基于Spark的电商用户行为实时分析可视化系统(Flask-SocketIO)
基于Spark的电商用户行为实时分析可视化系统(Flask-SocketIO)
- 项目简介
-
- 一、业务需求分析
- 二、系统流程及架构
- 三、系统技术版本以及相关部署配置
- 四、系统具体实施
- 五、系统运行
项目简介
由于做毕设之前学过大数据,但是一直没有做过一整套的实时数据分析系统,有点遗憾。所以毕业设计就自主选了这一套系统,算是对之前知识进行一次整合运行,也挑战一下自己。
该系统主要对用户行为日志(此项目使用的数据源是数据集,可以根据自己需求,在数据采集时监控网站用户数据存放目录或者用爬虫实时爬取数据的存放目录)进行实时分析可视化。
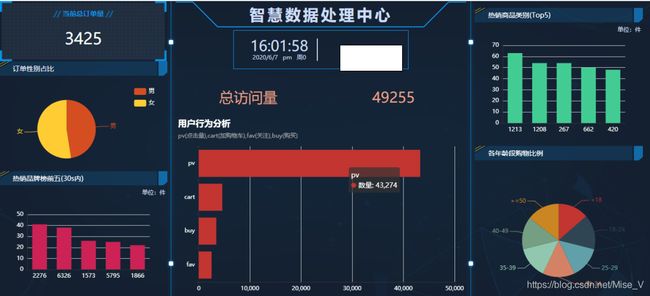
先放最终系统成果,才有耐心看下面的内容!!!
一、业务需求分析
- 采集用户行为日志数据;
- 实时分析数据(例如实时总订单、男女购物比例、用户各类行为分析、每段时间内最受欢迎的商品品牌、各年龄段购物比例等);
- 实时数据结果存储(将需要的结果数据存储到目标数据库);
- 数据可视化(将实时分析出的结果数据进行数据可视化);
二、系统流程及架构
登录系统后,通过日志采集模块来采集目标日志数据,将采集到的数据发送给日志传输模块,数据存放于kafka对应的topic中;数据处理模块创建与kafka的连接,消费对应topic中的数据,对数据进行预处理之后再进行处理分析,处理所得的结果数据存放进对应各topic中,以便于数据可视化,同时也将结果数据存入Redis数据库,便于后期其他功能分析使用。最后通过可视化模块,后台使用Flask作为Web框架,前端使用H5+Echarts,将结果数据进行可视化。系统流程图如图所示:
系统相关技术和组件:
Hadoop、Spark、Flume、Kafka、Zookeeper、Flask、SocketIO、Echarts、Scala、Python。项目架构如图所示: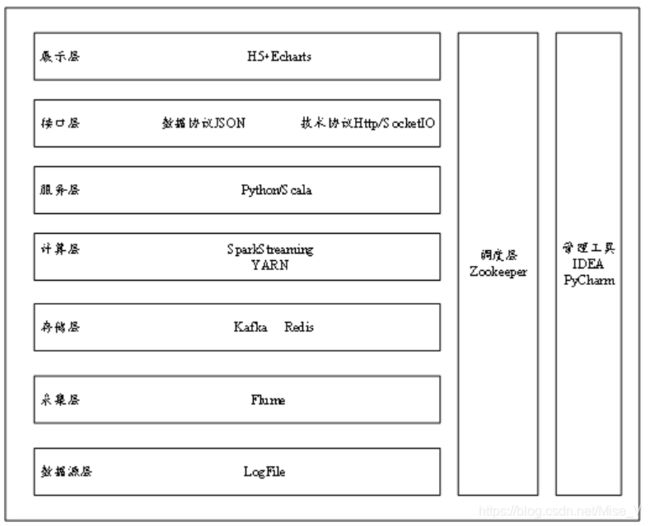
三、系统技术版本以及相关部署配置
此项目由于计算机硬件配置较低,所以采用Hadoop伪分布式集群(部署在虚拟机的linux系统上用于存放源数据和程序检查点)和单机Spark集群(部署在本地windows上)
1.Hadoop2.9.2
伪分布式搭建参考(此项目) https://blog.csdn.net/xujingran/article/details/83898140
全分布式搭建参考 https://blog.csdn.net/u011254180/article/details/77922331
2.Flume1.9.0
搭建参考 https://blog.csdn.net/caodaoxi/article/details/8885645
Flume作为kafka的sink的配置文件: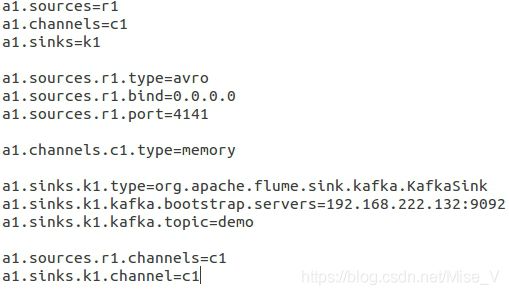
3.Kafka2.4.0
伪分布式搭建参考(此) https://blog.csdn.net/weixin_42207486/article/details/80635246
全分布式搭建参考 https://blog.csdn.net/qq_39211575/article/details/103677016
5.Spark2.4.4
Windows单机搭建参考(此) https://blog.csdn.net/Python_Big_love/article/details/81878142
6.Zookeeper3.5.6
伪分布式搭建参考(此项目)https://blog.csdn.net/MISSRIVEN/article/details/81394595
全分布式搭建参考 https://blog.csdn.net/sjhuangx/article/details/81155501
7.flask(系统Web框架)
安装参考 https://blog.csdn.net/cckavin/article/details/90766924
注意!!!
在本地(windows)Spark集群中编写SparkStreaming程序的时候,引入maven配置信息中(此项目依赖如下),scala、kafka、Spark-Streaming-kafka的版本都需要一致,高版本低版本都不行。
本系统使用scala版本为2.11、spark版本为2.4.4(此版本也有scala2.12编写版)、kafka版本为2.4.0(spark-streaming-kafka0.8最高支持kafka2.3.0以下版本,所以此项目使用0.10版本)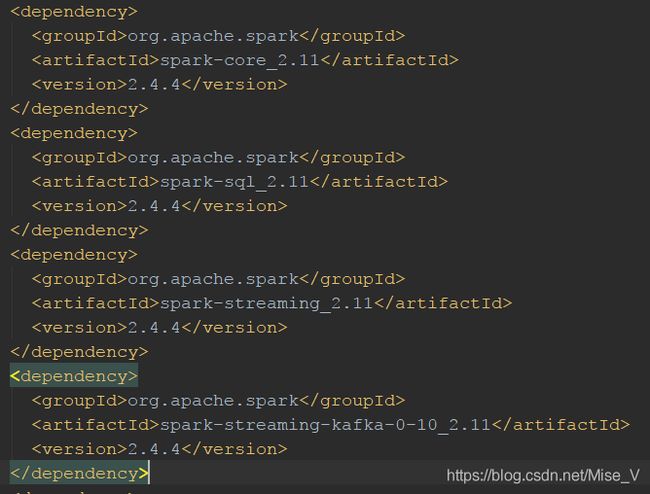

此外spark-streaming-kafka0.8和0.10在连接kafka时有差别,网上搜的两种连接分别为Receiver DStream和Direct DStream,但是0.10版本取消了Receiver DStream,所以只能用后面一种,而且创建实时数据流代码网上示例很多都过时了,需要用以下官网最新连接代码。(读取kafka数据会报序列化错误,需要注册序列化方式,以下代码中已加入Kryo序列化方式)
//构建conf ssc 对象
val conf = new SparkConf().
setAppName("Kafka_director").
setMaster("local[2]").
set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(
classOf[Array[org.apache.kafka.clients.consumer.ConsumerRecord[String,String]]]
))
val sc:SparkContext=new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(3))
//设置数据检查点
ssc.checkpoint("hdfs://192.168.222.132:9000/checkpoint")
//kafka 需要Zookeeper 需要消费者组
val topics = Set("demo")
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "192.168.222.132:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "g1",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val data = KafkaUtils.createDirectStream(
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
四、系统具体实施
- 集群部署和启动
此处为Hadoop、Zookeeper、Flume以及Kafka整体启动。
启动Hadoop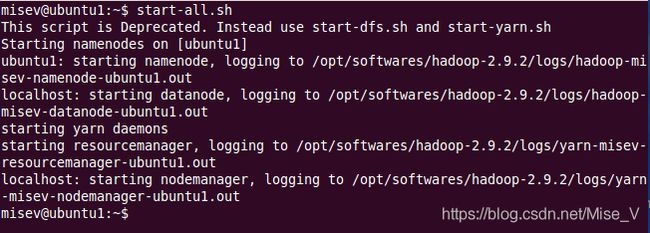
启动Zookeeper
加载flume的sink配置文件
启动flume的采集端(采集本地文件)
- 用户登录:在flask框架中自己添加即可
- 数据处理和结果数据存储
kafka中各个topic以及对应用处
| topic | 用处 |
|---|---|
| demo | 接受源数据 |
| ordernumall | 总订单数 |
| ordernumgender | 男女购物人数 |
| behavior | pv+buy+cart+fav |
| visitnum | 总访问量 |
| ordernumage | 各年龄段购物人数 |
| ordernumbrandtop | 各品牌销量 |
| ordernumcattop | 各商品类别销量 |
| ordernumregion | 各地区订单量 |
创建kafka连接,用于消费目标topic中的数据,创建kafka生产者发送结果数据到对应的topic。设立检查点。
//构建conf ssc 对象
val conf = new SparkConf().
setAppName("Kafka_director").
setMaster("local[2]").
set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
conf.registerKryoClasses(Array(
classOf[Array[org.apache.kafka.clients.consumer.ConsumerRecord[String,String]]]
))
val sc:SparkContext=new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(3))
//设置数据检查点
ssc.checkpoint("hdfs://192.168.222.132:9000/checkpoint")
//kafka 需要Zookeeper 需要消费者组
val topics = Set("demo")
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "192.168.222.132:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "g1",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val data = KafkaUtils.createDirectStream(
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams))
//kafka生产者(将处理好的数据结果传回给kafka)
val kafkaProducer: Broadcast[KafkaSink[String, String]] = {
val kafkaProducerConfig = {
val p = new Properties()
p.setProperty("bootstrap.servers", "192.168.222.132:9092")
p.setProperty("key.serializer", classOf[StringSerializer].getName)
p.setProperty("value.serializer", classOf[StringSerializer].getName)
p
}
sc.broadcast(KafkaSink[String, String](kafkaProducerConfig))
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
Redis工具类创建
package BeAnalysis.controller
import org.apache.commons.pool2.impl.GenericObjectPoolConfig
import redis.clients.jedis.JedisPool
object RedisClient extends Serializable {
val redisHost = "127.0.0.1"
val redisPort = 6379
val redisTimeout = 30000
lazy val pool = new JedisPool(
new GenericObjectPoolConfig(),
redisHost,
redisPort,
redisTimeout)
lazy val hook = new Thread {
override def run = {
println("Execute hook thread: " + this)
pool.destroy()
}
}
sys.addShutdownHook(hook.run)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
数据预处理,编写用户信息类(此处用户类类型设置有点粗糙,可以自行改正)和累加函数。
//统计结果
val result = data.map(_.value()).map(
line=>{
val record=line.split(",")
if(record(8).equals("0")||record(8)==null)record(8)="9"
if(record(9).equals("2")||record(9)==null)record(9)="3"
UserBehavior(
record(0),//买家id
record(1),//商品id
record(2),//商品类别id
record(3),//卖家id
record(4),//品牌id
record(5),//月份
record(6),//日数
record(7),//行为
record(8),//年龄段
record(9),//性别
record(10)//省份
)
})
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
用户信息类
class UserBehavior(
user_id: String,//买家id
item_id: String,//商品id
cat_id: String,//商品类别id
merchant_id: String,//卖家id
brand_id: String,//品牌id
month: String,//月份
day: String,//天数
act: String,//行为,,取值范围{0,1,2,3},0表示点击,1表示加入购物车,2表示购买,3表示关注商品
age_range: String,//买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
gender: String,//性别:0表示女性,1表示男性,2和NULL表示未知
province: String //收货地址省份
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
累加函数
val updateFunc =(curVal:Seq[Int],preVal:Option[Int])=>{
//进行数据统计当前值加上之前的值
var total = curVal.sum
//最初的值应该是0
var previous = preVal.getOrElse(0)
//Some 代表最终的但会值
Some(total+previous)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
过滤出用户行为为购买的数据,保存中间结果,对订单数进行累计统计,将结果数据实时放入对应的topic中。
//2.总订单数
//redis数据库号
val orderAllindex=2;
//设置redis的key
val orderKey = "orderKey"
val order_all=result.
filter(_.act.equals("2")).
map(be=>("ordernum_all",1)).
updateStateByKey(updateFunc).
transform(rdd=>{
rdd.foreach(record => {
val jedis = RedisClient.pool.getResource
jedis.select(orderAllindex);
jedis.hincrBy(orderKey,record._1.toString,record._2);
RedisClient.pool.returnResource(jedis);
kafkaProducer.value.
send("ordernumall",s"${record._1}:${record._2}")
})
rdd
}).print()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
过滤出用户行为为购买的数据,使用滑动窗口和topN,对各品牌销售量进行窗口统计,将结果数据实时放入对应的topic中。
val regionCount_brand_top=result.
filter(_.brand_id.length>=1).
filter(_.act.equals(("2"))).
map(be=>(be.brand_id,1)).
reduceByKeyAndWindow(
(v1:Int,v2:Int)=>v1+v2,
Seconds(30),//30秒滑动窗口
Seconds(15))//15秒刷新一次
val BrandtopNSort = regionCount_brand_top.transform(searchWordCountsRDD => {
val countSearchBrandRDD = searchWordCountsRDD.map(tuple => (tuple._2, tuple._1))
val sortedCountSearchBrandRDD = countSearchBrandRDD.sortByKey(false)
val sortedSearchBrandCountsRDD = sortedCountSearchBrandRDD.map(tuple => (tuple._1, tuple._2))
val top10SearchBrand = sortedSearchBrandCountsRDD.take(5)
for(tuple <- top10SearchBrand) {
kafkaProducer.value.send("ordernumbrandtop",s"${tuple._2}:${tuple._1}")
//println("top"+tuple)
}
searchWordCountsRDD
})
BrandtopNSort.print()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
其他功能都相似,就不一一列出。
数据处理部分流程图如图所示: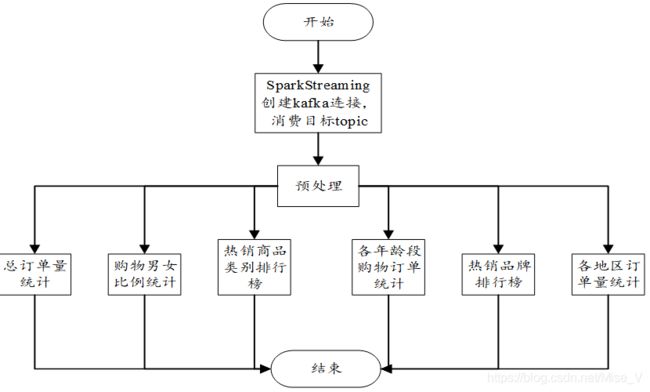
4. 数据可视化(Flask框架)
页面各数据展示显示类型
| 功能 | 显示类型 |
|---|---|
| 总订单数统计 | 页面标签 |
| 男女购物比例统计 | 饼图 |
| 各年龄段购物比例统计 | 饼图 |
| 热销品牌统计 | 柱状图 |
| 热销商品类别统计 | 柱状图 |
| 用户各行为分析 | 柱状图 |
| 系统时间 | 页面标签 |
| 总订单数 | 页面标签 |
获取kakfa对应的topic节点进行数据消费。
# 获取kafka中的ordernumall节点 (总订单数)
consumer1 = KafkaConsumer('ordernumall', bootstrap_servers=['192.168.222.132:9092'])
# 获取kafka中的ordernumgender节点 (购物男女数)
consumer2 = KafkaConsumer('ordernumgender', bootstrap_servers=['192.168.222.132:9092'])
- 1
- 2
- 3
- 4
- 5
编写flask视图函数中调用的回调函数(商品类别排行)
def background_thread6():
all_ = ""
flag = 0
for msg in consumer6:
data_json = msg.value.decode('utf8')
all_ = all_+","+data_json
flag = flag + 1
if flag % 5 == 0:
socketio.emit('ordernum_cattop_web', {'data': all_.lstrip(",")})
all_ = ""
flag = 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
商品类别排行的视图函数
# 商品类别topN视图函数,被js调用
@socketio.on('ordernum_cattop_back')
def connect(message):
print(message)
socketio.start_background_task(target=background_thread6)
socketio.emit('connected6', {'data': 'ordernum_cattop_back'})
- 1
- 2
- 3
- 4
- 5
- 6
创建SocketIO对象,并初始化
//创建socket对象
let socket = io.connect('http://' + document.domain + ':' + location.port);
//调用后台初始化连接
socket.on('connect', function () {
//总订单数(总购买量)
socket.emit('ordernum_all_back', {data: '总订单数连接正常!'});
//购物性别比例
socket.emit('ordernum_gender_back', {data: '总订单数(性别)连接正常!'});
//总访问量
socket.emit('visitnum_back',{data:'总访问量连接正常'});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
JS代码中处理flask中回调函数发送过来的数据(商品类别排行),同时进行Echarts绘图
//6.topN商品类别
var data_cattop = [
{name: "衣服", value : 0},
{name: "电脑", value : 0},
{name: "手机", value : 0},
{name: "日用品", value : 0},
{name: "家纺", value : 0}
];
socket.on('ordernum_cattop_web',function (message) {
var dataall=message.data.split(",");
var data;
var Flagdata=data_cattop;
for(var i=0;i- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
五、系统运行
- 启动hadoop start-all.sh
- 启动Zookeeper zkServer.sh start
- 启动kafka kafka-server-start.sh /opt/links/kafka/conf/servers.properties
- 配置kafka作为flume的sink flume-ng agent -f /home/misev/bigdata/flume/agents/b.flm -n a1 -c
/opt/links/flume/conf/ - 配置启动flume采集数据 flume-ng avro-client -H 192.168.222.132 -p 4141 -F /etc/passwd
- 启动本地Spark程序(windows环境下,由于硬件不支持在虚拟机中启动)
- 启动flask程序 运行效果开始已给出。