1-end2end_optimized_image_compression
论文解读 END-To-END optimized image compression
本文发表在2017年的ICLR上,主要贡献是提出了一套包括分析变换(analysis transformation)、均匀量化器(uniform quantizer)和综合变换(synthesis transformation)的端到端图像压缩框架,并使用代理函数的形式将量化和离散熵等不可导的步骤松弛为可导的步骤,作者同时证明,在特定条件下,本文的松弛化后的损失函数在形式上类似于变分自编码器(variable autoencoder)的似然。尽管本文所提出的端到端图像压缩编码器是基于MSE优化的,但是在MS-SSIM等客观评价指标上均优于JPEG和JPEG2000,尤其在低码率的情况下,端到端的图像压缩较基于正交线性变换的压缩方法在人眼感知上更加友好。
端到端图像压缩框架

其中, x x x和 x ^ \hat{x} x^分别是原图像和重建图像, g a g_a ga、 g s g_s gs和 g p g_p gp分别表示分析变换(编码)、综合变换(解码)和感知域变换,在具体实现中, g a g_a ga和 g s g_s gs在结构上是相反的,如下图所示, g a g_a ga主要由卷积层和GDN层(Generalized Divisive Normalization)交替拼接而成,而 g s g_s gs正好相反,图中注明了每层需要优化的参数量,而分析变换和综合变换各自所需要优化的参数集合记为 ϕ \phi ϕ和 θ \theta θ,对应 y = g a ( x ; θ ) y=g_a(x;\theta) y=ga(x;θ)和 x ^ = g s ( y ^ ; θ ) \hat{x}=g_s(\hat{y};\theta) x^=gs(y^;θ)。

该压缩框架的具体过程是,原始图像 x x x经过 g a g_a ga变换到code space上的连续向量 y y y,经量化后得到可传输的离散码流 q q q;在接收端 q q q作为输入 y ^ \hat{y} y^,经过 g s g_s gs变换到data space的 x x x作为重建图像。
在实际操作中,量化操作是不可导的,因此在训练过程中,并没有进行量化,而是使用松弛的损失函数模拟量化操作的误差,具体操作是使用 y ~ = y + Δ y \tilde{y}=y+\Delta y y~=y+Δy代替反量化后的数据,这样做有两个考虑:
-
当 Δ y ∈ U ( 0 , 1 ) \Delta y\in U(0,1) Δy∈U(0,1),即噪声服从均匀分布,此时 y ~ \tilde{y} y~和 q q q在整数点上的概率密度是一样的,即连续变量 y ~ \tilde{y} y~的概率密度可作为离散码流 q q q的概率的插值函数,如下图所示
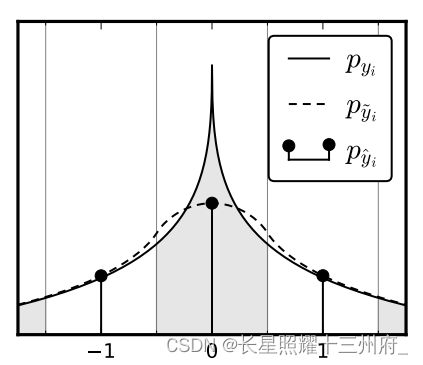
推导如下:
p y i ~ ( n ) = p y i ∗ r e c t ( n ) = ∫ n − 1 2 n + 1 2 p y i ( t ) d t = P q i ( n ) p_{\tilde{y_i}}(n)=p_{y_i}*rect(n)=\int_{n-\frac{1}{2}}^{n+\frac{1}{2}}p_{y_i}(t)d\text{t}=P_{q_i}(n) pyi~(n)=pyi∗rect(n)=∫n−21n+21pyi(t)dt=Pqi(n)
这样我们就可以使用均匀噪声模拟量化造成的误差 Δ y \Delta y Δy,而且该过程是可导的!(补充,此处的 i i i表示不同的channel) -
使用均匀噪声模拟量化操作的误差已经有先例(Gray and Neuhoff, 1998)
因此,我们解决了量化操作不可导的问题,可以计算重建图像和原始图像在感知域上的差异(这里简单采用了MSE),使失真的计算过程变得可导,对应于式(7)的第二项
E [ d ( z , z ^ ) ] = E x , Δ y [ d ( g p ( x ~ ) , g p ( x ) ) ] = E x , Δ y [ d ( g p ( g s ( g a ( x ; ϕ ) ; θ ) ) , g p ( x ) ) ] \begin{aligned}E[d(z,\hat{z})]&=E_{x,\Delta y}[d(g_p(\tilde{x}),g_p(x))]\\ &=E_{x,\Delta y}[d(g_p(g_s(g_a(x;\phi);\theta)),g_p(x))]\end{aligned} E[d(z,z^)]=Ex,Δy[d(gp(x~),gp(x))]=Ex,Δy[d(gp(gs(ga(x;ϕ);θ)),gp(x))]
此外,计算码率的过程也是不可导的——本文将离散熵作为码率的指标,但是统计每个符号的操作是不可导的,因此作者使用线性分段函数的形式估计 y ~ i \tilde{y}_i y~i的分布,对应的参数是 ψ i \psi_i ψi,具体操作应该是基于普通的梯度下降算法最大化似然函数:
L ψ ( ψ ( 0 ) , ψ ( 1 ) , . . . ) = − E y i ~ ∑ i p y i ~ ( y i ~ ; ψ ( i ) ) L_{\psi}(\psi^{(0)},\psi^{(1)},...)=-E_{\tilde{y_i}}\sum_ip_{\tilde{y_i}}(\tilde{y_i};\psi^{(i)}) Lψ(ψ(0),ψ(1),...)=−Eyi~i∑pyi~(yi~;ψ(i))
概率和似然在表达式上几乎没有区别,但是前者是参数已知,后者是参数未知。而基于梯度下降以实现最大化似然的过程也是类似的试探操作,改动参数如果能使得当前的概率更加符合实际情况,则认为参数的改动是合理的。
到此,本文已经解决了最棘手的两个问题:量化和计算熵的不可导,可以实现端到端的训练了。
损失函数
本文的损失函数分为码率和失真两部分,并通过 λ \lambda λ平衡二者的权重,形式如下:
L ( θ , ϕ ) = − E [ l o g 2 P q ] + λ E [ d ( z , z ~ ) ] = E x , Δ y [ − ∑ i l o g 2 p y i ~ ( g a ( x ; ϕ ) + Δ y ; ψ ( i ) ) + λ d ( g p ( x ) , g p ( g s ( g a ( x ; ϕ ) + Δ y ; θ ) ) ) ] = E x [ − ∑ i p y ~ i ( g a ( x ; ϕ ) + Δ y ; ψ ( i ) ) l o g 2 p y i ~ ( g a ( x ; ϕ ) + Δ y ; ψ ( i ) ) + λ d ( g p ( x ) , g p ( g s ( g a ( x ; ϕ ) + Δ y ; θ ) ) ) ] \begin{aligned} L(\theta,\phi)&=-\mathbb{E}[log_2P_q]+\lambda\mathbb{E}[d(z,\tilde{z})]\\ &=\mathbb{E}_{x,\Delta y}[-\sum_{i}log_2p_{\tilde{y_i}}(g_a(x;\phi)+\Delta y;\psi^{(i)}) +\lambda d(g_p(x),g_p(g_s(g_a(x;\phi)+\Delta y;\theta)))]\\ &=\mathbb{E}_{x}[-\sum_{i}p_{\tilde{y}_i}(g_a(x;\phi)+\Delta y;\psi^{(i)})log_2p_{\tilde{y_i}}(g_a(x;\phi)+\Delta y;\psi^{(i)})+\lambda d(g_p(x),g_p(g_s(g_a(x;\phi)+\Delta y;\theta)))] \end{aligned} L(θ,ϕ)=−E[log2Pq]+λE[d(z,z~)]=Ex,Δy[−i∑log2pyi~(ga(x;ϕ)+Δy;ψ(i))+λd(gp(x),gp(gs(ga(x;ϕ)+Δy;θ)))]=Ex[−i∑py~i(ga(x;ϕ)+Δy;ψ(i))log2pyi~(ga(x;ϕ)+Δy;ψ(i))+λd(gp(x),gp(gs(ga(x;ϕ)+Δy;θ)))]
此外,作者解释从data space到perceptual space的变换 g p g_p gp可以是固定的(a fixed transform),因为并没有需要优化的参数。
值得注意的是,上式的优化列表中并没有 ψ \psi ψ的出现,作者在附录6.1的末尾解释了 ψ \psi ψ的优化过程,每次反向传播时更新下面的负似然函数:
L ψ ( ψ ( 0 ) , ψ ( 1 ) , . . . ) = − E y ~ ∑ i p y ~ i ( y ~ i ; ψ ( i ) ) L_{\psi}(\psi^{(0)},\psi^{(1)},...)=-\mathbb{E}_{\tilde{y}}\sum_{i}p_{\tilde{y}_i}(\tilde{y}_i;\psi^{(i)}) Lψ(ψ(0),ψ(1),...)=−Ey~i∑py~i(y~i;ψ(i))
而且,每106 次梯度更新后,更新分段线性函数 p y ~ i p_{\tilde{y}_i} py~i的值。
理论推导:与变分自编码器的关系
变分自编码器的优化目标如下所示:
D K L ( q ( y ∣ x ) ∣ ∣ p y ∣ x ) = E y ∼ q log q ( y ∣ x ) − E y ∼ q log p y ∣ x = E y ∼ q log q ( y ∣ x ) − E y ∼ q log p x ∣ y ( x ∣ y ) + E y ∼ q log p y ( y ) − E y ∼ q log p x ( x ) \begin{aligned} &D_{KL}(q(y|x)||p_{y|x})\\ &=\mathbb{E}_{y\sim q}\log q(y|x)-\mathbb{E}_{y\sim q}\log p_{y|x}\\ &=\mathbb{E}_{y\sim q}\log q(y|x)-\mathbb{E}_{y\sim q}\log p_{x|y}(x|y)+\mathbb{E}_{y\sim q}\log p_{y}(y)-\mathbb{E}_{y\sim q}\log p_{x}(x) \end{aligned} DKL(q(y∣x)∣∣py∣x)=Ey∼qlogq(y∣x)−Ey∼qlogpy∣x=Ey∼qlogq(y∣x)−Ey∼qlogpx∣y(x∣y)+Ey∼qlogpy(y)−Ey∼qlogpx(x)
显然,最后一项为常数,作者提出,如果满足以下三个条件,前文的优化目标类似于变分自编码器的优化目标:
p x ∣ y ~ ( x ∣ y ~ ; λ , θ ) = N ( x ; g s ( y ~ ; θ ) , ( 2 λ ) − 1 1 ) p_{\boldsymbol{x}\mid \tilde{\boldsymbol{y}}}(\boldsymbol{x} \mid \tilde{\boldsymbol{y}} ; \lambda, \boldsymbol{\theta})=\mathcal{N}\left(\boldsymbol{x} ; g_{s}(\tilde{\boldsymbol{y}} ; \boldsymbol{\theta}),(2 \lambda)^{-1} \boldsymbol{1}\right) px∣y~(x∣y~;λ,θ)=N(x;gs(y~;θ),(2λ)−11)
p y ~ ( y ~ ; ψ ( 0 ) , ψ ( 1 ) , … ) = ∏ i p y ~ i ( y ~ i ; ψ ( i ) ) p_{\tilde{\boldsymbol{y}}}\left(\tilde{\boldsymbol{y}} ; \boldsymbol{\psi}^{(0)}, \boldsymbol{\psi}^{(1)}, \ldots\right)=\prod_{i} p_{\tilde{y}_{i}}\left(\tilde{y}_{i} ; \boldsymbol{\psi}^{(i)}\right) py~(y~;ψ(0),ψ(1),…)=i∏py~i(y~i;ψ(i))
q ( y ~ ∣ x ; ϕ ) = ∏ i U ( y ~ i ; y i , 1 ) with y = g a ( x ; ϕ ) q(\tilde{\boldsymbol{y}} \mid \boldsymbol{x} ; \boldsymbol{\phi})=\prod_i \mathcal{U}\left(\tilde{y}_{i} ; y_{i}, 1\right) \quad \text { with } \boldsymbol{y}=g_{a}(\boldsymbol{x} ; \boldsymbol{\phi}) q(y~∣x;ϕ)=i∏U(y~i;yi,1) with y=ga(x;ϕ)
其中,满足条件一需要避免使用感知域变换 g p g_p gp且失真度量 d d d必须是二范数,满足条件二意味着 y ~ \tilde{y} y~各通道相互独立,条件三则对应proxy function。
此时,(6)中的第一项和第四项都是常数,第二项对应失真,第三项对应码率。
尽管本文提出的端到端优化框架和变分自编码器(VAE)有诸多相似之处,但是两者仍然存在本质的区别:
- VAE是基于连续值优化的,而实际压缩和传输是在离散域进行的,而本文则在训练时使用离散熵模拟码率,在推理时使用熵编码计算码率,更加符合实际情况;
- VAE生成模型在优化时过于关注数据的微小波动,而本文的模型则可以实现失真-码率的平衡,忽略不重要的细节;而且在VAE生成模型的中间结果进行离散化,这可能产生意料之外的结果,但是也有一些研究(van den Oord, Kalchbrenner, and Kavukcuoglu, 2016 )
- 从生成模型的视角看,尽管(7)对应于端到端模型在较简单的度量形式下的失真,但是这种特殊形式的概率密度可能导致模型的选择不够普遍,从而难以达到最优。
实验结果
1. 松弛后的结果和实际结果的对比
作者在训练数据集上,分别比较了采用代理函数和量化引起的误差,以及微分熵和实际中的离散熵,结果如下所示

可见,使用均匀噪声替代量化操作引起的误差是很成功的,但是使用分段线性函数估计实际的 p y ~ p_{\tilde{y}} py~存在一定的偏差,但是也要看到随着量化程度越精细,偏差得到了缓解。作者给出的建议是, λ \lambda λ仅作为平衡各项的参数,可以在推理时修正这种偏差即可,即使用 λ + Δ λ \lambda+\Delta \lambda λ+Δλ。
2. 与JPEG和JPEG2000的对比
作者首先在客观评价指标 MS-SSIM(结构相似性,一种偏向人类感知的度量)和PSNR上与JPEG和JPEG2000进行了对比,结果如下所示

可见,本文提出的方法基本超越了JPEG和JPEG2000。
作者也给出了可视化的结果对比,同一码率下的结果对比,从上到下依次为JPEG、Ours和JPEG2000:



从主观感受上,本文所提出方法的压缩效果在低码率下的感受是明显好于此前传统编码的压缩效果。
作者还给出了不同码率下三种方法的压缩效果:

这个结果相当惊艳,端到端的压缩效果在不同码率上的效果十分类似,将对人眼不重要的细节成功“挑选”了出来,作者将其归功于端到端的学习方式在生物学意义上与大脑视觉皮层对图片的编码类似。
在附录中,作者还介绍了在模型推理时使用的经典熵编码算法CABAC(算术编码的一种形式),此处略。
压缩效果在不同码率上的效果十分类似,将对人眼不重要的细节成功“挑选”了出来,作者将其归功于端到端的学习方式在生物学意义上与大脑视觉皮层对图片的编码类似。
在附录中,作者还介绍了在模型推理时使用的经典熵编码算法CABAC(算术编码的一种形式),此处略。