论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection
目录
深度霍夫变换语义直线检测
摘要
1,引言
2,相关工作
3,方法
3.1直线参数化和反转
3.2 深度霍夫变换的特征变换
3.3 在参数空间上进行直线检测
3.4 反转映射
3.5 边缘导向的线细化
4 提出的评价指标
4.1回顾现存的评价指标
4.2 我们提出的评价指标
5 NKL:一个语义线检测数据集
5.1 数据的收集和标注
5.2 数据集统计
6 实验
6.1 实现细节
6.2 评估方案
6.3 调整量化间隔
6.4 定量比较
6.6 Ablation Study
7 结论
深度霍夫变换语义直线检测
主页:https://mmcheng.net/dhtline/
论文:http://mftp.mmcheng.net/Papers/21PAMI-DHT-line.pdf
代码:https://github.com/Hanqer/deep-hough-transform
摘要
我们专注于一项基础检测任务即检测有意义的直线结构(语义直线),在自然场景中。许多之前的方法都是把语义直线的检测当做是目标检测的一种特例来处理或者是修改传统的目标检测来做语义直线检测。这些方法都忽视了直线的固定特征,导致次优的表现。直线相比复杂的目标具有更简单的几何特性,因此直线可以用一些参数来进行参数化表示。为了更好的利用直线的特性,在本文中,我们将经典的霍夫变换与深度学习相结合,提出了一种one-shot end-to-end的直线检测learning framework.通过带有坡度角和偏置的参数化表示,我们使用霍夫变换来将深度表示转换道参数域中,在参数域中我们进行直线的检测。具体地,我们是沿着特征图平面上的候选直线来聚合特征,然后将聚合的特征分配到餐数据中的相应位置。因此在空间域中检测语义线的问题就转化为了参数域中检测各个点,使得后处理步骤(即NMS)更有效。此外,我们的方法对直线上下文特征更容易,直线上下文特征的提取对精准的直线检测是很重要的。除了提出的这些方法以外,我们还设计了一种评估直线检测的质量的方法,而且还为直线检测的任务构建了一个大的数据集。在我们自己的数据集上和其他公开的数据集上的实验结果都显示出我们方法相较于之前SOTA方案的优势。数据集和源码可以在这下载 https://mmcheng.net/dhtline/
1,引言
在数字图像中检测直线结构在计算机视觉领域有着很长的历史。线结构组织是一个早期的非常重要的步骤,对于将视觉限号转换成有用的视觉解释的中间概念[2]。尽管有许多用来检测显著对象和区域的方法被提出来[3,4,5,6,7],但是检测突出的线结构的工作很好。[11]一个最近的研究提出检测突出的直线被称为“语义线”,概述了自然图像中的结构概念。证明了这些语义线对于计算机图形学和视觉应用是非常重要的,例如摄影构图【12,13】,结构不变性的图像处理【14,15】,图像美学【16,17,18,19】,车道线检测【20】,和艺术创作【21,22,23,24】。如图1所示Liu et al.【12】提出了建议使用“突出线”根据黄金比例切割图像。检测这些语义线可以帮助我们生成在摄影构图中是视觉效果好的图像。
霍夫变换【25,26】是一种典型的直线检测的方法,它首次提出是用来检测气泡房间图片中的直线【27】,因为他的简单和高效性,HT被用来检测数字图像中的线【25】,并且【26】进一步扩展用来检测其他规则的形状像圆,矩形。HT的关键思路是从图像域到参数域的投票,并且接着在参数域上通过识别局部最大响应检测形状。在进行直线检测时,图像域中的一条直线可以被他的参数表示,例如,参数空间中的斜率和截距。HT在一个图像中沿着一条直线收集证据,并且将证据积累到参数空间中的一个点上。因此在图像域上的直线检测就被转变为在参数域上检测峰值响应的问题。传统的HT基于直线检测器【28,29,30,31】通常检测连续的直的边缘而忽略线结构的语义。此外这些方法对光线变化和遮挡都非常敏感。因此,结果经常是有噪声的并且包含无关的线,如图1(d).
CNN在各种计算机视觉任务中都取得了显著成功。以前的几项研究【11,34】已经提出了基于CNN方法的直线检测。具体的,他们把直线检测作为目标检测的特例并且使用现有的目标检测器,例如,faster-rcnn【35】或者CornerNet[36],受限于ROI Pooling和NMS【11】【34】都是非常低效的。此外,ROI Pooling 沿着一条单独的线聚合特征,而许多之前的研究表明丰富的上下文信息对很多任务都是至关重要的。例如,video classification 和Semantic segmentation.这一点将在Sec6.6中被验证,在这一节中实验证明仅仅沿着一条大度的直线聚合特征将产生次优的结果。
将强大的CNNs融入到霍夫变换中是一个非常有希望的方向对于语义线检测来说。一个简单的结合CNN和HT的方法是使用基于CNN的边缘检测器【40,41】进行边缘检测并且接着将标准的霍夫变换应用于边缘图中。但是这两个部分有不同的优化目标,导致次优的结果,经过我们实验证明。在本文中,我们提出一种将CNN和HT转换成一个端到端的方式,这样在我们提出 的方法中每一个部分都共享一个共同的优化目标。我们的方法首先基于CNN编码提取像素表示,接着在深度表示上进行HT来将表示从特征空间转换到参数空间上。然后全局直线检测问题被转换成在转换后的特征上简单的检测峰值响应。使得问题更简单。例如,NMS被计算参数空间中相连区域的中心替代,使得我们的方法非常高效,从而可以实时的检测直线。此外,在检测阶段,我们在转换后的特征上使用了好几个卷积层来聚合附近的线的上下文感知特征。因此,最终的决定不仅是根据一条线的特征,而是根据附近线的信息。图1(c)上显示,我们的方法检测出干净,有意义的,显著的线,这些线对于摄影构图是有帮助的。
为了更好的评估直线检测方法,我们引进了一个有原则的指标来评估检测到的直线的表现。尽管【11】已经提出了一种评估度量的方法,即用交叉区域来测量一对直线的相似度,这个方法可能会导致模糊和误导性的结果。最后我们收集了一个包含6500张精心标注的图像用于语义线的检测。新的数据集我们namely NKL (short for NanKai Lines),包含了各种场景图像并且比现有的数据集SEL【11】的图像和标注线都大。
本文的贡献总结如下:
- 本文提出了一种端到端的framwork,将CNN特征学习能力与霍夫变换相结合,得到一个有效实时的语义线检测方案。
- 为了促进语义线检测的研究,我们构件了一个6500张图像的数据集,这个数据集更大更多样相比以前的SEL数据集【11】
- 我们引进了一种两条直线相似度评估的原则指标。与以往的基于IOU的指标进行比较,我们的度量标准有直接的解释和更简单的实现,细节在Sec4.
- 在开放基准上的评估结果表明,我们的方法优于现有技术。
这项工作的初步版本是在【1】中。在这个改进工作中,我们介绍了三个主要的改进方案:
- 我们提出了一种新的“边缘导向细化”的模块,利用精准的边缘信息来调整线的位置,并或得更好的检测性能。这一部分详细见Sec3.5
- 我们引入了一个新的用于语义线检测的大规模数据集。如Sec5所述。新的数据集叫做NKL(NanKai Lines),总共包含6500张图,每张图都被标注。
- 在评估阶段我们使用the maximal bipartite graph matching[42]来匹配GT和检测到的直线(Sec6).匹配过程消除冗余的true positives,使得每条GT直线最多与一条检测到的线相关联,反之亦然。
本文的其余部分组织如下:Sec2 总结了相关工作。Sec3 详述了所提出的深度霍夫变换方法。Sec4 描述了所提出的评估指标,用来评价一对儿直线间的相似度。Sec 5 介绍了我们新的数据集。Sec6 给出了实验细节和实验结果。Sec7 总结结论。
2,相关工作
首先我们介绍了一下霍夫变换的演变工程,接着我们又介绍了集中基于CNN的线检测方法,最后我们总结了语义线检测的方法和数据集。
2.1霍夫变换
2.2线分割检测
2.3基于CNN的线检测
2.4语义线检测
3,方法
本节,我们详细介绍提出的深度霍夫变换语义线检测的实现细节,我们的方法主要包括如下四个部分:
- 一个CNN编码器,这一部分提取出像素深度表示
- DHT,这一部分是将深度表示从空间域转化到参数域中
- 直线检测器,该直线检测器在参数空间中检测直线是可靠的’
- 反向霍夫变换(RHT),将检测到的直线还原回图像上
所有的部分都被集成在一个端到端的框架中,一步实现前向推理和方向训练。Pipeline在下图2中被描述,详细的建构显示在补充的资料中。
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第1张图片](http://img.e-com-net.com/image/info8/f938fb9ba765410c9ad21d427194a268.jpg)
3.1直线参数化和反转
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第2张图片](http://img.e-com-net.com/image/info8/f2e3c7ed9f764308b04e53dce24e3a30.jpg)
图3中所示给出一个2D图![]() ,我们设置图像的中心为原点。在2D平面上,一个直线
,我们设置图像的中心为原点。在2D平面上,一个直线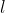 可以用两个参数来表示:
可以用两个参数来表示:
一个是方向参数![]() 表示和x-axis间的夹角;
表示和x-axis间的夹角;
一个是距离参数![]() 指和原点间的距离。
指和原点间的距离。
显然,有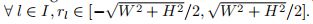
给定一个图I上任意直线,我们都可以进行参数化,相反给定一堆有效的![]() 我们也可以将其反转为I上的一条直线。我们将线到参数以及其逆映射定义为如下式子:
我们也可以将其反转为I上的一条直线。我们将线到参数以及其逆映射定义为如下式子:

显然,![]() 是双射线映射。实际上,
是双射线映射。实际上,![]() 会被量化为离散的值以便于计算机程序的处理。假设
会被量化为离散的值以便于计算机程序的处理。假设![]() 的量化间隔是
的量化间隔是![]() 然后量化公式如下:
然后量化公式如下:

这里的![]() 是量化后的直线参数。量化水平的数量用
是量化后的直线参数。量化水平的数量用![]() 表示,如下:
表示,如下:

如图4(a)所示。
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第3张图片](http://img.e-com-net.com/image/info8/e1a377ca32194dc4920f58cb1a12d8d9.jpg)
3.2 深度霍夫变换的特征变换
3.2.1 深度霍夫变换
给定一个输入图像I,我们首先用品那个编码器网络提取深度CNN特征![]() 这里C是通道数,H和W是空间大小,然后,DHT把X作为输入生成转换后的特征,
这里C是通道数,H和W是空间大小,然后,DHT把X作为输入生成转换后的特征,![]() 。转换后特征的尺寸
。转换后特征的尺寸![]() 如式子(3)所描述的量化间隔决定的。
如式子(3)所描述的量化间隔决定的。
如图4(a)所示,给定图像上任意直线,我们沿着聚合所有像素的特征,到参数空间Y中的![]()

其中i是位置索引![]() 被直线的参数决定如式子(1),然后被梁华成离散的网格如式子(2)。
被直线的参数决定如式子(1),然后被梁华成离散的网格如式子(2)。
给定量化水平![]() 的数量,我们有
的数量,我们有![]() 个特殊的候选线,然后将DHT应用于这些候选线,他们各自的特征被聚合到Y中的相应位置。值得注意的事,DHT在特征空间和参数空间都是order-agnostic的。使其具有高度可并行性。
个特殊的候选线,然后将DHT应用于这些候选线,他们各自的特征被聚合到Y中的相应位置。值得注意的事,DHT在特征空间和参数空间都是order-agnostic的。使其具有高度可并行性。
3.2.2 带有FPN的多尺度DHT
我们提出的DHT可以很容易的应用于任意特征空间。我们使用FPN作为我们的编码器。FPN可以帮助提取多尺度的丰富的语义特征。
尤其是,FPN输出4个特征图![]() 并且他们的分辨率分别为输入分辨率的1/4,1/8,1/16,1/16。每个特征图都独立由DHT模块进行转换,如图2所示。因为这些特征图分辨率不同,所以转换后的特征
并且他们的分辨率分别为输入分辨率的1/4,1/8,1/16,1/16。每个特征图都独立由DHT模块进行转换,如图2所示。因为这些特征图分辨率不同,所以转换后的特征![]() 尺寸不同,因为我们在所有阶段使用相同的量化间隔(如式子(3))。为了使得转换后的特征可以融合,我们将
尺寸不同,因为我们在所有阶段使用相同的量化间隔(如式子(3))。为了使得转换后的特征可以融合,我们将![]() 进行插值计算到
进行插值计算到![]() 的尺寸,并进行concate.
的尺寸,并进行concate.
3.3 在参数空间上进行直线检测
3.3.1具有上下文感知功能的直线检测器
在DHT之后,特征被转换到参数空间,在参数空间里,网格位置![]() 对应于特征空间中沿着一整条线
对应于特征空间中沿着一整条线![]() 的特征。将特征转换到参数空间下的一个重要原因是直线结构可以更紧凑的被表示,如图4(b)所示,特定直线附近的线被转换为邻域内的点
的特征。将特征转换到参数空间下的一个重要原因是直线结构可以更紧凑的被表示,如图4(b)所示,特定直线附近的线被转换为邻域内的点![]() 因此,在参数空间中使用卷积层可以有效的聚合邻近的直线的特征。
因此,在参数空间中使用卷积层可以有效的聚合邻近的直线的特征。
在FPN的每一阶段,我们用两个3*3的卷积层来聚合上下文直线特征。因然后我们进行插值特征来匹配不同阶段特征的分辨率,如图2所示,并且concate插值后的特征。最后使用一个1*1的卷积层来进行特征图的连接以供点态的预测。
3.3.2 损失函数
因为预测是直接在参数空间中进行,我们也在相同的空间中计算loss.对于一个训练的图像I,它的GT lines首先被转换到参数空间中用标准的霍夫变换。然后为了快速收敛,我们使用高斯核对GT进行平滑和expand处理。类似的tricks已经被用在了很多任务中像crowed counting[64,65]和roadsegmentation【66】。设G是GT map在参数空间中的二进制mask.。![]() 表示在参数空间i,j这个位置上有一条直线。expand后的GT图是
表示在参数空间i,j这个位置上有一条直线。expand后的GT图是
![]()
这里边K是一个5*5的高斯核并且![]() 为卷积运算。平滑后的GT和预测图如图2中所示。
为卷积运算。平滑后的GT和预测图如图2中所示。
最后我们计算smoothed GT 和predicted map在参数空间的交叉熵:
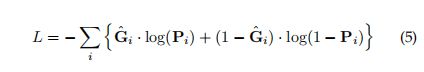
3.4 反转映射
我们的检测器在参数空间中产生预测值,来表示线存在的概率。然后预测概率图使用一个概率阈值(例如0.01)进行二值化。然后我们找到每一个连通域,并且计算连通域的中心。这些中心就被看作是检测到的直线的参数。最后,所有的直线都通过![]() 被映射回图空间上如公式(1)。我们将“反向映射”步骤称为霍夫变换的反映社(RHT),如图2所示。
被映射回图空间上如公式(1)。我们将“反向映射”步骤称为霍夫变换的反映社(RHT),如图2所示。
3.5 边缘导向的线细化
语义线是分割场景中不同区域的显著结构。因此,边缘可能作为语义线的指标。我们提出利用边缘信息来调整线的位置来优化检测结果。首先,我们用HED【41】计算一个边缘图E,然后指定一条检测到的直线的边缘密度被定义为沿直线的平均边缘响应:

这里的![]() 是在直线上像素的数量。为了保证稳定性,我们在线的两边加宽了一个像素(总宽3个像素)当计算公式(6)时。
是在直线上像素的数量。为了保证稳定性,我们在线的两边加宽了一个像素(总宽3个像素)当计算公式(6)时。
设L是邻近的一组线,这些线是通过顺时针和逆时针移动线的端点![]() 个像素获得。因为有两个端点并且每一个端点都有
个像素获得。因为有两个端点并且每一个端点都有![]() 个可能的位置,那么L的大小即为
个可能的位置,那么L的大小即为![]()
![]() 。然后就可以实现细化了通过从L中找到边缘密度最高的最佳线
。然后就可以实现细化了通过从L中找到边缘密度最高的最佳线![]() 。
。
![]()
这一步“edge-guided line refinement”with diffrent ![]() is recorded in Sed 6.6.2.
is recorded in Sed 6.6.2.
4 提出的评价指标
我们详细阐述了所提出的测量图像中两条直线建相似度的评价指标。首先,我们回顾了在计算机视觉领域中广泛使用的几个指标,并且接着阐述了为什么这些已有的评价指标都不是很适合我们的任务,最后引进我们最新提出的指标,计算两条线的一致性考虑了欧式距离和角度距离。
4.1回顾现存的评价指标
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第4张图片](http://img.e-com-net.com/image/info8/e757f52ceea44c5c825387098e09a1bb.jpg)
IOU被广泛用于目标检测,语义分割和很多其他任务中来甲酸检测到的BBOX和GT间的一致性。【11】采用了原始的IOU进行直线检测,并且提出基于线的IOU来计算检测到的线的质量。具体的两条线之间的相似度是用线的相交区域除以图像区域来测量,详见附图5(a)是一个例子,线m和n的相似度是![]() 。
。
但是我们认为,这种基于IOU的评价方式是不恰当的,在特定的情况下可能会导致不合理或模糊的结果。如图5(a)所展示,两对儿线(m,n 和p,q)有相似的结构,可能有非常不同的IOU分数。在图5(b)中,即使是人也无法决定那部分区域(红色或蓝色)应该被认为是交叉区域。
还有其他的评价指标,例如Earth Move‘是Distance(EMD)距离【67】和Chamfer distance(CD)[68],这些都可以用来评价直线的相似度,但是这些指标需要将线转化为相似,然后计算像素级的距离,效率较低。
为了改善这些缺陷,我们提出了一种简单有效的评价指标,在参数空间来计算两条直线的相似度。我们 提出的方法相比EMD和CD更高效,在Sec6.4中定量的比较证明我们提出的度量方法的结果与EMD和CD非常相近。
4.2 我们提出的评价指标
我们提出的评价指标,被称为EA-score,同时考虑了一对线的欧氏距离和角度距离。设![]() 是一对儿带计算的线,角度距离
是一对儿带计算的线,角度距离![]() 被定义为两条直线间的角度:
被定义为两条直线间的角度:
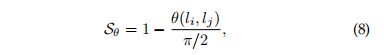
式子![]() 是
是![]() 间的角度,欧式距离被定义为:
间的角度,欧式距离被定义为:
![]()
式子![]() 是
是![]() 中点的欧氏距离。请注意,我们在计算
中点的欧氏距离。请注意,我们在计算![]() 之前会将图像标准化为一个单位正方形。
之前会将图像标准化为一个单位正方形。![]() 的例子如图5(c)和图5(d)。最后,我们提出的EA-score为:
的例子如图5(c)和图5(d)。最后,我们提出的EA-score为:
![]()
公式(10)是平方,使其在值较大时更敏感和具有辨别力。
图6中展示了几个示例线对儿和其对应的EA-score。
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第5张图片](http://img.e-com-net.com/image/info8/265ab1980df5482f99a8e97ef0dfc89d.jpg)
5 NKL:一个语义线检测数据集
据我们所致,只有一个数据集。SEL【11】,专门用于语义线检测。SEL包含了1715个图像,其中175个图像作为测试集其余用于训练。为了满足base cnn的大型模型与现有数据规模间的差距,我们收集了一个新的数据集用来进行语义线检测。
新数据集叫做NKL(short for NanKai Lines),包含6500个图像,有更丰富多样的场景和线。NKL每个图像都由多个熟练的人工标注员进行标注,以确保标注的质量。
5.1 数据的收集和标注
NKL中所有的图均通过关键词在互联网上爬取得到,例如:海洋,草地等等。在获取版权之后,我们仔筛选我们的图像保证至少存在一条语义线。因为语义线的标注时主观的,并且依赖于标注员,每张图像首先由3个knowledgeable human annotators 进行标注,并由其他人进行检验。只有当3个annotator均认同的线才被认为是positive。然后由另外两个annotator进行reviewed意见不一致的线。总之,一条线被至少3个至多5个annotator标注,并且一条线至少被3个annotator标记位positive。
5.2 数据集统计
5.2.1 图和语义线的数量
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第6张图片](http://img.e-com-net.com/image/info8/efd187da76384715b10da080e4a32e2c.jpg)
在NKL中总共有13148个语义线,在SEL【11】数据集中有2791个语义线。表1阐述了两个数据集中图像和语义线的数量。
图8中总结了NKL和SEL[11]数据集中每张图像上线数的直方图。在NKL数据集中有一半多的图像上有多条语义线,而在SEL中的比例仅仅是45.5%。
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第7张图片](http://img.e-com-net.com/image/info8/60f0b060639e4c8daa46ad9ae89612f0.jpg)
5.2.2 多元性统计
为了统计数据集SEL和NKL的多元性,我们把所有的图像feed 进在Place365上训练的ResNet50中,并且把预测结果作为类别标签,结果如图9所示
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第8张图片](http://img.e-com-net.com/image/info8/3ca4615b57e34e83a042c522fbb60922.jpg)
在Place365【70】数据集中共有365个类别,其中我们在SEL数据集上有167个唯一标签,在NKL上有327个。
此外,也如图9所示,与SEL数据集相比,NKL数据及上的场景标签可以更平均的分布。
6 实验
本节中我们将介绍我们系统的实现细节,并且与现有方法的实验结果进行比较。
6.1 实现细节
我们的系统用PyTorch框架实现,也提供了一个Jittor的实现。因为,我们提出的DHT是高度可并行的,因此我们实现DHT用本地CUDA编程,并且所有其他的部分都是基于框架级别的PythonAPI来实现的。我们使用了一块RTX2080TiGPU来完成所有的实验。
6.1.1 网络结构
我们使用了两种有代表性的网络架构 ResNet50和VGG16作为backbone,并且FPN来提取多尺度深度表示。
对于ResNet网络,按照以前的做法【74,75,76】最后一层使用dilated convolution[77]来增加特征图的分辨率。在网络上中也采用了常用的BN【78】。这个dilated convolution 和BN可以由【79,80】在未来的工作中进行调整。
6.1.2 超参数
Gaussian kenel 在Sec 3.3.2中用的尺寸是5*5 的。所有的图被resize到(400,400),然后打包成8de mini-batch.我们所有模型的训练都采用Adam optimizer without weight decay训练30个epochs。learning rate 和 momentum分别设置为![]() 。量化间隔
。量化间隔![]() 将在Sec6.3和公式(12)详细说明。
将在Sec6.3和公式(12)详细说明。
6.1.3 数据和数据增强
我们的实验实在数据集SEL和我们自己提出的数据集NKL上进行的。两个数据集已经在Sec5中进行了详细统计。按照文章【11】中的设置,我们在实验中仅仅做了左右翻转的数据增强。
6.2 评估方案
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第9张图片](http://img.e-com-net.com/image/info8/b754967de4284c5db75db2dd43fb6908.jpg)
我们从precision,recall,F-measure三个值来计算检测直线的质量。第一步是匹配检测到的直线和GT直线。
设![]() 分别是两组检测到的直线和GT。
分别是两组检测到的直线和GT。![]() 是一条检测到的和GT line。我们首先基于bipartite matching(二分图)来匹配
是一条检测到的和GT line。我们首先基于bipartite matching(二分图)来匹配![]() 中的lines.假设
中的lines.假设![]() 是一个
是一个![]() (https://en.wikipedia.org/wiki/Bipartite_graph)。顶点集合V可以被分成两个不想交的独立的集合,在我们这里,
(https://en.wikipedia.org/wiki/Bipartite_graph)。顶点集合V可以被分成两个不想交的独立的集合,在我们这里,![]() :
: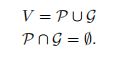
E中的每条边都表示在某种相似度的度量下的一对儿线之间的相似性。除了我们提出的EA-score之外,我们也使用了两个另外两个流行的指标:EMD和CD,如Sec4中所描述。注意,我们归一化EMD和CD的最大可能值使其在[0,1]内(对于EMD和CD,当两条线shrinkage到相反的对角线上的两点时,就会发生最大距离)
给定图![]() ,,二分图中的匹配是,选择出一组边,在这组边里没有两条边共享一个共同的顶点。在我们的任务中,给定预测线的集合P和GT的集合G,我们试图找到一种匹配,使得每一个GT
,,二分图中的匹配是,选择出一组边,在这组边里没有两条边共享一个共同的顶点。在我们的任务中,给定预测线的集合P和GT的集合G,我们试图找到一种匹配,使得每一个GT![]() 对应于唯一一个检测线
对应于唯一一个检测线![]() ,反之亦然。这个问题,一个二分图的最大匹配,可以很容易的用with 多项式时间复杂度的经典的Hungarian method[42]来解决。
,反之亦然。这个问题,一个二分图的最大匹配,可以很容易的用with 多项式时间复杂度的经典的Hungarian method[42]来解决。
在匹配了![]() 之后,我们可以计算TP,FP,FN。如图10所示。与GT线
之后,我们可以计算TP,FP,FN。如图10所示。与GT线![]() 配对的预测线
配对的预测线![]() 被认为是TP,与任何GT线都不匹配的预测线
被认为是TP,与任何GT线都不匹配的预测线![]() 认为是FP,没有相应预测线的GT线
认为是FP,没有相应预测线的GT线![]() 为FN,最后,Precision,Recall和F-measure是:
为FN,最后,Precision,Recall和F-measure是:
![]()
我们对预测和GT对儿使用一些阈值![]() 。因此,我们获得一系列的precision,recall,F-measure分数。最后,我们从平均precision,recall,和F-measure来评估性能。我们使用EMD和CD和我们提出的EA-score评价指标来进行定量比较。在 ablation study中,我们为了简单仅仅使用了EA评价指标。
。因此,我们获得一系列的precision,recall,F-measure分数。最后,我们从平均precision,recall,和F-measure来评估性能。我们使用EMD和CD和我们提出的EA-score评价指标来进行定量比较。在 ablation study中,我们为了简单仅仅使用了EA评价指标。
6.3 调整量化间隔
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第10张图片](http://img.e-com-net.com/image/info8/39da9b5ca0ea486bafbeadfd64c9ea01.jpg)
在公式(2)中的量化间隔![]() 是影响性能和效率的重要因素,量化间隔越大量化等级约少模型也就越快。越小的量化间隔,量化等级就越多计算开销就越重。
是影响性能和效率的重要因素,量化间隔越大量化等级约少模型也就越快。越小的量化间隔,量化等级就越多计算开销就越重。
我们在SEL数据集上执行一个坐标下降法,以找到计算效率和功能有效的适当量化间隔。注意,我们使用EA-score作为线相似度的度量,因为它简单。在第一轮中,我们将角度的量化间隔定为![]() ,然后搜索
,然后搜索![]() 结果如图11(a)所示,关于图11(a),首先缓慢上升然后随着
结果如图11(a)所示,关于图11(a),首先缓慢上升然后随着![]() 的减小而下降,这个转折点大概在
的减小而下降,这个转折点大概在![]() 附近。在第二轮中,我们修复
附近。在第二轮中,我们修复![]() 并且训练不同的
并且训练不同的![]() ,与图11(a)相似,图11(b)中的结果证明首先性能随着
,与图11(a)相似,图11(b)中的结果证明首先性能随着![]() 的下降而平稳增加,然后随震动迅速降低。因此,转折点
的下降而平稳增加,然后随震动迅速降低。因此,转折点![]() 是一个角度量化的合适的选择。
是一个角度量化的合适的选择。
综上,我们用 在量化中,并且响应的量化等级是:
在量化中,并且响应的量化等级是:
![]()
其中,H,W是在DHT要转换的 特征图的大小。
6.4 定量比较
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第11张图片](http://img.e-com-net.com/image/info8/17164a4dd1954b9bb8c271a1dfb8b6c8.jpg)
在这里我们给出了我们方法以及SBLet和HED+HT的结果。如图13所示,与其他方法相比,我们的结果与GT更兼容。除了图13,我们还提供了在补充材料中使用我们的方法和SLNet的所有检测结果。

6.6 Ablation Study
在本节,我们简化我们的方法中的每一个模块。
6.6.1 DHT中的组件
我们首先简化DHT模块。具体地,(a) the Deep Hough transform (DHT) module detailed in Sec. 3.2; (b) the multi-scale (MS) DHT architecture described in Sec. 3.2.2; (c) the context-aware (CTX) line detector proposed in Sec. 3.3.1. Experimental results are shown in Tab. 4.
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第12张图片](http://img.e-com-net.com/image/info8/ce682cb9037d4a048763bc64322cd755.jpg)
6.6.2 Edge-guided Refifinement
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第13张图片](http://img.e-com-net.com/image/info8/c8ee180b102446e5bf832979e35520bd.jpg)
![论文翻译--[TPAMI 2021]Deep Hough Transform For Semantic Line Detection_第14张图片](http://img.e-com-net.com/image/info8/8e239e1fa0a7488397662e1017eca624.jpg)