正则表达式(二)
第七个特殊字符 方括号[]
方括号表示要匹配 指定的几个字符之一
例如
[abc] 可以匹配 a, b, 或者 c 里面的任意一个字符。等价于 [a-c] 。
[a-c] 中间的 - 表示一个范围从a 到 c。
如果你想匹配所有的小写字母,可以使用 [a-z], 如果你想匹配所有的阿拉伯数字,可以使用 [0-9]
如果在方括号中使用 ^ ,表示 非 方括号里面的字符集合。
一些 元字符 在 方括号内 失去了魔法, 变得和普通字符一样了。比如[akm.] 匹配 a k m .里面任意一个字符。这里 . 点号在括号里面不在表示 匹配任意字符了,而就是表示匹配 .点号 这个 字符
第八个特殊字符 向上的箭头^
^ 表示匹配文本的 开头 位置。
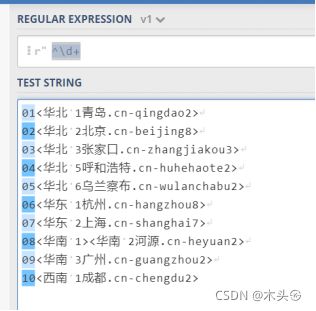
假设有下面这段字符
01<华北 1青岛.cn-qingdao2>
02<华北 2北京.cn-beijing8>
03<华北 3张家口.cn-zhangjiakou3>
04<华北 5呼和浩特.cn-huhehaote2>
05<华北 6乌兰察布.cn-wulanchabu2>
06<华东 1杭州.cn-hangzhou8>
07<华东 2上海.cn-shanghai7>
08<华南 1><华南 2河源.cn-heyuan2>
09<华南 3广州.cn-guangzhou2>
10<西南 1成都.cn-chengdu2>
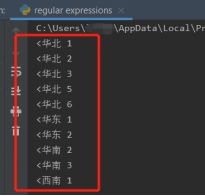
我们想提取每个服务器前面的编号,那么我们可以使用^\d+
正则表达式可以设定 单行模式 和 多行模式
如果是 单行模式 ,表示匹配 整个文本 的开头位置。
如果是 多行模式 ,表示匹配 文本每行 的开头位置。
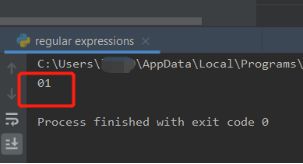
如果我们的代码是这样的 p = re.compile(r’^\d+’) 是单行模式
content= '''01<华北 1青岛.cn-qingdao2>
02<华北 2北京.cn-beijing8>
03<华北 3张家口.cn-zhangjiakou3>
04<华北 5呼和浩特.cn-huhehaote2>
05<华北 6乌兰察布.cn-wulanchabu2>
06<华东 1杭州.cn-hangzhou8>
07<华东 2上海.cn-shanghai7>
08<华南 1><华南 2河源.cn-heyuan2>
09<华南 3广州.cn-guangzhou2>
10<西南 1成都.cn-chengdu2>'''
import re
p = re.compile(r'^\d+')
for one in p.findall(content):
print(one)
运行结果:
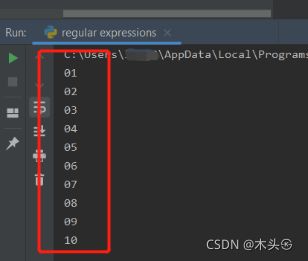
改成多行模式只需要在正则表达式后面加上re.M,像这样p = re.compile(r’^\d+’, re.M)
代码如下
content= '''01<华北 1青岛.cn-qingdao2>
02<华北 2北京.cn-beijing8>
03<华北 3张家口.cn-zhangjiakou3>
04<华北 5呼和浩特.cn-huhehaote2>
05<华北 6乌兰察布.cn-wulanchabu2>
06<华东 1杭州.cn-hangzhou8>
07<华东 2上海.cn-shanghai7>
08<华南 1><华南 2河源.cn-heyuan2>
09<华南 3广州.cn-guangzhou2>
10<西南 1成都.cn-chengdu2>'''
import re
p = re.compile(r'^\d+', re.M)
for one in p.findall(content):
print(one)
运行结果:
第九个特殊字符 $
和 恰 恰 相 反 , 和^恰恰相反, 和恰恰相反, 表示匹配文本的 结尾 位置。假如我们有以下文本,
01<华北 1青岛.cn-qingdao2
02<华北 2北京.cn-beijing8
03<华北 3张家口.cn-zhangjiakou3
04<华北 5呼和浩特.cn-huhehaote2
05<华北 6乌兰察布.cn-wulanchabu2
06<华东 1杭州.cn-hangzhou8
07<华东 2上海.cn-shanghai7
08<华南 1><华南 2河源.cn-heyuan2
09<华南 3广州.cn-guangzhou2
10<西南 1成都.cn-chengdu2
我们想提取每一个服务器最后的编号,就可以使用\w+$
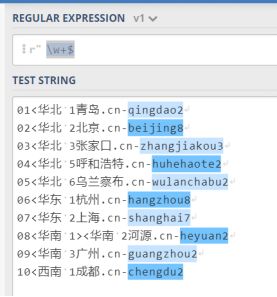
注意使用KaTeX parse error: Undefined control sequence: \w at position 38: …= re.compile(r'\̲w̲+’, re.M) 就会开启多行模式,而p = re.compile(r’\w+$’)则是单行模式.
多行模式开启:
content= '''01<华北 1青岛.cn-qingdao2
02<华北 2北京.cn-beijing8
03<华北 3张家口.cn-zhangjiakou3
04<华北 5呼和浩特.cn-huhehaote2
05<华北 6乌兰察布.cn-wulanchabu2
06<华东 1杭州.cn-hangzhou8
07<华东 2上海.cn-shanghai7
08<华南 1><华南 2河源.cn-heyuan2
09<华南 3广州.cn-guangzhou2
10<西南 1成都.cn-chengdu2'''
import re
p = re.compile(r'\w+$', re.M)
for one in p.findall(content):
print(one)
运行结果:
多行模式关闭,单行模式开启,代码如下
content= '''01<华北 1青岛.cn-qingdao2
02<华北 2北京.cn-beijing8
03<华北 3张家口.cn-zhangjiakou3
04<华北 5呼和浩特.cn-huhehaote2
05<华北 6乌兰察布.cn-wulanchabu2
06<华东 1杭州.cn-hangzhou8
07<华东 2上海.cn-shanghai7
08<华南 1><华南 2河源.cn-heyuan2
09<华南 3广州.cn-guangzhou2
10<西南 1成都.cn-chengdu2'''
import re
p = re.compile(r'\w+$')
for one in p.findall(content):
print(one)
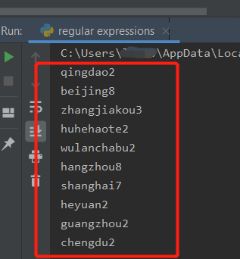
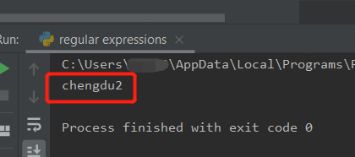
运行结果如下,从最后一行的末尾开始
第十个特殊字符 | 竖线
竖线表示 匹配 其中之一 。
华|北表示匹配“华”或者“北”
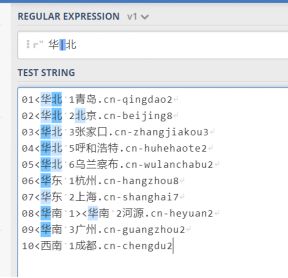
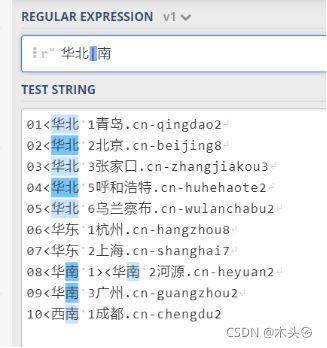
特别要注意的是, 竖线在正则表达式的优先级是最低的, 这就意味着,竖线隔开的部分是一个整体
例如 华北|南匹配的是“华北”或者“南”,而不是“华北”或者“华南”,见下图
第十一个特殊字符 括号
括号称之为 正则表达式的 组选择。
组 就是把 正则表达式 匹配的内容 里面 其中的某些部分 标记为某个组。
我们可以在 正则表达式中 标记 多个 组
为什么要有组的概念呢?因为我们往往需要提取已经匹配的 内容里面的 某些部分的信息
例如下面这段文本,我们想提取点号后面的内容,但是不包括点号。
‘<华北 1,青岛.cn-qingdao2>
<华北 2,北京.cn-beijing8>
<华北 3,张家口.cn-zhangjiakou3>
<华北 5,呼和浩特.cn-huhehaote2>
<华北 6,乌兰察布.cn-wulanchabu2>
<华东 1,杭州.cn-hangzhou8>
<华东 2,上海.cn-shanghai7>
<华南 1,><华南 2,河源.cn-heyuan2>
<华南 3,广州.cn-guangzhou2>
<西南 1,成都.cn-chengdu2>’
我们学\来转义点号的时候学到,可以使用^.,来选取点号后面的内容,但是这会把点号也包含在内。因此我们可以使用()来将内容分组: ^(.), 这样就表示选出来的内容中 .* 是一个组,然后后面有逗号的又是一个组,见下图


有逗号的是一个组,没有逗号的又是一个组
在python中可以这样提取一个组里面的:
content= '''<华北 1,青岛.cn-qingdao2>
<华北 2,北京.cn-beijing8>
<华北 3,张家口.cn-zhangjiakou3>
<华北 5,呼和浩特.cn-huhehaote2>
<华北 6,乌兰察布.cn-wulanchabu2>
<华东 1,杭州.cn-hangzhou8>
<华东 2,上海.cn-shanghai7>
<华南 1,><华南 2,河源.cn-heyuan2>
<华南 3,广州.cn-guangzhou2>
<西南 1,成都.cn-chengdu2>
'''
import re
p = re.compile(r'^(.*),', re.M)
for one in p.findall(content):
print(one)
运行结果如下
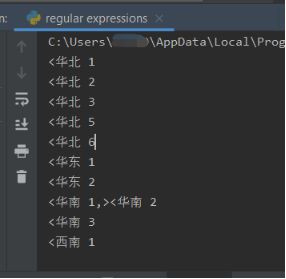
稍微复杂一点的
例如下面这段文字,我们想将地域,城市,和编号分别用组的概念表示出来,例如
<华北 1,青岛.cn-qingdao2>我们希望最后提取出来的组分别是“华北 1”, “青岛”,“qingdao2”这样
<华北 1,青岛.cn-qingdao2>
<华北 2,北京.cn-beijing8>
<华北 3,张家口.cn-zhangjiakou3>
<华北 5,呼和浩特.cn-huhehaote2>
<华北 6,乌兰察布.cn-wulanchabu2>
<华东 1,杭州.cn-hangzhou8>
<华东 2,上海.cn-shanghai7>
<华南 2,河源.cn-heyuan2>
<华南 3,广州.cn-guangzhou2>
<西南 1,成都.cn-chengdu2>
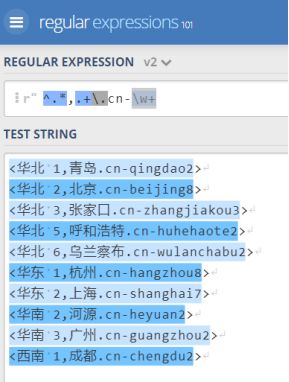
首先全部选取是 ^.,.+.cn-\w+
^., 是逗号前面的,包含逗号,表示地域
.+ 是.cn前面的城市
\w+ 是后面那串编号
接着我们开始拆分,分别在我们需要的信息两边加上括号 ^(.*),(.+).cn-(\w+)
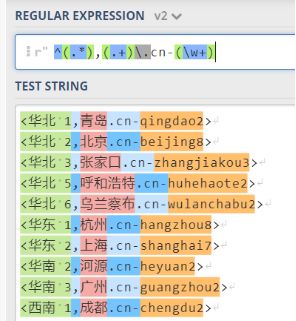
可以看到我们成功的将原来的信息分成了三组
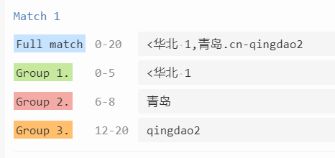
在Python中,如果直接使用这个正则表达式,返回的结果是一个元祖,如下
content= '''<华北 1,青岛.cn-qingdao2>
<华北 2,北京.cn-beijing8>
<华北 3,张家口.cn-zhangjiakou3>
<华北 5,呼和浩特.cn-huhehaote2>
<华北 6,乌兰察布.cn-wulanchabu2>
<华东 1,杭州.cn-hangzhou8>
<华东 2,上海.cn-shanghai7>
<华南 2,河源.cn-heyuan2>
<华南 3,广州.cn-guangzhou2>
<西南 1,成都.cn-chengdu2>
'''
import re
p = re.compile(r'^(.*),(.+)\.cn-(\w+)', re.M)
for one in p.findall(content):
print(one)
运行结果

在python中,当有多个分组的时候,我们可以使用 (?P<分组名>…) 这样的格式,给每个分组命名。
这样做的好处是,更方便后续的代码提取每个分组里面的内容
代码如下
content= '''<华北 1,青岛.cn-qingdao2>
<华北 2,北京.cn-beijing8>
<华北 3,张家口.cn-zhangjiakou3>
<华北 5,呼和浩特.cn-huhehaote2>
<华北 6,乌兰察布.cn-wulanchabu2>
<华东 1,杭州.cn-hangzhou8>
<华东 2,上海.cn-shanghai7>
<华南 2,河源.cn-heyuan2>
<华南 3,广州.cn-guangzhou2>
<西南 1,成都.cn-chengdu2>
'''
import re
p = re.compile(r'^(?P<地域>.*),(?P<城市>.+)\.cn-(?P<编号>\w+)', re.M)
for match in p.finditer(content):
print(match.group('地域'))
#print(match.group('城市'))
#print(match.group('编号'))
运行结果如下
让点匹配换行
前面说过, 点 是 不匹配换行符 的,可是有时候,特征 字符串就是跨行的,比如要找出下面文字中所有的职位名称
<div class="el">
<p class="t1">
<span>
<a>Python开发工程师</a>
</span>
</p>
<span class="t2">南京</span>
<span class="t3">1.5-2万/月</span>
</div>
<div class="el">
<p class="t1">
<span>
<a>java开发工程师</a>
</span>
</p>
<span class="t2">苏州</span>
<span class="t3">1.5-2/月</span>
</div>
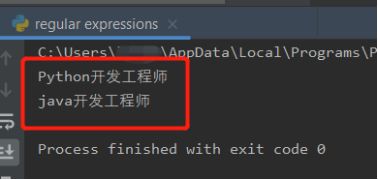
如果在regular expression测试界面使用正则表达式class=“t1”>.\s+\s+(.+)< 才可以匹配的我们需要的内容。
如果你直接使用表达式 class=“t1”>.?(.*?) 会发现匹配不上,因为 t1 和 之间有两个空行。
这时你需要 点也匹配换行符 ,可以使用 DOTALL 参数
代码如下
content = '''
'''
import re
p = re.compile(r'class=\"t1\">.*?(.*?)', re.DOTALL)
for one in p.findall(content):
print(one)
运行结果:
…接下来的点进主页见正则表达式(三)
有疑问滴滴V:mutou88848
