【爬虫|数据分析|Hadoop】利用scrapy框架爬取小说信息并进行数据分析
文章目录
- 爬虫部分
-
- 1. 创建项目
- 2. 修改配置文件
- 3. 编写items.py
- 4. 编写爬虫脚本
- 5. 编写pipeline.py
- 6.运行项目
- 数据分析部分
-
- 1. 导包
- 2. 数据预处理
-
- 2.1 读取文件
- 2.2 查看前5行
- 3. 数据清洗
-
- 3.1 地区数据处理
- 3.2 评分数据处理
- 3.3 年份数据处理
- 3.4 出版社数据处理
- 3.5 评论人数处理
- 3.6 小说简介处理
- 4. 数据分析
-
- 4.1 设置画布
- 4.2 数据分析
-
- 4.2.1 不同国家书本数分析
- 4.2.2 评分统计
- 4.2.3 小说数量随年份变化情况
- 4.2.4 出版社统计
- 4.2.5 评论人数统计
- 4.2.6 评论词云
- 4.3 保存数据
- Hadoop数据分析
-
- 1. 环境简介
- 2. WordCount
-
- 2.1 项目依赖 pom.xml
- 2.2 编写代码
-
- 2.2.1 编写WordCountDriver
- 2.2.2 编写WordCountMapper
- 2.2.3 编写WordCountReducer
- 2.3 本地运行
- 2.4 利用Hadoop集群运行
爬虫部分
1. 创建项目
scrapy startproject douban
执行完会自动生成项目文件夹及初始化文件
2. 修改配置文件
主要是为了反反爬虫,在settings.py文件中修改下面设置:
USER_AGENT = 'Mozilla/5.0(X11;Linux x86_64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/48.0.2564.116 Safari/537.36'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"
}
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
3. 编写items.py
定义爬取到的数据都有那些属性
import scrapy
class DoubanItem(scrapy.Item):
# 书名
book_name = scrapy.Field()
# 作者
author = scrapy.Field()
# 评分
grade = scrapy.Field()
# 评分人数
count = scrapy.Field()
# 简介
introduction = scrapy.Field()
# 出版社
press = scrapy.Field()
# 金额
price = scrapy.Field()
# 出版时间
publish_time = scrapy.Field()
4. 编写爬虫脚本
在 spiders 目录下随便新建一个py文件,此文件用于网页数据的爬取,内容如下:
# -*- coding:utf-8 -*-
# 时间 : 2022/6/5 21:09
# 作者 : 冷芝士鸭
import scrapy
from ..items import DoubanItem
class DoubanspiderSpider(scrapy.Spider):
name = 'doubanspider'
allowed_domains = ['douban.com']
def start_requests(self):
url = "https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4"
yield scrapy.Request(url, callback=self.parse, dont_filter=True)
def parse(self, response):
item = DoubanItem()
info_list = response.xpath("//div[@class='info']")
for info in info_list:
item['book_name'] = info.xpath("./h2/a/text()").extract_first().strip()
some_info = info.xpath("./div[@class='pub']/text()").extract_first().strip().split('/')
item['author'] = some_info[0]
if len(some_info) == 4:
# 正常,否则没有金额,最后一个是时间
if some_info[-2].__contains__("-"):
item['publish_time'] = some_info[-2]
item['press'] = some_info[-3]
item['price'] = some_info[-1]
else:
item['publish_time'] = some_info[-1]
item['press'] = some_info[-2]
item['grade'] = info.xpath("./div[2]/span[2]/text()").extract_first()
item['count'] = info.xpath("./div[2]/span[3]/text()").extract_first()
item['introduction'] = info.xpath("./p/text()").extract_first()
yield item
next_temp_url = response.xpath("//div[@id='subject_list']/div[@class='paginator']/span[@class='next']/a/@href").extract_first()
if next_temp_url:
next_url = response.urljoin(next_temp_url)
yield scrapy.Request(next_url)
5. 编写pipeline.py
此文件用于在生成items对象后进行操作。可以将item对象保存在数据库或者csv中,这里保存到了本地
# 导入CSV模块
import csv
class DoubanPipeline(object):
def __init__(self):
# 1. 创建文件对象(指定文件名,模式,编码方式)
with open("data.csv", "a", encoding="utf-8", newline="") as f:
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# 3. 构建列表头
# csv_writer.writerow(["book_name", "author", "press", "publish_time", "grade", "count", "price", "introduction"])
csv_writer.writerow(["book_name", "author", "press", "publish_time", "grade", "count", "price"])
def process_item(self, item, spider):
book_name = item.get("book_name", "N/A")
author = item.get("author", "N/A")
grade = item.get("grade", "N/A")
count = item.get("count", "N/A")
press = item.get("press", "N/A")
publish_time = item.get("publish_time", "N/A")
# introduction = item.get("introduction", "N/A")
price = item.get("price", "N/A")
# 1. 创建文件对象(指定文件名,模式,编码方式)
with open("data.csv", "a", encoding="utf-8", newline="") as f:
# 2. 基于文件对象构建 csv写入对象
csv_writer = csv.writer(f)
# 3. 构建列表头
# csv_writer.writerow(["book_name", "author", "press", "publish_time", "grade", "count", "price", "introduction"])
# 4. 写入csv文件内容
# csv_writer.writerow([book_name, author, press, publish_time, grade, count, price, introduction])
csv_writer.writerow([book_name, author, press, publish_time, grade, count, price])
# 5. 关闭文件
f.close()
6.运行项目
运行名称为doubanspider的爬虫脚本,将日志保存在log.txt文件中
scrapy crawl doubanspider --logfile log.txt
数据分析部分
1. 导包
import random
import jieba
import pandas as pd
from PIL import Image
from matplotlib import pyplot as plt
from pandas import *
from matplotlib.pyplot import *
2. 数据预处理
2.1 读取文件
from wordcloud import WordCloud
data = pd.read_csv("./data.csv")
2.2 查看前5行
print(data.head())
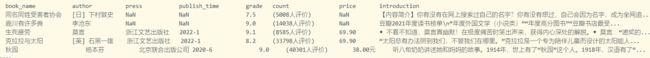
3. 数据清洗
3.1 地区数据处理
# 没有地区的默认为中国
def get_region(author):
if author.__contains__("["):
return author.split('[')[1].split(']')[0]
else:
return '中国'
data['region'] = data['author'].apply(get_region)
print(data['region'].head())
0 日
1 中国
2 中国
3 英
4 中国
Name: region, dtype: object
3.2 评分数据处理
# 没有评分的按照平均分填充
data=data[~(data['grade'].isnull())]
data['grade'].fillna(data['grade'].mean(), inplace=True)
3.3 年份数据处理
# 只保留年
def format_date(publish_time):
publish_time = publish_time.strip()
if len(publish_time) < 4 or len(publish_time) == 5:
return "未知"
# 按月统计有187个月,所以按年统计
if "元" in publish_time:
return "未知"
return publish_time.split('-')[0].strip()
data=data[~(data['publish_time'].isnull())] #删掉空行
data['publish_time'] = data['publish_time'].apply(format_date)
print(data["publish_time"].head())
2 2022
3 2022
4 2020
5 2012
6 2012
Name: publish_time, dtype: object
3.4 出版社数据处理
# 出版社包含数字或空的行删除
def format_press(press):
press = press.strip()
# 删除数字
if any(chr.isdigit() for chr in press):
return None
return press
data['press'] = data['press'].apply(format_press)
data=data[~(data['press'].isnull())] #删掉空行
3.5 评论人数处理
# 没有地区的默认为中国
def get_count(count):
if count.__contains__("("):
return count.split('(')[1].split('人')[0]
else:
return 0
print(len(data['count']))
data=data[~(data['count'].isnull())] #删掉空行
data['count'] = data['count'].apply(get_count)
print(len(data['count']))
print(data['count'].head())
874
874
2 8585
3 33798
4 40301
5 694348
6 47425
Name: count, dtype: object
3.6 小说简介处理
# 删除所有非中文内容
def remove_unChinese(content):
res = ""
content = str(content).replace("编辑推荐", "").replace("内容简介", "")
for i in content:
if u'\u4e00' <= i <= u'\u9fff':
res+=i
else:
res+=" "
return res
# 去除干扰信息
data['introduction'] = data['introduction'].apply(remove_unChinese)
# 转为一个字符串
text_content = ""
# 获取评论内容
for i in data['introduction']:
text_content+=str(i)
4. 数据分析
4.1 设置画布
# UserWarning: Glyph 24341 (\N{CJK UNIFIED IDEOGRAPH-5F15}) missing from current font.
plt.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei', 'FangSong'] # 汉字字体,优先使用楷体,如果找不到楷体,则使用黑体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
4.2 数据分析
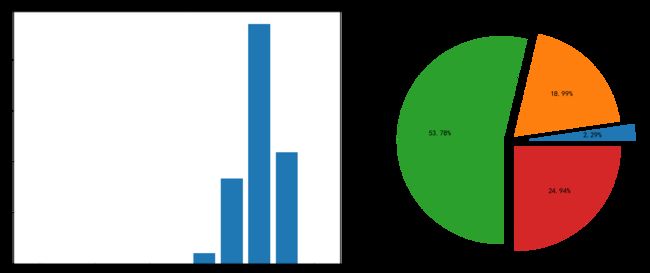
4.2.1 不同国家书本数分析
# 数量统计
region_count = {}
for i in data['region']:
if i in region_count:
region_count[i] += 1
else:
region_count[i] = 1
print(region_count)
print(len(region_count))
# 可视化
region = DataFrame()
# 截取前20个国家
region["num"] = list(region_count.values())[:20]
region["name"] = list(region_count.keys())[:20]
plt.subplots(1, 2,constrained_layout=True, figsize=(25, 10)) # 两行一列,位置是1的子图
plt.subplot(1, 2, 1) # 两行一列,位置是1的子图
plt.xticks(rotation=90)
plt.rcParams['font.size'] = 13 # 字体大小
plt.bar(region["name"],region["num"], label='数量')
plt.legend(loc='upper right')
plt.ylabel('数量/本')
plt.xlabel('国家')
plt.title('不同国家书本数量统计')
plt.subplot(1, 2, 2) # 两行一列,位置是1的子图
plt.rcParams['font.size'] = 15 # 字体大小
plt.pie(region["num"], labels=region["name"], autopct='%.2f%%')
# 标题
plt.title("小说评分统计")
plt.show()
{‘中国’: 353, ‘英’: 87, ‘日’: 139, ‘美’: 88, ‘马来西亚’: 2, ‘意’: 15, ‘哥伦比亚’: 5, ‘法’: 23, ‘萨尔瓦多’: 1, ‘德’: 16, ‘波’: 4, ‘加’: 5, ‘巴西’: 2, ‘阿根廷’: 9, ‘爱尔兰’: 7, ‘韩’: 3, ‘清’: 1, ‘意大利’: 2, ‘智利’: 5, ‘瑞典’: 8, ‘日本’: 4, ‘奥’: 3, ‘葡’: 3, ‘美国’: 9, ‘俄’: 23, ‘以色列’: 1, ‘英国’: 1, ‘瑞士’: 1, ‘安哥拉’: 1, ‘俄罗斯’: 2, ‘南非’: 1, ‘尼日利亚’: 1, ‘苏联’: 1, ‘波兰’: 6, ‘冰岛’: 1, ‘加拿大’: 6, ‘乌克兰’: 1, ‘明’: 3, ‘荷兰’: 1, ‘捷克’: 4, ‘匈’: 2, ‘土耳其’: 3, ‘丹’: 1, ‘澳’: 2, ‘匈牙利’: 1, ‘苏’: 1, ‘挪威’: 1, ‘西’: 3, ‘墨西哥’: 2, ‘乌拉圭’: 1, ‘奥地利’: 1, ‘古巴’: 1, ‘荷’: 1, ‘丹麦’: 1, ‘德国’: 2, ‘法国’: 1, ‘比’: 1, ‘秘鲁’: 1}
58

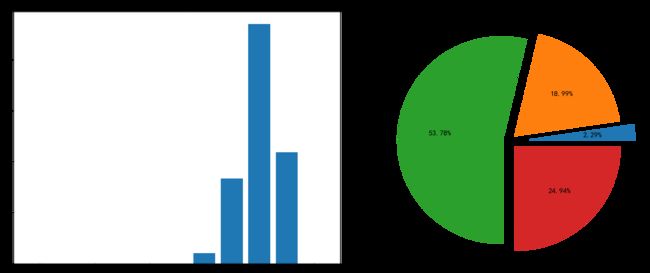
4.2.2 评分统计
# 统计每类评分占比
grade_count = []
for i in range(11):
grade_count.append(list(np.floor(data['grade'])).count(i))
print(grade_count)
# 可视化
plt.subplots(1, 2,constrained_layout=True, figsize=(25, 10)) # 两行一列,位置是1的子图
plt.subplot(1, 2, 1) # 两行一列,位置是1的子图
plt.rcParams['font.size'] = 20 # 字体大小
grade = DataFrame()
grade["rating"] = range(11)
grade["num"] = grade_count
plt.bar(grade["rating"], grade["num"])
plt.title("不同评分数量统计")
plt.subplot(1, 2, 2) # 两行一列,位置是1的子图
plt.rcParams['font.size'] = 20 # 字体大小
# 标签
label = [6, 7, 8, 9]
plt.pie(grade_count[6:10], labels=label, autopct='%.2f%%',explode=[0.2, 0.08, 0.08, 0.08])
# 标题
plt.title("不同评分所占比例统计")
plt.show()
[0, 0, 0, 0, 0, 0, 20, 166, 470, 218, 0]
4.2.3 小说数量随年份变化情况
# 按年份统计数量
time_count = {}
for i in data['publish_time']:
if i in time_count:
time_count[i.split("-")[0]] += 1
else:
time_count[i.split("-")[0]] = 1
print(time_count)
print(len(time_count))
# 对字典按键(key)进行排序(默认由小到大)
time_key_sort = sorted(time_count.keys())
# 输出结果
print(time_key_sort)
# [3, 6, 7, 8, 10]
time_count_sort = sorted(time_count.items(), key=lambda x: x[0])
# 输出结果
print(time_count_sort)
time_count_lsit = []
for i in time_count_sort:
time_count_lsit.append(i[1])
print(time_count_lsit)
{'2022': 154, '2020': 77, '2012': 26, '2005': 18, '2018': 65, '2021': 112, '2019': 60, '2008': 38, '2017': 73, '2010': 12, '2001': 3, '2016': 34, '2013': 36, '2014': 11, '1996': 1, '1991': 8, '2009': 21, '1973': 7, '2011': 4, '2002': 7, '1994': 6, '2004': 11, '1997': 9, '2015': 25, '2000': 14, '1999': 4, '1988': 7, '1998': 11, '2003': 3, '1981': 2, '未知': 8, '2006': 6, '2007': 1}
33
['1973', '1981', '1988', '1991', '1994', '1996', '1997', '1998', '1999', '2000', '2001', '2002', '2003', '2004', '2005', '2006', '2007', '2008', '2009', '2010', '2011', '2012', '2013', '2014', '2015', '2016', '2017', '2018', '2019', '2020', '2021', '2022', '未知']
[('1973', 7), ('1981', 2), ('1988', 7), ('1991', 8), ('1994', 6), ('1996', 1), ('1997', 9), ('1998', 11), ('1999', 4), ('2000', 14), ('2001', 3), ('2002', 7), ('2003', 3), ('2004', 11), ('2005', 18), ('2006', 6), ('2007', 1), ('2008', 38), ('2009', 21), ('2010', 12), ('2011', 4), ('2012', 26), ('2013', 36), ('2014', 11), ('2015', 25), ('2016', 34), ('2017', 73), ('2018', 65), ('2019', 60), ('2020', 77), ('2021', 112), ('2022', 154), ('未知', 8)]
[7, 2, 7, 8, 6, 1, 9, 11, 4, 14, 3, 7, 3, 11, 18, 6, 1, 38, 21, 12, 4, 26, 36, 11, 25, 34, 73, 65, 60, 77, 112, 154, 8]
year = DataFrame()
year["year"] = list(time_key_sort)
year["num"] = list(time_count_lsit)
plt.figure(dpi=200,figsize=(15,5))
plt.rcParams['font.size'] = 10 # 字体大小
plt.plot(year["year"], year["num"])
plt.title("小说年份统计")
plt.show()
4.2.4 出版社统计
# 数量统计
press_count = {}
for i in data['press']:
if i in press_count:
press_count[i] += 1
else:
press_count[i] = 1
# print(press_count)
# print(len(press_count))
# 可视化
press = DataFrame()
# 截取前20个国家
press["num"] = list(press_count.values())[:20]
press["name"] = list(press_count.keys())[:20]
plt.subplots(1, 2,constrained_layout=True, figsize=(25, 10)) # 两行一列,位置是1的子图
plt.subplot(1, 2, 1) # 两行一列,位置是1的子图
# 文字变斜
plt.xticks(rotation=90)
plt.rcParams['font.size'] = 12 # 字体大小
plt.bar(press["name"],press["num"], label='数量')
plt.legend(loc='upper right')
plt.ylabel('数量/本')
plt.xlabel('国家')
plt.title('不同国家书本数量统计')
plt.subplot(1, 2, 2) # 两行一列,位置是1的子图
plt.rcParams['font.size'] = 15 # 字体大小
plt.pie(press["num"], labels=press["name"], autopct='%.2f%%')
# 标题
plt.title("小说评分统计")
plt.show()

4.2.5 评论人数统计
import random
count_count = dict(zip(list(data['book_name']), list(int(i) for i in data['count'])))
# print(count_count)
# 对字典按键(key)进行排序(默认由小到大)
count_key_sort = sorted(count_count.keys())
# 输出结果
# print(count_key_sort)
count_count_sort = sorted(count_count.items(), key=lambda x: x[0])
# 输出结果
# print(count_count_sort)
count_count_lsit = []
for i in count_count_sort:
count_count_lsit.append(i[1])
# print(count_count_lsit)
# 随机选取20本数进行展示
idx = len(count_key_sort)-20
idx = random.randint(0,idx)
print(idx)
# print(list(count_key_sort)[idx: idx + 20])
# print(list(count_count_lsit)[idx: idx + 20])
# 可视化
plt.subplots(1, 2,constrained_layout=True, figsize=(25, 10)) # 两行一列,位置是1的子图
plt.subplot(1, 2, 1) # 两行一列,位置是1的子图
# 文字变斜
plt.xticks(rotation=90)
plt.rcParams['font.size'] = 12 # 字体大小
plt.bar(list(count_key_sort)[idx: idx + 20],list(count_count_lsit)[idx: idx + 20], label='评论数量')
plt.legend(loc='upper right')
plt.ylabel('数量/条')
plt.xlabel('书名')
plt.title('不同本的评论数量统计')
plt.subplot(1, 2, 2) # 两行一列,位置是1的子图
plt.rcParams['font.size'] = 15 # 字体大小
plt.pie(list(count_count_lsit)[idx: idx + 20], labels=list(count_key_sort)[idx: idx + 20], autopct='%.2f%%')
# 标题
plt.title("小说评分统计")
plt.show()
577
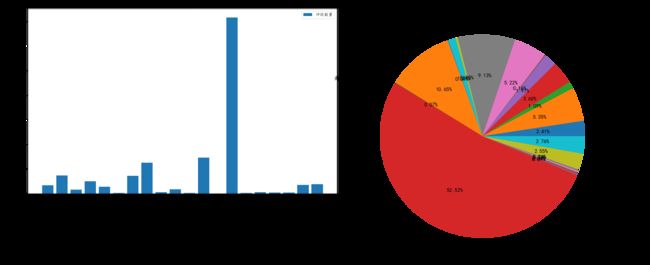
4.2.6 评论词云
wc = WordCloud(
background_color="#FFFFFF", #背景颜色
max_words=1000, #显示最大词数
font_path='simsun.ttc',
width=1000,
height=800,
mask=np.array(Image.open("cloud.png"))
)
plt.figure(dpi=200,figsize=(15,5))
split_content = " ".join(jieba.lcut(text_content))
img = wc.generate(split_content)
plt.imshow(img)
plt.xticks([]) # 去掉x轴
plt.yticks([]) # 去掉y轴
plt.axis('off') # 去掉坐标轴
plt.show()
Building prefix dict from the default dictionary …
Dumping model to file cache F:\temp\jieba.cache
Loading model cost 0.876 seconds.
Prefix dict has been built successfully.

4.3 保存数据
# 将处理过的数据写入本地文件
data.to_csv("result.csv",index=False)
# 将分词后的内容保存
with open("introduction.txt", "w", encoding="utf-8", newline="\n") as f:
for i in range(150):
f.write(split_content)
print("down!")
down!
4.4 数据统计
import time
content = ""
with open("introduction.txt", "r", encoding="utf-8") as f:
content = f.readline()
start = time.time()
word_dict = {}
for word in content:
if word in word_dict:
word_dict[word] += 1
else:
word_dict[word] = 1
end = time.time()
print(word_dict)
print("累计用时:", end - start, "秒")
{’ ': 60734000, ‘不’: 298000, ‘看’: 56000, ‘知’: 69000, ‘道’: 63000, ‘莫’: 35000, ‘言’: 58000, ‘真’: 100000, ‘幽’: 18000, ‘默’: 25000, ‘在’: 416000, ‘极’: 26000, ‘度’: 93000, ‘痛’: 13000, ‘苦’: 17000, ‘时’: 206000, ‘笑’: 19000, ‘出’: 225000, ‘声’: 30000, ‘来’: 142000, ‘获’: 76000, ‘得’: 152000, ‘内’: 71000, ‘心’: 137000…}
累计用时: 30.710124015808105 秒
Hadoop数据分析
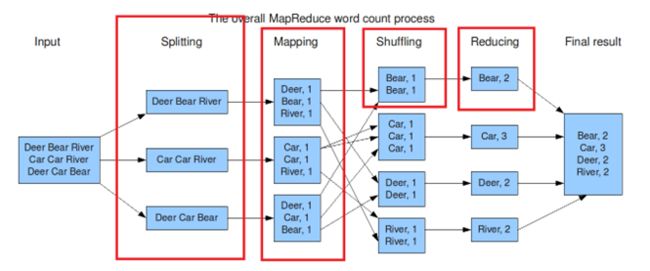
Hadoop环境搭建请参考2022最新黑马程序员大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程
1. 环境简介
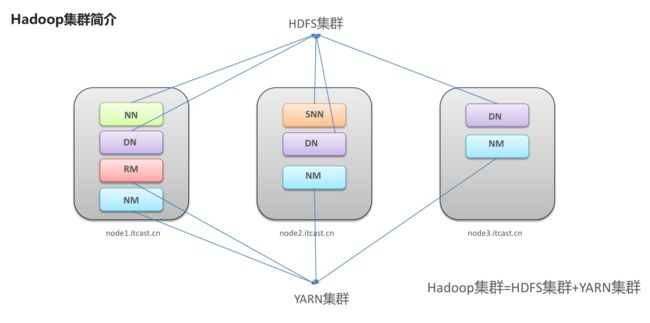
本地三台虚拟机搭建了一个Hadoop集群,如上图所示
2. WordCount
编写WordCount项目,基于maven管理依赖,采用Java语言编写词频统计项目
首先需要创建一个普通的maven 项目,结构如下(三个java文件和log4j.properties文件内容在下方)

2.1 项目依赖 pom.xml
将下方内容添加进pom.xml
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>RELEASEversion>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.8.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.7.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.7.2version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-pluginartifactId>
<version>2.3.2version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
<plugin>
<artifactId>maven-assembly-plugin artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<mainClass>WordCountDrivermainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
将下方内容添加进log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
2.2 编写代码
2.2.1 编写WordCountDriver
/**
* @Author: HAPPY
* @Project_name: wordcount
* @Package_name: PACKAGE_NAME
* @Date: 2022/6/13 10:53
* @Description:
*/
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
long start = System.currentTimeMillis();
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
job.setJarByClass(WordCountDriver.class);
// 3 设置map和reduce类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.out.println("累计用时: " + (System.currentTimeMillis() - start) / 1000 + "秒");
System.exit(result ? 0 : 1);
}
}
2.2.2 编写WordCountMapper
/**
* @Author: HAPPY
* @Project_name: wordcount
* @Package_name: PACKAGE_NAME
* @Date: 2022/6/13 10:53
* @Description:
*/
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割,用空格分割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
2.2.3 编写WordCountReducer
/**
* @Author: HAPPY
* @Project_name: wordcount
* @Package_name: PACKAGE_NAME
* @Date: 2022/6/13 10:53
* @Description:
*/
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
2.3 本地运行
点击WordCountDriver类的运行按钮,选择修改运行配置
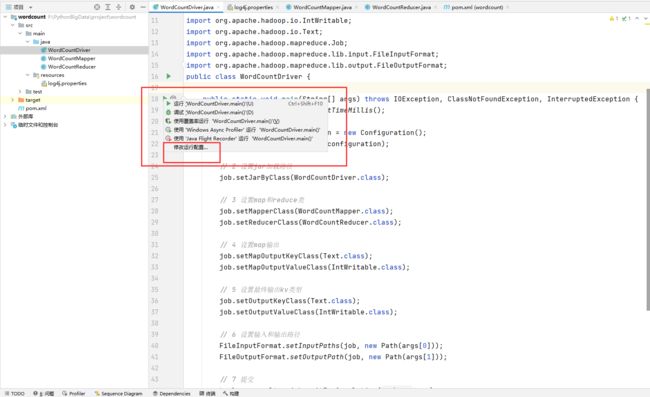
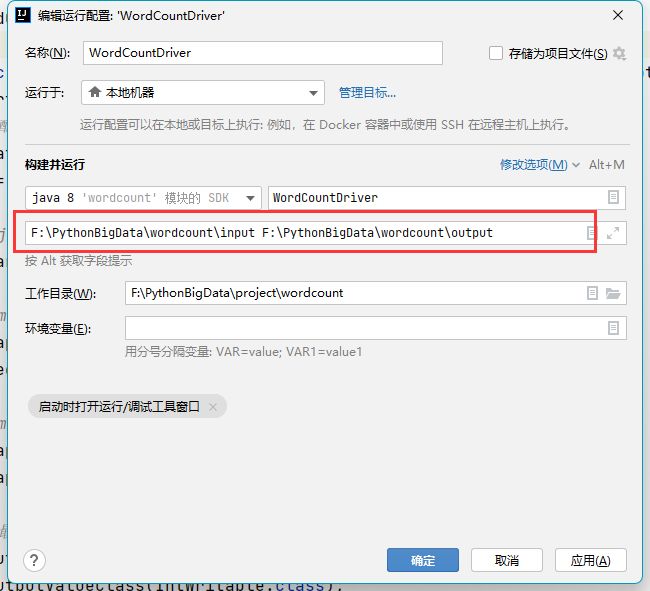
在此次输入文件的输入和输出路径,输出路径一定要不存在,中间用空格分割,两个路径均为文件夹路径
将输入文件置于输入文件夹中,名称随意,建议为全英文,如:input.txt
示例文件introduction.txt,新建一个直接复制即可:
百年孤独 译者 猫科动物 之友 范晔 的 首部 原创 幻想 文学作品 知名 萌宠 博主 顾湘 绘制 治愈 系软萌 插图 用 小 动物 的 天真 融化 人类 的 感伤 给 永远 是 小 动物 的 你 内容 包括 飞马 牌 汽车 马 王登基 金鱼 马 幻影 号 四部 作品 译自 年 德语 经典 第 版 个 童话 全本 无 删减 新增 篇 通行 版未 收录 故事 旅 德文 泽尔 历时 年 翻译 比 对 德文 各个 版本 为 每个 故事 附上 解说 讲述 本书 收入 王尔德 两部 著名 的 童话集 快乐 王子 集 和 石榴 之 家 是 唯美主义 童话 的 代表作 作家 除 遵循 一般 童话 中 应有 的 惩恶扬善 锄强扶弱 劫富济贫 以及 褒美 贬丑 等 主 一位 可爱 的 英国 小女孩 爱丽丝 在 百般 无聊 之际 发现 了 一只 揣着 怀表 会 说话 的 白兔 她 追赶 着 它 而 不慎 掉 进 了 一个 兔子 洞 由此 坠入 了 神奇 的 地下 世界 在 探险 的 同时 不断 认识 小王子 是 法国 著名作家 圣 埃克 絮 佩里 的 一部 享誉 世界 的 畅销 童话 本书 是 中 法 英 三种 语言 对照 的 版本 采用 彩色 插 国内 首部 黑塞 童话集 畅销 德国 百万 销量 纷扰 世界 中 的 心灵 桃源 艺术 童话 属于 世界 文学 中 最 受欢迎 的 小说 形式 在 弘扬 这一 传统 的 二十世纪 德语 作家 中 黑塞当 属 第一 其艺 一千零一夜 被 高尔基 誉为 世界 民间文学 史上 最 壮丽 的 一座 纪念碑 本书 故事 精彩 妙趣横生 想象 丰富 扣人心弦 充满 神秘 奇幻 的 色彩 蕴藏 瑰丽 丰富 的 风貌 既 是 儿 一个 蜘蛛 和 小猪 的 故事 写给 孩子 也 写给 大人 在 朱克曼 家 的 谷仓 里 快乐 地 生活 着 一群 动物 其中 小猪 威尔 伯 和 蜘蛛 夏洛 建立 了 最 真挚 的 友谊 然而 一个 最 丑恶 的 消息 打 在 成功 的 经济体 中 经济 政策 一定 是 务实 的 不是 意识形态化 的 是 具体 的 不是 抽象 的 直面 真 问题 深究 真 逻辑 的 复旦大学 经济学 毕业 课 连接 抽象 经济学 理 懂点 社会学 走出 混沌 的 日常 理解 社会 与 人生 位 社会学 巨擘 个 社会学 核心 概念 幅超 可爱 漫画 上 至 学科 奠基人 奥古斯特 孔德 埃米尔 涂尔 一份 自我 分析 的 行动 纲领 人们 需要 得到 科学 的 凝视 这种 凝视 既 是 对象化 的
点击运行,得到结果
2022-06-30 17:33:26,345 INFO [org.apache.hadoop.conf.Configuration.deprecation] - session.id is deprecated. Instead, use dfs.metrics.session-id
2022-06-30 17:33:26,346 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
2022-06-30 17:33:27,032 WARN [org.apache.hadoop.mapreduce.JobResourceUploader] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2022-06-30 17:33:27,056 WARN [org.apache.hadoop.mapreduce.JobResourceUploader] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2022-06-30 17:33:27,127 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 1
2022-06-30 17:33:27,157 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:1
2022-06-30 17:33:27,229 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local1933687710_0001
2022-06-30 17:33:27,373 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/
2022-06-30 17:33:27,374 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local1933687710_0001
2022-06-30 17:33:27,376 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null
2022-06-30 17:33:27,385 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - File Output Committer Algorithm version is 1
2022-06-30 17:33:27,388 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2022-06-30 17:33:27,447 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks
2022-06-30 17:33:27,447 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1933687710_0001_m_000000_0
2022-06-30 17:33:27,473 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - File Output Committer Algorithm version is 1
2022-06-30 17:33:27,480 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2022-06-30 17:33:27,516 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@542d1666
2022-06-30 17:33:27,531 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/F:/PythonBigData/wordcount/input/introduction.txt:0+2871
2022-06-30 17:33:27,589 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2022-06-30 17:33:27,589 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2022-06-30 17:33:27,589 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2022-06-30 17:33:27,589 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2022-06-30 17:33:27,589 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2022-06-30 17:33:27,593 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2022-06-30 17:33:27,614 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2022-06-30 17:33:27,615 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2022-06-30 17:33:27,615 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2022-06-30 17:33:27,615 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 5981; bufvoid = 104857600
2022-06-30 17:33:27,615 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26211288(104845152); length = 3109/6553600
2022-06-30 17:33:27,634 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2022-06-30 17:33:27,639 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1933687710_0001_m_000000_0 is done. And is in the process of committing
2022-06-30 17:33:27,650 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2022-06-30 17:33:27,650 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1933687710_0001_m_000000_0' done.
2022-06-30 17:33:27,650 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1933687710_0001_m_000000_0
2022-06-30 17:33:27,650 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.
2022-06-30 17:33:27,652 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for reduce tasks
2022-06-30 17:33:27,652 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1933687710_0001_r_000000_0
2022-06-30 17:33:27,658 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - File Output Committer Algorithm version is 1
2022-06-30 17:33:27,658 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2022-06-30 17:33:27,697 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@2ace12a4
2022-06-30 17:33:27,700 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@27c22b09
2022-06-30 17:33:27,714 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=2568277248, maxSingleShuffleLimit=642069312, mergeThreshold=1695063040, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2022-06-30 17:33:27,716 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local1933687710_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2022-06-30 17:33:27,755 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1933687710_0001_m_000000_0 decomp: 7539 len: 7543 to MEMORY
2022-06-30 17:33:27,766 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 7539 bytes from map-output for attempt_local1933687710_0001_m_000000_0
2022-06-30 17:33:27,768 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 7539, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->7539
2022-06-30 17:33:27,771 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
2022-06-30 17:33:27,772 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2022-06-30 17:33:27,772 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2022-06-30 17:33:27,783 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2022-06-30 17:33:27,783 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 7536 bytes
2022-06-30 17:33:27,786 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 1 segments, 7539 bytes to disk to satisfy reduce memory limit
2022-06-30 17:33:27,787 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 7543 bytes from disk
2022-06-30 17:33:27,788 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce
2022-06-30 17:33:27,788 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2022-06-30 17:33:27,790 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 7536 bytes
2022-06-30 17:33:27,790 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2022-06-30 17:33:27,794 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2022-06-30 17:33:27,807 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1933687710_0001_r_000000_0 is done. And is in the process of committing
2022-06-30 17:33:27,808 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied.
2022-06-30 17:33:27,808 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local1933687710_0001_r_000000_0 is allowed to commit now
2022-06-30 17:33:27,810 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local1933687710_0001_r_000000_0' to file:/F:/PythonBigData/wordcount/output/_temporary/0/task_local1933687710_0001_r_000000
2022-06-30 17:33:27,810 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2022-06-30 17:33:27,810 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1933687710_0001_r_000000_0' done.
2022-06-30 17:33:27,810 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1933687710_0001_r_000000_0
2022-06-30 17:33:27,810 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce task executor complete.
2022-06-30 17:33:28,380 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1933687710_0001 running in uber mode : false
2022-06-30 17:33:28,381 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 100%
2022-06-30 17:33:28,382 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1933687710_0001 completed successfully
2022-06-30 17:33:28,388 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 30
File System Counters
FILE: Number of bytes read=21212
FILE: Number of bytes written=585998
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=1
Map output records=778
Map output bytes=5981
Map output materialized bytes=7543
Input split bytes=120
Combine input records=0
Combine output records=0
Reduce input groups=282
Reduce shuffle bytes=7543
Reduce input records=778
Reduce output records=282
Spilled Records=1556
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=7
Total committed heap usage (bytes)=494927872
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2871
File Output Format Counters
Bytes Written=2545
累计用时: 2秒
进程已结束,退出代码为 0
此时去输入文件夹下查看输出结果,结果保存在part-r-00000文件中,用记事本打开就行
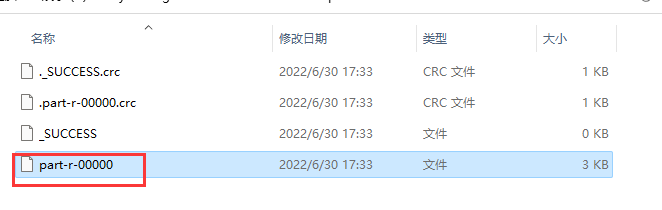
部分内容如下:
396
一个 3
一份 1
一位 1
一千零一夜 1
一只 1
一定 1
一座 1
一群 1
一般 1
一部 1
三种 1
上 1
不慎 1
不断 1
不是 2
与 1
丑恶 1
世界 5
两部 1
个 2
中 6
丰富 2
为 1
主 1
之 1
之友 1
之际 1
也 1
了 4
二十世纪 1
享誉 1
人们 1
人生 1
人类 1
代表作 1
以及 1
会 1
传统 1
伯 1
位 1
作品 1
作家 2
你 1
佩里 1
儿 1
充满 1
兔子 1
...
2.4 利用Hadoop集群运行
利用maven插件将程序打包为jar文件

将带有依赖的jar文件上传至任意虚拟机

将需要处理的文本文件上传到HDFS文件系统中,上传后集群中的三台虚拟机都可以使用该文件
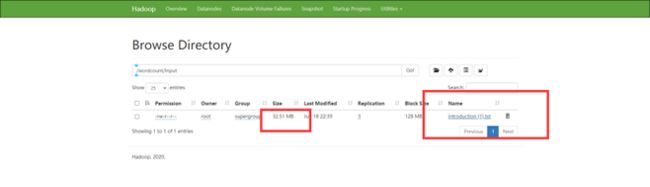
执行任务 hadoop jar wordcount-1.0-SNAPSHOT-jar-with-dependencies.jar /wordcount/input /wordcount/outputnew
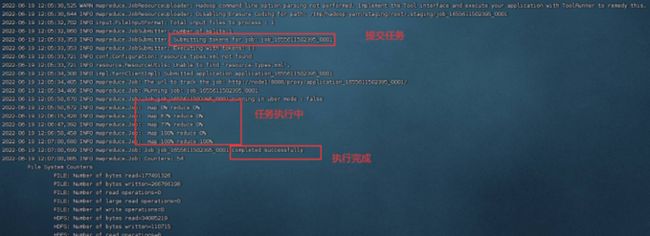
任务执行完累计耗时175秒,个人笔记本性能不是很好,三台虚拟机都只4G内存,因此运行效率较差。

查看输出结果,输出文件在HDFS的/wordcount/outputnew文件夹下
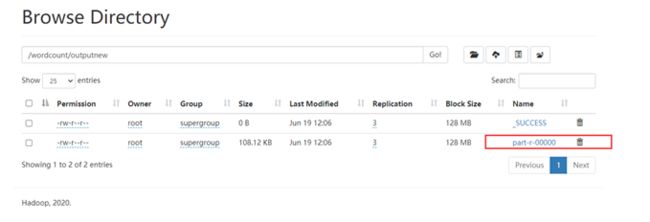
下载后打开,内容如下,与本地统计一致
Hadoop执行流程如下图所示: