本文首发于微信公众号“Shopee技术团队” 。
作者:Hao、Qianguang,来自 Shopee Digital Purchase 团队。
1. 背景
随着项目不断深入迭代,业务逻辑以及用户场景日渐复杂,补充和维护单元测试维护的成本也变得越来越高。测试覆盖质量通过测试用例评审或者人工 Code Review 的方式费时费力,单凭多方沟通和经验累积的方法,往往不够准确,也难以避免开发人员存在在代码上线前“夹带私货”的场景,并且没有量化的、直观的客观数据来支撑。
为了在有限的时间及人力成本内保证项目质量,实现对项目质量的精细化管理,我们研发了 Finder —— 全栈代码测试覆盖率及用例发现系统(下文简称 Finder),通过精确化的数据量化代码质量,从而实现精准化测试。本文将介绍 Finder 的总体架构,以及它作为质量保障体系中的重要一环,如何在项目中实现精确化测试。
2. Finder 项目介绍
Finder 主要分为两个模块,一个是测试过程中对代码测试覆盖率进行收集与统计,一个是分析代码和用例的映射关系,精准确定回归测试范围。
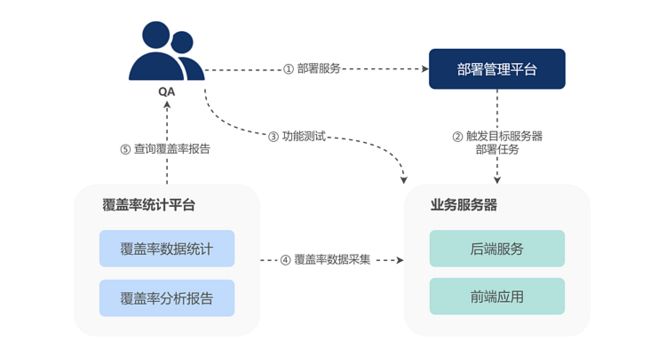
代码测试覆盖率统计模块,能够满足多环境、多需求、多服务的复杂测试场景,实时收集测试过程中的覆盖率信息,并生成覆盖率统计报告;其支持多端语言接入(Web、React Native、Golang),实现前后端项目全覆盖,打通整体研发流程。

相关用例发现模块,针对变动的代码分析函数调用关系,追溯完整的调用关系链路,标记出所影响的 API 接口及相关用例,确定测试回归范围。
3. 架构设计

Finder 分为代理层、应用层、核心服务层三个模块:
- 代理层 Finder Agent,负责前期数据采集的工作,包括编译阶段的代码插桩、覆盖率数据的采集、解析源码函数调用关系信息等;
- 应用层 Finder Platform,包含需求信息管理、分支信息管理、单文件覆盖率染色图展示、API 信息展示、测试用例关联、函数调用链展示等页面模块;
核心服务层 Finder Server,其中,覆盖率分析和服务调用分析是最主要的两个模块:
- 覆盖率分析,对收集到的覆盖率数据进行数据聚合、差异增量分析、数据修正等操作;
- 服务调用分析,将源码解析工具传输来的数据进行数据结构转换后,完成调用拓扑图生成、API 信息关联、测试用例发现等操作。
在前期完成数据采集的接入工作后,测试人员无需额外操作,正常进行业务测试,测试完成后可以在可视化平台中查看覆盖率数据、相关测试用例等信息。
4. 实现方案
4.1 代码测试覆盖率模块

代码覆盖率模块主要分为两个步骤,第一步是通过对项目源码插桩,采集覆盖率信息;第二步是对覆盖率信息进行分析,通过可视化平台展示统计报告。
步骤一:插桩与数据采集
代码插桩,意为在程序中插入一些代码,用于跟踪被测程序的某些信息。对于覆盖率测试而言,插桩的目的是检测程序中可执行语句被执行(即被覆盖)的情况。
Finder 支持 JS 和 Golang 两种程序语言的代码覆盖率统计,接入成本低,对业务需求无侵入性。
- 对于 JS 程序,我们在 babel 编译阶段进行插桩操作,注入到全局对象 window 中。我们提供了上报覆盖率数据的 npm 包 —— coverage-report,前端应用接入后会主动上报数据到 Finder Server;
- Golang 程序的覆盖率接入对业务项目零侵入,只需要引入 Finder Agent —— 覆盖率收集工具:它在编译阶段对源码插桩,包括 Git 信息和覆盖率信息注入;插桩完成后的服务会启动一个统计覆盖率的 Http Server,Finder Server 通过该 Http Server 提供的接口定时请求覆盖率数据。
步骤二:差异覆盖率统计
比起全量代码的覆盖率,实际上我们更关心改动代码部分的覆盖率情况。可以通过 Git 指令对比功能分支与 master 分支的代码差异,过滤无关代码,只针对改动代码部分进行覆盖率统计。
为实现差异覆盖率的计算,我们约定以行(line)作为维度的结构表示 Git 代码差异和覆盖率信息,满足两者一一对应的关系。

首先将 Git 分支对比得到的 Diff 数据转换成以代码行作为索引的数组格式,元素的值有空值和 + 两种枚举值:
- 空值代表没有改动;
- + 代表有改动。
覆盖率数组也转换成以代码行作为索引的数组格式,元素的值有 -1、0、1 三种枚举值:
- -1 代表无需统计覆盖率的代码(例如空格,注释等);
- 0 代表未覆盖的代码(尚未执行);
- 1 代表已覆盖的代码(已被执行)。
将 Diff 数据与覆盖率数组进行合并,将非改动代码的覆盖率值置为 -1 。得到最终的差异覆盖率数据。

关键问题一:数据源标准化
由于不同程序语言上报的覆盖率数据结构都不一致,我们需要将数据源标准化,统一转化以行(line)为维度的数组结构。
首先,前端应用上报的覆盖率数据包含三种维度的覆盖率数据:
- Statement Coverage:语句维度的覆盖率数据;
- Branch Coverage:条件维度的覆盖率数据,例如 if/else、switch、三元运算符等;
- Function Coverage:函数维度的覆盖率数据。
对于这三类覆盖率,我们做出以下数据转换:

我们采用与操作将三类覆盖率数据合并为行覆盖率,即一行代码满足三类覆盖率才算被执行过。
而后端 Golang 服务采集的覆盖率数据,如下图。

同样,我们也需要将其转换为行维度的数组结构。

关键问题二:确保代码变更后的覆盖率正确性
在集成测试的过程中,开发人员不可避免地会进行代码更新。当代码更新后,我们希望能够记录新代码改动覆盖率的同时,依然保持原有代码的覆盖率数据。所以我们需要获取新旧提交之间的代码差异,对原有覆盖率数据进行“修正”操作:
对原有的覆盖率数据,先删除 diff 结果中被移除的代码对应的覆盖率数据,再插入 diff 结果中新增的代码对应的覆盖率数据。
举个例子:

对比首次提交 commit 1 和 master 分支,得到首次改动:新增三行代码。
标记这三行代码的行索引 3、4、8,并统计它们的覆盖率。

对比 commit 1 和 commit 2,得到两次提交之间的改动:删除之前两行代码,新增一行代码。
移除原数据中第 3、4 行数据,然后插入新改动代码的行索引 7(删除后的索引位置)并统计新改动的覆盖率。

修正后的结果和 commit 2 与 master 分支对比的结果一致,既保留了首次改动的覆盖率数据,也记录了新改动的覆盖率数据。
关键问题三:单环境的代码覆盖率采集
在实际开发流程中,研发环境只有一套,我们往往不能独占它,所有周版本需求都在 staging 环境开发,在 test 环境测试。这样会出现一个问题:由于这种单一环境的测试流程,导致统计出来的覆盖率无法区分来自哪个具体功能分支,进而影响对各功能需求的测试范围判断。
为了解决这个问题,我们提出两个方案:
第一个方案是搭建多泳道研发环境,通过 PFB(Per Feature Branch)的形式对各需求开发环境进行隔离。PFB 是一个可以快速搭建虚拟环境的工具。它支持将多个功能分支版本同时部署在同一个测试环境中,且每个功能分支可拥有单独的流量访问,从而实现不同的功能分支可拥有相对隔离的虚拟环境。
但是由于这个架构改动较大,距离落地到项目中还需一段时间,因此第二个方案应运而生:我们对单一的集成分支进行功能追溯,判别出变动代码是属于合并进来的哪一个功能分支,并进行分类展示。

- 通过 Git Blame 命令从集成分支中判别出到各行代码对应的 commit hash;
- 通过 Git Branch 命令查找 commit hash 来自哪一个功能分支。
通过以上两步寻找到每行代码与功能分支的对应关系,与覆盖率结果进行映射后可得出对单一集成分支的功能追溯效果,解决单环境的代码覆盖率采集问题。
4.2 相关用例发现模块
相关用例发现模块的关键是通过追溯变动代码的调用关系链,确定测试回归范围。这个过程主要分为两个阶段:源码解析阶段和数据分析阶段。
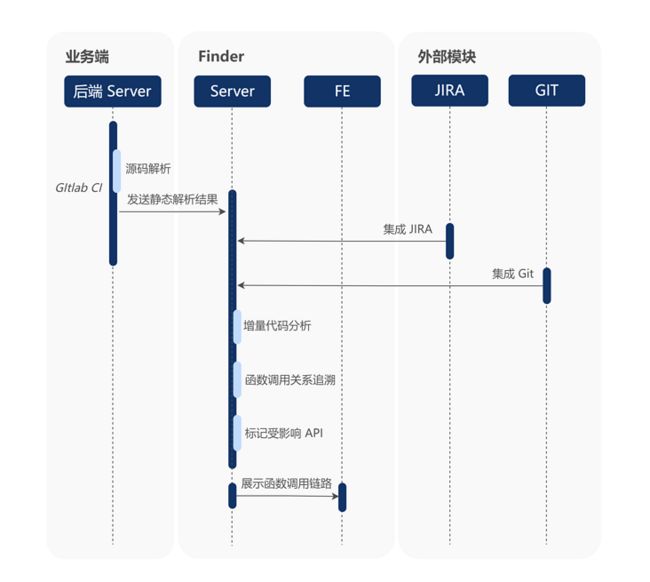
步骤一:源码解析
我们在 Gitlab CI 接入源码解析工具,当有新代码提交时,触发源码解析。
通过对抽象语法树 AST 和中间转换代码 SSA 进行解析,得到以下数据:
- 项目 Git 信息
- 函数基本信息
- 函数调用关系
- RPC 调用信息
- API 信息
最后将这些数据都打包统一发送到 Finder 服务端。
步骤二:数据分析
Finder 服务端接收到解析数据后,进行差异增量代码的函数调用关系全链路追溯,最后标记出相关的 API 信息及测试用例。具体追溯流程如下:

- Git Diff 得到功能分支与 Master 分支对比的代码改动;
- 通过差异增量代码的所在行数,确定所属函数体,进入步骤 3;
- 追溯指定函数的调用关系,直到寻找到 API 触发函数;
- 若遇到 RPC 调用的情况,进行 RPC 调用关系追溯,找到 RPC 调用方函数,继续回到步骤 3 的操作;
- 追溯工作完成,得到从变动函数到 API 触发函数的调用关系全链路;
- 通过以上得到的 API 触发函数,标记相关的 API 信息及测试用例。
每次代码变更都会触发上述流程,得到最新的函数调用链路信息,在可视化前台中展示该功能分支的变动函数调用关系链,以及相关测试用例。
关键问题:后端微服务架构串联,全链路覆盖
目前我们后端服务采用了分布式的微服务架构,例如一个购买商品的流程,当用户进入 APP 浏览商品时,会发起请求经过网关层,转发到商品服务,然后在创建订单时会调起订单服务,订单服务再调用用户信息服务和促销服务,整个过程还会调用多个基础服务共同完成一次操作流程。
我们希望除了解析服务内的调用关系外,也需要服务间的调用关系串联起来,得到完整的调用链路。

为了解决这个问题,我们针对项目中的 RPC 调用关系进行静态解析,通过寻找调用方函数——RPC Command——被调用方函数三者的关联关系,对调用方函数和被调用方函数进行标记,当函数调用关系链追溯到被调用方函数时,匹配到其对应的调用方函数,继续向上追溯,从而得到服务间的完整调用关系链路。
5. 实践应用
Finder 通过接入团队中的项目流程管理系统,在整个需求生命周期的各个环节发挥着不同的作用。

5.1 提测阶段
5.1.1 覆盖率提测达标
开发人员必须达到规定的覆盖率标准才能提测,对于覆盖率未达标的情况,开发人员需要反推代码逻辑是否存在问题,进一步分析前期技术方案设计不够合理,还是对技术方案的实现有误,或者是在实现过程中造成的策略性放弃等。
5.1.2 覆盖率定制化
针对不同项目会有定制化的覆盖率要求,支持配置需要忽略统计覆盖率的文件类型以及目录。
对于移动端应用,提供 iOS 和 Android 双平台的覆盖率数据统计,这样能够提前暴露移动端的兼容性问题,保证提测交付质量。

5.2 测试阶段
5.2.1 覆盖率实时分析
测试人员介入测试后可以在 Finder 平台上实时查看覆盖率分析结果,了解该测试版本变更代码的测试覆盖情况。

5.2.2 覆盖率染色图
通过代码覆盖率染色图辅助整个测试过程,方便测试人员对测试用例进行查漏补缺,尽可能保证所有关键场景都能覆盖到;同时可以驱动测试人员加强对代码的理解,充分把控代码质量。

5.2.3 需求维度覆盖率统计
通过关联项目管理系统,从需求级别的角度,提供该需求下各模块的覆盖率数据,包括不同的后端服务和前端应用,辅助测试人员做决策,衡量质量风险。

5.3 回归阶段
标记变更范围
根据代码变更范围推断出函数变更范围,进一步标记出相关测试用例,从而实现用例和代码的关联关系。
用例发现分析报告中会标记出该需求变更部分的相关信息,包括变更的函数调用关系链路和受影响的 API 接口,测试人员从中可以快速确定回归测试范围,通过更小的维度更精准地度量测试质量,针对性进行自动化/手工测试,极大减少回归阶段的工作量,以较小的回归成本保证较高的测试质量。


6. 未来展望
Finder 作为项目中质量保障体系中的一环,目前还处于初级阶段。在未来我们会持续寻找 Finder 在研测协同体系中的更优实践。
1)支持更多维度的覆盖率数据统计
我们希望在统计方面可以提供更产品化更精细化的数据,包括关键字覆盖率、相关代码覆盖率、高风险覆盖率等,能够更好地辅助测试人员做决策。
2)精准记录 Bug 轨迹
后续我们打算支持通过以添加标记的形式单独统计覆盖率,通过记录 bug 的完整代码轨迹,还原问题的复现路径,精确定位问题所在。
3)建立用例知识库
构建用例与代码映射关系,形成用例知识库,支持对代码和用例进行关联管理,精确推荐改动代码关联的用例,提供测试用例优化建议。