【深度学习】GCN的dgl官方代码解读
来源:gcn官方代码实现:gcn_mp.py
以下主要是记录个人对官方代码的理解。
GCN:多层网络
由多层GCNLayer组成
class GCN(nn.Module):
def __init__(self,
g,
in_feats, # 输入特征维度
n_hidden, # 隐藏层特征维度
n_classes, # 输出维度(分类个数)
n_layers, # 层数,每一层是最基本的卷积操作
activation, # 激活函数
dropout):
super(GCN, self).__init__()
self.layers = nn.ModuleList()
# input layer
self.layers.append(GCNLayer(g, in_feats, n_hidden, activation, dropout))
# hidden layers
for i in range(n_layers - 1):
self.layers.append(GCNLayer(g, n_hidden, n_hidden, activation, dropout))
# output layer
self.layers.append(GCNLayer(g, n_hidden, n_classes, None, dropout))
def forward(self, features):
h = features
for layer in self.layers:
h = layer(h)
return h
GCNLayer:单层卷积网络
概览
其实就是执行这样一次操作:
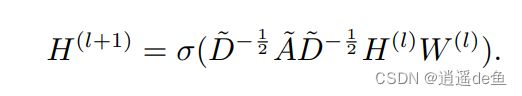
D ~ = D + I N \tilde{D}=D+I_N D~=D+IN, A ~ = A + I N \tilde{A}=A+I_N A~=A+IN, D D D为度矩阵(对角阵), A A A为邻接矩阵, I N I_N IN为单位矩阵。
H ( l ) H^{(l)} H(l)为第 l l l层的特征矩阵,维度 N × F l N\times F_l N×Fl
H ( l + 1 ) H^{(l+1)} H(l+1)为第 l + 1 l+1 l+1层的特征矩阵,维度 N × F l + 1 N\times F_{l+1} N×Fl+1
W ( l ) W^{(l)} W(l)第 l l l层的维度变换矩阵,维度 F l × F l + 1 F_l\times F_{l+1} Fl×Fl+1,矩阵乘法
class GCNLayer(nn.Module):
def __init__(self,
g,
in_feats,
out_feats,
activation,
dropout,
bias=True):
super(GCNLayer, self).__init__()
self.g = g
# 公式里的 W
self.weight = nn.Parameter(torch.Tensor(in_feats, out_feats))
if dropout:
self.dropout = nn.Dropout(p=dropout)
else:
self.dropout = 0.
self.node_update = NodeApplyModule(out_feats, activation, bias)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv)
def forward(self, h):
if self.dropout:
h = self.dropout(h)
# 公式里的 H^{l} * W^{l},对第l层特征进行维度变换后命名为'h'
self.g.ndata['h'] = torch.mm(h, self.weight)
# !重要:消息函数gcn_msg,聚合函数gcn_reduce,更新函数self.node_update
self.g.update_all(gcn_msg, gcn_reduce, self.node_update)
h = self.g.ndata.pop('h')
return h
dgl库的消息传递过程如下图所示:

来源网址
细节
消息函数
def gcn_msg(edge):
msg = edge.src['h'] * edge.src['norm']
return {'m': msg}
- 传入一条边edge
- edge.src:有向边的源节点
- edge.src[‘h’]:源节点的名为’h’的特征
- edge.src[‘norm’]:源节点的名为’norm’的特征,事实上就是归一化之后的特征,即节点特征乘以该点度的-1/2.
- msg = edge.src[‘h’] * edge.src[‘norm’],将特征’h’与特征’norm’做内积(对应位置相乘再相加)
- 将计算结果命名为’m’,作为新特征返回
聚合函数
def gcn_reduce(node):
accum = torch.sum(node.mailbox['m'], 1) * node.data['norm']
return {'h': accum}
- 传入一个节点node
- node.mailbox[‘m’]:node的消息中转站,接受消息函数传递的各种特征(消息),命名为’m’
- torch.sum(node.mailbox[‘m’], 1):对所有传递给node的、名为’m’的特征在维度1上求和,因为默认消息储存在维度1上
- torch.sum(node.mailbox[‘m’], 1) * node.data[‘norm’],再与node自身的特征’norm’做内积(对应位置相乘再相加)
- 将计算结果命名为’h’,作为新特征返回
更新函数
这里是对节点的特征做一些变换
class NodeApplyModule(nn.Module):
def __init__(self, out_feats, activation=None, bias=True):
super(NodeApplyModule, self).__init__()
if bias:
self.bias = nn.Parameter(torch.Tensor(out_feats))
else:
self.bias = None
self.activation = activation
self.reset_parameters()
def reset_parameters(self):
if self.bias is not None:
stdv = 1. / math.sqrt(self.bias.size(0))
self.bias.data.uniform_(-stdv, stdv)
def forward(self, nodes):
h = nodes.data['h']
if self.bias is not None:
h = h + self.bias
if self.activation:
h = self.activation(h)
return {'h': h}
- 看forward函数,传入节点node
- 如果设置了加偏置,就对节点node的特征’h’都加上一个偏置
- 如果设置了加激活函数,就对节点的特征’h’都通过激活函数
- 最后作为新特征’h’返回
主函数片段截取
'norm’特征哪里来的,就是在主函数里计算的
# normalization
degs = g.in_degrees().float() # D
norm = torch.pow(degs, -0.5) # D^{-1/2}
norm[torch.isinf(norm)] = 0
g.ndata['norm'] = norm.unsqueeze(1)
# 所有节点增加特征'norm',为自己的度的-1/2次方
https://blog.csdn.net/Wolf_AgOH/article/details/124482946