Spark-core项目实战——电商用户行为数据分析
0 数据准备
本实战项目的数据是采集自电商的用户行为数据。具体的数据可点此链接下载(提取码:44ax)
用户行为数据主要包含用户的 4 种行为: 搜索, 点击, 下单和支付.
数据格式如下, 不同的字段使用下划线分割开_:
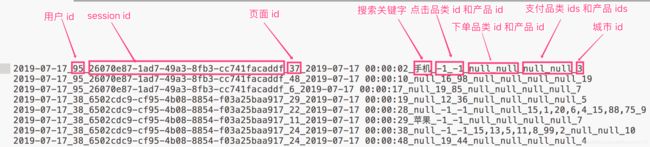
数据说明:
- 数据采用_分割字段
- 每一行表示用户的一个行为, 所以每一行只能是四种行为中的一种.
- 如果搜索关键字是 null, 表示这次不是搜索
- 如果点击的品类 id 和产品 id 是 -1 表示这次不是点击
- 下单行为来说一次可以下单多个产品, 所以品类 id 和产品 id 都是多个, id 之间使用逗号,分割. 如果本次不是下单行为, 则他们相关数据用null来表示
- 支付行为和下单行为类似.
1 需求1
按照每个品类的 点击、下单、支付 的量来统计热门品类的top10.
1.1思路:
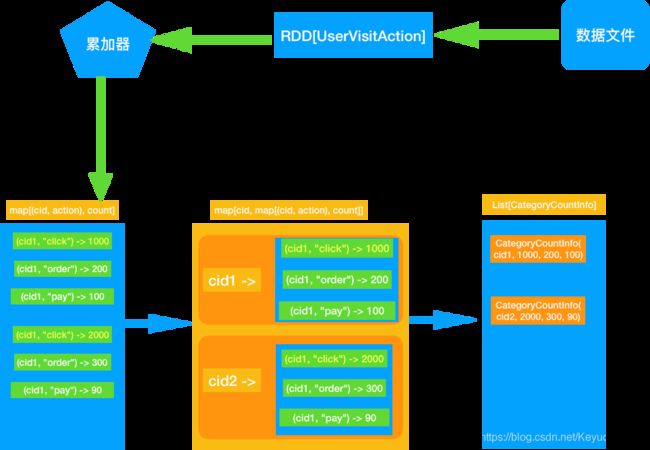
最好的办法应该是遍历一次能够计算出来上述的 3 个指标.
1)使用累加器可以达成我们的需求.
2)遍历全部日志数据, 根据品类 id 和操作类型分别累加. 需要用到累加器
3)定义累加器
4)当碰到订单和支付业务的时候注意拆分字段才能得到品类 id
5)遍历完成之后就得到每个每个品类 id 和操作类型的数量.
6)按照点击下单支付的顺序来排序
7)取出 Top10
1.2 具体实现
1.2.1 封装用户行为的bean类
/**
* 用户访问动作表
*
* @param date 用户点击行为的日期
* @param user_id 用户的ID
* @param session_id Session的ID
* @param page_id 某个页面的ID
* @param action_time 动作的时间点
* @param search_keyword 用户搜索的关键词
* @param click_category_id 某一个商品品类的ID
* @param click_product_id 某一个商品的ID
* @param order_category_ids 一次订单中所有品类的ID集合
* @param order_product_ids 一次订单中所有商品的ID集合
* @param pay_category_ids 一次支付中所有品类的ID集合
* @param pay_product_ids 一次支付中所有商品的ID集合
* @param city_id 城市 id
*/
case class UserVisitAction(date: String,
user_id: Long,
session_id: String,
page_id: Long,
action_time: String,
search_keyword: String,
click_category_id: Long,
click_product_id: Long,
order_category_ids: String,
order_product_ids: String,
pay_category_ids: String,
pay_product_ids: String,
city_id: Long)
case class CategoryCountInfo(categoryId: String,
clickCount: Long,
orderCount: Long,
payCount: Long)
1.2.2 定义累加器
import org.apache.spark.util.AccumulatorV2
import scala.collection.mutable
class MyAccumulator extends AccumulatorV2[(String, String), mutable.Map[(String, String), Long]]{
//定义返回的map类型
val map: mutable.Map[(String, String), Long] = mutable.Map[(String, String), Long]()
//当前累加器是否为初始状态,如果map是空的则为初始状态
override def isZero: Boolean = map.isEmpty
override def copy(): AccumulatorV2[(String, String), mutable.Map[(String, String), Long]] = {
val accumulator = new MyAccumulator
map.synchronized(
accumulator.map ++= map
)
accumulator
}
//重置累加器
override def reset(): Unit = map.clear()
//为累加器添加元素
override def add(v: (String, String)): Unit = {
map(v) = map.getOrElse(v, 0L) + 1
}
//合并累加器,因为累加器的副本要发给集群的每个Executor,所以最后要在Driver合并
override def merge(other: AccumulatorV2[(String, String), mutable.Map[(String, String), Long]]): Unit = {
val map1: mutable.Map[(String, String), Long] = other.value
map1.map(kv => map.put(kv._1,map.getOrElse(kv._1,0L)+kv._2))
}
//返回累加器的值,就是map
override def value: mutable.Map[(String, String), Long] = map
}
1.2.3 程序入口
import com.chen.spark.core.UserVisitAction
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DriverApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("DriverApp").setMaster("local[2]")
val sc = new SparkContext(conf)
//获取rdd
val lines: RDD[String] = sc.textFile("F:\\workplace_test\\spark-core\\user_visit_action.txt")
//处理数据
val userVisitActionRdd: RDD[UserVisitAction] = lines.map {
line =>
val splits: Array[String] = line.split("_")
UserVisitAction(
splits(0),
splits(1).toLong,
splits(2),
splits(3).toLong,
splits(4),
splits(5),
splits(6).toLong,
splits(7).toLong,
splits(8),
splits(9),
splits(10),
splits(11),
splits(12).toLong
)
}
//需求1:求每个商品类的热门top10
val countInfoes = CategoryTop10App.statCategoryTop10(sc, userVisitActionRdd)
countInfoes.foreach(println)
//关闭sc
sc.stop()
}
}
1.2.4 需求1方法实现
import com.chen.spark.core.{CategoryCountInfo, UserVisitAction}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import scala.collection.mutable
object CategoryTop10App {
def statCategoryTop10(sc: SparkContext, userVisitActionRDD: RDD[UserVisitAction]): List[CategoryCountInfo] = {
//1 获取累加器并完成注册
val acc: MyAccumulator = new MyAccumulator
sc.register(acc)
//2 根据userVisitActionRDD算子进行分类
userVisitActionRDD.foreach{
uva => {
if(uva.click_category_id != -1){
acc.add(uva.click_category_id.toString,"click")
}else if(uva.order_category_ids != "null"){
uva.order_category_ids.split(",").foreach{
order => acc.add(order.toString,"order")
}
}else if(uva.pay_category_ids != "null"){
uva.pay_category_ids.split(",").foreach{
pay => acc.add(pay.toString,"pay")
}
}
}
}
//3 遍历完成之后就得到每个品类 id 和操作类型的数量. 然后按照 CategoryId 进行进行分组
val accCountByCategoryIdMap: Map[String, mutable.Map[(String, String), Long]] = acc.value.groupBy(_._1._1)
//4 转换到CategoryCountInfo类并转换为list(方便排序)
val result: List[CategoryCountInfo] = accCountByCategoryIdMap.map {
case (cid, acc) => {
CategoryCountInfo(
cid,
acc.getOrElse((cid, "click"), 0L),
acc.getOrElse((cid, "order"), 0L),
acc.getOrElse((cid, "pay"), 0L)
)
}
}.toList
//5 排序并取前10条结果
val top10: List[CategoryCountInfo] = result.sortBy(x => (-x.clickCount, -x.orderCount, -x.payCount)).take(10)
//6 返回结果
top10
}
}
1.2.5 输出结果:热门的top10商品类

2 需求2:
对于排名前 10 的品类,分别获取每个品类点击次数排名前 10 的 sessionId。(注意: 这里我们只关注点击次数, 不关心下单和支付次数)
这个就是说,对于 top10 的品类,每一个都要获取对它点击次数排名前 10 的 sessionId。
这个功能,可以让我们看到,对某个用户群体最感兴趣的品类,各个品类最感兴趣最典型的用户的 session 的行为。
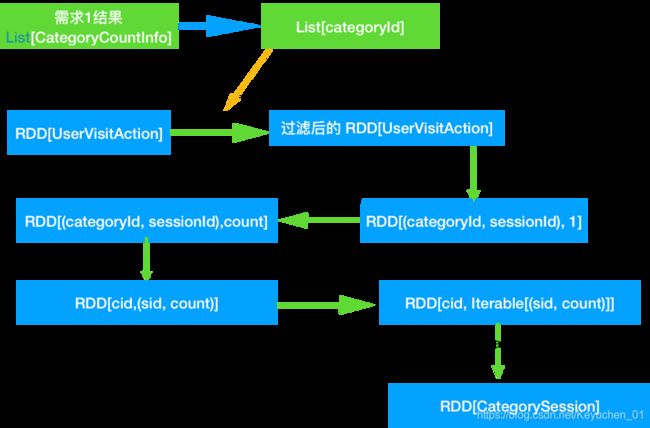
2.1思路
- 过滤出来 category Top10的日志
- 需要用到需求1的结果, 然后只需要得到categoryId就可以了
- 转换结果为 RDD[(categoryId, sessionId), 1] 然后统计数量 => RDD[(categoryId, sessionId), count]
- 统计每个品类 top10. => RDD[categoryId, (sessionId, count)] => RDD[categoryId, Iterable[(sessionId, count)]]
- 对每个 Iterable[(sessionId, count)]进行排序, 并取每个Iterable的前10
- 把数据封装到 CategorySession 中
2.2代码实现
2.2.1bean类
case class CategorySession(categoryId: String,
sessionId: String,
clickCount: Long)
2.2.2 具体实现
import com.chen.spark.core.{CategoryCountInfo, CategorySession, UserVisitAction}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object CategorySessionAPP {
def statCategoryTop10Session(sc: SparkContext, userVisitActionRDD: RDD[UserVisitAction], categoryTop10: List[CategoryCountInfo]) = {
//1 根据categoryTop10获取热门top10的品类id
val categoryIdTop10: List[String] = categoryTop10.map(_.categoryId)
//2 过滤userVisitActionRDD其他不符合要求的clickid
val filteredUserVisitActionRDD: RDD[UserVisitAction] = userVisitActionRDD.filter(uva => categoryIdTop10.contains(uva.click_category_id.toString))
//3 根据top10的品类id得到对应的sessionid并计数((cid,sid),1)
val categorySessionOne: RDD[((Long, String), Int)] = filteredUserVisitActionRDD.map {
uva => {
((uva.click_category_id, uva.session_id), 1)
}
}
//4 转换输出结果((cid,sid),1)=>((cid,sid),count)=>(cid,(sid,count))
val categorySessionCount: RDD[(Long, (String, Int))] = categorySessionOne.reduceByKey(_ + _).map {
x => (x._1._1.toLong, (x._1._2, x._2))
}
//5 按cid分组
val categorySessionGroup: RDD[(Long, Iterable[(String, Int)])] = categorySessionCount.groupByKey
//6 排序取前10条记录并封装到CategorySession类中
val categorySessionRDD: RDD[CategorySession] = categorySessionGroup.flatMap{
case (cid,it) => {
//转换成list集合进行排序
val list: Seq[(String, Int)] = it.toList.sortBy(x => -x._2).take(10)
//封装
val result: Seq[CategorySession] = list.map {
case (sid, count) => CategorySession(cid.toString, sid, count)
}
result
}
}
//7 获取结果
categorySessionRDD.foreach(println)
}
}
2.2.3 特别说明:
上面的操作中, 有一个操作是把迭代器中的数据转换成List之后再进行排序, 这里存在内存溢出的可能. 如果迭代器的数据足够大, 当转变成 List 的时候, 会把这个迭代器的所有数据都加载到内存中, 所以有可能造成内存的溢出。
前面的排序是使用的 Scala 的排序操作, 由于 scala 排序的时候需要把数据全部加载到内存中才能完成排序, 所以理论上都存在内存溢出的风险.
如果使用 RDD 提供的排序功能, 可以避免内存溢出的风险, 因为 RDD 的排序需要 shuffle, 是采用了内存+磁盘来完成的排序.
2.2.4 解决方案一:
使用 RDD 的排序功能, 但是由于 RDD 排序是对所有的数据整体排序, 所以一次只能针对一个 CategoryId 进行排序操作.
代码如下:
import com.chen.spark.core.{CategoryCountInfo, CategorySession, UserVisitAction}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object CategorySessionAPP2 {
def statCategoryTop10Session(sc: SparkContext, userVisitActionRDD: RDD[UserVisitAction], categoryTop10: List[CategoryCountInfo]) = {
//1 根据categoryTop10得到cid
val categoryIdTop10: List[String] = categoryTop10.map(_.categoryId)
//2 过滤userVisitActionRDD其他不符合要求的clickid
val filteredUserVisitActionRDD: RDD[UserVisitAction] = userVisitActionRDD.filter(uva => categoryIdTop10.contains(uva.click_category_id.toString))
//3 根据top10的品类id得到对应的sessionid并计数((cid,sid),1)
val categorySessionOne: RDD[((Long, String), Int)] = filteredUserVisitActionRDD.map {
uva => {
((uva.click_category_id, uva.session_id), 1)
}
}
//4 转换输出结果((cid,sid),1)=>((cid,sid),count)=>(cid,(sid,count))
val categorySessionCount: RDD[(Long, (String, Int))] = categorySessionOne.reduceByKey(_ + _).map {
(x => (x._1._1, (x._1._2, x._2)))
}
//5 每次过滤cid进行排序
categoryIdTop10.foreach{
cid => {
// 针对某个具体的 CategoryId, 过滤出来只包含这个CategoryId的RDD, 然后整体降序排列
val top10: Array[CategorySession] = categorySessionCount.filter(_._1 == cid.toLong).sortBy(x => x._2._2,false).take(10).map{
case(cid,(sid,count)) => CategorySession(cid.toString,sid,count)
}
top10.foreach(println)
}
}
}
}
2.2.5 解决方案二
方案 1 解决了内存溢出的问题, 但是也有另外的问题: 提交的 job 比较多, 有一个品类 id 就有一个 job, 在本案例中就有了 10 个 job.
有没有更加好的方案呢?
可以把同一个品类的数据都进入到同一个分区内, 然后对每个分区的数据进行排序!
需要用到自定义分区器.
2.2.6 自定义分区器
import org.apache.spark.Partitioner
class Mypartitions(categoryIdTop10: List[String]) extends Partitioner{
// 给每个 cid 配一个分区号(使用他们的索引就行了)
private val cidAndIndex: Map[String, Int] = categoryIdTop10.zipWithIndex.toMap
override def numPartitions: Int = cidAndIndex.size
override def getPartition(key: Any): Int = {
key match {
case (cid,_) => cidAndIndex(cid.toString)
}
}
}
2.2.7 bean类修改
ase class CategorySession2(categoryId: String,
sessionId: String,
clickCount: Long)extends Ordered[CategorySession2]{
override def compare(that: CategorySession2): Int = {
if(this.clickCount <= that.clickCount) 1
else -1
}
}
2.2.8 代码
import com.chen.spark.core.{CategoryCountInfo, CategorySession, CategorySession2, UserVisitAction}
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import scala.collection.mutable
object CategorySessionAPP3 {
def statCategoryTop10Session(sc: SparkContext, userVisitActionRDD: RDD[UserVisitAction], categoryTop10: List[CategoryCountInfo]) = {
//1 根据categoryTop10得到cid
val categoryIdTop10: List[String] = categoryTop10.map(_.categoryId)
//2 过滤userVisitActionRDD其他不符合要求的clickid
val filteredUserVisitActionRDD: RDD[UserVisitAction] = userVisitActionRDD.filter(uva => categoryIdTop10.contains(uva.click_category_id.toString))
//3 根据top10的品类id得到对应的sessionid并计数((cid,sid),1)
val categorySessionOne: RDD[((Long, String), Int)] = filteredUserVisitActionRDD.map {
uva => {
((uva.click_category_id, uva.session_id), 1)
}
}
//4 转换输出结果((cid,sid),1)=>((cid,sid),count)
val categorySessionCount: RDD[CategorySession2] = categorySessionOne.reduceByKey(new Mypartitions(categoryIdTop10), _ + _).map{
case((cid,sid),count) => CategorySession2(cid.toString,sid,count)
}
//6 排序取前10条记录并封装到CategorySession类中
val categorySessionRDD: RDD[CategorySession2] = categorySessionCount.mapPartitions(it => {
// 这个时候也不要把 it 变化 list 之后再排序, 否则仍然会有可能出现内存溢出.
// 我们可以把数据存储到能够自动排序的集合中 比如 TreeSet 或者 TreeMap 中, 并且永远保持这个集合的长度为 10
// 让TreeSet默认按照 count 的降序排列, 需要让CategorySession实现 Ordered 接口(Comparator)
var top10: mutable.TreeSet[CategorySession2] = mutable.TreeSet[CategorySession2]()
it.foreach(cs => {
// 把 CategorySession 添加到 TreeSet 中
top10 += cs
if (top10.size > 10) {
// 如果 TreeSet 的长度超过 10, 则移除最后一个
top10 = top10.take(10)
}
})
top10.toIterator
})
//7 取结果
categorySessionRDD.foreach(println)
}
}
执行结果:


3 需求3
3.1 页面单跳转化率统计
计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳,那么单跳转化率就是要统计页面点击的概率
比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV)为 A,然后获取符合条件的 Session 中访问了页面 3 又紧接着访问了页面 5 的次数为 B,那么 B/A 就是 3-5 的页面单跳转化率.

3.2 思路
- 读取到规定的页面
- 过滤出来规定页面的日志记录, 并统计出来每个页面的访问次数 countByKey 是行动算子 reduceByKey 是转换算子
- 明确哪些页面需要计算跳转次数 1-2, 2-3, 3-4 …
- 按照 session 统计所有页面的跳转次数, 并且需要按照时间升序来排序
- 按照 session 分组, 然后并对每组内的 UserVisitAction 进行排序
- 转换访问流水
- 过滤出来和统计目标一致的跳转
- 统计跳转次数
- 计算跳转率

3.3具体实现
import java.text.DecimalFormat
import com.chen.spark.core.UserVisitAction
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object PageConversionApp {
def calcPageConversion(sc: SparkContext, userVisitActionRDD: RDD[UserVisitAction], targetPageFlow: String) = {
//1 根据传入的targetPageFlow获取需要访问的page
val pageFlowArr: Array[String] = targetPageFlow.split(",")
val prePageArr: Array[String] = pageFlowArr.slice(0, pageFlowArr.length - 1)
val postPageArr: Array[String] = pageFlowArr.slice(1, pageFlowArr.length)
//2 过滤userVisitActionRDD中只包含pageFlowArr的内容,并求出count(n)
val targetPageCount: collection.Map[Long, Long] = userVisitActionRDD.filter(uva => pageFlowArr.contains(uva.page_id.toString)).map(x => (x.page_id, 1)).countByKey()
//3 得到要求的跳转页面
val targetPage: Array[String] = prePageArr.zip(postPageArr).map(x => (x._1 + "-" + x._2))
//4 按照session_id分组并按action_time时间排序,并过滤只包含targetPage的页面
// 4.1 按照 session 分组, 然后并对每组内的 UserVisitAction 进行排序
val pageJumpRDD: RDD[String] = userVisitActionRDD.groupBy(_.session_id).flatMap {
case (sid, it) => {
// 4.2 转换访问流水
val pages: List[UserVisitAction] = it.toList.sortBy(_.action_time)
val prepages: List[UserVisitAction] = pages.slice(0, pages.length - 1)
val postpages: List[UserVisitAction] = pages.slice(1, pages.length)
// 4.3 过滤出来和统计目标一致的跳转
prepages.zip(postpages).map(x=>(x._1.page_id+"-"+x._2.page_id)).filter(targetPage.contains(_))
}
}
//5 统计出count(n-m)
val pageJumpCount: Array[(String, Int)] = pageJumpRDD.map(x => (x, 1)).reduceByKey(_+_).collect()
//6 设置格式
val formatter = new DecimalFormat(".00%")
//7 计算
val result: Array[(String, String)] = pageJumpCount.map{
case (p2p,jumpcount) => {
val countn: Long = targetPageCount.getOrElse(p2p.split("-").head.toLong, 0L)
val rate: String = formatter.format(jumpcount.toDouble / countn)
(p2p,rate)
}
}
//8 遍历结果
result.foreach(println)
}
}
3.4执行

