图像或视频进行训练和测试。但是在实际开放世界中需要直接从原始图像/视频中进行端到端的行人检索。
3、丰富的标签数据和不可用/有限的标签(Sufficient Annotated Data vs. Unavailable/Limited Labels):封闭世界中,行人图像都是标注好的。但在实际应用中,标注费时费力成本高。故引发了有监督和无监督领域。
4、正确标签和噪声标签(Correct Annotation vs. Noisy Annotation):现有的封闭世界的行人重识别领域通常假定所有标签清晰且正确。然而实际应用中,标签噪声和不完善正确的检索跟踪结果导致的样本噪声也都不可避免,故引出了不同噪声类型下的鲁棒行人ReID。
5、query是否存在于gallery中(Query Exists in Gallery vs. Open-set):现有的封闭世界行人ReID都假设查询必须存在于图库中,并计算CMC和mAP。但是在现实情况中,查询行人不一定出现在图库中。
2 、Closed-World Person ReID(封闭世界)
此设置通常具有以下假设:1)通过单模态可见光摄像机捕获行人。2)已经给出行人bounding box。3)有足够的标注好的训练数据。用于监督训练。4)标签通常是正确的。5)query行人必须出现在图库中。标准的封闭世界ReID系统包含三个主要组件:2.1特征表示学习,着重于开发构造特征提取策略。2.2深度度量学习,旨在设计具有不同损失函数或采样策略的训练目标。2.3排名优化,重点在优化检索到的排序列表。
2.1、Feature Representation Learning(特征表示学习)
主要有四个类别:a)全局特征:为每个行人图像提取全局特征,没有附加标注。b)局部特征:汇总了被分块的局部特征,为每个行人图像制定了组合表示。c)辅助特征:使用辅助信息(属性、GAN生成的图像)来改进特征表示学习。d)视频特征:使用多个图像帧和时序信息,学习基于视频的ReID特征表示。

2.1.1、 Global Feature Representation Learning(全局特征)
将同一个行人的所有图像视为同一类(同一个ID),提取全局特征,将ReID任务视为一个多分类问题。
Attention Information
注意力机制被广泛应用以增强特征表示学习。1)行人图像中attention 2)跨多行人注意力
2.1.2、 Local Feature Representation Learning(局部特征)
具体方案不在此赘述,基本思路即在全局特征之外附加局部特征信息,必定能通过更多信息获得更好的结果。但有些分块技术需要额外的人体姿态对齐策略辅助,而固定分块技术(例如PCB)通过水平划分来进行分块,对重度遮挡和背景杂波敏感。
2.1.3、 Auxiliary Feature Representation Learning(辅助特征)
通常需要附加额外的注释信息,或利用GAN生成额外的训练样本进行原有数据的扩充。
2.1.4、 Architecture Design(架构设计)
将行人ReID视为特定的行人检索问题,现有大多工作都采用以图像分类为基础的网络体系结构做为baseline,一些工作试图修改主干架构以获得更好的性能。对于广泛使用ResNet50的主干网络,重要的修改包括:将最后的卷积核修改为1,将最后的池化层改为自适应平均池化,并在最后经过池化层后加一层BN层。
2.2、Deep Metric Learning(深度度量学习)
在深度学习时代之前,通过学习马氏距离函数或投影矩阵,对度量学习进行了广泛的研究。如今,度量学习的作用已由损失函数替代,以指导特征表示学习。在2.2.1中回顾广泛使用的损失函数,在2.2.2中总结具有特定采样设计的训练策略。
2.2.1、 Loss Function Design
下文仅针对行人ReID深度学习方法设计的三种损失函数:身份损失、验证损失和三元组损失。
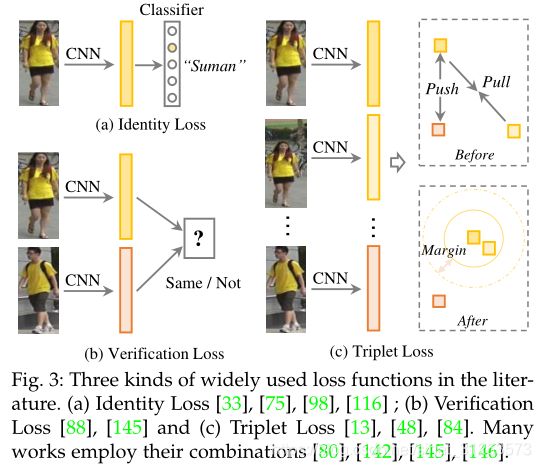
Identity Loss.(身份损失)
将行人重识别视作图像分类问题,每个ID都是不同的类别。测试阶段,将pooling层或embedding层的输出作为特征提取器,给定具有标签yi的图像xi,则被识别为yi类的xi的预测概率经过softmax函数,表示为p(yi|xi)。身份损失由交叉熵计算:

其中n代表每批训练样本的数量。
Verification Loss.(验证损失)
通过对比损失或二进制验证损失优化成对的行人关系。
对比损失改善了相对成对距离比较:
![]()
其中,dij表示两个输入样本xi和xj的embedding特征之间的欧式距离。δij是一个二进制标记指示符(当xi和xj属于同一标识时,δij= 1,否则,δij= 0)。
二进制验证在于区分输入图像的正负,通过fij= (fi− fj)2获得差异特征fij,fi和fj是两个输入样本的embedding特征,验证损失将差异特征分为正或负,我们使用p(δij|fij)来表示输入数据(xi和xj)被识别为δij(0或1)的概率,基于交叉熵的验证损失为:
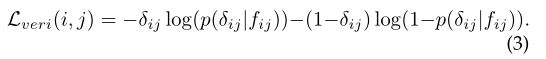
Triplet loss.(三元组)
将ReID模型训练过程视为检索排名问题。基本思想是:正样本对之间距离比负样本对间距离小于预定尺度。
![]()
2.2.2、 Training strategy
3 、Open-World Person ReID(开放世界)
此章节我们只关注异构数据分类中的跨模态ReID。
Visible-Infrared Re-ID
可见-红外Re-ID处理白天可见图像和夜间红外图像之间的跨模态匹配。这在光线不足的情况下很重要,在这种情况下,只能通过红外热像仪捕获图像。Zero-Padding(详情见RGB-Infrared Cross-Modality Person Re-Identification(2017 ICCV))通过提出一个深的零填充框架来自适应地学习模态可共享特征,开始了解决这个问题的首次尝试。在叶茫的论文(详情见Visible Thermal Person Re-Identification via Dual-Constrained Top-Ranking(IJCAI18))中引入了两流网络以对模态可共享和特定信息建模,同时解决模态内和跨模态变化。最近的方法采用GAN技术来生成跨模态人物图像,以减少图像和特征级别上的跨模态差异。
4 、AN OUTLOOK: RE-ID IN NEXT ERA
- 新的评价指标mINP
- AGW baseline
4.1、mINP: A New Evaluation Metric for Re-ID
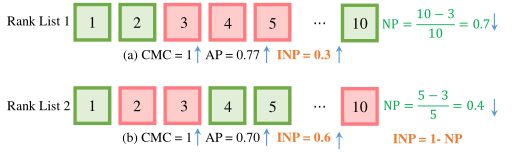
对于一个优异的ReID系统,应该尽可能准确地检索目标行人,即所有的匹配项都应具有较低的rank值。
在实际应用中,最远的正确排名位置决定了检查人员的工作量。但是当前广泛使用的CMC和mAP无法评估此属性,如下图所示,对于相同的CMC,表1的AP要比表2的AP高,但是要付出更多努力才能找到所有正确匹配项。为了解决此问题,设计了一种有效的度量标准,即负罚分(NP),用于测量罚分以找到最难的正确匹配项。
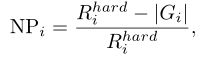
Rihard表示最难匹配的排名位置,而| Gi |代表查询i的正确匹配总数。自然,较小的NP表示较好的性能。为了与CMC和mAP保持一致,我们更喜欢使用NP的逆运算(INP)。总体而言,所有查询的平均INP表示为:
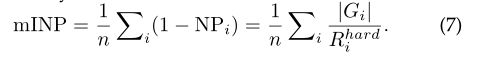
mINP的计算效率很高,可以无缝集成到CMC/mAP计算过程中。mINP避免了mAP/CMC评估中容易匹配的问题,此度量标准评估检索最难正确匹配的能力,从而为测量ReID性能提供了补充。
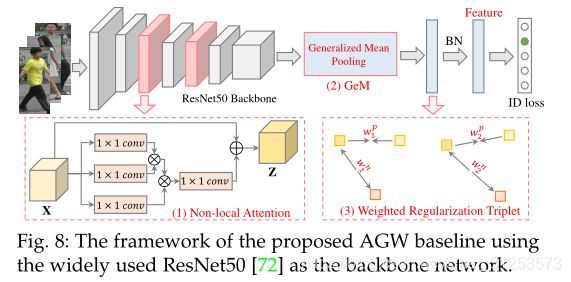
4.2、A New Baseline for Single-/Cross-Modality Re-ID
新baseline是在BagTricks(A strong baseline and batch normneuralization neck for deep person re-identification)上设计的,并且包含三个主要改进的组件:
(1) Non-local Attention (Att) Block.
采用强大的non-local注意力模块来获得所有位置的特征加权总和。
![]()
Wz是要学习的权重矩阵,φ(·)表示non-local运算,和xi形成残差学习策略。详情参见《Non-local neural networks》
(2) Generalized-mean (GeM) Pooling.
作为细粒度的实例检索,广泛使用的最大池化或平均池化无法捕获特定于域的区分特征。采用可学习的池化层,称为Generalized-mean (GeM) Pooling
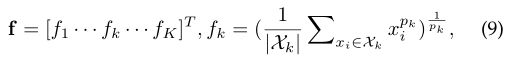
pki是一个池化超参数,可以在反向传播过程中学习,pk→∞时近似最大池化,在pk = 1时近似平均池化。详情参见《Fine-tuning cnn image retrieval with no human annotation》
(3) Weighted Regularization T riplet (WRT) loss.
除了使用基于softmax的交叉熵之外,还使用了另一个加权正则化三元组损失。
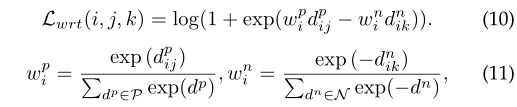
避免引入了margin参数,类似于《Multi-similarity loss with general pair weighting for deep metric learning》
完整框架如下图:
AGW在跨模态行人重识别中的效果:

最后附上论文链接,需要请自取:https://arxiv.org/abs/2001.04193v1
单模态AGW已开源:https://github.com/mangye16/ReID-Survey
跨模态行人重识别AGW已开源:https://github.com/mangye16/Cross-Modal-Re-ID-baseline