Ubuntu 20.04安装CUDA & CUDNN 手把手带你撸
新手先看这
之前一直使用CPU做训练,最近手上多了台单卡1080Ti显卡主机,于是开始研究GPU训练。用GPU训练一定会使用CUDA了,刚开始接触CUDA非常非常头痛,对小白很不友好,我几乎整了整整一天,中途想放弃过很多次,最后终于弄好了,回头看看其实不是很难,但是网上文章又多又杂,确实让我来回鼓捣了很久,于是写下这篇文章,希望对新入门GPU机去学习,想安装CUDA的朋友们一点帮助,少走弯路,不要像我一样浪费好多时间。
新手最难理解的就是CUDA和cuDNN是啥了,以及安装过程,步骤。 这里先简单说一下,先检查机器/usr/local目录下有没有cuda或cuda-xx.xx文件夹,如果没有,那99.99%说明该机器没有安装CUDA。不要相信nvidia-smi或nvcc --version指令看到的CUDA版本号,那都没意义。
如果说CUDA是GPU深度学习的运行库,那么cuDNN就是训练加速工具,两者要相互配合使用,所以一般机器学习需要训练引擎(tensorflow-gpu) + CUDA + cuDNN使用。想不安装cuDNN是不可以的,而且cuDNN版本要和CUDA版本相互搭配。具体搭配方式见下面博文。
检查是否安装显卡驱动
查看是否安装NVIDIA显卡
lspci | grep -i nvidia查看显卡信息
nvidia-smi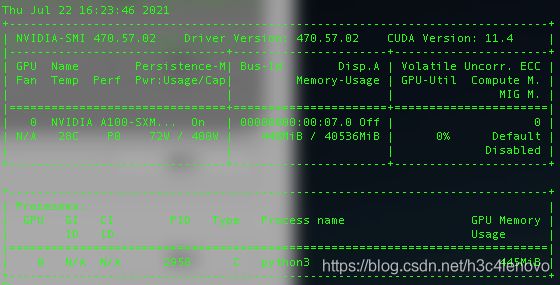
如果出现这个样式,说明已经安装显卡驱动了。通常装好的Ubuntu中都有显卡驱动。我是在阿里云上租借GPU云主机A100时候遇到了没有显卡驱动。如果没有驱动,那么就需要手动安装显卡驱动了。
先添加源:
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update检查可安装的驱动:
ubuntu-drivers devices找到最适合的驱动安装,安装recommended标记的,通常也是数字版本最大的那个。
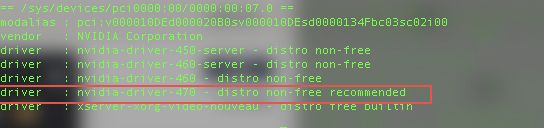
sudo apt install nvidia-driver-XXX也可以自动安装系统推荐那个
sudo ubuntu-drivers autoinstall如果没有遇到报错,说明安装成功,此时调用nvidia-smi指令可能还是看不到显卡信息,不要担心,重启系统之后就能看到了。
安装CUDA
我第一次接触CUDA的时候,以为nvidia-smi指令看到的那个CUDA Version有值就是安装了CUDA的意思。但是后来才知道这里的CUDA是说此显卡最大支持的CUDA版本号。因此我们仍然需要手动从官网下载CUDA,且版本号不能高于这个。安装CUDA就不细说了,除了刚刚提到的细节外,几乎坑不多,这里把有坑的地方简单介绍一下。
首先Ubuntu 20.04默认g++9版本太高,会导致CUDA无法安装,因此要先降低g++版本。
sudo apt-get install gcc-7 g++-7
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 9
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 1
sudo update-alternatives --display gcc
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 9
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-9 1
sudo update-alternatives --display g++然后从官网下载对应的CUDA,这里对新人最不友好的就是什么是“对应的CUDA”???除了我刚刚提到的GPU支持最大CUDA版本外,还需要考虑Tensorflow对应的CUDA版本,从这里可以查到:
https://www.tensorflow.org/install/source_windows
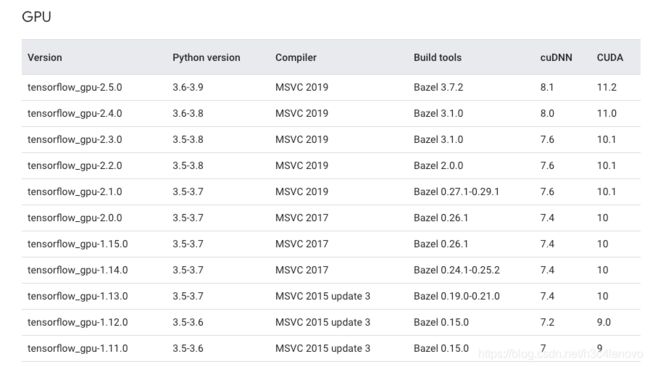
例如阿里云GPU主机常用的就是CUDA11 + cuDNN8,那么就要搭配tf-gpu 2.4.0版本使用。如果你不清楚你对应的CUDA是啥,我推荐你使用CUDA10.1 + cuDNN7.6 + tensorflow-gpu 2.2.0这个组合。
知道要安装的CUDA版本后,就很简单了,去NVIDIA官网直接下载对应版本就好了。
https://developer.nvidia.com/cuda-toolkit-archive
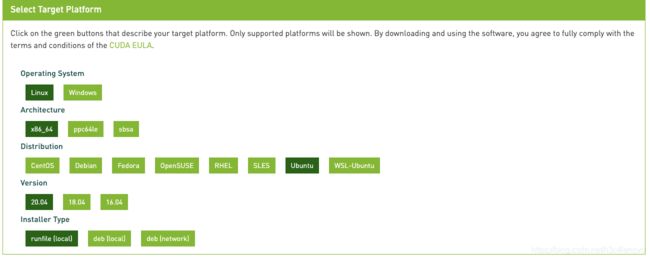
有20.04的就用20.04的,没有就选最大的,一般是18.04。推荐用runfile安装,两句话很简单:
wget https://developer.download.nvidia.com/compute/cuda/11.1.1/local_installers/cuda_11.1.1_455.32.00_linux.run
sudo sh cuda_11.1.1_455.32.00_linux.run第一句话是下载cuda_xxxx_linux.run脚本,第二句是执行脚本。在弹出的安装界面中选“continue”,如果选了会跳出安装,就说明安装失败,给了失败日志的路径,自己查看原因,一般是gcc版本问题,上面提到过降级方法,不赘述。

在这一步输入accept

然后选择安装项,一般情况我们都安装了显卡驱动,所以这里第一项驱动最好不勾选,其他默认安装。
成功后需要配置一下环境变量,这步很关键。一开始我忽略了这步,一直以为CUDA安装好了,但是TF运行的时候怎么都找不到GPU。
sudo vim ~/.bashrc最后一行增加
$ export PATH=/usr/local/cuda-10.1/bin${PATH:+:${PATH}}
$ export LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}特别注意文件夹路径,有时候文件夹直接是/usr/local/cuda,有时候是别的版本号,要确保文件夹存在。
source ~/.bashrc最后更新环境变量。
检查一下CUDA是否安装正确:(注意文件夹路径一定要存在,需要跟上面设置环境变量的路径保持一致)
cat /usr/local/cuda/version.txt这里特别注意:
一开始的时候,我对CUDA不是很了解,执行这句话没有任何反应,我以为是该方法失效了。我使用nvidia-smi或nvcc --version指令都看到了CUDA版本号。但是CUDA环境没有配置好,这两个也是能拿到版本号的,所以不准确。还是应该用上面的方法检查CUDA版本。
安装cuDNN
cuDNN比CUDA安装简单,下载对应版本压缩包,拷贝文件到指定目录,给予权限就好了。
官网下载地址:(需要注册)
https://developer.nvidia.com/cudnn
特别注意拷贝的路径一定是上面指定的环境变量路径!
sudo cp cuda/include/cudnn.h /usr/local/cuda-10.1/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-10.1/lib64
sudo chmod a+r /usr/local/cuda-10.1/include/cudnn.h
sudo chmod a+r /usr/local/cuda-10.1/lib64/libcudnn*查看cuDNN版本方法:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2注意,这句话可能执行了没效果,那是因为新版本换位置了,需要用:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2这里再次注意路径问题。
至此CUDN + cuDNN安装完成,可以执行相关训练文件查看是否有gpu信息输出,或监控一下gpu状态
watch -n 1 nvidia-smi如果还是使用的CPU训练,就需要按照上面的步骤检查到底哪里出了问题。
怎么样,撸的开心吗?