2_1 (Oracle/MySQL/SQLServer)数据类型之长度、精度、标度
目录
- 一.前言
- 二. 长度、精度、标度
-
- 2.1 SQLServer 数据类型
- 2.2 Oracle数据类型
- 三. 获取表结构信息
- F 附录
-
- F.1 表字段syscolumns 字典
- 参考文章
相关链接
- Excel目录
一.前言
在进行数据采集工作前 — 需要调研上游表结构
这样在数据仓库的S层创建的表与原表结构一致
才能保证采集来的数据长度不会溢出,且不占用过多空间
查询表结构时发现以下问题:(使用工具为DBeaver,上游库为SQLServer,版本12.0.5000.0)
- 常规表结构
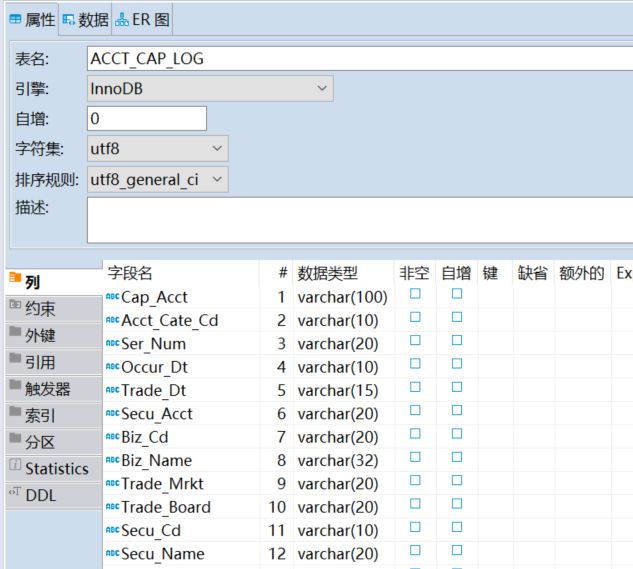
- 非常规表结构(自定义字段类型)
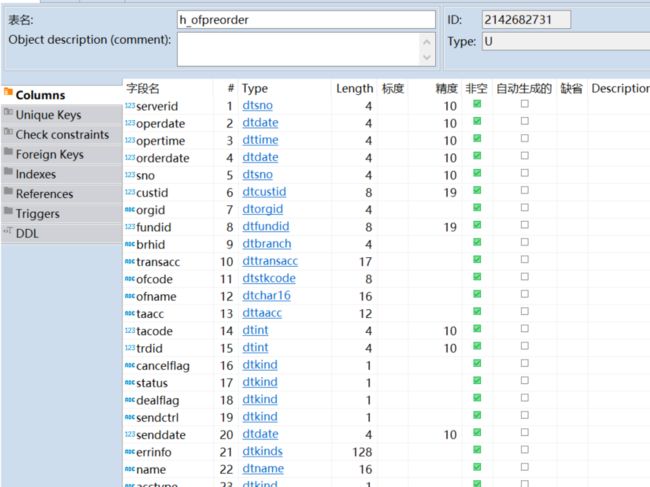
由于出现自定义字段类型,如dtsno 、dtdate 等
DBeaver显示数据类型时并没有显示,那么就有了以下两个问题
Q1:什么是长度,精度,标度
Q2:如何获取标准字段类型,以及数据类型如何转换
二. 长度、精度、标度
Q1:什么是长度,精度,标度
长度:占计算机存储容量,在上图中显示的Length表示长度,单位为字节 例如:int类型占用4个字节
精度:指数字的位数。例如:数 123.45 的精度是 5
标度:指小数点后的数字位数。 例如:数 123.45 的标度是 2。
bit --位:位是计算机中存储数据的最小单位,指二进制数中的一个位数,其值为“0”或“1”。
byte --字节:字节是计算机存储容量的基本单位,一个字节由8位二进制数组成。在计算机内部,一个字节可以表示一个数据,也可以表示一个英文字母,两个字节可以表示一个汉字。
1Byte=8bit (1B=8bit)
1KB=1024Byte(字节)=8*1024bit
1MB=1024KB
1GB=1024MB
1TB=1024GB
- 在DDL语句中,长度,精度,标度 都会用到
- numeric(m,n)
- m : 精度(有效位数)
- n : 标度 (小数点后位数)
- char(n)
- n : 长度(占计算机存储字节容量)
| 编码格式 | 中/Eng | 占用字节 | 优点 | 缺点 | 备注 |
|---|---|---|---|---|---|
| ASCII | Eng 中 |
1 Byte |
单字节,空间小 | 不支持中文 | 7 Bit字符集 最简单的英文编码方案 编码从0到127 |
| ISO-8859-1 | Eng 中 |
1 Byte |
单字节,空间小 | 不支持中文 不同国家编码 128-255不同 |
8 Bit字符集 有些环境下写作Latin-1 又叫ANSI编码 (非ASCII编码) 向下兼容ASCII |
| UNICODE | Eng 中 |
2 Byte 2 Byte |
国际组织编码,容纳世界上所有的文字和符号的字符编码 | 不利于英文传输/存储 | 在计算机内存中,统一使用Unicode编码, 当需要保存到硬盘或者需要传输的时候, 就转换为UTF-8编码。 用记事本编辑的时候, 从文件读取的UTF-8字符被转换为Unicode字符到内存里, 编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。 向下兼容 ISO-8859-1 |
| UTF-8 | Eng 中 |
1 Byte 3~4Byte |
变长的编码方式 1-6 Byte 英文占用空间小 且支持中文 |
不利于中文传输/存储 | 3 Byte:常用汉字 4 Byte:中文生僻字 UTF-8就是在互联网上使用最广的一种Unicode的实现方式 如字节第一位0 -> 分两种情况 —情况1.单字节开头 —情况2.多字节的结尾 如字节第一位1 ->多字节 (连续1的数量=字符占用字节数) 向下兼容ASCII |
| UTF-16 | Eng 中 |
4 Byte 4 Byte |
资料不全 | ||
| UTF-16BE | Eng 中 |
2 Byte 2 Byte |
资料不全 | ||
| UTF-16LE | Eng 中 |
2 Byte 2 Byte |
资料不全 | ||
| GB2312、GBK | Eng 中 |
2 Byte 2 Byte |
数据库占用空间比UTF-8少1/3 | 国际性兼容不好 外国访问出现乱码 |
汉字字符编码方案的国家标准 向下兼容ASCII |
2.1 SQLServer 数据类型
| 数据大类 | SQLServer | Teradata | 备注 |
|---|---|---|---|
| Character字符串 | char(n) | char(n) | 固定长度的字符串,最大长度为8000个字符 |
| varchar(n) | varchar(n) | 可变长度的字符串,最大长度为8000个字符 | |
| varchar(max) | 可变长度的字符串,最多2^30=1,073,741,824个字符 | ||
| text | 可变长度,最大长度为(2^31)-1=2147483647个字符(2GB字符数据) | ||
| Unicode字符串 | nchar(n) | char(n) | 固定长度的字符串,最大长度为4000个字符 |
| nvarchar(n) | varchar(n) | 可变长度的字符串,最大长度为4000个字符 | |
| nvarchar(max) | varchar(64000) | 存储可变长度的长文本,(2^30)-1=1073741823个字符 | |
| ntext | varchar(64000) | 存储可变长度的长文本,(2^30)-1=1073741823个字符(2GB字符数据) | |
| Binary类型 | bit | char(1) | 允许 0 1 null |
| image | 存储图片为二进制数据,最多2GB | ||
| Number类型 | tinyint | smallint | 占用1个字节,可表示范围: 0~255之间的整数 |
| smallint | smallint | 占用2个字节,可表示范围: (-215~215)-1之间的整数(-32767 到 32768) | |
| int | integer | 占用4个字节,可表示范围: (-231~231)-1之间的整数(-2,147,483,648 到 2,147,483,647) | |
| bigint | float | 占用8个字节,可表示范围: (-263~263)-1之间的整数(-9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 ) | |
| decimal(m,n) | decimal(m,n) | (-1038~1038)-1之间的固定精度和小数位的数字 | |
| numeric(m) | decimal(m,0) | 功能等同于decimal | |
| numeric(m,n) | decimal(m,n) | ||
| float | float | 从-1.79E+3081.79E+308的浮动精度数字数据。参数n指示该字段保存4字节还是8字节。 | |
| float(24) | float | 保存4字节,而float(53)保存8字节,n的默认值是53 | |
| money | 介于 -922,337,203,685,477.5808 和 922,337,203,685,477.5807 之间的货币数据 | ||
| real | 从-3.40E+38到3.40E+38的浮动精度数字数据 | ||
| Date类型 | datetime | Timestamp(6) | 从 1753 年 1 月 1 日 到 9999 年 12 月 31 日,精度为 3.33 毫秒 |
| datetime2 | Timestamp(6) | 从 1753 年 1 月 1 日 到 9999 年 12 月 31 日,精度为 100 纳秒 | |
| smalldatetime | Timestamp(6) | 从 1900 年 1 月 1 日 到 2079 年 6 月 6 日,精度为 1 分钟 | |
| date | Timestamp(6) | 仅存储日期,从 0001 年 1 月 1 日 到 9999 年 12 月 31 日 | |
| time | Timestamp(6) | 仅存储时间,精度为 100 纳秒 | |
| timestamp | Timestamp(6) | 存储唯一的数字,每当创建或修改某行时,该数字会更新 | |
| timestamp | Timestamp(6) | 基于内部时钟,不对应真实时间。每个表只能有一个 timestamp变量 |
-
Unicode字符串
1.有var前缀的,表示是实际存储空间是变长的,varchar,nvarchar
所谓定长就是长度固定的,当输入的数据长度没有达到指定的长度时将自动以英文空格在其后面填充,使长度达到相应的长度;而变长字符数据则不会以空格填充,比较例外的是,text存储的也是可变长。
2.n表示Unicode字符,即所有字符都占两个字节,nchar,nvarchar
字符中,英文字符只需要一个字节存储就足够了,但汉字众多,需要两个字节存储,英文与汉字同时存在时容易造成混乱,Unicode字符集就是为了解决字符集这种不兼容的问题而产生的,它所有的字符都用两个字节表示,即英文字符也是用两个字节表示。
3.基于以上两点来看看字段容量
char,varchar 最多8000个英文,4000个汉字
nchar,nvarchar 可存储4000个字符,无论英文还是汉字
4.使用(个人偏好)
a.如果数据量非常大,又能100%确定长度且保存只是ansi字符,那么char
b.能确定长度又不一定是ansi字符或者,那么用nchar;
c.对于超大数据,如文章内容,使用nText
d.其他的通用nvarchar -
tinyint
tinyint 型的字段如果设置为 unsigned (无符号)类型,只能存储从0到255的整数,不能用来储存负数。
tinyint 型的字段如果不设置 unsigned (无符号)类型,存储-128到127的整数。
2.2 Oracle数据类型
| Oracle | Teradata | 备注 |
|---|---|---|
| char(n) | char(n) | 定长字符串,n字节长,如果不指定长度,缺省为1个字节长(一个汉字为2字节) |
| varchar2(n) | varchar(n) | 可变长的字符串,具体定义时指明最大长度n |
| number(m) | Decimal(m,0) | 可变长的数值列,允许0、正值及负值,m是所有有效数字的位数,n是小数点以后的位数。 |
| number(m,n) | Decimal(m,n) | 可变长的数值列,允许0、正值及负值,m是所有有效数字的位数,n是小数点以后的位数。 |
| date | Timestamp(6) | 从公元前4712年1月1日到公元4712年12月31日的所有合法日期, |
| CLOB | 即字符型大型对象(Character Large Object),则与字符集相关,适于存贮文本型的数据(如历史档案、大部头著作等)。 |
-
varchar2(n)
可变长的字符串,具体定义时指明最大长度n,
这种数据类型可以放数字、字母以及ASCII码字符集(或者EBCDIC等数据库系统接受的字符集标准)中的所有符号。
如果数据长度没有达到最大值n,Oracle 8i会根据数据大小自动调节字段长度,
如果你的数据前后有空格,Oracle 8i会自动将其删去。VARCHAR2是最常用的数据类型。
可做索引的最大长度3209。 -
number(m) / number(m,n)
可变长的数值列,允许0、正值及负值,m是所有有效数字的位数,n是小数点以后的位数。
如:number(5,2),则这个字段的最大值是99,999,如果数值超出了位数限制就会被截取多余的位数。
如:number(5,2),但在一行数据中的这个字段输入575.316,则真正保存到字段中的数值是575.32。
如:number(3,0),输入575.316,真正保存的数据是575。 -
date
从公元前4712年1月1日到公元4712年12月31日的所有合法日期,
Oracle 8i其实在内部是按7个字节来保存日期数据,在定义中还包括小时、分、秒。
缺省格式为DD-MON-YY,如07-11月-00 表示2000年11月7日。 -
CLOB
即字符型大型对象(Character Large Object),则与字符集相关,适于存贮文本型的数据(如历史档案、大部头著作等)。
三. 获取表结构信息
Q2:如何获取标准字段类型,以及数据类型如何转换
通过直接查询SQLServer系统表,获取表结构
USE his ; --使用 his 库
SELECT
CASE
WHEN col.colorder=1
THEN obj.name
ELSE obj.name
END AS 表名,
ROW_NUMBER() OVER(PARTITION BY obj.name ORDER BY col.colorder) AS 序号,
col.name AS 列名,
t.name AS 数据类型,
cast(col.length AS varchar(80)) AS 长度 ,
cast(col.xprec AS varchar(80)) AS 精度 ,
cast(isnull(columnproperty(col.id,col.name,'Scale'),0)AS varchar(20)) AS 标度 ,
CASE
--字符类型 转换逻辑 => 数据类型 + (长度)
WHEN t.name IN ('char','varchar','text','nchar','nvarchar','ntext')
THEN UPPER(t.name + '(' + cast(col.length AS varchar(80)) +')')
--二进制类型 转换逻辑 => CHAR(1)
WHEN t.name IN ('bit')
THEN 'CHAR(1)'
--数字类型 int转换逻辑 => INTEGER
WHEN t.name IN ('int')
THEN 'INTEGER'
--数字类型 转换逻辑 => 数据类型 + (精度,标度)
WHEN t.name IN ('tinyint','smallint','bigint','float','money','real','decimal','numeric')
THEN UPPER('DECIMAL' + '(' + cast(col.xprec AS varchar(80)) +',' + cast(isnull(columnproperty(col.id,col.name,'Scale'),0)AS varchar(20))+')')
--时间类型转换逻辑 => TIMESTAMP(6)
WHEN t.name IN ('datetime','datetime2','smalldatetime','date','time','timestamp')
THEN 'TIMESTAMP(6)'
ELSE NULL
END AS 测试合并,
CASE
WHEN EXISTS (
SELECT
1
FROM dbo.sysindexes si --sysindexes:数据库中的每个索引和表在表中各占一行。
INNER JOIN dbo.sysindexkeys sik ON si.id=sik.id AND si.indid =sik.indid
INNER JOIN dbo.syscolumns sc ON sc.id=sik.id AND sc.colid=sik.colid
INNER JOIN dbo.sysobjects so ON so.name=si.name AND so.xtype='PK'
WHERE sc.id=col.id AND sc.colid=col.colid
)
THEN 'Y'
ELSE ''
END AS 是否主键
FROM dbo.syscolumns col --syscolumns 当前数据库的所有字段信息,名称,类型,长度等
LEFT JOIN dbo.systypes t --systypes 系统的字段表,保存当前数据库中的所有数据类型,包含系统提供数据类型和用户定义数据类型
ON col.xtype=t.xusertype
INNER JOIN dbo.sysobjects obj --sysobjects:在数据库内创建的每个对象(约束、默认值、日志、规则、存储过程等)在表中占一行。
ON col.id =obj.id AND obj.xtype ='U' AND obj.status>=0
/*--以下SQL没有使用,暂时注释
LEFT JOIN dbo.syscomments comm --syscomments: 可以用来查找所有关于库中用到的某个关键词的所有相关脚本
ON col.cdefault=comm.id
LEFT JOIN sys.extended_properties ep --extended_properties: 针对当前数据库中的每个扩展属性返回一行。
ON col.id=ep.major_id AND col.colid=ep.minor_id AND ep.name=''*/
WHERE obj.name IN ('h_ofpreorder')
ORDER BY 表名 , col.colorder ;
SQL查询结果(这里直接转换成数据仓库S层需要的数据类型了)
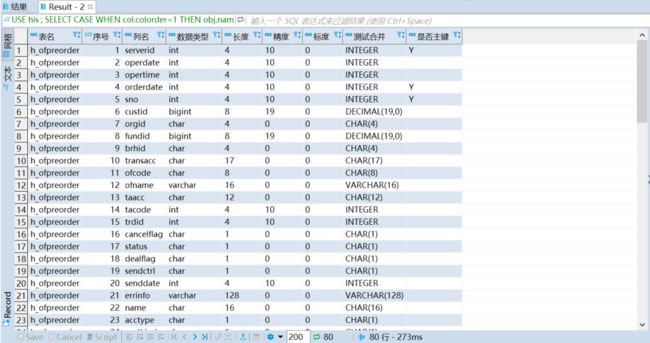
对比使用DBeaver查看表结构
F 附录
- 数据库的用户表列表:
sys.sysobjects
sys.tables
INFORMATION_SCHEMA.TABLES - 表的字段名:
sys.syscolumns
sys.columns
INFORMATION_SCHEMA.COLUMNS - 字段类型:
sys.syscolumns(加上sys.systypes)
sys.columns(加上sys.types)
INFORMATION_SCHEMA.COLUMNS - 字段长度:
sys.syscolumns
sys.columns
INFORMATION_SCHEMA.COLUMNS - 字段描述:
sys.extended_properties - 是否允许为空:
sys.syscolumns
sys.columns
INFORMATION_SCHEMA.COLUMNS - 是否为主键:
sys.sysobjects(加上sys.sysindexes和sys.sysindexkeys)
sys.indexes(加上sys.index_columns)
INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE
注:括号中的表都是需要他们联合才能拿到需要的信息的。
比如sys.sysobjects没有与字段id建立关系,所以才加上sys.sysindexes和sys.sysindexkeys这两张表做桥梁来建立关系
F.1 表字段syscolumns 字典
From 2.数据库表syscolumns 各个字段含义
| 列名 | 数据类型 | 描述 |
|---|---|---|
| name | sysname | 列名或过程参数的名称。 |
| id | int | 该列所属的表对象 ID,或与该参数关联的存储过程 ID。 |
| xtype | tinyint | systypes 中的物理存储类型。 |
| typestat | tinyint | 仅限内部使用。 |
| xusertype | smallint | 扩展的用户定义数据类型 ID。 |
| length | smallint | systypes 中的最大物理存储长度。 |
| xprec | tinyint | 仅限内部使用。 |
| xscale | tinyint | 仅限内部使用。 |
| colid | smallint | 列或参数 ID。 |
| xoffset | smallint | 仅限内部使用。 |
| bitpos | tinyint | 仅限内部使用。 |
| reserved | tinyint | 仅限内部使用。 |
| colstat | smallint | 仅限内部使用。 |
| cdefault | int | 该列的默认值 ID。 |
| domain | int | 该列的规则或 CHECK 约束 ID。 |
| number | smallint | 过程分组时(0 表示非过程项)的子过程号。 |
| colorder | smallint | 仅限内部使用。 |
| autoval | varbinary(255) | 仅限内部使用。 |
| offset | smallint | 该列所在行的偏移量;如果为负,表示可变长度行。 |
| status | tinyint | 用于描述列或参数属性的位图:0x08 = 列允许空值。 0x10 = 当添加 varchar 或 varbinary列时,ANSI 填充生效。保留 varchar 列的尾随空格,保留 varbinary 列的尾随零。 x40 = 参数为 OUTPUT 参数。 0x80 = 列为标识列。 |
| type | tinyint | systypes 中的物理存储类型。 |
| usertype | smallint | systypes 中的用户定义数据类型 ID。 |
| printfmt | varchar(255) | 仅限内部使用。 |
| prec | smallint | 该列的精度级别。 |
| scale | int | 该列的小数位数。 |
| iscomputed | int | 表示是否已计算该列的标志: 0 = 未计算。 1 = 已计算。 |
| isoutparam | int | 表示该过程参数是否是输出参数: 0 = 假。 1 = 真。 |
| isnullable | int | 表示该列是否允许空值: 0 = 假。 1 = 真。 |
参考文章
1.Sql server查询表结构(字段名,数据类型,长度,描述,是否允许为空,是否为主键)
2.数据库表syscolumns 各个字段含义
20/06/22
M