BF算法与KMP算法
字符串匹配问题
字符串匹配算法:就是给定两个串,查找另一个串是否在主串里面。找出一个子串在文本中的位置是特别重要的,我们称那个子串为模式串(pattern),然后我们称寻找的过程为:模式匹配(string match)。此算法通常输入为原字符串(string)和子串(pattern),要求返回子串在原字符串中首次出现的位置。比如原字符串为“ABCDEFG”,子串为“DEF”,则算法返回3。
Brute-Force算法
BF算法又叫朴素算法,是一种暴力解法,基本思想是穷举法。
首先将原字符串和子串左端对齐,逐一比较;如果第一个字符不能匹配,则子串向后移动一位继续比较;如果第一个字符匹配,则继续比较后续字符,直至全部匹配。
时间复杂度:O(mn)
具体思路:
我们给出主串T=“HELLOWORD”,子川S="LOWO".
1.从头开始一一对齐,若开始并不相等。则字串向后便宜与主串第二个开始匹配
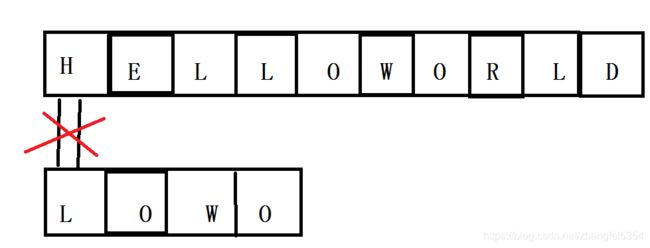
2.若匹配失败,则子串再向后偏移,与主串第三个开始匹配
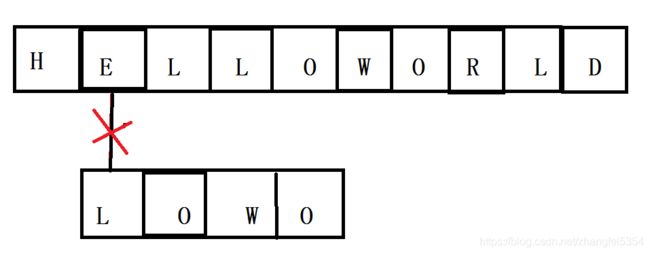
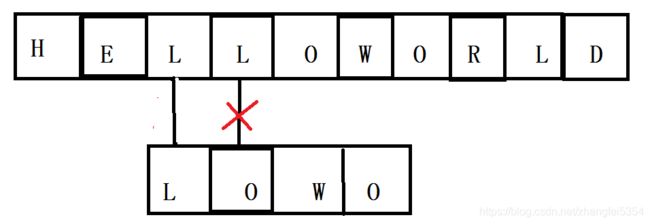
4.子串与主串第一个匹配成功,然后匹配下一个字符,成功继续匹配下一个,不成功子串向后偏移,重新匹配
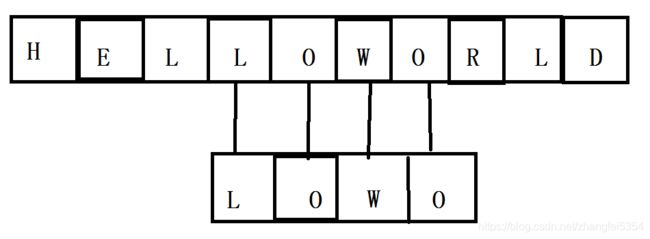
5.匹配成功
具体代码
int BF(char *str, char*sub, int pos)
{
assert(str != NULL&&sub != NULL);//断言
/*
在str中的pos位置开始,sub匹配;
1.求取两个串的长度,用i表示在str位置,j表示在sub的位置
2.循环匹配。
3.每次匹配:两个位置相等 同时++,若不相等,i回退到本次匹配开始位置的下一个位置,j回退到sub起始位置
4.出循环,若j>len_sub表示子串匹配成功,若i>len_str表示子串没匹配失败。
*/
int len_str = strlen(str);
int len_sub = strlen(sub);
int i = pos;
int j = 0;
while (i len_sub)
{
return i - j;
}
return -1;
}
int main()
{
char *s1 = "abcdefabcdefabcdef";
char*s2 = "abcde";
int index = BF(s1, s2, 3);
printf("%d\n", index);
getchar();
return 0;
} 若模式子串的长度是m, 目标穿的长度是n,这时最坏的情况是每遍比较都在最后出现不等,即每遍最多比较m次,最多比较n - m + 1遍,总的比较次数最多为m(n - m + 1),因此朴素的模式匹配算法的时间复杂度为O(mn)。朴素的模式匹配算法中存在回溯,这影响到匹配算法的效率,因而朴素的模式匹配算法在实际应用中很少采用。
KMP算法
相对于 BF 算法来说 KMP 算法更为高效,原因在于 BF 算法的时间复杂度是:O(mn),m代表主串的长度,n 代表子串的长度。而 KMP 的话,时间复杂度就变为 O(m+n);KMP 和 BF 唯一不一样的地方在,我主串的 i 并不会回退,并且 j 也不会移动到 0
号位置。
我们需要为KMP算法做大量的准备:
串的前缀和后缀
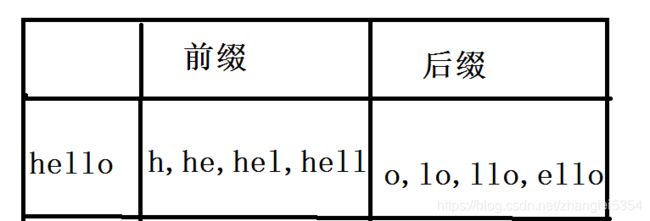
何为前缀后缀?简单来说,将一个字符串在任意位置分开,得到的左边部分即为前缀,右边部分即为后缀。例如对于字符串"hello",它的前缀有h , he hel ,hell ;后缀有o ,lo ,llo ,ello 注意前后缀均不包括字符串本身
最长公共前后缀
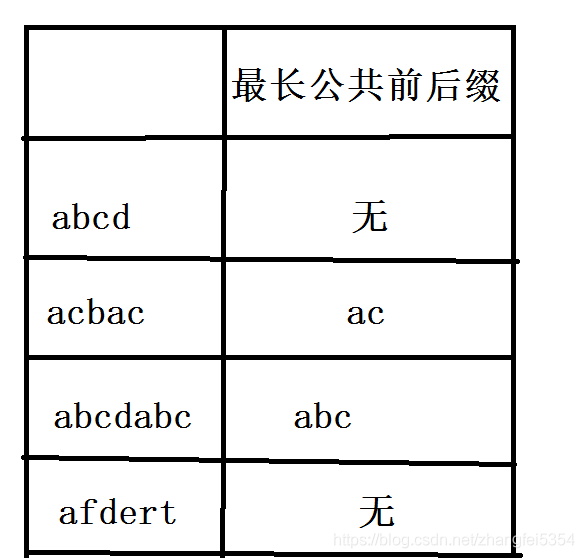
对于一个字符串来说,它既有前缀,又有后缀,所谓的最长公共前后缀,即该字符串最长的相等的前缀和后缀。例如上面的字符串"hello"就没有公共前后缀,更别提最长了,因为它的前后缀里就没有相等的;而字符串"abcab"就有一个最长的公共前后缀即"ab"。
那么求最长公共前后缀到底有什么用呢?我们先来分析BF解法中的操作,若不匹配,主串的下一字符开始与子串T的第一个字符重新开始比较
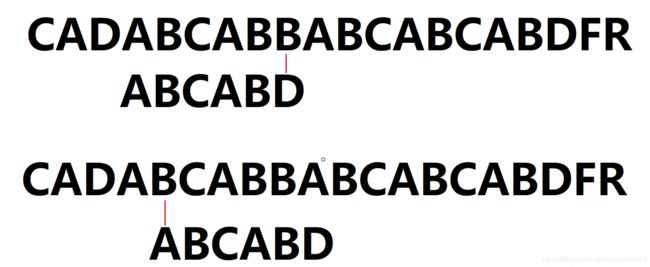
在kmp算法中,若是上述情况,为最后一个元素 D 失配,则D之前的元素都被成功匹配,D之前为AB,模式的首部两位也是AB,则接下来比较的是第三位 C (注意此时主串中的匹配字符位置不变,即无回溯,主串在匹配过程中一直在向前遍历)如下图
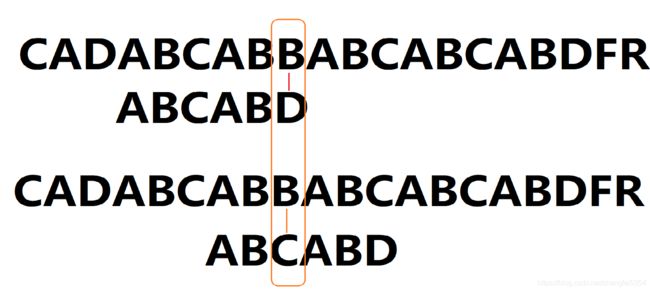
我们看到 原串 中字符 与 D 失配后,直接将 C 与 原串中该字符进行比较,原因是 D 之前的 串的最长公共前后缀长度为 2,即 若D失配后,我们根据此最长公共前缀的值来确定下个需要匹配的字符,即为模式中的第三个字符,2号下标,这就是kmp的核心,避免了不必要的匹配,提高了匹配的效率。
next数组
next数组是kmp算法的核心,它表明了若模式中的某字符在主串中匹配失败后,下次需要匹配的模式中的字符。
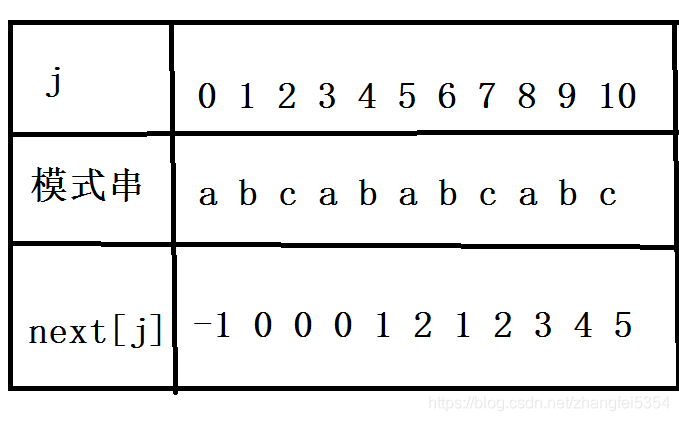
next[0] = -1
next[1] = 0
next[2] = 0
//表示若 c 匹配失败,下次匹配时从模式中下标为0的字符,即a,从头开始。
next[3]同上
next[4] = 1,
//表示若4号下标 b 匹配失败,下次匹配时从模式中下标为1的字符,即b开始,因为4号下标失配,则之前的a已被匹配,恰好模式0号下标正好为a,则下次从0号下标后即1号下标进行匹配
next[5] = 2,
//表示若5号下标 a 匹配失败,下次匹配时从模式中下标为2的字符,即c开始,因为5号下标失配,则之前的ab已被匹配,恰好模式0、1号下标正好为ab,则下次从1号下标后即2号下标进行匹配
next[6] = 1,
//表示若6号下标 b 匹配失败,分析同next[4]
next[7] = 2,
//表示若7号下标 c 匹配失败,分析同next[5]
next[8] = 3,
//表示若8号下标 a 匹配失败,下次匹配时从模式中下标为3的字符,即a开始,因为8号下标失配,则之前的abc已被匹配,恰好模式0、1、2号下标正好为abc,则下次从2号下标后即3号下标进行匹配
next[9] = 4,
//表示若9号下标 b 匹配失败,下次匹配时从模式中下标为4的字符,即b开始,因为9号下标失配,则之前的abca已被匹配,恰好模式0、1、2、3号下标正好为abca,则下次从3号下标后即4号下标进行匹配
next[10] = 5,
//表示若10号下标 c 匹配失败,下次匹配时从模式中下标为5的字符,即a开始,因为10号下标失配,则之前的abcab已被匹配,恰好模式0、1、2、3、4号下标正好为abcab,则下次从4号下标后即5号下标进行匹配
再练习几组

next数组实现
void GetNext(char *sub, int *next)
{
int len = strlen(sub);
int k = 0;
next[0] = -1;
next[1] = 0;
int i = 2;
while (i <= len)
{
if (sub[k] == sub[i - 1] || k == -1)
{
next[i] = ++k;
i++;
}
else
{
k = next[k];
}
}
}kmp算法实现
主串的起始位置 = 上一轮匹配的失配位置;
模式串的起始位置 = 失配位置的next值
int KMP(char *str, char* sub, int pos)
{
int lenstr = strlen(str);
int lensub = strlen(sub);
int i = pos;
int j = 0;
int *next = (int *)malloc(sizeof(int)*lensub);
assert(next != NULL);
GetNext(sub, next);
while (i < lenstr &&j < lensub)
{
if (j == -1 || str[i] == sub[j])
{
i++;
j++;
}
else
{
j = next[j];
}
}
if (j >= lensub)
{
return i - j;
}
return -1;
}算法的改进:
其实我们的next函数还是有一点缺陷,我们还可以通过一定的改进,让我们的算法的得到进一步的优化,例如:当我们的模式串为:ooooa, 主串为:ooocooooa, 我们根据之前的next函数可以得到next数组的值为: - 10123, 所以当我们的模式串的第四个字符和主串的第四个字符发生不相等的时候,我们还需要额外的三次比较,才知道这个我们应该直接把主串往前移动一位,后继续比较。其实,我们完全可以在生成next值的时候,避免这种情况出现,代码修改如下:
nextval数组实现
void GetNextVal(int *nextval, const char *sub)
{
int lensub = strlen(sub);
int *next = (int *)malloc(sizeof(int) * lensub);
GetNext(sub,next);
for (int i = 0; i < lensub; i++) // 将next数组全部写入nextval
{
nextval[i] = next[i];
}
int i = 1;
// 接下来我们将next数组中所有sub[next[i]] 与 sub[i]相等的i的nextval改为nextval[next[i]]
while (i < lensub)
{
if (sub[i] == sub[next[i]]) // 当sub[next[i]] 与 sub[i] 相等时,我们做以优化
{
nextval[i] = nextval[next[i]]; // 把nextval[next[i]] 的值 赋给 nextval[i]
}
i++;
}
}