超详细的进阶sql语句讲解
创建一个表学生表,字段有id(主键自增),name(学生姓名)
,class_id(班级id)
primary key = not null+unique
create table student(id int primary key auto_increment,name varchar(10),class_id int);
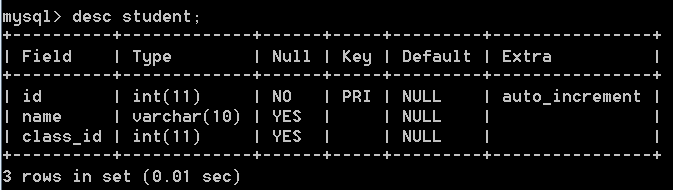
创建一个班级表,字段有id(主键自增),name(班级名称,默认为八三班)
create table class(id int primary key auto_increment,name varchar(10) default '八三班');
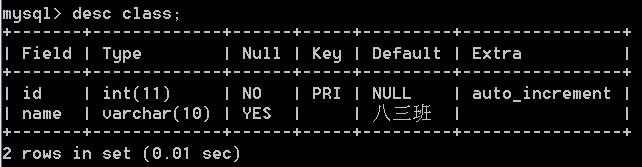
创建一个分数表,字段有id(主键自增),学生成绩sorce,学生id(stu_id)
create table sorce(id int primary key auto_increment,sorce double,stu_id int);
外键约束(foreign key)
drop table if exists student;
drop table if exists class;
创建一个班级表,字段有classId(主键自增),className(班级名称,默认为八三班)
create table class(classId int primary key auto_increment,className varchar(10) default '八三班');
创建一个学生表,字段有stu_id(主键自增),stu_name,class_Id(参考班级表的主键进行外键约束)
create table student(stu_id int primary key auto_increment,stu_name varchar(10),classId int, foreign key(classId) references class(classId));
外键约束带来的效果:
1.往学生表中插入的记录,班级id必须在班级表中存在
2.学生表指定的这个外键约束,必须是班级表的主键
3.外键约束建立好了之后,此时班级表中的班级id就不能随意修改或者删除了
--会报错
insert into student values(1,'张三',3);
当带有外键约束的数据要删除时,往往是借助逻辑上的删除而非物理上的删除。
insert的复杂语句
insert还可以搭配select语句进行使用
insert into student2 select * from student;
select 查询结果的列数和类型 + 顺序必须和待插入数据的表相匹配。
聚合查询:把若干行数据结合并起来
聚合查询往往需要搭配一些聚合函数来使用:count(),sum(),avg(),max(),min()
聚合查询的一个重要用法:分组查询group by
create table emp(id int primary key auto_increment,name varchar(20) not null,role varchar(20) not null,salary decimal(11,2));
insert into emp(name, role, salary) values
('马云','服务员', 1000.20),
('马化腾','游戏陪玩', 2000.99),
('孙悟空','游戏角色', 999.11),
('猪无能','游戏角色', 333.5),
('沙和尚','游戏角色', 700.33),
('隔壁老王','董事长', 12000.66);
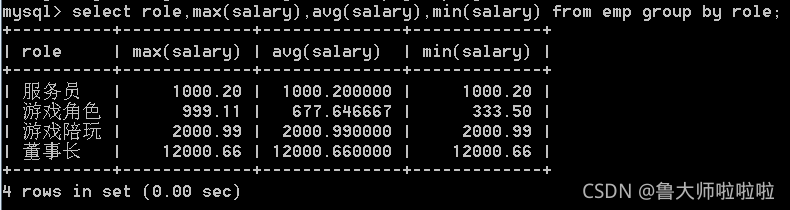
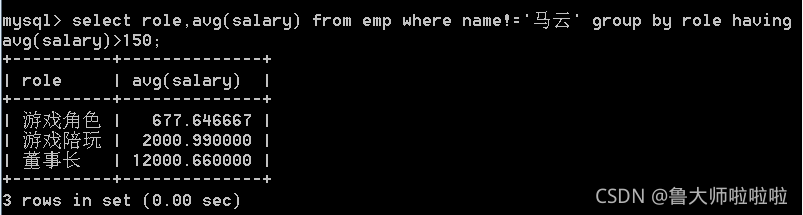
按照角色进行分组聚合,并计算各角色的平均工资,最高工资,最低工资
select role,max(salary),avg(salary),min(salary) from emp group by role;
针对聚合后的数据进行筛选,要使用having子句
select role,avg(salary) from emp where name!='马云' group by role having avg(salary)>150;
联合查询
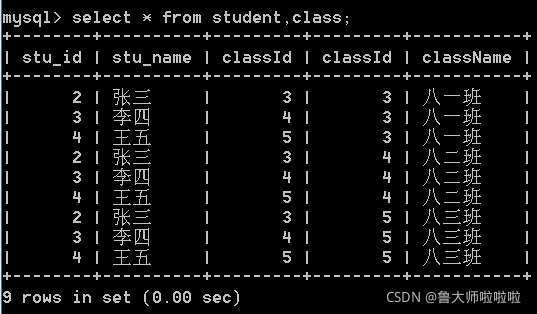
在sql中计算笛卡尔积主要有两种方式
1.select * from 表1,表2…;
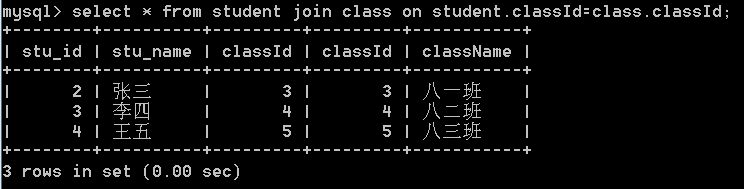
2.select * from 表1 join 表2 on 条件
内连接
外连接
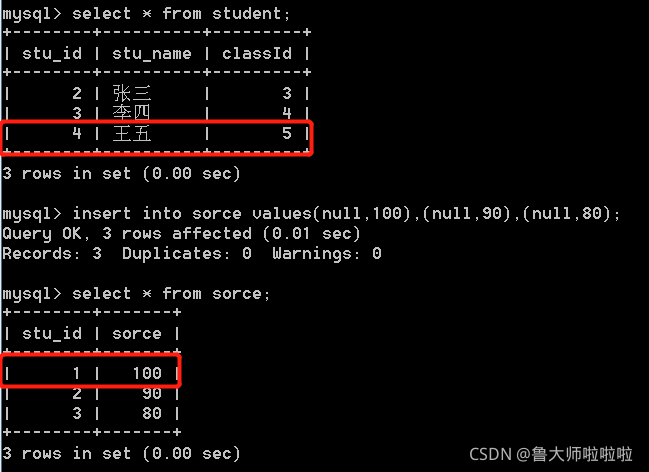
外连接和内连接的区别在于,对于“空值”的处理方式不同。此处的“空值”而是泛指两张表的数据对不上的情况。
内连接的情况
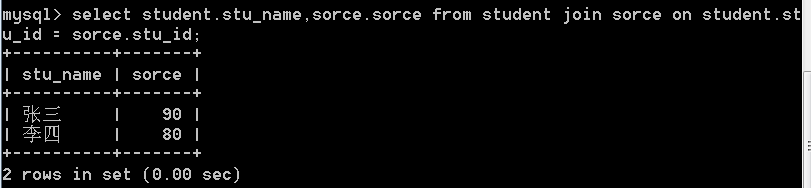
左外连接的情况
select student.stu_name,sorce.sorce from student left join sorce on student.stu_id = sorce.stu_id;
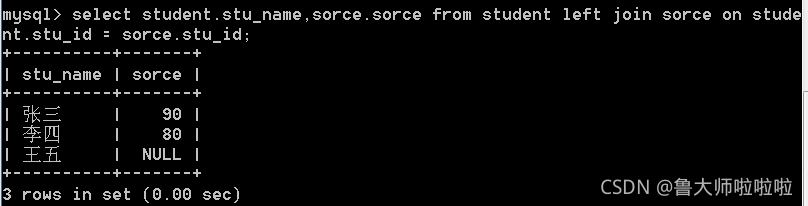
右外连接的情况
select student.stu_name,sorce.sorce from student right join sorce on student.stu_id = sorce.stu_id;

mysql不支持全外链接,但是在其他数据库是有支持的。
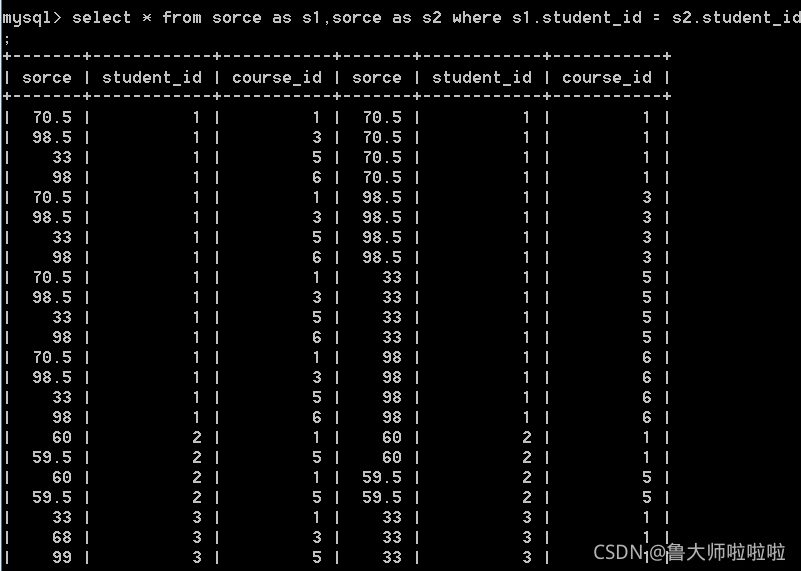
自连接:为了解决不同行的数据进行比较的问题
insert into sorce values(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
(60, 2, 1),(59.5, 2, 5),
(33, 3, 1),(68, 3, 3),(99, 3, 5),
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
(81, 5, 1),(37, 5, 5),
(56, 6, 2),(43, 6, 4),(79, 6, 6),
(80, 7, 2),(92, 7, 6);
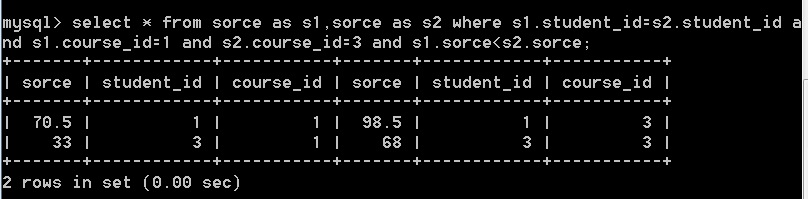
查询有哪些学生的课程id为1的课程成绩比课程id为3的分数要低的数据
子查询:将查询到的一条数据或者N条数据返回给查询语句
合并查询(union):要求两边的查询,得到的结果列是一致的(数量和类型)
select * from student where stu_name='张三' union select * from sorce where sorce>95;