人工智能 | ShowMeAI资讯日报 #2022.06.28

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
1.工具&框架

工具:DeepGTA - 用于从GTA V游戏中提取机器学习训练数据的系统
tags: [游戏数据,数据提取,机器学习]
‘DeepGTA - A system to easily extract ground truth training data for different machine learning tasks from GTAV’ by David Ott
GitHub: https://github.com/Eisbaer8/DeepGTAV

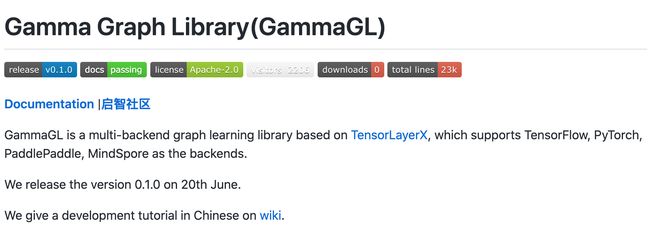
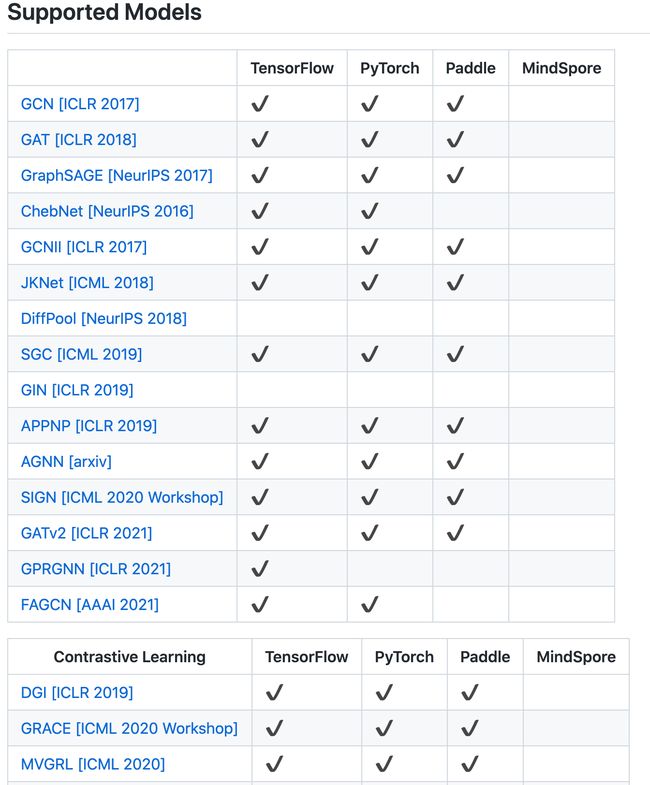
工具库:Gamma Graph Library(GammaGL) - 基于TensorLayerX的多后端图学习库
tags: [图学习,图模型]
‘Gamma Graph Library(GammaGL) - A multi-backend graph learning library.’ by BUPT GAMMA Lab
GitHub: https://github.com/BUPT-GAMMA/GammaGL
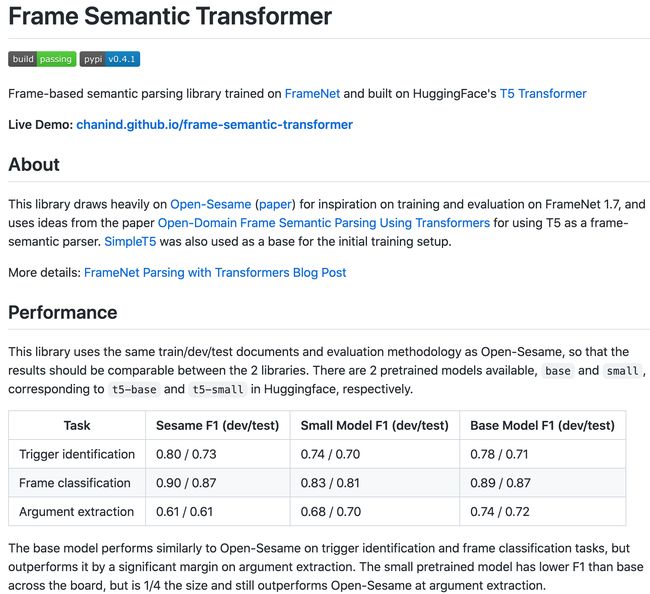
工具库:Frame Semantic Transformer - 基于T5和FrameNet的语义解析
tags: [语义解析,T5,FrameNet]
‘Frame Semantic Parser based on T5 and FrameNet’ by David Chanin
GitHub: https://github.com/chanind/frame-semantic-transformer
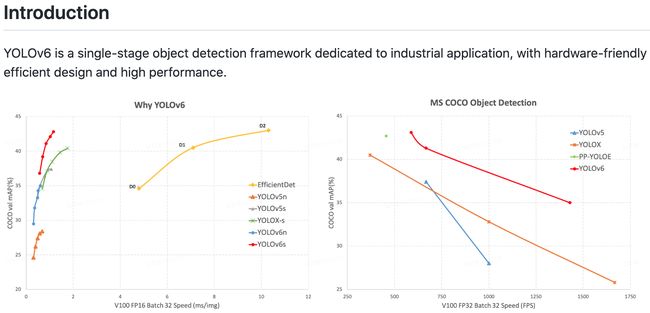
工具库:YOLOv6目标检测实现
tags: [目标检测,YOLO,YOLOv6]
‘YOLOv6: a single-stage object detection framework dedicated to industrial application.’ by Meituan
GitHub: https://github.com/meituan/YOLOv6

工具:Paralus - Kubernete管理工具
tags: [Kubernete,管理]
‘Paralus - an all-in-one Kubernetes access management tool.’ by Paralus Project
GitHub: https://github.com/paralus/paralus
工具:PyTorch零样本NAS工具箱,用于骨干网络搜索
tags: [零样本,NAS,骨干搜索,网络搜索]
‘Lightweight Neural Architecture Search (Light-NAS) - an open source zero-shot NAS toolbox for backbone search based on PyTorch.’ by Alibaba
GitHub: https://github.com/alibaba/lightweight-neural-architecture-search

工具:AiTLAS toolbox - 用于探索和预测分析卫星图像的工具包
tags: [卫星图像,探索分析,预测]
’AiTLAS toolbox - AiTLAS implements state-of-the-art AI methods for exploratory and predictive analysis of satellite images.’ by Bias Variance Labs
GitHub: https://github.com/biasvariancelabs/aitlas

2.博文&分享

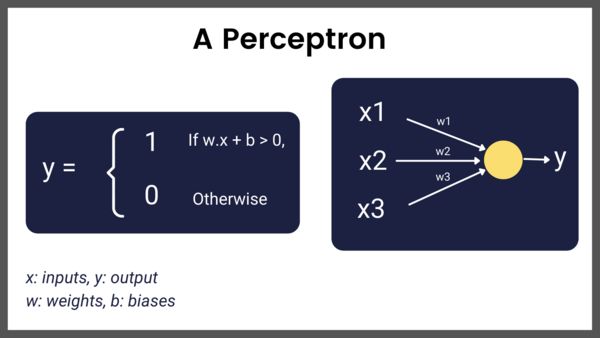
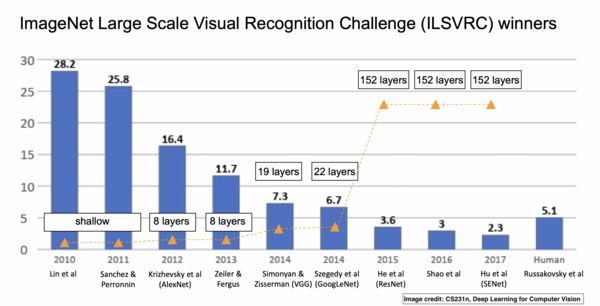
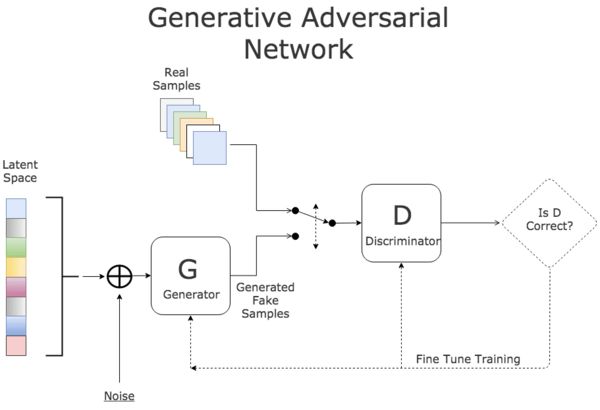
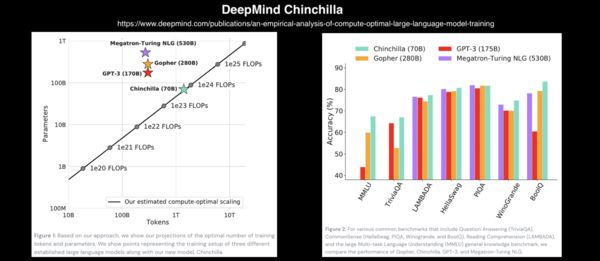
博文:深度学习简史
《A Revised History of Deep Learning | Revue》by Jean de Dieu Nyandwi
Link: https://www.getrevue.co/profile/deeprevision/issues/a-revised-history-of-deep-learning-issue-1-1145664


3.数据&资源

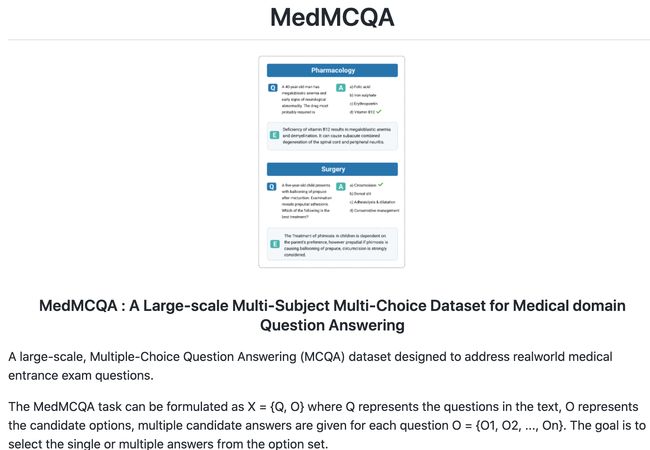
数据集:MedMCQA - 大规模多项选择题问答数据集,旨在解决现实世界的医学入学考试问题
tags: [医学,数据集,医学考试]
‘MedMCQA - A large-scale (194k), Multiple-Choice Question Answering (MCQA) dataset designed to address realworld medical entrance exam questions.’
GitHub: https://github.com/medmcqa/medmcqa
资源列表:说话头部生成相关文献资源列表
tags: [说话,头部图像生成,资源列表]
‘awesome-talking-head-generation’ by Fa-Ting Hong
GitHub: https://github.com/harlanhong/awesome-talking-head-generation

4.研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的6月论文合辑。
论文:Sequential estimation of quantiles with applications to A/B-testing and best-arm identification
论文标题:Sequential estimation of quantiles with applications to A/B-testing and best-arm identification
论文时间:24 Jun 2019
论文地址:https://arxiv.org/abs/1906.09712
代码实现:https://github.com/gostevehoward/confseq , https://github.com/gostevehoward/quantilecs , https://github.com/WLM1ke/poptimizer , https://github.com/wannabesmith/confseq
论文作者:Steven R. Howard, Aaditya Ramdas
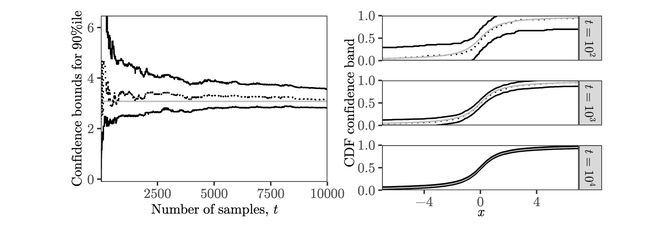
论文简介:We propose confidence sequences – sequences of confidence intervals which are valid uniformly over time – for quantiles of any distribution over a complete, fully-ordered set, based on a stream of i. i. d./我们提出了置信序列 - 随时间一致有效的置信区间序列 - 基于 i.i.d.
论文摘要:We propose confidence sequences – sequences of confidence intervals which are valid uniformly over time – for quantiles of any distribution over a complete, fully-ordered set, based on a stream of i.i.d. observations. We give methods both for tracking a fixed quantile and for tracking all quantiles simultaneously. Specifically, we provide explicit expressions with small constants for intervals whose widths shrink at the fastest possible t−1loglogt rate, along with a non-asymptotic concentration inequality for the empirical distribution function which holds uniformly over time with the same rate. The latter strengthens Smirnov’s empirical process law of the iterated logarithm and extends the Dvoretzky-Kiefer-Wolfowitz inequality to hold uniformly over time. We give a new algorithm and sample complexity bound for selecting an arm with an approximately best quantile in a multi-armed bandit framework. In simulations, our method requires fewer samples than existing methods by a factor of five to fifty.
我们提出了置信序列 - 随时间一致有效的置信区间序列 - 基于 i.i.d.观察。我们给出了跟踪固定分位数和同时跟踪所有分位数的方法。具体来说,我们为宽度以尽可能快的 t−1loglogt 速率收缩的区间提供了具有小常数的显式表达式,以及经验分布函数的非渐近浓度不等式,该分布函数随着时间的推移以相同的速率保持一致。后者强化了 Smirnov 的迭代对数经验过程定律,并将 Dvoretzky-Kiefer-Wolfowitz 不等式扩展为随着时间的推移保持一致。我们给出了一种新的算法和样本复杂度界限,用于在多臂老虎机框架中选择具有近似最佳分位数的臂。在模拟中,我们的方法需要的样本比现有方法少 5 到 50 倍。

论文:SpA-Former: Transformer image shadow detection and removal via spatial attention
论文标题:SpA-Former: Transformer image shadow detection and removal via spatial attention
论文时间:22 Jun 2022
所属领域:计算机视觉
对应任务:Shadow Detection,Shadow Detection And Removal,Shadow Removal,阴影检测,阴影检测和去除,阴影去除
论文地址:https://arxiv.org/abs/2206.10910
代码实现:https://github.com/zhangbaijin/spa-former-shadow-removal
论文作者:Xiao Feng Zhang, Chao Chen Gu, Shan Ying Zhu
论文简介:In this paper, we propose an end-to-end SpA-Former to recover a shadow-free image from a single shaded image./在本文中,我们提出了一种端到端的SpA-Former,以从单一有影子的图像中恢复无阴影图像。
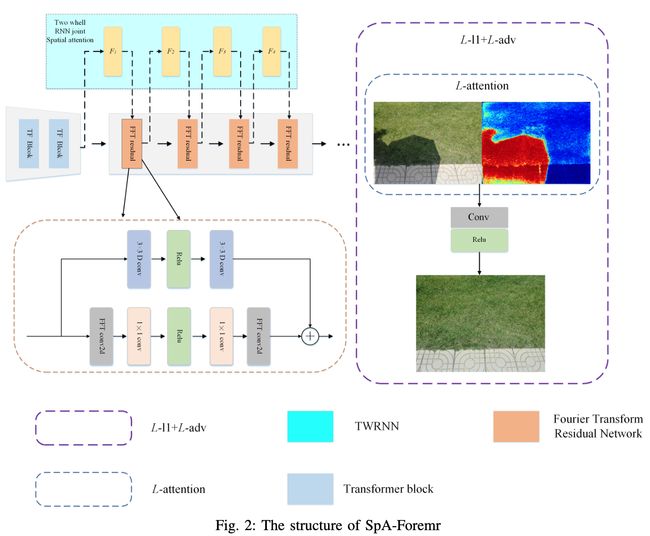
论文摘要:In this paper, we propose an end-to-end SpA-Former to recover a shadow-free image from a single shaded image. Unlike traditional methods that require two steps for shadow detection and then shadow removal, the SpA-Former unifies these steps into one, which is a one-stage network capable of directly learning the mapping function between shadows and no shadows, it does not require a separate shadow detection. Thus, SpA-former is adaptable to real image de-shadowing for shadows projected on different semantic regions. SpA-Former consists of transformer layer and a series of joint Fourier transform residual blocks and two-wheel joint spatial attention. The network in this paper is able to handle the task while achieving a very fast processing efficiency. Our code is relased on https://github.com/zhangbaijin/spa-former-shadow-removal
在本文中,我们提出了一种端到端的SpA-Former,以从单一的有影子图像中恢复出无阴影的图像。与传统的需要两步检测阴影和去除阴影的方法不同,SpA-Former将这些步骤统一为一步,它是一个能够直接学习阴影和无阴影之间映射函数的单阶段网络,它不需要单独的阴影检测。因此,SpA-former能够适应真实图像中投射在不同语义区域上的阴影的去蔽。SpA-former由transformer层和一系列联合傅里叶变换残差块和双轮联合空间注意力组成。本文的网络能够处理该任务,同时达到非常快的处理效率。我们的代码是在 https://github.com/zhangbaijin/spa-former-shadow-removal 上发布。
论文:3D Object Detection for Autonomous Driving: A Review and New Outlooks
论文标题:3D Object Detection for Autonomous Driving: A Review and New Outlooks
论文时间:19 Jun 2022
所属领域:计算机视觉
对应任务:3D Object Detection,Autonomous Driving,object-detection,Object Detection,3D物体检测,自动驾驶,物体检测
论文地址:https://arxiv.org/abs/2206.09474
代码实现:https://github.com/pointscoder/awesome-3d-object-detection-for-autonomous-driving
论文作者:Jiageng Mao, Shaoshuai Shi, Xiaogang Wang, Hongsheng Li
论文简介:Autonomous driving, in recent years, has been receiving increasing attention for its potential to relieve drivers’ burdens and improve the safety of driving./近年来,自主驾驶因其有可能减轻司机的负担并提高驾驶的安全性而受到越来越多的关注。
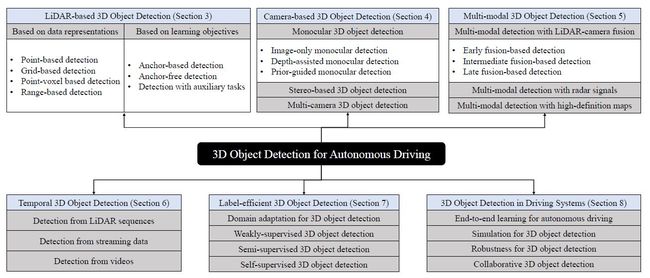
论文摘要:Autonomous driving, in recent years, has been receiving increasing attention for its potential to relieve drivers’ burdens and improve the safety of driving. In modern autonomous driving pipelines, the perception system is an indispensable component, aiming to accurately estimate the status of surrounding environments and provide reliable observations for prediction and planning. 3D object detection, which intelligently predicts the locations, sizes, and categories of the critical 3D objects near an autonomous vehicle, is an important part of a perception system. This paper reviews the advances in 3D object detection for autonomous driving. First, we introduce the background of 3D object detection and discuss the challenges in this task. Second, we conduct a comprehensive survey of the progress in 3D object detection from the aspects of models and sensory inputs, including LiDAR-based, camera-based, and multi-modal detection approaches. We also provide an in-depth analysis of the potentials and challenges in each category of methods. Additionally, we systematically investigate the applications of 3D object detection in driving systems. Finally, we conduct a performance analysis of the 3D object detection approaches, and we further summarize the research trends over the years and prospect the future directions of this area.
近年来,自动驾驶因其有可能减轻驾驶员的负担和提高驾驶的安全性而受到越来越多的关注。在现代自动驾驶流程中,感知系统是一个不可或缺的组成部分,旨在准确估计周围环境的状态,并为预测和规划提供可靠的观测。三维物体检测是感知系统的一个重要组成部分,它可以智能地预测自主车辆附近的关键三维物体的位置、大小和类别。本文回顾了用于自动驾驶的三维物体检测的进展情况。首先,我们介绍了3D物体检测的背景,并讨论了这项工作的挑战。其次,我们从模型和感官输入方面对三维物体检测的进展进行了全面的调查,包括基于LiDAR、基于相机和多模式的检测方法。我们还对每一类方法的潜力和挑战进行了深入分析。此外,我们系统地研究了三维物体检测在驾驶系统中的应用。最后,我们对三维物体检测方法进行了性能分析,并进一步总结了多年来的研究趋势,展望了该领域的未来方向。

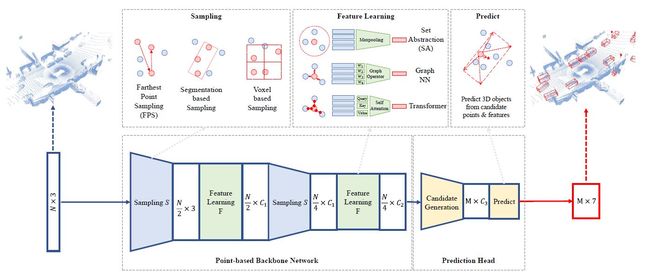
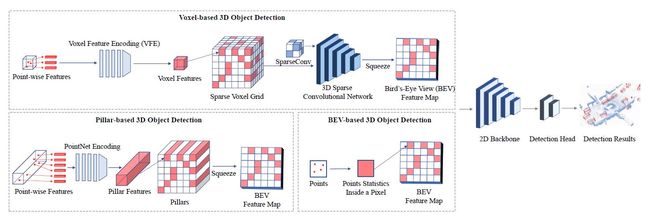
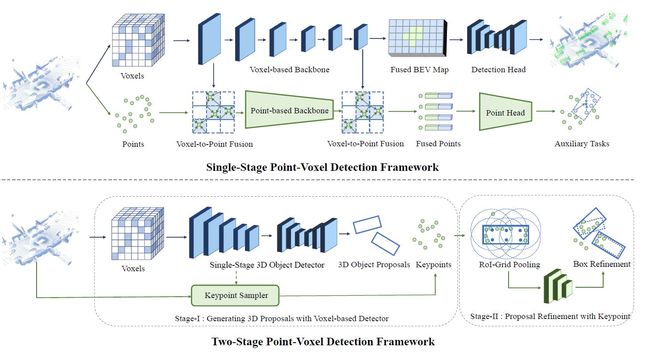
论文:Polar Parametrization for Vision-based Surround-View 3D Detection
论文标题:Polar Parametrization for Vision-based Surround-View 3D Detection
论文时间:22 Jun 2022
所属领域:计算机视觉
对应任务:Inductive Bias,归纳偏置
论文地址:https://arxiv.org/abs/2206.10965
代码实现:https://github.com/hustvl/polardetr
论文作者:Shaoyu Chen, Xinggang Wang, Tianheng Cheng, Qian Zhang, Chang Huang, Wenyu Liu
论文简介:Based on Polar Parametrization, we propose a surround-view 3D DEtection TRansformer, named PolarDETR./基于Polar Parametrization,我们提出了一个环视三维检测TRansformer,命名为PolarDETR。
论文摘要:3D detection based on surround-view camera system is a critical technique in autopilot. In this work, we present Polar Parametrization for 3D detection, which reformulates position parametrization, velocity decomposition, perception range, label assignment and loss function in polar coordinate system. Polar Parametrization establishes explicit associations between image patterns and prediction targets, exploiting the view symmetry of surround-view cameras as inductive bias to ease optimization and boost performance. Based on Polar Parametrization, we propose a surround-view 3D DEtection TRansformer, named PolarDETR. PolarDETR achieves promising performance-speed trade-off on different backbone configurations. Besides, PolarDETR ranks 1st on the leaderboard of nuScenes benchmark in terms of both 3D detection and 3D tracking at the submission time (Mar. 4th, 2022). Code will be released at https://github.com/hustvl/polardetr
基于环视摄像系统的3D检测是自动驾驶的一项关键技术。在这项工作中,我们提出了用于三维检测的极地参数化,它在极地坐标系中重新制定了位置参数化、速度分解、感知范围、标签分配和损失函数。极地参数化在图像模式和预测目标之间建立了明确的联系,利用环视摄像机的视图对称性作为归纳偏向,以简化优化并提高性能。在Polar Parametrization的基础上,我们提出了一个环视三维去伪存真TRansformer,名为PolarDETR。PolarDETR在不同的骨干网配置上实现了有希望的性能-速度权衡。此外,在提交时(2022年3月4日),PolarDETR在nuScenes基准的三维检测和三维跟踪方面都排名第一。代码将在 https://github.com/hustvl/polardetr
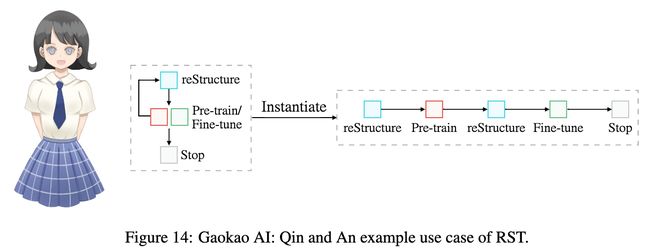
论文:reStructured Pre-training
论文标题:reStructured Pre-training
论文时间:22 Jun 2022
所属领域:自然语言处理
论文地址:https://arxiv.org/abs/2206.11147
代码实现:https://github.com/expressai/restructured-pretraining
论文作者:Weizhe Yuan, PengFei Liu
论文简介:In addition, we test our model in the 2022 College Entrance Examination English that happened a few days ago (2022. 06. 08), and it gets a total score of 134/此外,我们在几天前(2022年6月8日)举行的2022年高考英语中测试了我们的模型,它得到了134分的总分。
论文摘要:In this work, we try to decipher the internal connection of NLP technology development in the past decades, searching for essence, which rewards us with a (potential) new learning paradigm for NLP tasks, dubbed as reStructured Pre-training (RST). In such a paradigm, the role of data will be re-emphasized, and model pre-training and fine-tuning of downstream tasks are viewed as a process of data storing and accessing. Based on that, we operationalize the simple principle that a good storage mechanism should not only have the ability to cache a large amount of data but also consider the ease of access. We achieve this by pre-training models over restructured data that consist of a variety of valuable information instead of raw data after overcoming several engineering challenges. Experimentally, RST models not only surpass strong competitors (e.g., T0) on 52/55 popular datasets from a variety of NLP tasks, but also achieve superior performance in National College Entrance Examination - English (Gaokao-English),the most authoritative examination in China. Specifically, the proposed system Qin achieves 40 points higher than the average scores made by students and 15 points higher than GPT3 with 1/16 parameters. In particular, Qin gets a high score of 138.5 (the full mark is 150) in the 2018 English exam (national paper III). We have released the Gaokao Benchmark with an online submission platform. In addition, we test our model in the 2022 College Entrance Examination English that happened a few days ago (2022.06.08), and it gets a total score of 134 (v.s. GPT3’s 108).
在这项工作中,我们试图破译过去几十年NLP技术发展的内部联系,寻找本质,这给我们带来了NLP任务的(潜在)新的学习范式,被称为重构预训练(RST)。在这种范式中,数据的作用将被重新强调,模型的预训练和下游任务的微调被看作是一个数据存储和访问的过程。在此基础上,我们将一个简单的原则操作化,即一个好的存储机制不仅要有缓存大量数据的能力,还要考虑访问的便捷性。在克服了一些工程上的挑战后,我们通过对由各种有价值的信息组成的重组数据而不是原始数据进行预训练来实现这一目标。通过实验,RST模型不仅在各种NLP任务的52/55个流行数据集上超过了强大的竞争对手(例如T0),而且在中国最权威的考试–全国高考英语(Gaokao-English)中也取得了优异的成绩。具体来说,"秦 "系统比学生的平均成绩高40分,比GPT3(我们的参数只有其1/16)高15分。特别是在2018年的英语考试(全国卷III)中,Qin获得了138.5的高分(满分是150分)。我们发布了具有在线提交平台的Gaokao Benchmark。此外,我们在几天前发生的2022年高考英语中测试了我们的模型(2022.06.08),得到的总分是134分(对比GPT3得了108分)。

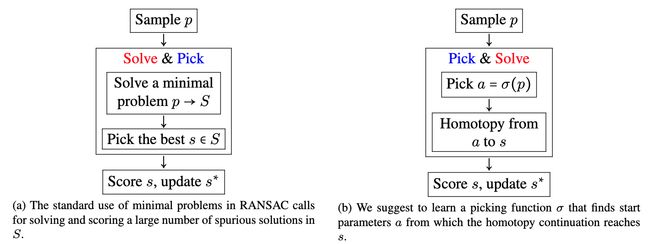
论文:Learning to Solve Hard Minimal Problems
论文标题:Learning to Solve Hard Minimal Problems
论文时间:CVPR 2022
论文地址:https://arxiv.org/abs/2112.03424
代码实现:https://github.com/petrhruby97/learning_minimal
论文作者:Petr Hruby, Timothy Duff, Anton Leykin, Tomas Pajdla
论文简介:The hard minimal problems arise from relaxing the original geometric optimization problem into a minimal problem with many spurious solutions./硬极小问题源于将原始几何优化问题放松为具有许多次级解决方案的极小问题。
论文摘要:We present an approach to solving hard geometric optimization problems in the RANSAC framework. The hard minimal problems arise from relaxing the original geometric optimization problem into a minimal problem with many spurious solutions. Our approach avoids computing large numbers of spurious solutions. We design a learning strategy for selecting a starting problem-solution pair that can be numerically continued to the problem and the solution of interest. We demonstrate our approach by developing a RANSAC solver for the problem of computing the relative pose of three calibrated cameras, via a minimal relaxation using four points in each view. On average, we can solve a single problem in under 70 μs. We also benchmark and study our engineering choices on the very familiar problem of computing the relative pose of two calibrated cameras, via the minimal case of five points in two views.
我们提出了一种在 RANSAC 框架中解决硬几何优化问题的方法。硬极小问题源于将原始几何优化问题放松为具有许多次级解决方案的极小问题。我们的方法避免了计算大量次级解决方案。我们设计了一种学习策略,用于选择可以在数字上继续解决问题和感兴趣的解决方案的起始问题-解决方案对。我们通过开发一个 RANSAC 求解器来演示我们的方法,该求解器通过在每个视图中使用四个点进行最小松弛来计算三个校准相机的相对姿势。平均而言,我们可以在 70 μs 内解决一个问题。我们还通过两个视图中的五个点的最小情况,在计算两个校准相机的相对姿态这一非常熟悉的问题上对我们的工程选择进行基准测试和研究。

论文:OpenHands: Making Sign Language Recognition Accessible with Pose-based Pretrained Models across Languages
论文标题:OpenHands: Making Sign Language Recognition Accessible with Pose-based Pretrained Models across Languages
论文时间:ACL 2022
所属领域:自然语言处理,计算机视觉
对应任务:Sign Language Recognition
论文地址:https://arxiv.org/abs/2110.05877
代码实现:https://github.com/ai4bharat/openhands
论文作者:Prem Selvaraj, Gokul NC, Pratyush Kumar, Mitesh Khapra
论文简介:Third, to address the lack of labelled data, we propose self-supervised pretraining on unlabelled data./第三,为了解决标记数据的缺乏,我们提出在无标记数据上进行自监督的预训练。
论文摘要:AI technologies for Natural Languages have made tremendous progress recently. However, commensurate progress has not been made on Sign Languages, in particular, in recognizing signs as individual words or as complete sentences. We introduce OpenHands, a library where we take four key ideas from the NLP community for low-resource languages and apply them to sign languages for word-level recognition. First, we propose using pose extracted through pretrained models as the standard modality of data to reduce training time and enable efficient inference, and we release standardized pose datasets for 6 different sign languages - American, Argentinian, Chinese, Greek, Indian, and Turkish. Second, we train and release checkpoints of 4 pose-based isolated sign language recognition models across all 6 languages, providing baselines and ready checkpoints for deployment. Third, to address the lack of labelled data, we propose self-supervised pretraining on unlabelled data. We curate and release the largest pose-based pretraining dataset on Indian Sign Language (Indian-SL). Fourth, we compare different pretraining strategies and for the first time establish that pretraining is effective for sign language recognition by demonstrating (a) improved fine-tuning performance especially in low-resource settings, and (b) high crosslingual transfer from Indian-SL to few other sign languages. We open-source all models and datasets in OpenHands with a hope that it makes research in sign languages more accessible, available here at https://github.com/ai4bharat/openhands
自然语言的AI技术最近取得了巨大的进展。然而,在手语方面还没有取得相应的进展,特别是在识别单个单词或完整句子方面。我们介绍了OpenHands,这是一个库,我们从低资源语言的NLP社区获得了四个关键的想法,并将其应用于手语的单词级识别。首先,我们建议使用通过预训练模型提取的姿势作为数据的标准模式,以减少训练时间并实现高效推理,我们发布了6种不同手语的标准化姿势数据集–美国、阿根廷、中国、希腊、印度和土耳其。第二,我们在所有6种语言中训练并发布了4个基于姿势的孤立手语识别模型的检查点,为部署提供基线和准备的检查点。第三,为了解决缺乏标记数据的问题,我们提出在无标记数据上进行自监督的预训练。我们策划并发布了最大的基于姿势的印度手语预训练数据集(Indian-SL)。第四,我们比较了不同的预训练策略,并首次确定预训练对手语识别是有效的,证明了(a)改进了微调性能,特别是在低资源环境下,以及(b)从印度手语到其他少数手语的高跨语言迁移。我们在OpenHands中开放了所有的模型和数据集,希望它能使手语的研究更容易获得,可在这里https://github.com/ai4bharat/openhands


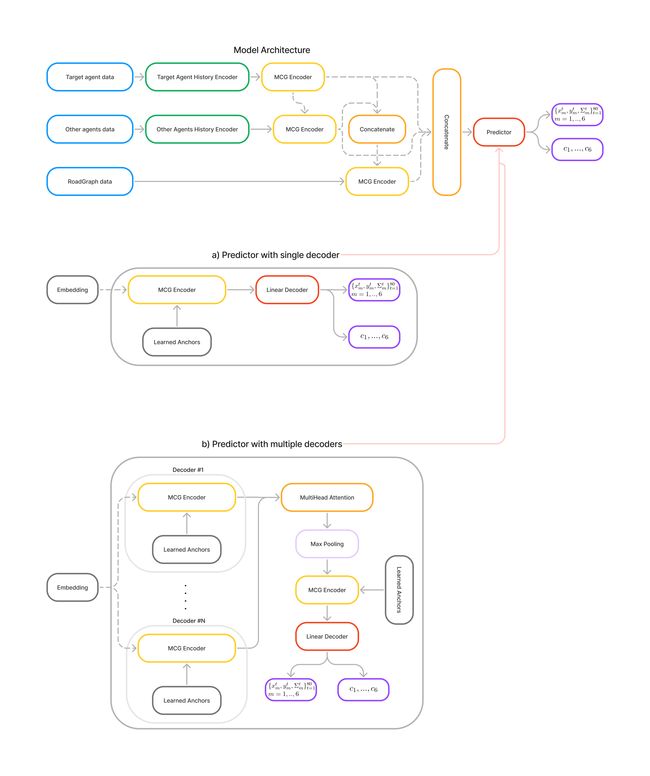
论文:MPA: MultiPath++ Based Architecture for Motion Prediction
论文标题:MPA: MultiPath++ Based Architecture for Motion Prediction
论文时间:20 Jun 2022
所属领域:计算机视觉
对应任务:Autonomous Driving,motion prediction,无人驾驶,运动预测
论文地址:https://arxiv.org/abs/2206.10041
代码实现:https://github.com/stepankonev/waymo-motion-prediction-chalenge-2022-multipath-plus-plus
论文作者:Stepan Konev
论文简介:Autonomous driving technology is developing rapidly and nowadays first autonomous rides are being provided in city areas./自动驾驶技术发展迅速,如今在城市地区提供了第一批自动驾驶汽车。
论文摘要:Autonomous driving technology is developing rapidly and nowadays first autonomous rides are being provided in city areas. This requires the highest standards for the safety and reliability of the technology. Motion prediction part of the general self-driving pipeline plays a crucial role in providing these qualities. In this work we present one of the solutions for Waymo Motion Prediction Challenge 2022 based on MultiPath++ ranked the 3rd as of May, 26 2022. Our source code is publicly available on GitHub.
自动驾驶技术正在迅速发展,如今在城市地区首次提供自动驾驶服务。这需要对该技术的安全性和可靠性采取最高标准。一般自动驾驶流程的运动预测部分在提供这些质量方面起着关键作用。在这项工作中,我们提出了基于MultiPath++的2022年Waymo运动预测挑战赛的解决方案之一,截至2022年5月26日,该方案排名第三。我们的源代码在GitHub上公开提供。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处
- 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~