基于Spark的证券公司仪表板实现
基于Spark的证券公司仪表板实现
- 一、业务场景
- 二、数据集说明
- 三、操作步骤
-
- 阶段一、启动HDFS、Spark集群服务
- 阶段二、准备案例中用到的数据监控目录
- 阶段三、处理实时数据
申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址
全文共计4227字,阅读大概需要3分钟
一、业务场景
现应某证券公司要求,应用Spark流处理技术,为该公司开发一套实时显示股票信息的仪表盘系统,用来实时统计每秒钟买卖股票的数量。
二、数据集说明
本案例用到的实时数据说明如下:
- 原始数据文件位于本地/data/dataset/streaming/orders.txt
- 脚本文件位于本地/data/dataset/streaming/splitAndSend.sh
- 通过运行splitAndSend.sh脚本,读取orders.txt数据并发送到HDFS的/data/dataset/orders-input/目录下,形成实时数据流,然后由Spark流处理程序处理在该目录下到达的流数据。
orders.txt文件中共有500,000行,代表买卖订单。这些数据是随机生成的。每一行包含如下用逗号分隔的元素:
■ Order时间戳 — 格式为yyyy-mm-dd hh:MM :ss
■ Order ID — 连续递增的整数
■ Client ID — 从1到100的范围随机选取整数
■ Stock代码 — 从80个股票符号的列表中随机抽取
■ 股票买卖的数量 — 从1到1000中的随机数字
■ 股票买卖的价格 — 从1到100中的随机数字
■ 字符B 或 S — 代表一个订单的买(B)/卖(S)事件
以可使用如下命令查看文件的前5行内容:
1. head -n 5 /data/dataset/streaming/orders.txt
内容如下所示:
1. 2016-03-22 20:25:28,1,80,EPE,710,51.00,B
2. 2016-03-22 20:25:28,2,70,NFLX,158,8.00,B
3. 2016-03-22 20:25:28,3,53,VALE,284,5.00,B
4. 2016-03-22 20:25:28,4,14,SRPT,183,34.00,B
5. 2016-03-22 20:25:28,5,62,BP,241,36.00,S
三、操作步骤
阶段一、启动HDFS、Spark集群服务
1、启动HDFS集群
在Linux终端窗口下,输入以下命令,启动HDFS集群:
1. $ start-dfs.sh
2、启动Spark集群
在Linux终端窗口下,输入以下命令,启动Spark集群:
1. $ cd /opt/spark
2. $ ./sbin/start-all.sh
3、验证以上进程是否已启动
在Linux终端窗口下,输入以下命令,查看启动的服务进程:
1. $ jps
如果显示以下5个进程,则说明各项服务启动正常,可以继续下一阶段。
1. 2288 NameNode
2. 2402 DataNode
3. 2603 SecondaryNameNode
4. 2769 Master
5. 2891 Worker
阶段二、准备案例中用到的数据监控目录
1、在HDFS上创建实时数据流监控目录。在Linux终端窗口下,输入以下命令:
1. $ hdfs dfs -mkdir -p /data/dataset/orders-input
2. $ hdfs dfs -mkdir -p /tmp/streaming
2、在Linux终端窗口下,输入以下命令,查看HDFS上是否已经有了orders-input目录:
1. $ hdfs dfs -ls /data/dataset/orders-input
这时应该看到该目录下目前为空。
阶段三、处理实时数据
1、启动spark shell。在Linux终端窗口中,输入以下命令:(注意,请将命令中的localhost替换为虚拟机实际的机器名)
1. spark-shell --master spark://localhost:7077
执行以上代码,进入到Spark Shell交互开发环境:

2、首先需要导入案例代码运行所依赖的包。在paste模式下,输入以下代码:
1. // 首先导入包
2. import org.apache.spark._
3. import org.apache.spark.streaming._
4. import java.sql.Timestamp
5. import java.text.SimpleDateFormat
同时按下【Ctrl + D】按键,执行以上代码,输出结果如下:

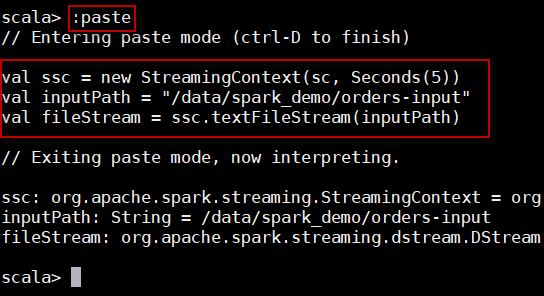
3、构造StreamingContext对象,读取流数据,构造DStream。在paste模式下,输入以下代码:
1. val ssc = new StreamingContext(sc, Seconds(5))
2. val inputPath = "/data/dataset/orders-input"
3. val fileStream = ssc.textFileStream(inputPath)
同时按下【 Ctrl + D】键,执行以上代码,输出结果如下:
4、构造一个case class,表示实时订单数据对象。在paste模式下,输入以下代码:
1. case class Order(time: java.sql.Timestamp,
2. orderId:Long,
3. clientId:Long,
4. symbol:String,
5. amount:Int,
6. price:Double,
7. buy:Boolean)
同时按下 【Ctrl + D】 键,执行以上代码,输出内容如下:

由以上输出内容可以看出,定义了一个case class叫Order。
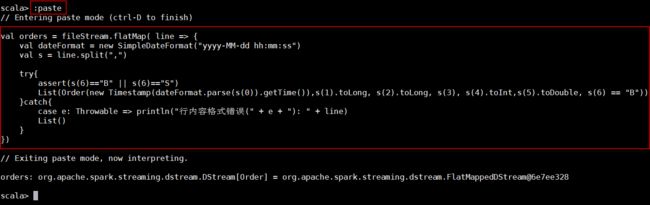
5、对接收到的实时数据进行格式处理和转换,包括日期格式解析。在paste模式下,输入以下代码:
1. val orders = fileStream.flatMap( line => {
2. val dateFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
3. val s = line.split(",")
4. try{
5. assert(s(6)=="B" || s(6)=="S")
6. List(Order(new Timestamp(dateFormat.parse(s(0)).getTime()),s(1).toLong, s(2).toLong, s(3), s(4).toInt,s(5).toDouble, s(6) == "B"))
7. }catch{
8. case e: Throwable => println("行内容格式错误(" + e + "): " + line)
9. List()
10. }
11. })
同时按下【Ctrl + D】 键,执行以上代码,输出内容如下:
6、计算每秒钟买卖股票的数量,并将结果保存到指定的位置。在paste模式下,输入以下代码:
1. val numPerType = orders.map(o => (o.buy, 1L))
2. .reduceByKey((c1,c2) => c1 + c2)
3. val resultPath = "/data/dataset/orders-output/result"
4. numPerType.repartition(1).saveAsTextFiles(resultPath, "txt")
5. numPerType.print()
同时按下 【Ctrl + D】 键,执行以上代码,输出内容如下:

7、启动刚ssc,监听实时流程序,并处理。在paste模式下,输入以下代码:
1. ssc.start()
同时按下 【Ctrl + D】 键,执行以上代码。
上面在spark-shell中执行的程序,一旦你输入ssc.start()以后,程序就开始自动进入循环监听状态,屏幕上会显示一堆的信息。

8、另打开一个终端窗口,命令行下执行如下命令:
1. $ cd /data/dataset/streaming
2. $ chmod +x splitAndSend.sh
3. $ ./splitAndSend.sh /data/dataset/orders-input
按下【Enter】键,执行以上代码。
9、回到第一个窗口(Spark流程序运行窗口),观察输出结果,如下所示:

在界面中会每秒钟输出股票买卖统计结果。其中true表示买入,false表示卖出。
10、在第一个终端窗口中,按下【Ctrl + C】键,终止程序执行。
或者,执行如下方法来停止:
1. ssc.stop(false)
— END —