elasticsearch简述与特性分析
文章目录
-
-
- 1 搜索的演化
-
- 1.1 搜索是什么
- 1.2 数据库做搜索弊端
- 1.3 互联网搜索,肯定不会使用数据库搜索。数据量太大。PB级。
- 1.4 全文检索、倒排索引和Lucene
- 2 Elasticsearch简述
-
- 2.1.1 简介
- 2.1.2 Elasticsearch的使用场景
- 2.1.3 Elasticsearch的特点
- 3 elasticsearch核心概念
-
- 3.1 lucene和elasticsearch的关系
- 3.2 elasticsearch的核心概念
- 4 elasticsearch核心概念 vs 数据库核心概念
- 5 ElasticSearch核心原理
-
- 5.1 文件储存
- 5.2 索引
- 5.2.1 FST
- 5.2.2 压缩技巧之Frame Of Reference
-
- Frame Of Reference 可以翻译成索引帧
- Elasticsearch是如何有效的对这些文档id压缩的呢?
- 5.2.3 缓存技巧之Roaring Bitmaps 咆哮位图
-
- 5.2.3.1 ES缓存高频率filter的原因
- 5.2.3.1 ES缓存的数据结构
- 5.2.3.1 Roaring Bitmap
- 5.2.3.1 Roaring Bitmap的特性
- 5.2.4 倒排索引如何做联合索引
- 总结和思考
- 拓展:
-
- 一 磁盘物理结构
- 二 磁盘如何完成单次IO操作
- 三 数据库中的磁盘读写
-
- 1 随机访问和连续访问
- 2 顺序IO和并发IO
-
1 搜索的演化
1.1 搜索是什么
- 概念:用户输入想要的关键词,返回含有该关键词的所有信息。
- 场景:
- 互联网搜索:谷歌、百度、各种新闻首页
- 站内搜索(垂直搜索):企业OA查询订单、人员、部门,电商网站
- 内部搜索商品(淘宝、京东)场景。
1.2 数据库做搜索弊端
- 站内搜索(垂直搜索):数据量小,简单搜索,可以使用数据库。
- 问题出现:
- 存储问题: 电商网站商品上亿条时,涉及到单表数据过大必须拆分表,数据库磁盘占用过大必须分库(mycat)。
- 性能问题:解决上面问题后,查询“笔记本电脑”等关键词时,上亿条数据的商品名字段逐行扫描,性能跟不上。
- 不能分词:如搜索“笔记本电脑”,只能搜索完全和关键词一样的数据,那么数据量小时,搜索“笔记电脑”,“电脑”数据要不要给用户。
1.3 互联网搜索,肯定不会使用数据库搜索。数据量太大。PB级。
1.4 全文检索、倒排索引和Lucene
- 全文检索
- 倒排索引。数据存储时,进行分词建立term索引库。见画图。
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(invertedfifile)。
- Lucene
就是一个jar包,里面封装了全文检索的引擎、搜索的算法代码。开发时,引入lucen的jar包,通过api开发搜索相关业务。底层会在磁盘建立索引库。
2 Elasticsearch简述
2.1.1 简介
官网:https://www.elastic.co/cn/products/elasticsearch1.3.2
- Elasticsearch的功能
- 分布式的搜索引擎和数据分析引擎
搜索:互联网搜索、电商网站站内搜索、OA系统查询
数据分析:电商网站查询近一周哪些品类的图书销售前十;
新闻网站,最近3天阅读量最高的十个关键词,舆情分析。
- 全文检索,结构化检索,数据分析
全文检索:搜索商品名称包含java的图书select from books where book_name like “%java%”。
结构化检索:搜索商品分类为spring的图书都有哪些,select from books where category_id=‘spring’
数据分析:分析每一个分类下有多少种图书,select category_id,count() from books group by category_id
- 对海量数据进行近实时的处理
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索,进行并行查询,提高搜索效率。相对的,Lucene是单机应用。
近实时:数据库上亿条数据查询,搜索一次耗时几个小时,是批处理(batch-processing)。而es只需秒级即可查询海量数据,所以叫近实时。秒级。
2.1.2 Elasticsearch的使用场景
国外:
维基百科,类似百度百科,“网络七层协议”的维基百科,全文检索,高亮,搜索推荐StackOverflflow(国外的程序讨论论坛),相当于程序员的贴吧。遇到it问题去上面发帖,热心网友下面回帖解答。GitHub(开源代码管理),搜索上千亿行代码。电商网站,检索商品日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅《Carl的笔记》的监控,如果价格低于27块钱,就通知我,我就去买。BI系统,商业智能(Business Intelligence)。大型连锁超市,分析全国网点传回的数据,分析各个商品在什么季节的销售量最好、利润最高。成本管理,店面租金、员工工资、负债等信息进行分析。从而部署下一个阶段的战略目标。
国内:
以前的百度搜索,第一次查询,使用es。后面则会添加一些广告。OA、ERP系统站内搜索。
2.1.3 Elasticsearch的特点
- 可拓展性:大型分布式集群(数百台服务器)技术,处理PB级数据,大公司可以使用。小公司数据量小,也可以部署在单机。大数据领域使用广泛。
- 技术整合:将全文检索、数据分析、分布式相关技术整合在一起:lucene(全文检索),商用的数据分析软件(BI软件),分布式数据库(mycat)
- 部署简单:开箱即用,很多默认配置不需关心,解压完成直接运行即可。拓展时,只需多部署几个实例即可,负载均衡、分片迁移集群内部自己实施。
- 接口简单:使用restful api进行交互,跨语言。功能强大:Elasticsearch作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能,如全文检索,同义词处理,相关度排名。
3 elasticsearch核心概念
3.1 lucene和elasticsearch的关系
Lucene:最先进、功能最强大的搜索库,直接基于lucene开发,非常复杂,api复杂Elasticsearch:基于lucene,封装了许多lucene底层功能,提供简单易用的restful api接口和许多语言的客户端,如java的高级客户端(Java High Level REST Client)和底层客户端(Java Low Level REST Client)起源:Shay Banon。2004年失业,陪老婆去伦敦学习厨师。失业在家帮老婆写一个菜谱搜索擎。封装了lucene的开源项目,compass。找到工作后,做分布式高性能项目,再封装compass,写出了elasticsearch,使得lucene支持分布式。现在是Elasticsearch创始人兼Elastic首席执行官。哈哈,等什么时候carl回家做菜了也写个组件出来。
3.2 elasticsearch的核心概念
-
NRT(NearRealtime):近实时
两方面:
写入数据时,过1秒才会被搜索到,因为内部在分词、录入索引。
es搜索时:搜索和分析数据需要秒级出结果。 -
Cluster:集群
包含一个或多个启动着es实例的机器群。通常一台机器起一个es实例。同一网络下,集名一样的多个es实例自动组成集群,自动均衡分片等行为。默认集群名为“elasticsearch”。
-
Node:节点
每个es实例称为一个节点。节点名自动分配,也可以手动配置。
-
Index:索引
包含一堆有相似结构的文档数据。
索引创建规则:- 仅限小写字母,不能包含\、/、 、?、"、<、>、|、#以及空格符等特殊符号
- 从7.0版本开始不再包含冒号
- 不能以-、_或+开头
- 不能超过255个字节(注意它是字节,因此多字节字符将计入255个限制)
-
Document:文档
es中的最小数据单元。一个document就像数据库中的一条记录。通常以json格式显示。多个document存储于一个索引(Index)中。
例如:
book document { "book_id": "1", "book_name": "carl的笔记", "book_desc": "carl呕心沥血写的菜谱,一定要好好研习", "category_id": "2", "category_name": "java" } -
Field:字段
就像数据库中的列(Columns),定义每个document应该有的字段。
-
Type:类型
每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field。7.x版本正式被去除。
分析:
为什么要7.X版本去除Type?
因为关系型数据库比非关系型数据库的概念提出的早,而且很成熟,应用广泛。所以,后来很多NoSQL(包括:MongoDB,Elasticsearch等)都参考并延用了传统关系型数据库的基本概念。由于需要有一个对应关系型数据库表的概念,所以type应运而生。那么为什么我们又需要把type去除呢?并且需要在7.X版本去除呢?
首先,我们可以看一下ES的版本演变。
在 5.X 版本中,一个 index 下可以创建多个 type;
在 6.X 版本中,一个 index下只能存在一个 type;
在7.X 版本中,直接去除了 type 的概念,就是说index 不再会有 type。原因分析:
为何要去除 type 的概念?
因为 Elasticsearch 设计初期,是直接查考了关系型数据库的设计模式,存在了 type(数据表)的概念。
但是,其搜索引擎是基于 Lucene 的,这种 “基因”决定了 type 是多余的。 Lucene 的全文检索功能之所以快,是因为 倒序索引 的存在。而这种 倒序索引 的生成是基于 index 的,而并非 type。多个type 反而会减慢搜索的速度。为了保持 Elasticsearch “一切为了搜索” 的宗旨,适当的做些改变(去除 type)也是无可厚非的,也是值得的。
为何不是在 6.X 版本开始就直接去除 type,而是要逐步去除type?
因为历史原因,前期 Elasticsearch 支持一个 index 下存在多个 type的,而且,有很多项目在使用Elasticsearch 作为数据库。如果直接去除 type 的概念,不仅是很多应用 Elasticsearch 的项目将面临业务、功能和代码的大改,而且对于 Elasticsearch 官方来说,也是一个巨大的挑战(这个是伤筋动骨的大手术,很多涉及到 type源码是要修改的)。所以,权衡利弊,采取逐步过渡的方式,最终,推迟到 7.X 版本才完成 “去除 type” 这个 革命性的变革。
-
shard:分片
index数据过大时,将index里面的数据,分为多个shard,分布式的存储在各个服务器上面。可以支持海量数据和高并发,提升性能和吞吐量,充分利用多台机器的cpu。
-
replica:副本
在分布式环境下,任何一台机器都会随时宕机,如果宕机,index的一个分片没有,导致此index不能搜索。所以,为了保证数据的安全,我们会将每个index的分片进行备份,存储在另外的机器上。保证少数机器宕机es集群仍可以搜索。能正常提供查询和插入的分片我们叫做主分片(primary shard),其余的我们就管他们叫做备份的分片(replica shard)。
4 elasticsearch核心概念 vs 数据库核心概念
| 关系型数据库(比如Mysql) | 非关系型数据库(Elasticsearch) |
|---|---|
| 数据库Database | 索引Index |
| 表Table | 索引Index(原为Type) |
| 数据行Row | 文档Document |
| 数据列Column | 字段Field |
| 约束 Schema | 映射Mapping |
5 ElasticSearch核心原理
5.1 文件储存
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "carl",
"sex" : "Male",
"age" : 18,
"birthDate": "1990/05/10",
"interests": [ "sports", "music" ]
}
用Mysql这样的数据库存储就会容易想到建立一张User表,有name,sex等字段,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) (7.x版本正式将type剔除) ⇒ 文档 (Docments) ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。Elasticsearch的交互,可以使用JavaAPI,也可以直接使用HTTP的Restful API方式
5.2 索引
Elasticsearch最关键的就是提供强大的索引能力了。
Elasticsearch索引的精髓用一句话来总结:一切设计都是为了提高搜索的性能,也就是让我们的搜索更快。但是这样的设计难免会带来一些问题。比如你搜索快,也就是插入快,那必然相对应的插入或者更新会有些问题。要是ElasticSearch十全十美,那其他数据库不用混了。既然Elasticsearch最核心功能是搜索。这个时候我们就可以对比一下传统的关系型数据库索引所采用的数据结构。
我们知道的二叉树查找效率是O(n),同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能(AVL)。因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读)(多路查找树,B树)。传统的关系型数据库采用的是B-Tree/B+Tree这样的数据结构:为了提高查询的效率,减少磁盘寻道次数,将多个值作为一个数组通过连续区间存放,一次寻道读取多个数据,同时也降低树的高度。
那么,我们的倒排索引在结构上有什么优势呢??,这里我们又应该举个例子我构建一个ES的搜索数据结构模型。那我们的结构化数据怎么储存呢?
我们拿到三条结构化数据:
| ID | Name | Age | Sex |
| -- |:------:| -----:| -----:|
| 1 | 叮咚 | 18 | Female
| 2 | Tom | 50 | Male
| 3 | carl | 18 | Male
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name:
| Term | Posting List |
| -- |:----:|
| 叮咚 | 1 |
| TOM | 2 |
| carl | 3 |
Age:
| Term | Posting List |
| -- |:----:|
| 50 | 2 |
| 18 | [1,3] |
Sex:
| Term | Posting List |
| -- |:----:|
| Female | 1 |
| Male | [2,3] |
Posting List(倒排表)
Elasticsearch分别为每个field都建立了一个倒排索引,Tom,carl, 18, Female这些叫term(分类索引),而[1,2]就是Posting List(倒排表)。Posting list就是一个int的数组,存储了所有符合某个term的文档id。通过posting list这种索引方式似乎可以很快进行查找,比如要找age=18的词条,立马就会有人回答,是1和3。但是,如果这里有上千万的记录呢?如果是想通过name来查找呢?
Term Dictionary(词典)
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,log(N)的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在好像跟我们的传统B树的方式一样啊 。那么我们的ES有什么进步呢?
Term Index(词典索引)
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了TermIndex,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:‘
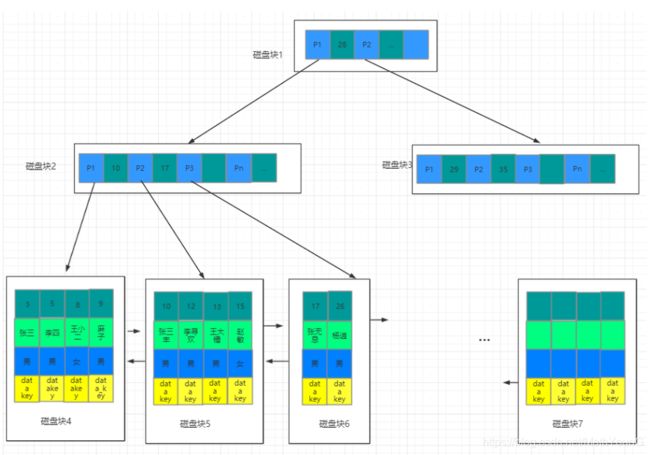
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到termdictionary的某个offset,然后从这个位置再往后顺序查找。
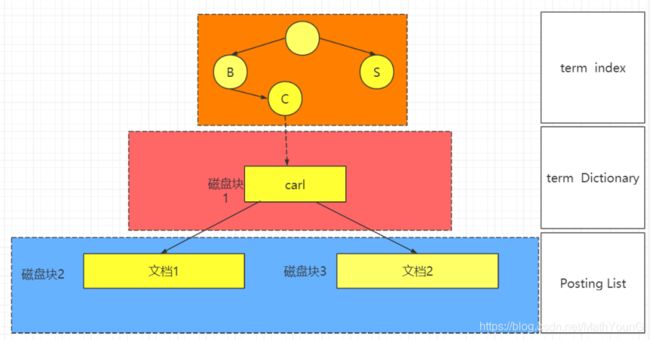
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从termindex查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
block块:文件系统不是一个扇区一个扇区的来读数据,太慢了,所以有了block(块)的概念,它是一个块一个块的读取的,block才是文件存取的最小单位。
5.2.1 FST
Finite StateTransducers 简称 FST,通常中文译作有穷状态转换器或者有限状态传感器
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
FST是一项将一个字节序列映射到block块的技术
假设我们现在要将mop, moth, pop, star, stop and top(term index里的term前缀)映射到序号:0,1,2,3,4,5(term dictionary的block位置)。最简单的做法就是定义个Map
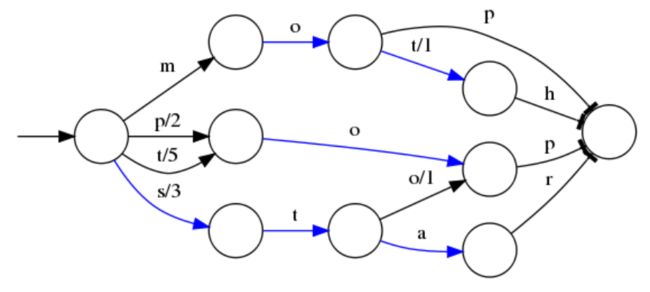
⭕表示一种状态
–>表示状态的变化过程,上面的字母/数字表示状态变化和权重
将单词分成单个字母通过⭕和–>表示出来,0权重不显示。如果⭕后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。
当遍历上面的每一条边的时候,都会加上这条边的输出,比如当输入是 stop 的时候会经过 s/3 和o/1 ,相加得到的排序的顺序是 4 ;而对于 mop ,得到的排序的结果是 0
但是这个树并不会包含所有的term,而是很多term的前缀,通过这些前缀快速定位到这个前缀所属的磁盘的block,再从这个block去找文档列表。为了压缩词典的空间,实际上每个block都只会保存block内不同的部分,比如 mop 和 moth 在同一个以 mo 开头的block,那么在对应的词典里面只会保存 p 和th ,这样空间利用率提高了一倍。
使用有限状态转换器在内存消耗上面要比远比 SortedMap 要少,但是在查询的时候需要更多的CPU资源。维基百科的索引就是使用的FST,只使用了69MB的空间,花了大约8秒钟,就为接近一千万个词条建立了索引,使用的堆空间不到256MB。
顺带提一句,在ES中有一种查询叫模糊查询(fuzzy query),根据搜索词和字段之间的编辑距离来判断是否匹配。在ES4.0之前,模糊查询会先让检索词和所有的term计算编辑距离筛选出所有编辑距离内的字段;在ES4.0之后,采用了由Robert开发的,直接通过有限状态转换器就可以搜索指定编辑距离内的单词的方法,将模糊查询的效率提高了超过100倍。
现在已经把词典压缩成了词条索引,尺寸已经足够小到放入内存,通过索引能够快速找到文档列表。现在又有另外一个问题,把所有的文档的id放入磁盘中会不会占用了太多空间?如果有一亿个文档,每个文档有10个字段,为了保存这个posting list就需要消耗十亿个integer的空间,磁盘空间的消耗也是巨大的,ES采用了一个更加巧妙的方式来保存所有的id。
5.2.2 压缩技巧之Frame Of Reference
Frame Of Reference 可以翻译成索引帧
Elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧。
又有人问了:“posting list不是已经只存储文档id了吗?还需要压缩?”
嗯,我们再看回最开始的例子,如果Elasticsearch需要对同学的性别进行索引会怎样?
彩蛋:传统关系型数据库索引会怎么处理这样的事情呢?
如果男同学和女同学数量很接近,传统关系型数据库索引是不会起到作用,如果差距大,还是会走索引的,其他同学要记住。
如果有上千万个同学,而世界上只有男/女这样两个性别,每个posting list都会有至少百万个文档id。
Elasticsearch是如何有效的对这些文档id压缩的呢?
在进行查询的时候经常会进行组合查询,比如查询同时包含man和woman的文档,那么就需要分别查出包含这两个单词的文档的id,然后取这两个id列表的交集;如果是查包含man或者woman的文档,那么就需要分别查出posting list然后取并集。为了能够高效的进行交集和并集的操作。为了方便压缩,Elasticsearch要求posting list是有序的(为了提高搜索的性能,再任性的要求也得满足)。同时为了减小存储空间,所有的id都会进行delta编码
(delta-encoding刀塔,我觉得可以翻译成增量编码)比如现在有id列表 [73, 300, 302, 332, 343, 372],转化成每一个id相对于前一个id的增量值(第一个id的前一个id默认是0,增量就是它自己)列表是 [73, 227, 2, 30, 11, 29]。在这个新的列表里面,所有的id都是小于255的,所以每个id只需要一个字节存储。实际上ES会做的更加精细,它会把所有的文档分成很多个block,每个block正好包含256个文档,然后单独对每个文档进行增量编码,计算出存储这个block里面所有文档最多需要多少位来保存每个id,并且把这个位数作为头信息(header)放在每个block 的前面。这个技术叫Frame of Reference,我翻译成索引帧。比如对上面的数据进行压缩(假设每个block只有3个文件而不是256),压缩过程如下

1 8个二进制位构成一个字节。这种压缩算法的原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储,而不是大大咧咧的尽管是2也是用int(4个字节)来存储。
2 在返回结果的时候,其实也并不需要把所有的数据直接解压然后一股脑全部返回,可以直接返回一个迭代器 iterator,直接通过迭代器的 next方法逐一取出压缩的id,这样也可以极大的节省计算和内存开销。
3 通过以上的方式可以极大的节省posting list的空间消耗,提高查询性能。不过ES为了提高filter过滤器查询的性能,还做了更多的工作,那就是缓存。
5.2.3 缓存技巧之Roaring Bitmaps 咆哮位图
5.2.3.1 ES缓存高频率filter的原因
ES会缓存频率比较高的filter查询,其中的原理也比较简单,即生成 (fitler, segment数据空间)和id列表的映射,但是和倒排索引不同,我们只把常用的filter缓存下来而倒排索引是保存所有的,并且filter缓存应该足够快,不然直接查询不就可以了。ES直接把缓存的filter放到内存里面,映射的postinglist放入磁盘中。
5.2.3.1 ES缓存的数据结构
ES在filter缓存使用的压缩方式和倒排索引的压缩方式并不相同,filter缓存使用了roaring bitmap的数据结构,在查询的时候相对于上面的Frame of Reference方式CPU消耗要小,查询效率更高,代价就是需要的存储空间(磁盘)更多。
Roaring Bitmap是由int数组和bitmap这两个数据结构改良过的成果——int数组速度快但是空间消耗大,bitmap相对来说空间消耗小但是不管包含多少文档都需要12.5MB的空间,即使只有一个文件也要12.5MB的空间,这样实在不划算,所以权衡之后就有了下面的Roaring Bitmap。
5.2.3.1 Roaring Bitmap
Bitmap是一种数据结构,假设有某个posting list:
[1,3,4,7,10]
对应的bitmap就是:
[1,0,1,1,0,0,1,0,0,1]
非常直观,用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。
Bitmap的缺点是存储空间随着文档个数线性增长,Roaring bitmaps需要打破这个魔咒就一定要用到某些指数特性.
5.2.3.1 Roaring Bitmap的特性
-
Roaring Bitmap首先会根据每个id的高16位分配id到对应的block里面,比如第一个block里面id应该都是在0到65535之间,第二个block的id在65536和131071之间
-
对于每一个block里面的数据,根据id数量分成两类
如果数量小于4096,就是用short数组保存
数量大于等于4096,就使用bitmap保存
在每一个block里面,一个数字实际上只需要2个字节来保存就行了,因为高16位在这个block里面都是相同的,高16位就是block的id,block id和文档的id都用short保存。
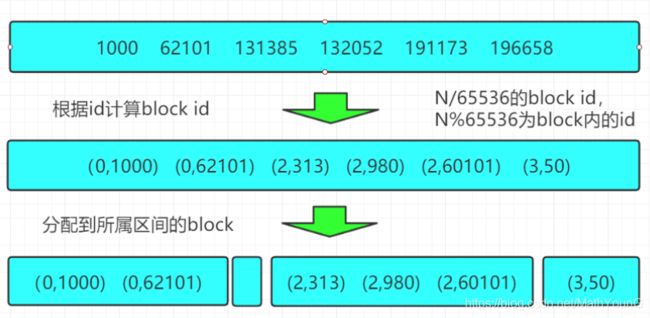
至于4096这个分界线,因为当数量小于4096的时候,如果用bitmap就需要8kB的空间,而使用2个字节的数组空间消耗就要少一点。比如只有2048个值,每个值2字节,一共只需要4kB就能保存,但是bitmap需要8kB。
由此见得,Elasticsearch使用的倒排索引确实比关系型数据库的B-Tree索引快。
注意:一个Lucene索引(也就是一个elasticsearch分片)不能处理多于21亿篇文档,或者多于2740亿的唯一词条。但达到这个极限之前,我们可能就没有足够的磁盘空间了!
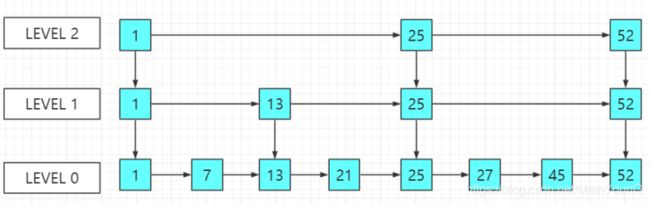
5.2.4 倒排索引如何做联合索引
上面说了半天都是单field索引,如果多个field索引的联合查询,倒排索引如何满足快速查询的要求呢?
利用跳表(Skip list)的数据结构快速做“与”运算,或者
利用上面提到的bitset按位“与”
先看看跳表的数据结构:
将一个有序链表level0,挑出其中几个元素到level1及level2,每个level越往上,选出来的指针元素越少,查找时依次从高level往低查找,比如45,先找到level2的25,最后找到45,查找效率和2叉树的效率相当,但也是用了一定的空间冗余来换取的。
假设有下面三个posting list需要联合索引:
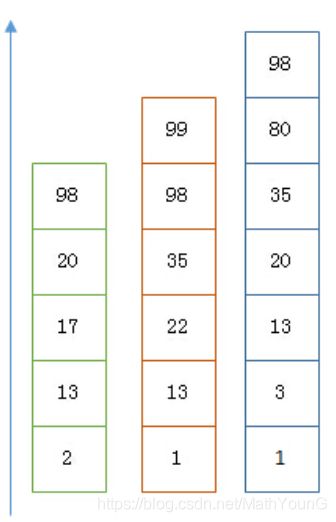
如果使用跳表,对最短的posting list中的每个id,逐个在另外两个posting list中查找看是否存在,最后得到交集的结果。
如果使用bitset(基于bitMap),就很直观了,直接按位与,得到的结果就是最后的交集。
注意,这是我们倒排索引实现联合索引的方式,不是我们ES就是这样操作的。
总结和思考
Elasticsearch的索引思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
所以,对于使用Elasticsearch进行索引时需要注意:不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
同样的道理,对于String类型的字段,不需要analysis(分词)的也需要明确定义出来,因为默认也是会analysis的
选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询
关于最后一点,个人认为有多个因素:
其中一个(也许不是最重要的)因素: 上面看到的压缩算法,都是对Posting list里的大量ID进行压缩的,那如果ID是顺序的,或者是有公共前缀等具有一定规律性的ID,压缩比会比较高;另外一个因素: 可能是最影响查询性能的,应该是最后通过Posting list里的ID到磁盘中查找Document信息的那步,因为Elasticsearch是分Segment存储的,根据ID这个大范围的Term定位到Segment的效率直接影响了最后查询的性能,如果ID是有规律的,可以快速跳过不包含该ID的Segment,从而减少不必要的磁盘读次数,具体可以参考我们的课程,如何选择一个高效的全局ID方案。
拓展:
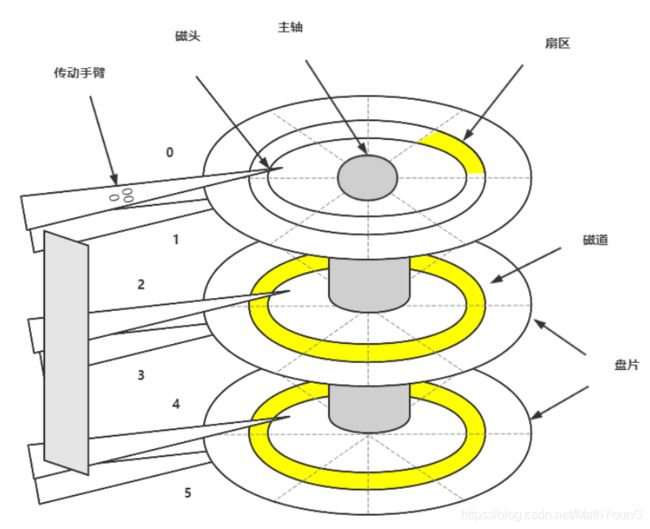
一 磁盘物理结构
- 盘片:硬盘的盘体由多个盘片叠在一起构成。
在硬盘出厂时,由硬盘生产商完成了低级格式化(物理格式化),作用是将空白的盘片(Platter)划分为一个个同圆心、不同半径的磁道(Track),还将磁道划分为若干个扇区(Sector),每个扇区可存储128×2的N次方(N=0.1.2.3)字节信息,默认每个扇区的大小为512字节。通常使用者无需再进行低级格式化操作。
- 磁头:每张盘片的正反两面各有一个磁头。
- 主轴:所有磁片都由主轴电机带动旋转。
- 控制集成电路板:复杂!上面还有ROM(内有软件系统)、Cache等。
二 磁盘如何完成单次IO操作
- 寻道
当控制器对磁盘发出一个IO操作命令的时候,磁盘的驱动臂(Actuator Arm)带动磁头(Head)离开着陆区(Landing Zone,位于内圈没有数据的区域),移动到要操作的初始数据块所在的磁道(Track)的正上方,这个过程被称为寻道(Seeking),对应消耗的时间被称为寻道时间(Seek Time);
- 旋转延迟
找到对应磁道还不能马上读取数据,这时候磁头要等到磁盘盘片(Platter)旋转到初始数据块所在的扇区(Sector)落在读写磁头正下方之后才能开始读取数据,在这个等待盘片旋转到可操作扇区的过程中消耗的时间称为旋转延时(Rotational Delay);
- 数据传送
接下来就随着盘片的旋转,磁头不断的读/写相应的数据块,直到完成这次IO所需要操作的全部数据,这个过程称为数据传送(Data Transfer),对应的时间称为传送时间(Transfer Time)。完成这三个步骤之后单次IO操作也就完成了。根据磁盘单次IO操作的过程,可以发现:
单次IO时间 = 寻道时间 + 旋转延迟 + 传送时间
三 数据库中的磁盘读写
1 随机访问和连续访问
-
随机访问(Random Access)
指的是本次IO所给出的扇区地址和上次IO给出扇区地址相差比较大,这样的话磁头在两次IO操作之间需要作比较大的移动动作才能重新开始读/写数据。也就是遍历的东西比较多。
-
连续访问(Sequential Access)
相反的,如果当次IO给出的扇区地址与上次IO结束的扇区地址一致或者是接近的话,那磁头就能很快的开始这次IO操作,这样的多个IO操作称为连续访问。也就是遍历的东西比较少。
-
以SQL Server数据库为例
数据文件,SQL Server统一区上的对象,是以extent(88k)为单位进行空间分配的,数据存放是很随机的,哪个数据页有空间,就写在哪里,除非通过文件组给每个表预分配足够大的、单独使用的文件,否则不能保证数据的连续性,通常为随机访问。另外哪怕聚集索引表,也只是逻辑上的连续,并不是物理上。日志文件,由于有VLF的存在,日志的读写理论上为连续访问,但如果日志文件设置为自动增长,且增量不大,VLF就会很多很小,那么就也并不是严格的连续访问了。
2 顺序IO和并发IO
-
顺序IO模式(Queue Mode)
磁盘控制器可能会一次对磁盘组发出一连串的IO命令,如果磁盘组一次只能执行一个IO命令,称为顺序IO;
-
并发IO模式(Burst Mode)
当磁盘组能同时执行多个IO命令时,称为并发IO。并发IO只能发生在由多个磁盘组成的磁盘组上,单块磁盘只能一次处理一个IO命令。
-
以SQL Server数据库为例
有的时候,尽管磁盘的IOPS(Disk Transfers/sec)还没有太大,但是发现数据库出现IO等待,为什么?通常是因为有了磁盘请求队列,有过多的IO请求堆积。
SSD是没有所谓的盘片的所以省去了寻道时间以及旋转延迟的,所以使用起来时间消耗较小。但是他还是存在顺序读以及随机读。所以,当我们的IO请求次数过多的时候,我们就会想到采用多路查找树,也就是我们的B树,或者他的优化版,B+树。
文件组给每个表预分配足够大的、单独使用的文件,否则不能保证数据的连续性,通常为随机访问。另外哪怕聚集索引表,也只是逻辑上的连续,并不是物理上。日志文件,由于有VLF的存在,日志的读写理论上为连续访问,但如果日志文件设置为自动增长,且增量不大,VLF就会很多很小,那么就也并不是严格的连续访问了。