dgl源码阅读笔记(1)——update_all
dgl源码阅读笔记(1)——update_all
图神经网络开源库dgl阅读笔记
文章目录
- dgl源码阅读笔记(1)——update_all
- 前言
- 一、update_all
-
- 1、is_builtin
- 2、message_passing
-
- invoke_gspmm
-
- gspmm
-
- gspmm_internal
- _gspmm
- 3、_set_n_repr
-
- (1) update
前言
update_all是dgl实现消息传递的重要函数,这里进行阅读了解
但是遗憾的是,目前没能彻底走完最底层的代码实现,希望有时间解决了遇到的问题。
对于这个大工程包,关于gsmm的调用及其的繁琐,很多层函数的套用。在学习的过程中,学到了修饰器,函数打包等在大型代码中是如何发挥作用的,也算是有点收获。
在debug过程是运行GCN模型后引用的该函数,有些数据集特征数,比如2708等,都是受数据集影响的,在文中为了方便理解所以写了下来。
一、update_all
查阅DGL手册了解到update_all的内容

g = dgl.graph(([0, 1, 2, 3], [1, 2, 3, 4]))
g.ndata[‘x’] = torch.ones(5, 2)
g.update_all(fn.copy_u(‘x’, ‘m’), fn.sum(‘m’, ‘h’))
g.ndata[‘h’]
输出为
tensor([[0., 0.],
[1., 1.],
[1., 1.],
[1., 1.],
[1., 1.]])
对于该函数的源码进行分析,了解底层逻辑。
首先对边的种类进行判断,etype=None,在get_etype_id中,如果etype是None就返回0
因为较少直接调用的函数有点多,尽可能多的在代码中用注释的方式解释
canonical_etypes调用的是DGLHeteroGraph类方法,在初始化的过程中:
def __init__(self,
gidx=[],
ntypes=['_N'],
etypes=['_E'],
node_frames=None,
edge_frames=None,
**deprecate_kwargs):
于是对于没有metapath的同构图,就会默认返回出[‘_N’,‘_E’,‘_N’]的这样一条边
def update_all(self,
message_func,
reduce_func,
apply_node_func=None,
etype=None):
# Graph with one relation type
if self._graph.number_of_etypes() == 1 or etype is not None:
etid = self.get_etype_id(etype)
etype = self.canonical_etypes[etid] #
_, dtid = self._graph.metagraph.find_edge(etid) # 输入边的种类,输出该边
\连接的src和dst的节点种类
g = self if etype is None else self[etype] # 只选取etype内的边构成的子图
ndata = core.message_passing(g, message_func, reduce_func, apply_node_func) # 进行消息
\传递
if core.is_builtin(reduce_func) and reduce_func.name in ['min', 'max'] and ndata:
# is_builtin用于判断传入的reduce_func方法是否是在dgl自带函数中
# Replace infinity with zero for isolated nodes
key = list(ndata.keys())[0]
ndata[key] = F.replace_inf_with_zero(ndata[key])
self._set_n_repr(dtid, ALL, ndata)
1、is_builtin
is_builtin用于判断传入的reduce_func参数是否是在dgl自带函数中
def is_builtin(func):
"""Return true if the function is a DGL builtin function."""
return isinstance(func, fn.BuiltinFunction)
2、message_passing
对整张图进行消息传递,输入图g和三个消息传递函数,消息函数,收缩函数,应用函数(默认为None)
但是也并没有直接执行消息传递的内容,而是先判断传入的参数,对应不同情况,执行invoke_gspmm实现消息传递
开始先判断两个函数是否是库支持的函数,否则就会进入到else中,去适应其他自定义的函数
然后调用invoke_gspmm(g, mfunc, rfunc)来实现
def message_passing(g, mfunc, rfunc, afunc):
if (is_builtin(mfunc) and is_builtin(rfunc) and
getattr(ops, '{}_{}'.format(mfunc.name, rfunc.name), None) is not None):
# invoke fused message passing
ndata = invoke_gspmm(g, mfunc, rfunc)
else:
# invoke message passing in two separate steps
# message phase
if is_builtin(mfunc):
msgdata = invoke_gsddmm(g, mfunc)
else:
orig_eid = g.edata.get(EID, None)
msgdata = invoke_edge_udf(g, ALL, g.canonical_etypes[0], mfunc, orig_eid=orig_eid)
# reduce phase
if is_builtin(rfunc):
msg = rfunc.msg_field
ndata = invoke_gspmm(g, fn.copy_e(msg, msg), rfunc, edata=msgdata)
else:
orig_nid = g.dstdata.get(NID, None)
ndata = invoke_udf_reduce(g, rfunc, msgdata, orig_nid=orig_nid)
# apply phase
if afunc is not None:
for k, v in g.dstdata.items(): # include original node features
if k not in ndata:
ndata[k] = v
orig_nid = g.dstdata.get(NID, None)
ndata = invoke_node_udf(g, ALL, g.dsttypes[0], afunc, ndata=ndata, orig_nid=orig_nid)
return ndata
最后将invoke后的ndata传出,返回到update_all中的ndata
invoke_gspmm
上面说到了调用这个函数,这里看一下是如何实现的
需要注意到的是本函数的实现基于DGL团队2019年提出的g-SPMM(稀疏矩阵乘法)方法
这个是论文的链接
https://arxiv.org/abs/1909.01315
首先是函数的定义和参数的介绍
def invoke_gspmm(graph, mfunc, rfunc, *, srcdata=None, dstdata=None, edata=None):
"""Invoke g-SPMM computation on the graph.
Parameters
----------
graph : DGLGraph
The input graph.
mfunc : dgl.function.BaseMessageFunction
Built-in message function.
rfunc : dgl.function.BaseReduceFunction
Built-in reduce function.
srcdata : dict[str, Tensor], optional
Source node feature data. If not provided, it use ``graph.srcdata``.
dstdata : dict[str, Tensor], optional
Destination node feature data. If not provided, it use ``graph.dstdata``.
edata : dict[str, Tensor], optional
Edge feature data. If not provided, it use ``graph.edata``.
Returns
-------
dict[str, Tensor]
Results from the g-SPMM computation.
"""
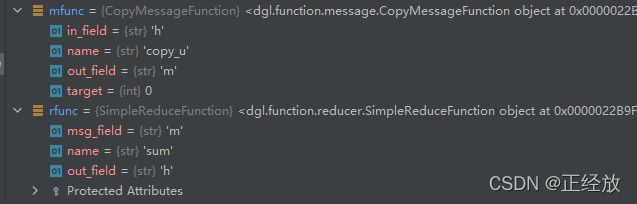
这里我们可以看到mfunc 和 rfunc的相关信息,下面代码的第一行是判断两个函数调用的graph.data的数据域是否一致,否则就无法实现完整的消息传递。
# sanity check
if mfunc.out_field != rfunc.msg_field:
raise DGLError('Invalid message ({}) and reduce ({}) function pairs.'
' The output field of the message function must be equal to the'
' message field of the reduce function.'.format(mfunc, rfunc))
然后判断并存储图信息。
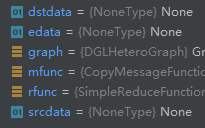
从上图变成了下图
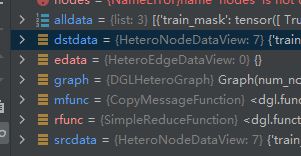
view一下dst_data如下

if edata is None:
edata = graph.edata
if srcdata is None:
srcdata = graph.srcdata
if dstdata is None:
dstdata = graph.dstdata
alldata = [srcdata, dstdata, edata]
首先判断mfunc不在BinaryMessageFunction中:
对于copy_u则进入else中
if isinstance(mfunc, fn.BinaryMessageFunction):
x = alldata[mfunc.lhs][mfunc.lhs_field]
y = alldata[mfunc.rhs][mfunc.rhs_field]
op = getattr(ops, '{}_{}'.format(mfunc.name, rfunc.name))
if graph._graph.number_of_etypes() > 1:
lhs_target, _, rhs_target = mfunc.name.split("_", 2)
x = data_dict_to_list(graph, x, mfunc, lhs_target)
y = data_dict_to_list(graph, y, mfunc, rhs_target)
z = op(graph, x, y)
首先把data[‘h’]传到x中,即(2708,7)的特征矩阵
op为在dlg.ops中寻找mfunc和rfunc对应的传播函数
z接受op函数调用的结果
else:
x = alldata[mfunc.target][mfunc.in_field]
op = getattr(ops, '{}_{}'.format(mfunc.name, rfunc.name))
if graph._graph.number_of_etypes() > 1 and not isinstance(x, tuple):
if mfunc.name == "copy_u":
x = data_dict_to_list(graph, x, mfunc, 'u')
else: # "copy_e"
x = data_dict_to_list(graph, x, mfunc, 'e')
z = op(graph, x)
return {rfunc.out_field : z}
打开调用的op
代码如下:
def func(g, x):
if binary_op == 'copy_u':
return gspmm(g, 'copy_lhs', reduce_op, x, None)
else:
return gspmm(g, 'copy_rhs', reduce_op, None, x)
func.__name__ = name
func.__doc__ = docstring(binary_op)
return func
gspmm
终于到了这里我们找到了消息传播真正实现部分
代码是在dgl/ops/spmm.py文件夹下
我把代码中的注释删掉了,大致内容如下:
gspmm把两个处理步骤放在了一起
用op进行消息计算,reduce_op进行消息聚合
基于这个公式进行更新,且这个公式不涉及到梯度传播阶段,不在更新范围之中
Xv是需要返回的dstdata,Xu和Xe是消息传播出的data
之所以拆成srcdata和dstdata是为了让节点的特征同步更新,保持同次训练时序上的更新一致性。op : 可能是
add,sub,mul,div,copy_lhs,copy_rhs.
reduce_op : 可能是sum,max,min,mean.
lhs_data : tensor or None
The left operand, could be None if it’s not required by the op.
rhs_data : tensor or None
The right operand, could be None if it’s not required by the op.
返回值:消息传递后的特征张量
此时op是copy_lhs
**接下来调用gspmm_internal(在代码开始from …backend import gspmm as gspmm_internal, 所以调用的实际上是另一个gspmm ),这里对聚合函数中的mean先求sum,然后在调用之后再做取平均处理。
返回的ret是如下图所示的消息传播之后的张量
invoke_gspmm的{rfunc.out_field : z},中的z就是ret,进而messagepassing中的ndata:ndata = invoke_gspmm(g, mfunc, rfunc),就是{rfunc.out_field : z},进而再把这个ndata返回到了update中:
在这个函数中,调用了ndata self._set_n_repr(dtid, ALL, ndata),将原本graph中ndata[‘rfunc.out_field’]的存储内容更新成了z
标志着一轮的消息传递结束。
但是我们还需要继续往底层看,看看ret是如何计算出来的。
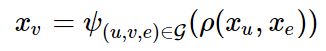
def gspmm(g, op, reduce_op, lhs_data, rhs_data):
if g._graph.number_of_etypes() == 1:
if op not in ['copy_lhs', 'copy_rhs']:
lhs_data, rhs_data = reshape_lhs_rhs(lhs_data, rhs_data)
# With max and min reducers infinity will be returned for zero degree nodes
ret = gspmm_internal(g._graph, op,
'sum' if reduce_op == 'mean' else reduce_op,
lhs_data, rhs_data)
else:
# lhs_data or rhs_data is None only in unary functions like ``copy-u`` or ``copy_e``
lhs_data = [None] * g._graph.number_of_ntypes() if lhs_data is None else lhs_data
rhs_data = [None] * g._graph.number_of_etypes() if rhs_data is None else rhs_data
# TODO (Israt): Call reshape func
lhs_and_rhs_tuple = tuple(list(lhs_data) + list(rhs_data))
ret = gspmm_internal_hetero(g._graph, op,
'sum' if reduce_op == 'mean' else reduce_op,
len(lhs_data), *lhs_and_rhs_tuple)
# TODO (Israt): Add support for 'mean' in heterograph
# divide in degrees for mean reducer.
if reduce_op == 'mean':
ret_shape = F.shape(ret)
deg = g.in_degrees()
deg = F.astype(F.clamp(deg, 1, max(g.number_of_edges(), 1)), F.dtype(ret))
deg_shape = (ret_shape[0],) + (1,) * (len(ret_shape) - 1)
return ret / F.reshape(deg, deg_shape)
else:
return ret
ret是根据gspmm_internal 也就是import 的gspmm计算的,所以继续往下看:
gspmm_internal
这里对减和除简单化,然后调用GSpMM.apply
def gspmm(gidx, op, reduce_op, lhs_data, rhs_data):
if op == 'sub':
op = 'add'
rhs_data = -rhs_data
if op == 'div':
op = 'mul'
rhs_data = 1. / rhs_data
return GSpMM.apply(gidx, op, reduce_op, lhs_data, rhs_data)
在这里值得说一句的是,GSpMM这个类是下面这个结构,定义了如下的方法(函数内容在这里省略了)。@staticmethod修饰的静态方法可以让我们不用实例化这个类就可以调用内部的函数,就像GSpMM.apply这样。
接下来因为对forward加了语法糖, @custom_fwd,所以会执行custom_fwd类中的代码
装饰器的本质,主要是为了拓展装饰器函数本身的功能,关于修饰器和语法糖的内容可以参考这篇博客:Python @ 语法糖,装饰器(详解)
class GSpMM(th.autograd.Function):
@staticmethod
@custom_fwd(cast_inputs=th.float16)
def forward(ctx, gidx, op, reduce_op, X, Y):
@staticmethod
@custom_bwd
def backward(ctx, dZ):
因为有@custom_bwd的修饰,实际上运行的是custom_fwd函数。
def custom_fwd(fwd=None, **kwargs):
关于args和kwargs是一个元组和一个字典,具体内容可以参考下面的博客:
Python中的*args和**kwargs
可以看到参数正确的传入到了args中,并且@custom_fwd(cast_inputs=th.float16)中的cast_inputs也顺利加了进来,如下图所示。
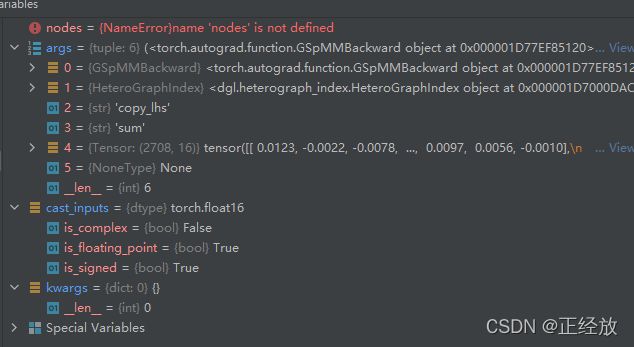
wraps本质是装饰器工程函数,因为其返回值是partial实例,partial实例可以作为装饰器修饰其它函数。
关于functools.wraps的更多内容,可以参考下面的博客
【Python装饰器】functools.wraps函数保留被装饰函数的元信息
下面的代码是custom_fwd的前半部分,在以装饰器的方式调用custom_fwd的时候,会先执行这部分的代码,然后再返回到调用前的地方。
if fwd is None:
if len(kwargs) == 0:
cast_inputs = None
else:
assert len(kwargs) == 1
cast_inputs = kwargs["cast_inputs"]
return functools.partial(custom_fwd, cast_inputs=cast_inputs)
if len(kwargs) == 0:
cast_inputs = None
else:
assert len(kwargs) == 1
cast_inputs = kwargs["cast_inputs"]
然后在下半部分将GSpMM的forword和backward函数都作为GSpMM(th.autograd.Function)模型的前向传播和后向传播函数被加载,具体代码细节不展开讲解,主要是利用了functools.wraps的函数打包功能。
@functools.wraps(fwd)
def decorate_fwd(*args, **kwargs):
if cast_inputs is None:
args[0]._fwd_used_autocast = torch.is_autocast_enabled()
return fwd(*args, **kwargs)
else:
autocast_context = torch.is_autocast_enabled()
args[0]._fwd_used_autocast = False
if autocast_context:
with autocast(enabled=False):
return fwd(*_cast(args, cast_inputs), **_cast(kwargs, cast_inputs))
else:
return fwd(*args, **kwargs)
return decorate_fwd
调试中发现,decorate_fwd走到了倒数第二行的这一步return fwd(*args, **kwargs),fwd就是被装饰器修饰的GSpMM.forward(),也就是继续向gspmm的实现迈进了,下面回到GSpMM类中
我们回顾一开始的传参:
GSpMM.apply(gidx, op, reduce_op, lhs_data, rhs_data)
在decorate_fwd中,args又在一开始加入了新的变化:
args[0]._fwd_used_autocast = torch.is_autocast_enabled()
所以就有了ctx, gidx, op, reduce_op, X, Y这六个参数
def forward(ctx, gidx, op, reduce_op, X, Y):
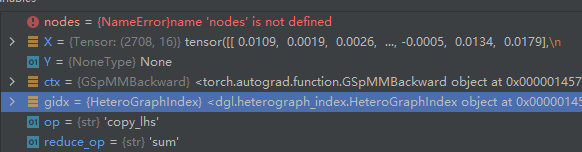
这里面调用了_gspmm,然后进行一些规定的数据处理,和为反向传播存储一些数据,返回出的out就是上一层函数接收的ret
out, (argX, argY) = _gspmm(gidx, op, reduce_op, X, Y)
reduce_last = _need_reduce_last_dim(X, Y)
X_shape = X.shape if X is not None else None
Y_shape = Y.shape if Y is not None else None
dtype = X.dtype if X is not None else Y.dtype
device = X.device if X is not None else Y.device
ctx.backward_cache = gidx, op, reduce_op, X_shape, Y_shape, dtype, device, reduce_last
req_grad_X = X.requires_grad if X is not None else False
req_grad_Y = Y.requires_grad if Y is not None else False
if not spmm_cache_X(op, reduce_op, req_grad_X, req_grad_Y):
X = None
if not spmm_cache_Y(op, reduce_op, req_grad_X, req_grad_Y):
Y = None
if not spmm_cache_argX(op, reduce_op, req_grad_X, req_grad_Y):
argX = None
if not spmm_cache_argY(op, reduce_op, req_grad_X, req_grad_Y):
argY = None
ctx.save_for_backward(X, Y, argX, argY)
return out
_gspmm
这里不特别详细的展开,通过注释解释。
def _gspmm(gidx, op, reduce_op, u, e):
if gidx.number_of_etypes() != 1:
raise DGLError("We only support gspmm on graph with one edge type")
use_u = op != 'copy_rhs'
use_e = op != 'copy_lhs'
if use_u and use_e:
if F.dtype(u) != F.dtype(e):
raise DGLError("The node features' data type {} doesn't match edge"
" features' data type {}, please convert them to the"
" same type.".format(F.dtype(u), F.dtype(e)))
# deal with scalar features.
expand_u, expand_e = False, False
if use_u:
if F.ndim(u) == 1:
u = F.unsqueeze(u, -1)
expand_u = True
if use_e:
if F.ndim(e) == 1:
e = F.unsqueeze(e, -1)
expand_e = True
# 以上更新了参数,use_e是False,因为没有用到边信息,use_u是True,因为copy_rhs是True
ctx = F.context(u) if use_u else F.context(e) # ctx为u对应的device : cpu
dtype = F.dtype(u) if use_u else F.dtype(e) # dtype是u中的数据格式 : torch.float32
u_shp = F.shape(u) if use_u else (0,) # u的格式 : (2708, 16)
e_shp = F.shape(e) if use_e else (0,) # e的格式 : (0,)
_, dsttype = gidx.metagraph.find_edge(0) # 边的种类号 : 0
v_shp = (gidx.number_of_nodes(dsttype), ) +\
infer_broadcast_shape(op, u_shp[1:], e_shp[1:]) # v_shp对应需要传递的张量维度(2708, 16)
v = F.zeros(v_shp, dtype, ctx) # 初始化传递后的结果张量
use_cmp = reduce_op in ['max', 'min'] # 是否需要比较
arg_u, arg_e = None, None
idtype = getattr(F, gidx.dtype)
if use_cmp: # use_cmp是None所以不执行
if use_u:
arg_u = F.zeros(v_shp, idtype, ctx)
if use_e:
arg_e = F.zeros(v_shp, idtype, ctx)
arg_u_nd = to_dgl_nd_for_write(arg_u) # arg_u是None,arg_u_nd是[]
arg_e_nd = to_dgl_nd_for_write(arg_e) # arg_e是None,arg_e_nd是[]
if gidx.number_of_edges(0) > 0:
_CAPI_DGLKernelSpMM(gidx, op, reduce_op,
to_dgl_nd(u if use_u else None),
to_dgl_nd(e if use_e else None),
to_dgl_nd_for_write(v),
arg_u_nd,
arg_e_nd) # 在这个函数里,v被更新了
# NOTE(zihao): actually we can avoid the following step, because arg_*_nd
# refers to the data that stores arg_*. After we call _CAPI_DGLKernelSpMM,
# arg_* should have already been changed. But we found this doesn't work
# under Tensorflow when index type is int32. (arg_u and arg_e would be
# all zero).
# The workaround is proposed by Jinjing, and we still need to investigate
# where the problem is.
arg_u = None if arg_u is None else F.zerocopy_from_dgl_ndarray(arg_u_nd)
arg_e = None if arg_e is None else F.zerocopy_from_dgl_ndarray(arg_e_nd)
# To deal with scalar node/edge features.
if (expand_u or not use_u) and (expand_e or not use_e):
v = F.squeeze(v, -1)
if expand_u and use_cmp:
arg_u = F.squeeze(arg_u, -1)
if expand_e and use_cmp:
arg_e = F.squeeze(arg_e, -1)
return v, (arg_u, arg_e)
返回的v就是经过dgl内核函数更新后的矩阵,然后向外一层层传递
3、_set_n_repr
update_all返回时调用了 self._set_n_repr(dtid, ALL, ndata):
代码如下,ntid就是传入的dtid,对于同构图就是0
data是update_all传入的ndata,ndata是经过message_passing得到的[2708,7]的特征矩阵
nfeats为取出data的第一维度长度,即2708
for key, val in data.items():这一循环体内并没有做实际的运算,而是判断程序是否出错。
def _set_n_repr(self, ntid, u, data):
"""
Parameters
----------
ntid : int
Node type id.
u : node, container or tensor
The node(s).
data : dict of tensor
Node representation.
"""
if is_all(u):
num_nodes = self._graph.number_of_nodes(ntid)
else:
u = utils.prepare_tensor(self, u, 'u')
num_nodes = len(u)
for key, val in data.items():
nfeats = F.shape(val)[0]
if nfeats != num_nodes:
raise DGLError('Expect number of features to match number of nodes (len(u)).'
' Got %d and %d instead.' % (nfeats, num_nodes))
if F.context(val) != self.device:
raise DGLError('Cannot assign node feature "{}" on device {} to a graph on'
' device {}. Call DGLGraph.to() to copy the graph to the'
' same device.'.format(key, F.context(val), self.device))
函数最后一部分才执行了最重要的操作:
调用了update函数,对data进行更新
if is_all(u):
self._node_frames[ntid].update(data)
else:
self._node_frames[ntid].update_row(u, data)
def is_all(arg):
"""Return true if the argument is a special symbol for all nodes or edges."""
return isinstance(arg, str) and arg == ALL
(1) update
self._node_frames[ntid]是一个继承了Mapping的类 class MutableMapping(Mapping),它有update的方法。
首先判断传入的data是否是Mapping类型,然后对于data,也就是other中的每一个属性(在本次运行中目前只产生了’h’一个属性),为这个,添加other的属性到self中。
其实完成的就是一个数据拷贝的过程,目前猜测需要通过这种方式更新可能是由于graph.local_scope()的关系不能直接改变graph当中的数据存储。
def update(self, other=(), /, **kwds):
if isinstance(other, Mapping):
for key in other:
self[key] = other[key]
elif hasattr(other, "keys"):
for key in other.keys():
self[key] = other[key]
else:
for key, value in other:
self[key] = value
for key, value in kwds.items():
self[key] = value
执行完之后,我们可以看到graph._node_frames中多了’h’这个属性
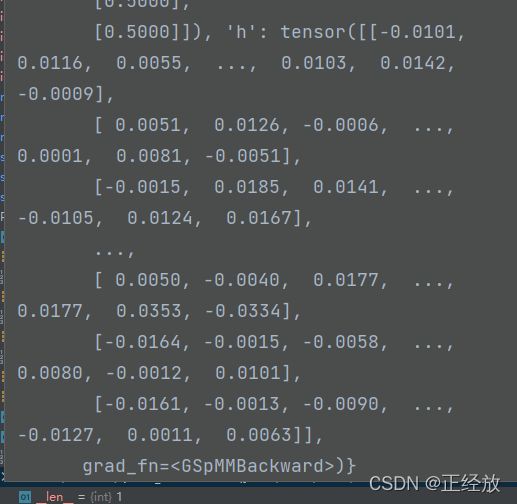
————————————————————————————————————————————————————
这是update_all的后半部分,但是是应用于异构图的,这里不做详细解释
else: # heterogeneous graph with number of relation types > 1
if not core.is_builtin(message_func) or not core.is_builtin(reduce_func):
raise DGLError("User defined functions are not yet "
"supported in update_all for heterogeneous graphs. "
"Please use multi_update_all instead.")
if reduce_func.name in ['mean']:
raise NotImplementedError("Cannot set both intra-type and inter-type reduce "
"operators as 'mean' using update_all. Please use "
"multi_update_all instead.")
g = self
all_out = core.message_passing(g, message_func, reduce_func, apply_node_func)
key = list(all_out.keys())[0]
out_tensor_tuples = all_out[key]
dst_tensor = {}
for _, _, dsttype in g.canonical_etypes:
dtid = g.get_ntype_id(dsttype)
dst_tensor[key] = out_tensor_tuples[dtid]
if core.is_builtin(reduce_func) and reduce_func.name in ['min', 'max']:
dst_tensor[key] = F.replace_inf_with_zero(dst_tensor[key])
self._node_frames[dtid].update(dst_tensor)