dgl源码阅读笔记(2)——GCN
dgl源码阅读笔记(2)——GCN
图神经网络开源库dgl阅读笔记
文章目录
- dgl源码阅读笔记(2)——GCN
- 前言
- 一、GCN简单回顾
- 二、走进DGL代码
-
- 1. class GCN
- 2. class GraphConv
- 三、开始执行训练train.py
-
- 1. 主函数启动
- 2. 在主函数调用main()
- 总结
前言
博客内容为个人阅读dgl代码笔记,仅供个人使用,还有许多不足需要发现改正。
一、GCN简单回顾
GCN源自2017年的论文 SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
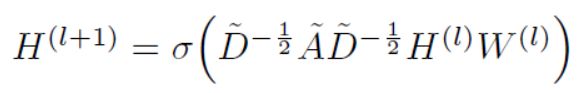
主要是利用了上图的卷积公式,其中A为邻接矩阵,D为度矩阵,H为每一层的特征矩阵,W为权重矩阵。
根据矩阵转移公式进行给定次数的迭代,分别用到了度矩阵,邻接表,归一化。
一开始的H(0)可以随机生成。进行了L层学习,那么H(0)就会变成H(l),每一层的区别在于权重W矩阵的不同,如果最后为了预测类别,利用softmax将embedding变成一个类别代号进行分类,从而可以进行一个有监督的学习。
二、走进DGL代码
1. class GCN
GCN类的全部代码(gcn.py)如下:
代码中有注释,常规的pytorch.nn架构较为好理解。
GCN内部调用了多层的GraphConv卷积层。
class GCN(nn.Module):
def __init__(self,
g,
in_feats,
n_hidden,
n_classes,
n_layers,
activation,
dropout):
# 图,输入特征维度,隐藏层维度,输出类别数,层数,激活函数,drop概率
super(GCN, self).__init__()
self.g = g
self.layers = nn.ModuleList()
# input layer
self.layers.append(GraphConv(in_feats, n_hidden, activation=activation))
# hidden layers
for i in range(n_layers - 1):
self.layers.append(GraphConv(n_hidden, n_hidden, activation=activation))
# output layer
self.layers.append(GraphConv(n_hidden, n_classes))
self.dropout = nn.Dropout(p=dropout)
def forward(self, features):
h = features
for i, layer in enumerate(self.layers):
if i != 0:
h = self.dropout(h)
h = layer(self.g, h)
return h
2. class GraphConv
这个类是在graphconv.py文件下
初始化函数如下:
传入了输入和输出的特征维度,norm有left,right,both三个选项,默认为both
右乘对应入度的归一化,左乘对应出度的归一化,both对应论文中要求的左右两边的归一化
weight是在H矩阵后乘的那个权重矩阵,默认为True,用th.Tensor初始化一个随机矩阵
bias是偏置向量,用th.Tensor初始化一个随机向量
def __init__(self,
in_feats,
out_feats,
norm='both',
weight=True,
bias=True,
activation=None,
allow_zero_in_degree=False):
super(GraphConv, self).__init__()
if norm not in ('none', 'both', 'right', 'left'):
raise DGLError('Invalid norm value. Must be either "none", "both", "right" or "left".'
' But got "{}".'.format(norm))
self._in_feats = in_feats
self._out_feats = out_feats
self._norm = norm
self._allow_zero_in_degree = allow_zero_in_degree
if weight:
self.weight = nn.Parameter(th.Tensor(in_feats, out_feats))
else:
self.register_parameter('weight', None)
if bias:
self.bias = nn.Parameter(th.Tensor(out_feats))
else:
self.register_parameter('bias', None)
self.reset_parameters()
self._activation = activation
注意到在最后调用了self.reset_parameters(),引入了特定的标准化方法处理权重矩阵,且偏置向量初始化为0
def reset_parameters(self):
r"""
Description
-----------
Reinitialize learnable parameters.
Note
----
The model parameters are initialized as in the
`original implementation 训练的过程中会调用forward()
def forward(self, graph, feat, weight=None, edge_weight=None):
with graph.local_scope():
if not self._allow_zero_in_degree:
if (graph.in_degrees() == 0).any():
raise DGLError('There are 0-in-degree nodes in the graph, '
'output for those nodes will be invalid. '
'This is harmful for some applications, '
'causing silent performance regression. '
'Adding self-loop on the input graph by '
'calling `g = dgl.add_self_loop(g)` will resolve '
'the issue. Setting ``allow_zero_in_degree`` '
'to be `True` when constructing this module will '
'suppress the check and let the code run.')
以上部分是判断是否有空入度,因为这样的节点永远无法被更新。
graph.local_scope()是在dgl.graph中进行操作,但是超出这个范围之后不会改变graph原本的值,所以forward代码几乎都在这个范围里运行,很安全不破坏数据。
aggregate_fn = fn.copy_src('h', 'm')
if edge_weight is not None:
assert edge_weight.shape[0] == graph.number_of_edges()
graph.edata['_edge_weight'] = edge_weight
aggregate_fn = fn.u_mul_e('h', '_edge_weight', 'm')
import dgl
message_func = dgl.function.copy_src(‘h’, ‘m’)
上面代码块和下面代码块的功能是一样的,就是定义一个函数,将其h属性复制一份到m属性上
也就是aggregate_fn的功能
def message_func(edges):
return {‘m’: edges.src[‘h’]}
下面的步骤是为了不同的度矩阵需求,对degs和norm进行不同的处理,both情况下norm需要开平方,其他情况只需要取逆。
# (BarclayII) For RGCN on heterogeneous graphs we need to support GCN on bipartite.
feat_src, feat_dst = expand_as_pair(feat, graph)
if self._norm in ['left', 'both']:
degs = graph.out_degrees().float().clamp(min=1)
if self._norm == 'both':
norm = th.pow(degs, -0.5)
else:
norm = 1.0 / degs
shp = norm.shape + (1,) * (feat_src.dim() - 1)
norm = th.reshape(norm, shp)
feat_src = feat_src * norm
上面代码块expand_as_pari,和shp的意义简单解释如下:
expanda_as_pair在右边的文件路径中![]()
如果feature已经是一个元组了,就返回feature本身
如果g不是block(g.is_block == False)就返回出两个一样的feature
norm原本是deg一样的维度(2708,),利用shp将norm变成了(2708, 2 - 1)维度的列向量
因为当前代码是在left或者both的判断逻辑中,所以最后一步不忘初心将feat_src进行了left的归一化
即 D-1 或者D-1/2
需要注意到,这里面的右乘列向量和矩阵乘法中左乘单位矩阵是一样的效果,这一步需要在消息传递前完成,因为每一行是一个节点的特征行向量,归一化后再传播。
开始执行到下面的代码块中
如果输入特征维度高于输出维度,先右乘权重矩阵再进行消息传递,这样可以在传递前减少需要计算的维度
否则先消息传递,再乘权重矩阵
这里把当前的特征矩阵存到了srcdata[‘h’]中,利用graph.update_all进行消息传递,其中的信息聚合参数为forward函数一开始定义的 aggregate_fn = fn.copy_src(‘h’, ‘m’),即将’h’数据赋值到’m’属性上
update_all实现了基于graph的消息传递,即完成了邻接矩阵A的功能,这个函数十分重要,在本系列另一篇博客 dgl源码阅读笔记(1)——update_all.有讲解。
此时的graph.dstdata[‘h’]存储了消息传递后的数据
但是最后除了输出的rst其他内容都没有用,因为都被with graph.local_scope():覆盖了,都是局部变量而已。
if weight is not None:
if self.weight is not None:
raise DGLError('External weight is provided while at the same time the'
' module has defined its own weight parameter. Please'
' create the module with flag weight=False.')
else:
weight = self.weight
if self._in_feats > self._out_feats:
# mult W first to reduce the feature size for aggregation.
if weight is not None:
feat_src = th.matmul(feat_src, weight)
graph.srcdata['h'] = feat_src
graph.update_all(aggregate_fn, fn.sum(msg='m', out='h'))
rst = graph.dstdata['h']
else:
# aggregate first then mult W
graph.srcdata['h'] = feat_src
graph.update_all(aggregate_fn, fn.sum(msg='m', out='h'))
rst = graph.dstdata['h']
if weight is not None:
rst = th.matmul(rst, weight)
下面与前面的函数类似,也是进行归一化的判断,对于right补上归一化操作,对于消息传递后的节点向量矩阵进行归一化就实现了消息接收的归一化。
if self._norm in ['right', 'both']:
degs = graph.in_degrees().float().clamp(min=1)
if self._norm == 'both':
norm = th.pow(degs, -0.5)
else:
norm = 1.0 / degs
shp = norm.shape + (1,) * (feat_dst.dim() - 1)
norm = th.reshape(norm, shp)
rst = rst * norm
if self.bias is not None:
rst = rst + self.bias
if self._activation is not None:
rst = self._activation(rst)
return rst
三、开始执行训练train.py
1. 主函数启动
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='GCN')
parser.add_argument("--dataset", type=str, default="cora",
help="Dataset name ('cora', 'citeseer', 'pubmed').")
parser.add_argument("--dropout", type=float, default=0.5,
help="dropout probability")
parser.add_argument("--gpu", type=int, default=-1,
help="gpu")
parser.add_argument("--lr", type=float, default=1e-2,
help="learning rate")
parser.add_argument("--n-epochs", type=int, default=200,
help="number of training epochs")
parser.add_argument("--n-hidden", type=int, default=16,
help="number of hidden gcn units")
parser.add_argument("--n-layers", type=int, default=1,
help="number of hidden gcn layers")
parser.add_argument("--weight-decay", type=float, default=5e-4,
help="Weight for L2 loss")
parser.add_argument("--self-loop", action='store_true',
help="graph self-loop (default=False)")
parser.set_defaults(self_loop=False)
args = parser.parse_args()
print(args)
main(args)
留存一下parser状态以便回来查看
2. 在主函数调用main()
上面的代码执行后进入到main()函数中:
首先进入main()之后对数据集进行加载,存储data中的参数,方便以后调用
数据集初始化结束
def main(args):
# load and preprocess dataset
if args.dataset == 'cora':
data = CoraGraphDataset()
elif args.dataset == 'citeseer':
data = CiteseerGraphDataset()
elif args.dataset == 'pubmed':
data = PubmedGraphDataset()
else:
raise ValueError('Unknown dataset: {}'.format(args.dataset))
g = data[0]
if args.gpu < 0:
cuda = False
else:
cuda = True
g = g.int().to(args.gpu)
features = g.ndata['feat']
labels = g.ndata['label']
train_mask = g.ndata['train_mask']
val_mask = g.ndata['val_mask']
test_mask = g.ndata['test_mask']
in_feats = features.shape[1]
n_classes = data.num_labels
n_edges = data.graph.number_of_edges()
下面的代码用于判断代码是否要添加自环,调用dgl的方法实现。然后对边数、节点度向量(D),度向量的-1/2次方,进行计算和存储。其中g.ndata[‘norm’]将norm展开成列向量存储。
if args.self_loop:
g = dgl.remove_self_loop(g)
g = dgl.add_self_loop(g)
n_edges = g.number_of_edges()
# normalization
degs = g.in_degrees().float()
norm = torch.pow(degs, -0.5)
norm[torch.isinf(norm)] = 0 # isinf是判断一个tensor是否无界
if cuda:
norm = norm.cuda()
g.ndata['norm'] = norm.unsqueeze(1)
接下来是模型的初始化阶段,包括GCNmodel,优化函数,误差函数:
# create GCN model
model = GCN(g,
in_feats,
args.n_hidden,
n_classes,
args.n_layers,
F.relu,
args.dropout)
if cuda:
model.cuda()
loss_fcn = torch.nn.CrossEntropyLoss()
# use optimizer
optimizer = torch.optim.Adam(model.parameters(),
lr=args.lr,
weight_decay=args.weight_decay)
主函数最后的这一部分内容,对模型进行epoch次的训练
model.train()是pytorch.nn.Module的函数,作用是启用batch normalization和drop out,和测试时的model.eval()会沿用batch normalization的值,并不使用drop out相互映照,都是给个状态
训练过程先给出一个logits,然后根据logits计算误差,计算梯度,反向传播更新参数。
# initialize graph
dur = []
for epoch in range(args.n_epochs):
model.train()
if epoch >= 3:
t0 = time.time()
# forward
logits = model(features)
loss = loss_fcn(logits[train_mask], labels[train_mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch >= 3:
dur.append(time.time() - t0)
acc = evaluate(model, features, labels, val_mask)
print("Epoch {:05d} | Time(s) {:.4f} | Loss {:.4f} | Accuracy {:.4f} | "
"ETputs(KTEPS) {:.2f}".format(epoch, np.mean(dur), loss.item(),
acc, n_edges / np.mean(dur) / 1000))
print()
acc = evaluate(model, features, labels, test_mask)
print("Test accuracy {:.2%}".format(acc))
在验证准确度的代码中调用了evaluate函数:
取每一个训练变量的最大class为label,计算和真实分类相同的个数,并n/N求得正确率
def evaluate(model, features, labels, mask):
model.eval()
with torch.no_grad():
logits = model(features)
logits = logits[mask]
labels = labels[mask]
_, indices = torch.max(logits, dim=1)
correct = torch.sum(indices == labels)
return correct.item() * 1.0 / len(labels)
这就是train的整个流程
总结
从整个代码的实现流程来看,调用了不少DGL库中经典的函数。
为了避免大规模的矩阵乘法,代码没有用邻接矩阵进行矩阵相乘,而是利用了消息传播和消息聚合来实现了每一层的消息传递。