人之所以不快乐,主要是缘于过去和未来:为过去耿耿于怀,为未来惴惴不安
大家好,我是柒八九。
在前期,我们开了一个关于前端工程化的系列文章。已经从
等角度进行了一些常规概念的介绍和梳理。而今天,我们选择了一个在前端范围内,占很大比重的构建工具--Webpack。
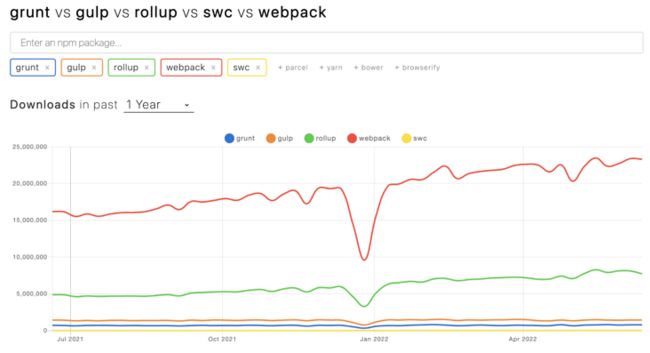
近一年的npm下载量
github对应的stars
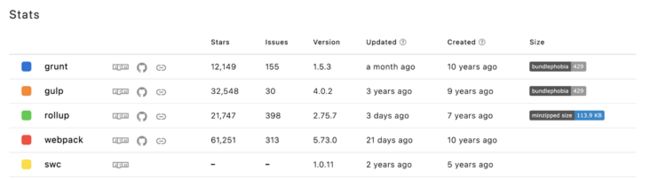
可以看到,无论是从npm 下载量和github的star的数量,Webpack都遥遥领先于其他工具(grunt/gulp/rollup/swc)
Webpack 是一个非常强大的构建工具,它可以被认为是当今许多技术中的一个基本组件,前端开发人员使用它来构建他们的应用程序。
好了,话不多说,继续赶路。

你能所学到的知识点
Webpack常见概念(entry/output/loader)- 从
entry对象{a:'./a.js'}如何构建一个模块树
`entry`=>`EntryPlugin`=>`EntryDependency`=>`NormalModuleFactory`=>模块树
ModuleGraph如何跟踪已建模块直接的关系ModuleGraph是如何被构建的Module/Chunk/ ChunkGroup /EntryPoint具体是啥并它们直接的关系ChunkGraph是如何被构建的
文章概要
Webpack基本概念简讲- 打包流程总览
entry对象- 深入理解 ModuleGraph
- 构建ModuleGraph
- Module/Chunk/ ChunkGroup /EntryPoint 是个啥
- 提交chunk资源
0. Webpack基本概念简讲
本质上,webpack是一个现代JavaScript应用程序的静态{模块打包器| module bundler}
当webpack处理应用程序时,它会递归地构建一个{依赖关系图| dependency graph},其中包含应用程序需要的每个模块,然后将所有这些模块打包成一个或多个bundle。
运行方式
在项目中有两种运行 Webpack 的方式:
- 基于命令行的方式
webpack --config webpack.config.js 基于代码的方式
var webpack = require('webpack') var config = require('./webpack.config') webpack(config, (err, stats) => {})重要概念
针对
Webpack有几个重要的概念需要知晓。
| 关键字 | 作用 |
|---|---|
Entry |
Webpack 的入口文件 指的是应该从哪个模块作为入口,来构建内部依赖图 |
Output |
告诉 Webpack 在哪输出它所创建的 bundle 文件以及输出的 bundle 文件该如何命名、输出到哪个路径下等规则 |
Loader |
模块代码转化器 使得 Webpack 有能力去处理除了 JS、JSON 以外的其他类型的文件 |
Plugin |
Plugin 提供执行更广的任务的功能 包括:打包优化,资源管理,注入环境变量等 |
Mode |
根据不同运行环境执行不同优化参数时的必要参数 |
Browser Compatibility |
支持所有 ES5 标准的浏览器(IE8 以上) |
1. 打包流程总览
在此篇文章中,我们只针对NormalModules进行讲解。当然,还有其他类型的模块 如 ExternalModule 和 ConcatenatedModule(当使用require.context()时)这些都不在我们讨论范围内。
先来一个总体流程,润润嗓子。(莫慌,关键的点,后面都会做解释)
2. entry对象
一切都从entry对象开始
我们用一个简单例子来说明它的作用,在这个例子中,entry对象只是一个键值对的集合。
// webpack.config.js
entry: {
a: './a.js',
b: './b.js',
/* ... */
}
webpack 中的模块与文件是一一对应的。
因此,在上面的代码中,a.js会产生一个新的模块,而b.js也会产生。
模块是文件的升级版。
模块,一旦创建和构建,除了源代码,还包含很多有意义的信息,如:
- 使用的加载器
- 它的依赖关系
- 它的出口(如果有的话)
- 它的哈希值
同时entry对象中的每一项都可以被认为是模块树中的根模块。模块树是因为根模块可能需要一些其他的模块,这些模块可能需要其他的模块,等等。所有这些模块树都被储存在 ModuleGraph中。
我们需要提到的下一件事是,webpack是建立在很多插件之上的。人们有很多方法可以加入自定义逻辑。webpack的可扩展性是通过hook实现的。例如,你可以在 ModuleGraph 建立后,当一个新的{资源|asset }被生成时,在模块即将被建立前(运行加载器和解析源代码),添加自定义逻辑。大多数时候,hook是根据它们的目的分组的,对于任何定义好的目的,都有一个{插件| plugin}。例如,有一个插件负责处理import()函数(负责解析注释和参数)--它被称为 ImportParserPlugin,它所做的就是在 AST 解析过程中遇到import()调用时,添加一个hook。
有几个插件负责处理entry对象。有一个 EntryOptionPlugin,它实际上是接收entry对象,并为对象中的每个项目创建一个 EntryPlugin对象。entry对象的每个项目都会产生一棵模块树(所有这些树都是相互分离的)。基本上,EntryPlugin 开始创建一个模块树,每个模块都会在同一个地方(ModuleGraph)添加信息。
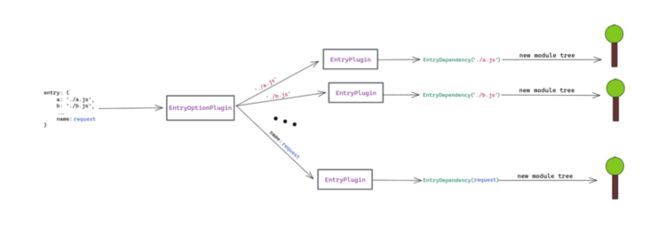
EntryPlugin 也是创建 EntryDependency 的地方。
基于上图,让我们简单地实现自定义的EntryOptionsPlugin。
class CustomEntryOptionPlugin {
// 这是创建插件的标准方法(实现apply方法)
// 就是一个简单的函数
apply(compiler) {
compiler.hooks.entryOption.tap('CustomEntryOptionPlugin', entryObject => {
// 对于`entryObject`中的每个项,我们为其创建一个模块树。
// 记住,每个模块树都是独立的
// `entryObject`可以是这样的。`{ a: './a.js' }`
for (const name in entryObject) {
const fileName = entryObject[name];
// 当打包过程开始时,准备为这个entryObject创建一个模块树。
new EntryOption({ name, fileName }).apply(compiler);
};
});
}
};
代码解析:
hook为我们提供了介入打包过程的可能性。- 在
entryOptionhook的帮助下,我们添加了一个逻辑。 - 此时基本上意味着打包过程的开始。
entryObject参数将保存来自配置文件的entry对象。- 配置文件中的
entry对象,将用它来设置创建模块树。
EntryOption插件的定义
// `EntryOption`类将处理模块树的创建。
class EntryOption {
constructor (options) {
this.options = options;
};
// 这仍然是一个插件,所以我们要遵守标准(实现apply)
apply(compiler) {
compiler.hooks.start('EntryOption', ({ createModuleTree }) => {
// 基于这个插件的配置,创建新的模块树。
createModuleTree(new EntryDependency(this.options));
});
};
};代码解析:
start钩子标志着打包过程的开始。 它将在调用hooks.entryOption之后被调用。options包含entry名称(本质上就是块的名称)和文件名。EntryDependency封装了这些选项,同时也提供了创建模块的方法。- 在调用
createModuleTree后,文件的源代码将被找到。 - 然后,一个模块实例将被创建,然后webpack将得到它的
AST,并且将在打包过程中进一步使用
上面代码中,我们提到了EntryDependency,我们来一步了解一下。
当涉及到创建新模块时,这一切都归结为一个抽象过程。简单地说,一个{依赖关系|dependency }只是一个实际模块实例的初步入口。例如,在 webpack 的观点中,甚至entry对象的项也是依赖关系,它们表明了创建模块实例的最低限度:它的路径(例如./a.js, ./b.js)。如果没有依赖关系,模块的创建就无法开始,因为依赖关系除其他重要信息外,还包含模块的请求,即可以找到模块源代码的文件的路径(例如"./a.js")。
依赖关系还表明如何构建该模块,它通过{模块工厂|ModuleFactory}来实现。模块工厂知道如何从一个原始状态(例如源代码是一个简单的字符串)开始,然后到达具体的实体文件,然后被webpack利用。EntryDependency 实际上是 ModuleDependency 的一种类型,意味着它肯定会持有模块的请求,它所指向的模块工厂是 NormalModuleFactory。那么,NormalModuleFactory 就知道要做什么,以便从一个路径中创建对webpack有意义的东西。
另一种思考方式是,模块起初只是一个简单的路径(要么在entry对象中,要么是import语句的一部分),然后它变成了一个依赖关系,最后变成了一个模块。

因此,EntryDependency 在一开始创建模块树的根模块时就被使用。
对于其余的模块,还有其他类型的依赖关系。例如,如果你使用import语句,比如从./a.js导入 defaultFn,那么就会有一个 HarmonyImportSideEffectDependency,./a.js持有模块的请求,也映射到 NormalModuleFactory。因此,将有一个新的模块用于'a.js'文件。
快速回顾一下我们在本节中所学到的内容:
- 对于
entry对象中的每一项,都会有一个EntryPlugin实例,其中创建了一个EntryDependency。- 这个
EntryDependency保存了模块的请求(即文件的路径),并且通过映射到一个模块工厂,即NormalModuleFactory,提供了一种使该请求有用的方法。- {模块工厂|ModuleFactory}知道如何从一个文件路径中创建对webpack有用的实体。
- {依赖关系|dependency }对创建一个模块至关重要,因为它拥有重要的信息,比如模块的请求和如何处理该请求。依赖关系有几种类型,并不是所有的依赖关系都对创建一个新模块有用。
- 从每个
EntryPlugin实例,在新创建的EntryDependency的帮助下,将创建一个模块树。模块树是建立在模块和它们的依赖关系之上的,这些模块也可以有依赖关系。
3. 深入理解 ModuleGraph
ModuleGraph 是一种跟踪已建模块的方法。
它在很大程度上依赖于{依赖关系|dependency },因为它们提供了连接两个不同模块的方法。
比如说。
// a.js
import defaultBFn from '.b.js/';
// b.js
export default function () { console.log('我是大帅 B!'); }
这里我们有两个文件,所以有两个模块。文件a需要文件b的一些东西,所以在a中存在一个依赖关系,这个依赖关系是通过导入语句建立的。就 ModuleGraph 而言,依赖关系定义了一种连接两个模块的方式。上面的片段可以被可视化为:

ModuleGraph 的节点被称为 ModuleGraphModule,它只是一个装饰过的NormalModule实例。ModuleGraph 在一个map对象的帮助下跟踪这些装饰过的模块,它有这样的签名:Map。
例如,如果只有 NormalModule 实例,那么你对它们就没有什么可做的,它们不知道如何相互交流。ModuleGraph 赋予这些原始模块能通过上述map的帮助将它们相互连接起来的能力,该map为每个NormalModule分配了一个ModuleGraphModule。我们将把属于ModuleGraph的模块也称为模块,因为NormalModule和ModuleGraphModule区别在于只包括一些额外的无关紧要属性。
对于一个属于 ModuleGraph 的节点来说,有几件事情是明确的:传入的连接和传出的连接。连接是 ModuleGraph 的另一个小实体,它拥有有意义的信息,如:起源模块、目标模块和连接上述两个模块的依赖关系。具体来说,基于上图,一个新的连接已经被创建。
//这是以上面的图和代码为基础的形成的连接关系
Connection: {
originModule: A, // 起源模块
destinationModule: B, // 目标模块
dependency: ImportDependency // 依赖关系
}
而上述连接对象将被添加到A.outgoingConnections集和和B.incomingConnections集和中。
所有从entry中创建的模块树都将向同一个单一的地方,即向ModuleGraph输出有意义的信息。这是因为所有这些模块树最终都将与空模块(ModuleGraph的根模块)相连。与空模块的连接是通过 EntryDependency 和从entry文件中创建的模块建立的。
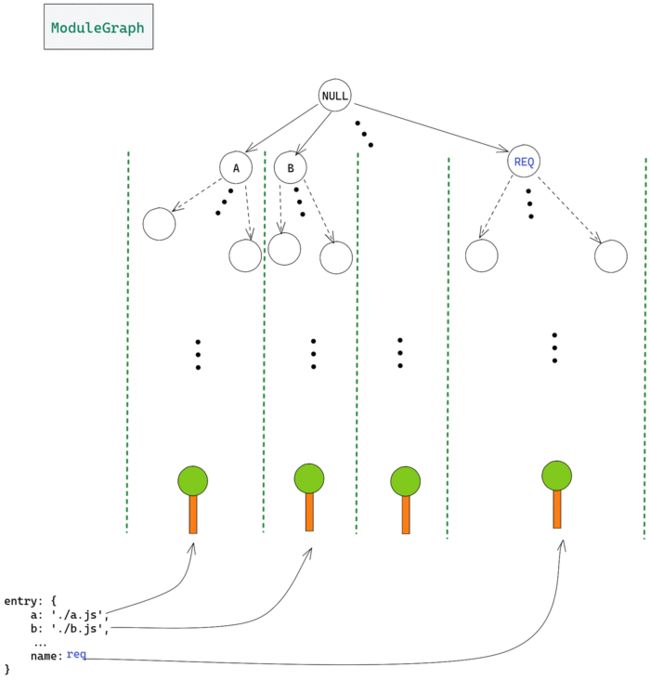
空模块与每个模块树的根模块有一个连接,该模块由entry对象中的一个项目生成。图中的每条边都代表2个模块之间的连接,每个连接都有关于源节点、目标节点和依赖关系的信息。
4. 构建ModuleGraph
ModuleGraph从一个空模块开始,其直系子孙是模块树的根模块,这些模块是由entry对象项构建的
首批创建的模块
我们从一个简单的entry对象开始。
entry: {
a: './a.js',
}正如我们上文说到,在某些时候,我们最终会得到一个 EntryDependency,其请求是./a.js。这个 EntryDependency 提供了一种从该请求创建有意义的东西的方法,因为它映射到一个模块工厂,即 NormalModuleFactory。
这个过程的下一步是 NormalModuleFactory 发挥作用的地方。NormalModuleFactory,如果它成功地完成了它的任务,将创建一个NormalModule。
NormalModule只是一个文件源代码的反序列化版本,它只不过是一个原始字符串。
一个原始的字符串不会带来太多的价值,所以webpack不能用它做什么。一个NormalModule会将源代码存储为一个字符串,但是,与此同时,它也会包含其他有意义的信息和功能,比如:
- 应用于它的加载器
- 构建模块的逻辑
- 生成运行时代码的逻辑
- 它的哈希值等等
换句话说,从 webpack 的角度来看,NormalModule 是一个简单原始文件的有用版本。
为了让 NormalModuleFactory 输出一个 NormalModule,它必须要经过一些步骤。在模块被创建后,还有一些事情要做,比如构建模块和处理其依赖关系(如果有的话)。
NormalModuleFactory 通过调用create()方法开始。然后,解析过程开始。在这里,请求(文件的路径)被解析,以及该类型文件的加载器。
注意,只有加载器的文件路径将被确定,加载器在这一步还没有被调用。
module 的构建过程
在所有必要的文件路径被解决后,NormalModule被创建。然而,在这步,模块的价值不大。很多相关的信息将在模块建立后出现。NormalModule 的构建过程还包括一些其他步骤。
- 首先,
loader将在原始源代码上被调用;如果有多个加载器,那么一个加载器的输出可能是另一个加载器的输入(配置文件中提供加载器的顺序很重要)。 - 其次,通过所有加载器运行后得到的字符串将被
acorn(JavaScript解析器)解析,得到给定文件的AST。 最后,
AST将被分析;- 在这个阶段,当前模块的依赖关系(如其他模块)将被确定,
webpack可以检测其它的功能(如require.context,module.hot)等; AST分析发生在JavascriptParser中, 这个过程的一部分是最重要的,因为打包过程中接下来的很多事情都取决于这个部分。
- 在这个阶段,当前模块的依赖关系(如其他模块)将被确定,
通过分析AST发现依赖关系

其中 moduleInstance 是指从index.js文件中创建的 NormalModule。红色的dep是指从第一个import语句中创建的依赖关系,蓝色的dep是指第二个import语句。
现在AST已经被检查过了,到建立模块树的过程了。下一步是处理在上一步发现的依赖关系。按照上图,index模块有两个依赖关系,也是模块,即math.js和utils.js。但在这些依赖关系成为实际的模块之前,我们只有index模块,为了把它们变成模块,我们需要使用这些依赖关系映射到的ModuleFactory,并重复上面描述的步骤(本节开头的图中的虚线箭头表示重复)。在处理完当前模块的依赖关系后,这些依赖关系也可能有依赖关系,这个过程一直持续到没有更多的依赖关系。这就是模块树的建立过程,当然也要确保父模块和子模块之间的连接被正确设置。
让我们实现一个自定义插件的方法,它将使我们能够遍历 ModuleGraph。下面是描述模块如何相互依赖的图。

简单的做一个介绍:a.js 文件导入b.js文件,b.js文件同时导入b1.js和c.js,然后c.js导入c1.js和d.js,最后,d.js导入d1.js。ROOT 指的是null模块,它是 ModuleGraph 的根。
入口选项只包括一个值,即a.js。
// webpack.config.js
const config = {
entry: path.resolve(__dirname, './src/a.js'),
/* ... */
};现在让我们看看我们的自定义插件会是什么样子
class UnderstandingModuleGraphPlugin {
apply(compiler) {
const className = this.constructor.name;
compiler.hooks.compilation.tap(className, (compilation) => {
compilation.hooks.finishModules.tap(className, (modules) => {
// 检索 Map
const {
moduleGraph: { _moduleMap: moduleMap },
} = compilation;
// 以DFS的方式遍历模块图
const dfs = () => {
// "模块图 "的根模块是*空模块*。
const root = null;
const visited = new Map();
const traverse = (crtNode) => {
if (visited.get(crtNode)) {
return;
}
visited.set(crtNode, true);
console.log(
crtNode?.resource ? path.basename(crtNode?.resource) : 'ROOT'
);
// 获得相关的`ModuleGraphModule`,它只有一些
//除了`NormalModule'之外的额外属性,我们可以用它来进一步遍历图形。
const correspondingGraphModule = moduleMap.get(crtNode);
// 通过指定字段构建`children`信息
const children = new Set(
Array.from(
correspondingGraphModule.outgoingConnections || [],
(c) => c.module
)
);
for (const c of children) {
traverse(c);
}
};
// 从root节点开始遍历
traverse(root);
};
dfs();
});
});
}
}
对代码最一个简单的解释
在现有的
webpack hooks中添加逻辑的方式是使用tap方法- 函数签名为
tap(string, callback) - 其中
string主要是为了调试的目的,表示自定义逻辑是由哪个来源添加的。 callback的参数取决于我们要添加自定义功能的hook
- 函数签名为
在
compilation对象上:它包含大部分打包过程状态- 模块图(module graph)
- 创建的
chunks - 创建的
modules - 生成的
assets - 以及更多的信息
finishModules是在所有模块(包括它们的依赖关系和依赖关系的依赖关系等等)构建完毕后才被被调用modules是一个包含所有已建模块的集合- 一个
NormalModule是由NormalModuleFactory产生的
- 一个
模块map(
Map)- 它包含了我们需要的所有信息,以便遍历图
- 以
DFS的方式遍历模块图 ModuleGraphModule,它只有一些除了`NormalModule'之外的额外属性Connection的字段信息Connection的originModule是箭头开始的地方。Connection的module是箭头的终点。所以,
Connection的module是一个子节点。
correspondingGraphModule.outgoingConnections是一个Set或者undefined(在节点没有子节点的情况下)。- 使用
new Set是因为一个模块可以通过多个连接引用同一个模块。 例如,一个
import foo from 'file.js'将导致2个连接:- 一个是简单的导入
- 一个用于`foo'默认指定器
- 使用
根据模块的层次结构,得到如下的输出。
a.js
b.js
b1.js
c.js
c1.js
d.js
d1.js
5. Module/Chunk/ ChunkGroup /EntryPoint 是个啥
Module
前文其实已经解释过了,这里再做一次总结哇。
模块是一个文件的升级版。
一个模块,一旦创建和构建,除了源代码,还包含很多有意义的信息,如:
- 使用的加载器
- 它的依赖关系
- 它的出口(如果有的话)
- 它的哈希值
Chunk
一个Chunk封装了一个或多个模块
一般情况下,entry文件(一个entry文件=entry对象的一个项目)的数量与所产生的Chunk的数量成正比。
- 因为
entry对象可能只有一个项目,而结果块的数量可能大于1。的确,对于每一个entry项目,在dist目录中都会有一个相应的chunk但也可能是隐式创建其他的
chunk,例如在使用import()函数时。但不管它是如何被创建的,每个chunk在dist目录下都会有一个对应的文件。
ChunkGroup
一个ChunkGroup包含一个或多个chunks
一个ChunkGroup可以是另一个ChunkGroup的父或子。
- 例如,当使用动态导入时,每使用一个
import()函数,就会有一个ChunkGroup被创建,它的父级是一个现有的ChunkGroup,即包括使用import()函数的文件(即模块)的那个。
EntryPoint
EntryPoint是ChunkGroup的一种类型,它是为entry对象中的每一个项目创建的。
构建 ChunkGraph
从整体的流程图上看,ModuleGraph 只是打包过程中的一个必要部分。为了使代码分割等功能成为可能,它必须被利用起来。
在打包过程的这一点上,对于entry对象中的每个项目,都会有一个 EntryPoint。 因为它是 ChunkGroup 的一种类型,它至少会包含一个chunk。所以,如果entry对象有3个项目,就会有3个 EntryPoint实例,每个实例都有一个chunk,也叫Entrypoint chunk,其名称是entry项目key的值。与entry文件相关联的模块被称为entry模块,它们每个都将属于它们的入口块。它们之所以重要是因为它们是 ChunkGraph 构建过程的起点。请注意,一个chunk可以有多个入口模块。
// webpack.config.js
entry: {
foo: ['./a.js', './b.js'],
},在上面的例子中,有一个名为foo(entry的key)的 chunk 将有2个入口模块:一个与a.js文件相关,另一个与b.js文件相关。当然,该chunk将属于根据entry项目创建的 EntryPoint实例。
在详细讨论之前,让我们先列出一个例子,在此基础上讨论构建过程。
entry: {
foo: [path.join(__dirname, 'src', 'a.js'), path.join(__dirname, 'src', 'a1.js')],
bar: path.join(__dirname, 'src', 'c.js'),
},
这个例子将包括前面提到的东西:ChunkGroups 的父子关系、chunks 和 EntryPoints。
ChunkGraph 是以递归的方式建立的。它首先将所有的entry模块添加到一个队列中。然后,当一个entry模块被处理时,意味着其依赖关系(也是模块)将被检查,每个依赖关系也将被添加到队列中。这样一直重复下去,直到队列变空。这个过程的这一部分是模块被访问的地方。然而,这只是第一部分。
ChunkGroups 可以是其他 ChunkGroups 的父/子。这些联系在第二部分得到解决。例如,如前所述,一个动态导入(即import()函数)会产生一个新的子ChunkGroup。在webpack的说法中,import()表达式定义了一个异步的依赖关系块。
现在,让我们先看看从上述配置中创建的ChunkGraph的图表。
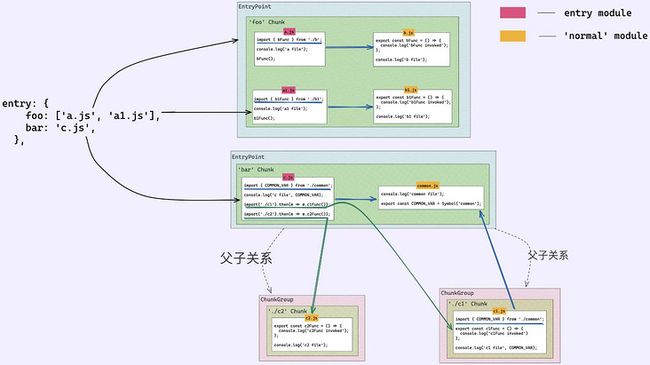
从上图中,可以看到有4个 chunk,所以会有4个输出文件。foo chunk将有4个模块,其中2个是entry模块。bar chunk将只有一个entry模块,另一个可以被认为是普通模块。每个import()表达式都会产生一个新的ChunkGroup(其父级是bar EntryPoint)。
产生的文件的内容是根据 ChunkGraph 来决定的,所以这就是为什么它对整个打包过程非常重要。
与 ModuleGraph 类似,属于 ChunkGraph 的节点被称为 ChunkGraphChunk,它只是一个装饰过的chunk,他们之间的关系如下:WeakMap。
6. 提交chunk资源
所产生的文件并不是原始文件的副本,因为为了实现其功能,webpack 需要添加一些自定义代码,使一切都按预期工作。
这就引出了一个问题:webpack如何知道要生成什么代码?
这一切都从最基本的部分开始:{模块| module}。一个模块可以导出成员,导入其他成员,使用import()导入,使用webpack特定的函数(例如require.resolve)等等。
根据模块的源代码,webpack可以决定生成哪些代码以实现所需的功能。并且在分析AST时发现对应模块的依赖关系。
例如,从./foo 导入 { aFunction } 将导致两个依赖关系(一个是导入语句本身,另一个是指定器,即 aFunction),从中将创建一个模块。
另一个例子是 import() 函数。这将导致一个异步的依赖关系块,其中一个依赖关系是 ImportDependency,它是动态导入所特有的。
这些依赖关系是必不可少的,因为它们带有一些关于应该生成什么代码的提示。例如,ImportDependency 确切地知道要告诉 webpack 一些信息,以便异步地获取导入的模块并使用其导出的成员。这些提示可以被称为运行时请求。
总而言之,一个模块会有它的运行时间要求,这取决于该模块在其源代码中使用的内容。现在,webpack知道了一个chunk的所有需求,它将能够正确地生成运行时代码。
这也被称为渲染过程,渲染过程在很大程度上依赖于 ChunkGraph,因为它包含Chunk组(即 ChunkGroup,EntryPoint),这些组包含Chunks,这些Chunks包含模块,这些模块以一种细化的方式包含有关webpack将生成的运行时代码的信息和提示。
后记
分享是一种态度。
参考资料:
全文完,既然看到这里了,如果觉得不错,随手点个赞和“在看”吧。

本文由mdnice多平台发布