csdn测开涨薪技术-Git原理及使用全套教程
前言
工欲善其事,必先利其器【文章末尾给大家留下了大量的福利】

Git是啥?
Git是分布式的版本库。
那么什么是分布式的版本库呢?说实话,第一次看到这句话时我的内心也是懵逼的。现在我们先不解释这个概念,总之你现在需要知道的就是:
Git非常强大,非常好用,比SVN好使1万倍,是编写代码、修改Bug、发布程序、持续集成,自动化运维、参与开源、居家旅行的必备神器。
Git为什么这么牛掰呢 ?因为它是Linus Torvalds开发的。Linus Torvalds是谁?Linus Torvalds是这个世界最牛掰的程序员,他21岁时就开发出了Linux。
等你认真读完这个手册,就会知道什么是分布式的版本库以及它相对于集中式版本库的好处。
下面我们正式开始进入 Git的世界。
安装Git
Linux
在Linux安装Git非常简单,只需一行命令
$ sudo yum install git-all$ git --version
Mac
现在Mac都默认安装Git,如果没有可以运行下面的命令
$ brew install git$ git --version
Get Started
安装完Git,让我们开始第一次Git之旅。在终端运行下面的命令
$git config --global user.name "tianle"$git config --global user.email "[email protected]"$git init git-demo$cd git-demo$echo "Git学习" > README.md$git add README.md$git commit -m 'init repo and add README.md'$git log
执行完以上命令,我们就已经建立了一个Git仓库,并且将文件README.md交由Git管理。是不是很简单!
如果你现在想把这个README.md分享给别人,就需要连接远程版本库,那么可以执行下面的命令。如果你比较自私不想分享你的成果,那么你现在就已经完成了第一个Git的"Hello World",可以跳到下一章了。
$git remote add origin [email protected]:christian-tl/git-demo.git$git push origin master
这样你就将README.md推到了远程仓库的master分支,其他的小伙伴就可以看到了。他们不光能看到,还能修改完善这个文件。这就是工作的协作。
好了,现在我们愉快的结束了第一次Git之旅。你和Git已经不是那么陌生了。
Icongit config 设置 user.name user.email 只需在首次使用git时设置,之后就无需再设置了。
如果是首次连接使用远程版本库的话,需要把当前用户的公钥传到远程版本库上,否则无法使用ssh协议

基本使用
由于Git是分布式的版本库,所以Git完全可以在没有网络的情况下使用,每个人的开发机都可以作为一个独立的版本库存在,开发者可以在自己的开发机管理代码版本,而不依赖于远程版本库。
所以,在使用Git时并不是必须有一个远程服务器的存在。但是在实际工作中的绝大部分时间里团队的成员之间都需要协作,提交(push)自己的修改和同步别人的代码(pull) .所以本文还是描述实际工作中的使用Git作为版本管理工具的协作方法。
团队开发中使用Git的基本流程:
- 克隆远程版本库
- 基于远程develop分支建立本地develop分支
- 基于develop分支建立本地特性分支feature
- 在feature分支编写程序
- 切换到develop分支,合并feature的修改
- 把本地develop分支的修改推到远程develop
上述流程基本上可以覆盖90%的日常开发工作。
下面我们就通过一个简单的例子说明上述的流程,看看是如何用Git进行实际代码协作的。
- 克隆远程版本库
$git clone [email protected]:christian-tl/git-demo.git - 基于远程develop分支建立本地develop分支
$cdgit-demo$git checkout -b develop origin/develop - 基于develop分支建立本地特性分支feature
$git branch feature$git checkout feature - 在feature分支编写程序
$viREADME.md$via.txt$git add README.md a.txt$git commit -m'add a.txt , change README.md' - 切换到develop分支,合并feature的修改
$git checkout develop$git pull$git merge feature - 把本地develop分支的修改推到远程develop
$git push
我们看到了一坨命令,是不是有点头晕眼花?是不是觉得Git很难用?没关系,你的想法是特别正常的。大部分人在最初接触Git时都想过放弃,觉得既然用SVN很简单为啥还要学着么难用的技术呢。实话实说Git的学习曲线确实很高,比SVN/CVS这种傻瓜式的版本控制工具要难很多。没办法,这个世界上没有什么完美的事情。我们要辩证的来看, 要想获得高收益就一定会付出一些代价。我们付出的代价就是多付出一点时间把Git的命令,对象存储原理弄明白,这对我们之后的整个开发流程都会有巨大的帮助。所以这个代价是值得的。
我们目前看到的命令是:git clone, git branch, git checkout, git add, git commit, git merge, git pull, git push
这些都是Git最重要的命令,伴随着整个Git的使用过程。当然,在实际工作中不会像示例里这么简单,我们经常需要用 git status 查看工作区和暂存区状态,用 git log 查看提交版本,用git diff 查看不同区域的差异,用 git reset 重置版本库,用 git rebase 合并提交与分支,用 cherry-pick 拣选提交,用 git fetch从远程版本库下载,用 git tag 建立里程碑,等等。Git有170多个命令,没有必要知道每个命令怎么用,也不可能做到。其实只要把上面列的命令会用了,工作中就基本够用了。后面的篇幅会详细介绍每个命令的用法。
在详细学习Git命令之前,我们要先了解一些Git的基本概念。这些概念非常的重要,它可以帮助我们理解Git的原理,这样我们才能更好的理解和使用命令,而不是对命令死记硬背。
Git最重要的概念就是工作区,暂存区,版本库,Git对象。
Git目录
执行 git init 或 git clone 之后会生成一个目录, 我们的开发都是在这个目录下进行的。这里面有我们所有的代码文件,我们把这个目录叫做项目目录。
比如:git clone [email protected]:christian-tl/git-demo.git 或git init git-demo 后 ,生成的这个 git-demo 目录就是项目目录。
在项目目录下有一个Git目录,除了Git目录之外的都是工作目录
Git目录
'Git目录'是项目存储所有历史和元信息的目录 - 包括所有的对象(commits,trees,blobs,tags).
每一个项目只能有一个'Git目录'(这和SVN,CVS的每个子目录中都有此类目录相反), Git目录是项目的根目录下的一个名为 .git 的隐藏目录. 如果你查看这个目录的内容, 你可以看到所有的重要文件。
还是回到前面Get Started的例子
$cd git-demo ; ll -aldrwxr-xr-x 9 christian staff 306 5 5 16:21 .git # 这个就是Git目录-rw-r--r-- 1 christian staff 10 5 5 15:23 README.md # 这个是刚刚创建的文件$cd .git ; tree -L 1|-- HEAD # 记录当前处在哪个分支里|-- config # 项目的配置信息,git config命令会改动它|-- description # 项目的描述信息|-- hooks/ # 系统默认钩子脚本目录|-- index # 索引文件|-- logs/ # 各个refs的历史信息|-- objects/ # Git本地仓库的所有对象 (commits, trees, blobs, tags)|-- refs/ # 标识每个分支指向了哪个提交(commit)。
这个.git目录中还有几个其他的文件和目录,但都不是很重要。不用太关注。工作目录
Git的 '工作目录' 存储着你现在签出(checkout)来用来编辑的文件. 当你在项目的不同分支间切换时, 工作目录里的文件经常会被替换和删除. 所有历史信息都保存在 'Git目录'中 ; 工作目录只用来临时保存签出(checkout) 文件的地方, 你可以编辑工作目录的文件直到下次提交(commit)为止.
'工作目录'包括在项目目录下,除了 .git 外的其他所有文件和目录
在我们的例子中对应关系如下。
项目目录:git-demo
Git目录:git-demo/.git
工作目录:git-demo下除了.git目录之外的全部
.git目录详解
对.git目录先有个基本了解对后面的学习有很大帮助。
HEAD文件
HEAD文件就是一个只有一行信息的纯文本文件。这行内容记录的是当前头指针的引用,通常是指向一个分支的引用 ,有时也是一个提交(commit)的SHA值
$ cat .git/HEADref: refs/heads/master #HEAD文件的内容只有这一行,表明当前处于master分支$ git checkout dd98199Note: checking out 'dd98199'.You are in 'detached HEAD' state....$ cat .git/HEADdd981999876726a1d31110479807e71bba979c44 #这种情况是”头指针分离“模式,不处于任何分支下。HEAD的值就是某一次commit的SHA
config文件
config文件记录着项目的配置信息,也是一个普通的纯文本文件。git config命令会改动它(当然也可以手工编辑)。
这个文件里面配置了当前这个版本库的基本属性信息,上游版本库信息,本地分支与上游的映射关系,命令别名等。
总之是一个很有用的文件。在你的.git目录里看到的config文件内容基本上是下面的样子。#基本配置[core]repositoryformatversion = 0filemode = truebare = falselogallrefupdates = trueignorecase = trueprecomposeunicode = true#上游版本库[remote "origin"]url = http://git.dangdang.com/stock/shopstock-update.gitfetch = +refs/heads/*:refs/remotes/origin/*#本地分支与上游版本库分支的映射[branch "master"]remote = originmerge = refs/heads/master#当前仓库Git命令别名[alias]st = status
Icon如果没有添加远程版本库,[remote "origin"]和[branch "master"]是不存在的;如果没有设置alias那么[alias]也是不存在的。
所以如果仅仅是git init之后的一个本地仓库,那么只有[core]配置项 hooks目录
钩子(hooks)是一些在.git/hooks目录的脚本, 在被特定的事件触发后被调用。当git init命令被 调用后, 一些非常有用的示例钩子脚本被拷到新仓库的hooks目录中; 但是在默认情况下它们是不生效的。 把这些钩 子文件的".sample"文件名后缀去掉就可以使它们生效。知道这个目录的用途就好,一般用不到。
index文件
git暂存区存放index文件中,所以我们把暂存区有时也叫作索引(index)。索引是一个二进制格式的文件,里面存放了与当前暂存内容相关的信息,包括暂存的文件名、文件内容的SHA1哈希串值和文件访问权限。暂存区是贯穿于整个Git使用流程的重要概念,所以index文件就很重要。由于是二进制所以我们无法查看具体内容,但是可以用git ls-files --stage 命令查看暂存区里面的文件
$git ls-files --stage100644 44601d12328ea8e04367337184dcccb85859610e 0 README.md
暂存区会在后面介绍,平时几乎不需要直接查看index文件,大家只需要知道index就是暂存区,非常重要就好。
objects目录
Git对象(blob,tree,commit,tag)都保存在objects目录里面,所以objects目录就是真正的仓库。objects里面的目录结构组织的很有特点,是以SHA值的前2位作为目录,后38位作为这个目录下的文件名。
$tree objects/objects/├── 44│ └── 601d12328ea8e04367337184dcccb85859610e├── dd│ └── 981999876726a1d31110479807e71bba979c44├── e7│ └── 77199b859e8e98db46e4897dc7076d07866042├── info└── pack
我们的工作目录里的所有文件,代码、库文件、图片等都会变成git对象存在这个objects目录下。每个文件都是一个二进制文件。可以通过 git cat-file -p SHA值来查看文件的内容。
refs目录
refs目录下面是一些纯文本文件,分别记录着本地分支和远程分支的SHA哈希值。文件的数量取决于分支的数量。
$tree refsrefs├── heads│ ├── develop # 记录本地develop分支的SHA哈希值│ └── master # 记录本地master分支的SHA哈希值├── remotes│ └── origin│ ├── develop # 记录远程版本库develop分支的SHA哈希值│ └── master # 记录远程版本库master分支的SHA哈希值└── tags└── v1.0 # 记录里程碑V1.0的SHA哈希值
回想前面介绍的 HEAD文件, HEAD文件的内容记录了当前处于哪个分支,值是 ref: refs/heads/master 。
而 refs/heads/master文件 记录了master分支的最新提交的SHA哈希值 ,Git就是通过HEAD文件和refs/heads下面的文件来判断当前分支及分支最新提交的。
$cat HEADref: refs/heads/master # 说明当前处于master分支$cat refs/heads/masterdd981999876726a1d31110479807e71bba979c44 # master分支的最新提交SHA哈希值
logs目录
logs目录下面是几个纯文本文件,分别保存着HEAD文件和refs文件内容的历史变化。由于HEAD文件和refs文件的内容就是SHA值,所以log文件的内容就是这些SHA值的变化历史。
$tree logslogs├── HEAD└── refs├── heads│ ├── develop│ └── master└── remotes└── origin├── develop└── master
logs目录的结构和refs几乎一样,只不过每个纯文本文件记录的HEAD文件和分支文件内容的变化日志,也就是SHA哈希值的变更日志。在实际使用中,我们经常需要把代码整体回滚到一个历史状态,这是需要用到 git reflog 命令,这个命令其实就是读取的logs目录里的日志文件。就是这么简单。
$cat logs/HEAD0000000000000000000000000000000000000000 dd981999876726a1d31110479807e71bba979c44 tianle
由于目前为止我们的例子只有一个提交(commit) , 所以只有一个日志记录。
到目前为止 .git目录 里的重要文件目录已经都介绍完了,大家掌握这些就可以了,还有一些其他的文件目录后续也会简单的提到。现在第一次看到这里,虽然我尽力写的简单,但是相信很多人看完一遍都会比较晕。比如提到了Git对象,那么什么是Git对象呢?我们接下来就介绍。等大家把后续的章节都看完一遍再回过头来 看这一章的时候会发现,原来真的不复杂很简单。
Git对象存储及管理
SHA
所有用来表示项目历史信息的文件,是通过一个40个字符的“对象名”来索引的,对象名看起来像这样:
dd981999876726a1d31110479807e71bba979c44
你会在Git里到处看到这种“40个字符”字符串。每一个“对象名”都是对“对象”内容做SHA1哈希计算得来的。
这样就意味着两个不同内容的对象不可能有相同的“对象名”。
这样做会有几个好处:
- Git只要比较对象名,就可以很快的判断两个对象是否相同。
- 因为在每个仓库(repository)的“对象名”的计算方法都完全一样,如果同样的内容存在两个不同的仓库中,就会存在相同的“对象名”下,节省空间。
- Git还可以通过检查对象内容的SHA1的哈希值和“对象名”是否相同,来判断对象内容是否正确。
在unix like 系统中,可以通过 sha1sum 命令对一个内容生成摘要。消息摘要算法主要有两种,分别是MD5和SHA。SHA又可以细分为SHA-1,SHA-256,SHA-384,SHA-512等算法,不同的算法会生成不同比特大小的哈希值。sha1sum 这个从名字上可以看出,用的是sha1 summary算法。git生成SHA哈希值用的就是SHA1算法。
$printf 'dangdang' | sha1sum19dd09a3502f4d118893eaefbeab0dfc177e0b7a - #这就是 'dangdang'通过SHA1算法生成的摘要
SHA1是一种密码学的信息摘要算法 ,
对象
每个对象(object) 包括三个部分:类型,大小和内容。大小就是指内容的大小,内容取决于对象的类型,Git有四种类型的对象:" blob"、" tree"、 " commit" 和" tag"。
BLOB
用来存储文件数据,通常是一个文件。
TREE
“tree”有点像一个目录,它管理一些“tree”或是 “blob”(就像文件和子目录)
COMMIT
一个“commit”只指向一个"tree",它用来标记项目某一个特定时间点的状态。它包括一些关于时间点的元数据,如时间戳、最近一次提交的作者、指向上次提交(commits)的指针等等。
TAG
一个“tag”是来标记某一个提交(commit) 的方法。
几乎所有的Git功能都是使用这四个简单的对象类型来完成的。它就像是在你本机的文件系统之上构建一个小的文件系统。这个小型的文件系统就是 .git/objects目录。
与SVN的区别
Git与你熟悉的大部分版本控制系统的差别是很大的。也许你熟悉Subversion、CVS、Perforce、Mercurial 等等,他们使用 “增量文件系统” (Delta Storage systems), 就是说它们存储每次提交(commit)之间的差异。Git正好与之相反,它会把你的每次提交的文件的全部内容(snapshot)都会记录下来。这会是在使用Git时的一个很重要的理念。
为了更好的说明这4种对象类型,我们现在添加一些文件目录到当前的版本库中。
$mkdir -p script/shell script/perl ; echo '#!/bin/bash' > script/shell/test1.sh ;echo '#!/usr/bin/perl' > script/perl/test2.pl$git add .$git commit -m 'add shell and perl scprit.'$git log#我们看到现在有了两次commitcommit e6361ed35aa40f5bae8bd52867885a2055d60ea2Author: tianle Date: Wed May 10 11:07:52 2017 +0800add shell and perl scprit.commit dd981999876726a1d31110479807e71bba979c44Author: tianle Date: Fri May 5 19:00:48 2017 +0800init repo and add README.md
看一下现在的工作目录
$tree.├── README.md└── script├── perl│ └── test2.pl└── test1.sh2 directories, 3 files
Blob对象
blob对象通常用来存储文件的内容。

可以使用 git show 或 git cat-file -p 命令来查看一个blob对象里的内容。在我们的例子中 README.md文件对应的 blob对象的SHA1哈希值是 44601d12328ea8e04367337184dcccb85859610e,我们可以通过下面的的命令来查看blob文件内容:
$ git show 44601d1Git学习
一个"blob对象"就是一块二进制数据,它没有指向任何东西或有任何其它属性。
因为blob对象内容全部都是数据,如两个文件在一个目录树中有同样的数据内容,那么它们将会共享同一个blob对象,也就是说同样一份数据内容git只存储一个blob对象。Blob对象和其所对应的文件所在路径、文件名是否改被更改都完全没有关系。
可以通过 git hash-object 命令生成文件的SHA哈希值,如果加上 -w 参数,会把这个文件生成blob对象并写入对象库。 hash-object 命令是个Git比较底层的命令,平时正常使用Git几乎用不到。
$git hash-object README.md44601d12328ea8e04367337184dcccb85859610e#这只会显示READMD.md文件blob对象的SHA值,并不会生成blob文件。#git hash-object -w README.md ,则会真正把README.md生blob对象并写入对象库
总之,被Git管理的所有文件都会生成一个blob对象,
Icon不需要写完整40位的SHA哈希值,只写前7位就可以
Tree 对象
一个tree对象有一串(bunch)指向blob对象或是其它tree对象的指针,它一般用来表示内容之间的目录层次关系。
git ls-tree 或 git cat-file -p 命令还可以用来查看tree对象,现在我们查看刚刚最新提交对应的Tree对象 我们可以像下面一样来查看它:
$git ls-tree HEAD^{tree}100644 blob 44601d12328ea8e04367337184dcccb85859610e README.md040000 tree 16a87dbed191bcfb19a4af9d0cc569f6448a01cc script
就如同你所见,一个tree对象包括一串(list)条目,每一个条目包括:mode、对象类型、SHA1值 和名字(这串条目是按名字排序的)。它用来表示一个目录树的内容。
一个tree对象可以指向(reference): 一个包含文件内容的blob对象, 也可以是其它包含某个子目录内容的其它tree对象. Tree对象、blob对象和其它所有的对象一样,都用其内容的SHA1哈希值来命名的;只有当两个tree对象的内容完全相同(包括其所指向所有子对象)时,它的名字才会一样,反之亦然。这样就能让Git仅仅通过比较两个相关的tree对象的名字是否相同,来快速的判断其内容是否不同。tree对象存储的是指针(tree和blob的SHA哈希值),不存储真正的对象。tree对象可以理解为就是一个目录,目录里包含子目录(tree的SHA值)和文件(blob的SHA值).而SHA值所对应的真正的对象文件存在 .git/objects下面。
Icon在submodules里,trees对象也可以指向commits对象,本文不涉及submodules的相关内容,因为平时一般开发很少用到,如果确实需要,可以查询Git官方手册
Commit对象
Commit就是提交, "commit对象"指向一个"tree对象", 这个tree对象就是本次提交所对应的目录树,里面包括这次提交时工作区里面所有的目录和文件的指针,有时也叫做快照。"commit对象"还带有相关的描述信息.

可以用 git log -1 --pretty=raw 或 git show -s --pretty=raw 或 git cat-file -p
$git cat-file -p HEADtree 8d384da6a7ebc4b88cc5fc5e45d609faf9b2cb29parent dd981999876726a1d31110479807e71bba979c44author tianle committer tianle add shell and perl scprit.$git show -s --pretty=raw dd98199commit dd981999876726a1d31110479807e71bba979c44tree e777199b859e8e98db46e4897dc7076d07866042author tianle committer tianle init repo and add README.md
提交(commit)由以下的部分组成:
一个 tree对象: tree对象的SHA1签名, 代表着目录在某一时间点的内容.
父提交 (parent(s)): 提交(commit)的SHA1签名代表着当前提交前一步的项目历史. 上面的那个例子就只有一个父对象; 合并的提交(merge commits)可能会有不只一个父对象. 如果一个提交没有父对象, 那么我们就叫它“根提交"(root commit), 它就代表着项目最初的一个版本(revision). 每个项目必须有至少有一个“根提交"(root commit)。Git就是通过父提交把每个提交联系起来,也就是我们一般所说的提交历史。父提交就是当前提交上一版本。
作者 : 做了此次修改的人的名字, 还有修改日期.
提交者(committer): 实际创建提交(commit)的人的名字, 同时也带有提交日期. TA可能会和作者不是同一个人; 例如作者写一个补丁(patch)并把它用邮件发给提交者, 由他来创建提交(commit).
提交说明 :用来描述此次提交.
一个提交(commit)本身并没有包括任何信息来说明其做了哪些修改; 所有的修改(changes)都是通过与父提交(parents)的内容比较而得出的。
一般用 git commit 来创建一个提交(commit), 这个提交(commit)的父对象一般是当前分支(current HEAD), 同时把存储在当前索引(index)的内容全部提交.
commit是使用频率最高的对象,一般在使用Git时,我们直接接触的就是commit。我们 commit代码, merge代码, pull / push代码,重置版本库,查看历史,切换分支这些在开发流程中的基本操作都是直接和commit对象打交道。
对象模型
现在我们已经了解了3种主要对象类型(blob, tree 和 commit), 好现在就让我们大概了解一下它们怎么组合到一起的.
回忆一下现在项目的目录结构:
$tree.├── README.md└── script├── perl│ └── test2.pl└── test1.sh2 directories, 3 files
在Git中它们的存储结构看起来就如下图:
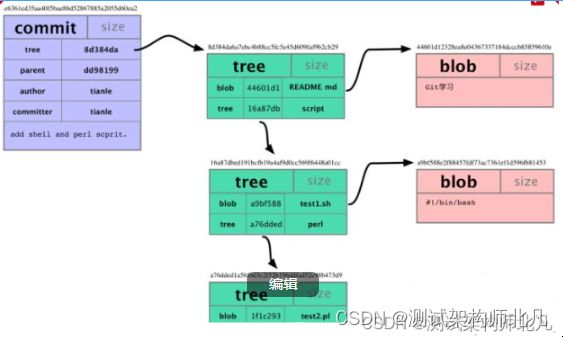
Icon每个目录都创建了 tree对象, 每个文件都创建了一个对应的 blob对象 . 最后有一个 commit对象 来指向根tree对象(root of trees), 这样我们就可以追踪项目每一项提交内容。除了第一个commit,每个commit对象都有一个父commit对象,父commit就是上一次的提交(历史 history),这样就形成了一条提交历史链。Git就是通过这种方式组成了git版本库
Tag 对象
一个标签对象包括一个对象名, 对象类型, 标签名, 标签创建人的名字("tagger"), 还有一条可能包含有签名(signature)的消息. 你可以用 git cat-file -p 命令来查看这些信息。
现在我们的git对象库里还没有一个tag对象,我们先用 git tag -m
$git tag -m 'create tag from demo' v1.0 #基于当前HEAD建立一个tag,所以tag指向的就是HEAD的引用$git tagv1.0$git cat-file -p v1.0object e6361ed35aa40f5bae8bd52867885a2055d60ea2type committag v1.0tagger tianle create tag from demo

Tag对象就是里程碑的作用,一般在我们正式发布代码是需要建立一个里程碑。
好了,至此我们就把Git的4种对象类型介绍完了。他们是 blob , tree , commit , tag 。这部分非常重要,理解了Git对象模型是理解Git使用流程和各种Git命令的基础。
要想会用Git,这部分必须弄清楚,否则永远不会用,只能照猫画虎死记硬背命令,这样一旦命令的结果的预想的不一致,就懵了。
Git官方文档对这部分写的很详细,看完上面的介绍再仔细看这个文档会有更深的认识 : Git-内部原理-Git-对象
工作区、暂存区、版本库
Git对于我们的代码管理分了3个区域,分别是工作区,暂存区和版本库。这是Git完全不同于SVN的地方。Git之所以强大很大程度上就是因为它设计了3个区域,但同时也是因为这个设计让Git学习起来比较难,上手也比较难,比较难理解。凡事都是有利有弊。
- 工作区(Working Directory):
就是电脑上的一个目录,里面是正在开发的工程代码。执行git init 命令后,生成的这个目录除了.git目录,就是工作区。
- 暂存区(Stage / Index):
暂存区最不好理解的一个概念,可以先认为需要提交的文件要先放到暂存区才能提交。所以暂存区可以理解为“提交任务”。是代码提交到版本库前的一个缓冲区域。
暂存区其实就是 .git/index文件
- 历史库(History):
Git版本库的概念和SVN完全不同。SVN的版本库指的是远程中央仓库,而Git的版本库指的是本地仓库,这里面存放着文件的各个版本的数据。其实就是 .git/objects 目录。Git对象都存在这个目录里
看过Git目录和Git对象两个章节后,再来理解这3个区域其实已经不是很难了。
历史库,版本库,Git仓库,History,叫法不同而已,其实指的是同一回事。就是执行了 git commit 后,生成了commit对象。现在我们知道commit对象包含了提交时间,提交人,提交说明以及提交时的目录树和父提交。那么上面这些都是构成版本库的要素。由于Git管理的所有对象文件都在 .git/objects 目录中,所以版本库概念可以具体形象的理解成 .git/objects 目录里面的对象文件。.git/objects 目录就是版本库,虽然这么说不是十分的准确,但是非常便于记忆和理解。
暂存区,Stage,Cached,Index ,叫法不同而已,其实指的是同一回事。暂存区就是 .git/index 这个二进制文件,记录着目录和文件的引用(SHA1值),而不是真正的文件对象。真正的文件对象存在于 .git/objects目录里面。
工作区其实就没啥可说的了,就是真实的,看的见摸得到的,正在写的代码。就是你的IDE里面打开的这一堆东西。
再次加强一下记忆: 暂存区就是 .git/index文件 ,版本库就是 .git/objects目录
下面的图例展示了3个区域的关系以及涉及到的主要命令 :git add , git commit , git reset , git checkout
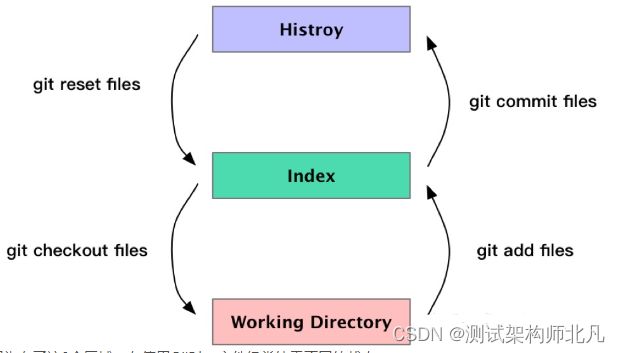
因为有了这3个区域,在使用Git时,文件经常处于不同的状态:
- 未被跟踪的文件(untracked file)
- 已被跟踪的文件(tracked file)
- 被修改但未被暂存的文件(changed but not updated或modified)
- 已暂存可以被提交的文件(changes to be committed 或staged)
- 自上次提交以来,未修改的文件(clean 或 unmodified)
好了,现在我们通过一张详细的图来形象的展现一下这3个区域。
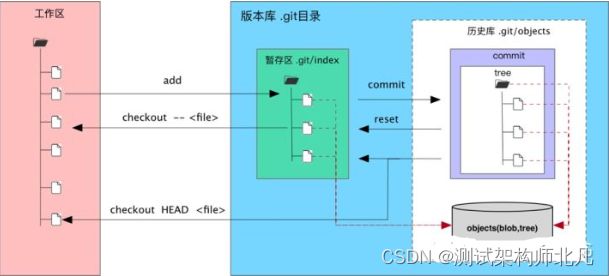
在这个图中,我们可以看到部分 Git 命令是如何影响工作区和暂存区的: 图中左侧为工作区,右侧为版本库。在版本库中标记为 "index" 的区域是暂存区(stage, index)。 图中的 objects 标识的区域为 Git 的对象库,实际位于 ".git/objects" 目录下 当对工作区修改(或新增)的文件执行 git add 命令时,暂存区的目录树被更新,同时工作区修改(或新增)的文件内容被写入到对象库中的一个新的对象中,而该对象的SHA1哈希值被记录在暂存区的文件索引中 当执行提交操作时,暂存区的目录树写到版本库(对象库)中。
当执行 git status 命令扫描工作区改动的时候,先依据 .git/index 文件中记录的(工作区跟踪文件的)时间戳、长度等信息判断工作区文件是否改变。如果工作区的文件时间戳改变,说明文件的内容可能被改变了,需要打开文件,读取文件内容,和更改前的原始文件相比较(本地文件和与之对应的object库中的文件的内容进行对比),判断文件内容是否被更改。如果文件内容没有改变,则将该文件新的时间戳记录到 .git/index 文件中。因为判断文件是否更改,使用时间戳、文件长度等信息进行比较要比通过文件内容比较要快的多,所以 Git 这样的实现方式可以让工作区状态扫描更快速的执行,这也是 Git 高效的因素之一。
命令 git diff
git add
准确的说法是 git add files 做了两件事:
- 将本地文件的时间戳、长度,当前文档对象的id等信息保存到一个树形目录中去(.git/index,即暂存区)
- 将本地文件的内容做快照并保存到Git 的对象库(.git/object) 。
从命令的角度来看,git add 可以分两条底层命令实现:
- git hash-object
- git update-index --add
$git hash-object a.txt$git update-index --add a.txt#以上两条命令等价于 git add a.txt
第一条命令,Git将会根据新生成的文件产生一个长度为40的SHA1哈希字符串,并在.git/objects目录下生成一个以该SHA1的前两个字符命名的子目录,然后在该子目录下,存储刚刚生成的一个新文件,新文件名称是SHA1的剩下的38个字符。
第二条命令将会更新.git/index索引,使它指向新生成的objects目录下的文件。
这2条命令是为了说明git add 文件到暂存区Git做了哪些事情,真正工作中大家只要记住把文件放到暂存区就是用 git add 命令就好。
我们再次加强一下理解,暂存区实际上就是一个包含文件索引的目录树,像是一个虚拟的工作区。在这个虚拟工作区的目录树中(.git/index),记录了文件名、文件的状态信息(时间戳、文件长度等),文件的内容并不存储其中,而是保存在 Git 对象库(.git/objects)中,文件索引建立了文件和对象库中对象实体之间的对应。
git commit
- 生成一个commit对象
- 把暂存区的目录树写到版本库中,也就是生成一个tree对象,这个tree里面的引用和暂存区index里的引用一样
- 跟新当前分支ref文件的引用,指向最新生成的这个commit的SHA1哈希值
git reset HEAD 命令,暂存区的目录树会被重写,被最新提交的目录树所替换,但是工作区不受影响。
“git checkout .” 或者 “git checkout --
“git checkout HEAD .” 或者 “git checkout HEAD
由于add 和 commit于SVN中的add commit命令名字相同,用惯了SVN刚接触Git时会很困惑,这里说明一下:
两个版本库中的add命令有点相似,都是让版本库track这个文件。只有被add的文件版本库才会管理它,这点是一样的。不同的是在SVN中,只有新文件才需要add ,之后就不再需要add了。而Git是不仅仅新文件需要add ,每次修改后都需要add 。
两个版本库中的commit命令则完全不同。在SVN中 commit是把代码提交到远程版本库,commit之后别人就能看到这个提交了,需要联网。而Git中的commit是提交到本地版本库,不是到远程版本库,别人看不到这个提交,完全都是本地操作,不需要联网。所以说SVN是集中式的版本库,而Git是分布式的。
这些就是Git暂存区相关的知识,比较难理解,一开始看不懂的话也正常,我也不想写更多了,因为确实没什么可写的了,写更多那样只会更晕。理解这部分内容最好的办法就是动手做实验,每个命令多执行几次,而且要看每个命令执行后 对.git/index 和 .git/objects目录的影响。放心的练习,不会因为执行几条Git命令就把电脑搞爆炸了。
最后总结几点:
- 理解Git暂存区和版本库的前提是理解和弄明白Git对象(blob,tree,commit),否则只是看本文或网上各种帖子的描述,死记这几个命令的话,是很难理清这个逻辑的,即使当时有思路了,过几天也会忘。因为这是Git的原理,弄清原理后看似复杂难用的git其实就变得很简单。
- 一定不能只是看和想,这个东西不动手很难真的想明白,一定多动手试试。
- 在实际开发中请记住,只要对一个文件执行add命令了,不管之后这个文件是被删了还是从历史版本中彻底删除了,这个文件的内容一定可以找回来。原因不解释,等对暂存区和Git对象真的明白了,自然就清楚了。
- 初用Git时千万不要和SVN的命令和流程做对比,这两个版本库的设计哲学和实现完全不一样。千万不要想Git的这个命令对应着SVN的哪个命令,因为很难找到对应。
至此,Git的原理已经介绍完了。接下来我们看看具体的使用。具体的使用就是命令,不同的命令干不同的活。
分支
分支是用来管理开发的,这点Git分支并没有什么不同,所以我们就不在这里过多解释什么是分支。我们现在要说的是Git是怎么实现的分支,为什么Git建分支这么快,这么方便?为什么Git分支对磁盘空间几乎没有任何影响,即使建了200个分支占用的空间也只不过不到1M的磁盘空间?在本章我们要关注的就是这个问题。
我们已经了解了Git目录结构和主要的文件,也清楚了Git的对象,现在是时候看一下Git版本库的整体结构了。
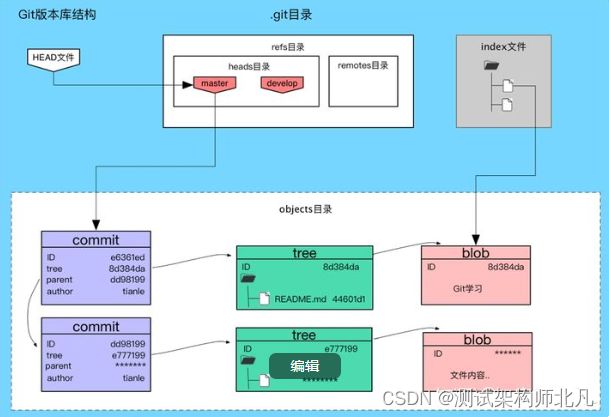
这个就是Git版本库的结构,组成这个结构的每个元素我们在前边都详细的描述过,大家仔细看下这个图就应该能够对Git整体有个清晰的认识了。
HEAD 文件记录了当前分支的引用文件名
refs/heads/
$git branch* master #当前处于master分支$cat .git/HEADref: refs/heads/master #指向了master分支,上面的git branch命令就是读取了这行记录才知道当前处于master分支$cat .git/refs/heads/mastere6361ed35aa40f5bae8bd52867885a2055d60ea2 #说明master分支所指向的提交ID
我们看到这两个文件都是普通的纯文本文件,且每个文件都只有一行记录。HEAD文件只有20字节,分支文件有41字节大小。
Git就是通过这两个文件表示一个分支,除此以外什么事都没干。分支文件在 .git/refs/heads 目录下与分支同名,每新建一个分支这个目录下就会生成一个同名的分支文件。
对于master分支,它的分支文件就是 .git/refs/heads/master ; 对于develop分支,它的分支文件就是 .git/refs/heads/develop,以此类推。
我们现在只有一个master分支,所以 .git/refs/heads/ 目录下只有一个master文件。
通过 git branch branchname
git branch develop e6361ed ,基于提交e6361ed创建新分支develop
git branch feature, 这个命令等价于 git branch feature HEAD,就是给予当前分支的最新提交创建分支feature
$git branch #git branch命令可以查看当前所有本地分支,前面有 * 的代表当前分支develop* master #当前在master分支上$git branch develop #基于master分支,创建一个名为develop的分支,这2个分支指向同一个commitID$cat .git/refs/heads/develop #.git/refs/heads目录下会生成一个名为develop的文本文件,文件的内容就是分支指向的commitIDe6361ed35aa40f5bae8bd52867885a2055d60ea2$git branch #git branch develop 只新建分支但不切换分支,所以目前仍然在master分支上面develop* master$cat .git/HEADref: refs/heads/master #HEAD文件指向的还是master的分支引用文件$git checkout develop #git checkout 命令会切换分支$git branch* develop #当前分支已经切换到develop上master$cat .git/HEAD #HEAD文件的内容也随之改变ref: refs/heads/develop$git checkout -b feature #git checkout -b 新建并切换分支, 等价于 git branch feature ; git checkout feature$git branchdevelop* featuremaster$git checkout master$git branch -D feature #git branch -D 删除一个分支Deleted branch feature (was e6361ed).
HEAD文件经常被称为头指针,就像一个游标,这个HEAD指向哪个分支当前就处于哪个分支。所以 git checkout 分支名 这个命令就是修改HEAD文件的内容。我们也可以手工修改HEAD文件,这和执行命令的效果是一样一样的。如果我们故意把HEAD文件清空,那么在这个项目目录里就无法识别这是个git工程了,有兴趣可以试试。
在项目目录中开发是,一般情况都是处于某一个分支中。有时,也会不处于任何分支下,这种情况叫做头指针分离。就是HEAD指向了一个提交号而不是分支文件
git checkout 提交号 命令会让项目处在头指针分离模式下
$git checkout e6361ed #detached HEAD, 头指针分离模式Note: checking out 'e6361ed'.You are in 'detached HEAD' state. You can look around, make experimentalchanges and commit them, and you can discard any commits you make in thisstate without impacting any branches by performing another checkout.$cat .git/HEADe6361ed35aa40f5bae8bd52867885a2055d60ea2 #HEAD指向了一个具体的提交号
在头指针分离模式下也可以继续正常add commit 等操作,并没有特别大的区别,只是不处在任何分支下。我觉得头指针分离并没什么特别的意义,相当于一个人不属于任何组织,单干。
一般是在需要做一些修改尝试又不想建一个分支的情况下会直接checkout 一个提交号进入头指针分离模式。但是Git建一个分支非常方便快捷,并不麻烦。所以,我们只需知道就行,平时很少用到。
Icongit init 初始化一个Git代码库之后,默认处于master分支下。HEAD文件指向 ref: refs/heads/master 。但是并不会有 .git/refs/heads/master文件,只有当第一次提交之后才会生成这个文件
现在我们了解到,Git新建一个分支就是在.git/refs/heads目录下生成一个41字节的分支文件,切换分支就是修改 .git/HEAD 文件的一行内容。不得不说Git的这个设计实在是太精妙了。
新建100个分支,就是新建100个分支文件而已,在分支间切换也只是修改一个HEAD文件而已。
所以
Git建分支才会这样快
无论建多少个分支都不会使Git仓库变得冗余
分支间切换可以在瞬间完成
分支是所有版本管理工具的重要内容,所以Git高效的分支机制是他这么受欢迎的重要原因之一,也是Git的优势所在。
Git分支比较简单好理解,没啥特别值得多说的。我这里主要想讨论的是对分支的管理
Git分支管理
经过近10年的发展,在实践中大家总结出来了一个行之有效的Git分支管理模型。这个模型有一些变种,但都是基于 Vincent Driessen 在 2010年提出的这个模型基础之上的。
这里我就介绍一下这个模型,英文好的同学可以直接看原文 http://nvie.com/posts/a-successful-git-branching-model/
如果我们的项目里只有一个分支,那么这个项目代码管理就是及其失败的。相当于只是把版本库当作一个代码分享工具,而不是开发流程管理工具。如果只有一个分支的话,那么这个项目团队一定是没有开发管理流程的。
因为一个分支确实无法HOLD住整个复杂的开发测试发布部署流程。比如,当你为一个项目开发新功能时线上出现BUG了,需要紧急修复,你改如何处理手头的代码呢?如果这个功能是几个人共同开发的,情况就更复杂了。比如,新加入的成员需要看线上稳定的程序代码,但是这时上面却是你提交了一半的新功能,如何保证代码取下来和线上的一致?再比如,你在给项目增加一个重要功能,另一个同事要增加别的不相关的功能,如何保证在最终合并前你们不互相影响?对于持续集成工具来说,如何从分支上拉取的代码保证是一定可以正常编译和运行的? 例子太多了,实际开发工作有各种复杂的情况。
所以这就需要我们管理好,利用好分支。
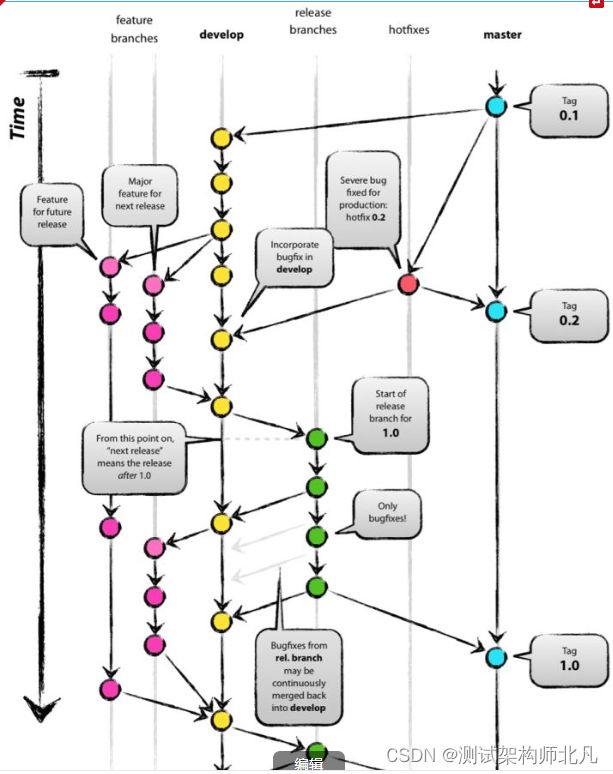
基础分支
- master
- develop
一个项目的代码库至少要有master和develop这两个分支。团队成员从主分支(master)获得的都是处于可发布状态的代码,而从开发分支(develop)应该总能够获得最新开发进展的代码。
从master上获得的代码一定要保证是和线上运行的程序是一致的。
从develop上获得的应该是最新的稳定版本的代码。
除了基础分支外,我们还需要辅助分支。辅助分支大体包括如下几类:“管理功能开发”的分支、“帮助构建可发布代码”的分支、“可以便捷的修复发布版本关键BUG”的分支。
辅助分支的最大特点就是“生命周期十分有限”,完成使命后即可被删除。
辅助分支
- Feature branch
- Release branch
- Hotfix branch
Feature branch
从develop分支检出,最终也会合并于develop分支。常用于开发一个独立的新功能,且其最终的结局必然只有两个,其一是合并入“develop”分支,其二是被抛弃。最典型的“Fearture branches”一定是存在于团队开发者那里,而不应该是“中心版本库”中。
通过下面的命令来解释这个流程
$ git checkout -b myfeature develop#在myfeature上开发完代码之后,需要合并到develop分支上$ git checkout develop$ git merge myfeature$ git branch -d myfeature$ git push origin develop
Release branch
从develop分支检出,最终合并于“develop”或“master”分支。这类分支建议命名为“release-*”。通常负责“短期的发布前准备工作”、“小bug的修复工作”、“版本号等元信息的准备工作”。与此同时,“develop”分支又可以承接下一个新功能的开发工作了。在一段短时间内,在“Release branch”上,我们可以继续修复bug。在此阶段,严禁新功能的并入,新功能应该是被合并到“develop”分支的。“Release branch”产生新提交的最好时机是“develop”分支已经基本到达预期的状态,至少希望新功能已经完全从“Feature branches”合并到“develop”分支了。
经过若干bug修复后,“Release branches”上的代码已经达到可发布状态,此时,需要完成三个动作:第一是将“Release branches”合并到“master”分支,第二是一定要为master上的这个新提交打Tag(记录里程碑),第三是要将“Release branches”合并回“develop”分支。
通过下面的命令来解释这个流程
$ git checkout -b release-1.2 develop#修改版本号等元信息的准备工作或者小bug的修复工作后 要合并到master$ git checkout master$ git merge release-1.2$ git tag -a 1.2 #发布前要建立里程碑#如果有bug的修改,还需要合并到develop$ git checkout develop$ git merge release-1.2$ git branch -d release-1.2 #最后删除这个发布分支,它已经完成使命
Hotfix branch
从“master”检出,合并于“develop”和“master”,通常命名为“hotfix-*”
建议设立“Hotfix branches”的原因是:线上总是可能产生非预期的关键BUG,希望避免“develop分支”新功能的开发必须为BUG修复让路的情况。
BUG修复后,需要将“Hotfix branches”合并回“master”分支,同时也需要合并回“develop”分支
通过下面的命令来解释这个流程
$ git checkout -b hotfix-1.2.1 master#修复完BUG之后,要合并到master$ git checkout master$ git merge hotfix-1.2.1$ git tag -a 1.2.1 #修改线上BUG需要打标签#修复完BUG之后,也要合并到develop$ git checkout develop$ git merge hotfix-1.2.1$ git branch -d hotfix-1.2.1 #最后hotfix的分支使命完成,删除之
这就是一个非常好的分支管理模型。
所以,在我们的gitlab上面我们一定至少要有2个分支
master 永远保持和线上代码同步,在上线部署时从这个分支拉去代码打包。如果我们的DI工具到时的功能完善,则DI工具直接从这个分支去代码打包发布
develop 我们的持续集成工具从每天从这个分支上取代码编译大包部署到测试环境(KVM,Docker)。
每次上线前都要建立里程碑Tag
分支使用规范
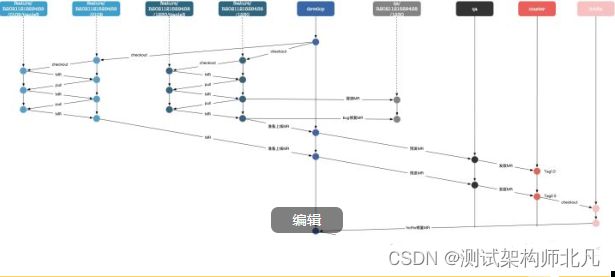
这种分支模型的好处是:
- 逻辑上明确各个分支的作用,在流程规范上杜绝了代码提交的混乱、代码合并的混乱、代码版本的混乱,可以更好的支持多人并行需求的开发过程。
- 从流程上严格保证了未经测试的代码不会被发布到生产环境。
- 不允许直接向develop分支提交代码,保证了develop分支的纯粹性,因为develop分支代表了最新最稳定的代码分支。同时,也可以把最后的代码评审收口到develop,尽最大努力保证develop分支代码的可靠性。
- qa分支部署预发环境,尽最大努力把最后的风险控制在预发环境,保证生产环境的绝对可靠。
- 在需求多并且交付频密,且多人协作的开发情况下,保证需求和需求之间、开发者和开发者之间互不影响。
- 只有master分支可以部署生产环境,尽最大努力保证master分支的干净、纯粹、稳定和万无一失。
远程版本库
Git版本库就是项目目录下的 .git 目录,里面包括所有的历史版本文件。如果这个.git目录发生损坏或被删除那么整个版本库就永远丢失了,或者不小心把整个项目目录删了,那么所有的努力都白费了,我们使用版本控制工具就是为了保证代码不丢失。还有,我们总是需要写协作分享我们的代码,那怎么分享自己的项目目录给别人呢?当然不是靠QQ或发邮件了。
克隆
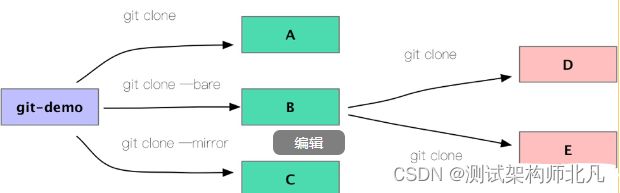
git clone 命令可以克隆一个版本库,主要有3种形式:
用法1 : git clone
用法2 : git clone --bare
用法3 : git clone --mirror
用法1会克隆一个
用法2克隆出来的版本库不包括工作区,直接就是版本库的内容,也就是不包括.git目录而是直接就是.git目录里面的内容。这样的版本库称为裸版本库。(通过bare名字就可以看出)
用法3和用法2类似,也是克隆出一个裸版本库。不过是可以通过git fetch命令与上游版本库repository持续同步。
$git clone git-demo A #clone一个对等的版本库 ACloning into 'A'...done.$git clone --bare git-demo B #clone一个裸的版本库 BCloning into bare repository 'B'...done.$git clone --mirror git-demo C #clone一个裸的镜像版本库 CCloning into bare repository 'C'...done.$ls -a A #对等版本库A 和 git-demo有着同样的工作区,同时也有.git目录.git README.md script$ls -a B #裸版本库B和C里面直接就是.git目录里面的内容HEAD config description hooks info objects packed-refs refs$ls -a CHEAD config description hooks info objects packed-refs refs$cat A/.git/config[core]repositoryformatversion = 0filemode = truebare = false #说明是非裸版本库logallrefupdates = trueignorecase = trueprecomposeunicode = true[remote "origin"] #当前版本库的上游版本库,名字为 originurl = /Users/christian/work/tmp/git/git-demo #上游版本库的位置(URL)fetch = +refs/heads/*:refs/remotes/origin/* #git fetch时的默认引用表达式[branch "master"] #本地master分支与上游版本库分支的映射,这样执行git pull时 相当于 git pull origin masterremote = originmerge = refs/heads/master$cat B/config[core]repositoryformatversion = 0filemode = truebare = true #说明是裸版本库ignorecase = trueprecomposeunicode = true[remote "origin"]url = /Users/christian/work/tmp/git/git-demo #上游版本库的位置(URL)$cat C/config[core]repositoryformatversion = 0filemode = truebare = true #说明是裸版本库ignorecase = trueprecomposeunicode = true[remote "origin"]url = /Users/christian/work/tmp/git/git-demofetch = +refs/*:refs/*mirror = true #说明是--mirror , 可以执行git fetch命令和上游保持同步
版本库之间的交互有3个命令:
git clone
git pull
git push
git fetch
有两点需要特别注意:
- 在非裸版本库中可以执行git pull和git push命令同步和推送代码,也可以从一个在非裸版本库pull代码,但是不能向在非裸版本库中push,因为在非裸版本库有工作区,push会导致工作区混乱。
- 在裸版本库中不可以执行git pull和git push命令,但是可以从裸版本库pull和向裸版本库push.
Tips
Git的裸版本库约定以".git"结尾,如标准的裸版本库名 git-demo.git 。这里为了例子演示方便,取了好写好记的名字 A B C...
为了方便我们的实验,需要再clone两个版本库
$git clone B D #基于裸版本库B clone一个非裸版本库 DCloning into 'D'...done.$git clone B E #基于裸版本库B clone一个非裸版本库 ECloning into 'E'...done.#没看错,可以从一个裸版本库clone出一个非裸版本库。$ls -a E #可以看到,E有工作区,也有.git目录.git README.md script
现在有6个版本库,看起来的关系是这样的
下面我们通过实例,来看一下 git pull,git push,git fetch 这3个命令
$cd git-demo$git commit --allow-empty -m 'c1' #为了方便测试,在git-demo里提交了一个空的commit[master 472f2ea] c1$cd ../A$git pull #在非裸版本库A中,把上游版本库master分支最新的提交pull下来remote: Counting objects: 1, done.remote: Total 1 (delta 0), reused 0 (delta 0)Unpacking objects: 100% (1/1), done.From /Users/christian/work/tmp/git/git-demoe6361ed..472f2ea master -> origin/masterUpdating e6361ed..472f2eaFast-forward$git log --oneline472f2ea c1 #确实将c1提交pull下来了。e6361ed add shell and perl scprit.dd98199 init repo and add README.md$git commit --allow-empty -m 'c2' #在A中也提交了一个新的commit[master eef952e] c2$git push #想要推送到上游版本库,但是失败了,因为上游git-demo是个非裸版本库Counting objects: 1, done.Writing objects: 100% (1/1), 171 bytes | 0 bytes/s, done.Total 1 (delta 0), reused 0 (delta 0)remote: error: refusing to update checked out branch: refs/heads/master...$cd ../B$git pull #我们到版本库B中,也想pull上游的最新提交c1,但是失败了,因为B没有工作区,是个裸版本库fatal: This operation must be run in a work tree$cd ../git-demo$git push ../B master #我们到git-demo中把提交push到B,说明可以向裸版本库push数据Counting objects: 1, done.Writing objects: 100% (1/1), 170 bytes | 0 bytes/s, done.Total 1 (delta 0), reused 0 (delta 0)To ../Be6361ed..472f2ea master -> master$cd ../C$git fetch #我们到mirror镜像版本库中fetch上游git-demo的新提交From /Users/christian/work/tmp/git/git-demoe6361ed..472f2ea master -> master
通过上面的例子我们基本了解了3中不同类型版本库的区别,下面我们再看个好玩的例子来加深对clone版本库的理解
$cd ../D$git pull #到非裸版本库D中pull上游裸版本库B的提交$git log --oneline472f2ea c1 #提交c1已经被pull下来,说明可以从裸版本库pull代码e6361ed add shell and perl scprit.dd98199 init repo and add README.md$git commit --allow-empty -m 'c2' #我们在当前D中创建一个新commit 'c2'[master be5099d] c2$git push origin master #把提交push到上游B, 说明可以向裸版本库push代码Counting objects: 1, done.Writing objects: 100% (1/1), 170 bytes | 0 bytes/s, done.Total 1 (delta 0), reused 0 (delta 0)To /Users/christian/work/tmp/git/B472f2ea..be5099d master -> master$cd ../E$git pull #到非裸版本库E中pull上游裸版本库B的提交remote: Counting objects: 2, done.remote: Compressing objects: 100% (2/2), done.remote: Total 2 (delta 1), reused 0 (delta 0)Unpacking objects: 100% (2/2), done.From /Users/christian/work/tmp/git/Be6361ed..be5099d master -> origin/masterUpdating e6361ed..be5099dFast-forward$git log --oneline #我们看到了D中最新的提交 c2 , 这是从上游裸版本库B 中pull下来的。be5099d c2472f2ea c1e6361ed add shell and perl scprit.dd98199 init repo and add README.md
上面例子的这个流程有没有觉得很眼熟 ? 对,这就是我们平时的开发流程,从一个远程中央版本库拉取(pull)代码,本地修改,然后推送(push)回远程中央版本库。在这里,版本库 B 就是 远程中央版本库。
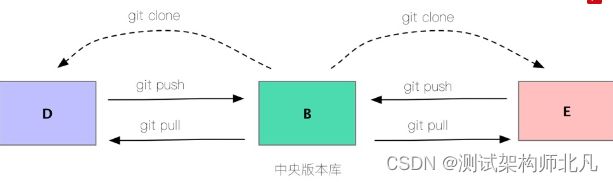
版本库 B 就是中央版本库。虽然它在本地而不是在"远程",大家不要觉得奇怪,因为没有人说中央版本库必须在"远程"。
对于Git版本库来说,从广义上来讲,除了本身以外,其他的版本库都是远程版本库。每个版本库都是平等的,无非是有的版本库处于同一个本地磁盘,有的在网络上。根据所处的位置不同,Git会采用不用的通信协议来进行交互。在本地就用本地协议,在网络上就用 SSH ,GIT,HTTP(S),FTP(S)等网络协议。不同的协议对使用来讲具体来说就是URL不同,其他的原理和使用方式没有任何不同。
在我们的例子中,因为使用的都是 /path/to/file ,这个是本地协议。在最开始的例子中,git clone ,这个用的就是HTTP协议。
不知道大家有没有注意到上面的例子中的这行命令:
$git push ../B master #我们到git-demo中把提交push到B,说明可以向裸版本库push数据
我们在例子中在克隆出来的版本库里向上游push,从上游pull代码。看起来天经地义,因为他们都有个上游可以追溯。但是虽然B是 git-demo的下游,但是对于git-demo里说并不知道这个下游,因为在git-demo没有任何记录下游的信息。(想想也是,一个仓库可以clone出来N个新的仓库,无需也不可能记下来所有的仓库)。好啦,这不是我们要说的重点,重点想说的是git-demo可以向一个没有什么关联的仓库push 。所以,向一个版本库push代码的完整命令可以写为:
git push 版本库 分支
只要Git可以找到这个版本库,就具备向它push的条件。这个版本库可以有3中形式:
1.版本库的路径
版本库的路径就是一个明确的URL,可以指向本地也可以指向网络上的版本库
$cd D#为了实验,我们在gitlab上新建一个名为git-demo2的空project$git push http://git.dangdang.com/tianle/git-demo2.git master #可以把版本库 D push 到 gitlab上面的git-demo2,虽然它们从未建立过任何联系Counting objects: 11, done.Delta compression using up to 4 threads.Compressing objects: 100% (6/6), done.Writing objects: 100% (11/11), 805 bytes | 0 bytes/s, done.Total 11 (delta 2), reused 0 (delta 0)To http://git.dangdang.com/tianle/git-demo2.git* [new branch] master -> master$git push ../C master #版本库C和D也从未建立过关联,但仍然可以pushCounting objects: 1, done.Writing objects: 100% (1/1), 170 bytes | 0 bytes/s, done.Total 1 (delta 0), reused 0 (delta 0)To ../C472f2ea..be5099d master -> master$git init FInitialized empty Git repository in /Users/christian/work/tmp/git/F/.git/$cd F$git pull http://git.dangdang.com/tianle/git-demo2.git master #可以直接从git-demo2 pull代码,而不是必需先cloneremote: Counting objects: 11, done.remote: Compressing objects: 100% (6/6), done.remote: Total 11 (delta 2), reused 0 (delta 0)Unpacking objects: 100% (11/11), done.From http://git.dangdang.com/tianle/git-demo2* branch master -> FETCH_HEAD
说明,只要git能找到命令中的这个版本库,就可以对其push 和 pull操作,并不一定需要clone来建立关联。
2.远程版本库的名字
我们可以为版本库指定一个名字,而不需要每次都写完整的URL。如果我们把下面的配置加到 .git/config配置文件中,就可以给版本库D注册一个远程版本库。
[remote "git-demo2"]url = http://git.dangdang.com/tianle/git-demo2.gitfetch = +refs/heads/*:refs/remotes/git-demo2/*$cat .git/config[core]repositoryformatversion = 0filemode = truebare = falselogallrefupdates = trueignorecase = trueprecomposeunicode = true[remote "origin"] #名为origin的远程版本库,URL : /Users/christian/work/tmp/git/Burl = /Users/christian/work/tmp/git/Bfetch = +refs/heads/*:refs/remotes/origin/*[branch "master"] #本地master分支对应的远程版本库分支remote = originmerge = refs/heads/master[remote "git-demo2"] #名为origin的远程版本库,URL : http://git.dangdang.com/tianle/git-demo2.giturl = http://git.dangdang.com/tianle/git-demo2.gitfetch = +refs/heads/*:refs/remotes/git-demo2/*$git fetch git-demo2 #直接写名字,不需要写完整URLFrom http://git.dangdang.com/tianle/git-demo2* [new branch] master -> git-demo2/master
3.省略版本库和分支名
如果 .git/config文件中有类似下面的配置,那么 执行 git push 等价于 git push origin master ,git pull 等价于 git push origin pull
[remote "origin"] #名为origin的远程版本库,URL : /Users/christian/work/tmp/git/Burl = /Users/christian/work/tmp/git/Bfetch = +refs/heads/*:refs/remotes/origin/*[branch "master"] #本地master分支对应的远程版本库分支remote = originmerge = refs/heads/master
理论上只要能定位到一个版本库就可以push/pull但是必须满足三个条件:
1: 必需是裸版本库
2: 有这个版本库push和pull的权限
3: 满足快进式Fast-forward模式,否则无法push成功,pull只会把代码fetch下来,但不会merge
快进式(Fast-forward)
一般情况下,只允许快进式push.所谓快进式推送,就是要推送的本地版本库的提交是建立在远程版本库相应分支的现有提交基础上的,即远程版本库相应分支的最新提交是本地版本库最新提交的祖先提交。非快进式(non-fast-forward)提交是不被允许的,因为这样每个人都随便提交的话会互相覆盖,会弄乱版本库,版本库无法保证一个完整的提交链。
Tip
广义上来说,当前版本库之外的版本库都是远程版本库,而上游版本库指的是通过git clone 或 git remote add 所指向的那个版本库。所以上游版本库是远程版本库的一个子集。但是在实际工作中,几乎所有的版本库都是通过git clone而来,所以一般情况下远程版本库和上游版本库是同一个意思。
因为每个版本库都是平等的,没有一个严格主次之分,所以说,Git是分布式的版本库,每个版本库都保存这所有的历史记录
远程版本库
我们现在已经了解了Git版本库之间的关系和交互方式,我们也应该清楚了Git是分布式的版本库,而不是向SVN这种集中式的版本库。各版本库之间没有主次之分,是平等的。
对于一个项目而言,你可以从你团队中任何一个人机器上的版本库上同步代码,也可以向他的版本库推送代码,所以在理论上来说,并不像SVN那样需要一台远程中央版本库。
但是在实际工作中,这比较难做到,因为首先不能保证个人的机器都不关机,而且最重要的原因是每个人版本库的提交都不一样,不能今天从A那同步代码,明天又向B提交代码。
所以就一定要在这个团队中固定一个人的版本库,大家都从他的版本库同步代码,也向他的版本库提交代码。这样大家的代码在能保证是同步更新的。那即使选定了一个固定的人但又不能保证他一直不关机。所以,我们需要找一个空闲的单独的稳定的服务器来做这个版本库,大家都从这里更新,向这个提交。这个版本库就是实际工作中的“远程版本库”。
因为这本版本库一定是在网络上,所以本机上的版本库和它交互就不能通过本地协议了,需要通过HTTP HTTPS SSH GIT等网络协议才行。
虽然这是一个远程版本库,但并不是一个主版本库,它和每个人机器上的版本库一样,没啥区别。只不过它在一台稳定的不断电的机器上,并且大家都通过它来协作而已。这个所谓的“远程”版本库就是一个普通的git版本库,只不过它恰巧在一个大家都通过网络可以访问到的机器上。
好了,不绕弯子了。我们实际工作中的这个远程版本库就是 git.dangdang.com
我们通过例子看一下是怎么和这个远程版本库交互的,其实这些例子和上面的例子没有任何不同,只是会更具体一些,也对实际工作更有意义。
其实说的还是 git clone, git pull, git push, git fetch这些命令,我们现在就来看看这几个命令是怎么应用于实际工作的。
我们要参与一个项目,首先我们要先从gitlab上clone一个工程到本地。git clone URL 本地目录
$git clone [email protected]:christian-tl/git-demo.git$cd git-demo #工程目录名是git-demo
这样我们就把git-demo工程克隆到本地的 git-demo目录。当然我可以指定这个目录的名称
$git clone [email protected]:christian-tl/git-demo.git your_code$cd your_code #工程目录名是your_code
我们注意到远程版本库的后缀是'.git',根据前面介绍的约定 '.git'后缀的版本库是裸版本库。
所以,远程版本库服务器上面的版本库都是裸版本库。
克隆下来的版本库会默认把他所克隆的这个版本库注册为上游版本库,并且起名为 origin . origin的英文就是‘起源’的意思,可以望文生义。上游版本库可以叫任何名字,只不过origin是git默认的上游版本库的名字,当需要写这个名字的地方却省略时,git默认认为是origin。除此以外,还做了一个本地master分支和远程版本库master分支的映射。
就因为有了这两个映射,所以在本地master分支上执行git pull origin master等价于 git pull, git push origin master等价于 git push
$cat .git/config[core]repositoryformatversion = 0filemode = truebare = falselogallrefupdates = trueignorecase = trueprecomposeunicode = true#git clone之后在本地版本库一定有下面的这2个配置节点[remote "origin"] #注册上游版本库url = [email protected]:christian-tl/git-demo.gitfetch = +refs/heads/*:refs/remotes/origin/*[branch "master"] #本地master分支到origin的master分支的映射remote = originmerge = refs/heads/master
和 git init 一样 git clone之后版本库默认只有一个master分支,master分支指向了origin/master分支相同的提交号 。
但是远程有master和develop两个分支,那我们如何得到develop分支呢?等等,是怎么知道远程版本库有master和develop的呢?
奥秘就存在于文件 .git/packed-refs 之中 ,git clone之后 会把了远程版本库的分支和对应的提交号存在这个文件里
$cat .git/packed-refs #这个文件记录了远程版本库的分支和对应的提交号472f2eaf555b622c4996d7cd17e2337c0c7fc448 refs/remotes/origin/develope6361ed35aa40f5bae8bd52867885a2055d60ea2 refs/remotes/origin/master
我们得到了这些commitID就自然找到了对应的commit对象,找到了commit对象也就找到了他的所有tree,blob对象。也就是得到了这个提交对应的所有文件。
那么这些对象在哪呢?当然是在 .git/objects里了。这个在前面已经说了无数遍了。
git clone 命令会把远程版本库的git对象下载下来到 .git/objects目录里,把分支引用保存到.git/packed-refs文件中。得到了引用和git对象,就得到了整个版本库了。
如果这个手册是从头到尾学习的,那么到现在为止理解这个概念应该非常容易了。
现在我们关注下 .git/refs目录
$tree .git/refs/.git/refs/├── heads│ ├── develop│ └── master├── remotes│ └── origin│ ├── HEAD└── tags
我们知道本地的分支文件在 .git/refs/heads目录下。从这个目录结构看,聪明的我们一定会想到,远程的分支文件应该在 .git/refs/heads/remotes/origin下才对。
本地的分支文件在 .git/refs/heads目录下,引用指向 .git/refs/objects目录里的git对象,远程的分支在 .git/refs/heads/remotes/origin下,引用也指向 .git/refs/objects目录里的git对象的话,这样就特别好理解了。可惜,目前看 .git/refs/heads/remotes/origin里面并没有master 和 develop两个分支文件。而是把分支引用保存在 .git/packed-refs文件里。
其实这只是暂时的,当远程版本库有新提交,并且本地版本库执行了git pull或 git fetch命令后,.git/refs/heads/remotes/origin目录下会生成对应的分支文件。
其实在git2.0之前,git clone之后就会有这2个分支文件,而不是 .git/packed-refs。为什么git2.0之后是这样的设计,我也不是很清楚,表示不理解。
好,我们现在知道了git clone的原理了。那我们就基于origin/develop来建一个本地develop分支
$git checkout -b develop origin/develop
我们来理解下这个命令。
我们知道 git checkout -b 命令可以建立并切换到一个分支。所以 git checkout -b develop origin/develop 就是建立develop分支并指向 origin/develop 的提交号。
origin/develop 就是远程develop分支,他的提交号保存在 .git/packed-refs文件里。
也可以通过 git rev-parse 命令查看 $git rev-parse origin/develop472f2eaf555b622c4996d7cd17e2337c0c7fc448
其实就是想说明,git clone 把远程版本库的git对象和分支引用下载到本地后,一切的操作和本地的任何操作是一样的。
唯一区别是,分支文件的目录不同罢了
本地分支文件保存在 .git/refs/heads 目录
远程分支文件保存在 .git/refs/heads/origin目录这下,明白了吗
让我们在看下现在 .git/config 文件的内容$cat .git/config...[remote "origin"]url = [email protected]:christian-tl/git-demo.gitfetch = +refs/heads/*:refs/remotes/origin/*[branch "master"]remote = originmerge = refs/heads/master[branch "develop"] #多了一个新的[branch]节点remote = originmerge = refs/heads/develop
git checkout -b develop origin/develop 命令会自动为新建的分支设置一个上游(upstream)对应分支.好了,现在我们本地有两个分支master和develop分别对应着远程的master,develop分支。实际工作中就是这么做的,保持同样的名字是为了规范便于记忆,方便管理。
但是本地分支和远程分支的映射的名字并没有任何限制。做个简单实验说明一下
$git checkout -b abc123 origin/developBranch abc123 set up to track remote branch develop from origin.Switched to a new branch 'abc123'$cat .git/config...[remote "origin"]url = [email protected]:christian-tl/git-demo.gitfetch = +refs/heads/*:refs/remotes/origin/*[branch "master"]remote = originmerge = refs/heads/master[branch "develop"]remote = originmerge = refs/heads/develop[branch "abc123"] #多了一个新的映射remote = originmerge = refs/heads/develop
好了,到这里聪明的你已经不需要我在过多解释了。
git clone之后本地就会有一个名为 origin的上游,上游的分支信息保存在 .git/refs/remotes/origin 目录下 。
其实git版本库可以有N个上游版本库,这完全取决于实际的需要。
git remote add 上游名 URL 命令可以添加上游版本库。现在我们就用这个命令再添加一个上游版本库,随便起个名字比如叫 upstream2
$git remote add upstream2 http://git.dangdang.com/tianle/git-demo2.git$cat .git/config...[remote "origin"]url = [email protected]:christian-tl/git-demo.gitfetch = +refs/heads/*:refs/remotes/origin/*#多了一个[remote]节点,名为upstream2[remote "upstream2"]url = http://git.dangdang.com/tianle/git-demo2.gitfetch = +refs/heads/*:refs/remotes/upstream2/*
我们还可以修改、重命名和删除一个上游版本库
$git remote set-url upstream2 [email protected]:christian-tl/git-demo.git #修改upstream2上游版本库的URL$git remote rename upstream2 upstream1 #把upstream2重命名成upstream1$cat .git/config...[remote "origin"]url = [email protected]:christian-tl/git-demo.gitfetch = +refs/heads/*:refs/remotes/origin/*...[remote "upstream1"] #名字变为了upstream1,之前是upstream2url = [email protected]:christian-tl/git-demo.git #URL变成了git-demo.git , 之前是git-demo2.gitfetch = +refs/heads/*:refs/remotes/upstream1/*$git remote rm upstream1 #删除上游版本库upstream1,.git/config文件的[remote "upstream1"]节点会被删掉
总结一下,git remote 的相关命令就是修改 .git/config文件而已,其实我们也可以手动编辑完成。
git fetch 命令可以把上游版本库的更新下载到本地版本库,这个更新包括Git对象和分支引用。
当上游版本库有新的提交后,上游版本库相关的分支文件会被更新,objects目录里会多了最新提交所对应的commit , tree,和blob对象。git fetch命令就是负责把这些更新下载到本地版本库。
现在我们通过一个实验来直观的看一下git fetch干了什么,并且这个实验可以把前面的一些命令串起来。
实验步骤:
- 克隆一份新版本库demo-for-fetch,demo-for-fetch向develop分支推送一个新的提交
- 在本地老的版本库里git fetch
#克隆一份新版本库demo-for-fetch,demo-for-fetch向develop分支推送一个新的提交$git clone [email protected]:christian-tl/git-demo.git demo-for-fetch$cd demo-for-fetch$git checkout -b develop origin/develop$echo '*.jar' >> .gitignore ; echo '*.war' >> .gitignore ; echo '*.ear' >> .gitignore; echo '*/target/*' >> .gitignore$git add .$git commit -m 'add .gitignore file'$git push origin develop$cat .git/refs/heads/developd83003a2e746416d37101acd6d8fbb8557aab63e #develop分支的提交号是d83003a$cd git-demo$git fetchremote: Counting objects: 3, done. #下载了3个对象文件remote: Compressing objects: 100% (2/2), done.remote: Total 3 (delta 0), reused 0 (delta 0)Unpacking objects: 100% (3/3), done.From http://git.dangdang.com/tianle/git-demo472f2ea..d83003a develop -> origin/develop #更新分支文件 注意提交号 d83003a$tree .git/refs/remotes/origin/.git/refs/remotes/origin/├── HEAD└── develop #fetch后 在 refs/remotes/origin生成了一个分支文件$cat .git/refs/remotes/origin/developd83003a2e746416d37101acd6d8fbb8557aab63e #origin/develop分支的提交号是d83003a
在我们的例子中远程版本库master并没有新的提交,所以fetch后本地refs/remotes/origin目录并没有生成一个master分支文件。有兴趣的话可以查看下 .git/objects目录,看看不是不多了3个文件。
篇幅所限,不在这里罗列了。
git pull 命令等价于 git fetch + git merge
git pull 命令先把远程版本库的更新下载到本地,然后和本地的分支合并 。
$git pull origin develop
#上面这条命令和用下面的两条命令的做的事情一样
$git fetch
$git merge origin/develop所以 git pull命令是分成了来给你个阶段完成的。阶段一从远程下载更新,需要网络。阶段二完全是正常分支间的合并操作,都是本地完成,不需要网络。
git pull命令是工作中最重要,最常用的命令之一,但是真的没什么需要过多描述的,因为他是两个命令的组合,fetch命令详细介绍完了,merge命令会在后面详细介绍
git push 命令会把本地版本库的git对象上传到远程版本库,并用本地分支引用更新远程版本库对应分支的引用。
当然不是把本地的所有对象都上传,而只是新提交所对应的那些git对象。
在push之前,必需要获得远程版本库的最新提交信息,而这个提交必需是我们本地提交的父提交,这就是前面提到的 快进式(Fast-forward),否则不能push成功。
在push操作时,必需要指定一个远程的分支,也就是要把提交推送到一个明确的分支。 所以在push之前,我们要先取得这个远程分支的提交并作为我们本地提交的祖先提交。
在这个祖先提交之后所有提交就是最新提交。push就是把这些提交对应的git对象上传到远程版本库。
所以,在push之前,一定要先pull 。git pull会取得最新提交并和当前分支merge,merge之后最新提交就是本地提交的祖先提交了。
在为本地分支建立了一个上游分支之后可以通过git status查看本地分支领先了远程分支几个commit
$git commit --allow-empty -m 'c2'$git statusOn branch developYour branch is ahead of 'origin/develop' by 1 commit. #仔细看这一行提示,现在origin/develop分支之后有了1次commit(use "git push" to publish your local commits)nothing to commit, working tree clean$git commit --allow-empty -m 'c3'$git statusOn branch developYour branch is ahead of 'origin/develop' by 2 commits. #仔细看这一行提示,现在origin/develop分支之后有了2次commit(use "git push" to publish your local commits)nothing to commit, working tree clean
现在我们执行 git push origin develop会成功吗?答案是 不一定。
由于我们的本地develop分支是基于origin/develop分支创建的,所以这之后的提交的祖先提交就是origin/develop分支所对应的提交。
如果在这个时间段内,远程版本库没有新的提交,那么就符合快进式提交条件,可以push成功。如果这个时间段内远程有新的提交,就不能push成功。
所以 , 在每次push前 一定要先pull一下,同步一下远程版本库的最新信息。
#因为目前除了我没有人会更新git-demo,所以我们的push当然时成功的啦$git push origin developCounting objects: 2, done.Delta compression using up to 4 threads.Compressing objects: 100% (2/2), done.Writing objects: 100% (2/2), 256 bytes | 0 bytes/s, done.Total 2 (delta 1), reused 0 (delta 0)remote:remote: Create merge request for develop:remote: http://git.dangdang.com/tianle/git-demo/merge_requests/new?merge_request%5Bsource_branch%5D=developremote:To [email protected]:christian-tl/git-demo.gitd83003a..05d68dd develop -> develop
push不光可以推送到远程已经存在的分支,也可以推送到不存在的分支,当推送到不存在分支时,就创建了这个远程分支。
push到已经存在的分支时需要受到快进式(Fast-forward)的限制,但是push到不存在的分支时一定是成功的。
$git checkout develop$git push origin develop:feature* [new branch] develop -> feature #这样就在远程版本库创建了一个feature新分支
所以 push命令的比较完整的写法是 git push 上游版本库 本地分支:远程分支 ,当本地分支于远程分支同名时只需 git push 上游版本库 本地分支
$git push origin :feature # git push 上游版本库 :远程分支 可以删除远程分支To [email protected]:christian-tl/git-demo.git- [deleted] feature
常见问题简答
如何创建Git版本库?
git init 或 git clone
如何为当前本地版本库添加远程版本库?
git remote add origin URL
git checkout 和 git reset的区别 ?
checkout修改HEAD文件的内容,reset修改refs/heads下面分支文件的内容。同时他们都可以替换工作区和暂存区的文件。
git merge 和 git rebase的区别?
都可以合并分支,但是一般建议用merge。因为rebase会改变已经生成的提交号,如果这个分支是大家协作的分支,那么你改了提交号之后会带来整个分支的混乱。
SHA值是怎么生成的?
通过SHA1消息摘要算法,可以使用系统命令 sha1sum
如何产生公钥?
ssh-keygen -t rsa -C"[email protected]"
cat~/.ssh/id_rsa.pub
如何产生commit-ID ?
(printf "commit %s\0" $(git --no-replace-objects cat-file commit HEAD | wc -c); git cat-file commit HEAD) | sha1sum
结束语
学习git首先要了解原理, 然后就是多动手。
可以git clone [email protected]:christian-tl/git-demo.git
这个手册里的和git-demo相关的例子都已经push了。特别是学习git对象时,手册里图片里的那些对象ID都能和objects目录里的对象对应起来
重点:学习资料学习当然离不开资料,这里当然也给你们准备了600G的学习资料
需要的先关注再私我关键字【000】免费获取哦 注意关键字是:000
疑惑:为什么要先关注呢? 回:因为没关注的话私信回了你看不到
项目实战
app项目,银行项目,医药项目,电商,金融

大型电商项目

全套软件测试自动化测试教学视频
300G教程资料下载【视频教程+PPT+项目源码】
全套软件测试自动化测试大厂面经
python自动化测试++全套模板+性能测试

听说关注我并三连的铁汁都已经升职加薪暴富了哦!!!!