负载均衡一致性哈希算法实现 | nginx 负载均衡一致性哈希源码分析 | ngx_http_upstream_consistent_hash_module 源码分析
这是本学期分布式计算/系统课程负载均衡节的课后作业,理解七层反向代理的负载均衡 Nginx 中使用的的一致性哈希算法。开头只是讲一些没用的东西,后面主要是分析 Nginx 的 O(1) 时间复杂度的一致性哈希负载均衡的模块源代码实现,顺便了解一下 nginx 模块开发(参考Development guide (nginx.org) 中的 load balancing 部分)的大致样子。
前情提要:
负载均衡比较 | dpdk 和 lvs 对比 | Nginx 反向代理负载均衡实验_我说我谁呢 --CSDN博客_lvs反向代理
文件共享服务的需求
一开始还是以最为广泛使用的 P2P、BT、PT 等分布式系统来讲解吧。一致性哈希还应用在负载均衡、分布式缓存(比如分布式 kv 数据库)等很多方面。
NAT 废话
P2P 的最大拦路虎是 nat ,对于纯纯 p2p 的 nat 打洞之前的笔记已经有了结论了,总之就是一方公网肯定赢,采用公网中介节点中转浪费带宽,两方 nat 只能借助一个索引服务器进行打洞不保证能通(对称和不对称、IPS nat 网关对入站和出站不同的策略、因素比如连通时机、链路上设备对某个 rfc 的支持、isp 掐断连接等)。对于 BT 来说,最好的体验需要公网 IP,百度云之前的 P2P 可能是 nat 内的,之前 windows 10 支持的系统更新下载 p2p 也是说就近的用户共享可能也是 nat 内,避免进行复杂的不可靠不可控的 nat 打洞,对于 BT 没有公网 IP 可能也能做种,因为至少一些节点有公网 IP 或者他的 nat 支持 in bound,但是具体有没有 nat 打洞可能是没有的。
Tracker 服务器
没有 DHT 的他们实际不是完全去中心化的,因为至少他需要 tracker 服务器,当然 tracker 服务器理论上是必须的(索引作用)。如果能够把这个索引的功能做成分布式的就能从文件去中心化到完全去中心化。这里就用了 DHT(Distributed Hash Table) 技术,算法是一致性哈希算法。进入一个共享资源的网络时,索引信息是必须的,不然你不知道去哪里下载。tracker 的原理是在 torrent 上附带一个 trackerlist,一般 tracker 服务器是不会完蛋的。然后下载方或者做种方都可以链接到 tracker 服务器上让别人了解到一些 metadata。
tracker 的原理是新人通过 torrent 信息发送请求给 tracker server,请求的内容包括种子标识、节点标识、端口、需要下载的范围之类的东西,当然节点的下载开始、停止做种等也会通过请求来进行。然后 tracker 会发一些信息返回,这些信息包括下载完的(可以发送请求)和还在下载(给你之后做种用,比如 nat 可以通过这个给公网用户做种)节点数、节点的 ip:port 等。
BitTorrent
而下载的过程无非就是直接向公网地址请求、运营商大内网时直接请求,本机公网的可能收到 nat 的入站请求等,然后就是下载文件了。这个过程如下(PPT 来自 Princeton COS518: Advanced Computer Systems Lecture 15 spring 17):

更加详细的,通过一个非官方的 spec 看 BitTorrentSpecification - TheoryOrg (v1.0 的,没有用到 dht 和一致性哈希)。tracker 本身不保存文件的信息,比如某个节点他哪个文件在哪个范围,因为这个可能会易变动,不可能时刻 coordinate。对于具体的官方资料, bittorrent 他们给了一些 bep_0000.rst_post (bittorrent.org),包括普通的、投入使用的比如 uTorrent 可能有一些新的 extensions,以及一些 draft。当然 spec 本身没有说 dht 怎么实现,易接口的方式描述使用 dht 构建 bt 客户端。总之现在知道 tracker 的实现是没有一致性哈希的,文件能不能下载,节点有哪些文件这些需要通过 peer message 来获取。
一致性哈希和 DHT 概述
一致性哈希可以用来实现 dht 。DHT 能够保证链路的稳定性,say 一个新人要下载东西,使用哈希算法来进行一堆文件服务器中选一个下载某个块,过程中的节点进出会导致哈希的变动, 网络动荡不安。DHT 的原理是构建一个分布式的 hash table 技术(或者就字面意义指这个哈希表)。以 BT 举例,DHT 使得每一个节点都只有部分哈希表(当然整体上会有 replication)。结合一致性哈希,能够实现一个要点就是对于新节点的加入来说,即使链路上的节点没有获取到最新的哈希表(CAP 来说这个实现没有一致性但是有 Partition tolerance 和 Avaliabilitiy),也能支持正常的下载,如果有人 down 机了,下载方自然会请求更新 DHT。对于服务器的负载均衡的时候,注册用户的数据在哪个服务器(数据库水平分区),就应该保证每次都对应到那一台避免大量缓存失效。
图解
15-445 Intro to DDB 里面的图解

总之一致性哈希的整体思路就是使用虚拟节点和某个时针的顺序遍历真实节点策略,一致在一个很大的环上面 hashing, hash 出来的是虚拟节点,虚拟节点可能没有真实节点,于是就顺延直到找到一个真实节点。
负载均衡需要的一致性哈希
Nginx 的负载均衡就可以这样实现,不过 nginx 的负载均衡根本不需要 DHT。但是注意的是默认的 ip_hash 策略不是的,其中不包含一致性hash,所以需要安装ngx_http_upstream_consistent_hash 模块(Upstream Consistent Hash | NGINX)才能获取一致性哈希特效。
额,完全的一致性哈希算法+DHT 的实现思路可以在这个 PPT 看清楚。
L15-dhts (princeton.edu)
我主要讲一下纯一致性哈希(在一个中心化服务器上)的实现思路,对于 DHT 来说这个得另外写一篇。DHT 主要要进行哈希表信息本身的分散,每个节点只能看到一部分的内容,然后整体有 overlap 的部分。
最直接的思路是环这个很简单理解,一样真思路就是用一个数组,但是你一想啊,虚拟节点可能有很多很多的(稀疏的),而真实节点只占有一小部分,所以这样什么的效率都很低下了。本来哈希表就是平均空间浪费 100%,现在还要再搞虚拟节点,肯定是不行的。实际上的一致性哈希算法的哈希表一般是要支持动态扩容的,因为理论上我们需要保证网络总是可以加入的,所以环上真实节点的稀疏性应该维护,可以通过一个倍数来限制,扩容的时候其实很简单就是增加了末端而已,比 JDK hashmap 那个扩容简单多了!当然,实际情况是对于小网络而言,可以限制一个最大容量,大量节点的时候,环可以不用稀疏,发生动荡(比如有人 down 机了)也就变稀疏了。
所以要实现这个环,环本身是虚拟的(逻辑存储),我们可以用红黑树(std::map)、跳表等东西来做,因为本身只需要指定查找 lower_bound 或者 upper_bound 时的 comparator 就行了.

上面这个是一个 upper_bound 的例子,say hash 出来的是 0x1,那么查找的时候一直找到第一个大于 1 的,就会引流到 NodeA。边界考虑是,大于 0xazd656co 的哈希数值比如 0xfffffffe,第一个大于他的没有 Node 了,就会返回 end 迭代器,这个时候只需要返回 map 的 begin 就行了。
高性能和配置需要的优化
一个优化是,再增加一些虚拟节点从而达到分布均匀或者说负载均衡(当然均匀这个本身应该是由哈希算法保证的,但是实际是做不到的,特别是一开始物理节点就比较稀疏的情况会很容易一个负载重一个轻),另外这种方案也能方便调节比如说有一些节点的能力(对于 BT 可能是带宽之类的)更强,应当提供一些复制节点,这个实现也很简单,只需要增加一个中间层。我们每次创建节点都给 id 加上一些编号,然后他的实际信息都是同一个节点。这个优化其实还有一个用途,我们说过做 DHT 需要一些冗余存在,实际就是一些互相构成有部分重叠的小网络。

至此简单的思路都讲明白了。关键就是使用二叉树(对于动态更新需求不高可以直接用有序数据结构)而已。
ngx_http_upstream_consistent_hash_module 模块
下面应该要讲的是怎么实现分布式哈希表。比较重要的一个实现应该是 Kademlia 如果你需要实现一个 P2P 共享网络。对于实际的网络应用开发需求而言,我们并不需要分布式的哈希表来做什么东西,所以我不打算在这里讲解这个具体的算法的实现。因为本来如果你做单机服务,只有一个问题,如果要做分布式的东西,你就有两个问题了。单线程多线程也一样,如果要做多线程,那两问个题了有你。DHT 主要是用于节点的发现和联系,P2P 是一个应用,过程中这个 hashtable 可能不是一致的,但是维护的信息保证网络是一段时间可用的。而对于分布式系统来说,比如分布式数据库,需要的不是通过网络去查找节点获取信息,而是尽可能地在 CAP 里面做 trade-off ,所以这里用 Paxos 、Raft 这种协调 partitions 和 replications 的一致性才是重点。
但是上面讲的单机一致性哈希算法是广泛应用的。比如负载均衡的时候,注册用户的数据在哪个服务器(数据库水平分区),就应该保证每次都对应到那一台避免大量缓存失效。对于扩容之后,也应当保证尽可能少的路由发生改变。
不需要的运行时动态
这里本来应该有一段复习数据结构的 BST 和有序数组+二分查找的两种数据结构的复杂度分析的,但是我懒得做的,脑子里想一想就好了吧,无非是动态修改的不太一样,然后是移动的次数、Cache 友好型上的。总之其实如果知道了这个之后,实际对于 upstream server 的 configuration 是不会事实变化的,对动态修改其实并不是很需要啦。至于 down 机检测避开的情况也很好解决,不直接在哈希环上面打 tag,而是另外打就行了。实际的扩容减容的更新都是需要 reload 的,这个时候只需要保证每次初始化的时候同一台服务器都能映射到环上同一个点就行了,这个用 server name 做 hash key 就行了。
然后就看 Nginx 的一致性哈希模块是怎么实现一致性哈希的。早期这个模块的实现思路就是环形的,现在新版本的代码修改了一些地方,采用了新的思路,实现了 O(1) 引流。
ngx_http_consistent_hash/ngx_http_upstream_consistent_hash_module.c at master · replay/ngx_http_consistent_hash (github.com)
下面是对用到的数据结构的认识:
画图绘制,下面具体讲解实现。
源码分析
初始化
首先是模块的初始化:
ngx_http_upstream_consistent_hash
ngx_http_consistent_hash/ngx_http_upstream_consistent_hash_module.c at d4aa50b35bb44d576b968ecdf235c268c03664c5 · replay/ngx_http_consistent_hash · GitHub
可以看到注册 upstream 初始化函数为:ngx_http_upstream_init_consistent_hash
下面就看他
ngx_http_upstream_init_consistent_hash
中
ngx_http_consistent_hash/ngx_http_upstream_consistent_hash_module.c at master · replay/ngx_http_consistent_hash (github.com)

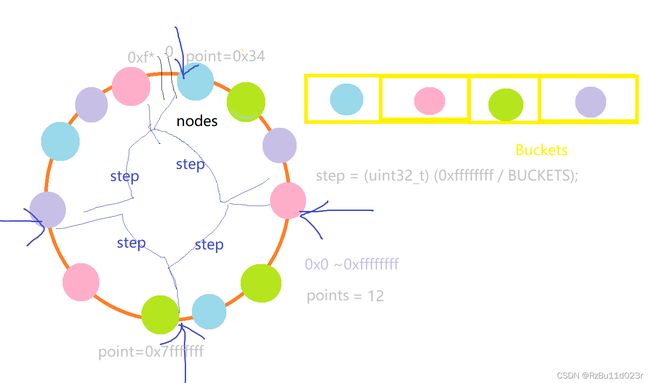
根据服务器的权重和一定的倍数乘积来决定最后建立多少个虚拟的中间节点来实现权重均匀分布,这里的 points 是整体的数量变量,用来决定要分配多少内存的(毕竟是 C 写的)。这里对于同样的服务器配置,应该都是同样的 points 大小。
continuum 是临时的指针,最后 buckets 会存到 us->peer.data 里面。下面是构建一个哈希环,只有有效节点的。

这一段是初始化 nodes 数组,从而根据配置文件把所有的 upstream (us)都放到 nodes 数组里面去了,每个中间虚拟节点的哈希值则是使用 crc32 算法,不过注意这里的 hash_data 的值。point 的意思就是他在0~0xffffffff 环上的点的位置,这里可以看到 hash_data 是根据 server name 和 k (就是 copy 的节点编号)来编码的,理论上服务器不可能有千万台 crc 应该不会重复,证明的话只需要证明字符串中间一个子的编码值是连续的时候会不会冲突就行了。
形成哈希环
然后采用了 qsort 来进行一次的根据哈希值(point)排序,使得数组成哈希环。
ngx_http_consistent_hash/ngx_http_upstream_consistent_hash_module.c at master · replay/ngx_http_consistent_hash (github.com)

空间换时间
然后他在 buckets 数组里面分别放上了 nodes 数组每个范围的头头(hash_find 是数组中的根据 point 的二分查找),目前情况如下图那样。

所以实际他是通过这个 buckets 来实现一致性哈希的。而 buckets 本身是对 nodes 数组的一个采样,steps * buckets = 0xffffffff,所以就是等于上面一块取一个节点然后放进 bckets 中,注意乘法溢出的利用。注意 buckets 的数量是比服务器数量要大很多的,比如 1024,上图只是简化版.
到此结束,之后只会用到 buckets (这个是最新的版本2015的实现,改为使用 bucket 进行引流),这样的好处是什么呢?是每次查询都不需要进行二分查找了,空间换时间保证了 O(1) 的引流速度,这也是高性能的要求!至于空间损耗,我大概估算是不到 10KB 吧(此处可能有误,也许可以说是很值了)。
O(1) 的客户端请求处理
接下来到客户端到达的情况了!
我们可以看到 peer init 注册为函数 ngx_http_upstream_init_consistent_hash_peer
https://github.com/replay/ngx_http_consistent_hash/blob/d4aa50b35bb44d576b968ecdf235c268c03664c5/ngx_http_upstream_consistent_hash_module.c#L135
这个函数实际就是客户端连接进来的时候进行的初始化:
ngx_http_upstream_init_consistent_hash_peer
ngx_http_consistent_hash/ngx_http_upstream_consistent_hash_module.c at d4aa50b35bb44d576b968ecdf235c268c03664c5 · replay/ngx_http_consistent_hash · GitHub
可以看到,注册 get 为
ngx_http_upstream_get_consistent_hash_peer
ngx_http_consistent_hash/ngx_http_upstream_consistent_hash_module.c at d4aa50b35bb44d576b968ecdf235c268c03664c5 · replay/ngx_http_consistent_hash · GitHub

O(1) 没毛病。(如果有错误请欢迎指出,我会悔改删除跑路)
附注,文件共享服务和 DHT 的历史(这段没有意义,不用读)。
- 1968-1969 年,肯尼迪被暗杀,夏威夷大学的研究人员开始研究 ALOHA 网络。1969年,Unix 被开发出来,同年ARPANET 建立,B 树被发明。
- 70s 初 C语言出来,B+树被发明,在电话线上可以上网(Unix)。1971 年 aloha 广播算法搞出来,同年在 ARPANET 上建立了 email。1971 年 Gourand 明暗处理,72年红黑树被发明出来。1975年 Phong 光照模型。
- 1978 Intel 8086 处理器发布。同年改革开放,世界上第一个 BBS。
- 1979 中美建交。摩托罗拉 68000,第一代 Macintosh 采用,人类消灭天花。
- 1980 年福岛邦彦论文提出神经网络(CNN),同年 Witted 光透视模型。1981 年,MS-DOS 系统发布。
- 1983 年,ARPANET 的协议标准定为 TCP/IP
- 1985 年出了 FTP(rfc959)。同年 80386 发布, Windows 1.0 图形界面发布. ARM 开始做 RISC,同年 C++ 出现,任天堂红白机和马里奥发布。
- 1986 年 SQL86 标准,塞尔达传说登场,87年 SQL 标准,最终幻想1发布。89 年 80486 处理器发布,同年 Lecun 发表第一个实现反向传播神经网络 和实现了 CNN,具有应用论文。
- 1990 年,www 正式提出了(浏览器+网页编辑器 for NeXT(乔布斯当时离开苹果创立的,摩托罗拉 CPU)),这个时候有了各种音视频的格式,网络的传输速度也更快了,MIME 出现了。同年 lamport 大佬的 paxos 算法提出(以一个岛故事发布),此时也许没有多少人能看懂,或者分布式应用还没有广泛,总之相关的应用还要过好多年才火热。此时 windows 3.0 发布.
- 1991 海湾战争。同年 Linux 开始开发,AMD 发布 AM386,年底苏联解体。1992 年 OpenGL 第一版发布,。
- 1993 年,邪恶的 NAT 在 RFC 1663 提出。NAT 推动了互联网飞入平常百姓家。同年 HTML 提出. Windows 3.1 上支持第一个图形网页浏览器。同年 Windows NT 3.1 发布,内核支持 IOCP。同年 DOOM 游戏发布。
- 1994 Linux 1.0 正式发布。1995 年 DirectX 发布,win95 发布,Java 发布。1996 年 W3C 发布第一个 CSS 标准,同年游戏 Quake 游戏发布。1997年哈利波特与魔法师, GTA 游戏发布。1998 年 Google 成立。中国 CERNET 建成
- 1999年,napster , p2p 音乐共享软件发布,他是一个中心化的 CS 架构,本身napster 的 Server 用来引流,文件本身则是通过 P2P 传输。第一个 GPU Geforce 256发布。美国轰炸南联盟。
- 2000年的时候 ed2k 出现了,他和 napster 相比最大的 feature 就是分块下载,为后面的 BT 奠定了基础。后来 ed2k 的改进版本 embed 了服务器,开始搞出网络之上的网络 eDonkey Network,也就是现代 p2p 共享网络的起源。但是本质上还是需要文件提供方充当服务器的 CS 结构,只不过这个 P2P 是指没有机构。
- 2001napster 树大招风,被关掉了(7月)同月 BitTorrent 发布,主要是和 ed2k 差不多,但是增加了对已下载片段的做种,同时仍然是需要中心化的 indexing sites (tracker)。同年 iPod +iTunes 发布(10月)。同年 DHT 相关研究火热(Chord 算法),但是 BitTorrent 还不支持 trackerless。ed2k 支持 seeding 的方法是搭建一个中心化的 indexing 网站,需要有人通过 torrent 给登记种子。
- 2002 年 Kademlia 论文(kad,基于 DHT 的 p2p overlay network)发布,同年 emule 发布,emule 是一个 支持 e2dk 协议的开源客户端,1.0 时同时支持 kad 网络,成为 e2dk 的替代品,kad 网络是支持 dht 的 bt 原型。同年 linux 2.4.44 发布了 epoll。
- 2004 年 Nginx 第一版发布。同年 facebook,
- 2005 年 BitTorrent 引入 Mainline DHT 实现 trackerless,基于 Kademlia(11月),至此真正的去中心化 P2P file sharing 出现。同年分布式数据库开始流行,
- 20年代末中间人攻击用 TCP 搞 bittorrent 客户端,导致后续的文件服务器都开始用 UDP,ISP 不稳定,无连接报太多 hop 了,实际链路上的设备会把 UDP 丢包,具有随机性,这些可能是由于路径上设备的处理能力等有关,实际 TCP 不丢包只是因为他有重传机制,所以 UDP 也要自己做 seq、ack 、retransmission 这些。本质上什么都有连接的。
- 2014 年 Raft 论文(Stanford)。同年 MapReduce 论文(Google)。