基于Apriori算法的奖学金获得者特点研究
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
》源代码下载:基于Apriori算法的奖学金获得者特点研究【毕业设计】【关联挖掘】【数据分析】【flask+web】【源代码+演示视频】-CSDN下载
1. 项目简介
高等院校在每年评选奖学金工作中积累大量的数据,本课题将数据挖掘技术中的关联规则挖掘算法Apriori应用于学校学生综合测评中,通过对这些数据分析,找到学生综合测评成绩与学生成绩,学习习惯、方法、生活习惯、兴趣爱好、家庭情况,性别,父母职业,父母教育背景,父母职业,学生在校获奖情况等相关,为学生评优工作,专业教学、课程开设等提供参考依据。
本项目根据录入的数据,建立相关数据模型,对数据进行统计预测,输出统计分析表,数据挖掘利用Apriori算法进行产品关联度的显示和排行, 分析奖学金与学科成绩等因素之间的关联度。
2. 功能组成
基于Apriori算法的奖学金获得者特点研究的功能主要包括:
3. 基于Apriori算法的奖学金获得者分析系统
3.1 系统注册登录
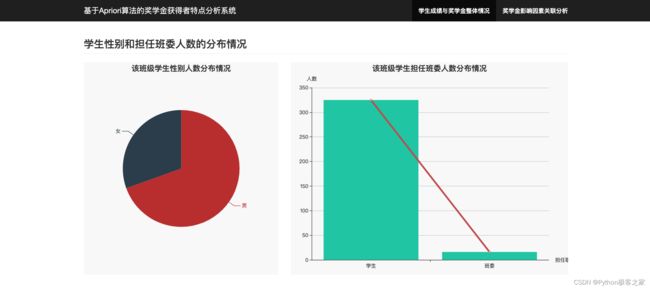
3.2 学生性别和担任班委人数的分布情况
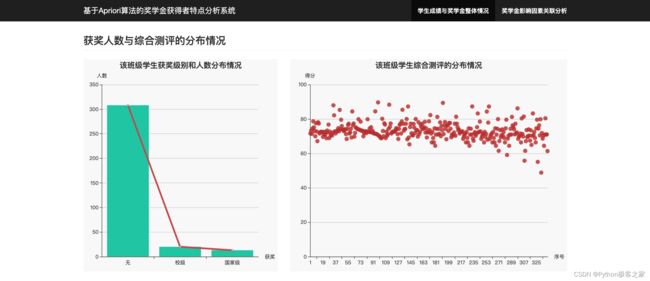
3.3 获奖人数与综合测评的分布情况
3.4 Apriori关联挖掘算法
3.4.1 关联规则挖掘定义
关联规则挖掘是数据挖掘领域的热点,关联规则反映一个对象与其他对象之间的相互依赖关系,如果多个对象之间存在一定的关联关系,那么一个对象可以通过其他对象进行预测。大多数关联规则挖掘算法通常采用的一种策略是,将关联规则挖掘任务分解为如下两个主要的子任务:
- 频繁项集产生(Frequent Itemset Generation)其目标是发现满足最小支持度阈值的所有项集,这些项集称作频繁项集;
- 规则的产生(Rule Generation)其目标是从上一步发现的频繁项集中提取所有高置信度的规则,这些规则称作强规则。关联分析的目标发现频繁项集;由频繁项集产生强关联规则,这些规则必须大于或等于最小支持度和最小置信度。
关联分析的目标是:
- 发现频繁项集;
- 由频繁项集产生强关联规则,这些规则必须大于或等于最小支持度和最小置信度。
3.4.2 支持度
支持度表示该数据项在事务中出现的频度。 数据项集X的支持度support(X)是D中包含X的事务数量与D的总事务数量之比,如下公式所示:

关联规则X=>Y的支持度等于项集X∪Y的支持度,如下公式所示:
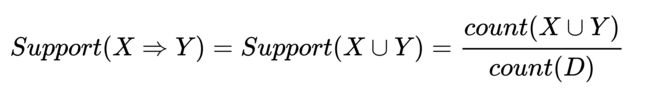
如果support(X)大于等于用户指定的最小支持度minsup,则称X为频繁项目集,否则称X为非频繁项目集。
3.4.3 置信度
置信度也称为可信度,规则 X=>Y 的置信度表示D中包含X的事务中有多大可能性也包含Y。表示的是这个规则确定性的强度,记作confidence(X=>Y)。通常,用户会根据自己的挖掘需要来指定最小置信度阈值,记为minconf。
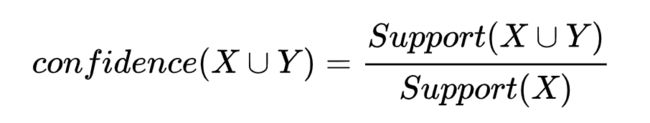
如果数据项集X满足support(X) >= minsup,则X是频繁数据项集。若规则X=>Y同时满足confidence(X=>Y)>=minconf,则称该规则为强关联规则,否则称为弱关联规则。一般由用户给定最小置信度阈值和最小支持度阈值。发现关联规则的任务就是从数据库中发现那些置信度、支持度大于等于给定最小阈值的强关联规则。
3.5 Apriori 算法挖掘奖学金与性别和班委等因素之间的关联关系
def clac_student_association(min_support, min_threshold):
"""计算奖学金与其他因素之间的关联规则"""
......
te = TransactionEncoder()
# 进行 one-hot 编码
te_ary = te.fit(products).transform(products)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 利用 Apriori 找出频繁项集
freq = apriori(df, min_support=float(min_support), use_colnames=True)
# 计算关联规则
result = association_rules(freq, metric="confidence", min_threshold=float(min_threshold))
# 关联结果按照置信度或提升度高进行排序
result = result.sort_values(by='lift', ascending=False)
result.fillna(0, inplace=True)
def trans(x):
if x == np.inf:
return -1
try:
return float(x)
except:
return -1
for c in ['antecedent support', 'consequent support', 'support', 'confidence', 'lift', 'leverage', 'conviction']:
result[c] = result[c].map(trans)
results = result.to_dict(orient='records')
return_results = []
for result in results:
......
return jsonify(return_results)
4. 结论
本项目根据录入的数据,建立相关数据模型,对数据进行统计预测,输出统计分析表,数据挖掘利用Apriori算法进行产品关联度的显示和排行, 分析奖学金与学科成绩等因素之间的关联度度。
》源代码下载:基于Apriori算法的奖学金获得者特点研究【毕业设计】【关联挖掘】【数据分析】【flask+web】【源代码+演示视频】-CSDN下载
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
技术交流认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
Python 毕设精品实战案例
