利用pytorch搭建LeNet-5网络模型(win11)
目录
1. 前言
2. 程序
2.1 net
2.2 train
2.3 main
3. 总结
1. 前言
手写字体识别模型LeNet5诞生于1994年,是最早的卷积神经网络之一。LeNet5通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别,这个网络也是最近大量神经网络架构的起点。
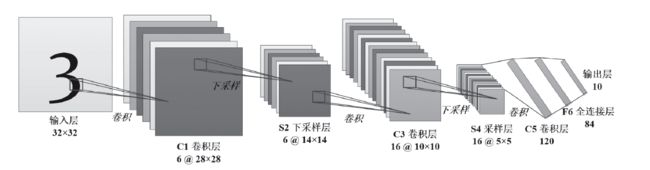
代码分析见视频: 从0开始撸代码--手把手教你搭建LeNet-5网络模型
环境配置见:基于Anaconda安装pytorch和paddle深度学习环境(win11)
卷积或池化输出图像尺寸的计算公式如下:
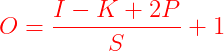
O=输出图像的尺寸;I=输入图像的尺寸;K=池化或卷积层的核尺寸;S=移动步长;P =填充数
2. 程序
程序分为三部分net、train、main(test)
2.1 net
定义网络结构,初始化输入输出参数
import torch
from torch import nn
# 定义一个网络模型类
class MyLeNet5(nn.Module):
# 初始化网络
def __init__(self):
super(MyLeNet5, self).__init__()
# 输入大小为32*32,输出大小为28*28,输入通道为1,输出为6,卷积核为5
self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
# 使用sigmoid激活函数
self.Sigmoid = nn.Sigmoid()
# 使用平均池化
self.s2 = nn.AvgPool2d(kernel_size=2, stride=2)
self.c3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.s4 = nn.AvgPool2d(kernel_size=2, stride=2)
self.c5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
self.flatten = nn.Flatten()
self.f6 = nn.Linear(120, 84)
self.output = nn.Linear(84, 10)
def forward(self, x):
# x输入为32*32*1, 输出为28*28*6
x = self.Sigmoid(self.c1(x))
# x输入为28*28*6, 输出为14*14*6
x = self.s2(x)
# x输入为14*14*6, 输出为10*10*16
x = self.Sigmoid(self.c3(x))
# x输入为10*10*16, 输出为5*5*16
x = self.s4(x)
# x输入为5*5*16, 输出为1*1*120
x = self.c5(x)
x = self.flatten(x)
# x输入为120, 输出为84
x = self.f6(x)
# x输入为84, 输出为10
x = self.output(x)
return x
if __name__ == "__main__":
x = torch.rand([1, 1, 28, 28])
model = MyLeNet5()
y = model(x)可以右键run 一下,检验程序是否正确。

2.2 train
数据转化为tensor格式,加载训练数据集,如果显卡可用,则用显卡进行训练,如果GPU可用则将模型转到GPU,定义损失函数,定义训练函数,定义验证函数,开始训练,这里为了节约时间只训练了20次。
import torch
from torch import nn
from net import MyLeNet5
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
import os
# 将数据转化为tensor格式
data_transform = transforms.Compose([
transforms.ToTensor()
])
# 加载训练数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_transform, download=True)
# 给训练集创建一个数据加载器, shuffle=True用于打乱数据集,每次都会以不同的顺序返回。
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
# 加载训练数据集
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_transform, download=True)
# 给训练集创建一个数据加载器, shuffle=True用于打乱数据集,每次都会以不同的顺序返回。
test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else 'cpu'
# 调用net里面定义的模型,如果GPU可用则将模型转到GPU
model = MyLeNet5().to(device)
# 定义损失函数(交叉熵损失)
loss_fn = nn.CrossEntropyLoss()
# 定义优化器,SGD,
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
# 学习率每隔10epoch变为原来的0.1
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
loss, current, n = 0.0, 0.0, 0
# enumerate返回为数据和标签还有批次
for batch, (X, y) in enumerate(dataloader):
# 前向传播
X, y = X.to(device), y.to(device)
output = model(X)
cur_loss = loss_fn(output, y)
# torch.max返回每行最大的概率和最大概率的索引,由于批次是16,所以返回16个概率和索引
_, pred = torch.max(output, axis=1)
# 计算每批次的准确率, output.shape[0]为该批次的多少
cur_acc = torch.sum(y == pred) / output.shape[0]
# print(cur_acc)
# 反向传播
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()
# 取出loss值和精度值
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
print('train_loss' + str(loss / n))
print('train_acc' + str(current / n))
# 定义验证函数
def val(dataloader, model, loss_fn):
# 将模型转为验证模式
model.eval()
loss, current, n = 0.0, 0.0, 0
# 非训练,推理期用到(测试时模型参数不用更新, 所以no_grad)
# print(torch.no_grad)
with torch.no_grad():
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
output = model(X)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
print('val_loss' + str(loss / n))
print('val_acc' + str(current / n))
return current / n
# 开始训练
epoch = 20
min_acc = 0
for t in range(epoch):
lr_scheduler.step()
print(f"epoch{t + 1}\n-------------------")
train(train_dataloader, model, loss_fn, optimizer)
a = val(test_dataloader, model, loss_fn)
# 保存最好的模型权重文件
if a > min_acc:
folder = 'sava_model'
if not os.path.exists(folder):
os.mkdir('sava_model')
min_acc = a
print('save best model', )
torch.save(model.state_dict(), "sava_model/best_model.pth")
# 保存最后的权重文件
if t == epoch - 1:
torch.save(model.state_dict(), "sava_model/last_model.pth")
print('Done!')可以run(F5) 一下,得到最佳模型,精度达到了96.16%,还不错呦


2.3 main
数据转化为tensor格式,加载训练数据集,如果显卡可用,则用显卡进行训练,如果GPU可用则将模型转到GPU,加载 train.py 里训练好的模型,把tensor转成Image, 方便可视化,获取预测结果,进入验证阶段,测试前五张图片。
import torch
from net import MyLeNet5
from torch.autograd import Variable
from torchvision import datasets, transforms
from torchvision.transforms import ToPILImage
# 将数据转化为tensor格式
data_transform = transforms.Compose([
transforms.ToTensor()
])
# 加载训练数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_transform, download=True)
# 给训练集创建一个数据加载器, shuffle=True用于打乱数据集,每次都会以不同的顺序返回。
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
# 加载训练数据集
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_transform, download=True)
# 给训练集创建一个数据加载器, shuffle=True用于打乱数据集,每次都会以不同的顺序返回。
test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else 'cpu'
# 调用net里面定义的模型,如果GPU可用则将模型转到GPU
model = MyLeNet5().to(device)
# 加载 train.py 里训练好的模型
model.load_state_dict(torch.load("sava_model/best_model.pth"))
# 获取预测结果
classes = [
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9",
]
# 把tensor转成Image, 方便可视化
show = ToPILImage()
# 进入验证阶段
model.eval()
# 对test_dataset里10000张手写数字图片进行推理
# for i in range(len(test_dataloader)):
for i in range(5):
x, y = test_dataset[i][0], test_dataset[i][1]
# tensor格式数据可视化
show(x).show()
# 扩展张量维度为4维
x = Variable(torch.unsqueeze(x, dim=0).float(), requires_grad=False).to(device)
with torch.no_grad():
pred = model(x)
# 得到预测类别中最高的那一类,再把最高的这一类对应classes中的哪一类标签
predicted, actual = classes[torch.argmax(pred[0])], classes[y]
# 最终输出的预测值与真实值
print(f'predicted: "{predicted}", actual:"{actual}"')效果如下 ,全部都是正确的滴!


3. 总结
本文介绍利用pytorch搭建LeNet-5网络模型(win11),接下来我会记录我的pytorch和paddle深度学习记录,很高兴能和大家分享!希望你能有所收获。

参考链接:
windows环境下的Anaconda安装与OpenCV机器视觉环境搭建
基于Anaconda安装环境的OpenCV机器视觉环境搭建
利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装---免额外安装CUDA和cudnn
Anaconda安装pytorch和paddle深度学习环境+pycharm安装
基于Anaconda安装pytorch和paddle深度学习环境(win11)