【论文学习笔记】《Voice Transformer Network》
《Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining》论文学习
文章目录
- 《Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining》论文学习
-
- 摘要
- 1 介绍
- 2 背景
-
- 2.1 序列到序列语音合成
- 2.2 基于 Transformer 的文本语音合成
- 3 语音 Transformer 网络
- 4 提出文本-语音预训练的训练策略
-
- 4.1 解码器预训练
- 4.2 编码器预训练
- 4.3 VC 模型训练
- 5 实验评估
-
- 5.1 实验设置
- 5.2 TTS 预训练的有效性
- 5.3 与基线方法比较
- 6 结论
摘要
提出了一种新的序列到序列( seq2seq )语音转换模型,该模型基于文本到语音( TTS )预训练的 Transformer 结构。
Seq2seq VC 模型是有吸引力的,因为他们的能力转换韵律。
基于递归神经网络( RNNs )和卷积神经网络( CNNs )的 seq2seq 模型已经成功地应用于 VC ,而 Transformer 网络在各种语音处理任务中显示出了良好的结果,尚未被研究。
尽管如此, seq2seq 模型的数据需求性和转换语音的错误发音使其不切实际。
为此,我们提出了一种简单而有效的前训练技术,从大规模、易于获取的 TTS 语料库中迁移知识。
用这些预先训练的模型参数初始化的 VC 模型能够为高保真、高清晰度的转换语音生成有效的隐藏表示。
实验结果表明,该预训练方案能够促进数据高效训练,并在可理解性、自然度和相似度方面优于基于 RNN 的 seq2seq VC 模型。
索引术语 —— 语音转换 , 序列到序列学习 , Transformer ,预训练
1 介绍
语音转换( VC )的目的是在不改变语言内容(《Continuous probabilistic transform for voice conversion》)的情况下,将源语音转换为目标语音。
传统的 VC 系统遵循分析转换合成范式(《Voice Conversion Based on Maximum-Likelihood Estimation of Spectral Parameter Trajectory》)。
首先,利用 WORLD (《WORLD: A VocoderBased High-Quality Speech Synthesis System for Real-Time Applications》)或 STRAIGHT (《Restructuring speech representations using a pitch-adaptive timefrequency smoothing and an instantaneous-frequency-based F0 extraction: Possible role of a repetitive structure in sounds》)等高质量声码器提取不同的声学特征,如光谱特征和基频( F0 )。
这些特征分别转换,波形合成器最终使用转换的特征生成转换波形。
以往的 VC 研究主要集中在光谱特征的转换上,而只是对 F0 进行简单的线性变换。
此外,转换通常是逐帧进行的,即转换后的语音和源语音的长度总是相同的。
综上所述,目前的 VC 文献对包括 F0 和持续时间在内的韵律转换过于简化。
这就是序列到序列( seq2seq )模型(《Sequence to Sequence Learning with Neural Networks》)可以发挥作用的地方。
现代的 seq2seq 模型通常带有注意机制(《Neural machine translation by jointly learning to align and translate》,《Effective approaches to attention-based neural machine translation》),用于隐式学习源序列和输出序列之间的对齐关系,可以生成各种长度的输出。
这种能力使 seq2seq 模型成为在 VC 中转换持续时间的自然选择。
此外, F0 轮廓也可以采用显式 F0 (如将光谱和 F0 序列串联起来形成输入特征序列)(《Voice Conversion Using Sequence-to-Sequence Learning of Context Posterior Probabilities》,《ATTS2S-VC: Sequence-to-sequence Voice Conversion with Attention and Context Preservation Mechanisms》,《ConvS2SVC: Fully convolutional sequence-to-sequence voice conversion》)或隐式 F0 轮廓(如使用 Mel 谱图作为输入特征)(《Sequence-toSequence Acoustic Modeling for Voice Conversion》,《Improving Sequence-to-sequence Voice Conversion by Adding Text-supervision》,《Non-Parallel Sequenceto-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations》,《Foreign Accent Conversion by Synthesizing Speech from Phonetic Posteriorgrams》,《Hierarchical sequence to sequence voice conversion with limited data》,《Parrotron: An End-to-End Speech-to-Speech Conversion Model and its Applications to Hearing-Impaired Speech and Speech Separation》)进行转换。
Seq2seq VC 可以进一步应用到重音转换(《Foreign Accent Conversion by Synthesizing Speech from Phonetic Posteriorgrams》)中,其中韵律转换起着重要作用。
现有的 seq2seq VC 模型要么基于递归神经网络( RNNs )(《Voice Conversion Using Sequence-to-Sequence Learning of Context Posterior Probabilities》,《ATTS2S-VC: Sequence-to-sequence Voice Conversion with Attention and Context Preservation Mechanisms》,《Sequence-toSequence Acoustic Modeling for Voice Conversion》,《Improving Sequence-to-sequence Voice Conversion by Adding Text-supervision》,《Non-Parallel Sequenceto-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations》,《Foreign Accent Conversion by Synthesizing Speech from Phonetic Posteriorgrams》,《Hierarchical sequence to sequence voice conversion with limited data》,《Parrotron: An End-to-End Speech-to-Speech Conversion Model and its Applications to Hearing-Impaired Speech and Speech Separation》),要么基于卷积神经网络( CNNs )(《ConvS2SVC: Fully convolutional sequence-to-sequence voice conversion》)。
近年来,在自动语音识别( ASR )(《Speech-Transformer: A NoRecurrence Sequence-to-Sequence Model for Speech Recognition》)、语音翻译( ST )(《End-to-End Speech Translation with the Transformer》,《Enhancing Transformer for End-to-end Speech-to-Text Translation》)和文本到语音( TTS )(《Neural Speech Synthesis with Transformer Network》)等各种语音处理任务中, Transformer 架构(《Attention is All you Need》)已经被证明能够有效地执行(《A comparative study on transformer vs RNN in speech applications》)。
在注意力机制的基础上,该 Transformer 通过避免使用循环层来实现并行训练,并通过使用多头自我注意而不是卷积层来提供跨越整个输入的接受域。
尽管如此,上述成功利用 Transformer 架构的语音应用程序都试图在文本和声学特征序列之间找到映射。
相反, VC 尝试在声学框架之间映射,其高时间分辨率带来了计算记忆成本和准确注意力学习方面的挑战。
尽管有很好的结果, seq2seq VC 模型有两个主要的问题。
首先, seq2seq 模型通常需要大量的训练数据,但大规模的平行语料库,即源说话者和目标说话者表达的语言内容相同的成对语音样本,是不现实的。
其次,正如(《Improving Sequence-to-sequence Voice Conversion by Adding Text-supervision》)中所指出的,转换后的语音经常会出现读音错误和音素、跳过音素等不稳定问题。已经提出了几种技术来解决这些问题。
在(《Sequence-to-Sequence Acoustic Modeling for Voice Conversion》)中,使用预先训练的 ASR 模块提取语音后音图( PPGs )作为额外的线索,而在(《Foreign Accent Conversion by Synthesizing Speech from Phonetic Posteriorgrams》)中, PPGs 仅作为输入。
也有人提出使用上下文保留丢失和引导注意力丢失(《Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention》)来稳定训练(《ATTS2S-VC: Sequence-to-sequence Voice Conversion with Attention and Context Preservation Mechanisms》,《ConvS2SVC: Fully convolutional sequence-to-sequence voice conversion》)。
使用额外的文本标签将多任务学习和数据增强整合到(《Improving Sequence-to-sequence Voice Conversion by Adding Text-supervision》)中,以提高数据效率,并在(《Non-Parallel Sequenceto-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations》)中解除语言和说话者表示,以实现非并行训练,从而消除了对并行语料库的需要。
在(《Parrotron: An End-to-End Speech-to-Speech Conversion Model and its Applications to Hearing-Impaired Speech and Speech Separation》)中,一个大型的手工转录语料被用来从多对一(归一化) VC 模型的 TTS 模型生成人工训练数据,其中多任务学习也被使用。
处理有限训练数据问题的一种常用方法是迁移学习,即利用大量领域外数据的知识来帮助目标领域的学习。
近年来,由于社区贡献了大量的大规模语料库, TTS 系统特别是神经 seq2seq 模型取得了巨大的成功。
我们认为,这些 TTS 模型的核心是生成有效中间表征的能力,这有助于正确的注意力学习,从而连接编码器和解码器。
TTS 的迁移学习已经成功地应用于说话者适应等任务(《Neural voice cloning with a few samples》,《Transfer learning from speaker verification to multispeaker text-to-speech synthesis》,《Sample efficient adaptive text-to-speech》,《ESPnet-TTS: Unified, Reproducible, and Integratable Open Source End-to-End Text-toSpeech Toolkit》)。
在(《Bootstrapping non-parallel voice conversion from speaker-adaptive text-to-speech》)中,第一次尝试将这种技术应用到 VC 中是通过从预先训练的说话人自适应 TTS 模型中引导一个非并行 VC 系统。
在本研究中,我们提出了一种新颖而简单的前训练技术来转移学习过的 TTS 模型中的知识。
为了传递核心能力,即精细表示的生成和利用,需要编码器和解码器的知识。
因此,我们分步骤对它们进行预训练:首先,利用大规模的 TTS 语料库对传统的 TTS 模型进行预训练。
TTS 训练确保了一个经过良好训练的解码器能够产生具有正确隐藏表示的高质量语音。
由于编码器必须经过预先训练,以将输入语音编码为解码器可以识别的隐藏表示,因此我们以自动编码器风格训练编码器,并固定预先训练的解码器。
这是通过一个简单的重建损失来实现的。
我们证明了用上述预训练的模型参数初始化的 VC 模型即使在非常有限的训练数据下也能产生高质量、高清晰度的语音。
我们在这项工作中的贡献如下:
• 我们将 Transformer 网络应用到 VC 中。据我们所知,这是研究这种组合的第一个工作。
• 提出了一种面向 VC 的 TTS 预训练技术。预训练过程为快速、样本高效的 VC 模型学习提供了先验条件,从而减少了对数据大小的要求和训练时间。在本研究中,我们通过将基于 Transformer 的 TTS 模型中的知识转移到基于 Transformer 的 VC 模型中来验证该方案的有效性。
2 背景
2.1 序列到序列语音合成
Seq2seq 模型用于寻找一个源特征序列 x 1 : n = ( x 1 , . . . , x n ) x_{1:n} = (x_1,...,x_n) x1:n=(x1,...,xn) 与一个目标特征序列 y 1 : m = ( y 1 , . . . , y m ) y_{1:m} = (y_1,...,y_m) y1:m=(y1,...,ym) 之间的映射,而目标特征序列的长度不一定相同,即 n ≠ m n \neq m n=m。
大多数 seq2seq 型号具有编码器解码器结构(《Sequence to Sequence Learning with Neural Networks》),高级型号具有注意机制(《Neural machine translation by jointly learning to align and translate》,《Effective approaches to attention-based neural machine translation》)。
首先,编码器( Enc )将 x 1 : n x_{1:n} x1:n 映射到一个隐藏表示序列 h 1 : n = ( h 1 , . . . , h n ) h_{1:n} = (h_1,...,h_n) h1:n=(h1,...,hn) 。
输出序列的解码是自回归的,这意味着之前生成的符号被认为是每个解码时间步长的额外输入。
为解码输出特征 y t y_t yt , h 1 : n h_{1:n} h1:n 的加权和首先形成上下文向量 c t c_t ct ,其中权重向量表示为计算得到的注意概率向量 a t = ( a t ( 1 ) , . . . , a t ( n ) ) a_t = (a^{(1)}_ t,...,a^{(n)}_t) at=(at(1),...,at(n)) 。
每个注意概率 a t ( k ) a^{(k)}_t at(k) ,可以认为是隐含表示法 h k h_k hk 在第 t t t 个时间步长的重要性。
然后解码器( Dec )使用上下文向量 c c c 和之前生成的特征 y 1 : t − 1 = ( y 1 , . . . , y t − 1 ) y_{1:t-1} = (y_1,...,y_{t-1}) y1:t−1=(y1,...,yt−1) 解码 y t y_t yt 。
注意,注意向量的计算和解码过程都以解码器 q t − 1 q_{t-1} qt−1的前一个隐藏状态作为输入。
上述程序可以制定如下:

正如(《Bootstrapping non-parallel voice conversion from speaker-adaptive text-to-speech》,《Joint Training Framework for Text-to-Speech and Voice Conversion Using Multi-Source Tacotron and WaveNet》)所指出的, TTS 和 VC 是相似的,因为两个任务的输出都是一系列的声学特征。
在这样的 seq2seq 语音合成任务中,通常的做法是使用线性层来进一步将解码器输出投影到所需的维度。
在训练期间,通过使用 L1 或 L2 损失的反向传播来优化模型。
2.2 基于 Transformer 的文本语音合成
在本小节中,我们将描述(《Neural Speech Synthesis with Transformer Network》)中提出的基于 Transformer 的 TTS 系统,我们将其称为 Transformer-TTS 。
Transformer-TTS 是 Transformer (《Attention is All you Need》)架构和 Tacotron 2 (《Natural TTS Synthesis by Conditioning WaveNet on MEL Spectrogram Predictions》) TTS 系统的组合。
我们首先简要介绍了 Transformer 模型(《Attention is All you Need》)。
Transformer 完全依赖于所谓的多头自我注意模块,该模块通过共同关注来自不同表示子空间的信息来学习顺序依赖性。
Transformer-TTS 的主体类似于原始的 Transformer 架构,与任何传统的 seq2seq 模型一样,它由一个编码器堆栈和一个解码器堆栈组成,分别由 L 个编码器层和 L 个解码器层组成。
编码器层包含一个多头自注意子层,然后是一个位置上完全连接的前馈网络。
解码器层,除了编码器层中的两个子层之外,还包含第三个子层,它对编码器堆栈的输出执行多头注意。
每个层都配备了残差连接和层规范化。
最后,由于没有使用循环关系,将正弦位置编码(《Convolutional Sequence to Sequence Learning》)添加到编码器和解码器的输入,这样模型就可以知道每个元素的相对或绝对位置信息。
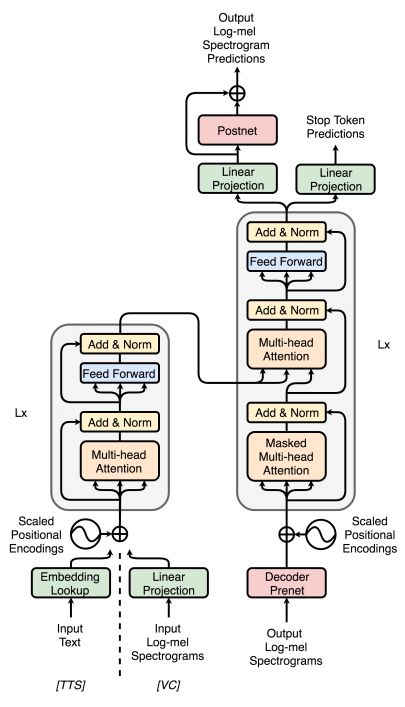
图 1 描述了 Transformer-TTS 的模型架构。由于 Transformer 体系结构最初是为机器翻译而设计的,因此对(《Neural Speech Synthesis with Transformer Network》)中的体系结构进行了一些修改,以使其与 TTS 任务兼容。
首先,就像在 Tacotron 2 中一样,在编码器和解码器端添加前置网络。
由于文本空间和声学特征空间是不同的,因此采用相应的可训练权值进行位置嵌入,以适应每个空间的尺度。
除了线性投影来预测输出的声学特征外,还增加了一个额外的线性层来预测停止标记(《Natural TTS Synthesis by Conditioning WaveNet on MEL Spectrogram Predictions》)。
使用加权二值交叉熵损失,使模型能够学习何时停止解码。
在最近的 TTS 模型中,一个五层的 CNN 后置网络预测一个残差,以完善最终的预测。
在这项工作中,我们的实现是基于开放源码的 ESPnet-TTS (《ESPnet: End-to-End Speech Processing Toolkit》,《ESPnet-TTS: Unified, Reproducible, and Integratable Open Source End-to-End Text-toSpeech Toolkit》),其中编码器前置网络被丢弃,引导注意损失(《Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention》)应用于部分解码器层(《A comparative study on transformer vs RNN in speech applications》)的部分头。
3 语音 Transformer 网络
在本节中,我们将描述 Transformer 和 seq2seq VC 的组合。我们提出的模型,称为 Voice Transformer Network ( VTN ),主要基于第 2.2 节介绍的 Transformer-TTS 。
我们的模型使用源对数梅尔谱图并输出转换后的对数梅尔谱图。
如 2.1 节所述, TTS 和 VC 分别对文本特征和声学特征进行编码,对声学特征进行解码。
因此,我们对 TTS 模型做了一个非常简单的修改,用一个线性投影层替换编码器中的嵌入查找层,如图 1 所示。
虽然可以使用更复杂的网络,但我们发现这种简单的设计足以产生令人满意的结果。
模型架构的其余部分以及训练过程与 Transformer-TTS 保持一致。
我们发现一个很有用的重要技巧是在编码器和解码器中为了准确的注意力学习使用一个减少因子。
在 seq2seq TTS 中,由于声特征的时间分辨率通常比文本输入的时间分辨率大得多,因此通常在解码器侧(《Tacotron: Towards end-to-end speech synthesis》)上使用缩减因子 r d r_d rd ,在每个时间步长解码多个堆叠帧。
另一方面,虽然 VC 的输入和输出都是声学特征,但其高时间分辨率(约 100 帧/秒)不仅使注意力学习困难,而且增加了训练记忆足迹。
虽然在(《Sequence-toSequence Acoustic Modeling for Voice Conversion》)中使用金字塔 RNN 来降低时间分辨率,在这里我们简单地引入一个编码器缩减因子 r e r_e re ,其中相邻帧堆叠来减少时间轴。
我们发现,这不仅导致更好的注意力对齐,而且还减少了一半的训练记忆足迹,随后所需的梯度积累步骤(《Sequence-to-Sequence Acoustic Modeling for Voice Conversion》)。
4 提出文本-语音预训练的训练策略
我们提出了一种文本到语音的预训练技术,能够实现快速、有效的样本训练,而不会对原始模型结构进行额外的修改或损失或训练损失。
假设,除了一个小型的、并行的 VC 数据集 D V C = { S s r c , S t r g } D_{VC} = \{S_{src}, S_{trg}\} DVC={Ssrc,Strg} 之外,还可以访问一个大型的单说话人 TTS 语料库 D T T S = { T T T S , S T T S } D_{TTS} = \{T_{TTS}, S_{TTS}\} DTTS={TTTS,STTS} 。
S s r c S_{src} Ssrc、 S t r g S_{trg} Strg 分别表示源语音、目标语音, T T T S T_{TTS} TTTS 、 S T T S S_{TTS} STTS 分别表示 TTS 讲话者的文本和语音。
我们的设置是高度灵活的,因为我们不要求任何说话者是相同的,也不要求任何句子在 VC 和 TTS 语料库之间是平行的。
我们采用了一个两阶段的训练过程,在第一阶段我们使用 D T T S D_{TTS} DTTS 学习初始参数作为先验,然后在第二阶段使用 D V C D_{VC} DVC 适应 VC 模型。
如第 1 节所述,生成细粒度隐藏表示的能力是一个好的 VC 模型的关键,所以我们的目标是找到一组先验模型参数来训练最终的编码器 E n c V C S Enc^S_{VC} EncVCS 和解码器 D e c V C S Dec^S_{VC} DecVCS 。
图 2 描述了整个过程。

4.1 解码器预训练
解码器的预训练就像使用 D T T S D_{TTS} DTTS 训练一个传统的 TTS 模型一样简单。
由于文本本身包含纯语言信息,这里的文本编码器 E n c T T S T Enc^T_{TTS} EncTTST 可以确保学习编码一种有效的隐藏表示,以便解码器 D e c T T S S Dec^S_{TTS} DecTTSS 解码。
此外,通过利用大规模语料库,译码器有望通过捕捉各种语音特征(如发音和韵律)来提高鲁棒性。
4.2 编码器预训练
一个良好的预先训练的编码器应该能够将声学特征编码成预先训练的解码器可以识别的隐藏表示。
考虑到这个目标,我们训练一个自动编码器,它的解码器是 4.1 节中预先训练的,并在训练期间保持固定。
通过最小化 S T T S S_{TTS} STTS 的重构损失,可以得到所需的预训练编码器 E n c T T S S Enc^S_{TTS} EncTTSS 。
4.1 节中描述的解码器预训练过程需要一个隐藏表示从文本作为输入编码,解决在编码器预训练过程保证了编码器的行为类似于文本编码器 E n c T T S T Enc^T_{TTS} EncTTST ,用来提取细粒度的,语言信息丰富的表示。
4.3 VC 模型训练
最后,我们使用 D V C D_{VC} DVC 训练所需的 VC 模型,编码器和解码器分别用 4.2 节和 4.1 节中预先训练的 E n c T T S S Enc^S_{TTS} EncTTSS 和 D e c T T S S Dec^S_{TTS} DecTTSS 初始化。
正如我们将在后面展示的那样,预先训练的模型参数可以很好地适应相对稀缺的 VC 数据。
此外,与从零开始训练相比,该模型与预训练方案的收敛时间不到训练时间的一半,训练效率极高。
5 实验评估
5.1 实验设置
我们在 CMU ARCTIC 数据库(《The CMU ARCTIC speech databases》)上进行了实验,该数据库包含了以 16khz 采样的专业美国英语人士的平行录音。
一名女性( slt )被选为目标说话者,一名男性( bdl )和一名女性( clb )被选为来源。
我们分别选取 100 个话语进行验证和评价,其余的 932 个话语作为训练数据。
对于 TTS 语料库,我们从 M-AILABS 语音数据集(《The M-AILABS speech dataset》)中选择了一位美国女性英语说话者( judy bieber )来训练一个单说话者 Transformer-TTS 模型。
在采样率同样为 16khz 的情况下,训练集包含 15200 个话语,大约 32 个小时。
整个实现都是在开源的 ESPnet 工具包上进行的(《ESPnet: End-to-End Speech Processing Toolkit》,《ESPnet-TTS: Unified, Reproducible, and Integratable Open Source End-to-End Text-toSpeech Toolkit》),包括特征提取、训练和基准测试。我们提取了具有 1024 个 FFT 点和 256 个帧移的 80 维梅尔光谱图。
TTS 模型和培训的基本设置遵循(《ESPnet-TTS: Unified, Reproducible, and Integratable Open Source End-to-End Text-toSpeech Toolkit》)中 Transformer v1 配置,我们在 VC 中对它做了最小的修改。所有 VC 模型的约简因子 r e r_e re 、 r d r_d rd 均为 2 。
对于波形合成模块,我们使用了并行 WaveGAN ( PWG )(《Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram》),它是 WaveNet 声码器的非自回归变体(《Wavenet: A generative model for raw audio》,《Speaker-dependent wavenet vocoder》),并且能够并行,比实时波形产生更快。
我们遵循开源实现: https://github.com/kan-bayashi/ParallelWaveGAN 。
由于依赖于说话人的神经声码器优于不依赖于说话人的(《An investigation of multi-speaker training for WaveNet vocoder》),我们利用 slt 的完整训练数据,通过对自然梅尔谱图进行条件反射来训练一个依赖于说话人的 PWG 。
我们的目标是证明我们所提出的方法的有效性,因此我们没有针对使用的 TTS/VC 模型的不同训练规模单独训练 PWGs ,尽管在 VC 中数据有限的目标说话人适应可以使用(《WaveNet Vocoder with Limited Training Data for Voice Conversion》)。
我们进行了两种类型的客观评估之间的转换的语音和真实情况:梅尔倒谱失真( MCD ), VC 中频谱失真的一种常用测量方法,以及字符错误率( CER )和单词错误率( WER ),能评估转换后的语音的可理解性。
我们使用 WORLD 声码器(《WORLD: A VocoderBased High-Quality Speech Synthesis System for Real-Time Applications》)以 5 毫秒帧位移提取 24 维梅尔倒谱系数,并计算非静默、时间对齐帧对的失真。
ASR 引擎基于 Transformer 架构(《Speech-Transformer: A NoRecurrence Sequence-to-Sequence Model for Speech Recognition》),并使用 LibriSpeech 数据集(《LibriSpeech: An ASR corpus based on public domain audio books》)进行训练。
slt 的真实情况评价集的 CER 和 WER 分别为 0.9% 和 3.8% 。
我们也在表 1 中报道了基于不同大小的 slt 训练数据的 TTS 模型的 ASR 结果,可以将其视为上界。

5.2 TTS 预训练的有效性
为了评估我们提出的每个预训练方案的重要性和有效性,我们对不同的训练过程和不同规模的训练数据进行了系统的比较。客观结果见表 1 。
首先,在没有任何预训练的情况下,对网络进行从零开始的训练,即使得到完整的训练集,其效果也不令人满意。
通过解码器预训练, MCD 的性能得到了提升,而 ASR 的结果是相似的。
尽管如此,当我们减少训练规模时,性能显著下降,这与(《Non-Parallel Sequenceto-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations》)报告的趋势相似。
最后,通过整合编码器预训练,该模型在所有客观措施中显示了显著的改进,在减少训练数据大小的情况下,其有效性是稳健的。
请注意,在 clb-slt 转换对中,我们提出的方法显示了实现与 TTS 上限相当的极其令人印象深刻的 ASR 结果的潜力。
5.3 与基线方法比较
接下来,我们将我们的 VTN 模型与基于 RNN 的 seq2seq VC 模型 ATTS2S (《ATTS2S-VC: Sequence-to-sequence Voice Conversion with Attention and Context Preservation Mechanisms》)进行比较。
该模型以 Tacotron 模型(《Tacotron: Towards end-to-end speech synthesis》)为基础,通过上下文保留丢失和引导注意丢失来稳定训练,并在转换后保持语言一致性。
我们沿用了(《ATTS2S-VC: Sequence-to-sequence Voice Conversion with Attention and Context Preservation Mechanisms》)中的配置,但使用的是梅尔频谱图而不是 WORLD 特征。
基线客观评价结果见表 1 。
对于不同大小的训练数据,我们的系统不仅始终优于基线方法,而且保持鲁棒性,而基线方法的性能随着训练数据大小的减少而急剧下降。
这证明了我们提出的方法在提高数据效率的同时,也提高了语音质量。
我们还观察到,当从零开始训练时,我们的 VTN 模型与基线相比具有相似的 MCD 和较差的 ASR 性能。
由于 ATTS2S 使用了额外的机制来稳定训练,这一结果可能表明使用 Transformer 架构比使用 RNNs 的优势。
我们把严格的调查留到以后的工作中去。
系统的主观测试,自然和转换相似度,也进行了知觉表现评价。
音频样本可以在 https://unilight.github.io/Publication-Demos/publications/transformer-vc/ 上找到
在自然性方面,参与者被要求通过平均意见得分( MOS )测试来评估演讲的自然程度,满分为 5 分。
对于转换相似性,给每个听者一个目标说话者的自然讲话和一个转换后的讲话,并要求他们判断这两个讲话者是在对决定有信心的情况下产生的,即确定还是不确定。
招募了 10 名非英语母语人士。

表 2 为评价集的主观结果。
首先,对于完整的训练集,我们提出的 VTN 模型在自然度和相似度方面显著优于基线 ATTS2S ,分别高出 1点和 30% 。
此外,当使用 80 个话语进行训练时,我们提出的方法的表现只有轻微的下降,仍然优于基线方法。
这一结果证明了我们方法的有效性,同时也证明了预训练技术可以在不严重降低性能的情况下极大地提高数据效率。
最后,一个有趣的发现是,使用完整训练集训练的 VTN 的表现也优于采用的 TTS 模型,而数据有限的 VTN 表现出类似的表现。
考虑到 TTS 模型实际上获得了良好的 ASR 结果,我们认为 VC 生成的语音可以从源语音的韵律信息编码中获益。
相反, TTS 语言输入中缺乏韵律线索,降低了生成语音的自然度。
6 结论
在本工作中,我们成功地将 Transformer 结构应用到 seq2seq VC 中。
此外,为了解决 seq2seq VC 中的数据效率和发音错误问题,我们提出了利用预先训练好的 TTS 模型初始化 VC 模型,从易于获取的大规模 TTS 语料中转移知识。
对解码器和编码器进行预训练的两阶段训练策略随后确保生成并充分利用细粒度的中间表示。
客观和主观评价表明,我们的预训练方案可以大大提高语音可理解度,并且显著优于基于 RNN 的 seq2seq VC 基线。
即使只有有限的训练数据,我们的系统也可以在没有显著性能下降的情况下成功训练。
在未来,我们计划更系统地检查 Transformer 体系结构与基于 RNN 的模型的有效性。
将我们的预训练方法扩展到更灵活的训练条件,如非平行训练(《Non-Parallel Sequenceto-Sequence Voice Conversion with Disentangled Linguistic and Speaker Representations》,《Bootstrapping non-parallel voice conversion from speaker-adaptive text-to-speech》),也是未来的一项重要任务。