darknet + yolov4 训练自定义数据集 + windows环境搭建
目录
一、前期准备工作
1、样本数据集的收集
2、样本数据的处理
自己实践过程中整理的标注规范
标注图片
3、修改配置和下载预训练模型
二、darknet 的环境搭建
1、windows 编译环境搭建
安装显卡驱动
安装 CUDA
安装 Visual Studio
安装 cuDNN
安装OpenCV(非必须)
三、windows 下的编译和训练
1、编译 darknet
2、组合数据
目录结构
3、windows 上训练
4、什么时候停止
5、验证权重
6、训练记录
上一篇博文讲解了 java 实现 darknet + yolov4 实现官方标注的目标检测,本篇博文记录下训练自定义数据的整个过程。
yolov4 的 github ,上面讲解的比较详细了。
一、前期准备工作
1、样本数据集的收集
样本需要多样化,其特点:
- 不同角度
- 不同大小
- 不同光照
- 不同形态
- 不要过多重复(重复率最好低于80%)
样本的数量是越多越好。
数据收集好了之后,按照 4:1 到 1:1 的比例范围分成两份,多的用作训练数据集,少的部分用作测试数据集。强烈建议不要使用训练数据集作为测试数据集。
2、样本数据的处理
图片的标注直接影响整个 ai 分析的精准度以及预测框的精准度,所以一定要定义好标注的规范文档,规定好每种目标对象的定义是什么,因为在实际的标准过程中,可能不是你自己来标注,所以需要统一每个人的标注。
自己实践过程中整理的标注规范
- 标注目标物体或者重叠部分
- 以肉眼能够看清的为标准
- 标注框只比目标物体大一点,留有一点空隙即可
- 训练数据集保留少量负样本——不画任何标注框,但是需要生成 txt 文件(把图片在 yolo_mark 工具上过一遍就会自动生成 txt 文件),我的做法是在 10 的整数倍图片上不标注,即 1/10 的样本作为负样本。
如果样本较少,可以少留一点负样本。负样本是增加网络的泛化性的。
- 标注对象的定义需要清楚
标注图片
使用 yolov4 github 上推荐的 yolo_mark 工具 对 训练数据集、验证数据集进行标注,详情请查阅github 文档。
准备好 obj.names 文件,里面存放的是要训练的类型名称,一行一个类型名称。
例如:obj.names
people
car
ship
dog
...
将该文件放在 yolo_mark/data目录下。注意训练数据集需要保留负样本,而测试数据集是不需要负样本的。
标注完成后,yolo_mark/data/img目录下会自动生成与jpg同名的txt文件;yolo_mark/data目录下会自动生成 train.txt 文件。
3、修改配置和下载预训练模型
yolo-obj.cfg:修改配置请依据 自定义配置 和 不同显卡的模型参数设置 进行修改,讲解的比较详细。
yolov4.conv.137:下载预训练模型
二、darknet 的环境搭建
1、windows 编译环境搭建
使用的编译方式官方文档上推荐的 windows 系统 vcpkg 的方式。(vc 表示的是 Visual c++环境)
需要的环境和版本号(github 上有详细说明)
- CUDA >= 10.2: CUDA Toolkit Archive | NVIDIA Developer (on Linux do Post-installation Actions)
- OpenCV >= 2.4: (非必须的)use your preferred package manager (brew, apt), build from source using vcpkg or download from OpenCV official site (on Windows set system variable OpenCV_DIR = C:\opencv\build - where are the include and x64 folders image)
- cuDNN >= 8.0.2 cuDNN Archive | NVIDIA Developer (on Linux follow steps described here Installation Guide :: NVIDIA Deep Learning cuDNN Documentation , on Windows follow steps described here Installation Guide :: NVIDIA Deep Learning cuDNN Documentation)
- Visual Studio:依据 CUDA 的版本安装不同的版本
安装显卡驱动
如果没有安装驱动,没关系,在安装 CUDA 的时候就一起安装。如果安装了,在cmd 使用 nvidia-smi命令查看显卡驱动,并在nvidia官网上查看是否有最新的显卡驱动。
安装 CUDA
官方要求 CUDA 的版本 >= 10.2,所以一定要大于这个版本,最好是先查看nvidia官网当前电脑的显卡支持的版本和驱动,一般来说下载 CUDA 11 就可以了;
在 CUDA Toolkit Archive | NVIDIA Developer 官网地址下载(我下载的是11.4.1),如下截图
在下载过程中,可以阅读对应版本后面的 Online Documentation 在线文档,查看环境,文档截图:

注意,一定要先安装好 VS 环境,CUDA 才能安装成功。(如果没有安装 VS 请看下面的文档,在回来安装)
假设现在已经安装好了对应版本的 VS 环境,直接双击下载的 CUDA exe,解压安装即可。
安装过程中,选择自定义安装,因为经典安装是全安装,包括驱动程序都会覆盖。
(自定义)选择需要安装的组件:
- CUDA 组件:必须勾选
- 显卡驱动:如果电脑没有安装显卡驱动或者已安装的版本比当前版本低,直接勾选,否则不用勾选
- 其他组件:没有安装过显卡驱动或者已安装的比当前版本低,直接勾选,否则不勾选
然后安装,记住安装的 CUDA 位置,等待完成。使用 nvcc -V验证 CUDA 是否安装成功。
安装 Visual Studio
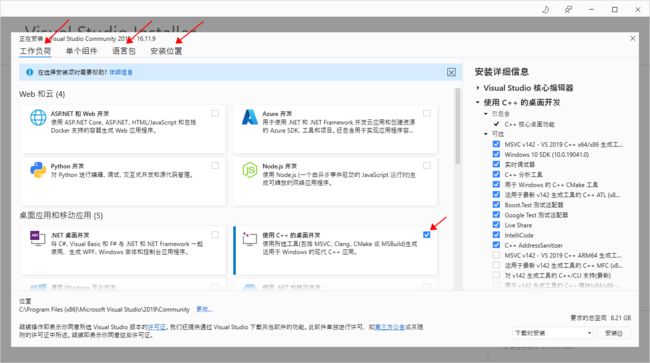
依据 CUDA 中提示的版本信息,到微软官网下载对应版本的 VS,直接下载社区版本的就可以,不需要激活的。
在安装时,工作负荷: C++ 桌面组件,语言包:英文;然后自己修改位置,等待下载组件安装完成。
安装 cuDNN
在 cuDNN Archive | NVIDIA Developer 下载与 CUDA 对应版本的 cuDNN——下载这个需要注册 Nvidia 账号并加入他们的开发者计划中才能下载。
下载后解压,将里面的文件拷贝到 CUDA 的对应目录下即可。
配置 CUDA 的环境变量——一般来说安装 CUDA 后自动配置好了。
安装OpenCV(非必须)
在 opencv 官网 Releases - OpenCV 下载,下载完成后安装。
配置环境变量:OpenCV_DIR=目录\opencv\build
如果需要使用 darkent 进行视频的测试等,可以安装。
三、windows 下的编译和训练
1、编译 darknet
在 https://github.com/AlexeyAB/darknet 上将 darknet 下载下来,文档上推荐 windows 系统上使用 vcpkg 进行编译,在 darknet 目录下 PowerShell 上执行:
.\build.ps1 -UseVCPKG -EnableOPENCV -EnableCUDA -EnableCUDNN
命令即可构建成功。如果没有安装 openCV,则不需要 -EnableOPENCV参数。
但是,现实是残酷的,没有这么简单。
-UseVCPKG参数会检查当前目录下是否存在 vcpkg,如果不存在会去 github 上拉取,我遇到的情况是,不拉不动,后报错,干脆自己直接下载zip包,解压后将 vcpkg-master 重命名为 vcpkg,再次运行,跳过了拉取,然后在构建过程中接二连三的出现问题,依据提示还分别下载了 ninja(也放在根目录下),升级了 git 客户端、7z 程序,最后再次构建,等待了约30分钟,终于构建完毕了。
构建成功后,会在 darknet/build/x64/release 目录下生成一个darknet.exe
2、组合数据
通过前面的数据准备步骤,我们拿到了如下数据:
- 标注好的训练数据集
- train.txt
- 标注好的测试数据集
- test.txt(标注测试数据生成的train.txt)
- obj.names
- yolo-obj.cfg
- yolov4.conv.137
我们现在需要对数据与 darkent 组合,做训练前的准备。
train.txt 和 test.txt 中的内容是 data/img/xxx.jpg,由于我将训练数据集和测试数据集分别放在不同的文件夹下面,所以对 train.txt 的 data/img/xxx.jpg 替换为 data/train/xxx.jpg,对 test.txt 的 data/img/xxx.jpg 替换为 data/test/xxx.jpg
目录结构
将如下数据放入到 darknet 目录中,目录结构和数据如下:
darknet/
|--darknet.exe
|--data/
|--train/ (名称自定义)
|--标注好的训练数据集,jpg和txt 文件
|--test/ (名称自定义)
|--测试数据集,jpg和txt 文件
|--train.txt
|--test.txt
|--obj.names(标注时使用的文件)
|--yolo-obj.cfg(修改好的配置文件)
|--yolov4.conv.137(预训练模型文件)
|--obj.data(新建)
|--backup/ (新建)
- obj.data
obj.data 文件是对数据的组合文件,告诉 darknet 数据文件在哪里,内容如下:
classes = 与yolo-obj.cfg中的classes值一致 train = data/train.txt valid = data/test.txt names = data/obj.names backup = backup/
- backup
backup 文件夹也需要手动先创建一下(obj.data 文件中的 backup 配置项指定的目录),我遇到的情况就是在我不创建的情况下,darknet 不会自动帮我创建,并且需要保存 weights 文件时找不到路径,直接程序闪崩。所以手动创建上。
3、windows 上训练
cmd开始训练命令:
darknet.exe detector train data/obj.data data/yolo-obj.cfg data/yolov4.conv.137 -map
部分参数说明:
-map:打开平均精度曲线
-dont_show:关闭损失图,如果没有 GUI 界面的电脑使用这个参数,不加这个参数启动训练后会自动打开一个实时损失图
-mjpeg_port 8090:如果没有 GUI 但是又想看实时损失图怎么办,使用这个参数打开一个 8090 的web端口,通过浏览器访问这个端口就可以展示了。
-gpus 0,1,2:如果有多个GPU就使用这个参数指定,使用了多个gpu训练,那么学习率就需要用原来的值除以GPU数量,burn_in 等于 GPU 数量*1000
(我的训练过程没那么简单,最下方记录了问题和问题解决方案)
如果训练到中途中断了怎么办?使用下面的命令:
darknet.exe detector train data/obj.data data/yolo-obj.cfg backup/xxx.last.weights -map
可以看到除了使用的模型不一样,其他都一样,xxx.last.weights 就是在训练过程中生成的权重文件,这个权重文件是每迭代100次就把模型参数写入到这个文件,其他的 xxx.1000.weights 等都是1000次才写一次模型参数。
4、什么时候停止
当平均损失在 0.05 到 3 之间,且多次迭代都不下降时,可以停止。如果开启了 map 参数,那么当 map 值比较大时可以停止。
5、验证权重
训练结束后,我们需要验证输出的权重文件,最终选定最好的一个权重,使用以下命令查看指定权重文件的信息:
darknet.exe detector map data/obj.data data/yolo-obj.cfg backup/yolo-obj_7000.weights
上面的命令是对 7000 次迭代的权重验证。
多对几个权重文件进行验证,取 mAP 或 IoU 最大的那个,优先取 mAP 最大的。
校验结果截图:
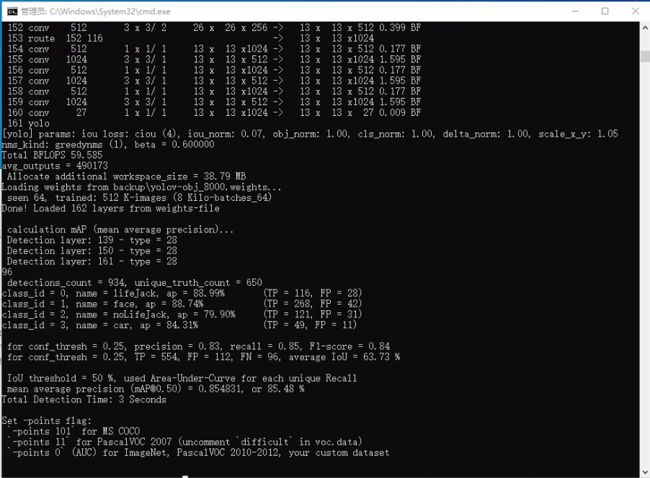
如上图所示: map=85.48%,IoU=63.73%(倒数的第6行和第8行)
6、训练记录
- subdivisions 配置对比
对于 2080Ti 显卡,官网推荐的配置是 batch=64,subdivisions=16,但是我依然进行了一个简单的对比验证。
batch=64的情况下
| 对比项 |
subdivisions=32 |
subdivisions=16 |
| loss 下降 |
初期下降慢 |
初期下降快 |
| 显存占用 |
5G左右 |
9-10G |
所以最终配置 subdivisions=16 即可。
- 开启平均精度计算
训练时,使用 -map 参数打开平均精度计算,但是训练到 1000 次的时候提示 cuDNN status error,导致训练中断。
通过google查找资料,发现以经有人遇到这个问题,并将问题提到了 issues 中:
cuDNN Error: CUDNN_STATUS_BAD_PARAM while training · Issue #2367 · pjreddie/darknet · GitHub
cuDNN Error while training -map · Issue #7153 · AlexeyAB/darknet · GitHub
大体的意思就是在计算平均精度的时候出了问题,可以通过修改 darknet 源码或者降低 CUDA 和 cuDNN 的版本来解决(但是也有人降低了版本也没解决),不过可以尝试。
我的解决方案就是先去掉 -map参数,不进行计算。其影响就是在验证权重文件时看不到这个精度,只能通过 IoU 来选择权重文件了。