机器学习----KNN算法及机器学习的套路
机器学习:
分类
按照是否有标签(答案)
有监督学习(都有标签)- 半监督学习(部分标签)
- 无监督学习 (无标签)
监督学习(Supervised learning)
按照数据预测的结果
- 分类 Classification 预测的值是离散的 股票的涨还是跌(二分类) 鸢尾花数据集分类,识别0~9数字
- 回归 Regression 预测的值是连续的 股票的价格, 房屋的价格
KNN算法的原理介绍
- 优点

k nearest neighbors
- 原理案例介绍
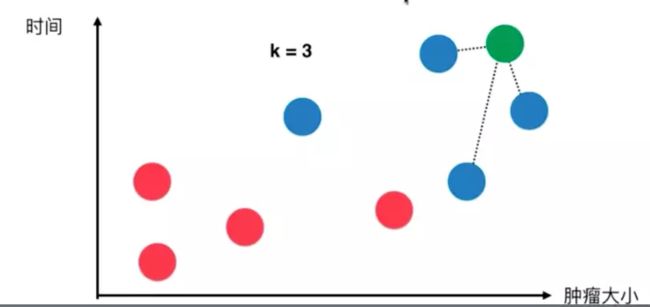
假设现在设计一个程序判断一个新的肿瘤病人是良性肿瘤还是恶性肿瘤。
先基于原有的肿瘤病人的发现时间和肿瘤大小(特征)对应的良性/恶性(值)建立了一张散点图,横坐标是肿瘤大小,纵坐标是发现时间,红色代表良性,蓝色代表恶性,现在要预测的病人的颜色为绿色。
- 首先需要取一个k值(这个k值的取法后面会介绍),然后找到距离要预测的病人的点(绿点)距离最近的k个点。
- 然后用第一步中取到的三个点进行投票,比如本例中投票结果就是
蓝:红 = 3:0,3>0,所以判断这个新病人幻的事恶性肿瘤。
-
本质
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN算法的一个简单实现
import numpy as np
import matplotlib.pyplot as plt
原始集合
# 特征
raw_data_x= [[3.393533211,2.331273381],
[2.110073483,1.781539638],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.424088941],
[7.939820817,0.791637231]
]
# 所属类别
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
训练集合
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
# 要预测的点
x = np.array([8.093607318,3.365731514])
绘制数据集及要预测的点
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='g')
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='r')
plt.scatter(x[0],x[1],color='b')
<matplotlib.collections.PathCollection at 0x11addb908>
KNN 实现过程简单编码
from math import sqrt
distances = []
for x_train in X_train:
# 欧拉
# **2 求平方
d = sqrt(np.sum((x_train - x)**2))
distances.append(d)
distances
[4.812566907609877,
6.189696362066091,
6.749798999160064,
4.6986266144110695,
5.83460014556857,
1.4900114024329525,
2.354574897431513,
1.3761132675144652,
0.3064319992975,
2.5786840957478887]
# 生成表达式
distances = [sqrt(np.sum((x_train - x)**2)) for x_train in X_train]
distances
[4.812566907609877,
6.189696362066091,
6.749798999160064,
4.6986266144110695,
5.83460014556857,
1.4900114024329525,
2.354574897431513,
1.3761132675144652,
0.3064319992975,
2.5786840957478887]
# 返回排序后的结果的索引,也就是距离测试点距离最近的点的排序坐标数组
nearset = np.argsort(distances)
k = 6
投票
# 求出距离测试点最近的6个点的类别
topK_y = [y_train[i] for i in nearset[:k]]
topK_y
[1, 1, 1, 1, 1, 0]
# collections的Counter方法可以求出一个数组的相同元素的个数,返回一个dict【key=元素名,value=元素个数】
from collections import Counter
Counter(topK_y)
Counter({0: 1, 1: 5})
# most_common方法求出最多的元素对应的那个键值对
votes = Counter(topK_y)
votes.most_common(1)
[(1, 5)]
votes.most_common(1)[0][0]
1
predict_y = votes.most_common(1)[0][0]
predict_y
1
将KNN算法封装成函数
import numpy as np
from math import sqrt
from collections import Counter
def kNN_classify(k, X_train, y_train, x):
assert 1 <= k <= X_train.shape[0], "k must be valid"
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
assert X_train.shape[1] == x.shape[0], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x)**2)) for x_train in X_train]
nearest = np.argsort(distances)
topK_y = [y_train[i] for i in nearest[:k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
# 特征
raw_data_x= [[3.393533211,2.331273381],
[2.110073483,1.781539638],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.424088941],
[7.939820817,0.791637231]
]
# 所述类别
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
# 要预测的点
x = np.array([8.093607318,3.365731514])
predict = kNN_classify(6,X_train,y_train,x)
print(predict)
机器学习套路
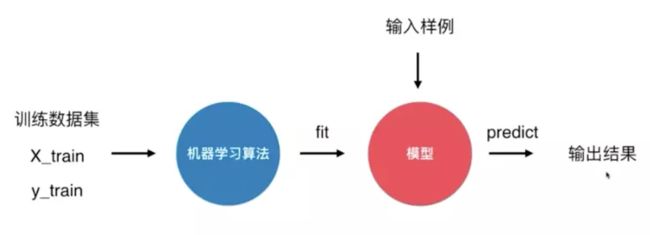
可以说kNN是一个不需要训练过程的算法
k近邻算法是非常特殊的,可以被认为是没有模型的算法
为了和其他算法统一,可以认为训练数据集就是模型
使用scikit-learn中的kNN
from sklearn.neighbors import KNeighborsClassifier
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
kNN_classifier.fit(X_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=6, p=2,
weights='uniform')
kNN_classifier.predict(x)
/Users/yuanzhang/anaconda/lib/python3.6/site-packages/sklearn/utils/validation.py:395: DeprecationWarning: Passing 1d arrays as data is deprecated in 0.17 and will raise ValueError in 0.19. Reshape your data either using X.reshape(-1, 1) if your data has a single feature or X.reshape(1, -1) if it contains a single sample.
DeprecationWarning)
array([1])
X_predict = x.reshape(1, -1)
X_predict
array([[ 8.09360732, 3.36573151]])
kNN_classifier.predict(X_predict)
array([1])
y_predict = kNN_classifier.predict(X_predict)
y_predict[0]
1
完整代码
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
# 特征
raw_data_x= [[3.393533211,2.331273381],
[2.110073483,1.781539638],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.424088941],
[7.939820817,0.791637231]
]
# 所述类别
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
# 要预测的点
x = np.array([8.093607318,3.365731514])
kNN_classifier.fit(X_train, y_train)
X_predict = x.reshape(1, -1)
kNN_classifier.predict(X_predict)
y_predict = kNN_classifier.predict(X_predict)
print(y_predict[0])
封装自己的KNN
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self,k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回标示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"mush fit before predict"
assert self._X_train.shape[1] == X_predict.shape[1], \
"the feature number of x must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
distances = [sqrt(np.sum((x_train-x)**2)) for x_train in self._X_train]
nearset = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearset[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
kNN_classifier = KNNClassifier(6)
# 特征
raw_data_x= [[3.393533211,2.331273381],
[2.110073483,1.781539638],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.424088941],
[7.939820817,0.791637231]
]
# 所述类别
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
# 要预测的点
x = np.array([8.093607318,3.365731514])
kNN_classifier.fit(X_train, y_train)
X_predict = x.reshape(1, -1)
kNN_classifier.predict(X_predict)
y_predict = kNN_classifier.predict(X_predict)
print(y_predict[0])
判断机器学习算法的性能
train test split

封装我们自己的 train test split
加载鸢尾花数据集
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
iris.keys()
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
print(iris.DESCR)
Iris Plants Database
====================
Notes
-----
Data Set Characteristics:
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%[email protected])
:Date: July, 1988
This is a copy of UCI ML iris datasets.
http://archive.ics.uci.edu/ml/datasets/Iris
The famous Iris database, first used by Sir R.A Fisher
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
References
----------
- Fisher,R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda,R.O., & Hart,P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...
iris.data
array([[ 5.1, 3.5, 1.4, 0.2],
[ 4.9, 3. , 1.4, 0.2],
[ 4.7, 3.2, 1.3, 0.2],
[ 4.6, 3.1, 1.5, 0.2],
[ 5. , 3.6, 1.4, 0.2],
[ 5.4, 3.9, 1.7, 0.4],
[ 4.6, 3.4, 1.4, 0.3],
[ 5. , 3.4, 1.5, 0.2],
[ 4.4, 2.9, 1.4, 0.2],
[ 4.9, 3.1, 1.5, 0.1],
[ 5.4, 3.7, 1.5, 0.2],
[ 4.8, 3.4, 1.6, 0.2],
[ 4.8, 3. , 1.4, 0.1],
[ 4.3, 3. , 1.1, 0.1],
[ 5.8, 4. , 1.2, 0.2],
...
[ 5.9, 3. , 5.1, 1.8]])
iris.data.shape
(150, 4)
iris.feature_names
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
iris.target
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
iris.target.shape
(150,)
iris.target_names
array(['setosa', 'versicolor', 'virginica'],
dtype='X = iris.data[:,:2]
plt.scatter(X[:,0], X[:,1])
plt.show()

y = iris.target
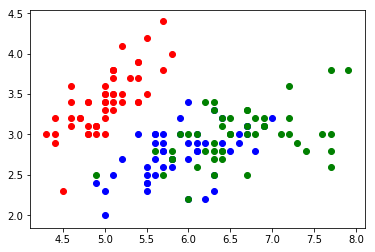
plt.scatter(X[y==0,0], X[y==0,1], color="red")
plt.scatter(X[y==1,0], X[y==1,1], color="blue")
plt.scatter(X[y==2,0], X[y==2,1], color="green")
plt.show()
plt.scatter(X[y==0,0], X[y==0,1], color="red", marker="o")
plt.scatter(X[y==1,0], X[y==1,1], color="blue", marker="+")
plt.scatter(X[y==2,0], X[y==2,1], color="green", marker="x")
plt.show()
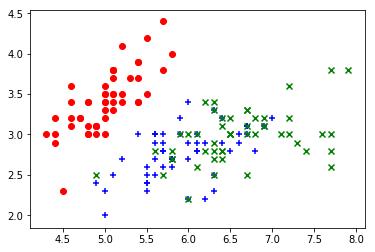
关于marker参数:http://matplotlib.org/1.4.2/api/markers_api.html
X = iris.data[:,2:]
plt.scatter(X[y==0,0], X[y==0,1], color="red", marker="o")
plt.scatter(X[y==1,0], X[y==1,1], color="blue", marker="+")
plt.scatter(X[y==2,0], X[y==2,1], color="green", marker="x")
plt.show()
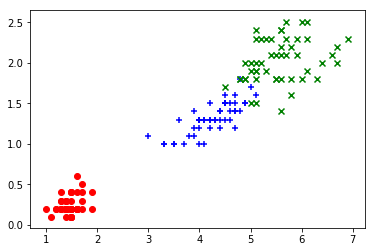
train_test_spilt
# permutation(n) 给出从0到n-1的一个随机排列
shuffle_indexes = np.random.permutation(len(X))
shuffle_indexes
array([139, 40, 63, 138, 88, 123, 101, 122, 89, 0, 132, 108, 120,
111, 140, 30, 47, 6, 128, 46, 49, 105, 3, 53, 85, 9,
147, 95, 116, 75, 20, 134, 34, 42, 144, 7, 10, 73, 90,
72, 141, 99, 57, 93, 74, 103, 39, 106, 86, 35, 15, 96,
78, 129, 19, 51, 117, 62, 113, 77, 100, 118, 83, 18, 70,
94, 26, 25, 12, 50, 28, 133, 145, 43, 33, 109, 44, 114,
92, 112, 82, 119, 115, 69, 27, 80, 41, 38, 98, 97, 61,
16, 56, 11, 64, 135, 1, 126, 137, 45, 32, 60, 124, 71,
58, 52, 84, 21, 81, 13, 142, 127, 55, 79, 14, 68, 146,
48, 23, 76, 17, 8, 136, 110, 87, 2, 143, 104, 24, 37,
107, 31, 4, 131, 66, 121, 149, 102, 5, 65, 54, 148, 59,
125, 29, 67, 36, 91, 130, 22])
# 测试数据集的比例
test_ratio = 0.2
# 获取测试数据集
tets_size = int(len(X) * test_ratio)
tets_size
30
test_indexes = shuffle_indexes[:tets_size]
train_indexes = shuffle_indexes[tets_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(113, 4)
(113,)
(37, 4)
(37,)
使用我们自己封装的测试分割函数分割训练集
import numpy as np
def train_test_split(X, y, test_radio=0.2, seed=None):
"""将数据X和y按照test_radio分割成X_train,y_train,X_test,y_test"""
assert X.shape[0] == y.shape[0],\
"the size of X must be equal to the size of y"
assert 0.0 <= test_radio <= 1.0, \
"test_radio must be valid"
if seed:
np.random.seed(seed)
shuffled_indexes = np.random.permutation(len(X))
test_size = int(len(X)*test_radio)
test_indexes = shuffled_indexes[:test_size]
train_indexes = shuffled_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, y_train, X_test, y_test
import machine_learning
from machine_learning.module_selection import train_test_split
X_train,y_train,X_test,y_test = train_test_split(X,y,test_radio=0.25)
测试我们的KNN算法
from machine_learning.KNN import KNNClassifier
my_knn_clf = KNNClassifier(k=6)
my_knn_clf.fit(X_train,y_train)
<machine_learning.KNN.KNNClassifier at 0x1a102a3a58>
# 预测结果
y_predict = my_knn_clf.predict(X_test)
y_predict
array([2, 2, 2, 1, 0, 0, 2, 2, 2, 1, 1, 0, 1, 1, 2, 2, 2, 2, 0, 0, 1, 2,
0, 2, 0, 2, 1, 1, 2, 1, 1, 1, 2, 0, 1, 2, 2, 2])
y_test
array([2, 2, 2, 1, 0, 0, 2, 2, 2, 2, 1, 0, 1, 1, 2, 2, 2, 2, 0, 0, 1, 2,
0, 2, 0, 2, 1, 1, 2, 1, 1, 1, 2, 0, 1, 2, 1, 2])
# 求出准确率
sum(y_predict==y_test)/len(y_test)
0.9473684210526315
使用sklearn的分割函数分割训练集并测试
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(112, 4)
(112,)
(38, 4)
(38,)
from sklearn.neighbors import KNeighborsClassifier
sklearn_knn_clf = KNeighborsClassifier(n_neighbors=6)
sklearn_knn_clf.fit(X_train,y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=6, p=2,
weights='uniform')
y_predict = sklearn_knn_clf.predict(X_test)
y_predict
array([2, 2, 2, 1, 0, 0, 2, 2, 2, 1, 1, 0, 1, 1, 2, 2, 2, 2, 0, 0, 1, 2,
0, 2, 0, 2, 1, 1, 2, 1, 1, 1, 2, 0, 1, 2, 2, 2])
y_test
array([2, 2, 2, 1, 0, 0, 2, 2, 2, 2, 1, 0, 1, 1, 2, 2, 2, 2, 0, 0, 1, 2,
0, 2, 0, 2, 1, 1, 2, 1, 1, 1, 2, 0, 1, 2, 1, 2])
sum(y_predict==y_test)/len(y_test)
0.9473684210526315
分类准确度
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
digits.keys()
dict_keys(['data', 'target', 'target_names', 'images', 'DESCR'])
print(digits.DESCR)
Optical Recognition of Handwritten Digits Data Set
===================================================
Notes
-----
Data Set Characteristics:
:Number of Instances: 5620
:Number of Attributes: 64
:Attribute Information: 8x8 image of integer pixels in the range 0..16.
:Missing Attribute Values: None
:Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)
:Date: July; 1998
This is a copy of the test set of the UCI ML hand-written digits datasets
http://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits
The data set contains images of hand-written digits: 10 classes where
each class refers to a digit.
Preprocessing programs made available by NIST were used to extract
normalized bitmaps of handwritten digits from a preprinted form. From a
total of 43 people, 30 contributed to the training set and different 13
to the test set. 32x32 bitmaps are divided into nonoverlapping blocks of
4x4 and the number of on pixels are counted in each block. This generates
an input matrix of 8x8 where each element is an integer in the range
0..16. This reduces dimensionality and gives invariance to small
distortions.
For info on NIST preprocessing routines, see M. D. Garris, J. L. Blue, G.
T. Candela, D. L. Dimmick, J. Geist, P. J. Grother, S. A. Janet, and C.
L. Wilson, NIST Form-Based Handprint Recognition System, NISTIR 5469,
1994.
References
----------
- C. Kaynak (1995) Methods of Combining Multiple Classifiers and Their
Applications to Handwritten Digit Recognition, MSc Thesis, Institute of
Graduate Studies in Science and Engineering, Bogazici University.
- E. Alpaydin, C. Kaynak (1998) Cascading Classifiers, Kybernetika.
- Ken Tang and Ponnuthurai N. Suganthan and Xi Yao and A. Kai Qin.
Linear dimensionalityreduction using relevance weighted LDA. School of
Electrical and Electronic Engineering Nanyang Technological University.
2005.
- Claudio Gentile. A New Approximate Maximal Margin Classification
Algorithm. NIPS. 2000.
X = digits.data
X.shape
(1797, 64)
y = digits.target
y.shape
(1797,)
y[:100]
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2,
3, 4, 5, 6, 7, 8, 9, 0, 9, 5, 5, 6, 5, 0, 9, 8, 9, 8, 4, 1, 7, 7, 3,
5, 1, 0, 0, 2, 2, 7, 8, 2, 0, 1, 2, 6, 3, 3, 7, 3, 3, 4, 6, 6, 6, 4,
9, 1, 5, 0, 9, 5, 2, 8, 2, 0, 0, 1, 7, 6, 3, 2, 1, 7, 4, 6, 3, 1, 3,
9, 1, 7, 6, 8, 4, 3, 1])
X[:10]
array([[ 0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13.,
15., 10., 15., 5., 0., 0., 3., 15., 2., 0., 11.,
8., 0., 0., 4., 12., 0., 0., 8., 8., 0., 0.,
5., 8., 0., 0., 9., 8., 0., 0., 4., 11., 0.,
1., 12., 7., 0., 0., 2., 14., 5., 10., 12., 0.,
0., 0., 0., 6., 13., 10., 0., 0., 0.],
[ 0., 0., 0., 12., 13., 5., 0., 0., 0., 0., 0.,
11., 16., 9., 0., 0., 0., 0., 3., 15., 16., 6.,
0., 0., 0., 7., 15., 16., 16., 2., 0., 0., 0.,
0., 1., 16., 16., 3., 0., 0., 0., 0., 1., 16.,
16., 6., 0., 0., 0., 0., 1., 16., 16., 6., 0.,
0., 0., 0., 0., 11., 16., 10., 0., 0.],
[ 0., 0., 0., 4., 15., 12., 0., 0., 0., 0., 3.,
16., 15., 14., 0., 0., 0., 0., 8., 13., 8., 16.,
0., 0., 0., 0., 1., 6., 15., 11., 0., 0., 0.,
1., 8., 13., 15., 1., 0., 0., 0., 9., 16., 16.,
5., 0., 0., 0., 0., 3., 13., 16., 16., 11., 5.,
0., 0., 0., 0., 3., 11., 16., 9., 0.],
[ 0., 0., 7., 15., 13., 1., 0., 0., 0., 8., 13.,
6., 15., 4., 0., 0., 0., 2., 1., 13., 13., 0.,
0., 0., 0., 0., 2., 15., 11., 1., 0., 0., 0.,
0., 0., 1., 12., 12., 1., 0., 0., 0., 0., 0.,
1., 10., 8., 0., 0., 0., 8., 4., 5., 14., 9.,
0., 0., 0., 7., 13., 13., 9., 0., 0.],
[ 0., 0., 0., 1., 11., 0., 0., 0., 0., 0., 0.,
7., 8., 0., 0., 0., 0., 0., 1., 13., 6., 2.,
2., 0., 0., 0., 7., 15., 0., 9., 8., 0., 0.,
5., 16., 10., 0., 16., 6., 0., 0., 4., 15., 16.,
13., 16., 1., 0., 0., 0., 0., 3., 15., 10., 0.,
0., 0., 0., 0., 2., 16., 4., 0., 0.],
[ 0., 0., 12., 10., 0., 0., 0., 0., 0., 0., 14.,
16., 16., 14., 0., 0., 0., 0., 13., 16., 15., 10.,
1., 0., 0., 0., 11., 16., 16., 7., 0., 0., 0.,
0., 0., 4., 7., 16., 7., 0., 0., 0., 0., 0.,
4., 16., 9., 0., 0., 0., 5., 4., 12., 16., 4.,
0., 0., 0., 9., 16., 16., 10., 0., 0.],
[ 0., 0., 0., 12., 13., 0., 0., 0., 0., 0., 5.,
16., 8., 0., 0., 0., 0., 0., 13., 16., 3., 0.,
0., 0., 0., 0., 14., 13., 0., 0., 0., 0., 0.,
0., 15., 12., 7., 2., 0., 0., 0., 0., 13., 16.,
13., 16., 3., 0., 0., 0., 7., 16., 11., 15., 8.,
0., 0., 0., 1., 9., 15., 11., 3., 0.],
[ 0., 0., 7., 8., 13., 16., 15., 1., 0., 0., 7.,
7., 4., 11., 12., 0., 0., 0., 0., 0., 8., 13.,
1., 0., 0., 4., 8., 8., 15., 15., 6., 0., 0.,
2., 11., 15., 15., 4., 0., 0., 0., 0., 0., 16.,
5., 0., 0., 0., 0., 0., 9., 15., 1., 0., 0.,
0., 0., 0., 13., 5., 0., 0., 0., 0.],
[ 0., 0., 9., 14., 8., 1., 0., 0., 0., 0., 12.,
14., 14., 12., 0., 0., 0., 0., 9., 10., 0., 15.,
4., 0., 0., 0., 3., 16., 12., 14., 2., 0., 0.,
0., 4., 16., 16., 2., 0., 0., 0., 3., 16., 8.,
10., 13., 2., 0., 0., 1., 15., 1., 3., 16., 8.,
0., 0., 0., 11., 16., 15., 11., 1., 0.],
[ 0., 0., 11., 12., 0., 0., 0., 0., 0., 2., 16.,
16., 16., 13., 0., 0., 0., 3., 16., 12., 10., 14.,
0., 0., 0., 1., 16., 1., 12., 15., 0., 0., 0.,
0., 13., 16., 9., 15., 2., 0., 0., 0., 0., 3.,
0., 9., 11., 0., 0., 0., 0., 0., 9., 15., 4.,
0., 0., 0., 9., 12., 13., 3., 0., 0.]])
some_digit = X[666]
some_digit_image = some_digit.reshape(8, 8)
import matplotlib
import matplotlib.pyplot as plt
plt.imshow(some_digit_image, cmap = matplotlib.cm.binary)
plt.show()

from playML.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_ratio=0.2)
from playML.kNN import KNNClassifier
my_knn_clf = KNNClassifier(k=3)
my_knn_clf.fit(X_train, y_train)
y_predict = my_knn_clf.predict(X_test)
sum(y_predict == y_test) / len(y_test)
0.99442896935933145
封装我们自己的accuracy_score
metrics.py
import numpy as np
def accuracy_score(y_true, y_predict):
'''计算y_true和y_predict之间的准确率'''
assert y_true.shape[0] == y_predict.shape[0], \
"the size of y_true must be equal to the size of y_predict"
return sum(y_true == y_predict) / len(y_true)
from playML.metrics import accuracy_score
accuracy_score(y_test, y_predict)
0.99442896935933145
my_knn_clf.score(X_test, y_test)
0.99442896935933145
kNN.py中添加score方法
import numpy as np
from math import sqrt
from collections import Counter
from .metrics import accuracy_score
class KNNClassifier:
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return accuracy_score(y_test, y_predict)
scikit-learn中的accuracy_score
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train, y_train)
y_predict = knn_clf.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
0.98888888888888893
knn_clf.score(X_test, y_test)
0.98888888888888893
超参数和模型参数

-
寻找好的超参数
- 领域知识
- 经验数值
- 实验搜索
寻找最好的k
# 思路,遍历1-11,分别拿每一个k去调用算法,得出分数,取得分最高的那个k
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
from sklearn.neighbors import KNeighborsClassifier
best_score = 0.0
best_k = -1
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train, y_train)
score = knn_clf.score(X_test, y_test)
if score > best_score:
best_k = k
best_score = score
print("best_k =", best_k)
print("best_score =", best_score)
-
kNN的另外一个超参数:距离的权重
一般情况下使用距离的导数作为权证
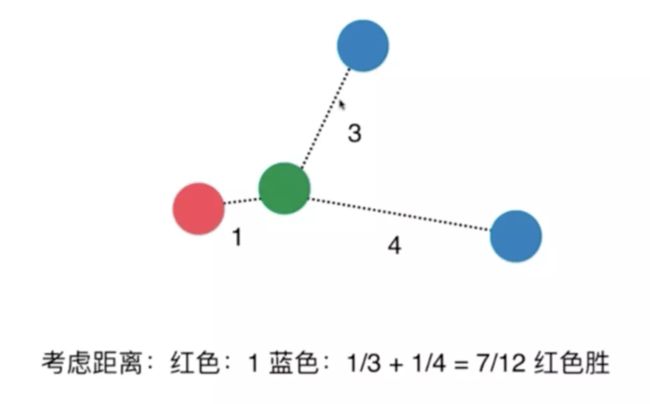
考虑距离?不考虑距离
best_method = ""
best_score = 0.0
best_k = -1
for method in ["uniform","distance"]:
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights=method)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score > best_score:
best_k = k
best_score = score
best_method = method
print("best_k=",best_k)
print("best_score=",best_score)
print("best_method=",best_method)
-
什么是距离
- 欧拉距离
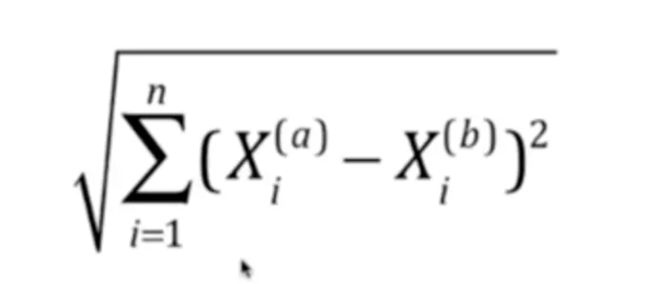
- 曼哈顿距离
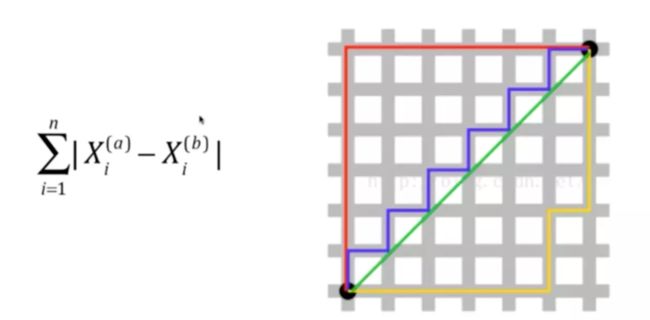
- 两种距离的整理对比
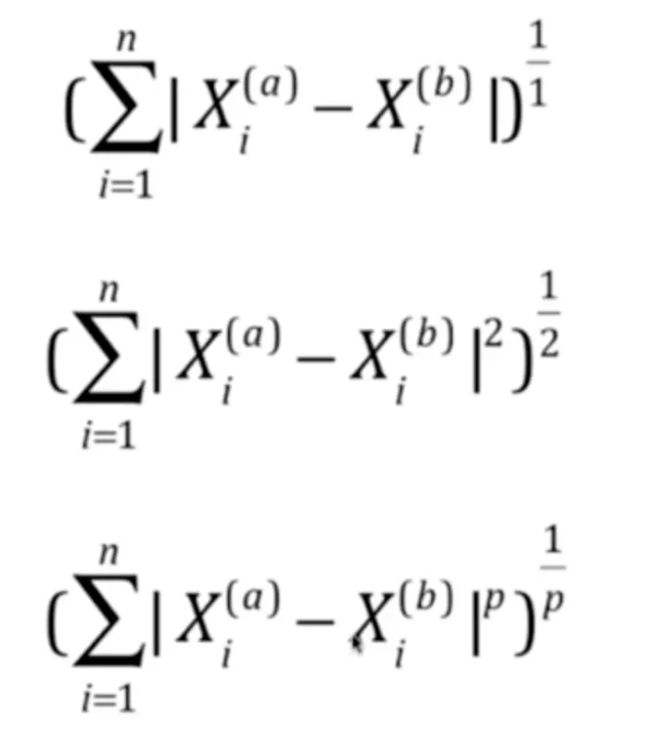
- 明克夫斯基距离
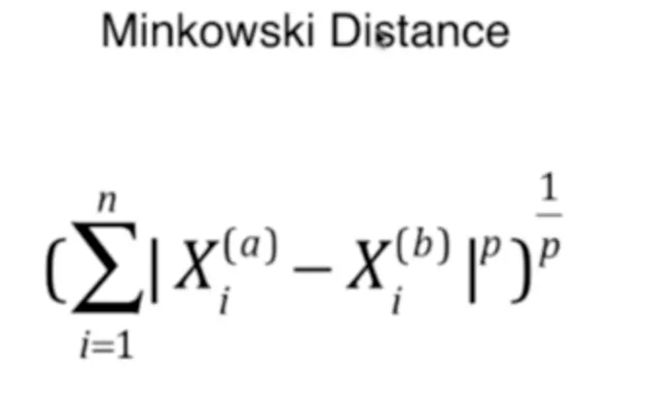
到这里,我们获得了一个新的超参数 p
搜索明可夫斯基距离相应的p
best_p = -1
best_score = 0.0
best_k = -1
for k in range(1,11):
for p in range(1,6):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights='distance',p=p)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score > best_score:
best_k = k
best_score = score
best_p = p
print("best_p=",best_p)
print("best_k=",best_k)
print("best_score=",best_score)
网格搜索
Grid Search
# array>
param_grid =[
{
'weights':['uniform'],
'n_neighbors': [i for i in range(1,11)]
},
{
'weights':['distance'],
'n_neighbors': [i for i in range(1,11)],
'p': [i for i in range(1,6)]
}
]
# 先new一个默认的Classifier对象
knn_clf = KNeighborsClassifier()
# 调用GridSearchCV创建网格搜索对象,传入参数为Classifier对象以及参数列表
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(knn_clf,param_grid)
# 调用fit方法执行网格搜索
%%time
grid_search.fit(X_train,y_train)
GridSearchCV(cv=None, error_score='raise',
estimator=KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform'),
fit_params=None, iid=True, n_jobs=1,
param_grid=[{'weights': ['uniform'], 'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}, {'weights': ['distance'], 'n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], 'p': [1, 2, 3, 4, 5]}],
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
# 不是用户传入的参数,而是根据用户传入的参数计算出来的结果,以_结尾
# 最好的评估结果,返回的是KNeighborsClassifier对象
grid_search.best_estimator_
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=3, p=3,
weights='distance')
# 最好的分数
grid_search.best_score_
0.9853862212943633
# 最好的参数
grid_search.best_params_
{'n_neighbors': 3, 'p': 3, 'weights': 'distance'}
knn_clf = grid_search.best_estimator_
knn_clf.score(X_test,y_test)
0.9833333333333333
%%time
# n_jobs 多线程并行处理,占用几个核,-1为使用所有的核
# verbose 是否打印搜索信息,传入值越大,输出信息越详细
grid_search = GridSearchCV(knn_clf,param_grid,n_jobs=-1,verbose=2)
grid_search.fit(X_train,y_train)
数据归一化
样本间的距离被一个字段所主导

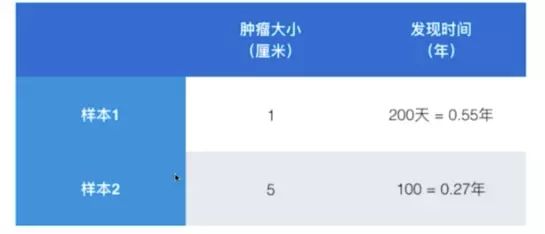
解决方案 :将所有的数据映射到同一尺度
-
最值归一化 normalization:把所有数据映射到0-1之间
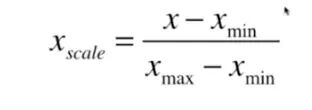
1.将这个数据映射到0~Xmax-Xmin 之间 2.然后对于每个x相比于整个范围所占的比例
适用于分布有明显边界的情况;受outlier影响较大
-
均值方差归一化 standardization
把所有数据归一到均值为0方差为1的分布中
适用于数据分布没有明显边界;有可能存在极端情况值

最值归一化 normalization
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
# 生成一个一维向量进行归一化
x = np.random.randint(0,100,size=100)
x
array([95, 6, 47, 89, 87, 86, 72, 46, 45, 42, 44, 68, 89, 28, 99, 10, 58,
32, 96, 85, 69, 20, 84, 89, 6, 99, 74, 54, 6, 8, 66, 64, 52, 0,
7, 55, 35, 20, 33, 28, 40, 92, 70, 49, 21, 16, 68, 76, 91, 68, 48,
52, 19, 83, 34, 80, 15, 20, 60, 39, 56, 37, 27, 32, 12, 21, 54, 85,
54, 43, 20, 86, 95, 81, 0, 18, 63, 40, 40, 70, 53, 77, 57, 64, 70,
33, 9, 86, 72, 35, 97, 67, 55, 73, 99, 85, 94, 59, 80, 55])
[(x-np.min(x))/np.max(x)-np.min(x)]
[array([0.95959596, 0.06060606, 0.47474747, 0.8989899 , 0.87878788,
0.86868687, 0.72727273, 0.46464646, 0.45454545, 0.42424242,
0.44444444, 0.68686869, 0.8989899 , 0.28282828, 1. ,
0.1010101 , 0.58585859, 0.32323232, 0.96969697, 0.85858586,
0.6969697 , 0.2020202 , 0.84848485, 0.8989899 , 0.06060606,
1. , 0.74747475, 0.54545455, 0.06060606, 0.08080808,
0.66666667, 0.64646465, 0.52525253, 0. , 0.07070707,
0.55555556, 0.35353535, 0.2020202 , 0.33333333, 0.28282828,
0.4040404 , 0.92929293, 0.70707071, 0.49494949, 0.21212121,
0.16161616, 0.68686869, 0.76767677, 0.91919192, 0.68686869,
0.48484848, 0.52525253, 0.19191919, 0.83838384, 0.34343434,
0.80808081, 0.15151515, 0.2020202 , 0.60606061, 0.39393939,
0.56565657, 0.37373737, 0.27272727, 0.32323232, 0.12121212,
0.21212121, 0.54545455, 0.85858586, 0.54545455, 0.43434343,
0.2020202 , 0.86868687, 0.95959596, 0.81818182, 0. ,
0.18181818, 0.63636364, 0.4040404 , 0.4040404 , 0.70707071,
0.53535354, 0.77777778, 0.57575758, 0.64646465, 0.70707071,
0.33333333, 0.09090909, 0.86868687, 0.72727273, 0.35353535,
0.97979798, 0.67676768, 0.55555556, 0.73737374, 1. ,
0.85858586, 0.94949495, 0.5959596 , 0.80808081, 0.55555556])]
# 生成一个二维矩阵进行归一化
X = np.random.randint(0,100,(50,2))
X[:10,:]
array([[52, 2],
[25, 93],
[73, 31],
[39, 48],
[15, 57],
[33, 42],
[27, 15],
[49, 48],
[ 6, 62],
[98, 82]])
X = np.array(X,dtype=float)
X[:10,:]
array([[52., 2.],
[25., 93.],
[73., 31.],
[39., 48.],
[15., 57.],
[33., 42.],
[27., 15.],
[49., 48.],
[ 6., 62.],
[98., 82.]])
X[:,0] = (X[:,0]-np.min(X[:,0]))/(np.max(X[:,0])-np.min(X[:,0]))
X[:,1] = ((X[:,1]-np.min(X[:,1]))/(np.max(X[:,1])-np.min(X[:,1])))
X[:10,:]
array([[0.52525253, 0.02020202],
[0.25252525, 0.93939394],
[0.73737374, 0.31313131],
[0.39393939, 0.48484848],
[0.15151515, 0.57575758],
[0.33333333, 0.42424242],
[0.27272727, 0.15151515],
[0.49494949, 0.48484848],
[0.06060606, 0.62626263],
[0.98989899, 0.82828283]])
# 均值,可以看出现在的数据集是均匀分布的
np.mean(X[:,0])
0.46848484848484845
# 方差
np.std(X[:,0])
0.3156554505030807
np.mean(X[:,1])
0.4917171717171717
np.std(X[:,1])
0.2805277286657274
均值方差归一化 Standardization
X2 = np.random.randint(0,100,(50,2))
X2 = np.array(X2,dtype=float)
X2[:,0] = (X2[:,0]-np.mean(X2[:,0]))/np.std(X2[:,0])
X2[:,1] = (X2[:,1]-np.mean(X2[:,1]))/np.std(X2[:,1])
plt.scatter(X2[:,0],X2[:,1])
<matplotlib.collections.PathCollection at 0x108c3d3c8>

np.mean(X2[:,0])
3.1086244689504386e-17
np.std(X2[:,0])
1.0
np.mean(X2[:,1])
1.7763568394002505e-17
np.std(X2[:,1])
1.0
对测试数据集如何归一化?

在scikit-learn中使用Scaler
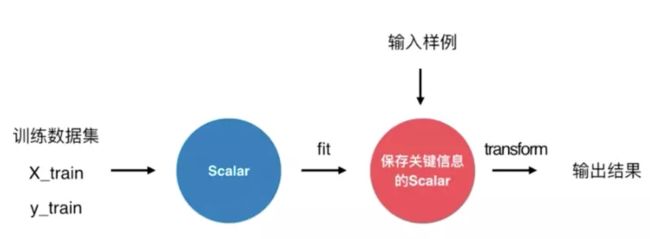
Scikit-learn 中的Scaler
import numpy as np
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=666)
scikit-learn 中的StandardScaler
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
# 存放了均值方差归一化所对应的信息
standardScaler.fit(X_train)
StandardScaler(copy=True, with_mean=True, with_std=True)
### 均值
standardScaler.mean_
array([5.83416667, 3.0825 , 3.70916667, 1.16916667])
### 描述数据的分布范围(标准差)
standardScaler.scale_
array([0.81019502, 0.44076874, 1.76295187, 0.75429833])
X_train = standardScaler.transform(X_train)
X_train
array([[-0.90616043, 0.94720873, -1.30982967, -1.28485856],
[-1.15301457, -0.18717298, -1.30982967, -1.28485856],
[-0.16559799, -0.64092567, 0.22169257, 0.17345038],
[ 0.45153738, 0.72033239, 0.95909217, 1.49918578],
[-0.90616043, -1.3215547 , -0.40226093, -0.0916967 ],
[ 1.43895396, 0.2665797 , 0.56203085, 0.30602392],
[ 0.3281103 , -1.09467835, 1.07253826, 0.30602392],
[ 2.1795164 , -0.18717298, 1.63976872, 1.2340387 ],
[-0.78273335, 2.30846679, -1.25310662, -1.4174321 ],
[ 0.45153738, -2.00218372, 0.44858475, 0.43859746],
[ 1.80923518, -0.41404933, 1.46959958, 0.83631808],
[ 0.69839152, 0.2665797 , 0.90236912, 1.49918578],
[ 0.20468323, 0.72033239, 0.44858475, 0.571171 ],
[-0.78273335, -0.86780201, 0.10824648, 0.30602392],
[-0.53587921, 1.40096142, -1.25310662, -1.28485856],
[-0.65930628, 1.40096142, -1.25310662, -1.28485856],
[-1.0295875 , 0.94720873, -1.19638358, -0.7545644 ],
[-1.77014994, -0.41404933, -1.30982967, -1.28485856],
[-0.04217092, -0.86780201, 0.10824648, 0.04087684],
[-0.78273335, 0.72033239, -1.30982967, -1.28485856],
[-1.52329579, 0.72033239, -1.30982967, -1.15228502],
[ 0.82181859, 0.2665797 , 0.78892303, 1.10146516],
[-0.16559799, -0.41404933, 0.27841562, 0.17345038],
[ 0.94524567, -0.18717298, 0.39186171, 0.30602392],
[ 0.20468323, -0.41404933, 0.44858475, 0.43859746],
[-1.39986872, 0.2665797 , -1.19638358, -1.28485856],
[-1.15301457, 0.03970336, -1.25310662, -1.4174321 ],
[ 1.06867274, 0.03970336, 1.07253826, 1.63175932],
[ 0.57496445, -0.86780201, 0.67547694, 0.83631808],
[ 0.3281103 , -0.64092567, 0.56203085, 0.04087684],
[ 0.45153738, -0.64092567, 0.61875389, 0.83631808],
[-0.16559799, 2.98909581, -1.25310662, -1.01971148],
[ 0.57496445, -1.3215547 , 0.67547694, 0.43859746],
[ 0.69839152, -0.41404933, 0.33513866, 0.17345038],
[-0.90616043, 1.62783776, -1.02621444, -1.01971148],
[ 1.19209981, -0.64092567, 0.61875389, 0.30602392],
[-0.90616043, 0.94720873, -1.30982967, -1.15228502],
[-1.89357701, -0.18717298, -1.47999881, -1.4174321 ],
[ 0.08125616, -0.18717298, 0.78892303, 0.83631808],
[ 0.69839152, -0.64092567, 1.07253826, 1.2340387 ],
[-0.28902506, -0.64092567, 0.67547694, 1.10146516],
[-0.41245214, -1.54843104, -0.00519961, -0.22427024],
[ 1.31552689, 0.03970336, 0.67547694, 0.43859746],
[ 0.57496445, 0.72033239, 1.07253826, 1.63175932],
[ 0.82181859, -0.18717298, 1.18598435, 1.36661224],
[-0.16559799, 1.62783776, -1.13966053, -1.15228502],
[ 0.94524567, -0.41404933, 0.5053078 , 0.17345038],
[ 1.06867274, 0.49345605, 1.12926131, 1.76433286],
[-1.27644165, -0.18717298, -1.30982967, -1.4174321 ],
[-1.0295875 , 1.17408507, -1.30982967, -1.28485856],
[ 0.20468323, -0.18717298, 0.61875389, 0.83631808],
[-1.0295875 , -0.18717298, -1.19638358, -1.28485856],
[ 0.3281103 , -0.18717298, 0.67547694, 0.83631808],
[ 0.69839152, 0.03970336, 1.01581521, 0.83631808],
[-0.90616043, 1.40096142, -1.25310662, -1.01971148],
[-0.16559799, -0.18717298, 0.27841562, 0.04087684],
[-1.0295875 , 0.94720873, -1.36655271, -1.15228502],
[-0.90616043, 1.62783776, -1.25310662, -1.15228502],
[-1.52329579, 0.2665797 , -1.30982967, -1.28485856],
[-0.53587921, -0.18717298, 0.44858475, 0.43859746],
[ 0.82181859, -0.64092567, 0.5053078 , 0.43859746],
[ 0.3281103 , -0.64092567, 0.16496953, 0.17345038],
[-1.27644165, 0.72033239, -1.19638358, -1.28485856],
[-0.90616043, 0.49345605, -1.13966053, -0.88713794],
[-0.04217092, -0.86780201, 0.78892303, 0.96889162],
[-0.28902506, -0.18717298, 0.22169257, 0.17345038],
[ 0.57496445, -0.64092567, 0.78892303, 0.43859746],
[ 1.06867274, 0.49345605, 1.12926131, 1.2340387 ],
[ 1.68580811, -0.18717298, 1.18598435, 0.571171 ],
[ 1.06867274, -0.18717298, 0.84564608, 1.49918578],
[-1.15301457, 0.03970336, -1.25310662, -1.4174321 ],
[-1.15301457, -1.3215547 , 0.44858475, 0.70374454],
[-0.16559799, -1.3215547 , 0.73219998, 1.10146516],
[-1.15301457, -1.54843104, -0.2320918 , -0.22427024],
[-0.41245214, -1.54843104, 0.05152343, -0.0916967 ],
[ 1.06867274, -1.3215547 , 1.18598435, 0.83631808],
[ 0.82181859, -0.18717298, 1.01581521, 0.83631808],
[-0.16559799, -1.09467835, -0.1186457 , -0.22427024],
[ 0.20468323, -2.00218372, 0.73219998, 0.43859746],
[ 1.06867274, 0.03970336, 0.56203085, 0.43859746],
[-1.15301457, 0.03970336, -1.25310662, -1.4174321 ],
[ 0.57496445, -1.3215547 , 0.73219998, 0.96889162],
[-1.39986872, 0.2665797 , -1.36655271, -1.28485856],
[ 0.20468323, -0.86780201, 0.78892303, 0.571171 ],
[-0.04217092, -1.09467835, 0.16496953, 0.04087684],
[ 1.31552689, 0.2665797 , 1.12926131, 1.49918578],
[-1.77014994, -0.18717298, -1.36655271, -1.28485856],
[ 1.56238103, -0.18717298, 1.2427074 , 1.2340387 ],
[ 1.19209981, 0.2665797 , 1.2427074 , 1.49918578],
[-0.78273335, 0.94720873, -1.25310662, -1.28485856],
[ 2.54979762, 1.62783776, 1.52632263, 1.10146516],
[ 0.69839152, -0.64092567, 1.07253826, 1.36661224],
[-0.28902506, -0.41404933, -0.06192266, 0.17345038],
[-0.41245214, 2.53534313, -1.30982967, -1.28485856],
[-1.27644165, -0.18717298, -1.30982967, -1.15228502],
[ 0.57496445, -0.41404933, 1.07253826, 0.83631808],
[-1.77014994, 0.2665797 , -1.36655271, -1.28485856],
[-0.53587921, 1.8547141 , -1.13966053, -1.01971148],
[-1.0295875 , 0.72033239, -1.19638358, -1.01971148],
[ 1.06867274, -0.18717298, 0.73219998, 0.70374454],
[-0.53587921, 1.8547141 , -1.36655271, -1.01971148],
[ 2.30294347, -0.64092567, 1.69649176, 1.10146516],
[-0.28902506, -0.86780201, 0.27841562, 0.17345038],
[ 1.19209981, -0.18717298, 1.01581521, 1.2340387 ],
[-0.41245214, 0.94720873, -1.36655271, -1.28485856],
[-1.27644165, 0.72033239, -1.02621444, -1.28485856],
[-0.53587921, 0.72033239, -1.13966053, -1.28485856],
[ 2.30294347, 1.62783776, 1.69649176, 1.36661224],
[ 1.31552689, 0.03970336, 0.95909217, 1.2340387 ],
[-0.28902506, -1.3215547 , 0.10824648, -0.0916967 ],
[-0.90616043, 0.72033239, -1.25310662, -1.28485856],
[-0.90616043, 1.62783776, -1.19638358, -1.28485856],
[ 0.3281103 , -0.41404933, 0.56203085, 0.30602392],
[-0.04217092, 2.08159044, -1.42327576, -1.28485856],
[-1.0295875 , -2.45593641, -0.1186457 , -0.22427024],
[ 0.69839152, 0.2665797 , 0.44858475, 0.43859746],
[ 0.3281103 , -0.18717298, 0.5053078 , 0.30602392],
[ 0.08125616, 0.2665797 , 0.61875389, 0.83631808],
[ 0.20468323, -2.00218372, 0.16496953, -0.22427024],
[ 1.93266225, -0.64092567, 1.35615349, 0.96889162]])
X_test = standardScaler.transform(X_test)
X_test
array([[-0.28902506, -0.18717298, 0.44858475, 0.43859746],
[-0.04217092, -0.64092567, 0.78892303, 1.63175932],
[-1.0295875 , -1.77530738, -0.2320918 , -0.22427024],
[-0.04217092, -0.86780201, 0.78892303, 0.96889162],
[-1.52329579, 0.03970336, -1.25310662, -1.28485856],
[-0.41245214, -1.3215547 , 0.16496953, 0.17345038],
[-0.16559799, -0.64092567, 0.44858475, 0.17345038],
[ 0.82181859, -0.18717298, 0.84564608, 1.10146516],
[ 0.57496445, -1.77530738, 0.39186171, 0.17345038],
[-0.41245214, -1.09467835, 0.39186171, 0.04087684],
[ 1.06867274, 0.03970336, 0.39186171, 0.30602392],
[-1.64672287, -1.77530738, -1.36655271, -1.15228502],
[-1.27644165, 0.03970336, -1.19638358, -1.28485856],
[-0.53587921, 0.72033239, -1.25310662, -1.01971148],
[ 1.68580811, 1.17408507, 1.35615349, 1.76433286],
[-0.04217092, -0.86780201, 0.22169257, -0.22427024],
[-1.52329579, 1.17408507, -1.53672185, -1.28485856],
[ 1.68580811, 0.2665797 , 1.29943044, 0.83631808],
[ 1.31552689, 0.03970336, 0.78892303, 1.49918578],
[ 0.69839152, -0.86780201, 0.90236912, 0.96889162],
[ 0.57496445, 0.49345605, 0.56203085, 0.571171 ],
[-1.0295875 , 0.72033239, -1.25310662, -1.28485856],
[ 2.30294347, -1.09467835, 1.80993786, 1.49918578],
[-1.0295875 , 0.49345605, -1.30982967, -1.28485856],
[ 0.45153738, -0.41404933, 0.33513866, 0.17345038],
[ 0.08125616, -0.18717298, 0.27841562, 0.43859746],
[-1.0295875 , 0.2665797 , -1.42327576, -1.28485856],
[-0.41245214, -1.77530738, 0.16496953, 0.17345038],
[ 0.57496445, 0.49345605, 1.29943044, 1.76433286],
[ 2.30294347, -0.18717298, 1.35615349, 1.49918578]])
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier(n_neighbors=3)
knn_clf.fit(X_train,y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=3, p=2,
weights='uniform')
knn_clf.score(X_test,y_test)
1.0
实现自己的StandardScaler
import numpy as np
class StandardScaler():
def __init__(self):
self.mean_ = None
self.scale_ = None
pass
def fit(self, X):
"""断言, 对传入数据的提前判断"""
assert X.ndim == 2, "X必须是矩阵"
self.mean_ = np.array([np.mean(X[:, i]) for i in range(X.shape[1])])
self.scale_ = np.array([np.std(X[:, i]) for i in range(X.shape[1])])
def transform(self, X):
"""将X根据这个StandardScaler进行均值方差归一化处理"""
assert X.ndim == 2, "X必须是矩阵"
assert self.mean_ is not None and self.scale_ is not None, "must be fit before tranform"
assert X.shape[1] == len(self.mean_), "the feature number of X must be equal to mean_ and std_"
resX = np.empty(shape=X.shape, dtype=float)
for col in range(X.shape[1]):
resX[:, col] = (X[:, col] - self.mean_[col])/self.scale_[col]
return resX
KNN的缺点
