【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner
标题:Baidu Apollo EM Motion Planner
作者:Haoyang Fan | Fan Zhu2 | Changchun Liu | Liangliang Zhang | Li Zhuang | Dong (东) Li | Weicheng Zhu | Jiangtao Hu | Hongye Li | Qi Kong3
来源:https://arxiv.org/abs/1807.08048
代码:https://github.com/ApolloAuto/apollo/tree/master/modules/planning
本文主体部分转载于https://blog.csdn.net/Travis_X/article/details/109174898,原文总结地非常好,因此直接转载啦,感谢原博客作者的付出!
另外这里稍微修改了一些部分~~
摘要
基于Baidu Apollo平台提出一种实时运动规划系统,该规划系统包括顶层的多车道和其中的单车道自动驾驶:
- 系统顶层是一种多车道策略,通过并行计算车道级别轨迹来处理车道变更场景;
- 在车道轨迹生成器内部,迭代的解决基于Frenet坐标的路径和速度规划;
- 针对路径和速度规划问题,提出了动态规划与基于样条的二次规划相结合的方法,构造了一个可扩展且易于调整的框架,同时处理交通规则、障碍物决策和平滑度问题。
该规划器可扩展至高速公路和城市低速驾驶场景。
文章目录
- 摘要
- 一、简介
-
- 1.多车道策略
- 2.路径-速度(Path-Speed)迭代算法
- 3.决策和道路规则
- 二、多车道策略的EM Planner框架
- 三、车道级别的EM Planner
-
- SL和ST投影(E-step)
-
- SL投影
- ST投影
- M-Step DP Path(E-Step)
- 样条QP路径(M-Step)
- DP速度优化器(M-Step)
- QP速度优化器(M-Step)
- 求解二次规划问题笔记
- 求解DP和QP非凸问题笔记
- 四、案例学习
- 五、计算性能
- 六、结论
一、简介
- 高精地图模块提供了任何人都可以访问的高精地图。
- 感知和定位模块提供了动态环境中必要的信息。
- 运动规划模块考虑生成一条安全平滑的轨迹再交由汽车的控制模块去执行。
- 运动规划以安全第一为原则,遵循各种规则。
- 对于规划的覆盖范围:至少提供8秒或者200米的运动规划轨迹,算法的反应时间必须在100ms(人是300ms反应时间)内做出反应。
- 必须设有安全应急模块。
- 除了安全以外,乘客的体验感也很重要,舒适度主要取决于轨迹的平滑性。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第1张图片](http://img.e-com-net.com/image/info8/39fa4ef82aff499b98b57024c151aa2d.jpg)
EM Planner是Apollo面向L4的实时运动规划算法,该算法首先通过顶层多车道策略,选择出一条参考路径,再根据这条参考线,在Frenet坐标系下,进行车道级的路径和速度规划,规划主要通过Dynamic Programming和基于样条的Quadratic Programming实现。EM Planner充分考虑了无人车安全性、舒适性、可扩展性的需求,通过考虑交通规则、障碍物决策、轨迹光滑性等要求,可适应高速公路、低速城区场景的规划需求。通过Apollo仿真和在环测试,EM Planner算法体现了高度的可靠性,和低耗时性。
1.多车道策略
对于L4级别的自动驾驶,变道策略是必须的。一种常见的方法是开发一种搜索算法,可以计算所有可能的车道上的代价函数,然后选择代价最低的一条轨迹。
但是该方法存在一些困难。首先,搜索空间因多车道而增大,导致计算量增大。其次,每个车道的交通规则不同,很难在同一框架下应用相同的算法的代价函数。此外,避免突然变道的轨迹稳定性也应该被考虑进来。遵循一致的道路驾驶规则是很重要的,以便其他驾驶员知道自动驾驶汽车的驾驶意图。
通常情况下,多车道策略应涵盖主动和被迫换道的情况。主动车道变换是routing模块因为要到达最终目的地而发出的换道请求。被动换道时因为当前车道被动态环境阻挡时汽车的自主行为。在主动和被动换道中,我们的目标是提供一个安全、平稳、成功率高的车道变换策略。因此提出了一个并行框架来处理主动和被动的换道。对于候选车道,所有障碍物和环境信息都投影到Frenet框架上。然后,将交通规则与车道级别的策略绑定。然后在此框架下,每个候选车道基于规划器都生成一条最佳轨迹。最后,进行多车道轨迹决策确定一个最佳车道。
2.路径-速度(Path-Speed)迭代算法
在运动规划中,最优性和效率都是很重要的。因此,许多自动驾驶运动规划算法是在Frenet框架下的SLT图并且借助于参考线来降低规划的维度。在Frenet框架下找到最优的轨迹本质上是三维空间约束优化问题。因此有两种类型方法:直接三维空间优化方法和路径-速度分解方法。
直接三维空间方法尝试使用轨迹采样或 lattice (晶格) search在SLT中找到最佳轨迹。这种方法受到其搜索复杂度的限制,搜索复杂度随着空间和时间搜索分辨率的增加而增加。为了满足时间消耗要求,必须在增加搜索网格大小或采样分辨率上做出折衷。因此,所产生的轨迹是次优的。
相反,路径-速度分解方法是分别将路径规划和速度规划分开。路径规划通常考虑静态障碍。然后,基于生成的路径产生速度曲线。但当出现动态障碍物时,路径-速度分解方法可能不是最优的。但是,由于路径规划和速度规划是分离的,因此该方法在路径和速度规划上都具有很大的灵活性。
EM Planner迭代优化路径和速度。在路径规划器中,上一个周期的速度曲线被用估计和迎面来的低速动态障碍物的影响。然后,将生成的路径送到速度规划器以评估最佳速度曲线。对于高速动态障碍物,EMPlanner出于安全考虑,更倾向于变道躲避而不是接近。
因此,EM规划器的迭代策略可以帮助解决路径-速度分解框架下的动态障碍。
3.决策和道路规则
在EM Planner中,决策和交通规则是两种不同的约束。
交通规则属于硬约束,是不能改变的,一些障碍则属于软约束,是可以协调的。对于决策模块来说,一些决策方法直接考虑的是数值上的最优解【7】,也有像【5】一样同时进行规划和决策。
在Apollo EM Planner器中,先做决策再做规划。决策过程意在于明确道路并缩小轨迹规划的搜索空间来寻找最优的轨迹。许多包含决策的规划器尝试让汽车自我决策生成相应的状态。这些方法进一步被分为手写决策和基于模型的决策。手写方式有局限性,不够灵活。基于模型的方法将汽车状态离散,并使用数据驱动方式来调整模型。
针对L4级别的自动驾驶,决策模块应具有可扩展性和可行性。可扩展性是场景表达能力。在多障碍时,很难通过有限的自我汽车状态集准确的描述决策行为。出于可行性考虑,我们的意思是所生成的决策应包括一个可行的区域,自我汽车可以在该区域内进行动态限制。但是,手写方式和基于模型的决策都不会产生无障碍轨迹来验证可行性。
在EM Planner的决策步骤中,我们以不同的方式描述行为。首先,通过一个粗略可行的轨迹来描述汽车的移动意图。这条轨迹也可以用来估计与障碍物之间的交互,即便情景变得更加复杂,这种基于可行的轨迹的决策也是可扩展的。其次,规划器还将基于轨迹生成凸的可行空间,用来平滑样条曲线参数。基于二次规划的平滑样条曲线求解器可用于生成遵循该决策的更平滑的路径和速度曲线。这保证了可行且平滑的解决方案。
二、多车道策略的EM Planner框架
本节中,我们先介绍Apollo EM Planner的整体架构,然后重点介绍车道级别的优化器架构。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第2张图片](http://img.e-com-net.com/image/info8/b2b2cb8040a54b3e9973f2b0e1ff19c4.jpg)
在顶层的数据中心,所有来源的信息都被收集和同步。采集数据后,参考线生成器会生成一系列携带交通规则信息和障碍物信息的参考线。这个过程要基于从Routing模块的导航信息和HD地图。在运动规划中,先构造Frenet框架。在框架中构建车辆与周围环境的关系。再将构建的关系传递给规划器。规划器模块执行速度和路径规划。
在路径规划过程中,周围环境的信息被投影到Frenet框架中(E-step)。然后基于投影的信息产生一条平滑的路径(M-step)。
速度规划也是类似。在速度优化过程中,一旦路径优化器生成了一条平滑的路径,障碍物就会投影到station-time graph 中(E-step)。 然后,速度优化器将生成平滑的速度曲线(M-step)。
结合路径和速度曲线,我们将获得指定车道的平滑轨迹。 在最后一步中,所有车道级别的最佳轨迹都将发送到参考线轨迹决策器。 根据当前的汽车状态,法规和成本,最后将路径和速度结合获得一条平滑的轨迹。最后一步中将所有得到的轨迹发送到参考线决策器,根据当前汽车状态、法规和每条轨迹的代价,轨迹决策器将选择最优的轨迹交由汽车去执行。
三、车道级别的EM Planner
在本节中,我们将讨论车道级别优化问题。图3展示了车道级别规划内的路径-速度EM迭代。迭代过程包括两个E-step和两个M-step。轨迹信息将在规划周期之间迭代。各子模块的解释如下:
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第3张图片](http://img.e-com-net.com/image/info8/782867f507ae416b85b30fd5ee639a02.jpg)
-
在第一个E-steps中,动态和静态障碍物都被投影到车道Frenet坐标系下。静态障碍物会直接从笛卡尔坐标系转换到Frenet坐标系,而动态障碍物的信息则以其运动轨迹来描述。在Apollo框架中,可以预测动态障碍物的移动轨迹。通过上一帧的预测信息,和自车的运动信息,可以估算自车和动态障碍物在每个时间点的交互情况,轨迹重叠的部分会被映射到Frenet坐标系中。另外,动态障碍物的出现会最终导致自车做出避让的决策。因此,出于安全考虑,SL投影只考虑低速和来向障碍物,而对于高速的动态障碍物,EM Planner的平行变道策略会考虑这种情景。
-
在第二个E-steps中,基于生成的路径在ST坐标系下,所有障碍物(包括高速、低速和即将到来的障碍物)都将被估计,生成速度曲线。如果障碍物轨迹和已经规划的路径重叠,那么将在ST坐标系下对应区域将会再重新生成。
-
在两个M-steps中,通过动态规划和二次规划生成路径和速度曲线。尽管我们将障碍物投影到SL和ST坐标系下,但是最优的路径和速度解仍在非凸空间中。因此,我们使用动态规划先获得一个粗略解,同时,这个解可以提供避让、减速、超车等障碍决策。通过这个粗略的解,可以构建一个凸包,然后使用基于二次规划的样条优化器来求解。
接下来的部分将会详细介绍框架中的步骤。
SL和ST投影(E-step)
SL投影
SL投影是基于类似于G2平滑参考线(曲率导数连续)。在笛卡尔空间中,将障碍物和车的状态以及曲率和曲率的导数转换到Frenet坐标系中。由于静态障碍物的位置不会随着时间改变,因此转换很简单。对于转换动态障碍物,我们需要借助上一个周期的轨迹来实现。把上一个周期的运动轨迹被投影到Frenet坐标系上,以提取状态方向的速度曲线。给定确定的时间就会估计出汽车状态的坐标。估计的汽车状态坐标将会帮助估计动态障碍物的影响。一旦汽车状态坐标同时与障碍物轨迹发生交叉时,SL地图上的阴影区域将被标记。在此,交叉区域被定义为汽车与障碍物的重叠区域。
例如,如图4所示,从预测模块估计的迎面而来的动态障碍物和相应的轨迹被标记为红色,小车标记为蓝色。首先将迎面而来的动态障碍物的轨迹随时间离散成若干个轨迹点,然后将这些轨迹点投影到Frenet坐标上。一旦我们发现自车的位置坐标与投射的障碍点有交互作用,重叠区域(图中紫色部分)将在Frenet坐标中标记出来。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第4张图片](http://img.e-com-net.com/image/info8/27d749c573d447069fd32b25599fdaa8.jpg)
ST投影
ST投影可以帮助我们评估自车的速度曲线。当路径优化器在Frenet坐标中生成光滑的路径曲线后,与自车有交互的静态障碍物及动态障碍物的轨迹都将被投影在路径上。同理,这种交互也定义为包围盒的重叠。
如图,红色区域表示在2s处距离自车40m远切入规划路径的动态障碍物ST信息,绿色表示在自车后的动态障碍物ST信息,M-step将会在剩下的区域找到可行光滑的最优解。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第5张图片](http://img.e-com-net.com/image/info8/f161f081956a4a739615a804fcc7c396.jpg)
M-Step DP Path(E-Step)
M-step求解Frenet坐标系下的最优路径规划,实际上在一个非凸的区间(从左和从右避让是两个局部最优情景)就是找到一个最优的 l = f ( s ) l = f(s) l=f(s)方程。主要包括两步:基于动态规划的路径决策和基于样条的路径规划。
基于动态规划的路径步骤提供一条粗略的路径信息,其可以带来可行通道和避障决策,如图6所示,这一步包括 Lattice (晶格) 采样、代价函数、动态规划搜索。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第6张图片](http://img.e-com-net.com/image/info8/beb0dc881d0a4398bded17eda4108c5f.jpg)
Lattice采样器基于Frenet坐标系。如图7所示,首先在车辆之前对多行lattice进行采样。不同行之间的点通过五次多项式来平滑连接。行之间的间隔距离取决于速度,道路结构,变换车道等。该框架允许根据场景自定义采样策略。
例如,车道变换的采样间隔可能比当前车道行驶更长。此外,出于安全考虑,路径总长可以达到200m或者覆盖8s的行驶长度。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第7张图片](http://img.e-com-net.com/image/info8/392f967286e14bf0b72d1c0d2297b94d.jpg)
构造完lattice后,通过代价函数的总和来评估每条路径。我们使用从SL投影得到的信息结合交通规则、汽车动力学模型去构建函数。总的代价是平滑度,避障和车道代价函数的线性组合。
每段 Lattice (晶格) 路径的代价通过光滑程度、障碍物避让、车道代价来评价:
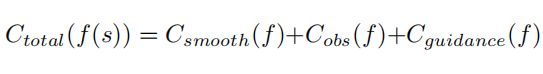
而光滑程度又通过以下方程来衡量,一阶导表示朝向偏差,二阶导表示曲率,三阶导表示曲率导数:
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第8张图片](http://img.e-com-net.com/image/info8/e8e3af41818949c1a683416855702bf0.jpg)
障碍物的代价由以下方程给出,方程中的 d d d由自车bounding box到障碍物bounding box的距离表示。
C n u d g e C_{nudge} Cnudge定义为单调递减函数。出于安全考虑, d c d_c dc设置保留缓冲区。可根据情况微调 d n d_n dn范围。 C c o l l i s i o n C_{collision} Ccollision是碰撞代价函数,可帮助检测不可行的路径。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第9张图片](http://img.e-com-net.com/image/info8/70b6589a096f40f3b237103dc95b66b3.jpg)
车道代价由以下方程给出,主要是考虑在道路上与否以及与参考线之间的差异,一般是与车道中心线的差异。
车道代价函数包括两个部分:引导线代价和车道代价。引导线定义为周围没有障碍物时的理想路径,通常这条线提取的是道路中心线。车道代价函数通常被道路边界决定,道路外的路径点将受到很高代价的惩罚:

最终总的路径代价函数包含平滑度、障碍和车道代价。然后边缘代价会用于通过动态规划去选择最低成本的候选路径。候选路径也将确定障碍物决策。
样条QP路径(M-Step)
样条QP路径步骤是对动态规划路径的改进。在动态规划路径中,会根据所选的路径生成可行的走廊。然后基于样条QP步骤将在该走廊中生成一条平滑路径,如图8所示:
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第10张图片](http://img.e-com-net.com/image/info8/c58538c781614ffe8135d945276b0ec6.jpg)
通过QP求解器求解具有线性约束的目标函数生成最优的QP路径。如图9所示:
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第11张图片](http://img.e-com-net.com/image/info8/b30fd955662e43a1becde78550073db7.jpg)
QP路径的目标代价函数是平滑度代价和引导线代价的线性组合。该步骤中的引导线是动态规划挑选出来的路径。引导线提供了避开障碍物的估计值。在数学上QP路径步骤优化以下函数:
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第12张图片](http://img.e-com-net.com/image/info8/8699b0542bd042af9d171bc6c1a26786.jpg)
g ( s ) g(s) g(s)是动态规划的结果。 f ( s ) , f ′ ′ ( s ) , f ′ ′ ′ ( s ) f(s),f''(s), f'''(s) f(s),f′′(s),f′′′(s)分别表示朝向、曲率和曲率的导数。该目标函数描述了避开障碍物和平滑度之间的平衡。
QP路径中的限制条件包含了边界约束条件和动力学可行性。这些约束都会施加在每个 s s s处。为了提取边界约束,提取各状态点的可行区间。在EM Planner中,车辆被看成自行车模型。因此仅仅提供 l = f ( s ) l=f(s) l=f(s)的范围是不够的,因为车的方向也很重要。
在图10中,为了保持边界约束的凸包性和线性,我们在汽车的前后两后端分别添加两个半圆,其中前轮到后轮的中心距离为 L f L_f Lf和车辆宽度为 w w w。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第13张图片](http://img.e-com-net.com/image/info8/87fa2ee248684b0397b2c0bf58053ae1.jpg)
然后车的左前角的横向位置由以下表示:
![]()
θ是汽车和道路状态方向之间的航向角。可用下面的不等式进一步近似地线性约束:
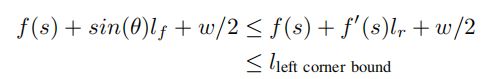
类似地,线性优化剩下的三个角度。线性约束足够好是因为θ通常很小(小于 θ < π / 12 θ<\pi/12 θ<π/12)。
f ′ ′ ( s ) f''(s) f′′(s)和 f ′ ′ ′ ( s ) f'''(s) f′′′(s)的区间限制可表示为动力学约束,因为曲率与曲率导数有关。除了边界约束外,生成的路径还可以匹配汽车的横向初始位置和导数( f ( s 0 ) , f ′ ′ ( s 0 ) , f ′ ′ ′ ( s 0 ) f(s_0),f''(s_0), f'''(s_0) f(s0),f′′(s0),f′′′(s0))。由于所有约束相对于样条曲线参数都是线性的,因此可以使用二次规划求解器来快速解决问题。
DP速度优化器(M-Step)
M-Step速度规划器在ST图里面生成一个速度曲线,该速度曲线表示为相对于时间 S ( t ) S(t) S(t)的状态函数。与路径规划器相似,在ST图上寻找最优速度曲线也是一个非凸问题,所以采用DP与QP相结合的方法在ST图上寻找一个光滑的速度曲线。
如图11所示,在QP速度时采用DP生成的速度曲线作为引导线,利用可行走廊生成凸域。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第14张图片](http://img.e-com-net.com/image/info8/a3cdeb23620d44bc8053912f2773ab06.jpg)
在图12中,DP速度规划步骤包括代价函数,ST图网格和DP搜索。生成分段性速度曲线,可行的走廊和障碍物速度决策。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第15张图片](http://img.e-com-net.com/image/info8/28b8daf9d7694e34b9e2a671e293af96.jpg)
具体来说,障碍物信息首先在ST图上离散成网格。将 ( t 0 , t 1 … t n ) (t_0,t_1…t_n) (t0,t1…tn)表示为在时间轴上具有间隔 d t dt dt的等距评估点。分段性速度曲线函数在网格上表示为 S = ( s 0 , s 1 , … s n ) S=(s_0,s_1,…s_n) S=(s0,s1,…sn)。此外,利用有限差分方法对导数进行了逼近。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第16张图片](http://img.e-com-net.com/image/info8/42e6521818044d49b7bd39ac3aee04d1.jpg)
目标是在ST图中优化一个带有约束的代价函数。准确地说,DP速度优化器的代价表示为:
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第17张图片](http://img.e-com-net.com/image/info8/b94ecd77a3a34238b44a7e2f62ca6722.jpg)
第一项是速度保持代价,表示当没有障碍物或者没有红绿灯时,车辆应按照指定的速度行驶。 V r e f V_{ref} Vref描述的是参考速度,参考速度由道路速度限制、曲率和其他交通规则来确定。 g g g函数被用来对小于或者大于 V r e f V_{ref} Vref值施加的不同惩罚。最后一个 C o b s C_{obs} Cobs值描述了总障碍代价,对车辆到所有的障碍物的距离进行评估,确定总障碍物代价。
动态规划搜索空间必须在动力学约束范围内,包括加速度、加加速度 jerk 和单调性约束。因为我们要求生成的轨迹在道路上不执行倒车的操作,只能在泊车或者其他指定情况下直行倒车。搜索算法是向前的,基于车辆动态约束的一些必要修剪也被应用以加速该过程。
QP速度优化器(M-Step)
由于分段线性速度曲线不能满足动力学要求,需要用QP来解决这个问题。在图13中,样条速度包括三个部分:代价函数、线性约束条件和样条QP求解器。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第18张图片](http://img.e-com-net.com/image/info8/9c13ddd64ad6427f813eb7f5ac779b86.jpg)
代价函数可以这样表示:
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第19张图片](http://img.e-com-net.com/image/info8/8cfa61aee0af4f8e9d55f4328d7da8bc.jpg)
第一项是DP速度参考线 S r e f S_{ref} Sref和最后需要生成的S之间的距离。加速度和jerk是速度曲线平滑度。因此,目标函数是为了平衡引导线和平滑度。
QP速度优化器的限制条件包括了边界限制、初始速度和加速度匹配的约束:
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第20张图片](http://img.e-com-net.com/image/info8/94d19b2511ab455ba099113b5dc0ae58.jpg)
第一个约束是单调性。第二、第三和第四、五个约束是来自交通规则和车辆动力学约束的要求。在完成代价函数和约束后,QP求解器将生成一条平滑可行的速度曲线,如图14结合路径曲线,EM规划器将给控制模块生成一条平滑的轨迹。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第21张图片](http://img.e-com-net.com/image/info8/da510d5db008413abc70488759b12ea3.jpg)
求解二次规划问题笔记
出于安全的考虑,我们评估了大概100个不同位置或时间点的路径和速度。约束的数量超过600。对于选择所需的路径和速度优化器,我们发现五项多项式是比较合适的。样条曲线包括3到5个多项式,大约有30个参数。因此,二次规划问题有相对较小的目标函数,但约束条件较多。因此,主动设置QP求解器有助于解决该类问题。除了加速二次规划求解外,我们还将上一个循环的计算结果作为hot start(热启动)。QP问题平均可以在3ms内解决,满足了我们对时间消耗的需求。
求解DP和QP非凸问题笔记
DP和QP在非凸领域都有各自的局限性。DP和QP的结合将充分利用两者的优点,以达到最理想的解决方案。
- DP:如前文所述,DP算法依赖于一个采样步骤来生成候选解。由于处理时间的限制,采样网格限制了候选样本的数量。有限网格内的优化会得到一个粗糙的DP解。换句话说,DP不一定能在所有的场景下都取得最优解。例如,DP求出从左侧避开障碍物的路径,但不能选择具有最佳距离的路径。
- QP:相反,QP是基于凸域生成解。如果没有DP步骤的帮助,它是不可用的。例如,如果一个障碍物在车辆前面,QP需要一个决策,例如从左侧变道,从右侧变道,跟随或者超车,来生成其约束。随机或基于规则的决策容易使QP陷入失败或者局部极小值。
- DP+QP:DP+QP算法将两者的局限性降到最低:(1)EM规划器首先用DP在网格内搜索,以求得粗略的解;(2)DP的结果被用于生成凸域并引导QP;(3)QP被用于在凸域内寻找全局最优解。
四、案例学习
如上所述,虽然大多数高级的规划算法都是基于重决策的,但EM planner是一个基于轻决策的规划器。确实,基于重决策的算法,或者依赖规则的算法,很容易理解和解释。但是缺点也很明显:它可能被困在角落的情况下(陷入局部最优解的频率与限制条件的复杂性和数量密切关),并不总是最优的。在本节中,我们将通过几个案例来说明基于轻决策的规划算法的优点。这些案例都是在百度很多的重决策规划模块中的日常测试中暴露出来的,并最后由轻决策解决。
![【自动驾驶】Apollo EM Planner学习(一):[论文解读]Baidu Apollo EM Motion Planner_第22张图片](http://img.e-com-net.com/image/info8/ec87537841e947fb9edc641551bc5cfb.jpg)
图15是EM规划器如何在规划周期和迭代周期之间迭代以获得最佳轨迹的实际例子。在这个案例研究中,我们演示了当障碍物进入我们的路径时如何生成轨迹。假设车辆的速度为10m/s,并且有一个动态障碍物以10m/s的速度朝我们移动,EM规划器将按照以下步骤迭代生成路径和速度曲线。
- 原始规划(图15a)。在历史规划速度曲线中,即动态障碍物进入前,车辆以10m/s的恒定速度直线前进;
- 路径曲线的迭代(b)。在这一步中,速度曲线以10m/s的速度从原始曲线巡航。根据该速度推算,车子和动态障碍物将在s=40m处相撞,因此,避免该障碍物的最佳方法是在s=40m处从右侧躲避。
- 速度曲线迭代(c)。从步骤1开始,根据从右侧避开的路径曲线,原始根据其与障碍物的距离来调整期望速度。因此,如乘客所期望的一样,车辆速度将减至5m/s以较低速度通过障碍物。
- 路径曲线迭代2(d)。在新的速度曲线下,车辆不会在s=40m处通过障碍物,而是在s=30m处通过。因此应躲避障碍物的路径更新为一个新的路径,以使躲避的距离最大化为s=30。
- 速度曲线迭代2(e)。在新的路径曲线下,在s=30m处执行而不再需要在s=40m处进行减速。新的速度曲线显示,车辆可以在s=40处加速,在s=30处仍然能平稳通过。
因此,基于这四个步骤生成的最终轨迹整体过程是:在s=30处缓慢躲避障碍物,然后车辆通过障碍物再加速,这才是人类驾驶员在这种情况下可能的操作。
请注意,规划并不一定要始终执行四个步骤。它根据不同的场景可以采用更少或者更多的步骤。一般来说,环境越复杂,可能需要的步骤就越多。
五、计算性能
由于将三维状态横向速度问题分解为状态横向速度和状态速度两个二维问题,极大降低了EM Planner的计算复杂度。因而具有很高的规划效率。假设我们有n个障碍物、M条候选路径和N条候选速度曲线,则该算法的计算复杂度为O(n(M+N))。
六、结论
EM Planner是一个基于轻决策的规划算法。与其他基于重决策的算法相比,Em规划器的优势在于能够在复杂的多障碍场景下执行。当基于重决策的方法试图预先确定如何处理每个障碍物时,困难是显而易见的:(1)很难理解和预测障碍物如何与主车相互作用,因此它们的跟随运动难以描述,因此很难被任何规则考虑;(2)当多个障碍物阻塞道路时,无法找到满足所有预定决策的轨迹概率大大降低,从而导致规划的失败。
自动驾驶汽车的一个关键问题是对安全性和通过性的挑战,严格的规则增加了汽车的安全性,但降低了通过性,反之亦然。以换道为例,如果后面有车辆,只要有简单的规则,就可以很容易地暂停换道过程。这样可以保证安全,但大大降低了通过性。本文所描述的EM-planner,在解决潜在决策与规划不一致的同时,也提高了自主驾驶车辆的通过性。
EM计划器通过将三维规划问题转换为两个二维规划问题,大大降低了计算复杂度。 它可以大大减少处理时间,从而提升整个系统的交互能力。