论点挖掘(Argument Mining)是一项从文本中提取论点成分的任务,通常作为自动写作评估系统的一部分。这是自然语言处理中一个非常热门的领域。一个好的 AM 模型可以将一段原始将一段原始文本的序列标记为它们所属的论点内容。虽然历史上这一问题被视为一个语义分割问题,最先进的(SOTA) AM技术把它作为一个命名实体识别(NER)问题的长序列的文本。

尽管有这个领域的历史,关于NER AM数据集的文献相对较少,自2014年以来的唯一贡献是Christian Stab和Iryna Gurevych的Argument Annotated Essays。最近(截至2022年3月),随着PERSUADE(在Kaggle竞赛Feedback Prize中使用)和ARG2020数据集(在GitHub发布),这种情况虽然得到了改善,但很少有关于AM模型的跨数据集性能测试。因此也没有研究对抗性训练如何提高AM模型的跨数据集性能。对AM模型对抗实例的鲁棒性研究也较少。
由于每个数据集都以不同的格式存储,使上述挑战变得更加复杂,这使得在实验中对数据进行标准化处理变得困难(Feedback Prize比赛就可以确认这一点,因为大部分代码都是用于处理数据的)。
本文介绍的ArgMiner是一个用于使用基于Transformer的模型对SOTA论点挖掘数据集进行标准化的数据处理、数据增强、训练和推断的pytorch的包。本文从包特性介绍开始,然后是SOTA数据集的介绍,并详细描述了ArgMiner的处理和扩展特性。最后对论点挖掘模型的推理和评估(通过Web应用程序)进行了简要的讨论。
ArgMiner简介
ArgMiner 的主要特点总结如下:
- 处理SOTA 数据集,而无需编写任何额外的代码行
- 可以在单词和子标记级别生成以下标记方法 {io, bio, bioo, bixo},无需额外的代码
- 可以在不更改数据处理管道的情况下进行自定义增强
- 提供一个 用于使用任何 HuggingFace TokenClassification 模型进行论点挖掘微调的PyTorch数据集类
- 提供高效的训练和推理流程
下图显示了 ArgMiner 的端到端工作:
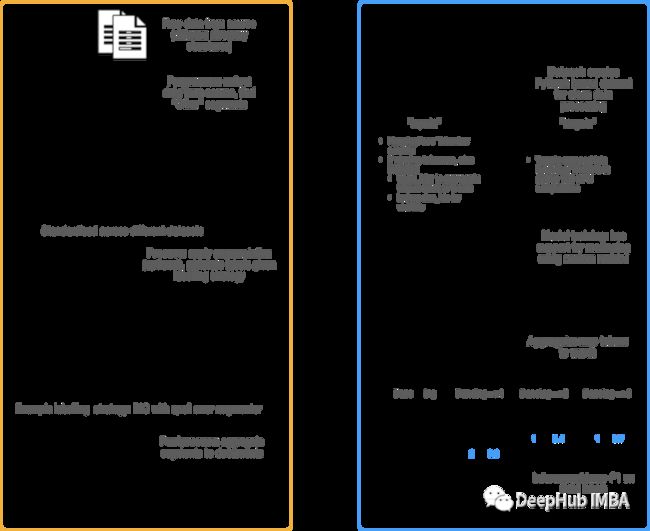
数据处理和增强
数据集
论点注释论文(Argument Annotated Essays ):这是一个402篇论文的合集。它有三个论点组成部分:Claim, MajorClaim, Premise。数据集可以在TUDarmstadt中找到;原始的论文在ACL上,后续的论文在MIT Press Direct上。PERSUADE:这是一本由美国6-12年级学生撰写的15000篇文章的合集。它有7个论点组成部分:Lead, Position, Claim, Counterclaim, Rebuttal, Evidence, ConcludingStatement。数据集可以通过Kaggle比赛访问。
ARG2020:这是一本145篇中学生作文的合集。它有两个论点组成部分:Claim Premise。该数据集在GitHub上公开,有关这项工作的论文在ArXiv上。
这些数据集以不同的方式存储和处理。例如,AAE和ARG2020数据集有ann文件,数据还附带了原始论文文本的.txt文件。与ARG2020不同,AAE数据集带有用于分割数据的训练和测试id。
PERSUADE有更复杂的目录结构,其中包括原始的.txt论文的训练和测试目录。关于论点标签的实际信息包含在train.csv中。
没有一个数据集实际上表明文章中不是论点组成部分的部分,即所谓的“其他”类。但是NER问题通常需要这样做(否则你是选择性地从文章中而不是整个文章中查看信息)。因此需要从论文本身提取这些内容。
为了以标准化的格式处理这些变化很大的原始文本,ArgMiner采用了3个阶段:
预处理:从源中提取数据
这个步骤以原始格式(对于每个数据集)获取数据,并使用span_start和span_end特性和原始文本生成一个DataFrame,其结构如下:[essay_id, text, argument_component]。
这样可以支持使用标准方法来生成NER标签,或增强数据。这些处理都基于一个基本的DataProcessor类,该类具有保存和应用train-test-split的内置特性,因此可以轻松地从它创建新的处理类。
from argminer.data import TUDarmstadtProcessor, PersuadeProcessor, DataProcessor
# process the AAE dataset from source
processor = TUDarmstadtProcessor('path_to_AAE_dir').preprocess()
print(processor.dataframe.head())
# process the Persuade dataset from source
processor = PersuadeProcessor('path_to_persuade_dir').preprocess()
print(processor.dataframe.head())
# create a custom processor for new dataset (e.g. ARG2020 will be done this way)
class ARG2020Processor(DataProcessor):
def __init__(self, path=''):
super().__init__(path)
def _preprocess(self):
pass生成标签和(可选)增加数据
数据经过了处理已经变为标准格式了,那么下一步就可以为数据生成NER样式标签。在这一步结束时,数据集将像这样:[essay_id, text, argument_component, NER_labels]。
有时人们可能会对增强数据感兴趣,无论是对抗性训练还是对抗性例子的鲁棒性测试。在这种情况下,可以提供一个接受一段文本并返回一段增强文本的函数。在这个函数里可以使用其他的NLP扩充库,如textattack和nlpaug。
from argminer.data import PersuadeProcessor
processor = PersuadeProcessor().preprocess().process(strategy='bio')
# augmenters
# remove first word (toy example) on io labelling
first_word_removal = lambda x: ' '.join(x.split()[1:])
processor = PersuadeProcessor().preprocess().process(strategy='io', processors=[first_word_removal])
# remove last word (toy example) on bieo labelling
last_word_removal = lambda x: ' '.join(x.split()[:-1])
processor = PersuadeProcessor().preprocess().process(strategy='io', processors=[last_word_removal])后处理:将序列聚合到文档
最后一步非常简单,因为标签已经创建好了,最后就需要通过段的doc_id来连接它们。这个阶段的结果输出是一个DataFrame:[essay_id, full_essay_text, NER_labels]。使用内置的训练和测试集的分割也是非常容易的。
from argminer.data import PersuadeProcessor
processor = PersuadeProcessor().preprocess().process('bio').postprocess()
# full data
print(processor.dataframe.head())
# train test split
df_dict = processor.get_tts(test_size=0.3, val_size=0.1)
df_train = df_dict['train']
df_test = df_dict['test']
df_val = df_dict['val']PyTorch数据集
PyTorch数据集被设计为接受.postprocess()阶段的输入,变量strategy_level可以确定标记策略是否应该应用于单词级别还是标记级别。数据集将类标签可以扩展到子标记。与Kaggle上的例子相比,这是一个巨大的改进,因为它是矢量化的可以有效地使用GPU。数据集还创建了一个映射,将扩展标签合并到它们的核心标签,以进行推断(例如“B-Claim, I- claim, E-Claim”都被合并为Claim)。
它的使用也非常简单,而且由于它是基于PyTorch的可以很容易地将它集成到训练中。例如:
from argminer.data import ArgumentMiningDataset
trainset = ArgumentMiningDataset(df_label_map, df_train, tokenizer, max_length)
train_loader = DataLoader(trainset)
for epoch in range(epochs):
model.train()
for i, (inputs, targets) in enumerate(train_loader):
optimizer.zero_grad()
loss, outputs = model(
labels=targets,
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
return_dict=False
)
# backward pass
loss.backward()
optimizer.step()推理
ArgMiner还提供了用于训练模型训练和进行推理的函数。
ArgMiner将推断函数编写成高效的(在可能的情况下,它们利用GPU和矢量化)和批处理的(因此非常适合低内存设置),这意味着推断函数也可以在针对验证数据的训练过程中使用。在推理过程中当从标记映射回单词时,可以轻松地选择聚合级别。例如,给定两个标记“Unit”和“ed”以及每个类的概率,可以使用单词“Unit”的最佳概率、最佳平均概率或最佳最大概率将它们聚合成“United”。
与Feedback Prize竞赛中使用的方案相比,该推理方案具有一些优势。
Web应用程序
ArgMiner还包含有一个web应用程序,可以查看模型给出的输出(或任何来自HuggingFace的模型),也可用于评估自定义数据集上的模型的性能。这是一种有用的(非正式的)方法,可以在特定的例子上探究模型,

了解它在做什么。
总结
很长一段时间以来,论点挖掘的文献对数据集的描述非常少,但随着PERSUADE和ARG2020的发布,这种情况发生了改变。论点挖掘中的知识转移问题以及鲁棒性问题还有待进一步研究。但首先从数据处理方面来看,这通常是困难的,因为不同源的数据格式、表示数据有很多多种方法,以及由于使用不相等的段进行表示和推断而导致的效率问题。
ArgMiner是Early Release Access中的一个包,可以用于对SOTA论点挖掘数据集进行标准化处理、扩充、训练和执行推断
虽然包的核心已经准备好了,但是还有一些零散的部分需要解决,例如:ARG2020数据集的数据处理还不完善,还没有扩展DataProcessor类以允许分层的训练测试分割。
如果您对论点挖掘和NLP感兴趣,并且对本文感兴趣,可以联系该项目的并申请成为合作者。因为作者想将这个项目做成长期的项目并帮助更多的人能够方便的构建论点挖掘的模型。
项目地址如下:
https://avoid.overfit.cn/post/8bed8579a0c6485fab8c414dbf6eff90
作者:yousefnami