11种常见的时间序列预测方法
参考内容:4大类11种常见的时间序列预测方法总结和代码示例
代码地址:
https://github.com/SeafyLiang/machine_learning_study/blob/master/time_series
11种常见的时间序列预测方法
-
- 1、指数平滑Exponential Smoothing
- 2、Holt-Winters 法
- 3、自回归 (AR)
- 4、移动平均模型(MA)
- 5、自回归滑动平均模型 (ARMA)
- 6、差分整合移动平均自回归模型 (ARIMA)
- 7、季节性 ARIMA (SARIMA)
- 8、包含外生变量的SARIMA (SARIMAX)
- 9、向量自回归 (VAR)
- 10、向量自回归滑动平均模型 (VARMA)
- 11、包含外生变量的向量自回归滑动平均模型 (VARMAX)
- 总结
本篇文章将总结时间序列预测方法,并将所有方法分类介绍并提供相应的python代码示例,以下是本文将要介绍的方法列表:
1、使用平滑技术进行时间序列预测
- 指数平滑
- Holt-Winters 法
2、单变量时间序列预测
- 自回归 (AR)
- 移动平均模型 (MA)
- 自回归滑动平均模型 (ARMA)
- 差分整合移动平均自回归模型 (ARIMA)
- 季节性 ARIMA (SARIMA)
3、外生变量的时间序列预测
- 包含外生变量的SARIMAX (SARIMAX)
- 具有外生回归量的向量自回归移动平均 (VARMAX)
4、多元时间序列预测
- 向量自回归 (VAR)
- 向量自回归移动平均 (VARMA)
下面我们对上面的方法一一进行介绍,并给出python的代码示例
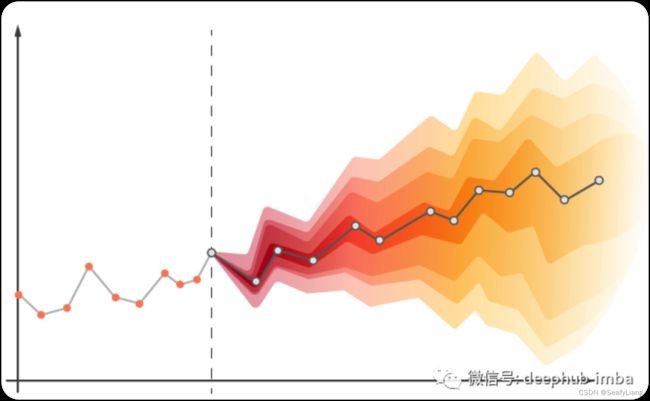
1、指数平滑Exponential Smoothing
指数平滑法是过去观测值的加权平均值,随着观测值变老,权重呈指数会衰减。换句话说,观察时间越近相关权重就越高。它可以快速生成可靠的预测,并且适用于广泛的时间序列。
简单指数平滑:此方法适用于预测没有明确趋势或季节性模式的单变量时间序列数据。简单指数平滑法将下一个时间步建模为先前时间步的观测值的指数加权线性函数。
它需要一个称为 alpha (a) 的参数,也称为平滑因子或平滑系数,它控制先前时间步长的观测值的影响呈指数衰减的速率,即控制权重减小的速率。a 通常设置为 0 和 1 之间的值。较大的值意味着模型主要关注最近的过去观察,而较小的值意味着在进行预测时会考虑更多的历史。简单指数平滑时间序列的简单数学解释如下所示:
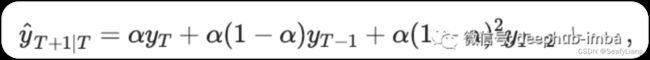
# SES
from statsmodels.tsa.holtwinters import SimpleExpSmoothing
from random import random
# contrived dataset
data = [x + random() for x in range(1, 100)]
# fit model
model = SimpleExpSmoothing(data)
model_fit = model.fit()
# make prediction
yhat = model_fit.predict(len(data), len(data))
print(yhat)
2、Holt-Winters 法
在 1957 年初,Holt扩展了简单的指数平滑法,使它可以预测具有趋势的数据。这种被称为 Holt 线性趋势的方法包括一个预测方程和两个平滑方程(一个用于水平,一个用于趋势)以及相应的平滑参数 α 和 β。后来为了避免趋势模式无限重复,引入了阻尼趋势法,当需要预测许多序列时,它被证明是非常成功和最受欢迎的单个方法。除了两个平滑参数之外,它还包括一个称为阻尼参数 φ 的附加参数。
一旦能够捕捉到趋势,Holt-Winters 法扩展了传统的Holt法来捕捉季节性。Holt-Winters 的季节性方法包括预测方程和三个平滑方程——一个用于水平,一个用于趋势,一个用于季节性分量,并具有相应的平滑参数 α、β 和 γ。
此方法有两种变体,它们在季节性成分的性质上有所不同。当季节变化在整个系列中大致恒定时,首选加法方法,而当季节变化与系列水平成比例变化时,首选乘法方法。
# HWES
from statsmodels.tsa.holtwinters import ExponentialSmoothing
from random import random
# contrived dataset
data = [x + random() for x in range(1, 100)]
# fit model
model = ExponentialSmoothing(data)
model_fit = model.fit()
# make prediction
yhat = model_fit.predict(len(data), len(data))
print(yhat)
3、自回归 (AR)
在 AR 模型中,我们使用变量过去值的线性组合来预测感兴趣的变量。术语自回归表明它是变量对自身的回归。AR模型的简单数学表示如下:
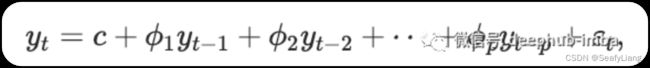
这里,εt 是白噪声。这类似于多元回归,但是使用 yt 的滞后值作为预测变量。我们将其称为 AR§ 模型,即 p 阶的自回归模型。
#AR
from statsmodels.tsa.ar_model import AutoReg
from random import random
# contrived dataset
data = [x + random() for x in range(1, 100)]
# fit model
model = AutoReg(data, lags=1)
model_fit = model.fit()
# make prediction
yhat = model_fit.predict(len(data), len(data))
print(yhat)
4、移动平均模型(MA)
与在回归中使用预测变量的过去值的 AR 模型不同,MA 模型在类似回归的模型中关注过去的预测误差或残差。MA模型的简单数学表示如下:

这里,εt 是白噪声。我们将其称为 MA(q) 模型,即 q 阶移动平均模型。
# MA
from statsmodels.tsa.arima.model import ARIMA
from random import random
# contrived dataset
data = [x + random() for x in range(1, 100)]
# fit model
model = ARIMA(data, order=(0, 0, 1))
model_fit = model.fit()
# make prediction
yhat = model_fit.predict(len(data), len(data))
print(yhat)
需要说明的是不应将这里说的移动平均线方法与计算时间序列的移动平均线混淆,因为两者是不同的概念。
5、自回归滑动平均模型 (ARMA)
在 AR 模型中,我们使用变量过去值与过去预测误差或残差的线性组合来预测感兴趣的变量。它结合了自回归 (AR) 和移动平均 (MA) 模型。
AR 部分涉及对变量自身的滞后(即过去)值进行回归。MA部分涉及将误差项建模为在过去不同时间同时发生的误差项的线性组合。模型的符号涉及将 AR§ 和 MA(q) 模型的顺序指定为 ARMA 函数的参数,例如 ARMA(p,q)。ARMA 模型的简单数学表示如下所示:
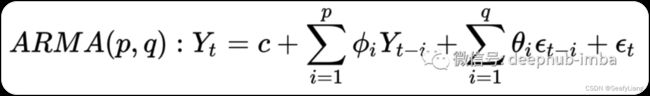
# ARMA
from statsmodels.tsa.arima.model import ARIMA
from random import random
# contrived dataset
data = [random() for x in range(1, 100)]
# fit model
model = ARIMA(data, order=(2, 0, 1))
model_fit = model.fit()
# make prediction
yhat = model_fit.predict(len(data), len(data))
print(yhat)
6、差分整合移动平均自回归模型 (ARIMA)
如果我们将差分与自回归和移动平均模型相结合,我们将获得 ARIMA 模型。ARIMA 是差分整合移动平均自回归模型Autoregressive Integrated Moving Average model 的首字母缩写。它结合了自回归 (AR) 和移动平均模型 (MA) 以及为了使序列平稳而对序列的差分预处理过程,这个过程称为积分(I)。ARIMA 模型的简单数学表示如下:
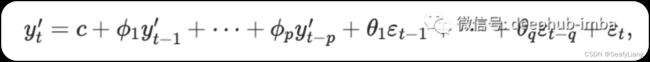
其中 y′t 是差分级数。右侧的“预测变量”包括滞后值和滞后误差。我们称之为 ARIMA(p,d,q) 模型。
这里,p 是自回归部分的阶数,d 是所涉及的一阶差分程度,q 是移动平均部分的阶数。
ACF 和 PACF 图在求 p 和 q 阶中的意义:
- 为了找到 AR§ 模型的阶 p:我们预计 ACF 图会逐渐减小,同时 PACF 在 p 显著滞后后会急剧下降或切断。
- 为了找到 MA(q) 模型的阶 p:我们预计 PACF 图将逐渐减小,同时 ACF 应该在某些 q 显著滞后后急剧下降或切断。
# ARIMA
from statsmodels.tsa.arima.model import ARIMA
from random import random
# contrived dataset
data = [x + random() for x in range(1, 100)]
# fit model
model = ARIMA(data, order=(1, 1, 1))
model_fit = model.fit()
# make prediction
yhat = model_fit.predict(len(data), len(data), typ='levels')
print(yhat)
7、季节性 ARIMA (SARIMA)
ARIMA 模型还能够对广泛的季节性数据进行建模。季节性 ARIMA 模型是通过在 ARIMA 模型中包含额外的季节性项来形成的。

这里,m = 每个时间季节的步数。我们对模型的季节性部分使用大写符号,对模型的非季节性部分使用小写符号。
它将 ARIMA 模型与在季节性数据级别执行相同的自回归、差分和移动平均建模的能力相结合。
# SARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from random import random
# contrived dataset
data = [x + random() for x in range(1, 100)]
# fit model
model = SARIMAX(data, order=(1, 1, 1), seasonal_order=(0, 0, 0, 0))
model_fit = model.fit(disp=False)
# make prediction
yhat = model_fit.predict(len(data), len(data))
print(yhat)
8、包含外生变量的SARIMA (SARIMAX)
SARIMAX 模型是传统 SARIMA 模型的扩展,包括外生变量的建模,是Seasonal Autoregressive Integrated Moving-Average with Exogenous Regressors 的缩写
外生变量是其值在模型之外确定并施加在模型上的变量。它们也被称为协变量。外生变量的观测值在每个时间步直接包含在模型中,并且与主要内生序列的使用不同的建模方式。
SARIMAX 方法也可用于通过包含外生变量来模拟具有外生变量的其他变化,例如 ARX、MAX、ARMAX 和 ARIMAX。
# SARIMAX
from statsmodels.tsa.statespace.sarimax import SARIMAX
from random import random
# contrived dataset
data1 = [x + random() for x in range(1, 100)]
data2 = [x + random() for x in range(101, 200)]
# fit model
model = SARIMAX(data1, exog=data2, order=(1, 1, 1), seasonal_order=(0, 0, 0, 0))
model_fit = model.fit(disp=False)
# make prediction
exog2 = [200 + random()]
yhat = model_fit.predict(len(data1), len(data1), exog=[exog2])
print(yhat)
9、向量自回归 (VAR)
VAR 模型是单变量自回归模型的推广,用于预测时间序列向量或多个并行时间序列,例如 多元时间序列。它是关于系统中每个变量的一个方程。
如果序列是平稳的,可以通过将 VAR 直接拟合到数据来预测它们(称为“VAR in levels”)。如果序列是非平稳的,我们会取数据的差异以使其平稳,然后拟合 VAR 模型(称为“VAR in differences”)。
我们将其称为 VAR§ 模型,即 p 阶向量自回归模型。
# VAR
from statsmodels.tsa.vector_ar.var_model import VAR
from random import random
# contrived dataset with dependency
data = list()
for i in range(100):
v1 = i + random()
v2 = v1 + random()
row = [v1, v2]
data.append(row)
# fit model
model = VAR(data)
model_fit = model.fit()
# make prediction
yhat = model_fit.forecast(model_fit.y, steps=1)
print(yhat)
10、向量自回归滑动平均模型 (VARMA)
VARMA 方法是 ARMA 对多个并行时间序列的推广,例如 多元时间序列。具有有限阶 MA 误差项的有限阶 VAR 过程称为 VARMA。
模型的公式将 AR§ 和 MA(q) 模型的阶数指定为 VARMA 函数的参数,例如 VARMA(p,q)。VARMA 模型也可用于VAR 或 VMA 模型。
# VARMA
from statsmodels.tsa.statespace.varmax import VARMAX
from random import random
# contrived dataset with dependency
data = list()
for i in range(100):
v1 = random()
v2 = v1 + random()
row = [v1, v2]
data.append(row)
# fit model
model = VARMAX(data, order=(1, 1))
model_fit = model.fit(disp=False)
# make prediction
yhat = model_fit.forecast()
print(yhat)
11、包含外生变量的向量自回归滑动平均模型 (VARMAX)
Vector Autoregression Moving-Average with Exogenous Regressors (VARMAX) 是 VARMA 模型的扩展,模型中还包含使用外生变量的建模。它是 ARMAX 方法对多个并行时间序列的推广,即 ARMAX 方法的多变量版本。
VARMAX 方法也可用于对包含外生变量的包含模型进行建模,例如 VARX 和 VMAX。
# VARMAX
from statsmodels.tsa.statespace.varmax import VARMAX
from random import random
# contrived dataset with dependency
data = list()
for i in range(100):
v1 = random()
v2 = v1 + random()
row = [v1, v2]
data.append(row)
data_exog = [x + random() for x in range(100)]
# fit model
model = VARMAX(data, exog=data_exog, order=(1, 1))
model_fit = model.fit(disp=False)
# make prediction
data_exog2 = [[100]]
yhat = model_fit.forecast(exog=data_exog2)
print(yhat)
总结
在这篇文章中,基本上覆盖了所有主要时间序列预测的问题。我们可以把上面提到的方法整理成以下几个重要的方向:
- AR:自回归
- MA:平均移动
- I:差分整合
- S:季节性
- V:向量(多维输入)
- X:外生变量
本文中提到的每种算法基本上都是这几种方法的组合,本文中已将每种的算法都进行了重点的描述和代码的演示,如果你想深入了解其中的知识请查看相关的论文。