仿牛客技术博客项目常见问题及解答(二)
书接上回:仿牛客技术博客项目常见问题及解答(一)_李孛欢的博客-CSDN博客
8.项目里哪块用到aop了
项目中统一处理日志时,用到了AOP。

如果我们在每个业务组件中都记录日志,那么会产生非常多的重复代码。如果我们采用OOP的思想,将记录日志的功能封装成一个bean去调用,那么会产生耦合度高等问题。因为记录日志本身不属于业务需求,它属于系统需求,所以我们不应该将业务需求和系统需求耦合在一起,这个时候我们就需要用AOP来处理。
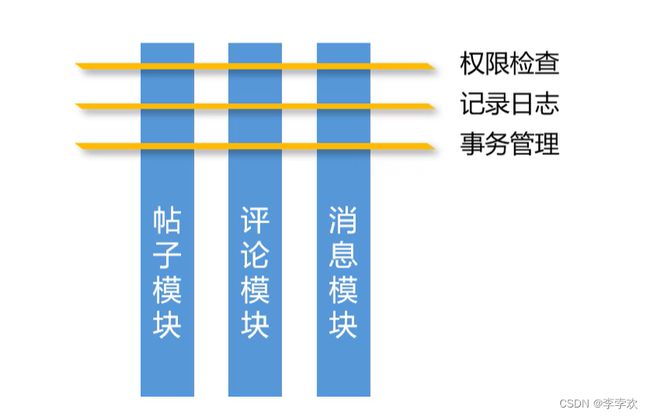

Target是我们已经开发好的业务逻辑的一个一个bean,我们称之为目标对象,目标对象上有很多地方可以被织入代码,可以被织入代码的地方我们统称为连接点joinpoint。AOP解决统一处理系统需求的方式是将代码定义到一个额外的bean,叫切面组件Aspect,这个组件在程序运行之前就需要被框架织入到某些连接点。切面组件的pointcut声明织入到哪个位置,通知Advice方法声明切面要处理什么样的逻辑。

具体使用:
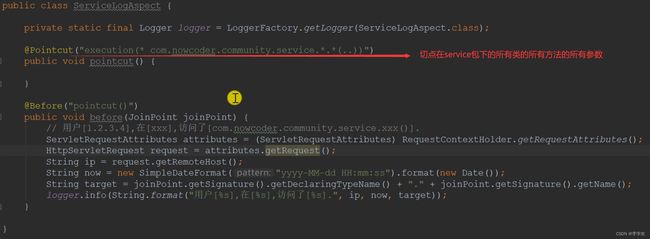
before代码前置通知,在开头织入程序。
9.项目中redis怎么用的
缓存点赞和关注:
1、Redis缓存用户点赞数用String类型,以用户ID为key,点赞时,自增,取消赞时,自减;
缓存实体点赞数,set类型,用户给实体点赞时添加进列表,取消赞时则移除,最后用size统计;
2、缓存粉丝列表,使用zset,存入粉丝的id和关注的时间戳,使用zCard获得粉丝数量。利用reverseRange的时间戳反向排序,按关注时间加载粉丝列表。
优化登录:
1、使用Redis缓存用户信息。将user缓存到Redis中,获取user时,先从Redis获取。取不到时,则从数据库中查询,再缓存到Redis中。因为很多界面都要用到user信息,并发时,频繁的访问数据库,会导致数据库崩溃。变更数据库时,先更新数据库,再清空缓存;
2、使用Redis缓存验证码 。原本添加到session中,减轻服务器压力。将验证码存到Redis中,方便查询检验;
-验证码需要频繁的访问与刷新,对性能要求很高;
-验证码不需要永久存储,通常在很短的时间内就会失效;
-分布式部署时,存在session共享问题;
3、登录凭证:原本添加到MySQL中,为减轻每次登录都去查询数据库的压力,将登录凭证ticket缓存在Redis中,防止每次都要进行数据库的查询,提高并发能力。退出登录时,原本要修改数据库中的登录凭证,现在只需要修改Redis即可。
10.redis的key怎么设计?
redis的key是String类型的,编写了一个工具类来生成redis的key。key由多个单词拼接而成,中间采用冒号隔开,有的单词是固定的,有些单词是动态的,设计方法如下所示:
这里如某个实体的赞采用了set来存入,存的是userId,这样的话能够得到每个点赞的人,以及数量。
这里用户的赞用int存,它等于该用户实体(帖子+评论)收到的赞的总和。

关注的实体和实体拥有的粉丝都用zset存。set保存关注者以及关注时间为score
缓存用户数据使用Value类型,key为用userID得到的key,value为user对象(设置过期时间,且数据修改时需要清除缓存)
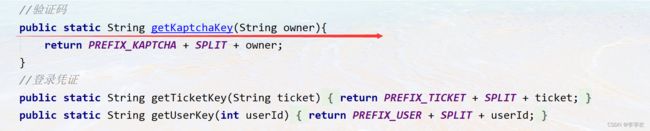 验证码是与user相关的,但是这里我们不能直接传入userId,因为还未登录,我们不知道用户是谁。这里传入了一个字符串owner,这是在用户访问登录页面的时候,给他发一个凭证(随机字符串),存到cookie里,如下图所示。
验证码是与user相关的,但是这里我们不能直接传入userId,因为还未登录,我们不知道用户是谁。这里传入了一个字符串owner,这是在用户访问登录页面的时候,给他发一个凭证(随机字符串),存到cookie里,如下图所示。
用的时候从cookie内将这个owner取出来,在得到rediskey,然后获取验证码,与输入的验证码进行对比。
11.缓存点赞数如何实现
帖子和评论的赞一起存,统称为实体的赞。还需要统计用户的赞(用户的帖子和评论收到的赞的总和)如下图所示。因为如果统计用户所有帖子和评论的赞得到用户获得的赞太麻烦,所以这里以用户ID采用rediskey工具拼接为key记录点赞数量(这就会涉及到事务操作。用户的帖子或者评论的点赞数增加了对应的用户的赞要增加)

具体实现:使用redis来存储点赞数,首先需要构造redis的key,如下图拼接
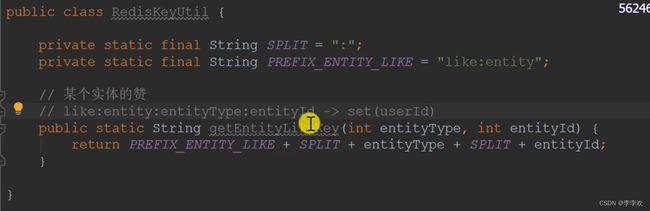
主要考虑到这个entityType(帖子还是评论)和 entityId(这个类型下的目标)确定实体类型和id
而redis的值使用set类型而不是一个简单的整数,这主要是为了可能需求发生变化,比如说想看到谁给我点赞了。集合里面存userid。用户的赞的值就采用value
点赞使用set类型存储,key为点赞对象,set中保存点赞人的ID
点赞的时候需要判断用户是否已经点赞:通过redistemplate.opsforSet().ismember方法 如果已经点过赞了就要把点赞记录删除 否则添加数据。 这里用到了事务操作 重写了execute方法
还需要查询某实体的点赞数量和点赞状态:
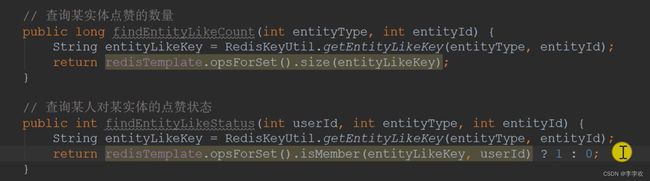
这里点赞状态没有用布尔值是为了之后开发新功能,比如踩就能使用-1;
12 如何保证redis和数据库一致性?
项目中只有redis保存用户信息那里才会出现这个问题!! 因为redis对于点赞、关注、用户凭证和验证码等功能来说都是当作数据库来用的,所以没有这个问题。
只要我们使用 Redis 缓存,就必然会面对缓存和数据库间的一致性保证问题,这也算是 Redis 缓存应用中的“必答题”了。最重要的是,如果数据不一致,那么业务应用从缓存中读取的数据就不是最新数据,这会导致严重的错误。比如说,我们把电商商品的库存信息缓存在 Redis 中,如果库存信息不对,那么业务层下单操作就可能出错,这当然是不能接受的。
缓存和数据库的数据不一致是如何发生的?首先,我们得清楚“数据的一致性”具体是啥意思。其实,这里的“一致性”包含了两种情况:
- 1. 缓存中有数据,那么,缓存的数据值需要和数据库中的值相同;
- 2. 缓存中本身没有数据,那么,数据库中的值必须是最新值。
- 不符合这两种情况的,就属于缓存和数据库的数据不一致问题了。不过,当缓存的读写模式不同时,缓存数据不一致的发生情况不一样,我们的应对方法也会有所不同,所以,我们先按照缓存读写模式,来分别了解下不同模式下的缓存不一致情况。
对于读写缓存来说,如果要对数据进行增删改,就需要在缓存中进行,同时还要根据采取的写回策略,决定是否同步写回到数据库中。
- 1. 同步直写策略:写缓存时,也同步写数据库,缓存和数据库中的数据一致;
- 2. 异步写回策略:写缓存时不同步写数据库,等到数据从缓存中淘汰时,再写回数据库。使用这种策略时,如果数据还没有写回数据库,缓存就发生了故障,那么,此时,数据库就没有最新的数据了。
所以,对于读写缓存来说,要想保证缓存和数据库中的数据一致,就要采用同步直写策略。不过,需要注意的是,如果采用这种策略,就需要同时更新缓存和数据库。所以,我们要在业务应用中使用事务机制,来保证缓存和数据库的更新具有原子性,也就是说,两者要不一起更新,要不都不更新,返回错误信息,进行重试。否则,我们就无法实现同步直写。当然,在有些场景下,我们对数据一致性的要求可能不是那么高,比如说缓存的是电商商品的非关键属性或者短视频的创建或修改时间等,那么,我们可以使用异步写回策略。
下面我们再来说说只读缓存。对于只读缓存来说,如果有数据新增,会直接写入数据库;而有数据删改时,就需要把只读缓存中的数据标记为无效。这样一来,应用后续再访问这些增删改的数据时,因为缓存中没有相应的数据,就会发生缓存缺失。此时,应用再从数据库中把数据读入缓存,这样后续再访问数据时,就能够直接从缓存中读取了。
项目中的redis在存储用户信息时,是只读模式,看代码:
首先从缓存中取,如果有则直接返回,没有则初始化(从数据库取后存入缓存),然后返回。
那么只读情况下,这个过程中会不会出现数据不一致的情况呢?考虑到新增数据和删改数据的情况不一样,所以我们分开来看。
如果是新增数据,数据会直接写到数据库中,不用对缓存做任何操作,此时,缓存中本身就没有新增数据,而数据库中是最新值,此时,缓存和数据库的数据是一致的。
如果发生删改操作,应用既要更新数据库,也要在缓存中删除数据。会出现以下两种问题(前一个要素成果的前提下)

我们在项目中用的是第二种情况,即先更新数据库值,然后删除缓存,如图:
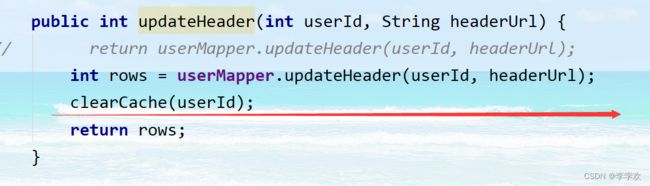 为什么不选择先删除缓存的主要原因是有可能导致请求因缓存缺失而访问数据库,给数据库带来压力
为什么不选择先删除缓存的主要原因是有可能导致请求因缓存缺失而访问数据库,给数据库带来压力
如何解决数据不一致问题?
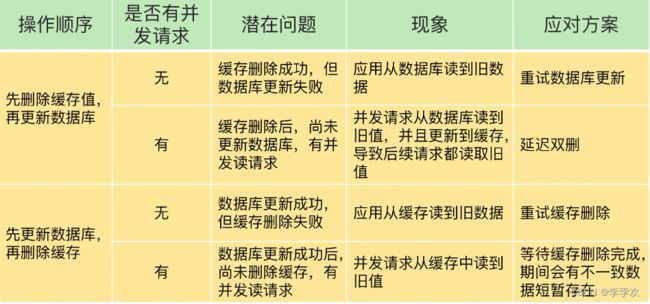
缓存和数据库的数据不一致一般是由两个原因导致的,提供了相应的解决方案。
- 删除缓存值或更新数据库失败而导致数据不一致,可以使用重试机制确保删除或更新操作成功。
- 在删除缓存值、更新数据库的这两步操作中,有其他线程的并发读操作,导致其他线程读取到旧值,应对方案是延迟双删。
重试机制:具体来说,可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中。当应用没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了。否则的话,我们还需要再次进行重试。如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了 。
延迟双删: 一般应用于先删除缓存,再更新数据库的多线程并发访问的情况。这是因为,先更新数据库值,再删除缓存值的情况下,如果线程 A 删除了数据库中的值,但还没来得及删除缓存值,线程 B 就开始读取数据了,那么此时,线程 B 查询缓存时,发现缓存命中,就会直接从缓存中读取旧值。不过,在这种情况下,如果其他线程并发读缓存的请求不多,那么,就不会有很多请求读取到旧值。而且,线程 A 一般也会很快删除缓存值,这样一来,其他线程再次读取时,就会发生缓存缺失,进而从数据库中读取最新值。所以,这种情况对业务的影响较小。
而假设线程 A 删除缓存值后,还没有来得及更新数据库(比如说有网络延迟),线程 B 就开始读取数据了,那么这个时候,线程 B 会发现缓存缺失,就只能去数据库读取。这会带来两个问题:
- 线程 B 读取到了旧值;
- 线程 B 是在缓存缺失的情况下读取的数据库,所以,它还会把旧值写入缓存,这可能会导致其他线程从缓存中读到旧值。
等到线程 B 从数据库读取完数据、更新了缓存后,线程 A 才开始更新数据库,此时,缓存中的数据是旧值,而数据库中的是最新值,两者就不一致了。
这种情况我们就用延迟双删来解决: 在线程 A 更新完数据库值以后,我们可以让它先 sleep 一小段时间,再进行一次缓存删除操作。之所以要加上 sleep 的这段时间,就是为了让线程 B 能够先从数据库读取数据,再把缺失的数据写入缓存,然后,线程 A 再进行删除,这样再有线程来读取,就不会出现我们上面所说的,线程A更新了数据库,却发现缓存值于数据库不一致的情况了。
总结如图:
参考资料:极客时间极客时间-轻松学习,高效学习-极客邦 (geekbang.org) redis核心技术与实战