我们知道,Cluster 是 Google Kubernetes Engine (简称GKE)的基础,代表容器化应用程序的 Kubernetes 对象都在集群之上运行。
Google Kubernetes Engine (GKE) 提供了一个托管环境,开发人员可以使用 Google 基础架构在 GKE 中部署、管理和扩缩容器化应用。GKE 环境包括多个 Compute Engine 实例,这些实例组合在一起就形成了 Google Kubernetes Cluster.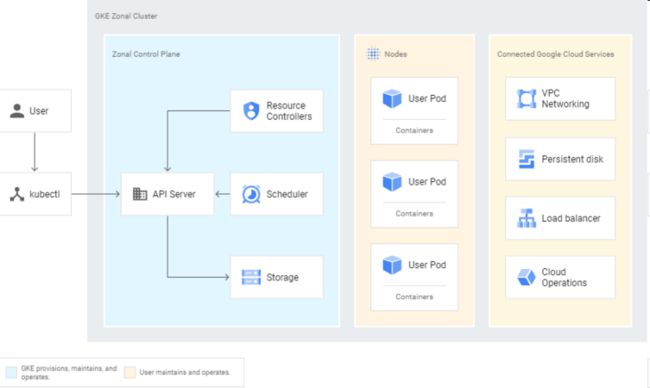
SAP HANA Expression 是 SAP HANA 的简化版本,旨在在笔记本电脑和其他主机(包括云托管的虚拟机)上运行,当然也就支持在本文刚刚描述的 Google Kubernetes Cluster 上运行。这个版本除了支持 SAP HANA传统的内存数据库功能之外,还提供 bring-your-own-language 等多种技术栈,支持微服务、预测分析和机器学习算法,以及用于构建洞察驱动应用程序的地理空间处理等特性。

本文将详细介绍如何在 Google Kubernetes Cluster 上部署并使用 HANA Expression Database Service.
在 Google Cloud Platform 上创建 Google Kubernetes Cluster 实例
登录 Google Cloud Platform 控制台:
点击控制台左上角的 Hamburger 菜单,创建一个新的 Kubernetes Cluster:
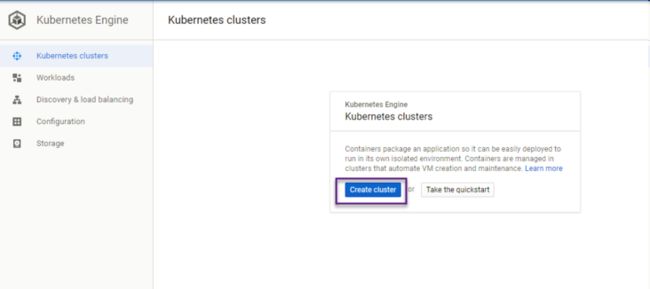
维护 Cluster 的名称,选择恰当的版本,点击 Customize 进行定制化: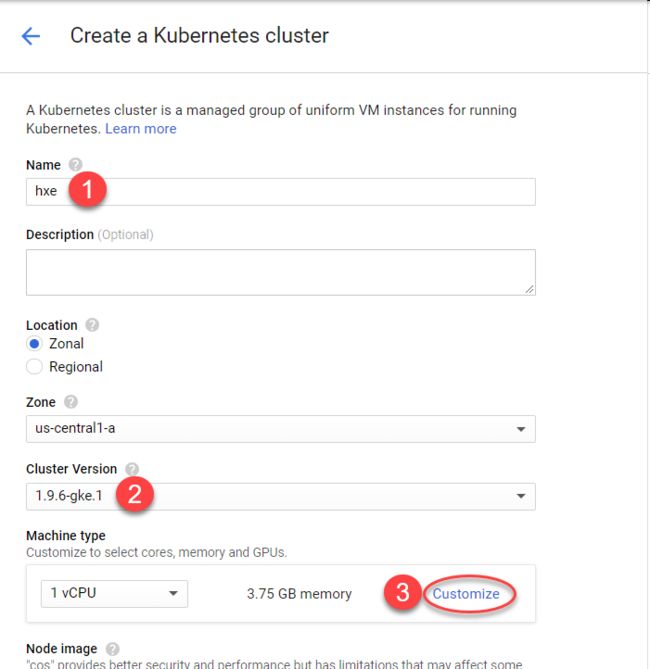
为 Cluster 指定 CPU 和内存参数,选定 Ubuntu 作为操作系统。Cluster 的尺寸设置为 1.
Cluster 创建完并成功部署后,点击 Connect 按钮进行连接。

连接成功之后,就可以使用 Cloud Shell 操作集群了: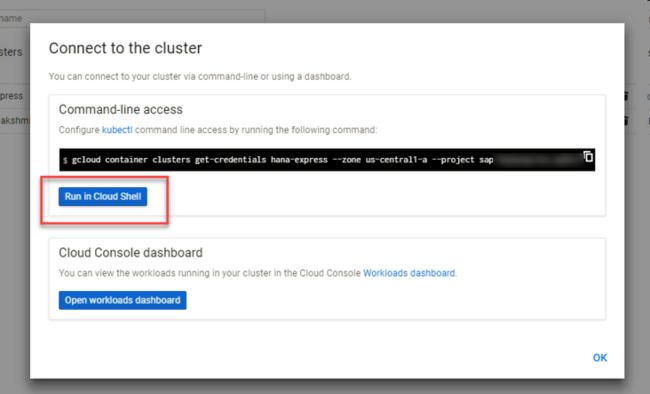
Cloud Shell 提供了命令行的方式同 Cluster 进行交互。

在 Google Kubernetes Cluster 上部署 HANA Expression Database Service
使用以下命令创建一个 secret 以获取 Docker 镜像:
kubectl create secret docker-registry docker-secret --docker-server=https://index.docker.io/v1/ --docker-username=xxx --docker-password=yyyyyy [email protected]
创建一个 yaml 格式的部署配置文件(Deployment Configuration File), 另存成 hxe.yaml 文件:
kind: ConfigMap
apiVersion: v1
metadata:
creationTimestamp: 2022-06-25T19:14:38Z
name: hxe-pass
data:
password.json: |+
{"master_password" : "JERRYHana1"}
---
kind: PersistentVolume
apiVersion: v1
metadata:
name: persistent-vol-hxe
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 150Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/data/hxe_pv"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: hxe-pvc
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: hxe
labels:
name: hxe
spec:
selector:
matchLabels:
run: hxe
app: hxe
role: master
tier: backend
replicas: 1
template:
metadata:
labels:
run: hxe
app: hxe
role: master
tier: backend
spec:
initContainers:
- name: install
image: busybox
command: [ 'sh', '-c', 'chown 12000:79 /hana/mounts' ]
volumeMounts:
- name: hxe-data
mountPath: /hana/mounts
volumes:
- name: hxe-data
persistentVolumeClaim:
claimName: hxe-pvc
- name: hxe-config
configMap:
name: hxe-pass
imagePullSecrets:
- name: docker-secret
containers:
- name: hxe-container
image: "store/saplabs/hanaexpress:2.00.030.00.20180403.2"
ports:
- containerPort: 39013
name: port1
- containerPort: 39015
name: port2
- containerPort: 39017
name: port3
- containerPort: 8090
name: port4
- containerPort: 39041
name: port5
- containerPort: 59013
name: port6
args: [ "--agree-to-sap-license", "--dont-check-system", "--passwords-url", "file:///hana/hxeconfig/password.json" ]
volumeMounts:
- name: hxe-data
mountPath: /hana/mounts
- name: hxe-config
mountPath: /hana/hxeconfig
- name: sqlpad-container
image: "sqlpad/sqlpad"
ports:
- containerPort: 3000
---
apiVersion: v1
kind: Service
metadata:
name: hxe-connect
labels:
app: hxe
spec:
type: LoadBalancer
ports:
- port: 39013
targetPort: 39013
name: port1
- port: 39015
targetPort: 39015
name: port2
- port: 39017
targetPort: 39017
name: port3
- port: 39041
targetPort: 39041
name: port5
selector:
app: hxe
---
apiVersion: v1
kind: Service
metadata:
name: sqlpad
labels:
app: hxe
spec:
type: LoadBalancer
ports:
- port: 3000
targetPort: 3000
protocol: TCP
name: sqlpad
selector:
app: hxe这个 yaml 文件里定义了一个 HANA Expression 的 Docker 镜像:store/saplabs/hanaexpress:2.00.030.00.20180403.2
使用如下命令行将这个 Docker 镜像部署到 Kubernetes Cluster 上:
- kubectl create -f hxe.yaml
- kubectl describe pods
等待部署成功结束:
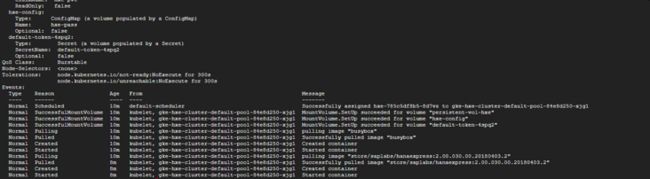
执行命令行 kubectl get pods,确保 pod 状态为 Running,然后进入 Pod 容器内部:
kubectl exec -it <
此时就可以使用 SQL 命令行,连接运行在 Pod 里的 HANA Expression 实例了:
hdbsql -i 90 -d systemdb -u SYSTEM -p HXEHana1
给数据库添加 document store 的支持:alter database HXE add 'docstore';
从 SQLPAD service 获得 external IP 地址:
kubectl get services

有了这个外部可以访问的 IP 地址之后,访问其 3000 端口,就可以在浏览器里登录 SQLPAD 了:
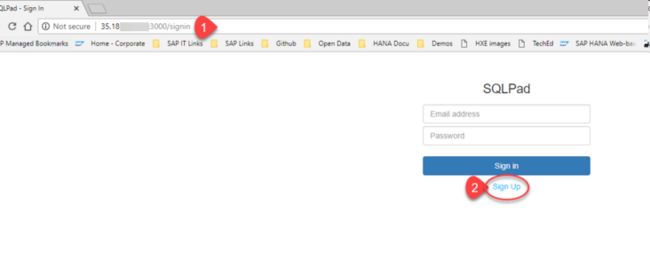
点击 Sign In,创建一个 Administration account.
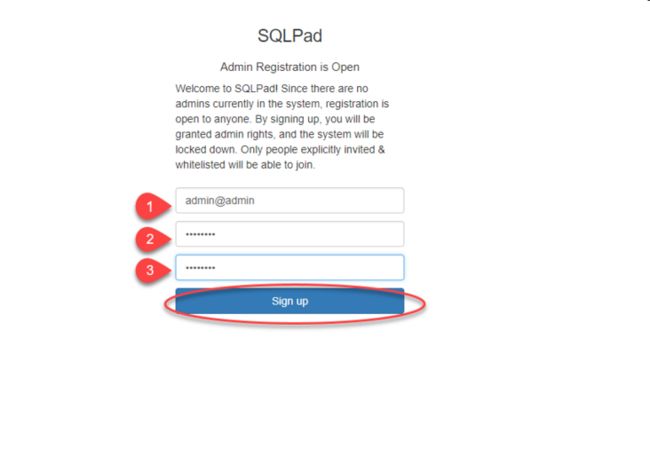
使用 Connections 菜单,连接 HANA Expression 实例里的数据库表:
从 kubectl get services 命令行结果列表里找到 hxe-connect,抄下其 External IP 地址:

新建一个数据库连接,维护刚刚抄下来的 External IP 地址,数据库用户名和密码,Tenant 等登录信息:
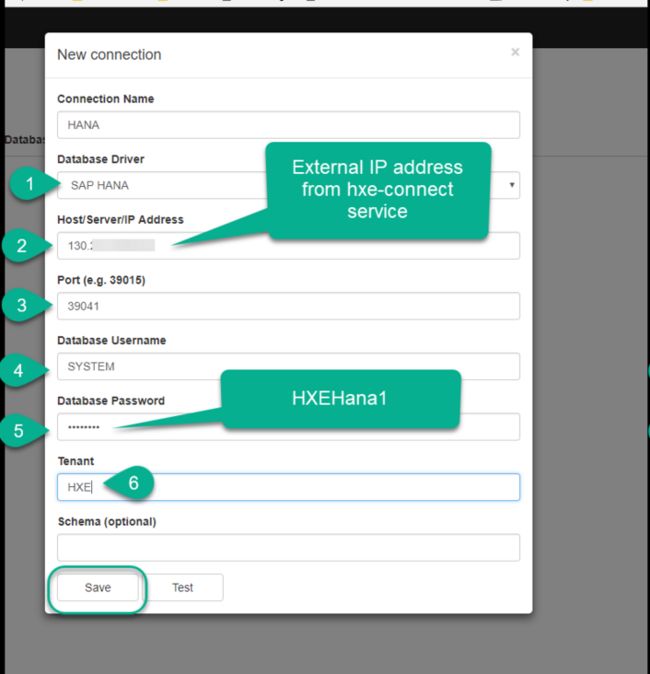
数据库连接建立连接之后,就可以新建一个 Query,对其进行读写操作。

创建一个名叫 quotes 的 document store, 并插入一些测试数据:
create collection quotes;
--Create a collection for document store and insert JSON values
insert into quotes values ( { "FROM" : 'HOMER', "QUOTE" : 'I want to share something with you: The three little sentences that will get you through life. Number 1: Cover for me. Number 2: Oh, good idea, Boss! Number 3: It wai like that when I got here.', "MOES_BAR" : 'Point( -86.880306 36.508361 )', "QUOTE_ID" : 1 });
insert into quotes values ( { "FROM" : 'HOMER', "QUOTE" : 'Wait a minute. Bart''s teacher is named Krabappel? Oh, I''ve been calling her Crandall. Why did not anyone tell me? Ohhh, I have been making an idiot out of myself!', "QUOTE_ID" : 2, "MOES_BAR" : 'Point( -87.182708 37.213414 )' });
insert into quotes values ( { "FROM" : 'HOMER', "QUOTE" : 'Oh no! What have I done? I smashed open my little boy''s piggy bank, and for what? A few measly cents, not even enough to buy one beer. Weit a minute, lemme count and make sure…not even close.', "MOES_BAR" : 'Point( -122.400690 37.784366 )', "QUOTE_ID" : 3 });创建一个 Column 表,开启 Fuzzy Search 的支持:
create column table quote_analysis
(
id integer,
homer_quote text FAST PREPROCESS ON FUZZY SEARCH INDEX ON,
lon_lat nvarchar(200)
);将插入到 document store collection 的数据拷贝到上面的 Column 表里:
insert into quote_analysis
with doc_store as (select quote_id, quote from quotes)
select doc_store.quote_id as id, doc_store.quote as homer_quote, 'Point( -122.676366 45.535889 )'
from doc_store;查询与 wait 相似度最低的词:
select id, score() as similarity , lon_lat, TO_VARCHAR(HOMER_QUOTE)
from quote_analysis
where contains(HOMER_QUOTE, 'wait', fuzzy(0.5,'textsearch=compare'))
order by similarity asc总结
至此,我们完成了在 Google Kubernetes Cluster 里操作 HANA Expression Database Service 的操作步骤。从整个过程不难感觉出,将包含 HANA Expression 的 Docker 镜像部署在 Google Kubernetes Cluster 并运行在 Pod 内,实现了 HANA Expression 服务的开箱即用,从而避免了 On-Premises 部署模式下 HANA Expression 繁琐的安装和配置步骤。