ISCC2022 擂台misc
文章目录
-
-
- 666
- 扫!
- 弱雪
- 真扫
- 黑暗森林
- PNGstego
- 这是压缩包吗?
- 小 数
-
学习了
666
考查知识点:伪加密、猜谜的steghide弱口令爆破、流量分析、gif帧、键盘密码、AES
下载下来是一个压缩包,但是图片显示需要密码,010查看后发现源文件目录区的全局方式位标记为00 09 ,而源文件数据区的全局加密位为00 00,考虑zip伪加密
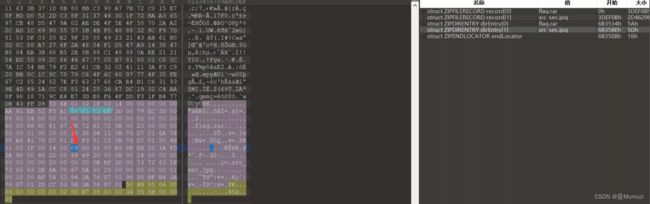
将09改成00后保存即可正常解压
下载下来是给了一张图片和一个压缩包,压缩包带有密码,尝试多种可能的爆破之后并没有结果,因此猜测jpg图片本身就是需要使用软件进行隐写解密。
在尝试后发现,能使用steghide对图片进行解密,密码为弱口令123456
下载下来,根据附件名字为high.png,猜测需要修改图片高度
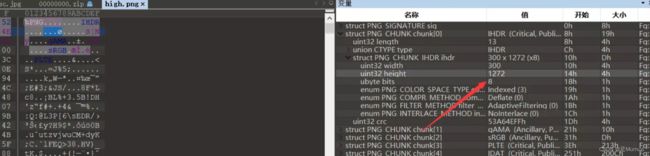

得到压缩包密码!@#$%678()_+
这里对协议分级,发现只有UDP和TCP协议,其中UDP协议无其他信息,因此主要查看TCP协议内容,一层层看
当查看到流17时,发现上传了一个666.txt和一张gif,上传到了cnblog,这里直接访问网站,因为传输的gif不完整。将网站上的gif下载下来https://www.cnblogs.com/konglingdi/p/14998301.html
看第6 16 26帧
SE1ERWt1eTo4NTIgOTg3NDU2MzIxIDk4NDIzIFJFQUxrZXk6eFN4eA==
pQLKpP/
EPmw301eZRzuYvQ==
第一段解码,得到HMDEkuy:852 987456321 98423 REALkey:xSxx
这里数字部分查看小键盘,正好组成ISCC,而且后面的REALkey指的也正好是ISCC
使用AES在线网站解密
http://tool.chacuo.net/cryptaes
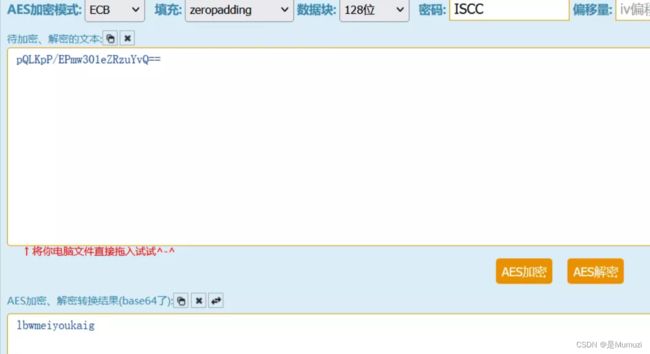
ISCC{lbwmeiyoukaig}
扫!
考查知识点:QR CODE的mask pattern、Rar4伪加密(带非预期)、ImageIN
氪金测试(?
首先直接解压,能解压出3w+的文件夹和8w+的二维码
![]()
随便进入一个文件夹,如0,发现下面有三个文件,尝试分别扫描
结果分别是no_flag no_flag flag_where?
全部扫描后去重,即可将8种内容全部得到,为['flag_not_here','no_flag','flag{fake_flag}','whereisflag','
And then,可以计算一下有多少种不同的二维码,这一步是当天就有师傅做了的,有64种。
继续看第0个文件夹能够发现这三张二维码一共使用了两种不同的mask pattern,但都是L模式
怎么说呢,一共8种内容,正好64/8=8,也正好说明使用了8种mask pattern


这三张的pattern根据1.png 2.png 3.png的顺序进行排序,分别为1 2 2
pattern的范围为0-7,正好每个文件夹下只有最多3张二维码,将122从8进制转到ascii之后,能得到字符’R’
多转换几个之后,发现正好是rar的文件头Rar
因此编写一个脚本,取所有的pattern并转换成16进制后写入文件
from PIL import Image
from tqdm import tqdm
import os
f = open('output.rar','w+')
pattern = ['001000111','110011111','010101101','101110101','111101100','000110100','100000110','011011110']
for i in tqdm(range(31091)):
path = f'./challs/{str(i)}/'
file_list = os.listdir(path)
this_bit = ''
for j in file_list:
img = Image.open(f'{path}{j}')
tmp = ''
for k in range(9):
if(img.getpixel((8,k)) == 0):
tmp += '1'
else:
tmp += '0'
ind = pattern.index(tmp)
this_bit += str(ind)
this_bit = hex(int(this_bit,8))[2:].zfill(2)
f.write(this_bit)
# print(chr(int(this_bit,16)))
okey,此时得到了他的hex数后,使用cyberchef或notepad++草convert功能进行转换,即可得到一个rar

直接打开此rar,发现需要密码,可是刚刚明明没有得到密码呢?
用010查看,发现该rar为rar4,而且没有报错,难道是真加密吗?
这里查看一下加密位,发现虽然需要密码,但并没有加密
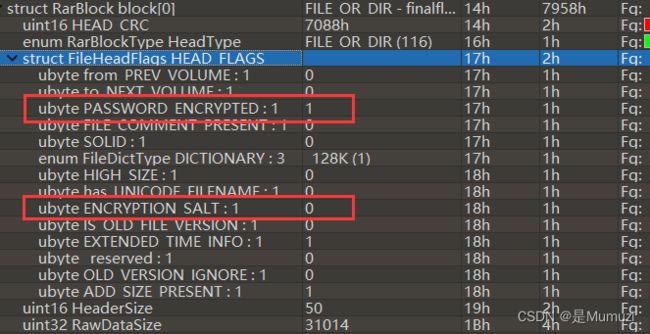
因此猜测为伪加密,将上面的1改成0后,save,再f5刷新一下,提示crc错误

将7088改成5b5d

即可正常解压,为什么要加粗呢,是应该用winrar等软件,在输入密码的时候直接按确定,也可以直接解压。算是非预期吧,Tokeii发现的,我只用360所以没发现。
解压出来后是一张logo,文件尾有一串base64,解码
flag{this_is_flag?}
Maybe SomeThing IN it!
这里提示有东西在里面,虽然使用stegsolve查看通道确实有问题,但是并找不到问题在哪,结合常见的隐写工具和解码出来的提示,最后锁定ImageIN,直接将该软件放进去即可获得flag

flag{S0_Many_qR}
希望没人懂这个FLAG的含义
enc_qr.py:
import qrcode
import os
import random
from tqdm import tqdm
table = ['flag_not_here','no_flag','flag{fake_flag}','whereisflag','' ,'flag_where?','flag_other_file','flag_zipped']
def gen_qr(pattern,infos,out):
qr = qrcode.QRCode(
version=2,
error_correction=qrcode.constants.ERROR_CORRECT_L,
box_size=1,
border=0,
mask_pattern=pattern
)
qr.add_data(infos)
qr.make(fit=True)
img = qr.make_image()
img.save(out)
f = open('finalflag.rar','rb').read()
for i in tqdm(range(len(f))):
infomations = oct(f[i])[2:]
os.mkdir(f'./challs/{str(i)}')
for j in range(len(infomations)):
infos = table[random.randint(0,7)]
out_path = f'./challs/{str(i)}/{str(j+1)}.png'
gen_qr(int(infomations[j]),infos,out_path)
print('done~')
弱雪
考查知识点:时间戳隐写、SNOW弱口令爆破
拿到附件之后,能发现有1936个txt文件,去除以8发现能被整除,猜测2进制。
每个txt中都带有一个很像base64的字符串,尝试解码都无法解出像样的明文
用010打开看一下zip包,发现时间各不相同

这里猜测了一波模二,但是在提取时间戳的时候发现不对。
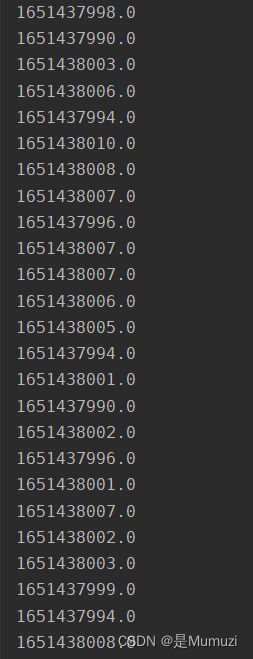
在提取时间戳之前,首先判断了ctime和mtime是否相等,因为可能考虑到两者之差,判断之后发现完全相等,因此去除这个思路,在研究的时候发现ctime都在1651438000上下波动,这里把小于1651438000的当做0,大于的当做1,发现开头正好是7z,因此编写一个脚本
import os
from tqdm import tqdm
path = './Misc-2022.05.05/'
n = 1936
f = open('outfile.txt','w+')
for i in range(n):
# ctime = os.path.getctime(f'{path}{str(i)}.txt')
# mtime = os.path.getmtime(f'{path}{str(i)}.txt')
# if(ctime != mtime):
# print(i)
ctime = os.path.getctime(f'{path}{str(i)}.txt')
print(ctime)
if(int(ctime) < 1651438000):
f.write('0')
else:
f.write('1')
然后用cyberchef转换

得到一个snow.txt,很明显的SNOW隐写,这里尝试了空密码,显示residual of 3 bits not uncompressed。结合题目弱雪,猜测需要近进行爆破,这里拿出祖传弱口令(大概7k),当然这里差不多去github下载一个1000弱口令就行了
然后爆破
import os
from tqdm import tqdm
f = open('password.txt','r').read().splitlines()
for i in tqdm(f):
try:
os.system(f'SNOW.EXE -p {i} -C snow.txt > testflag.txt')
f1 = open('testflag.txt','r').read()
if('flag' in f1):
print(f1)
except:
pass
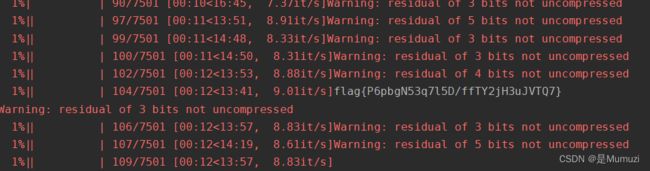
flag{P6pbgN53q7l5D/ffTY2jH3uJVTQ7}
真扫
这里还没上题之前给主办发过一个新描述但是没看到
![]() 考查知识点:CODE39与CODE128(2进制)、根据附件名字只含01A-Z提取二维码,需要注意的是CODE39在最后会加上一位校验码,在写脚本的时候需要删掉
考查知识点:CODE39与CODE128(2进制)、根据附件名字只含01A-Z提取二维码,需要注意的是CODE39在最后会加上一位校验码,在写脚本的时候需要删掉
首先拿到一堆条形码

怪了捏,高矮不一样捏
稍微看了一下,能够看到一个start.png,猜测从这里开始
扫一下看看

就和内容一样,说明肯定不是单纯的扫
然后刚开始就很明显的看到了,条形码种类不一样的
比如这张显示CODE39,而再扫一张

通过扫描前8张,如果把CODE39当0 CODE128当1,能够发现是R
首先是如何进行正确的扫描,根据提示说明从start.png开始,扫描出来发现内容即start.png上写好的内容,为JAYZF1UF。查看一下文件能够发现有个文件叫JAYZF1U.png,至于为什么start.png扫描出来的最后会多出一个F,是因为CODE39条形码会在最后生成一个check digit,其计算方式是条形码各字符的数值相加模43取余,因此会多出一个字符。事实上为了降低难度所有的内容都是用的7个字符,所以如果扫出来是8个字符,需要去掉最后一个字符,脚本里也写到了这一点
上图为zxing扫描结果,后续都是用pyzbar,pyzbar yyds
好,又是Rar。那就写个脚本吧(
在放脚本之前,先说后面那步
咱打开那个Rar,一看需要密码,那么密码一定在这些文件当中吧
仔细一看,原来文件名当中,有1有0(只有01A-Z),如果提取出来,正好625个,二维码也正好是25*25
01字符转换图像脚本如下
from PIL import Image
pic = Image.new('RGB',(25,25),(255,255,255))
f = open('passwd.txt','r').read()
for i in range(len(f)):
if(f[i] == '1'):
pic.putpixel((i%25,i//25),(0,0,0))
pic.show()
当然要注意,文件名长度全是7,而内容有的是8有的是7,所以如果是8的时候,需要把最后一位去掉,此为干扰数据,是生成时自己出来的
将其01串转成二维码一扫
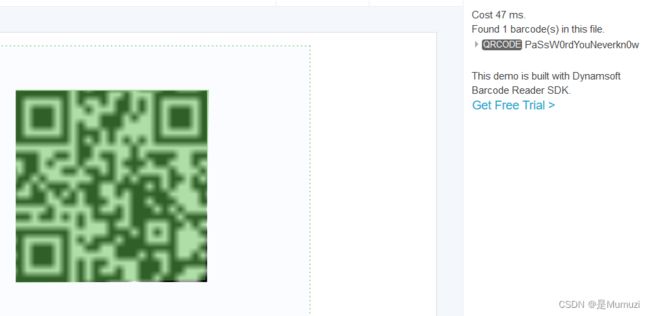
PaSsW0rdYouNeverkn0w
打开就是flag
ISCC{c0de39&c0de128awa}
解题脚本:
import pyzbar.pyzbar as pyzbar
from PIL import Image
name = 'start'
files = open('outfile.txt','a')
passwd = open('ps.txt','a')
while 1:
image = f'./chall/{name}.png'
img = Image.open(image)
texts = pyzbar.decode(img)
print(texts)
for text in texts:
if ('CODE' not in text[1]):
files.close()
passwd.close()
exit(1)
if (text[1] == 'CODE39'):
files.write('0')
else:
files.write('1')
name = text[0].decode()
if (len(name) == 8):
name = name[:-1]
if ('0' in name):
passwd.write('0')
elif ('1' in name):
passwd.write('1')
gen_barcode:
import barcode
from barcode.writer import ImageWriter
import random
import string
table = string.ascii_uppercase
CODE128 = barcode.get_barcode_class('code128') #1
CODE39 = barcode.get_barcode_class('code39') #0
from tqdm import tqdm
filename = 'start'
flag = open('binflag.txt','r').read()
password = open('passwd.txt','r').read()
for i in tqdm(range(len(flag))):
if(i < len(password)):
text = ''.join(random.sample(table,6))
r = random.randint(0,5)
text = text[:r] + password[i] + text[r:]
if(flag[i] == '1'):
ena1 = CODE128(text,writer=ImageWriter())
fullname = ena1.save(f'./chall/{filename}')
filename = text
else:
ena2 = CODE39(text, writer=ImageWriter())
fullname = ena2.save(f'./chall/{filename}')
filename = text
else:
text = ''.join(random.sample(table,7))
if(flag[i] == '1'):
ena1 = CODE128(text,writer=ImageWriter())
fullname = ena1.save(f'./chall/{filename}')
filename = text
else:
ena2 = CODE39(text, writer=ImageWriter())
fullname = ena2.save(f'./chall/{filename}')
filename = text
黑暗森林
考查知识点:bmp reserverd、apng、rar结构、信息收集
这些bmp图片,直接扫描是一堆base64串,需要找到相应的顺序
010打开后发现,bfreserverd1都是存在值的,而通常这两保留字段都应该是0
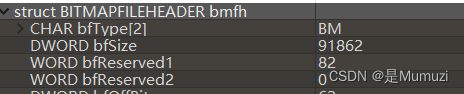
排个序看看
import os
dir = os.listdir('./universe')
lists = []
for i in dir:
file = f'./universe/{i}'
ind = open(file, 'rb').read()[6]
lists.append(ind)
lists.sort()
print(lists)
输出[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100]
没毛病,那么写个脚本拼起来,然后写入文件,看了一下是rar头,于是得到以下脚本
import os
import pyzbar.pyzbar as pyzbar
from PIL import Image
from tqdm import tqdm
import base64
dir = os.listdir('./universe')
lists = ['']*100
for i in tqdm(dir):
file = f'./universe/{i}'
img = Image.open(file)
texts = pyzbar.decode(img)
for text in texts:
ind = open(file,'rb').read()[6]
lists[ind-1] = text[0].decode()
out = ''.join(lists)
# print(out)
f = open('flag.rar','wb').write(base64.b64decode(out.encode()))
然后对于png图片的处理,放010很明显看出来是apng

于是用apngdis_gui进行分离,得到一堆图片

文件不多,就不ocr了,直接手撸,得到数字
table = [21,42,47,50,53,71,72,73,88,113,118,125,128,148,150,158,161,162,166,167,176,190,194,206,223,236,239,266,269,270,274,289,290,302,305,308,316,318,326,328,329,360,375,392,395,414,425,443,450,463,469,471,477,487,494,498,514,519,522,523,527,531,540,555,561,574,589,627,629,636,637,654,668,673,689,690,704,736,751,752,753,763,765,769,774,780,801,814,817,858,870,899,915,928,934,948,951,964,967,982]
然后rar,直接放010是报错的,删了一下第21字节,发现模板能识别的更多了,于是删除以上的100个字节,脚本如下
table = [21,42,47,50,53,71,72,73,88,113,118,125,128,148,150,158,161,162,166,167,176,190,194,206,223,236,239,266,269,270,274,289,290,302,305,308,316,318,326,328,329,360,375,392,395,414,425,443,450,463,469,471,477,487,494,498,514,519,522,523,527,531,540,555,561,574,589,627,629,636,637,654,668,673,689,690,704,736,751,752,753,763,765,769,774,780,801,814,817,858,870,899,915,928,934,948,951,964,967,982]
f1 = open('flag.rar','rb').read()
f2 = open('outflag.rar','wb+')
tmp = f1[:1000]
tmp = list(tmp)
tmp_list = []
for j in range(1000):
if(j not in table):
tmp_list.append(tmp[j])
f2.write(bytearray(tmp_list))
f2.write(f1[1000:])
打开修好的rar,发现还需要密码,谷歌搜到密码,百度不行
civilization

ISCC{7he_Dark3st_F0rest}
PNGstego
考查知识点:弱口令爆破、Adam7、LSB、7bit
首先打开out.zip,发现需要密码

需要爆破,长度5位且包含小写字母和数字,271毫秒得到密码为adam7
解压得到一张图片,如果用stegsolve观察能够发现明显的LSB
![]()
但是直接提取最上面并不能发现有什么,而且往后拉能发现一句话
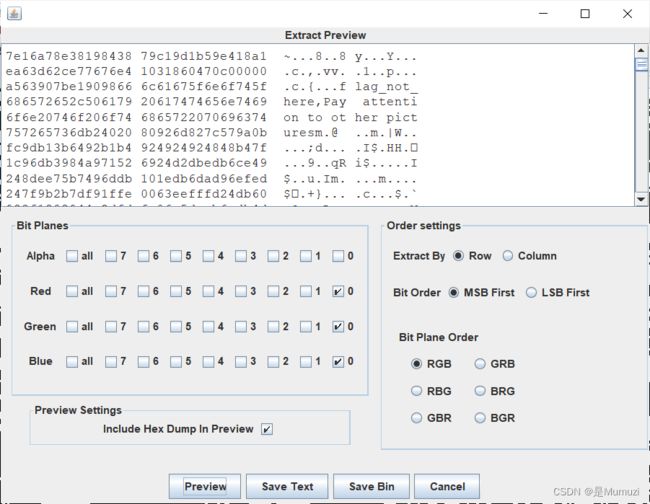
好,这里题目说了葫芦娃、压缩包密码Adam7

因此该图片很明显,有两种做法
一是因为图片本身就是Adam7扫描的图片,完全可以通过提取IDAT块的数据,将其先zlib inflate后,将7张图片的数据分别写入7个图片文件(先把图片改成Adam7图)。
二是直接通过PIL库或cv2+numpy库,按照官方给出的格式,提取出7张图片。
用第二种方法,主要在这里
for i in tqdm(range(7)):
w_tmp = (w-1-list[i][0])//list[i][2] + 1
h_tmp = (h-1-list[i][1])//list[i][3] + 1
print(w_tmp,h_tmp)
img = Image.new(type,(w_tmp,h_tmp))
for j in range(h_tmp):
for k in range(w_tmp):
pixel = pic.getpixel((list[i][0]+k*list[i][2],list[i][1]+j*list[i][3]))
img.putpixel((k,j),pixel)
img.save(f'{tmppath}{filename[:-4]}_{str(i)}.png')
得到7张小图之后,因为之前已经知道是LSB,因此直接看LSB,在第out_4.png中发现一个压缩包带有信息


7bits
f = open('music.txt','r').read().splitlines()
for i in f:
tmp = ''
for j in i:
if(j == 'x'):
tmp += '0'
else:
tmp += '1'
print(chr(int(tmp,2)),end='')
#ISCC{Adam7_so_ez_and_music_2}
这是压缩包吗?
考查知识点:猫脸、bmp位深、文件分离
直接解压能得到o!.txt和key.bmp
文件尾有一个bmp,分离出来如下

放进010中发现该图片的位深是16,改成24之后能得到正常显示的图片

放进stegsolve,发现b0通道存在问题

根据o!.txt
RGB?
abn!
猜测RGB 分别对应猫脸中的a b n
问题出在,怎么排列组合key.bmp的值都弄不出来
包括 xy yx xy[::-1] yx[::-1] 对同一张图进行25次变换,对同一张图分别进行25次变换、x[::-1]y x[::-1]y[::-1] y[::-1]x y[::-1]x[::-1],都不行
但是如果只进行一次变换,有几张图其实看着非常像
其实当时在想出题人会不会用的是知乎上的那个脚本,那个脚本虽然有shuf的次数n,但是并没有真正的进行shuf,所以爆破了一波256*256
5-127的时候得到一张能看的清楚的

ISCC{The_less_files_the_better}
11
小 数
考查知识点:zip、rar套娃解压转01、emoji-aes(AES)爆破、base45
看文件尾能够发现一个提示和一堆PK头,很明显这个7z是一个zip的压缩包且把文件头改成了00,因此改回来

在手动解压过程中,发现存在zip和rar,而且解压出最后的文件之后并没有得到flag,因此猜测和zip与rar有关,因此写个脚本把rar和zip转成0和1也对应下来,脚本如下,需要注意的是环境变量中需要有winrar在program files目录下
把flag.7z改成flag
import rarfile
import os
flags = ''
while True:
os.rename('flag', 'flag1')
fs = open('flag1', 'rb').read()
if fs[:2] == b'PK':
zipf = zipfile.ZipFile('flag1', 'r')
zipf.extract('flag')
zipf.close()
os.remove('flag1')
flags += '0'
elif fs[:3] == b'Rar':
rarf = rarfile.RarFile('flag1', 'r')
rarf.extract('flag')
rarf.close()
os.remove('flag1')
flags += '1'
else:
s, rflag = '', ''
flags = flags[::-1]
for i in flag_bin:
s += i
if len(s) == 8:
rflag += chr(int(s, 2))
s = ''
fw = open('file', 'wb')
fw.write(rflag.encode('latin'))
报错之后,得到一个file文件,一看是rar头,改成file.rar
得到
secret in it!
❓❓⏩☺☺✅ℹ☀✖❓❓ℹ✅☂✖⏩⌨⌨☂ℹ☂
但是没有其他信息嘞,结合hint可以知道需要爆破,有三个地方都提醒是小写+数字这里就不细说了,脚本如下
脚本编写很简单,二十分钟就写完了(虽然重点部分是google找的,而且没考虑到rot)
然后根据 secret in it可以知道信息中带有secret,按此进行爆破
from tqdm import tqdm
from Crypto.Cipher import AES
import base64
from hashlib import md5
import string
import itertools
emojisInit = ["", "", "", "", "", "", "", "", "ℹ", "", "", "✉", "", "", "", "", "", "", "", "", "☂", "", "", "✖", "☀", "", "", "", "", "", "", "", "", "", "☃", "", "", "", "", "", "", "", "⌨", "", "", "", "", "", "", "", "❓", "⏩", "", "", "", "", "☺", "", "", "", "", "", "✅", "", ""]
table = string.ascii_lowercase+string.ascii_uppercase+string.digits+'+/='
table = list(table)
def unpad(data):
return data[:-(data[-1] if type(data[-1]) == int else ord(data[-1]))]
def bytes_to_key(data, salt, output=48):
# extended from https://gist.github.com/gsakkis/4546068
assert len(salt) == 8, len(salt)
data += salt
key = md5(data).digest()
final_key = key
while len(final_key) < output:
key = md5(key + data).digest()
final_key += key
return final_key[:output]
def decrypt(emo, passphrase):
#https://my.oschina.net/u/3021599/blog/3134709
bs64 = ''
for i in emo:
bs64 += table[emojisInit.index(i)]
encrypted = base64.b64decode(bs64)
assert encrypted[0:8] == b"Salted__"
salt = encrypted[8:16]
key_iv = bytes_to_key(passphrase, salt, 32+16)
key = key_iv[:32]
iv = key_iv[32:]
aes = AES.new(key, AES.MODE_CBC, iv)
return unpad(aes.decrypt(encrypted[16:]))
if __name__ == '__main__':
TABLE = string.ascii_lowercase+string.digits
emoji_enc = input('input your emoji_enc:')
for i in tqdm(itertools.product(''.join(i for i in TABLE), repeat= 4)):
passphrase = str(''.join(i)).encode('utf-8')
result = decrypt(emoji_enc,passphrase)
if(b'secret' in result):
print('text is :',result,'and key is :',passphrase)
text is : b’secret:V%66B7DY9W:6-8Z80H9ZM8-/5N+9RM81Y8T+9ES8+/5VA6PX8DY9PZANB8R6AEB8GM83ZA5IB’ and key is : b’x1a0’
V%66B7DY9W:6-8Z80H9ZM8-/5N+9RM81Y8T+9ES8+/5VA6PX8DY9PZANB8R6AEB8GM83ZA5IB很明显是base45
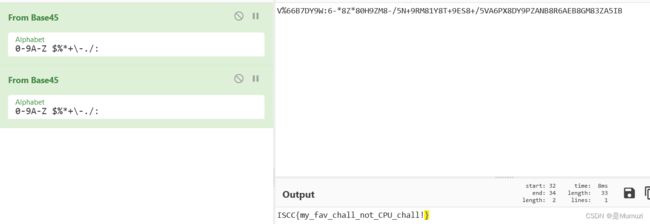
ISCC{my_fav_chall_not_CPU_chall!}