使用Spring WebFlux和Spring Cloud的反应式微服务
在Spring5正式发布之后,值得一看它的当前版本。此外,我们将尝试将我们的反应式微服务放在Spring云生态系统中,该生态系统包含诸如Eureka的服务发现、Spring Cloud Commons@LoadBalanced的负载平衡以及使用Spring Cloud gateway的API gateway(也基于WebFlux和Netty)等元素。我们还将通过SpringDatareactiveMongo项目的示例来检查Spring对NoSQL数据库的响应式支持。
下图展示了示例系统的体系结构,该体系结构由两个微服务组成:discovery server、gateway和MongoDB数据库。源代码与往常一样可以在GitHub的SpringCloudWebFlux示例库中获得。
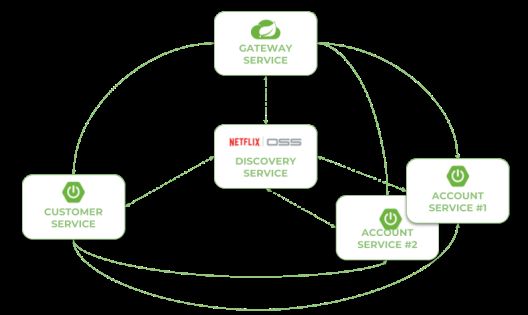
让我们描述创建上述系统的进一步步骤。
第一步. 使用SpringWebFlux构建反应式应用程序
要为项目启用库SpringWebFlux,我们应该在依赖项中包含 spring-boot-starter-webflux 。它包括一些依赖库,如Reactor或Netty服务器。
org.springframework.boot spring-boot-starter-webflux
REST控制器看起来非常类似于为同步web服务定义的控制器。唯一的区别在于返回对象的类型。我们返回的不是单个对象,而是 Mono 类的实例,我们返回的不是 list 类的实例,而是 Flux 类的实例。多亏了 SpringDataResponsiveMongo ,我们不必在存储库bean上调用所需的方法。
@RestController
public class AccountController {
private static final Logger LOGGER = LoggerFactory.getLogger(AccountController.class);
@Autowired
private AccountRepository repository;
@GetMapping("/customer/{customer}")
public Flux findByCustomer(@PathVariable("customer") String customerId) {
LOGGER.info("findByCustomer: customerId={}", customerId);
return repository.findByCustomerId(customerId);
}
@GetMapping
public Flux findAll() {
LOGGER.info("findAll");
return repository.findAll();
}
@GetMapping("/{id}")
public Mono findById(@PathVariable("id") String id) {
LOGGER.info("findById: id={}", id);
return repository.findById(id);
}
@PostMapping
public Mono create(@RequestBody Account account) {
LOGGER.info("create: {}", account);
return repository.save(account);
}
}
第二步. 使用Spring Data Mongo将应用程序与数据库集成
应用程序和数据库集成的实现也非常简单。首先,我们需要包括 spring-boot-starter-data-mongodb-reactive ,以响应项目依赖关系。
org.springframework.boot spring-boot-starter-data-mongodb-reactive
对反应式Mongo存储库的支持在包含初学者后自动启用。下一步是使用ORM映射声明实体。 AccountController 还将以下类作为响应返回。
@Document
public class Account {
@Id
private String id;
private String number;
private String customerId;
private int amount;
...
}
最后,我们可以创建一个扩展 ReactiveCrudepository 的存储库接口。它遵循 SpringDataJPA 实现的模式,并为CRUD操作提供一些基本方法。它还允许您使用自动映射到查询的名称定义方法。与标准Spring数据JPA存储库相比,唯一的区别在于方法签名。对象由 Mono 和 Flux 包裹。
public interface AccountRepository extends ReactiveCrudRepository {
Flux findByCustomerId(String customerId);
}
在本例中,我使用Docker容器在本地运行MongoDB。因为我使用Docker Toolkit在Windows上运行Docker,Docker机器的默认地址是 192.168.99.100 。下面是 application.yml 文件中数据源的配置。
spring:
data:
mongodb:
uri: mongodb://192.168.99.100/test
第三步. 使用Eureka启用服务发现
与SpringCloudEureka的集成与同步REST微服务的集成非常相似。为了启用discovery client,我们应该首先将 spring-cloud-starter-netflix-eureka-client 包含到项目依赖项中。
org.springframework.cloud spring-cloud-starter-netflix-eureka-client
然后我们必须使用 @EnableDiscoveryClient 注释启用它。
@SpringBootApplication
@EnableDiscoveryClient
public class AccountApplication {
public static void main(String[] args) {
SpringApplication.run(AccountApplication.class, args);
}
}
Microservice将自动在Eureka中注册。当然,我们可能会运行每个服务的多个实例。这是显示Eureka仪表板的屏幕( http://localhost:8761 )运行两个 account-service 实例和一个 customer-service 实例后。Eureka服务器作为发现服务模块提供。

第四步. 反应式微服务与WebClient之间的服务间通信
服务间通信由SpringWebFlux项目的WebClient实现。与RestTemplate相同,您应该使用 SpringCloudCommons@LoadBalanced 对其进行注释。它使用Netflix OSS Ribbon client实现与服务发现和负载平衡的集成。因此,第一步是用 @LoadBalanced 注释声明一个客户端构建器bean。
@Bean
@LoadBalanced
public WebClient.Builder loadBalancedWebClientBuilder() {
return WebClient.builder();
}
然后我们可以将WebClient Builder注入REST控制器。与帐户服务的通信是在 GET/{id}/with accounts 中实现的,在这里我们首先使用reactive Spring数据存储库搜索客户实体。它返回object Mono,而WebClient返回Flux。现在,我们的主要目标是将这些内容合并到发布者,并返回单个Mono对象以及从 Flux 获取的帐户列表,而不阻塞流。下面的代码片段演示了我如何使用WebClient与其他microservice通信,然后将存储库中的响应和结果合并到单个 Mono 对象。这种合并可能会以更“优雅”的方式进行,所以可以随意使用您的提案创建推送请求。
@Autowired
private WebClient.Builder webClientBuilder;
@GetMapping("/{id}/with-accounts")
public Mono findByIdWithAccounts(@PathVariable("id") String id) {
LOGGER.info("findByIdWithAccounts: id={}", id);
Flux accounts = webClientBuilder.build().get().uri("http://account-service/customer/{customer}", id).retrieve().bodyToFlux(Account.class);
return accounts
.collectList()
.map(a -> new Customer(a))
.mergeWith(repository.findById(id))
.collectList()
.map(CustomerMapper::map);
}
第五步. 使用Spring Cloud网关构建API网关
SpringCloudGateway是最新的SpringCloud项目之一。它构建在SpringWebFlux之上,正因为如此,我们可以使用它作为基于SpringBoot的反应式微服务的示例系统的网关。与SpringWebFlux应用程序类似,它在嵌入式Netty服务器上运行。要为SpringBoot应用程序启用它,只需将以下依赖项包含到您的项目中。
org.springframework.cloud spring-cloud-starter-gateway
我们还应该启用发现客户端,以便允许网关获取已注册微服务的列表。但是,不需要在Eureka中注册网关应用程序。要禁用注册,可以在 application.yml 文件中将属性 eureka.client.registerWithEureka 设置为 false 。
@SpringBootApplication
@EnableDiscoveryClient
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}
默认情况下,SpringCloudGateway不支持与服务发现的集成。要启用它,我们应该将属性 spring.cloud.gateway.discovery.locator.enabled 设置为 true 。现在,应该做的最后一件事是路由的配置。SpringCloudGateway提供了两种类型的组件,可以在路由内部配置:过滤器和谓词。谓词用于将HTTP请求与路由匹配,而过滤器可用于在发送下游请求之前或之后修改请求和响应。下面是网关的完整配置。它启用服务发现位置,并根据服务注册表中的条目定义两条路由。我们使用路径路由谓词工厂来匹配传入请求,使用重写路径网关过滤器工厂来修改请求的路径,以使其适应下游服务公开的格式(端点在Path/下公开,而网关在 Path/account 和 /customer 下公开)。
spring:
cloud:
gateway:
discovery:
locator:
enabled: true
routes:
- id: account-service
uri: lb://account-service
predicates:
- Path=/account/**
filters:
- RewritePath=/account/(?.*), /$\{path}
- id: customer-service
uri: lb://customer-service
predicates:
- Path=/customer/**
filters:
- RewritePath=/customer/(?.*), /$\{path}
第六步. 使用Spring Boot测试反应式微服务
在进行一些测试之前,让我们回顾一下我们的示例系统。我们有两个微服务帐户服务,客户服务使用MongoDB作为数据库。Microservice客户服务调用由帐户服务公开的端点 GET/customer/{customer} 。帐户服务的URL取自Eureka。整个示例系统隐藏在网关后面,网关的地址为 localhost:8090 。
现在,第一步是在Docker容器上运行MongoDB。执行以下命令后,Mongo在地址 192.168.99.100:27017 下可用。
$ docker run -d --name mongo -p 27017:27017 mongo
然后我们可以继续运行发现服务。Eureka的默认地址为 localhost:8761 。您可以使用IDE运行它,或者只需执行命令 java-jar target/discovery-service-1.0-SNAPHOT.jar 即可。同样的规则也适用于我们的示例微服务。但是,帐户服务需要在两个实例中相乘,因此在运行第二个实例时,需要使用 -Dserver.port VM 参数覆盖默认HTTP端口,例如 java-jar-Dserver.port=2223 target/account-service-1.0-SNAPSHOT.jar 。最后,在运行网关服务之后,我们可以添加一些测试数据。
$ curl --header "Content-Type: application/json" --request POST --data '{"firstName": "John","lastName": "Scott","age": 30}' http://localhost:8090/customer
{"id": "5aec1debfa656c0b38b952b4","firstName": "John","lastName": "Scott","age": 30,"accounts": null}
$ curl --header "Content-Type: application/json" --request POST --data '{"number": "1234567890","amount": 5000,"customerId": "5aec1debfa656c0b38b952b4"}' http://localhost:8090/account
{"id": "5aec1e86fa656c11d4c655fb","number": "1234567892","customerId": "5aec1debfa656c0b38b952b4","amount": 5000}
$ curl --header "Content-Type: application/json" --request POST --data '{"number": "1234567891","amount": 12000,"customerId": "5aec1debfa656c0b38b952b4"}' http://localhost:8090/account
{"id": "5aec1e91fa656c11d4c655fc","number": "1234567892","customerId": "5aec1debfa656c0b38b952b4","amount": 12000}
$ curl --header "Content-Type: application/json" --request POST --data '{"number": "1234567892","amount": 2000,"customerId": "5aec1debfa656c0b38b952b4"}' http://localhost:8090/account
{"id": "5aec1e99fa656c11d4c655fd","number": "1234567892","customerId": "5aec1debfa656c0b38b952b4","amount": 2000}
要测试服务间通信,只需使用网关服务上的帐户调用端点 GET/customer/{id}/ 。它将请求转发给客户服务,然后客户服务使用反应式WebClient调用 account-service 公开的端点。结果如下所示。

结论
自Spring5和SpringBoot2.0以来,有一整套可用的方法来构建基于微服务的体系结构。我们可以使用Spring Cloud Netflix项目的一对一通信、基于message broker的消息传递微服务和Spring Cloud Stream的发布/订阅通信模型,以及最终使用Spring WebFlux的异步、反应式微服务,构建标准的同步系统。本文的主要目标是向您展示如何将SpringWebFlux与SpringCloud项目结合使用,以便为构建在SpringBoot之上的反应式微服务提供服务发现、负载平衡或API网关等机制。在Spring5之前,缺少对反应式微服务的支持Spring引导支持是Spring框架的缺点之一,但现在使用SpringWebFlux就不再是这样了。不仅如此,我们还可以利用Spring对最流行的NoSQL数据库(如MongoDB或Cassandra)的反应式支持,轻松地将反应式微服务与同步REST微服务放在一个系统中。